SpringBoot(05):Spring Data JPA------用面向对象的方式操作数据库

写 SQL 是一件很拧巴的事。Java 是面向对象的语言,但一碰到数据库,就得写一堆字符串拼 SQL,用 ResultSet 一行行取字段再塞进对象里。增删改查四个操作,每个都要手动处理连接、异常、资源关闭。更烦的是,表结构一改,几十处 SQL 得跟着动。Spring Data JPA 的思路很直接:你只管定义 Java 对象和接口,SQL 的事框架帮你搞定。
问题:Java 对象和关系数据库的割裂
假设有一张用户表,用 JDBC 实现查询:
ini
public User findById(Long id) {
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
conn = dataSource.getConnection();
ps = conn.prepareStatement("SELECT id, name, age, email FROM user WHERE id = ?");
ps.setLong(1, id);
rs = ps.executeQuery();
if (rs.next()) {
User user = new User();
user.setId(rs.getLong("id"));
user.setName(rs.getString("name"));
user.setAge(rs.getInt("age"));
user.setEmail(rs.getString("email"));
return user;
}
return null;
} catch (SQLException e) {
throw new RuntimeException(e);
} finally {
if (rs != null) try { rs.close(); } catch (SQLException ignored) {}
if (ps != null) try { ps.close(); } catch (SQLException ignored) {}
if (conn != null) try { conn.close(); } catch (SQLException ignored) {}
}
}20 多行代码,就干了一件事:把数据库里的一行记录变成一个 Java 对象。10 张表、每张表 5 个查询方法,这种代码得写 50 遍。MyBatis 用 XML 把 SQL 和 Java 代码分开了,但你还是得手写每一条 SQL。JPA 走了另一条路:你定义好 Java 实体类和字段映射,框架根据方法名或者注解自动生成 SQL。
JPA 是什么
JPA(Java Persistence API)是 Java 的一套 ORM 规范,定义了用面向对象的方式操作关系数据库的标准接口。注意,JPA 是规范,不是实现。最常见的实现是 Hibernate。
 几个关键概念:
几个关键概念:
- Entity(实体) :一个 Java 类映射到数据库的一张表,类的字段映射到表的列
- EntityManager:JPA 的核心接口,负责实体的增删改查、事务管理
- JPQL:Java Persistence Query Language,面向对象的查询语言,操作的是实体类而不是表
- Spring Data JPA:Spring 在 JPA 之上又做了一层封装,通过 Repository 接口进一步减少代码量
Spring Boot 集成 Spring Data JPA
引入依赖
xml
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>一个 starter 全搞定。它会自动引入 Hibernate、Spring Data JPA、Spring ORM 等依赖。
配置数据源
yaml
spring:
datasource:
url: jdbc:mysql://localhost:3306/mydb?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
jpa:
hibernate:
ddl-auto: update
show-sql: true
properties:
hibernate:
format_sql: true几个配置项说明:
| 配置 | 作用 |
|---|---|
ddl-auto: update |
启动时自动根据实体类更新表结构(生产环境用 validate 或 none) |
show-sql: true |
控制台打印执行的 SQL |
format_sql: true |
格式化 SQL,方便调试 |
定义实体类
less
@Entity
@Table(name = "user")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "name", length = 50, nullable = false)
private String name;
@Column(name = "age")
private Integer age;
@Column(name = "email", length = 100)
private String email;
@CreationTimestamp
@Column(name = "create_time", updatable = false)
private LocalDateTime createTime;
@UpdateTimestamp
@Column(name = "update_time")
private LocalDateTime updateTime;
public User() {}
// getter / setter 省略
}核心注解说明:
| 注解 | 作用 |
|---|---|
@Entity |
标记这个类是一个 JPA 实体 |
@Table |
指定映射的数据库表名 |
@Id |
标记主键字段 |
@GeneratedValue |
主键生成策略,IDENTITY 表示数据库自增 |
@Column |
映射数据库列,可指定列名、长度、是否可空 |
@CreationTimestamp |
插入时自动填充当前时间 |
@UpdateTimestamp |
更新时自动填充当前时间 |
定义 Repository 接口
csharp
public interface UserRepository extends JpaRepository<User, Long> {
}就这样。继承了 JpaRepository<User, Long>,Spring Data JPA 自动给你注入了完整的 CRUD 方法。你一行实现代码都不用写。
直接使用
scss
@SpringBootTest
class UserRepositoryTest {
@Autowired
private UserRepository userRepository;
@Test
void testInsert() {
User user = new User();
user.setName("张三");
user.setAge(25);
user.setEmail("zhangsan@example.com");
userRepository.save(user);
System.out.println("插入成功,id = " + user.getId());
}
@Test
void testFindById() {
User user = userRepository.findById(1L).orElse(null);
System.out.println(user);
}
@Test
void testFindAll() {
List<User> users = userRepository.findAll();
users.forEach(System.out::println);
}
@Test
void testUpdate() {
User user = userRepository.findById(1L).orElse(null);
if (user != null) {
user.setName("李四");
