大家好,我是老刘
之前不是发了篇文章说我退订了Trae,改用copilot加第三方的模型套餐。
文章中提到我的三层大模型选择策略,于是有很多人私信问,老表是看什么评分去选择实际编程中使用的大模型的?
那我们就来聊聊,在各种评分刷榜的时代,我们应该通过哪些测评来真实地评估大模型的工作能力。
注意,老刘的策略和实际选择都是以Flutter项目为主要的使用场景,仅供大家参考。
没有任何测评能完全代表模型在实际工作中的体验
因为所有的测评本质上都是搞一个试题集。根据大模型在某个Agent中做题的结果进行人工打分,或者基于固定的测评结果进行打分。
所以这些测评其实只能代表模型在特定Agent下在解决特定类别问题时的表现。
而你的实际工作场景,大概率和这个测试的问题集是有比较大的差异的。
以老刘工作的场景举例:
我们开发一个需求的输入是产品经理给出的PRD文档,以及UI/UE设计师提供的界面设计。
而这些文档中,包含了大量我们日常工作中可以用简单的词所代表的上下文语境。
比如文档中提到的单品页或者活动页,可能是特指今年618或者双11的商品或者活动。
所以为了解决这种问题,我们在实际开发中,会使用大量的skill或rules去要求大模型,把不明确的概念让程序员明确。
如果想真正地评估一个大模型在我们实际工作的环境中的表现,正确的做法是,把过去已经发生的多个需求和bug整理成一个我们私有的测试集。
通过人工去评估大模型在我们的工作环境下,针对我们私有测试机的表现如何。这其中不仅仅包含功能是否完成、bug是否解决,还包含生成的代码是否符合我们整个项目的编码规范和上下文习惯。
那测评是不是没有参考意义呢?
有人问了:老刘,你说的这些我听不懂,我就想知道到底看啥评分?
