一、介绍


二、环境准备
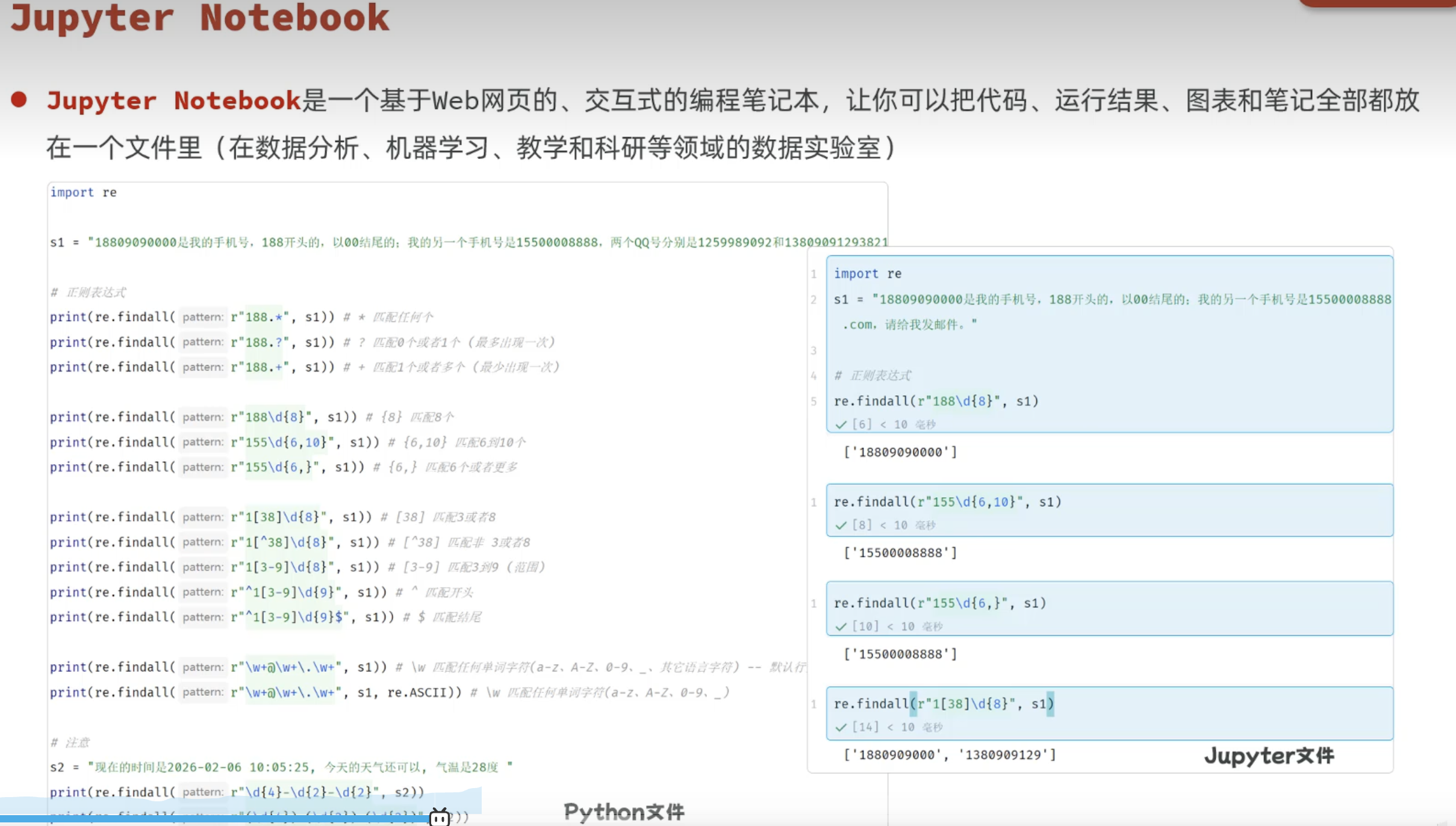
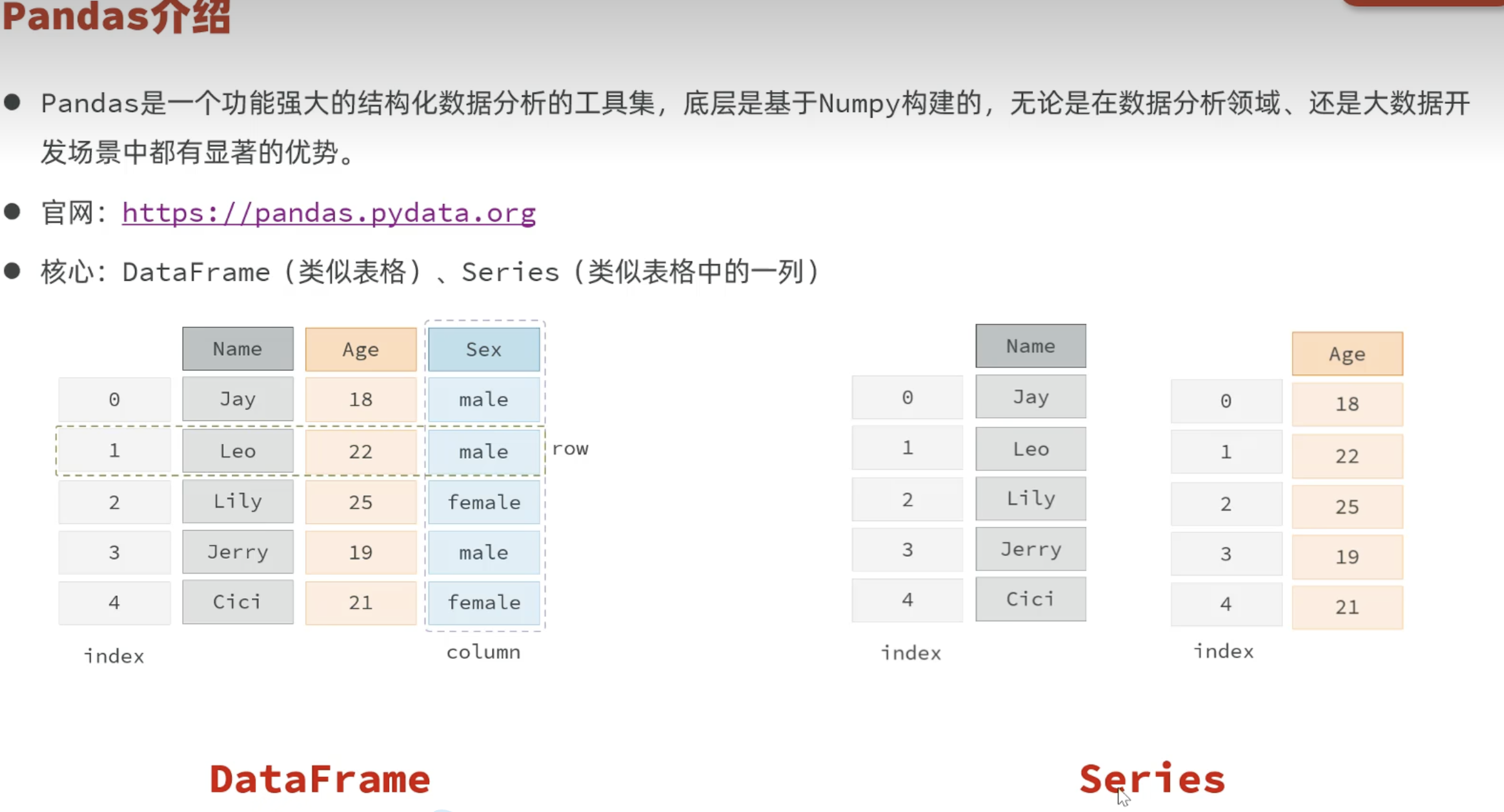
三、Pandas基础

3.1 初体验Pandas
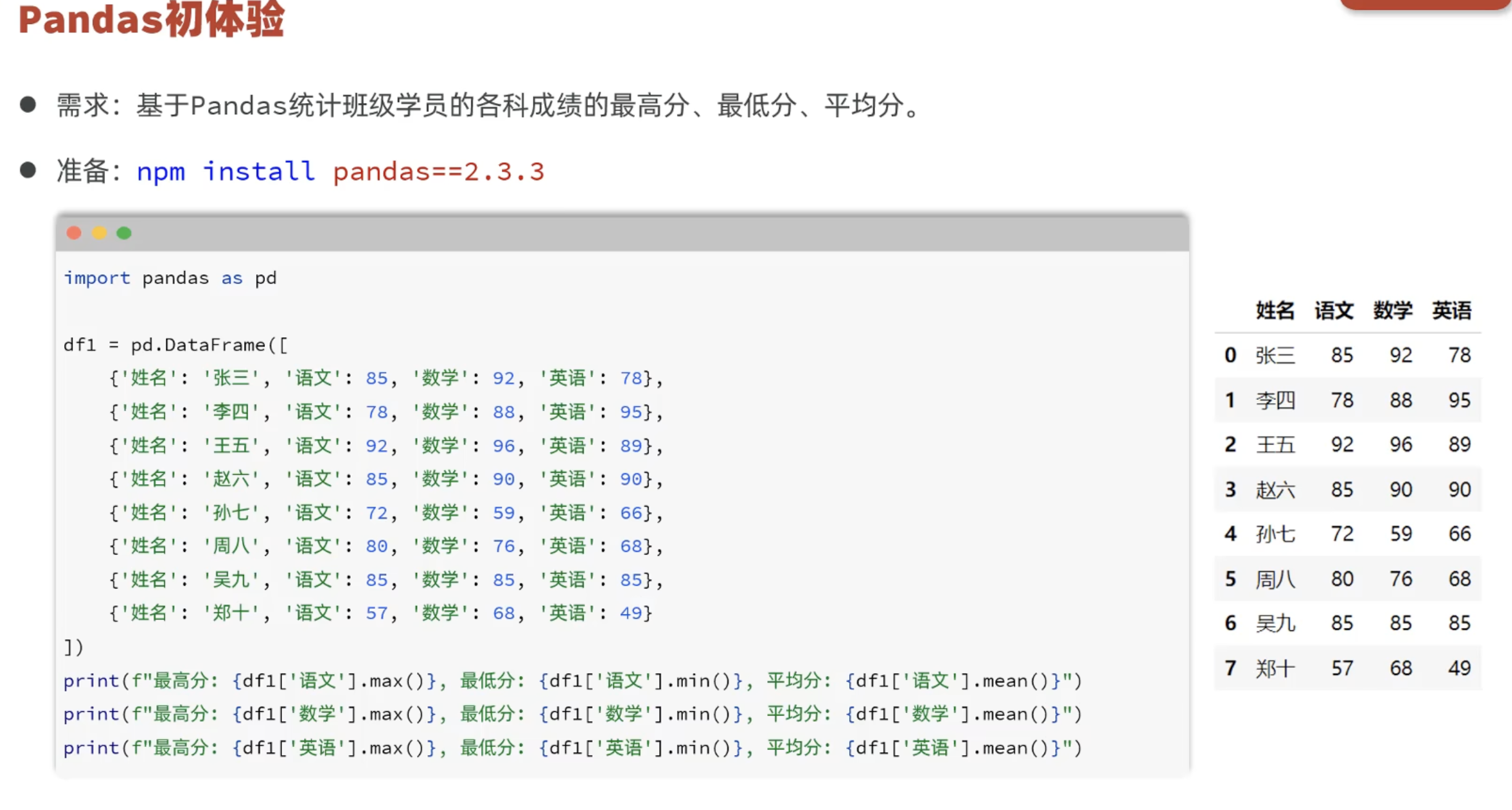
安装pandas

python
import pandas as pd
#构造DataFrame---创建数据集(学生成绩信息)
df = pd.DataFrame([
{"姓名":"小王","数学":99,"语文":98,"英语":97},
{"姓名":"小张","数学":95,"语文":96,"英语":98},
{"姓名":"小李","数学":90,"语文":95,"英语":95},
{"姓名":"小美","数学":100,"语文":87,"英语":87},
{"姓名":"小希","数学":100,"语文":65,"英语":77},
{"姓名":"小虎","数学":100,"语文":65,"英语":77}
])
df
#统计信息
df['语文'] #获取一列数据
type(df['语文']) #pandas.Series
df["语文"].max() #最大值
print(f"语文最高分:{df["语文"].max()},最低分:{df["语文"].min()},平均分:{df["语文"].mean():.2f}")
print(f"数学最高分:{df["数学"].max()},最低分:{df["数学"].min()},平均分:{df["数学"].mean():.2f}")
print(f"英语最高分:{df["英语"].max()},最低分:{df["英语"].min()},平均分:{df["英语"].mean():.2f}")
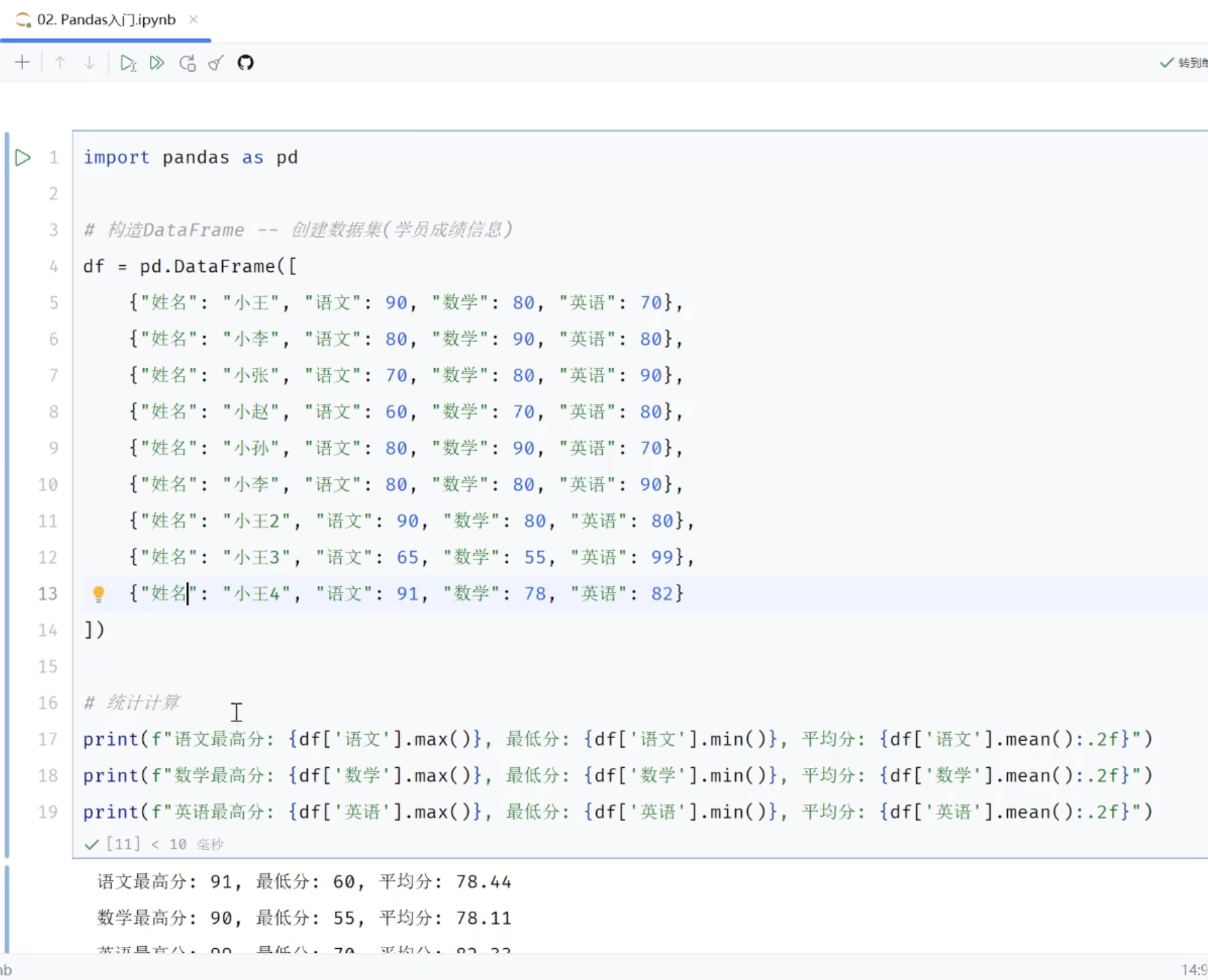
3.2 初体验DataFrame
3.2.1 DataFrame构建方式及属性

python
#DataFrame构建方式
import pandas as pd
