最简单的语句,往往最值得琢磨。比如,++i和i++这两种最简单的自加1运算,它们谁更快?虽然,你可以很快从网上搜出答案,但却不见得能说服自己接受这个答案,今天让我们从CPU的视角,看看谁快、谁慢。
●代码分析
打开Compiler Explore,写一个简单、常见的前加(++i)的函数func1,再写一个后加(i++)的函数func2:
int func1()
{
int i = 1;
++i;
}
int func2()
{
int i = 1;
i++;
}
暂时不用理会CPU指令的具体含义,只比较两个函数的汇编指令,如下图所示:
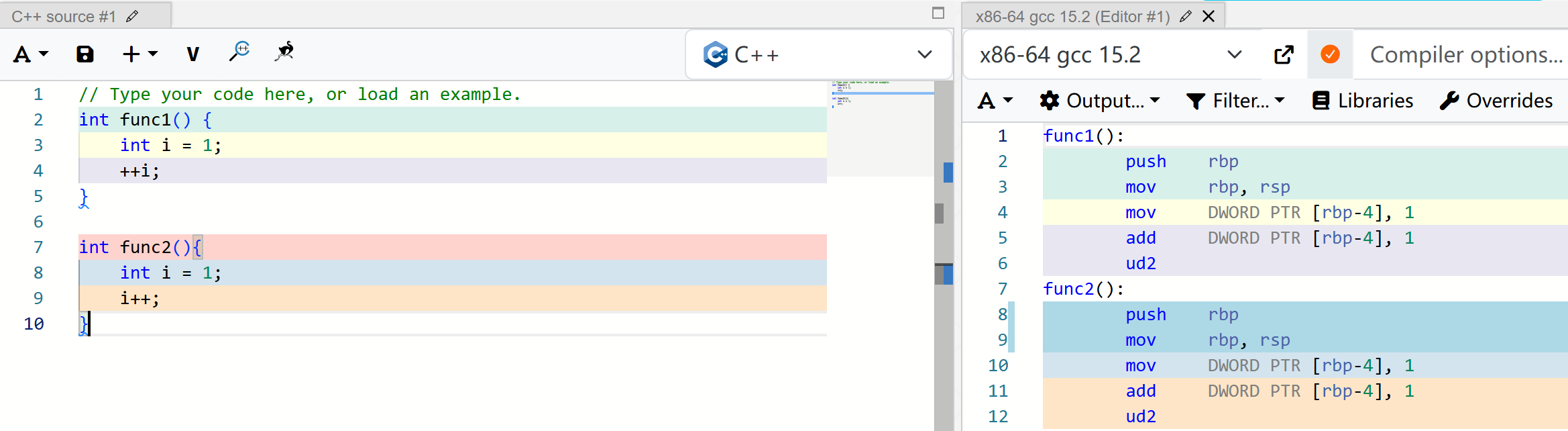
二者的汇编指令完全一致!所以可以认为++i和i++的速度是一样的。如果是这样的话,我们就不必再为这个问题争论不休了。
但非常遗憾,这种使用方式太过简单,还不能覆盖所有的情况,让我们稍微修改一下代码,返回++i和i++的值试试,如图所示。
差异出现了:前加(++i)只对应了2条指令;后加(i++)对应了3条指令。如果忽略不同指令的执行时间,前加(++i)用的指令少,所以,前加(++i)的运行速度会快一点点。
