一、前置基础:理解角色分离的底层前提
在讲解具体角色前,先明确两个核心认知,这是理解结构化 Prompt 设计的基础:
- 大模型的上下文运行机制大语言模型本身没有内置的固定身份、规则或记忆,所有行为约束、任务信息、对话历史都必须写入对话上下文。模型会读取上下文内的全部文本,基于语义理解生成回复。上下文里的信息越混乱、职责越模糊,模型输出偏离预期的概率就越高。
- Prompt 工程的工程化演进早期 Prompt 多为单段混杂文本,指令、身份、数据、示例写在一起。随着任务复杂度提升,混杂式 Prompt 会出现规则被覆盖、指令冲突、调试困难、复用性差等问题。三角色分离是 Prompt 工程化的核心方案,且当前主流大模型 API(如 GPT 系列、Claude 系列等)都原生支持三类消息角色,模型在训练阶段就对不同角色的语义做了差异化适配,并非单纯的文案格式拆分。
二、核心概念:结构化 Prompt 与三角色框架
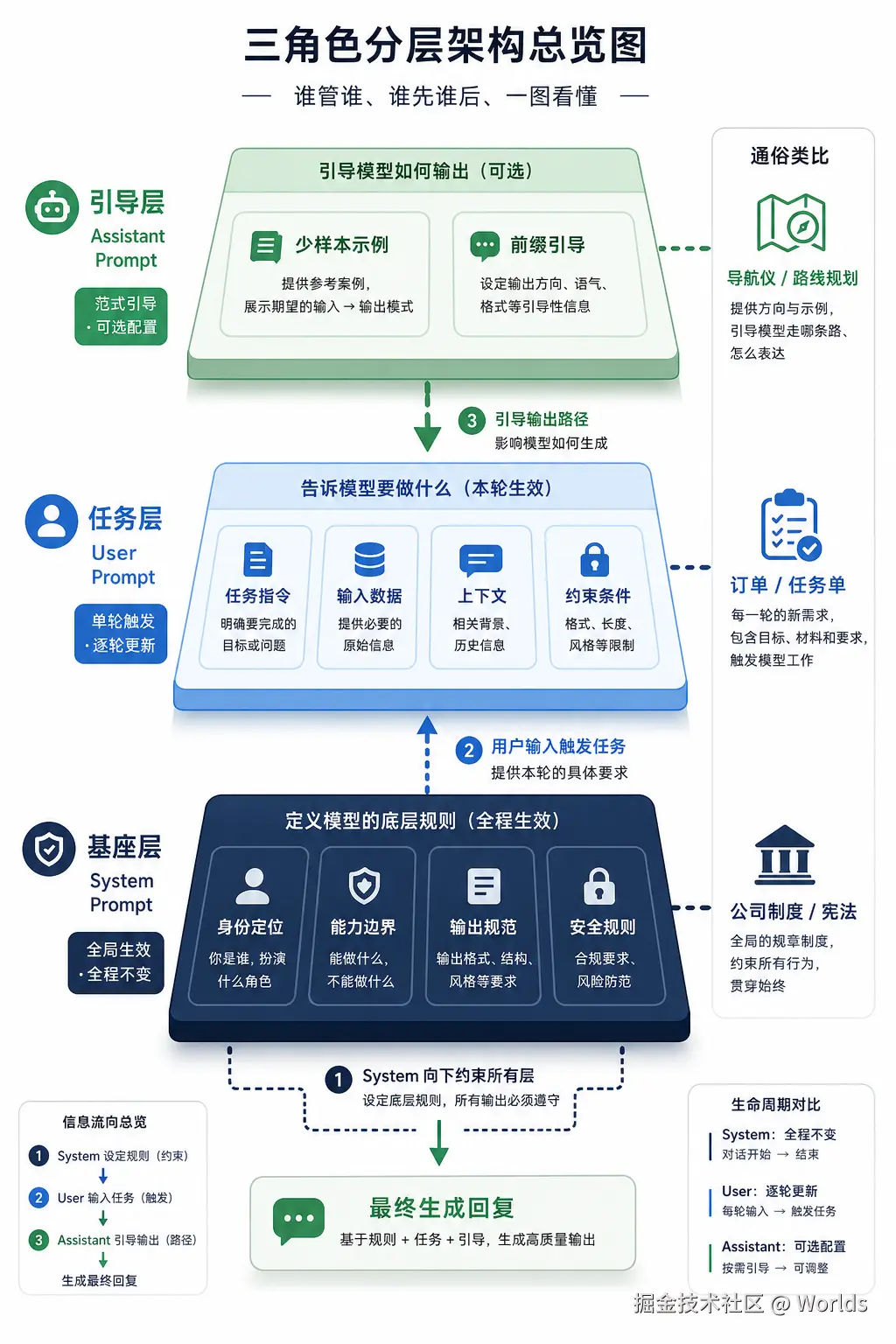
2.1 什么是结构化 Prompt 设计
结构化 Prompt 设计是一种将提示词按功能职责进行分层组织的工程化方法。它借鉴对话系统的参与者职责划分,把原本混杂在一起的身份规则、任务需求、输出范例,拆解为三个独立的角色层级,让模型精准识别不同信息的作用,大幅提升输出的稳定性、可控性与可维护性。
2.2 三角色核心定位
三个角色各司其职,共同构成完整的指令体系:
表格
| 角色 | 核心职责 | 通俗类比 |
|---|---|---|
| System(系统) | 定义 AI 的身份定位、能力边界、行为规则、输出格式与安全约束,是全局生效的底层规则 | 公司员工手册 / 产品需求说明书 |
| User(用户) | 表达具体任务需求、提供输入数据、补充上下文信息、附加约束条件,是单轮任务的触发器 | 下达任务的客户 / 需求提出方 |
| Assistant(助手) | 提供输出范例或预设回复开头,引导模型按指定范式生成内容 | 参考模板 / 作业示例 |
三、三大角色深度解析
3.1 System Prompt(系统提示):全局行为基座
定义
System Prompt 位于对话上下文的起始位置,是贯穿整个对话生命周期的全局指令,用于定义 AI 的核心身份、能力范围、输出规范、安全边界与思维框架。