# 1、横向定义,每一行按照key:value的方式
df = pd.DataFrame([
{'姓名':'张三','语文':78,'数学':99,'英语':66},
{'姓名':'王五','语文':88,'数学':90,'英语':90},
{'姓名':'赵六','语文':90,'数学':100,'英语':100}
])
df
# 2、纵向定义,每一列按照key:value的方式,value是一个数组
df1 = pd.DataFrame({'姓名':['张三','王五','赵六'],'语文':[78,88,90],'数学':[99,90,100],'英语':[66,90,100]})
df1
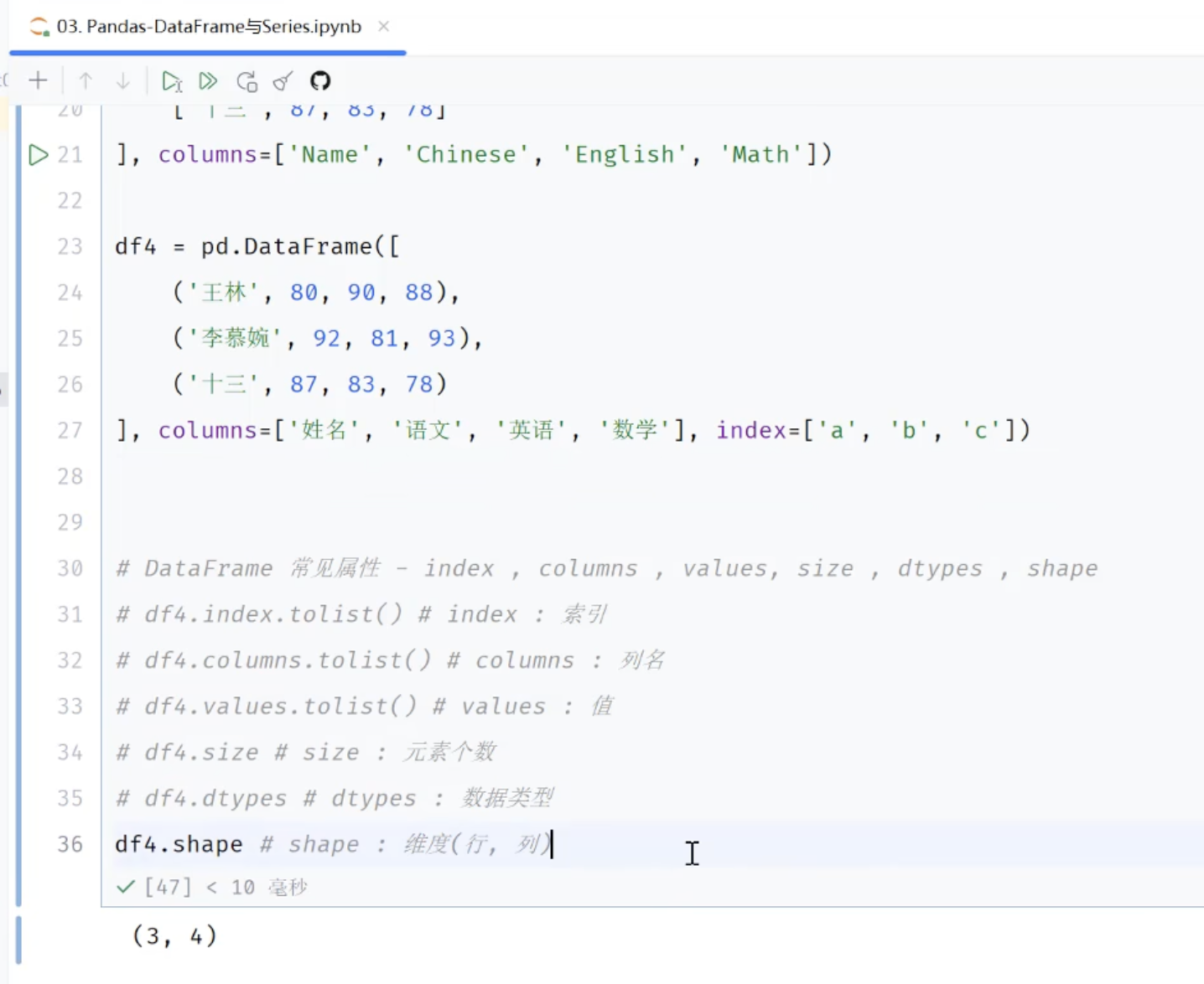
# 3、横向直接写数据,表头放后面,可以用数组或者元组,
# 3.1使用元组,表头自定义,使用columns关键字
df2 = pd.DataFrame([('张三',78,88,90),('王五',88,90,90),('赵六',90,100,100)],
columns=['姓名','语文','数学','英语'])
df2
# 3.2 使用数组 ,默认索引从0开始,索引可以自定义,使用index关键字
df3 = pd.DataFrame([['张三',78,88,90],['王五',88,90,90],['赵六',90,100,101]],
columns=['姓名','语文','数学','英语'],index=['a','b','c'])
df3
# 4、更多构建方式,参照DataFrame定义及示例
#DataFrame常见属性 index columns values size dtypes shape
# df3.index # 索引 Index(['a', 'b', 'c'], dtype='str')
# df3.index.tolist()
# df3.columns # 列名 Index(['姓名', '语文', '数学', '英语'], dtype='str')
# df3.columns.tolist()
# df3.values # 数组
# df3.values.tolist()
# df3.size # 元素个数 12
# df3.dtypes # 列名对应的数据类型
df3.shape # 表格维度(行,列)3.2.2 Series

