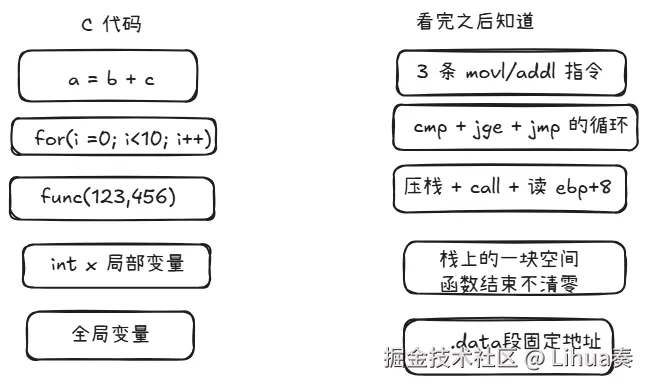
为什么会有汇编语言
学习汇编语言之前,看看他为什么诞生
我们知道,CPU只能执行机器码,那看下面的机器码
text
8B 45 F8
03 45 F4
89 45 EC谁能看懂?
那么 汇编语言 它出现了, 汇编语言就是给机器码起的人类可读的名字。
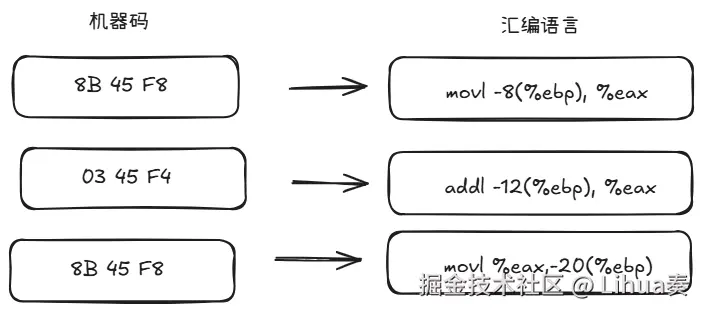
一般可以这样理解:在同一套 CPU 架构下,一条机器指令通常对应一条汇编指令
- c语言: a = b + c ->通常对应 3 - 10 条机器指令
- 汇编语言: 一条汇编 -> 一条机器指令
汇编器和反汇编器
汇编器和反汇编器
正向:
text
汇编代码 → [汇编器] → 机器码(本机代码)逆向:
text
机器码 → [反汇编器] → 汇编代码注意: 机器码 -> 汇编代码 可以反汇编出对应指令,但变量名、注释、函数结构这些信息通常回不来;而 汇编代码 -> c 代码 更无法完全还原
为什么?
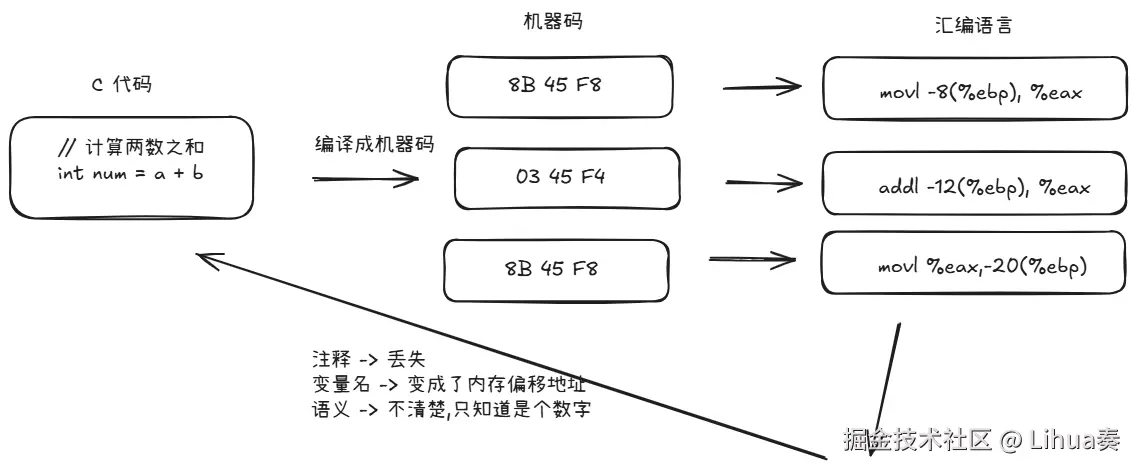
用编译器生成汇编
现在我们可以不需要手写汇编,用编译器就可以直接把 C 代码翻译给你看
比如:参数: -S,它的作用是: 生成一个 hello.s文件,里面是汇编代码
text
gcc -S hello.c举个例子:
c
int AddNum(int a, int b){
return a + b
}
void MyFunc(){
int c;
c = AddNum(123,456);
}通过 -S 编译后
text
AddNum:
pushl %ebp
movl %esp, %ebp
movl 8(%ebp), %eax
addl 12(%ebp), %eax
popl %ebp
ret
MyFunc:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
movl $456, 4(%esp) # 压入第二个参数
movl $123, (%esp) # 压入第一个参数
call AddNum
movl %eax, -4(%ebp)
leave
ret这里再次说明了,一行 c 代码,由多条汇编指令构成
参数为什么从右往左压栈
在上面我们可以看到
text
先 movl $456, 4(%esp)
再 movl $123, (%esp)正常来说,应该是 123 去加上 456,为什么会是这个顺序?