userRepository.save(user);
}
}
@Test
void testDelete() {
userRepository.deleteById(1L);
}
}没写一行 SQL,没写一行实现代码,增删改查全有了。
JpaRepository 提供的方法
JpaRepository 继承自 PagingAndSortingRepository,后者又继承自 CrudRepository。三层加起来,提供了以下方法:
csharp
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
// 批量保存
List<T> saveAll(Iterable<S> entities);
// 批量刷新到数据库
void flush();
// 保存并刷新
<S extends T> S saveAndFlush(S entity);
// 批量删除(实体)
void deleteAllInBatch(Iterable<T> entities);
// 截断表(直接 TRUNCATE,不一条条删)
void deleteAllInBatch();
// 根据ID获取引用(延迟加载,不立即查数据库)
T getOne(ID id);
T getById(ID id);
// Example 查询
<S extends T> List<S> findAll(Example<S> example);
<S extends T> List<S> findAll(Example<S> example, Sort sort);
}CrudRepository 提供的基础方法:
csharp
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S entity); // 保存(id 为空则 insert,不为空则 update)
Optional<T> findById(ID id); // 根据 ID 查询
boolean existsById(ID id); // 判断是否存在
List<T> findAll(); // 查询全部
List<T> findAllById(Iterable<ID> ids); // 根据 ID 批量查询
long count(); // 统计总数
void deleteById(ID id); // 根据 ID 删除
void delete(T entity); // 根据实体删除
void deleteAllById(Iterable<? extends ID> ids);
void deleteAll(Iterable<? extends T> entities);
void deleteAll(); // 删除全部
}PagingAndSortingRepository 增加分页和排序:
csharp
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort sort);
Page<T> findAll(Pageable pageable);
}数一下,JpaRepository 及其父接口加起来提供了将近 40 个方法,日常开发够用了。
方法名派生查询:最省事的功能
Spring Data JPA 最省事的功能:你只要按规则定义方法名,框架自动生成查询 SQL。
基本规则
方法名以 findBy、readBy、queryBy、getBy 开头,后面接字段名和查询条件:
arduino
public interface UserRepository extends JpaRepository<User, Long> {
// 根据名字查
User findByName(String name);
// 根据名字和年龄查
List<User> findByNameAndAge(String name, Integer age);
// 根据名字或邮箱查
List<User> findByNameOrEmail(String name, String email);
// 年龄小于某个值
List<User> findByAgeLessThan(Integer age);
// 名字模糊查询
List<User> findByNameContaining(String keyword);
// 名字以某个前缀开头
List<User> findByNameStartingWith(String prefix);
// 年龄在某个范围内
List<User> findByAgeBetween(Integer min, Integer max);
// 邮箱不为空
List<User> findByEmailNotNull();
// 按年龄降序
List<User> findAllByOrderByAgeDesc();
// 组合条件:名字包含关键词且年龄大于某个值,按创建时间降序
List<User> findByNameContainingAndAgeGreaterThanOrderByCreateTimeDesc(
String keyword, Integer minAge);
}支持的关键字
| 关键字 | JPQL 片段 | 示例 |
|---|---|---|
And |
AND | findByNameAndAge |
Or |
OR | findByNameOrEmail |
Is, Equals |
= | findByName / findByNameIs |
Not |
!= | findByNameNot |
LessThan |
< | findByAgeLessThan |
LessThanEqual |
<= | findByAgeLessThanEqual |
GreaterThan |
findByAgeGreaterThan |
|
GreaterThanEqual |
>= | findByAgeGreaterThanEqual |
Between |
BETWEEN | findByAgeBetween |
Before |
< (时间) | findByCreateTimeBefore |
After |
> (时间) | findByCreateTimeAfter |
IsNull |
IS NULL | findByEmailIsNull |
IsNotNull |
IS NOT NULL | findByEmailNotNull |
Like |
LIKE | findByNameLike |
NotLike |
NOT LIKE | findByNameNotLike |
Containing |
LIKE '%x%' | findByNameContaining |
StartingWith |
LIKE 'x%' | findByNameStartingWith |
EndingWith |
LIKE '%x' | findByNameEndingWith |
In |
IN | findByAgeIn(List<Integer>) |
NotIn |
NOT IN | findByAgeNotIn |
OrderBy |
ORDER BY | findByAgeOrderByNameDesc |
True |
= true | findByActiveTrue |
False |
= false | findByActiveFalse |
IgnoreCase |
忽略大小写 | findByNameIgnoreCase |
方法名支持的条件嵌套最多到三层。超过三层或者条件太多,方法名会变得又臭又长,这种时候就用 @Query 注解。
限制查询结果
scss
// 只取第一条
User findFirstByName(String name);
User findTopByName(String name);
// 取前 10 条
List<User> findTop10ByAgeGreaterThan(Integer age);
List<User> findFirst10ByAgeGreaterThan(Integer age);删除操作
arduino
// 根据名字删除(返回删除的记录数)
Long deleteByName(String name);
// 根据名字删除(返回被删除的实体列表)