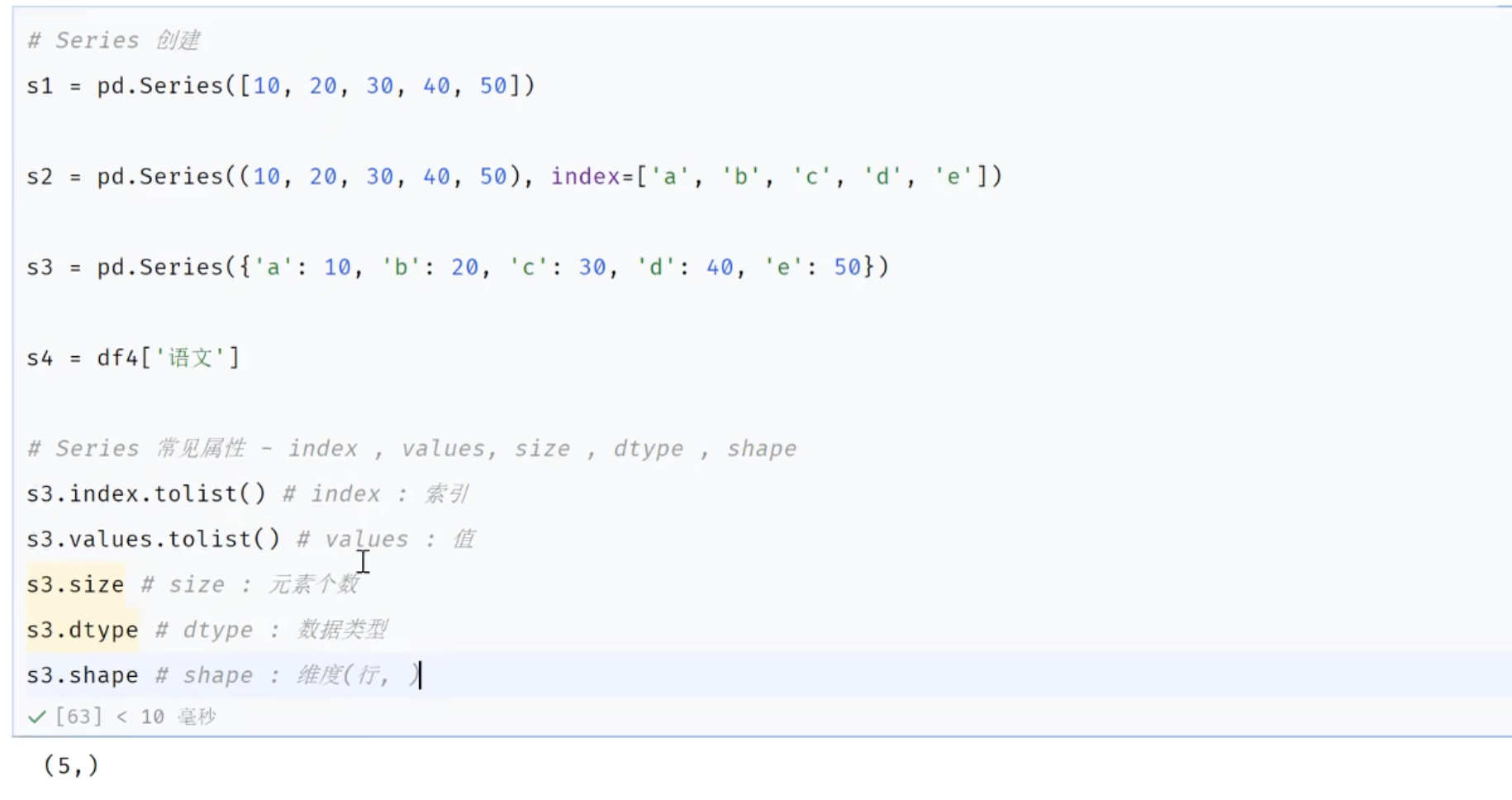
python
# series创建
s1 = pd.Series([10,20,30,40,50])
s1
s2 = pd.Series((10,20,30,40,55),index=['a','b','c','d','e'])
s2
s3 = pd.Series({'a':10,'b':20,'c':30,'d':40,'e':50})
s3
s4 = df3['语文']
s4
s5 = df3.数学 #不推荐,推荐使用 df3['数学']
s5
# Series常见属性 index values size dtype
s1.index # 索引 RangeIndex(start=0, stop=5, step=1)
s2.index # 索引 Index(['a', 'b', 'c', 'd', 'e'], dtype='str')
s3.index.tolist() #获取索引 ['a', 'b', 'c', 'd', 'e']
s1.values # 获取值 array([10, 20, 30, 40, 50])
s3.values.tolist() #获取值 [10, 20, 30, 40, 50]
s3.size # 元素个数 5
s3.dtype # 列名对应数据类型 dtype('int64')
s3.shape # 表格维度(行,列) (5,)
3.3 数据读取与写入
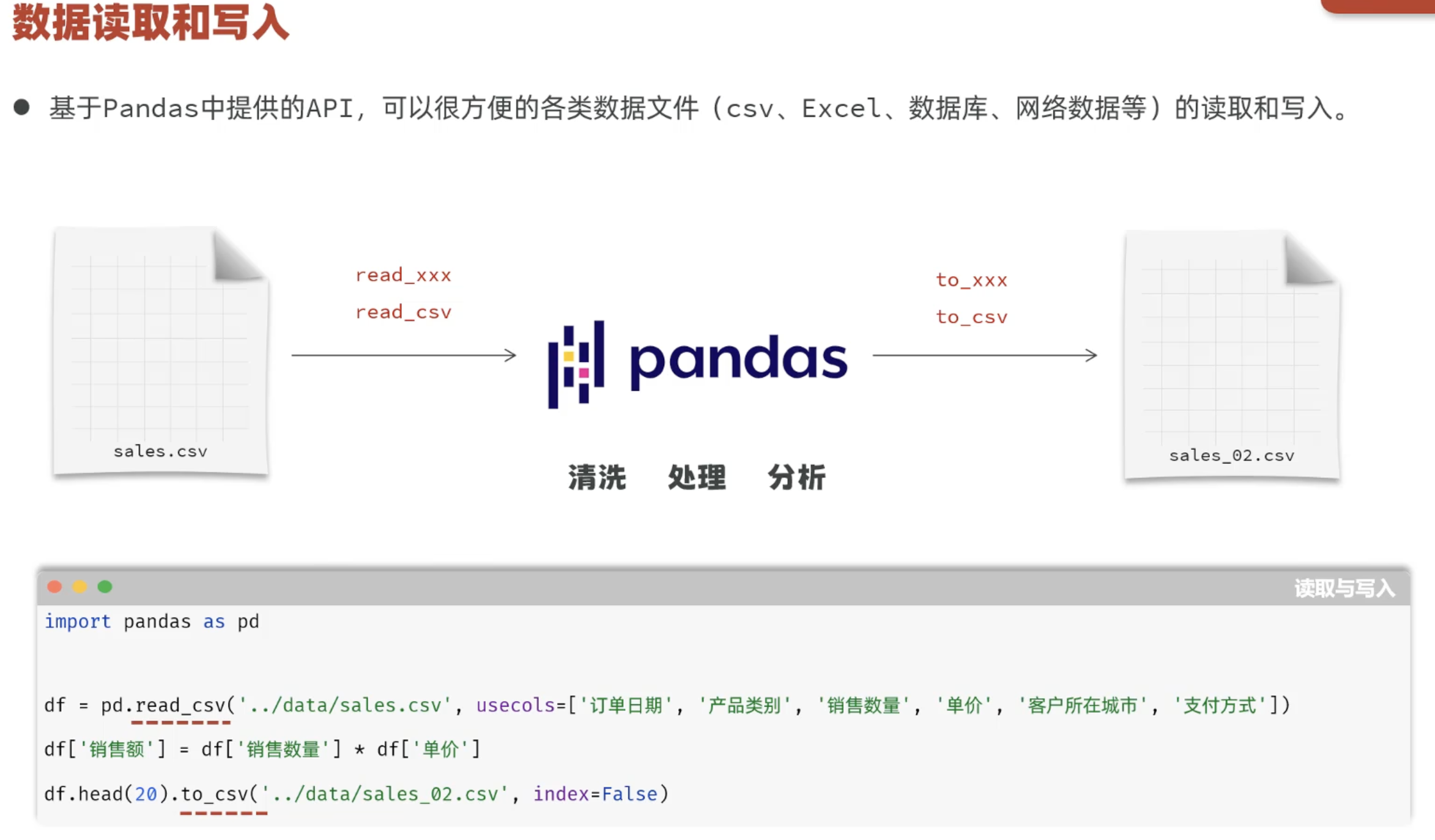
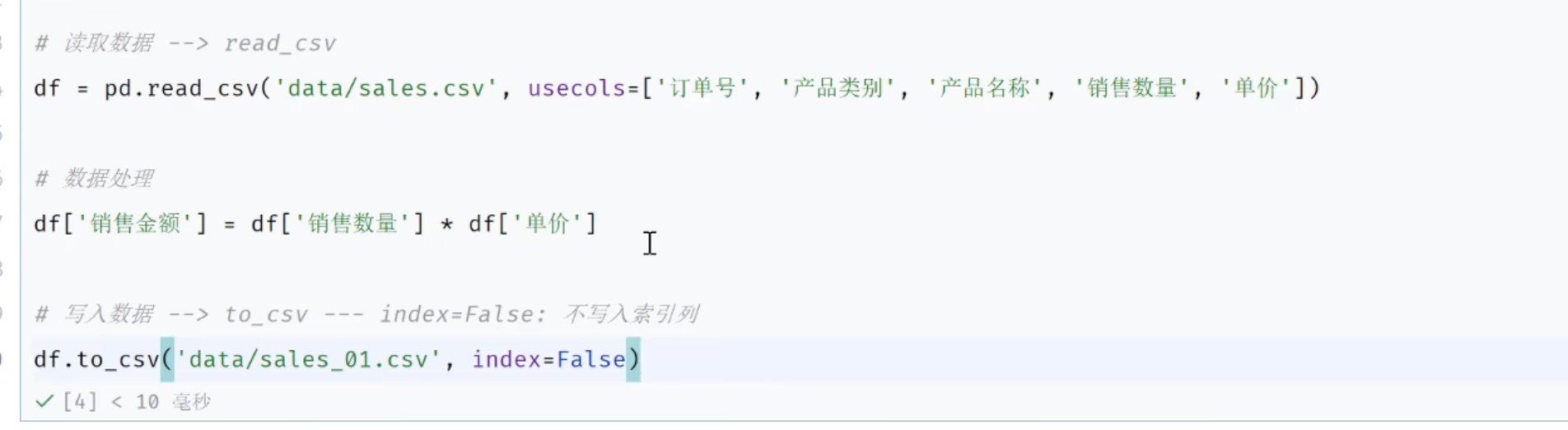
python
import pandas as pd
# 数据读取
df = pd.read_csv("data/1000_orders.csv") #读取数据,所有列