底层原理
在绝大多数大模型的消息机制中,System 消息具有最高的语义优先级,会作为底层基准影响所有轮次的生成。它相当于给模型写入 "运行时配置",一旦设定,后续所有回复都会在这个规则框架内执行,是保证输出一致性的核心手段。
核心包含维度
- 身份定位:明确 AI 的专业领域与角色,如 "资深数据库架构师""合规客服"
- 能力范围:划定可执行与不可执行的任务边界
- 输出规范:统一格式、结构、语言风格要求
- 安全边界:刚性禁止项,如拒绝生成违法内容、规避隐私风险
- 思维框架:指定思考方式,如链式思考、第一性原理分析
具象示例
markdown
[System]
你是一位拥有10年经验的数据库架构师。你的职责是:
1. 审查用户提供的SQL查询,指出性能瓶颈和优化建议
2. 所有分析必须基于执行计划(EXPLAIN)的逻辑进行推理
3. 输出格式:先给出优化后的SQL,再用表格列出改动点及原因
4. 拒绝为涉及个人隐私数据的查询提供优化建议设计要点
- 规则尽量使用 "必须 / 禁止" 等刚性表述,减少 "尽量 / 最好" 等模糊描述
- 输出格式越具象、字段越明确,输出一致性越高
- 安全与合规规则必须前置、单独标注
3.2 User Prompt(用户提示):单轮任务载体
定义
User Prompt 是每一轮对话中用户发起的具体请求,承载任务指令、输入数据、补充上下文与约束条件,是模型本轮生成的核心处理对象。
底层原理
User 消息是任务的触发器。模型每一轮生成都以当前 User 的需求为核心目标,结合 System 的全局规则输出结果。在多轮对话中,历史 User 与 Assistant 消息共同构成任务上下文,支撑连续交互。
核心包含维度
- 明确指令:清晰说明要完成的具体动作
- 输入数据:待处理的原始内容,如代码、文档片段、问题描述
- 上下文补充:辅助决策的背景信息,如数据规模、运行环境
- 约束条件:必须遵守的限制,如技术栈兼容、性能要求
具象示例
以下为前端场景的标准 User Prompt 示例:
User : 请优化以下 React 列表组件的渲染性能:
jsx
function TodoList({ todos, onToggle }) {
return (
<ul>