其实也不是没有参考意义。
本质上是能真实地反映大模型在某个特定的问题区间的能力的。比如逻辑推理,比如数学推导,比如在编码中生成某个特定功能的函数,或者在长城编码中解决一个具体的需求。
但是这一切的前提条件是模型没有针对某些测试集过拟合。
但是你看现实情况是,三天两头发布的新模型又登顶了。但是他们只放出来少数几个测评的得分,其他测评只字不提。
所以,如果你想要通过测评得分,来初步评估一个大模型是否适合你的工作流程。我要的建议是选择闭源的测评。
也就是那种测评的题目并不公开的。
这里列举老刘常看的两个测评:
1. CursorBench
CursorBench: cursor.com/cn/cursorbe...
这个是Cursor内部基于他们的大量案例整理出来的测试集,最大的好处是这个测试集并不公开。
而且这个测试主要针对的就是开发场景,所以对我们的参考价值比较高。
但问题是,这个测评的更新并不频繁,很多最新发布的国产大模型都没有加入进去。
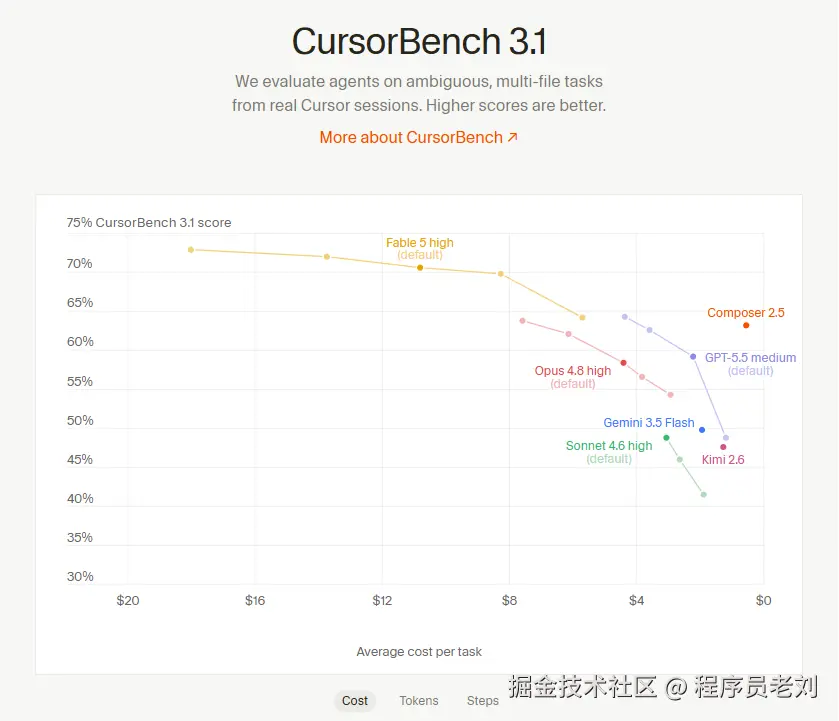
所以这个测评,更适合用来评估国外顶尖大模型在编程中的真实能力水平。
另外,Cursor自家的模型在这个评分中排名很高,还是要谨慎看待。
2. LiveBench
LiveBench: livebench.ai/
Livebench的测试集也是不公开的,另外它拥有更多的测试维度,也会及时更新最新发布的一些主流大模型。
所以,如果你订阅了一些国内的coding plan,在纠结选择哪个大模型作为你日常工作的主力,我建议你看这个测评。
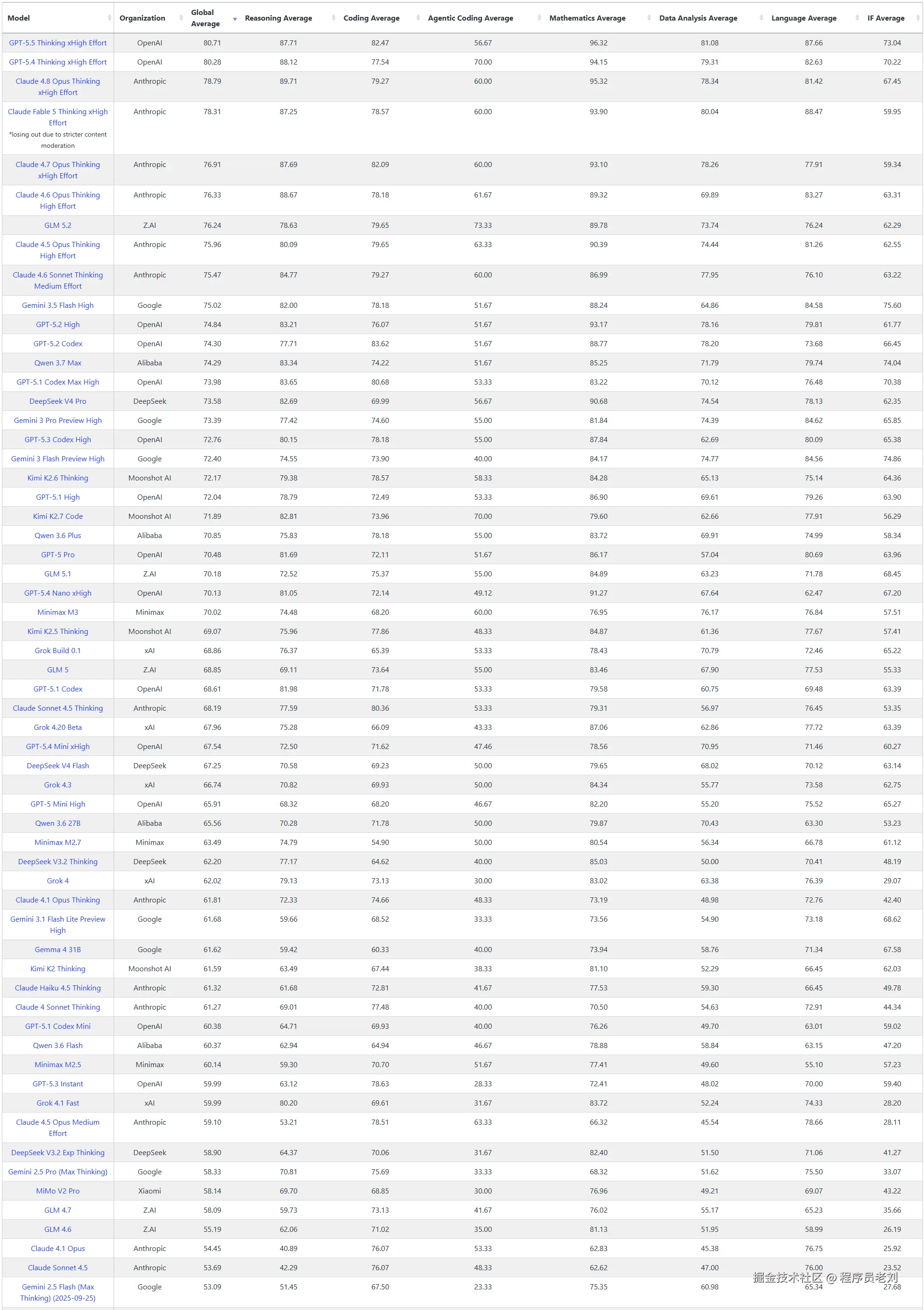
你们认为很强的模型都在什么位置?