df = pd.read_csv("data/1000_orders.csv",usecols=["订单号","产品类别","产品名称","销售数量","单价"]) #指定列
df
# 数据处理
df['销售金额']=df['单价']*df['销售数量']
df
df = df.head(100)
df
# 写入数据 to_csv ----index=False 表示不写入索引列
df.to_csv("data/100_orders_new.csv",index=False)
3.4 数据查看、选择与过滤
3.4.1 查看
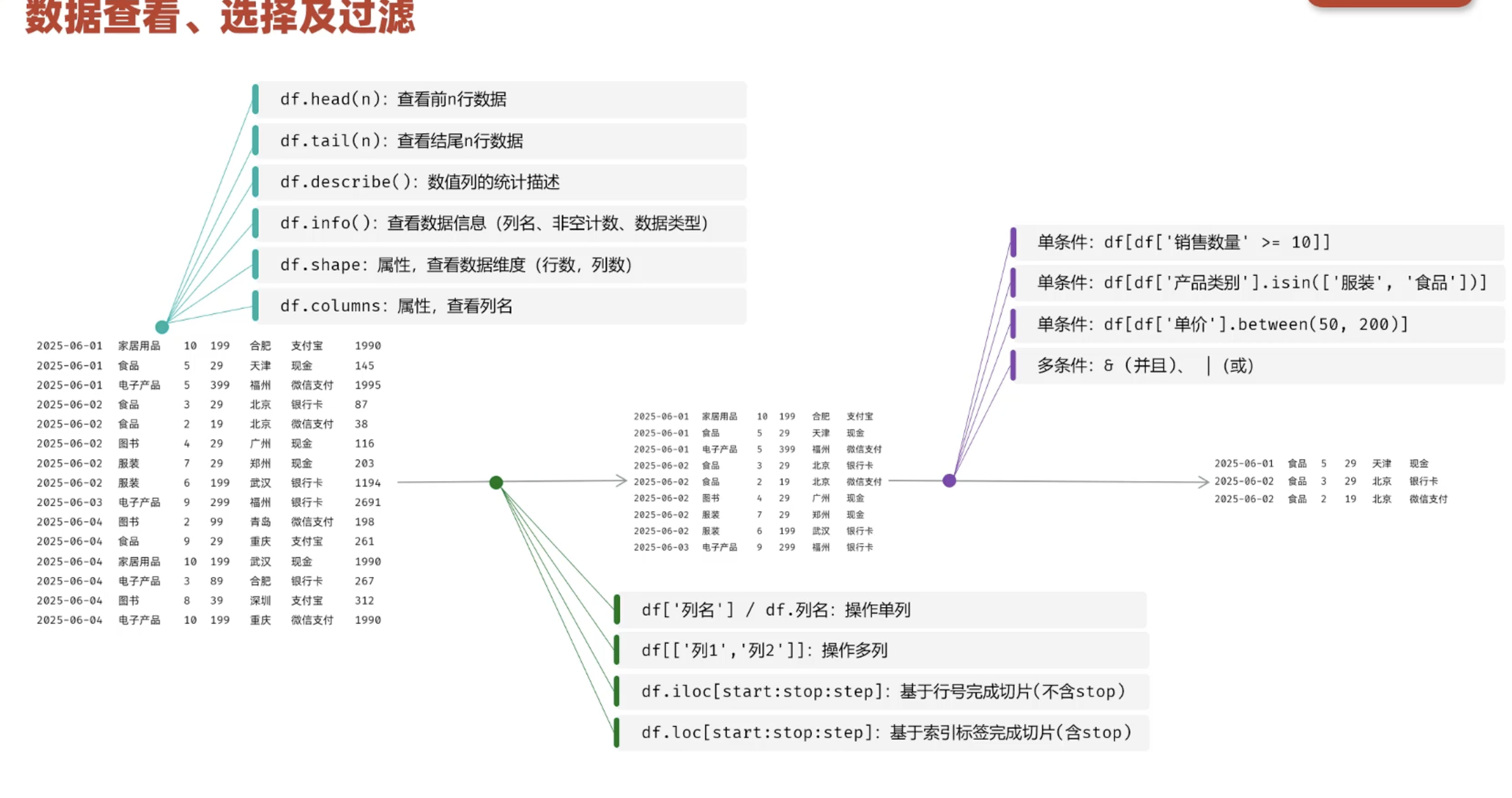
python
#数据查看 head() tail() describe() info() shape columns
df = pd.read_csv("data/1000_orders.csv",usecols=["订单号","产品类别","产品名称","销售数量","单价"])
df.head() #获取前5行数据
df.head(10) #获取前10行数据
df.tail() #获取最后5行数据
df.tail(10) #获取最后10行数据
df.sample(10) #随机获取10行数据
df.describe() #描述数据统计信息
df.info() #数据信息(列名、非空计数、数据类型类型)
df.shape # 属性,数据行数、列数
df.columns #属性,列名3.4.2 选择

python
#数据选择
df2 = pd.read_csv("data/1000_orders.csv",usecols=["订单号","产品类别","产品名称","销售数量","单价"],index_col="订单号")
df2
#选择列
#选择单列
df2['产品名称']
# df2.产品名称
#选择多列
df2[['产品名称','单价']]
df2[['产品名称','产品类别','单价']]
#选择行 iloc loc