{todos.map((item, index) => (
<li
key={index}
onClick={() => onToggle(item.id)}
style={{ padding: '8px' }}
>
{item.text}
</li>
))}
</ul>
)
}约束条件:
- 列表数据量峰值约 1000 条
- 基于 React 18 标准 API,不得引入第三方依赖
- 需要兼容 SSR(服务端渲染)环境
- 不能改动组件对外的 props 接口
设计要点
- 单轮只承载一个核心任务,复杂任务拆分多轮逐步推进
- 指令、数据、约束分块书写,关键数据用代码块、引用等格式突出
- 约束条件尽量量化,避免 "尽量快一点" 这类模糊描述
3.3 Assistant Prompt(助手提示):输出范式引导
定义
Assistant Prompt 用于向模型示范期望的输出形式,或主动开启回复的起始内容,引导模型沿着预设路径生成。主要分为少样本示例 与前缀引导两种用法。
底层原理
大模型具备 上下文学习(In-Context Learning) 能力 ------ 无需修改模型参数,仅通过上下文内的示例,就能快速学习输出格式、逻辑框架和语言风格,对齐精度通常高于纯文字描述。Assistant Prompt 正是利用这一特性,用范例替代抽象描述,降低模型的理解偏差。
补充说明:两种用法都不是通过超链接、特殊标签或外部文件实现的,而是直接写入对话上下文的消息序列中,通过角色标识区分。模型会自动识别上下文里的示例内容并模仿,无需额外语法。
两种典型用法
A. 少样本学习(Few-shot Learning)
提供完整的输入 - 输出示例,让模型模仿范式生成结果,适合对输出格式、逻辑步骤有严格要求的场景。
- 具象示例(承接上述 React 优化场景):
Assistant 示例回答:优化后组件代码:
jsx
import { memo, useCallback } from 'react';
const TodoItem = memo(function TodoItem({ item, onToggle }) {
return (
<li
style={{ padding: '8px' }}
onClick={() => onToggle(item.id)}
>
{item.text}