日常工作建议参考综合得分,代码开发建议参考下面四个维度:
| 维度 | 说明 |
|---|---|
| Reasoning Average | 推理能力,在复杂的业务逻辑构建时,这项能力非常重要。 |
| Coding Average | 可以简单理解为实现一个功能函数这种体量的代码的能力。在企业开发中,如果你已经把功能拆得非常细,那么这项能力是非常重要的评估维度。 |
| Agentic Coding Average | 这是评估大模型独立完成一个功能模块的能力。对独立开发者来说,这个维度的能力非常重要。 |
| IF Average | 指令遵循,在任何一个开发场景中,这都是非常重要的能力。特别是在企业级开发中,它直接影响了大模型生成的代码能否精准地符合项目的代码规范。 |
可以看到GLM 5.2的排名非常高,在编程任务中确实是能担当主力的选择。
注意和LiveCodeBench区分,两者的核心差异如下:
| 对比维度 | LiveBench | LiveCodeBench |
|---|---|---|
| 评测范围 | 综合能力(编码、数学、推理、写作等) | 专注编程能力 |
| 测试集公开性 | 封闭,题目定期更新替换 | 开源,测试集公开 |
| 防刷题机制 | 有,防止模型过拟合测试集 | 无,可本地复现验证 |
| 题目来源 | LMSYS 团队维护的综合题库 | 竞赛编程 + 真实代码库问题 |
| 参考价值 | 更适合评估模型整体实力 | 适合针对性评估编程能力 |
| 分数可信度 | 更高,难以刷分 | 相对较低,可能被过拟合 |
简单来说:LiveBench 更难"刷",参考价值更高;LiveCodeBench 则适合针对性评估编程能力。
3. DeepSWE
DeepSWE: deepswe.datacurve.ai/
它的v1.1版本更新于今年6月20日,对前沿编程大模型在原创性、长周期工程任务上的表现进行测量评估。
这是一个主要针对复杂编程任务的测评,题目非常难,而且刚刚发布,所有模型都没办法抄作业。
我想这个测评也在一定程度上能体现模型的真实能力:
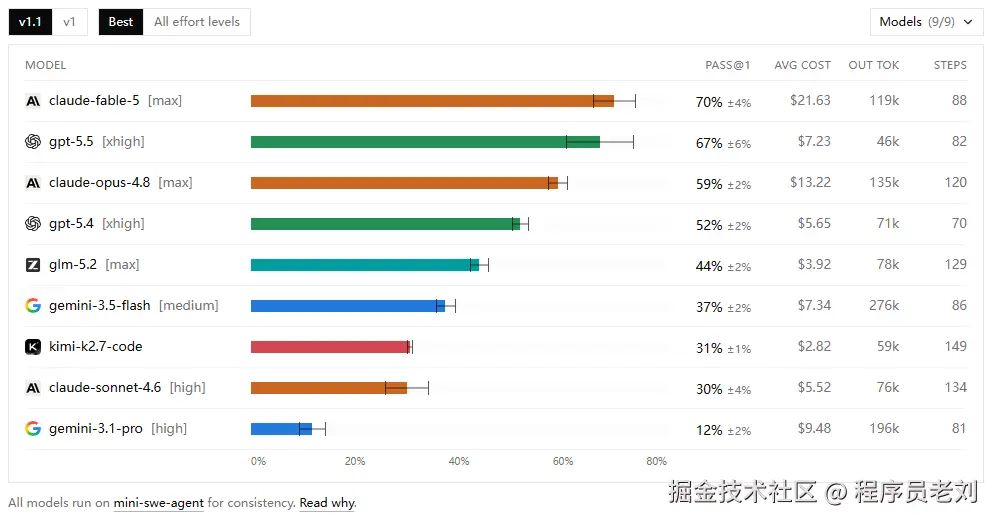
顶尖模型就选前三个,其中gpt-5.5性价比最高。
第二梯队GLM-5.2是最具性价比的。也是开源模型中最能打的。
老刘的三层模型选择法:省钱又高效
老刘在文章的开始就说了,测评只能作为一个参考,更多的还是要放到自己实际工作场景中去评估。
所以这里给大家一个基础模板,大家可以根据自己实际工作的情况替换其中的模型。
老刘把日常的工作分为三层:简单任务,核心任务,疑难任务
1. 简单任务
比如整理一个GitHub仓库的基本功能,汇总几个网站的数据,开发一个简单的按钮,或者修改文本提示。
模型选择:deepseek-v4-flash、agnes-2.0-flash、mimo-v2.5、qwen3.6-plus