# iloc----》 基于行号选择行 (不包含结束位置) 语法: iloc[开始行号:结束行号:步长]
df2.iloc[0:5:1]
# loc -----》基于索引选择行 (包含结束位置) 语法: loc[开始行索引:结束行索引:步长]
df2.loc['ORD2023000001':'ORD2023000010':2]3.4.3 数据过滤
语法:df条件表达式
python
#数据过滤
df3 = pd.read_csv("data/1000_orders.csv")
#配置项,展示所有行
# pd.set_option("display.max_rows",None)
df3
#数据过滤 df[filter]
# 1. 获取 销售数量>=10 的订单数据
df3[df3['销售数量']>=10]
# 2. 获取 产品类别 是 "食品饮料" 或"图书文具" 的订单数据
df3[df3['产品类别'].isin(["食品饮料","图书文具"])]
# df3[(df3['产品类别'] == "食品饮料") | (df3['产品类别'] == "图书文具")]
#3. 获取 单价在100到200 之间的订单数据 between包含边界
df3[df3['单价'].between(100,200)] #between包含边界
df3[df3['单价'].between(100,200,inclusive='left')] #between的取值:left:包含左边界, right:包含右边界 ,neither:不包含边界 both:包含边界
#4. 获取 销售数量>10 并且 单价>5000 的订单数据 --》多条件 (并且& 或者|)
df3[(df3['销售数量']>10) & (df3['单价']>5000)]
#5. 获取 产品类别 是 "食品饮料" 或"图书文具",支付方式为支付宝/微信支付 的订单数据
df3[(df3['产品类别'].isin(["食品饮料","图书文具"])) & (df3['支付方式'].isin(["支付宝","微信支付"]))]
3.5 数据清洗
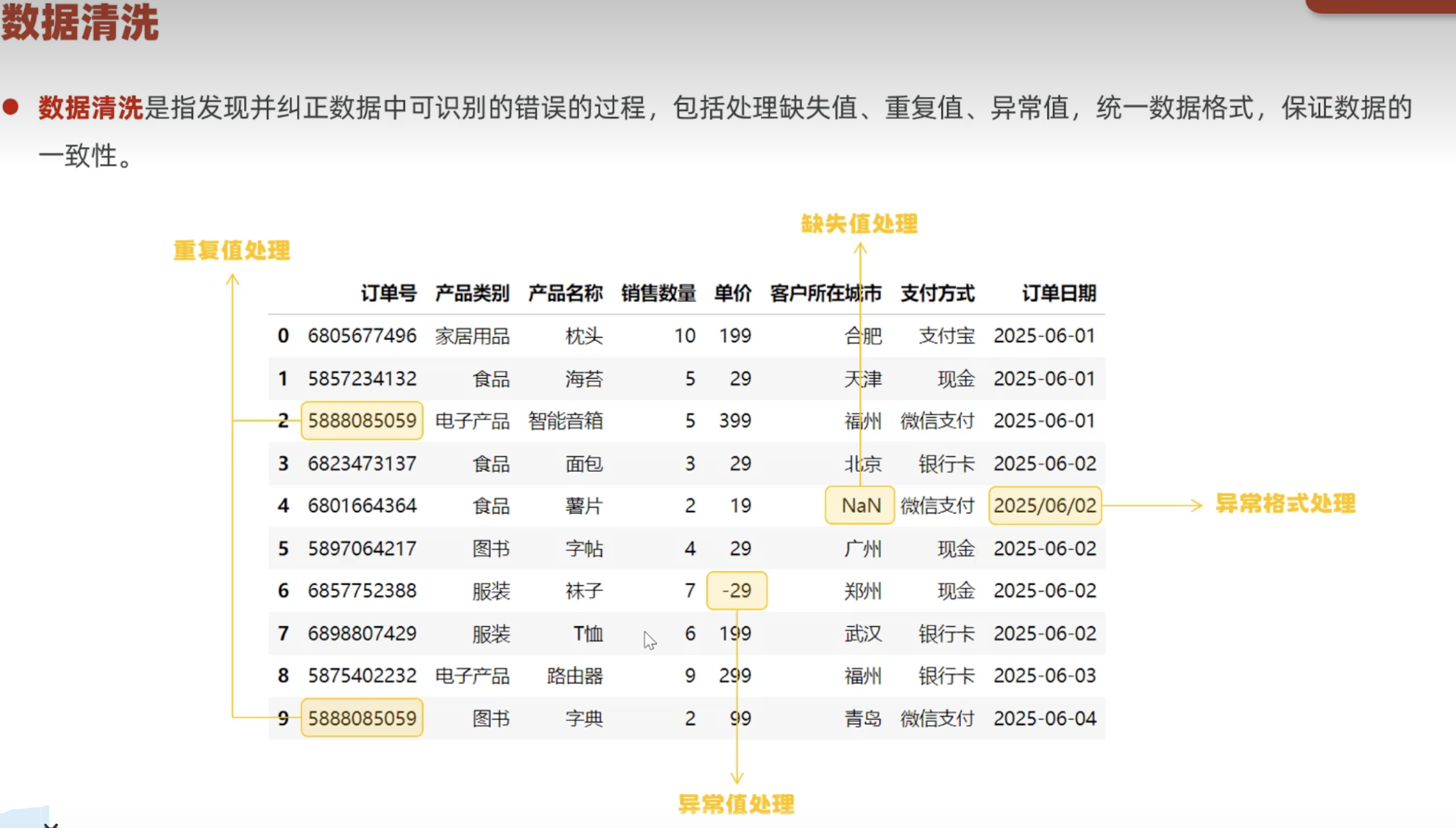