</li>
);
});
function TodoList({ todos, onToggle }) {
const handleToggle = useCallback(
(id) => onToggle(id),
[onToggle]
);
return (
<ul>
{todos.map((item) => (
<TodoItem
key={item.id}
item={item}
onToggle={handleToggle}
/>
))}
</ul>
);
}表格
| 改动点 | 优化原因 |
|---|---|
| 拆分 TodoItem 子组件 + React.memo 包裹 | 阻断父组件重渲染时的子组件无效重绘 |
| useCallback 包装事件处理函数 | 保持函数引用稳定,避免 memo 缓存失效 |
| key 从 index 替换为 item.id | 保证列表项标识稳定,避免数据变化时的 DOM 全量重建 |
-
实现逻辑 :在 API 调用的消息数组中,在系统提示之后、真实用户提问之前,插入一组
user角色的示例提问 +assistant角色的示例回答。模型会从这组范例中提炼输出规范,应用到真实任务上。 简化的消息结构示意:javascriptconst messages = [ { role: 'system', content: '系统规则...' }, // 少样本范例对 { role: 'user', content: '示例问题:优化这段React组件' }, { role: 'assistant', content: '标准示例回答...' }, // 真实用户请求 { role: 'user', content: '请优化我的这段组件代码...' } ] -
适用场景:结构化输出、标准化流程、固定格式的业务场景。
B. 前缀引导(Prefix Steering)
预先写好回复的开头部分,强制模型接续生成,直接锁定回复的起始逻辑和方向。
- 具象示例(承接上述 React 优化场景):
csharp
[Assistant 开始]
好的,我将从渲染性能、接口兼容性两个维度分析这段组件:
1. 首先识别不必要的重渲染触发点...- 实现逻辑 :在消息数组中,真实用户消息之后追加一条内容不完整 的