List<User> removeByName(String name);这些删除方法默认会先查出符合条件的记录,再逐条删除。如果数据量大,用 @Query + @Modifying 写批量删除更高效。
@Query 注解:复杂查询的退路
方法名派生虽然方便,但碰上复杂条件就力不从心了。@Query 注解让你直接写 JPQL 或原生 SQL。
JPQL 查询
less
public interface UserRepository extends JpaRepository<User, Long> {
// JPQL:操作的是实体类和字段名,不是表名和列名
@Query("SELECT u FROM User u WHERE u.name = ?1 AND u.age > ?2")
List<User> findByNameAndAgeGreaterThan(String name, Integer age);
// 命名参数(推荐,可读性好)
@Query("SELECT u FROM User u WHERE u.name = :name AND u.email LIKE %:keyword%")
List<User> findByNameAndEmailKeyword(@Param("name") String name,
@Param("keyword") String keyword);
// 排序
@Query("SELECT u FROM User u WHERE u.age > :age ORDER BY u.createTime DESC")
List<User> findByAgeGreaterThan(@Param("age") Integer age);
// 只查部分字段(返回 Object[] 或用投影)
@Query("SELECT u.name, u.age FROM User u WHERE u.age BETWEEN :min AND :max")
List<Object[]> findNameAndAgeBetween(@Param("min") Integer min, @Param("max") Integer max);
// 统计
@Query("SELECT COUNT(u) FROM User u WHERE u.age > :age")
Long countByAgeGreaterThan(@Param("age") Integer age);
// 更新操作必须加 @Modifying
@Modifying
@Query("UPDATE User u SET u.age = :age WHERE u.name = :name")
int updateAgeByName(@Param("name") String name, @Param("age") Integer age);
// 删除操作
@Modifying
@Query("DELETE FROM User u WHERE u.createTime < :deadline")
int deleteByCreateTimeBefore(@Param("deadline") LocalDateTime deadline);
}注意:@Modifying 标记的更新和删除操作,必须在事务中执行。在 Service 层加 @Transactional 就行。
原生 SQL 查询
less
public interface UserRepository extends JpaRepository<User, Long> {
// nativeQuery = true 表示使用原生 SQL
@Query(value = "SELECT * FROM user WHERE age > ?1 LIMIT ?2", nativeQuery = true)
List<User> findByAgeGreaterThanLimit(Integer age, Integer limit);
// 复杂统计 SQL
@Query(value = "SELECT age, COUNT(*) as cnt FROM user GROUP BY age HAVING cnt > ?1",
nativeQuery = true)
List<Object[]> countGroupByAgeHaving(Long minCount);
// 分页查询(原生 SQL 也支持分页)
@Query(value = "SELECT * FROM user WHERE name LIKE %:keyword%",
countQuery = "SELECT COUNT(*) FROM user WHERE name LIKE %:keyword%",
nativeQuery = true)
Page<User> findByNameKeyword(@Param("keyword") String keyword, Pageable pageable);
}原生 SQL 直接操作表名和列名,不走 Hibernate 的 JPQL 翻译。适合复杂统计、数据库特有语法(如 MySQL 的 FIND_IN_SET)等场景。
分页查询
Spring Data JPA 自带分页支持,用 Pageable 参数就行。
基本分页
csharp
@Test
void testPage() {
// 第 1 页(从 0 开始),每页 10 条,按 id 降序
Pageable pageable = PageRequest.of(0, 10, Sort.by(Sort.Direction.DESC, "id"));
Page<User> page = userRepository.findAll(pageable);
System.out.println("总记录数: " + page.getTotalElements());
System.out.println("总页数: " + page.getTotalPages());
System.out.println("当前页数据: " + page.getContent());
System.out.println("当前页码: " + page.getNumber());
System.out.println("每页条数: " + page.getSize());
System.out.println("是否有下一页: " + page.hasNext());
}带条件的分页
less
// Repository 中定义带分页的查询方法
@Query("SELECT u FROM User u WHERE u.name LIKE %:keyword%")
Page<User> findByNameKeyword(@Param("keyword") String keyword, Pageable pageable);
// Controller 中使用
@GetMapping("/page")
public Page<User> page(@RequestParam(defaultValue = "0") Integer page,
@RequestParam(defaultValue = "10") Integer size,
@RequestParam(required = false) String keyword) {
Pageable pageable = PageRequest.of(page, size, Sort.by(Sort.Direction.DESC, "id"));
if (StringUtils.isNotBlank(keyword)) {
return userRepository.findByNameKeyword(keyword, pageable);
}
return userRepository.findAll(pageable);
}Sort 排序
ini
// 单字段排序
Sort sort = Sort.by(Sort.Direction.DESC, "age");
List<User> users = userRepository.findAll(sort);
// 多字段排序
Sort sort = Sort.by("age").descending()