缺失值

重复值

python
#重复值
#查看重复值
df.duplicated() #查看重复值(所有的列数据全都一样)
df.duplicated(subset=["订单号"]) #查看重复值(指定列数据)
#删除重复值
df.drop_duplicates(subset=["订单号"]) #删除重复值(指定列数据)
df.drop_duplicates(subset=["订单号"],keep=False) #删除重复值 keep="first":保留第一个 keep="last":保留最后一个 keep=False:删除所有重复值异常值
数据格式


3.6 数据排序与分组
3.6.1 数据排序

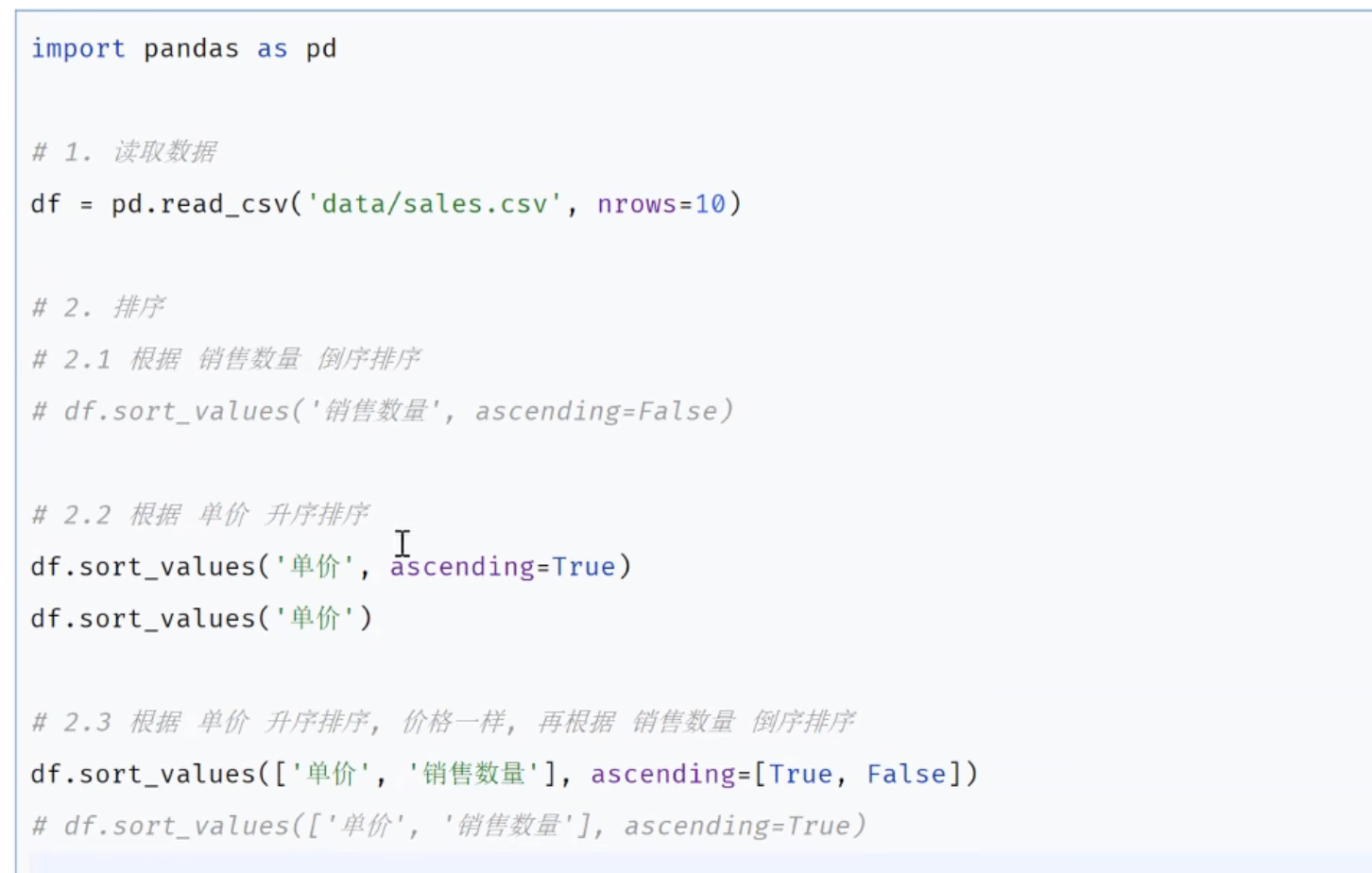

'
3.6.2 数据分组


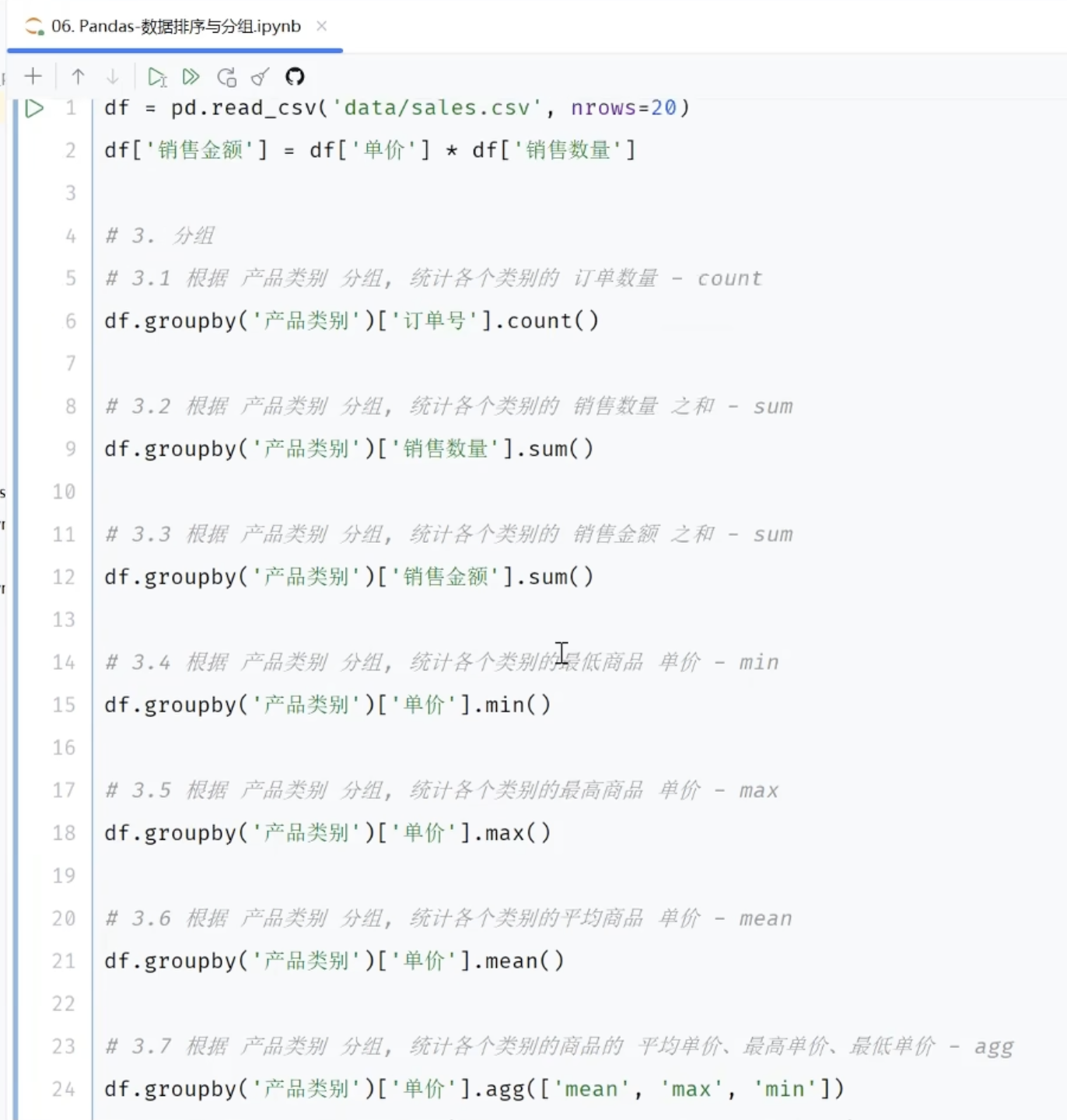


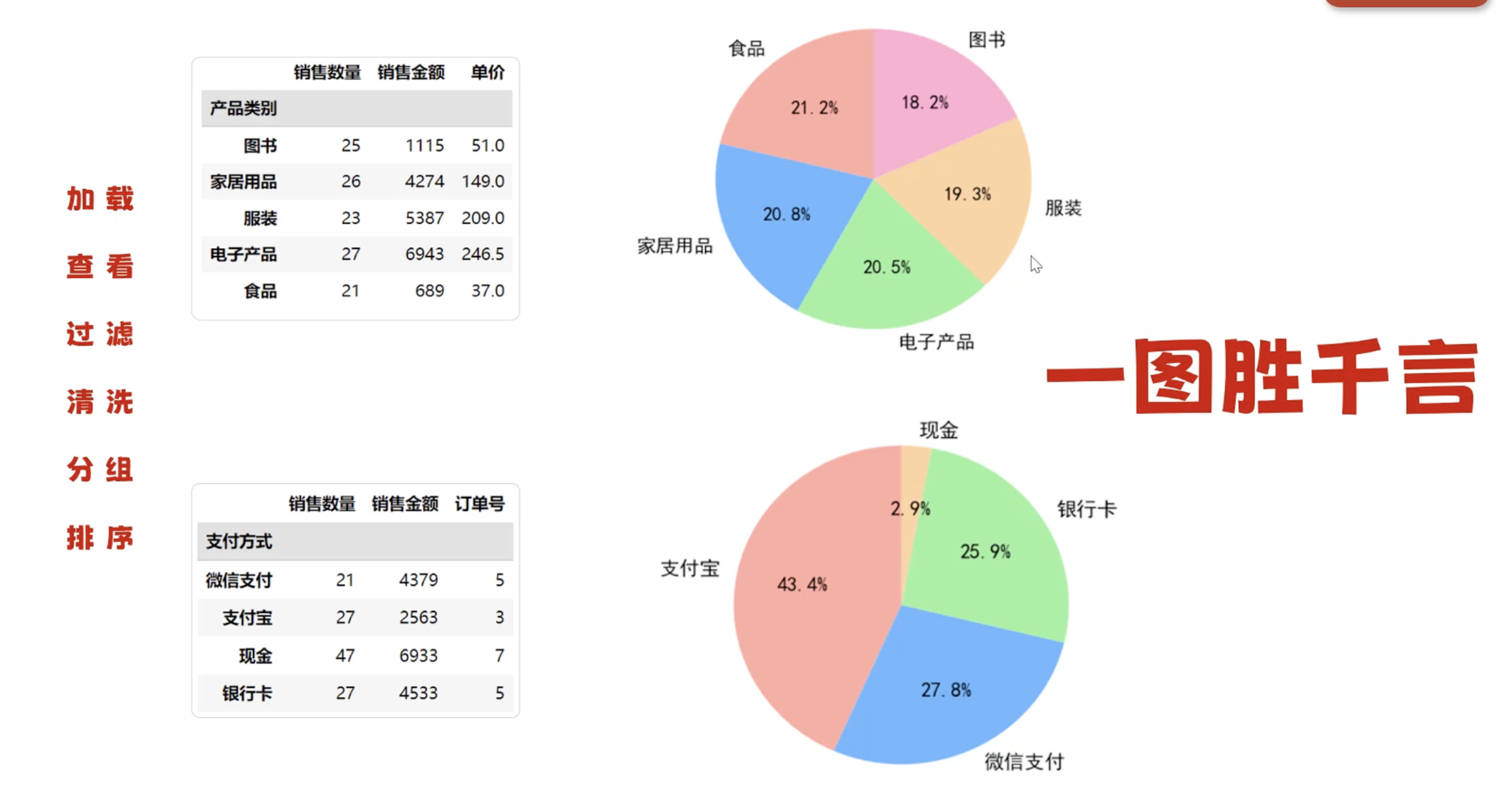
四、MatPlotLib
4.1 Matplotlib入门
4.1.1 安装matplotlib
4.1.2 入门程序
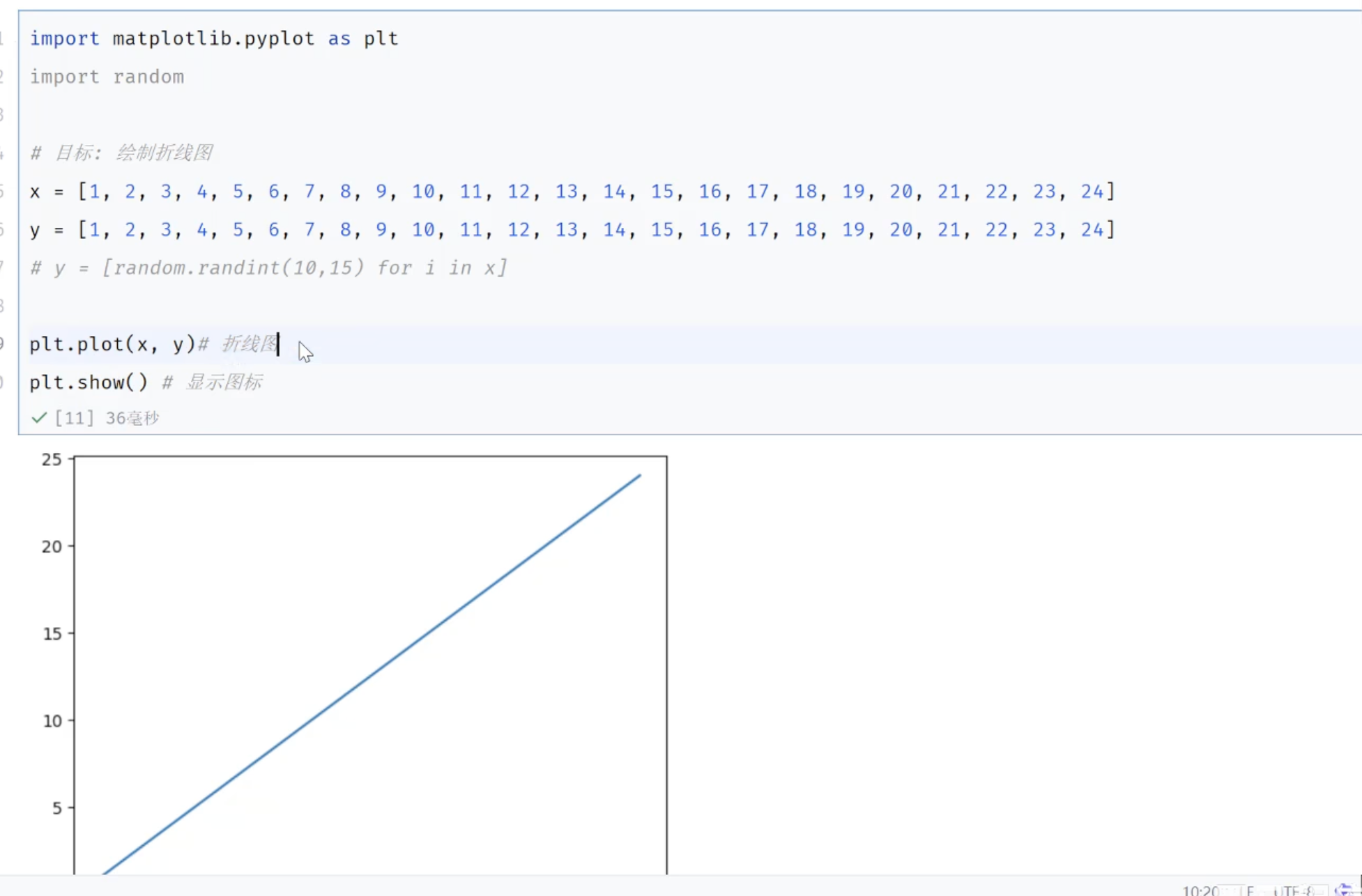
python
import matplotlib.pyplot as plt
import random
#目标:绘制折线图
x = [1,2,3,4,5,6,7,8,9,10]
# y = [2,4,6,8,10,12,14,16,18,20]
y = [random.randint(1,20) for i in x]
print(x)
print(y)
plt.plot(x,y)#绘制折线图
plt.show()#显示折线图4.2 图表信息详解
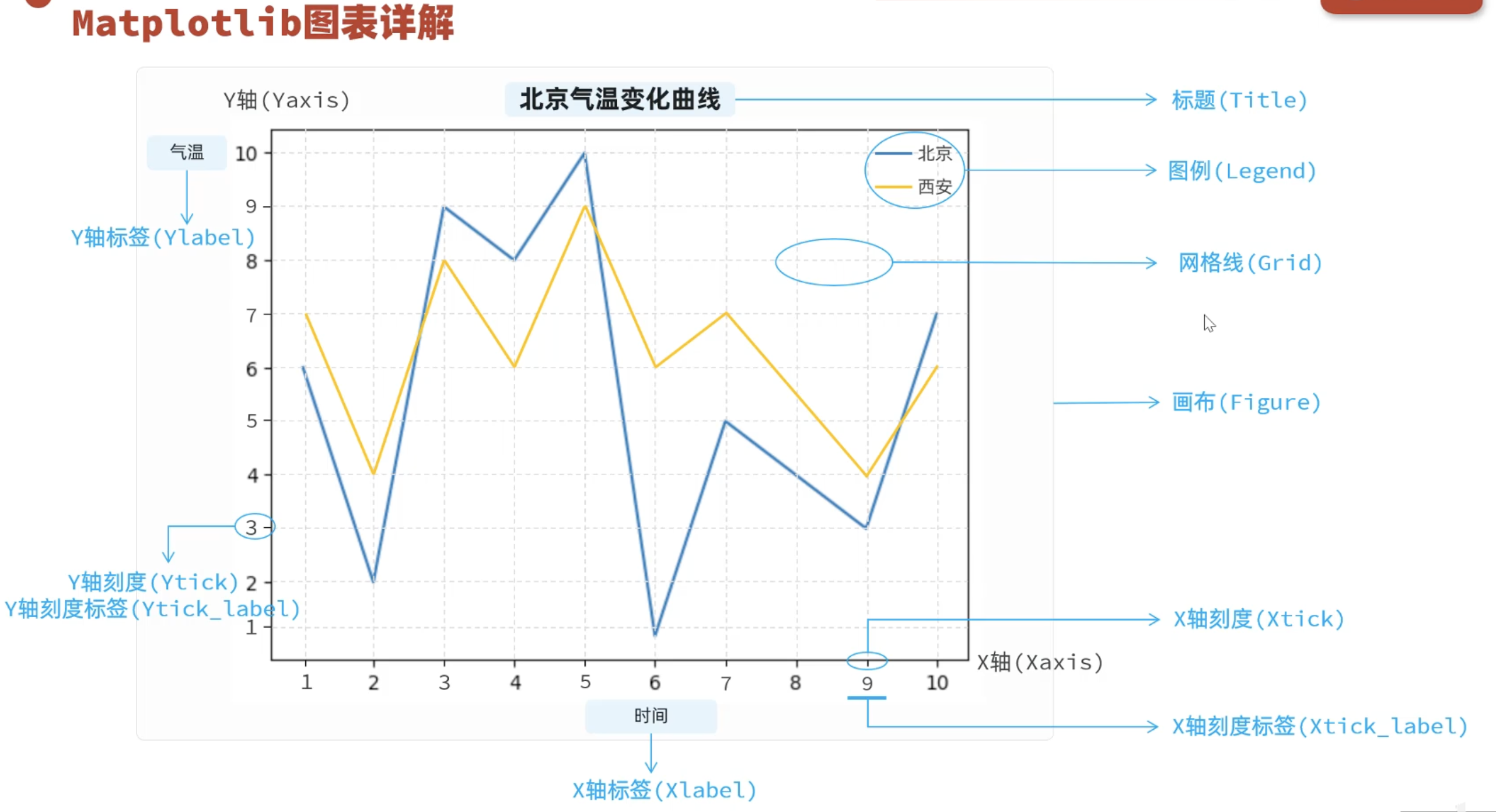
python
x = [i for i in range(1,11)]
y_bj = [random.randint(13,18) for i in x]