这里先知道两概念:压栈 和 弹栈
简单来说:
- 压栈 = esp 下移 + 写数据
- 弹栈 = 读数据 + esp 上移
那么,如果我们先写入 123
text
栈的位置:
456 ->后压 栈顶
123 ->先压那么我们读取第一个参数,也就是 123 的时候,他并不在栈顶,需要我们去找
先写入 456
text
栈的位置:
123 ->后压 栈顶
456 ->先压这样能保证第一个参数 永远固定 在 栈顶,函数可以用相同的偏移量直接取
printf 这类函数,参数数量不固定:
c
printf("%d %d %d", a, b, c);
printf("%s", str);右到左压栈后,格式字符串(第一个参数)永远在栈顶。printf 先读格式字符串,再根据里面有几个 %d决定往后读几个参数。
如果顺序反了,printf 不知道格式字符串在哪,也就无法决定读多少个参数。
伪指令和注释
伪指令:给汇编器看的
比如:
text
.section .text
# 告诉汇编器:下面的内容放进代码段
.section .data
# 下面的内容放进数据段
myNum: .long 100
# 数据段中声明一个变量,值为 100注释:给人看的
比如:
text
movl 8(%ebp), %eax # 取第一个参数 a,放进 eax
addl 12(%ebp), %eax # 加上第二个参数 b当我们用编译器参数 -S 生成汇编时,有些说明性注释可能来自编译器输出,也可能是我们自己为了阅读方便加上的
在最终生成的可执行文件中,注释会在编译时直接丢弃,伪指令只是给汇编器看的说明,处理完之后也不会作为普通指令存在
所以,在最终的可执行文件中,通常看不到源码里的注释、变量名、说明和伪指令,这也说明了为什么逆向工程这么难
汇编语言的语法
汇编语言的语法:操作码 操作数
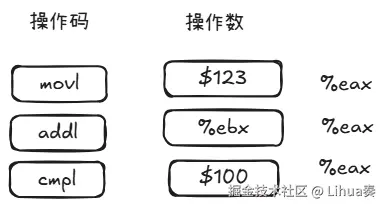
操作码:
- movl -> 搬移数据(move)
- addl -> 加法(add)
- subl -> 减法(sub)
- cmpl -> 比较(compare)
- jmp -> 跳转(jump)
- call -> 调用函数
- ret -> 函数返回
末尾的 l 表示操作 32位数据(long)
操作数:
- 立即数(直接写入的数据, 开头)123 ->数字 123
- 寄存器(CPU内部的临时格子,% 开头) %eax -> eax 寄存器里的值
- 内存地址(括号表示去该地址取值) (%eax) -> 去 eax 里存的地址,取那里的值 4(%eax) -> eax 的值加 4,去那个地址取值
movl 指令
movl 是用得最多的指令,意思是搬移 32 位的数据
格式: movl 源, 目标
比如:
text
#1.把立即数放进寄存器
movl $123, %eax #eax= 123
#2.寄存器之间复制
movl %ebx, %eax # eax = ebx
#3.把立即数写入内存
movl $456, 4(%esp) #内存地址[esp+4]= 456
#4.从内存读进寄存器
movl 8(%ebp), %eax #eax=内存地址[ebp+8]的值esp 和栈
esp 是栈的核心
esp 永远指向栈顶,栈向低地址方向增长
压入数据的两个步骤
text
1. esp 下移,腾出空间
subl $8, %esp
# esp = esp - 8(腾出 8 字节)
2. 用 movl 写入数据
movl $456, 4(%esp) # 写入第一个数据
movl $123, (%esp) # 写入第二个数据完整的函数调用过程
看完前面的,来一个完整的函数调用过程
text
c = AddNum(123, 456);
subl $8, %esp # 栈上腾出空间
movl $456, 4(%esp) # 右到左:先压 456
movl $123, (%esp) # 再压 123
call AddNum # 调用函数call 做了什么?