.and(Sort.by("name").ascending());
List<User> users = userRepository.findAll(sort);实体关联关系
数据库表之间有关联关系,JPA 用注解在实体类之间表达这些关系。
一对多 / 多对一
一个部门有多个员工:
less
@Entity
@Table(name = "department")
public class Department {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "name")
private String name;
// 一个部门有多个员工
// mappedBy:由 Employee 的 department 字段维护关联关系
// FetchType.LAZY:延迟加载,用到的时候才查
@OneToMany(mappedBy = "department", fetch = FetchType.LAZY)
private List<Employee> employees = new ArrayList<>();
}
less
@Entity
@Table(name = "employee")
public class Employee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "name")
private String name;
// 多个员工属于一个部门
// FetchType.LAZY:延迟加载
// JoinColumn:外键列名
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "department_id")
private Department department;
}一对一
一个用户有一个详情:
less
@Entity
@Table(name = "user")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// cascade:级联操作,保存用户时自动保存详情
// orphanRemoval:删除孤立记录
@OneToOne(cascade = CascadeType.ALL, orphanRemoval = true)
@JoinColumn(name = "detail_id")
private UserDetail detail;
}
less
@Entity
@Table(name = "user_detail")
public class UserDetail {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "address")
private String address;
@Column(name = "phone")
private String phone;
}多对多
一个学生选多门课,一门课有多个学生:
less
@Entity
@Table(name = "student")
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// 中间表:student_course
@ManyToMany
@JoinTable(
name = "student_course",
joinColumns = @JoinColumn(name = "student_id"),
inverseJoinColumns = @JoinColumn(name = "course_id")
)
private List<Course> courses = new ArrayList<>();
}
less
@Entity
@Table(name = "course")
public class Course {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToMany(mappedBy = "courses")
private List<Student> students = new ArrayList<>();
}关联关系的坑
N+1 查询问题:这是 JPA 最容易踩的坑。查 10 个部门,每个部门的员工列表是延迟加载的,访问时每个部门再发一条 SQL 查员工。10 个部门发了 11 条 SQL(1 + 10)。数据量大的时候性能炸裂。
解决方案:
less
// 方案一:JOIN FETCH(推荐)
@Query("SELECT d FROM Department d LEFT JOIN FETCH d.employees WHERE d.id = :id")
Department findByIdWithEmployees(@Param("id") Long id);
// 方案二:@EntityGraph(不用改 JPQL)
@EntityGraph(attributePaths = {"employees"})
@Query("SELECT d FROM Department d")
List<Department> findAllWithEmployees();
// 方案三:批量获取(配置文件)
// hibernate.default_batch_fetch_size = 100延迟加载与序列化冲突 :用 @RestController 返回实体时,Jackson 序列化会触发延迟加载,可能导致 LazyInitializationException。解决方案有两个:在事务内返回 DTO,或者用 @JsonIgnore 忽略关联字段。
Specification 动态查询
方法名派生和 @Query 都是静态查询------编译期就确定了查询条件。如果查询条件是动态的(比如搜索框里填了哪些字段就按哪些字段查),用 Specification。
定义 Specification Repository
csharp
public interface UserRepository extends JpaRepository<User, Long>, JpaSpecificationExecutor<User> {
}多继承一个 JpaSpecificationExecutor<User> 就行。
使用 Specification
csharp
@Service
public class UserQueryService {
@Autowired
private UserRepository userRepository;
public Page<User> search(String name, Integer minAge, Integer maxAge,
String email, Pageable pageable) {
Specification<User> spec = (root, query, cb) -> {
List<Predicate> predicates = new ArrayList<>();
if (StringUtils.isNotBlank(name)) {
predicates.add(cb.like(root.get("name"), "%" + name + "%"));
}
if (minAge != null) {
predicates.add(cb.greaterThanOrEqualTo(root.get("age"), minAge));
}
if (maxAge != null) {
predicates.add(cb.lessThanOrEqualTo(root.get("age"), maxAge));
}
if (StringUtils.isNotBlank(email)) {
predicates.add(cb.like(root.get("email"), "%" + email + "%"));
}
return cb.and(predicates.toArray(new Predicate[0]));
};
return userRepository.findAll(spec, pageable);
}
}Specification 的三个参数:
Root<User>:实体的根对象,用来引用字段CriteriaQuery<?>:查询对象,可以设置 select、groupBy、having 等CriteriaBuilder:条件构造器,生成各种查询条件(等于、大于、Like 等)
可复用的 Specification
把常用的查询条件提取成静态方法,多个查询可以复用:
arduino
public class UserSpecs {
public static Specification<User> nameContains(String keyword) {
return (root, query, cb) ->
cb.like(root.get("name"), "%" + keyword + "%");
}
public static Specification<User> ageBetween(Integer min, Integer max) {
return (root, query, cb) ->
cb.between(root.get("age"), min, max);
}
public static Specification<User> emailContains(String keyword) {
return (root, query, cb) ->
cb.like(root.get("email"), "%" + keyword + "%");
}
}
// 使用:链式组合
Specification<User> spec = Specification
.where(UserSpecs.nameContains("张"))
.and(UserSpecs.ageBetween(20, 30));
List<User> users = userRepository.findAll(spec);原理:Spring Data JPA 怎么做到的
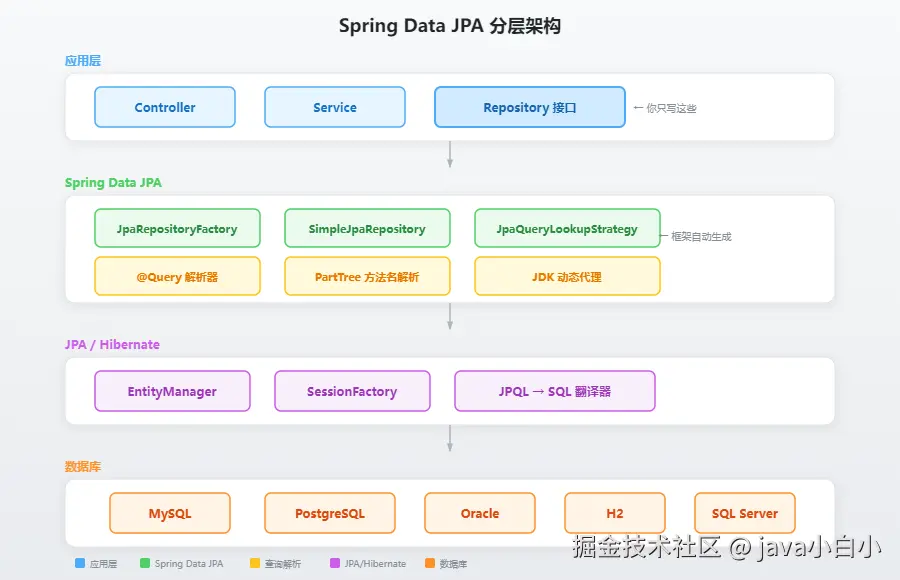
整体架构
 核心流程:
核心流程:
- 启动阶段 :Spring 扫描到
UserRepository接口,发现它继承了JpaRepository - 代理创建:Spring Data JPA 用 JDK 动态代理为接口生成实现类
- 方法解析 :对接口中每个方法,按优先级选择查询策略(
@Query> 方法名派生 > 默认) - SQL 生成:根据策略生成 JPQL,再由 Hibernate 翻译成 SQL
- 执行返回:执行 SQL,将 ResultSet 映射为 Java 对象
源码分析:Repository 代理的创建
入口是 @EnableJpaRepositories 注解,它导入了 JpaRepositoriesRegistrar:
scala
// org.springframework.data.jpa.repository.config.JpaRepositoriesRegistrar
public class JpaRepositoriesRegistrar extends RepositoryBeanDefinitionRegistrarSupport {
@Override
protected Class<? extends RepositoryFactorySupport> getRepositoryFactoryClassName() {
return JpaRepositoryFactory.class;
}
}JpaRepositoryFactory 是创建 Repository 代理的核心工厂:
scala
// org.springframework.data.jpa.repository.support.JpaRepositoryFactory
public class JpaRepositoryFactory extends RepositoryFactorySupport {
@Override
protected RepositoryMetadata getRepositoryMetadata(Class<?> repositoryInterface) {
return new DefaultRepositoryMetadata(repositoryInterface);
}
@Override
protected Object getTargetRepository(RepositoryInformation information) {
// 创建实际的 Repository 实现类
// 默认是 SimpleJpaRepository
JpaEntityInformation<?, ?> entityInformation = getEntityInformation(
information.getDomainType());
SimpleJpaRepository<?, ?> repository = getTargetRepositoryViaReflection(
information, entityInformation, entityManager,
getRepositoryMethodsWithQueryAnnotation()
);
return repository;
}
@Override
protected Class<?> getRepositoryBaseClass(RepositoryMetadata metadata) {
// 返回基础实现类
return SimpleJpaRepository.class;
}
}源码分析:SimpleJpaRepository------默认实现
你定义的 Repository 接口,最终由 SimpleJpaRepository 提供实现:
typescript
// org.springframework.data.jpa.repository.support.SimpleJpaRepository
public class SimpleJpaRepository<T, ID> implements JpaRepositoryImplementation<T, ID> {
private final JpaEntityInformation<T, ?> entityInformation;
private final EntityManager em;
private final PersistenceProvider provider;
@Override
@Transactional
public <S extends T> S save(S entity) {
// id 为空 → persist(insert)
// id 不为空 → merge(update)
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
@Override
public Optional<T> findById(ID id) {
return Optional.ofNullable(em.find(entityInformation.getJavaType(), id));
}
@Override
public List<T> findAll() {
return getQuery(null, Sort.unsorted()).getResultList();
}
@Override
public Page<T> findAll(Pageable pageable) {
if (pageable.isUnpaged()) {
return new PageImpl<>(findAll());
}
// 先查总数
long total = count();
// 再查数据
List<T> content = getQuery(null, pageable).getResultList();
return new PageImpl<>(content, pageable, total);
}
@Override
public void deleteById(ID id) {
// 先查出来再删(触发 JPA 生命周期回调)
T entity = findById(id).orElseThrow(
() -> new EmptyResultDataAccessException(
"No class entity with id " + id + " exists!", 1));