y_sh = [random.randint(15,20) for i in x]
#图表显示中文,字体设置
plt.rcParams['font.sans-serif'] = ['STHeiti']#需要根据电脑的字体设置,mac跟windows应该有差别
plt.figure(figsize=(10,5))#设置画布大小,长和宽
plt.title("气温变化曲线")#设置标题
plt.plot(x,y_bj,label="北京")
plt.plot(x,y_sh,label="上海")
plt.legend()#显示图例
plt.xlabel('时间') #设置x轴标签
plt.ylabel('气温') #设置y轴标签
plt.xticks(x) #设置x轴刻度
# plt.xticks(x[::2]) #设置x轴刻度
y_ticks = [i for i in range(10,25)]
plt.yticks(y_ticks) #设置y轴刻度
plt.grid(color='r',linestyle='-.',alpha=0.3)#显示网格
plt.legend(loc='upper right')#图例位置
# plt.legend(loc='upper left')
plt.show()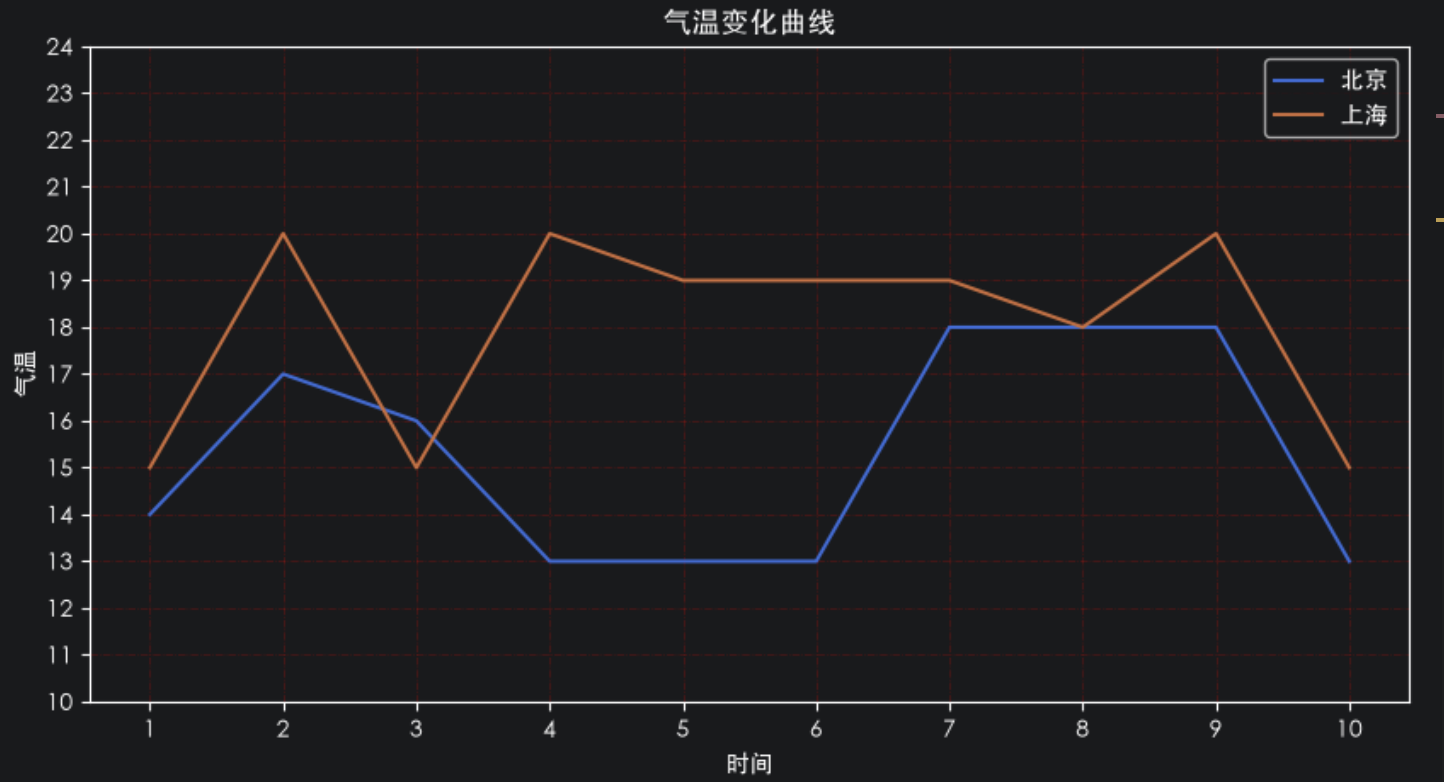
4.3 图表实战
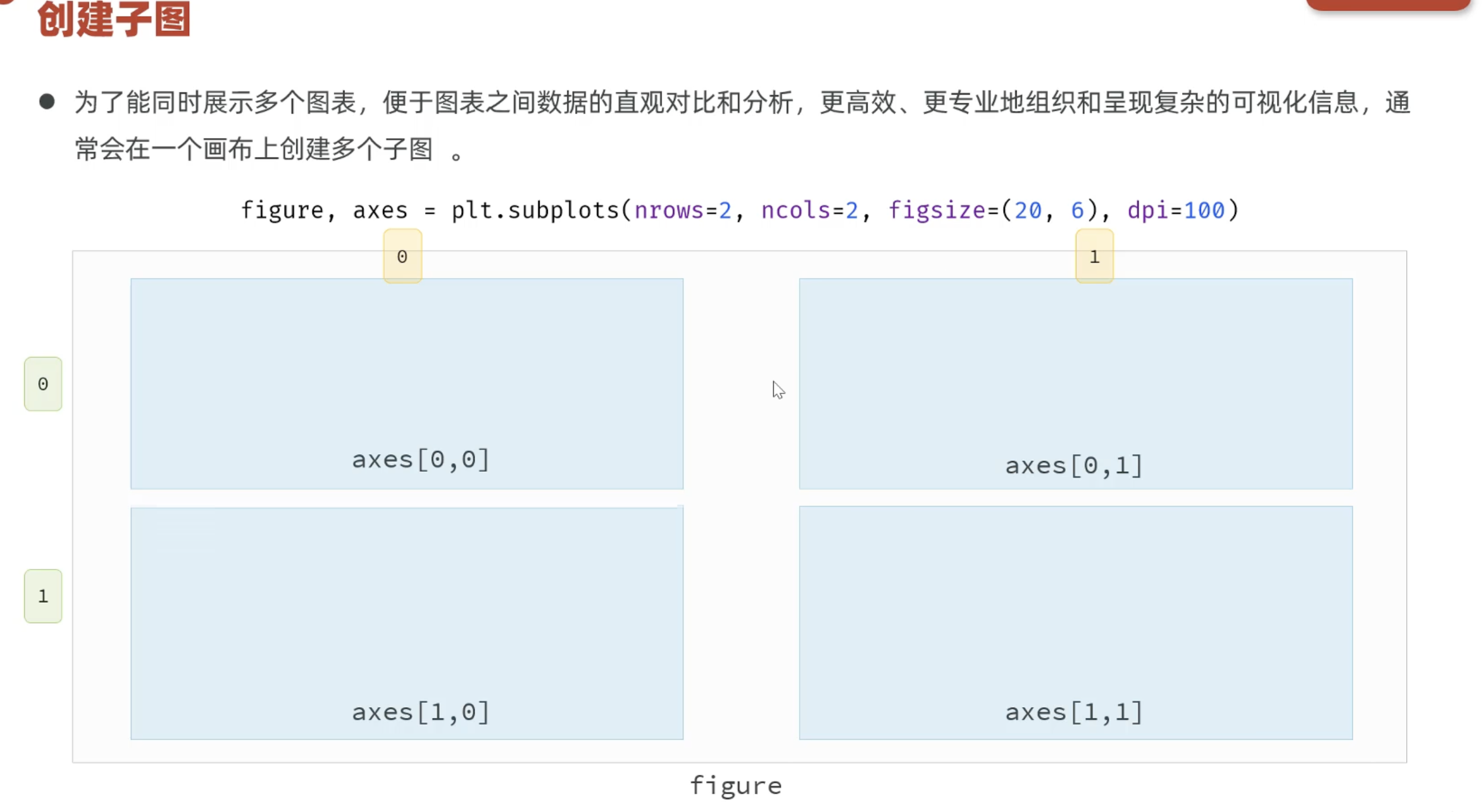
4.3.1 创建子图

4.3.2 柱状图
python
import matplotlib.pyplot as plt
#展示中文
plt.rcParams['font.sans-serif'] = ['STHeiti'] # 设置中文字体为黑体
# 创建子图 figure:画布对象 axes:子图对象(里面存放的是Axes对象类型)
figure, axes = plt.subplots(nrows=1,ncols=2,figsize=(15,5),dpi=100) # nrows=行数 ncols=列数 figsize=画布大小 dpi=分辨率