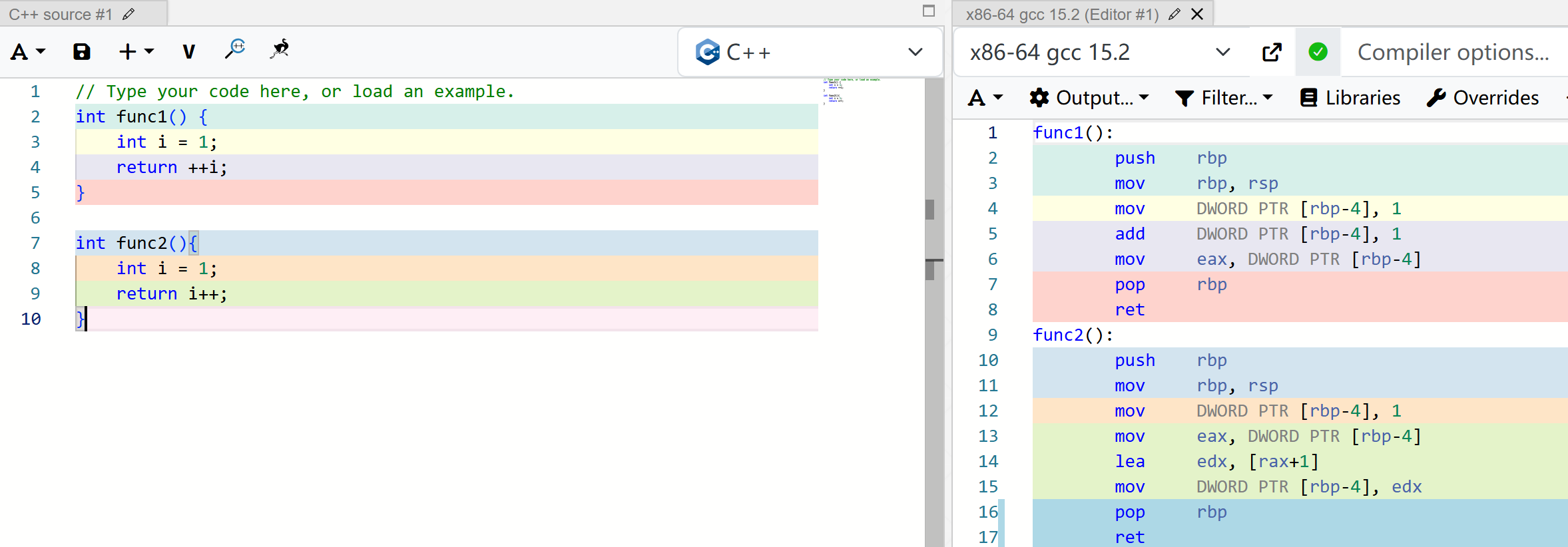
区区一条指令,快的不多,对于1秒钟执行上亿次运算的CPU而言,几乎可以忽略不计。
●差异分析
或许现在只是一条指令的差异,那未来会不会有某种情况,可能产生更多的指令差异,让它们的运行速度差异巨大呢?让我们再仔细分析汇编指令的差异部分,如图所示。

先看++i,它由两条指令构成 :
第1条指令,读取变量i的值,并做加1运算,其结果为2,再写入变量i。
其中变量i的内存地址值是rbp - 4。
第2条指令,读取变量i的值,并传递给寄存器eax,用来作为函数的返回值。
再看i++,它由3条指令构成 :
第1条指令,由于i++需要返回加1前的原始值,所以,先读取i的值,并传递给寄存器eax,用作函数的返回值。
第2、3条指令,有点烦琐,但实质上,等价于++i的第一条指令。
从图中给出的等效C语言代码看来,它们仅仅是代码顺序的差异,这种顺序差异,并不能对效率产生太大的影响。如果再加上编译器优化,它们生成的汇编指令可能是完全相同的 。
但就是这个顺序差异,在特定的情况下,也能让二者在效率上,产生较大的差异,甚至通过编译器优化,也无法抵消这种差异。