delete(entity);
}
@Override
public void delete(T entity) {
em.remove(em.contains(entity) ? entity : em.merge(entity));
}
}几个要点:
save()通过判断isNew()决定是persist还是merge,这也是为什么主键用包装类型(Long)比基本类型(long)好------null 表示新实体deleteById()先查再删,是为了触发 JPA 的@PreRemove生命周期回调findAll()内部调用getQuery()构建 JPQL 查询
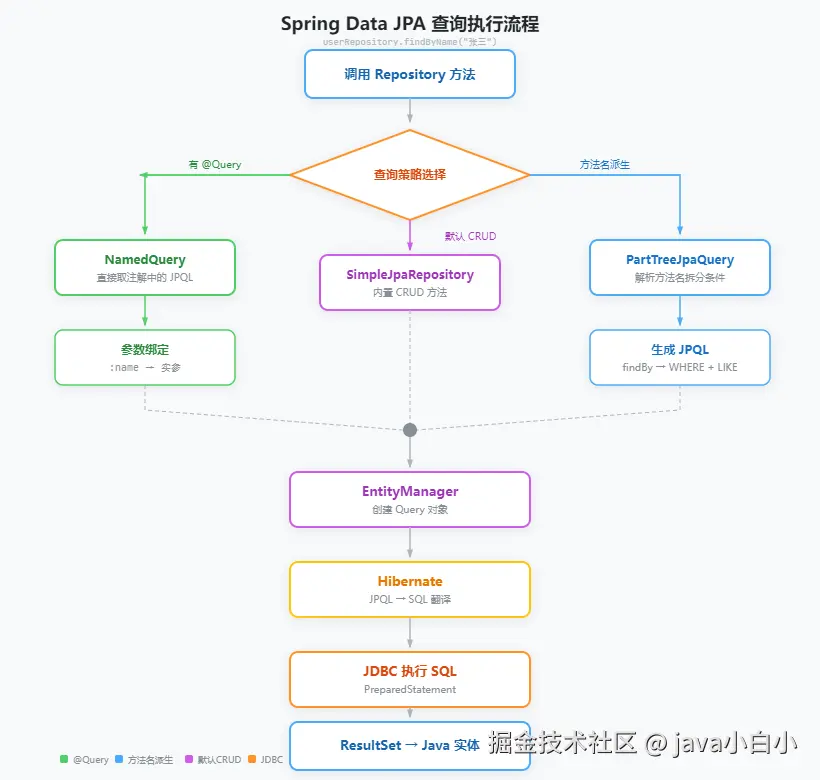
源码分析:方法名查询解析
当你在 Repository 接口定义了 findByNameAndAgeGreaterThan 方法时,Spring Data JPA 的解析过程:
arduino
// org.springframework.data.repository.query.parser.PartTree
public class PartTree implements Iterable<PartTree.OrPart> {
private final Subject subject; // select / count / delete
private final Predicate predicate; // 查询条件
public PartTree(String methodName, Class<?> domainClass) {
// 解析方法名
// findByNameAndAgeGreaterThan →
// Subject: find
// Predicate: Name And AgeGreaterThan
this.subject = new Subject(methodName);
this.predicate = new Predicate(methodName, domainClass);
}
}
scala
// org.springframework.data.jpa.repository.query.PartTreeJpaQuery
public class PartTreeJpaQuery extends AbstractJpaQuery {
@Override
protected Query doCreateQuery(JpaParametersParameterAccessor accessor) {
// 根据 PartTree 解析结果,构建 CriteriaBuilder 查询
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<?> query = cb.createQuery(domainClass);
Root<?> root = query.from(domainClass);
// Name → cb.like(root.get("name"), parameterValue)
// AgeGreaterThan → cb.greaterThan(root.get("age"), parameterValue)
// And → cb.and(predicate1, predicate2)
// 最终生成的 JPQL 等价于:
// SELECT u FROM User u WHERE u.name = ?1 AND u.age > ?2
return em.createQuery(query);
}
}源码分析:查询策略选择
Spring Data JPA 按以下优先级选择查询策略:
kotlin
// org.springframework.data.jpa.repository.query.JpaQueryLookupStrategy
public abstract class JpaQueryLookupStrategy implements QueryLookupStrategy {
@Override
public RepositoryQuery resolveQuery(Method method, RepositoryMetadata metadata,
ProjectionFactory factory, NamedQueries namedQueries) {
// 优先级1:查找 @Query 注解
RepositoryQuery query = lookupFromAnnotation(method, metadata, factory);
if (query != null) return query;
// 优先级2:查找 named query(实体类上的 @NamedQuery)
query = lookupFromNamedQueries(method, namedQueries);
if (query != null) return query;
// 优先级3:方法名派生查询(PartTree)
return createPartTreeQuery(method, metadata, factory);
}
}解析顺序:
- 方法上有
@Query→ 用注解里的 JPQL / SQL - 实体类上有对应的
@NamedQuery→ 用 NamedQuery - 都没有 → 解析方法名生成 JPQL
如果方法名不符合派生规则,启动时直接报错。
源码分析:save() 的 isNew 判断
typescript
// org.springframework.data.jpa.repository.support.JpaEntityInformationSupport
public boolean isNew(T entity) {
// 如果主键类型是 Number(Long, Integer 等)
if (id instanceof Number) {
// id 为 null 或 0,视为新实体
return ((Number) id).longValue() == 0L;
}
// 其他类型,id 为 null 视为新实体
return id == null;
}这就是为什么实体类的主键要用 Long 而不是 long------long 的默认值是 0,无法区分"未赋值"和"值为 0"。
实战功能
审计功能:自动填充创建人、修改人
除了 @CreationTimestamp 和 @UpdateTimestamp 自动填充时间,JPA 还支持自动填充创建人和修改人。
less
@Entity
@Table(name = "user")
@EntityListeners(AuditingEntityListener.class)
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@CreatedDate
@Column(name = "create_time", updatable = false)
private LocalDateTime createTime;
@LastModifiedDate
@Column(name = "update_time")
private LocalDateTime updateTime;
@CreatedBy
@Column(name = "created_by", updatable = false)
private String createdBy;
@LastModifiedBy
@Column(name = "updated_by")
private String updatedBy;
}配置 AuditorAware:
typescript
@Component
public class SpringSecurityAuditorAware implements AuditorAware<String> {
@Override
public Optional<String> getCurrentAuditor() {
// 从 SecurityContext 获取当前登录用户
return Optional.of(SecurityContextHolder.getContext()
.getAuthentication().getName());