- 把 下一条指令的地址 压入栈
- 跳转到 AddNum 的入口
相当于
text
返回地址
123
456进入函数后:建立 栈帧
text
AddNum:
pushl %ebp
# 保存调用者的 ebp
movl %esp, %ebp
# ebp = esp,标记当前函数的栈底执行完之后:
text
旧 ebp
返回地址
123
456ret 指令:返回
- 从栈顶弹出返回地址
- 跳转到那个地址
- 回到 call 的下一条指令继续执行

上面的图说的是 调用者(MyFunc)的流程,接下来是 被调用者(AddNum) 内部 具体做了什么
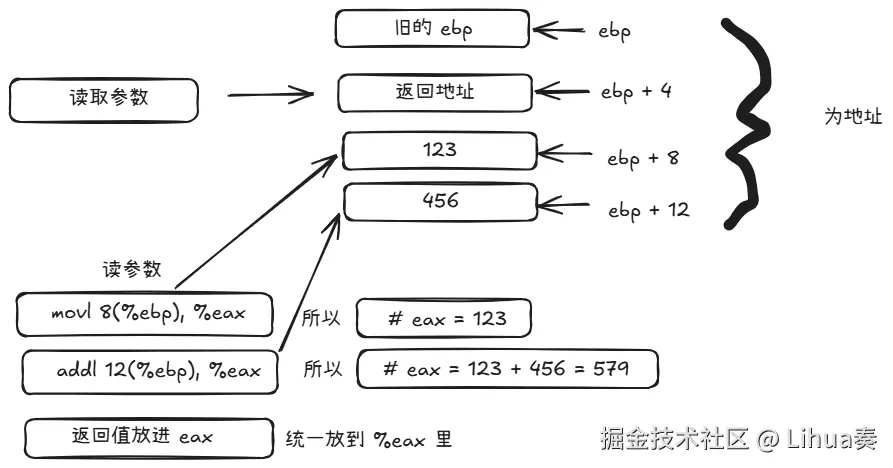
在 MyFunc 里
text
call AddNum
movl %eax, -4(%ebp)函数结束后
text
popl %ebp
ret全局变量和局部变量
全局变量:定义在 .data段中
- 有固定的内存地址
- 程序运行期间一直存在
- 任何函数都能访问
c
int num = 100;
void funcA(){ num = 200 }局部变量:定义在 栈 中
c
void funcA(){
int x = 10
}但是,栈上的数据并不会清零
当 esp 上移时,局部变量的空间还在那, 数据依旧在那
这就是为什么局部变量不初始化就使用,会读到垃圾值
c
void func(){
int x;
printf("%d",x);
//可能打印出上一个函数留下的数据
}可以看出,全局变量很方便,那我们全用全局变量不好吗?