这类任务通常都比较简单,不需要顶级大模型,所以成本低、速度快的轻量级模型就是最好的选择。
很多平台都对这些轻量级模型提供免费的使用额度,用来满足日常工作基本是够用的。
其实agnes-2.0-flash的能力也基本能胜任核心任务,但是因为目前是完全免费的,所以在这一层推荐给大家。
2. 核心任务
比如编写一个核心页面,编写一个模块的业务逻辑,技术方案的对比与选择。
模型选择: 开发任务:glm-5.2 非开发任务:deepseek-v4-pro、qwen-3.7-max、gemini-3.5-flash
其实这一层的选择非常多,基本上国内外的主流一线模型都能胜任,主要是根据大家能买到的coding plan,选择性价比较高的。
另外就是需要根据自己的实际工作场景去测试一下不同模型的效果。
比如老刘发现在这一层,不管是开发任务(Flutter项目)还是非开发任务,gemini-3.5-flash给我的体验都非常好,速度飞快,结果也比较精准。
3. 疑难任务
这一层没有典型的例子,一般是核心任务中发现模型搞不定,老刘就会直接切换到最顶级的大模型重新尝试。
模型选择:GPT-5.5 Thinking xHigh、Claude 4.8 Opus
碰到疑难杂症,最顶级的模型效果大概率会好一些,但也不见得就能解决问题。
还是需要开发者和模型配合,比如你提供疑点和思路,让大模型帮你去测试和验证。
老刘建议,如果碰到疑难杂症,一定要快速切换到顶级模型进行分析和处理。
否则可能你消耗了大量的时间、精力和token,在尝试了各种各样神奇的思路后,发现问题没有解决,钱也没有少花
选模型并非全部
模型好不好当然对任务完成得好不好、快不快,有直接的影响。
但是终究有些任务,你用最顶级的模型也未必能取得理想的效果。同样,非顶级的模型使用方法得当,也能得到和顶级模型差不多的结果。
这就要靠上下文的管理了,给模型清晰的、没有被混杂信息稀释的上下文,配置清晰且高效的工具,通过subagent隔离各种工具调用带来的庞大信息,以及在多轮次的循环中保持状态,清洗和压缩不重要的信息。
本质上,这就是harness工程要解决的问题。
不过大家始终要明白一件事:是否能管理好你的上下文,决定了你是把顶级模型用出三流的效果,还是用一个很便宜的coding plan就能完成只有顶级模型才能完成的工作。
总结
测评只是参考,真正决定效率的,是你有没有一套适合自己的模型选择策略。
好的模型搭配策略既省钱又能解决疑难杂症。
另一方面,用对方法,便宜模型也能打出顶级模型的效果。 这才是老刘想说的核心。
欢迎在评论区聊聊,你平时都用哪些模型?效果怎么样?
🤝 如果看到这里的同学对客户端或者Flutter开发感兴趣,欢迎联系老刘,我们互相学习。
🎁 私信免费领老刘整理的《Flutter开发手册》,覆盖90%应用开发场景。可以作为Flutter学习的知识地图。
💬 : laoliu_dev
📂 老刘也把自己历史文章整理在GitHub仓库里,方便大家查阅。