如果把i++比作一个函数的话,因为语法规则的要求,它只能把加1前的原始值,返回给主调函数。所以,在自加1之前,它需要用一个临时变量,保存自己的原始值,而构建这个临时变量,就可能需要占用一定的内存和CPU资源。如果这个临时变量是一个比较复杂的类对象的话,那么构建临时对象的开销就不能被忽略了。
下面是C++的前加(++i)、后加(i++)操作符的重载函数,我们可以直观地感受一下它们在执行过程上的差异,如下图所示。
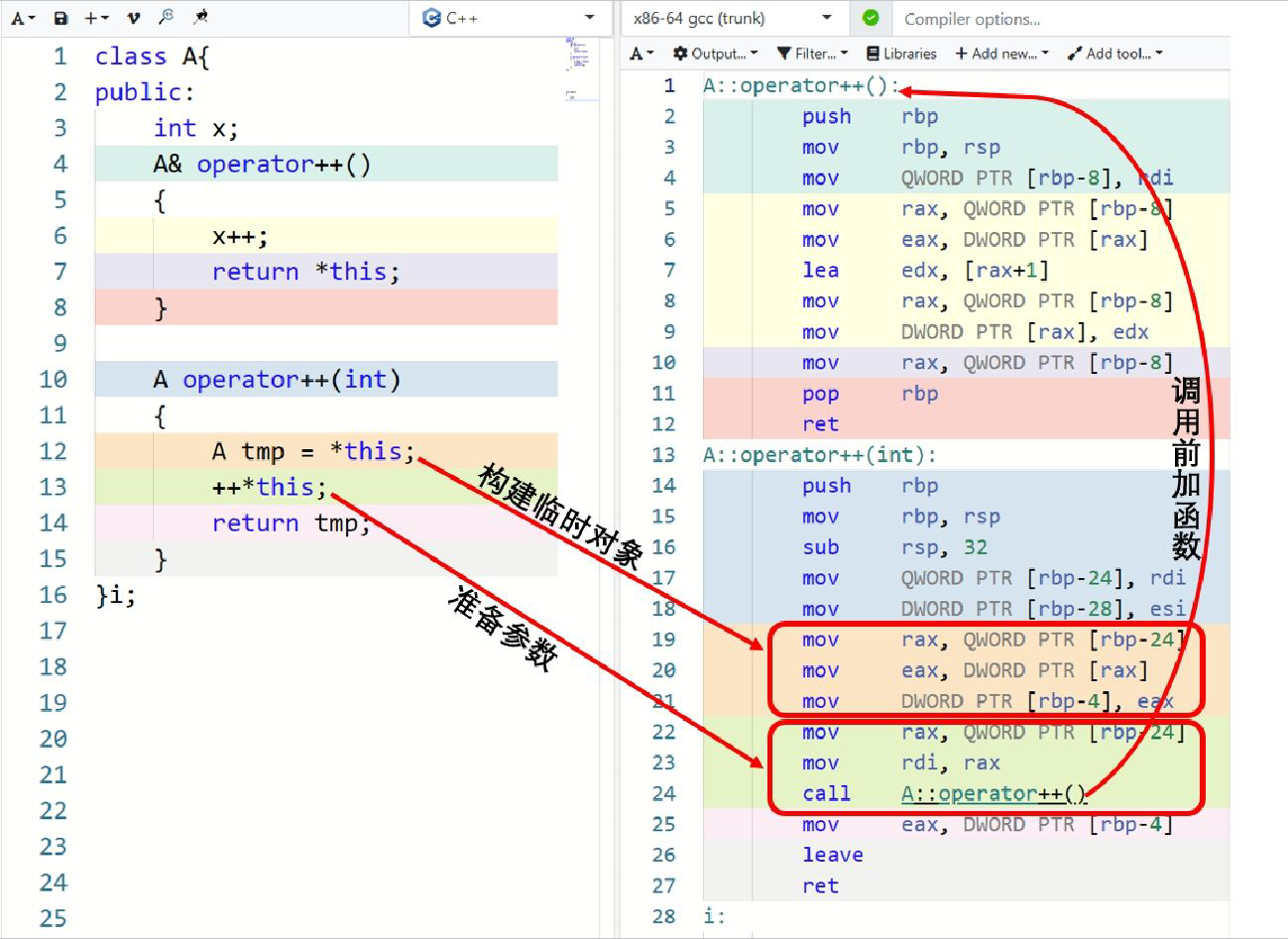
后加运算符(i++),要先准备构建临时变量,然后准备参数,最后再调用一次完整的前加(++i)运算函数。这样,后加(i++)往往需要包含一个完整的前加(++i)操作。而这种差异,往往是编译器难以优化掉的。
●总结
(1)对于简单数据类型(int、short、char、long),前加(++i)和后加(i++)几乎没有效率上的差异,在不同的编译环境下,前加(++i)可能会略快,但优势可以忽略不计。
(2)对于复杂数据结构,特别是class,后加(i++)需要构建临时对象,会放大后加(i++)的劣势。所以,对象的++运算,首选前加(++i)。