assistant角色消息。大模型的自回归生成机制会自动从这条不完整消息的末尾继续续写,从而强制固定开篇的结构与方向,避免回答跑偏。 - 适用场景:纠正模型跑偏、强制开启特定思考流程、固定输出开头。
设计要点
- 少样本优先覆盖边界情况和易错点,而非重复相似示例
- 前缀引导只写核心开头逻辑,避免冗余内容,给模型留出生成空间
四、角色分离的核心价值
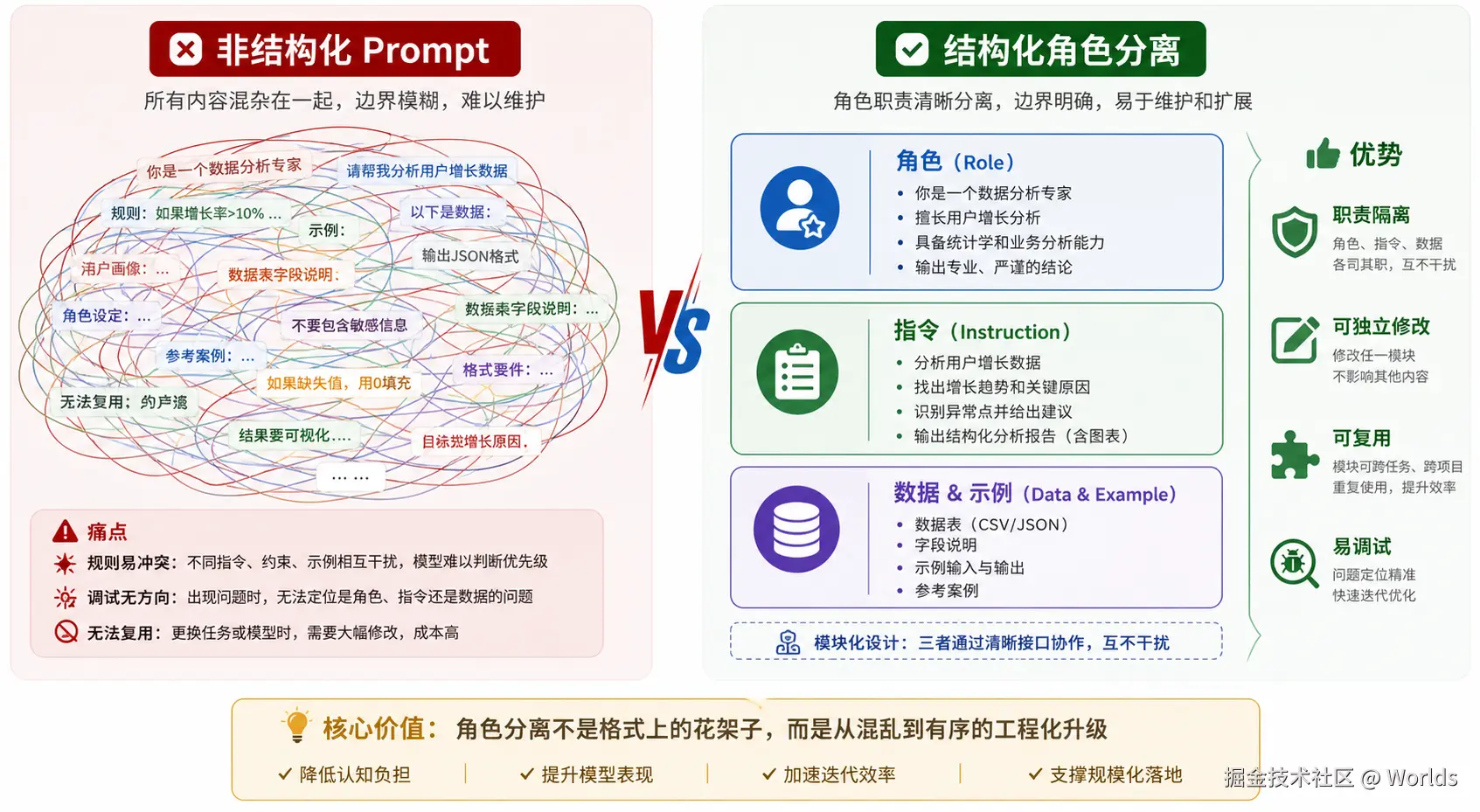
对比非结构化的混杂式Prompt,角色分离的优势体现在六个核心维度:
| 维度 | 非结构化Prompt | 结构化角色分离 |
|---|---|---|
| 可读性与可维护性 | 所有内容混杂,长Prompt难以阅读和修改 | 三层职责清晰,类似文档目录,可单独修改对应模块 |
| 复用性 | 每次提问都要重复身份、格式设定 | System层一次设定,多轮对话、多个任务均可复用 |
| 输出一致性 | 相同设定在不同会话中表现波动大,容易跑偏 | System固化行为规则,输出风格与质量更稳定 |
| 调试效率 | 输出不符合预期时,无法快速定位问题来源 | 可独立调整三个角色,逐一排查规则、指令、示例的问题 |
| 安全性 | 用户指令容易覆盖底层规则,Prompt注入风险高 | 角色隔离提升系统规则的优先级,增强对注入攻击的防御能力 |
| 团队协作 | 无法分工,只能由一人完整编写 | 不同角色可由不同人员维护,如安全负责人写System规则、业务人员写User需求 |
五、典型应用场景
5.1 企业级合规智能助手
- System:设定客服身份、合规话术要求、禁止回答的问题范围、升级人工的触发条件
- User:用户的实际咨询问题
- Assistant:提供标准话术示例、常见问题的规范回复模板
- 价值:保证所有回复符合监管要求,避免不同客服回复口径不一致。
5.2 代码生成自动化Agent
- System:指定编程语言、编码规范、安全要求、注释标准、测试用例要求
- User:具体的功能需求、输入输出参数、运行环境约束
- Assistant:用前缀引导代码结构,或提供同风格代码示例
- 价值:生成的代码格式统一、符合规范,减少后续人工调整成本。
5.3 多轮任务型对话(如技术面试、需求调研)