全用全局变量会出现一个问题: 追踪困难
c
int count = 0;
void funcA() { count++; }
void funcB() { count = 0; }
void funcC() { count *= 2; }当 count 的值出错了,你需要调查所有用过 count 的函数
而 局部变量 没有这个问题,因为只有一个函数能改他,对应的也能容易排查
还可能出现更严重的问题: 多线程
- 线程 A 读 count = 10
- 线程 B 同时把 count 改成 0
- 线程 A 继续用它以为是 10 的 count 做计算
if 和 for 的底层
for循环,在汇编中其实就是 比较 + 跳转
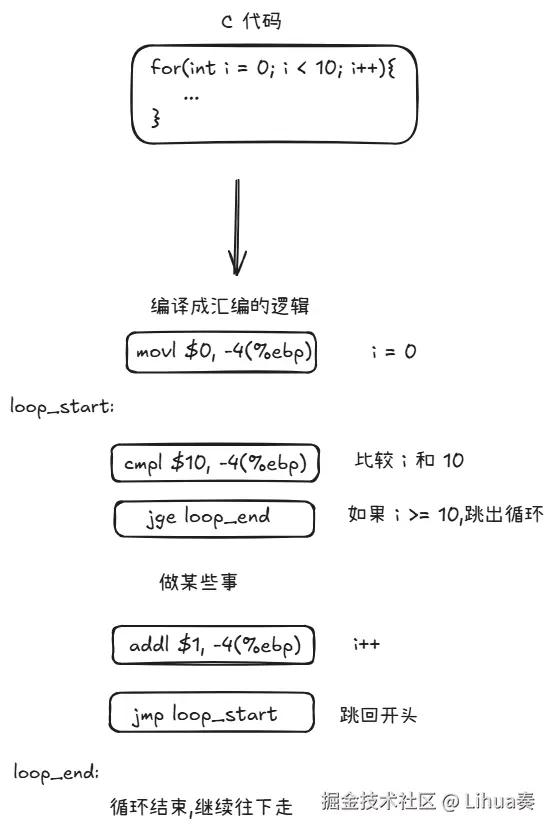
if 判断也是一样的,也是 比较 + 跳转
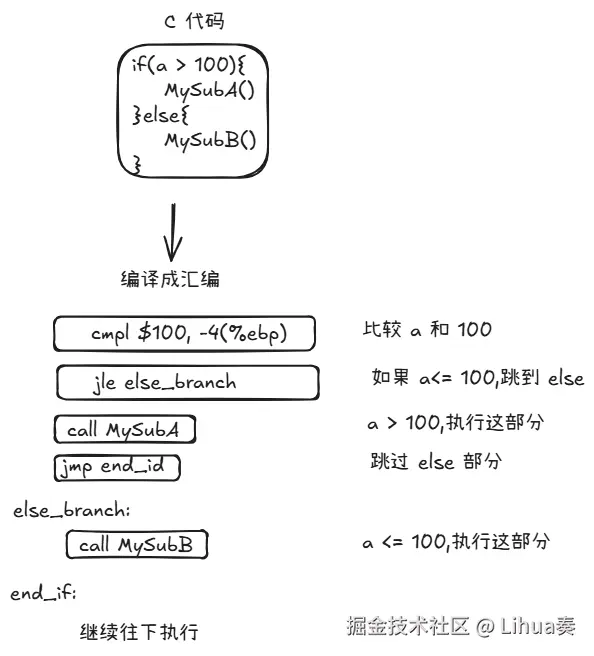
乍一看,if 和 for 都差不多,都是 比较 + 跳转,但还是有区别的
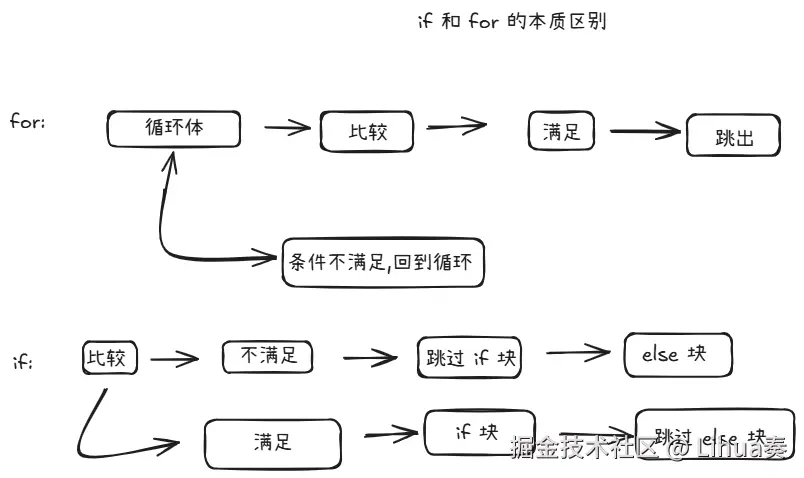
而我们的 CPU 从头到尾只做一件事:
text
取指令 → 执行 → PC移动 → 取下一条指令 → 执行 → ...所以,所有的高级语言结构,其本质都是控制 PC 跳到哪里去
text
顺序执行 → PC 每次 +1,往前走
if/else → 条件不满足,PC 跳过一段
for/while → 条件满足,PC 跳回去
函数调用 → PC 跳到函数入口,返回时跳回来总结
最后,如果只用一句话去理解 汇编语言 ,那就是: 它不是为了让你每天手写机器指令,而是为了让你看懂高级语言背后到底发生了什么。
像平时我们写 C 语言、Java 或者其他高级语言时,看到的是变量、函数、if、for 这些结构。但到了 CPU 真正执行的时候,这些东西都会被拆成更底层的指令,比如搬移数据、比较、跳转、调用函数、返回地址