}
}启动类加 @EnableJpaAuditing:
less
@SpringBootApplication
@EnableJpaAuditing
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}之后所有 save() 操作,创建时间、修改时间、创建人、修改人会自动填充。
乐观锁
less
@Entity
@Table(name = "product")
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private Integer stock;
@Version
private Integer version;
}加一个 @Version 注解就行。JPA 在 update 时会自动比对 version:
java
UPDATE product SET name = ?, stock = ?, version = 2 WHERE id = ? AND version = 1如果 version 不匹配,更新失败,抛出 OptimisticLockException。
生命周期回调
JPA 提供了实体生命周期回调,在特定操作前后执行自定义逻辑:
typescript
@Entity
@Table(name = "user")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String password;
@PrePersist
public void prePersist() {
// 插入前:密码加密
this.password = encryptPassword(this.password);
}
@PostPersist
public void postPersist() {
// 插入后:记录日志
log.info("新用户注册: id={}, name={}", this.id, this.name);
}
@PreUpdate
public void preUpdate() {
// 更新前:校验
if (this.name == null || this.name.trim().isEmpty()) {
throw new IllegalArgumentException("用户名不能为空");
}
}
@PreRemove
public void preRemove() {
// 删除前:检查关联数据
if (hasActiveOrders()) {
throw new BusinessException("该用户有未完成的订单,无法删除");
}
}
}可用的回调注解:
| 注解 | 触发时机 |
|---|---|
@PrePersist |
persist(insert)之前 |
@PostPersist |
persist(insert)之后 |
@PreUpdate |
merge(update)之前 |
@PostUpdate |
merge(update)之后 |
@PreRemove |
remove(delete)之前 |
@PostRemove |
remove(delete)之后 |
@PostLoad |
从数据库加载之后 |
投影(Projection):只查需要的字段
不需要整个实体对象,只要几个字段?用投影。
csharp
// 基于接口的投影(推荐)
public interface UserNameProjection {
String getName();
Integer getAge();
}
public interface UserRepository extends JpaRepository<User, Long> {
// 返回值用投影接口
List<UserNameProjection> findByAgeGreaterThan(Integer age);
// 基于 @Query 的投影
@Query("SELECT u.name AS name, u.age AS age FROM User u WHERE u.age > :age")
List<UserNameProjection> findByAgeGreaterThanProjection(@Param("age") Integer age);
}Spring Data JPA 会自动生成代理类来实现这个接口,只查 name 和 age 两个字段。
Example 查询:用实体对象当查询条件
ini
@Test
void testExampleQuery() {
User probe = new User();
probe.setName("张");
probe.setAge(25);
// 精确匹配
Example<User> example = Example.of(probe);
// 自定义匹配规则
ExampleMatcher matcher = ExampleMatcher.matching()
.withMatcher("name", ExampleMatcher.GenericPropertyMatchers.contains())
.withIgnorePaths("email")
.withIgnoreCase();
Example<User> example = Example.of(probe, matcher);
List<User> users = userRepository.findAll(example);
}Example 查询适合简单场景,复杂条件还是用 Specification。
实战:完整的 Controller 层
把上面学的功能串起来,写一个完整的用户管理接口:
less
@RestController
@RequestMapping("/users")
public class UserController {
private final UserService userService;
private final UserRepository userRepository;
public UserController(UserService userService, UserRepository userRepository) {
this.userService = userService;
this.userRepository = userRepository;
}
@PostMapping
public User create(@RequestBody User user) {
return userRepository.save(user);
}
@PutMapping("/{id}")
public User update(@PathVariable Long id, @RequestBody User user) {
user.setId(id);
return userRepository.save(user);
}
@DeleteMapping("/{id}")
public void delete(@PathVariable Long id) {
userRepository.deleteById(id);
}
@GetMapping("/{id}")
public User getById(@PathVariable Long id) {
return userRepository.findById(id)
.orElseThrow(() -> new RuntimeException("用户不存在"));
}
@GetMapping("/page")
public Page<User> page(
@RequestParam(defaultValue = "0") Integer page,
@RequestParam(defaultValue = "10") Integer size,
@RequestParam(required = false) String name,
@RequestParam(required = false) Integer minAge,
@RequestParam(required = false) Integer maxAge) {