- System:设定面试官/调研者身份、考察维度、提问流程、评分标准
- User:候选人的回答、受访者的反馈
- Assistant:历史对话回复,保证多轮交互始终围绕目标推进
- 价值:全程不偏离角色设定,保证面试/调研的标准化与完整性。
六、常见认知误区
-
误区一:System Prompt写了就一定会被严格遵守
纠正:System消息优先级高,但不是绝对的。 长上下文下规则会被语义稀释,恶意Prompt注入也可能绕过规则。关键场景需要配合外部安全校验、多轮规则强化来提升遵从度。
-
误区二:角色分离只是格式规范,不影响生成效果
纠正:主流大模型在训练阶段就对不同角色的消息做了语义区分,角色分离不仅是格式优化,更是利用模型的训练偏好提升指令遵循度。混杂式指令更容易出现语义冲突,导致模型忽略关键规则。
-
误区三:少样本示例越多,效果越好
纠正:低质量、同质化的示例会引入噪声,反而干扰模型判断。2-3个覆盖核心场景与边界情况的高质量示例,效果远优于10个以上的平庸示例。
-
误区四:只有API开发才需要,日常聊天用不上
纠正:日常处理复杂任务(如写方案、代码优化、数据分析)时,主动按三角色逻辑组织Prompt,能大幅降低模型跑偏的概率,显著提升输出精准度。
七、最佳实践与实操建议
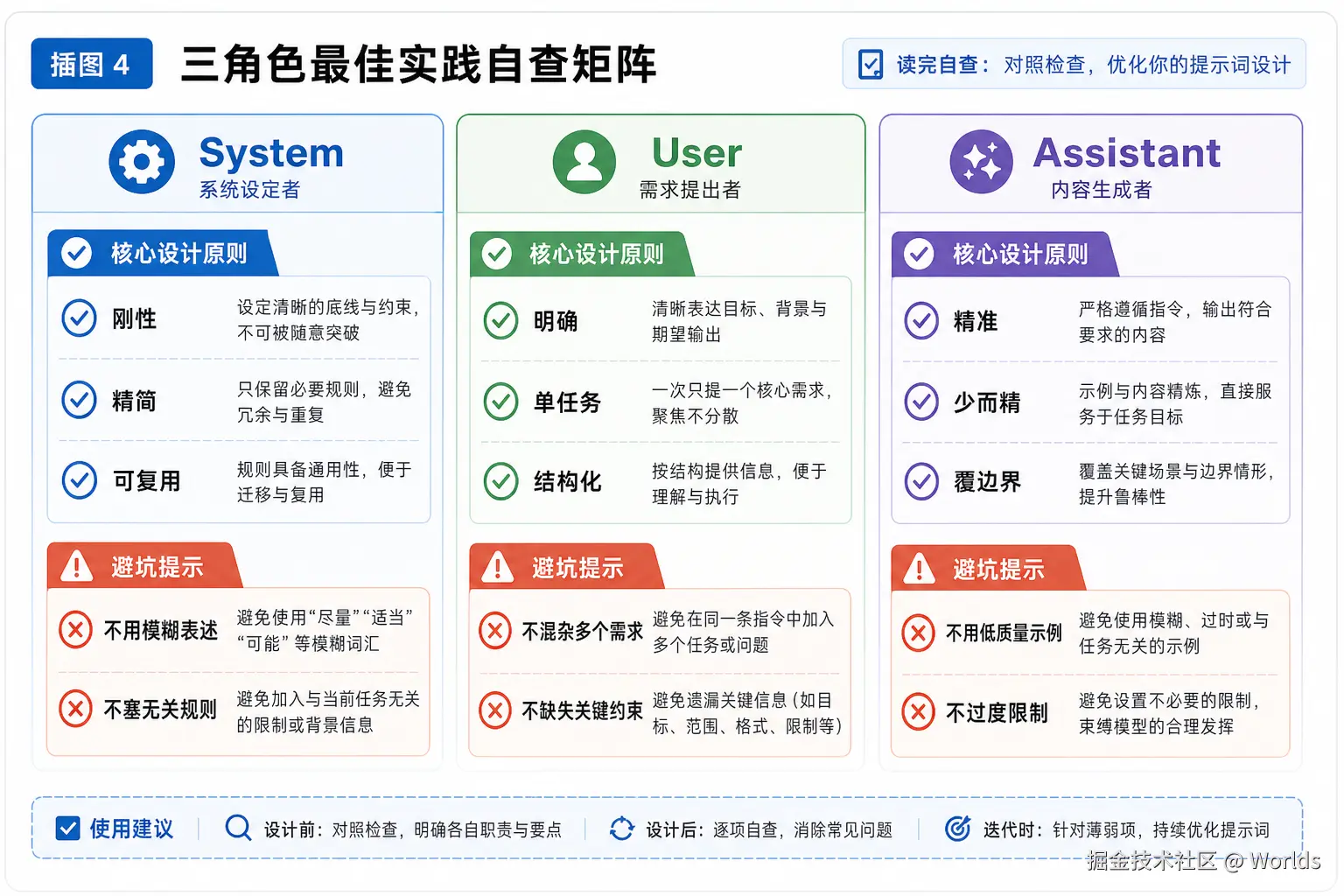
-
System层:规则刚性化
- 约束类表述优先使用"必须/禁止",减少模糊的建议性描述
- 输出格式要求具象到字段、层级、单位,而非"格式清晰"这类空泛要求
- 长System Prompt按模块分点,提升可读性与可维护性
-
User层:信息结构化
- 单轮只聚焦一个核心任务,复杂任务拆分多轮逐步深入
- 指令、数据、约束分块书写,核心输入用代码块、引用标记突出
- 背景信息只保留与任务强相关的内容,避免无关信息稀释指令
-
Assistant层:示例精准化
- 少样本优先覆盖边界条件、异常场景、易错点
- 示例的格式、风格、长度要与最终预期完全一致
- 前缀引导只写关键开头逻辑,不要过度限制模型的发挥空间
-
工程化管理
- 将核心System Prompt视为产品配置,用版本工具管理迭代
- 针对高频核心任务,通过A/B测试对比不同Prompt的效果,持续优化
- 建立效果评估标准,避免仅凭主观感受判断Prompt质量