Pageable pageable = PageRequest.of(page, size, Sort.by(Sort.Direction.DESC, "id"));
Specification<User> spec = (root, query, cb) -> {
List<Predicate> predicates = new ArrayList<>();
if (StringUtils.isNotBlank(name)) {
predicates.add(cb.like(root.get("name"), "%" + name + "%"));
}
if (minAge != null) {
predicates.add(cb.greaterThanOrEqualTo(root.get("age"), minAge));
}
if (maxAge != null) {
predicates.add(cb.lessThanOrEqualTo(root.get("age"), maxAge));
}
return cb.and(predicates.toArray(new Predicate[0]));
};
return userRepository.findAll(spec, pageable);
}
@GetMapping("/count")
public Long count(@RequestParam Integer minAge) {
return userRepository.countByAgeGreaterThan(minAge);
}
@PostMapping("/batch")
public List<User> batchCreate(@RequestBody List<User> users) {
return userRepository.saveAll(users);
}
}Service 层处理复杂业务逻辑:
java
@Service
public class UserService {
private final UserRepository userRepository;
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
@Transactional
public User createUser(User user) {
if (userRepository.existsByName(user.getName())) {
throw new BusinessException("用户名已存在");
}
return userRepository.save(user);
}
@Transactional
public void updateAge(Long id, Integer age) {
int updated = userRepository.updateAgeByName(
userRepository.findById(id).orElseThrow().getName(), age);
if (updated == 0) {
throw new BusinessException("更新失败");
}
}
}Spring Data JPA vs MyBatis-Plus
| 对比项 | Spring Data JPA | MyBatis-Plus |
|---|---|---|
| 核心 ORM | Hibernate(全自动 ORM) | MyBatis(半自动 ORM) |
| CRUD 代码 | 继承 JpaRepository,零代码 | 继承 BaseMapper,零代码 |
| 查询方式 | 方法名派生 / @Query / Specification | Wrapper 条件构造器 |
| SQL 可见性 | SQL 由框架生成,黑盒 | SQL 可控透明,白盒 |
| 多表关联 | 注解自动映射,方便但容易出 N+1 | 手动写 SQL,灵活可控 |
| 学习曲线 | 需要理解实体状态、延迟加载等概念 | 会 MyBatis 就会用 |
| 性能调优 | 需要 JPQL、fetch、batch 调优 | 直接优化 SQL |
| 适用场景 | 领域模型驱动、快速开发 | 重视 SQL 控制、复杂报表 |
怎么选?团队习惯 SQL 驱动开发,报表多、复杂查询多,MyBatis-Plus 更顺手。业务模型比较稳定,追求开发速度,Spring Data JPA 少写很多代码。两者也能混用------主流程用 JPA,复杂报表用 MyBatis。
注意事项和常见坑
1. 实体类必须有无参构造器
JPA 通过反射创建实体对象,要求类必须有一个 public 或 protected 的无参构造器。如果你写了有参构造器,记得手动加一个无参的。
2. save() 不是纯 insert
save() 方法内部先判断 isNew(),id 为空执行 persist(insert),id 不为空执行 merge(先查再更新)。merge 会先发一条 SELECT 再发 UPDATE,数据量大时性能比直接 UPDATE 差。
3. 延迟加载要在事务内
less
// Controller 层(没有事务)
@GetMapping("/{id}")
public Department getDepartment(@PathVariable Long id) {
Department dept = departmentRepository.findById(id).orElse(null);
// 报错!employees 是延迟加载的,此时事务已结束
dept.getEmployees().size();
return dept;
}解决方案:在 Service 层加 @Transactional(readOnly = true),或者用 JOIN FETCH 一次性查出来。
4. N+1 查询
前面提到过,关联查询中最常见的性能问题。一定要用 JOIN FETCH 或 @EntityGraph 解决。
5. 避免 JPA 的 "Dirty Checking" 性能问题
JPA 会在事务提交时自动检测实体对象的字段变化,脏字段会自动生成 UPDATE SQL。如果你在事务内读了一个实体又修改了它(哪怕只是临时赋值),提交时都会被更新。
csharp
@Transactional
public void someMethod() {
User user = userRepository.findById(1L).get();
user.setName("临时赋值"); // 事务提交时会自动 UPDATE!
}6. ddl-auto 在生产环境用 validate 或 none
ddl-auto: update 会在启动时根据实体类自动修改表结构。开发环境图个方便,生产环境千万别用------一个字段改名可能把数据搞丢。生产环境用 validate(只校验不修改)或 none。
总结
| 知识点 | 要点 |
|---|---|
| 核心思想 | Java 对象映射数据库表,用面向对象的方式操作数据库 |
| 实体映射 | @Entity、@Table、@Id、@Column 等注解定义映射 |
| Repository | 继承 JpaRepository,获得完整 CRUD 方法 |
| 方法名派生 | 按规则命名方法,框架自动生成查询 SQL |
| @Query | JPQL 或原生 SQL,处理复杂查询 |
| Specification | 动态查询,CriteriaBuilder 风格 |
| 关联关系 | @OneToMany、@ManyToOne、@OneToOne、@ManyToMany |
| 分页排序 | Pageable + Sort |
| 审计功能 | @CreatedDate、@LastModifiedBy 等自动填充 |
| 乐观锁 | @Version 注解 |
| 生命周期 | @PrePersist、@PostLoad 等回调 |
| 代理创建 | JpaRepositoryFactory + JDK 动态代理 |
| 默认实现 | SimpleJpaRepository |
| 查询解析 | @Query 优先 → 方法名派生 → 默认 CRUD |
Spring Data JPA 的本质就一句话:你只管定义 Java 对象和接口,SQL 的事框架帮你搞定。