# 图一:柱状图(世界石油储备)
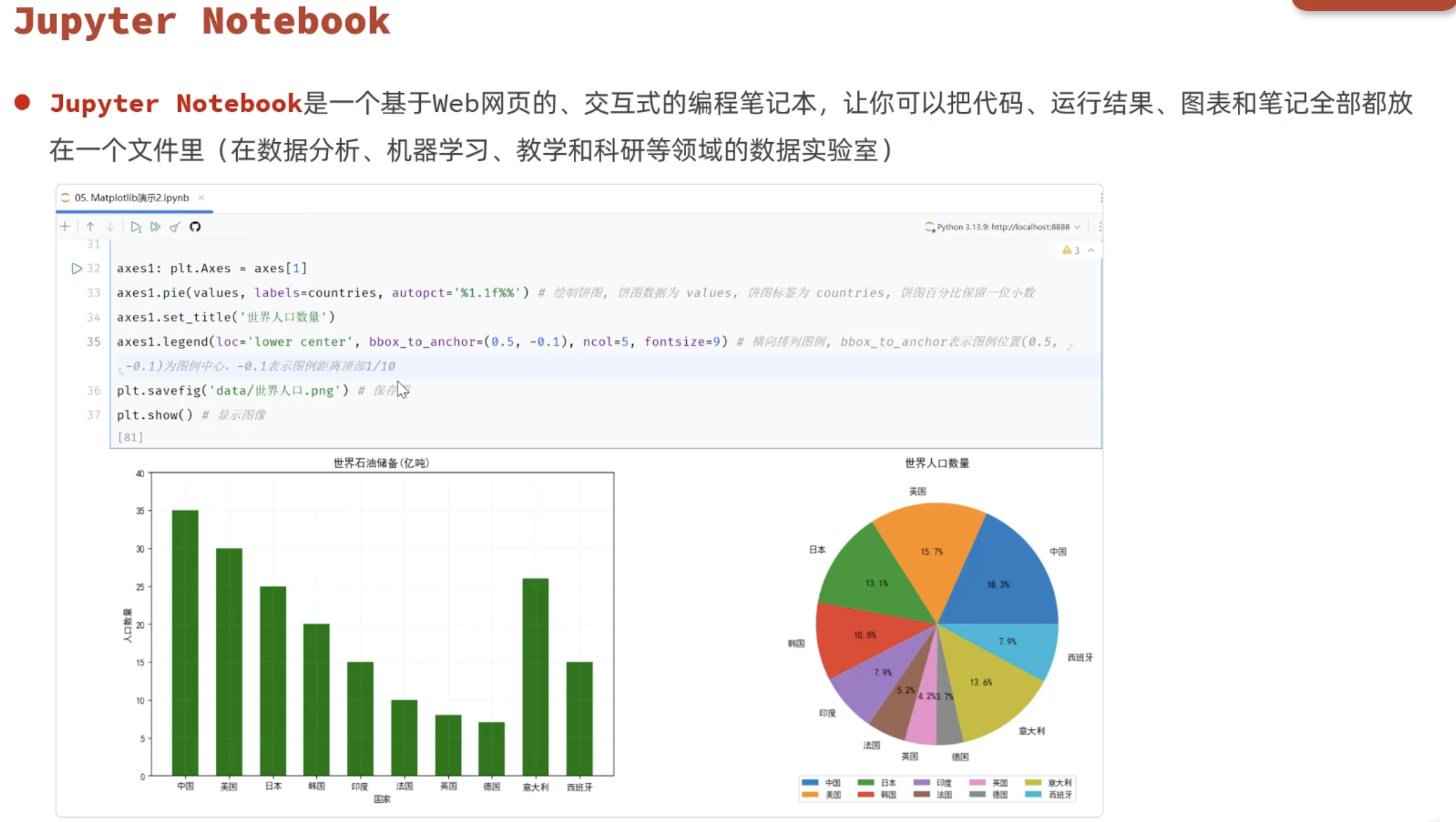
countries = ["中国","美国","日本","印度","英国","法国","德国"] # 国家列表
values = [60,50,80,40,20,70,90] # 国家对应的油量
axes1: plt.Axes = axes[0]
axes1.bar(countries, values,width=0.5,color="skyblue") # 绘制柱状图 width:柱状图宽度 color:柱状图颜色
axes1.set_title("世界石油储备",fontsize=16) # 设置标题
axes1.set_xlabel("国家",fontsize=12) # 设置X轴标签
axes1.set_ylabel("油量(亿桶)",fontsize=12) # 设置Y轴标签
axes1.grid(linestyle='--',alpha=0.3,color="gray") # 设置网格线 linestyle:线型 alpha:透明度
plt.show()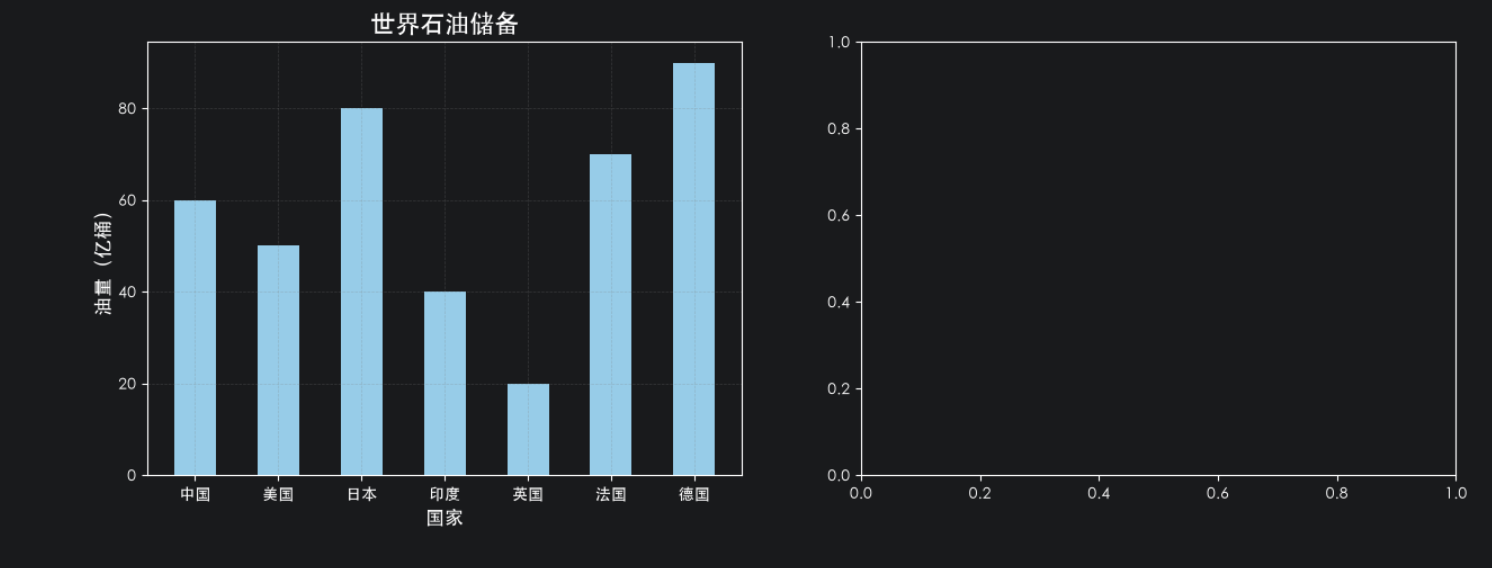
4.3.3 饼状图
python
import matplotlib.pyplot as plt
#展示中文
plt.rcParams['font.sans-serif'] = ['STHeiti'] # 设置中文字体为黑体
# 创建子图 figure:画布对象 axes:子图对象(里面存放的是Axes对象类型)
figure, axes = plt.subplots(nrows=1,ncols=2,figsize=(15,5),dpi=100) # nrows=行数 ncols=列数 figsize=画布大小 dpi=分辨率
# 图一:柱状图(世界石油储备)---->bar
countries = ["中国","美国","日本","印度","英国","法国","德国"] # 国家列表
values = [60,50,80,40,20,70,90] # 国家对应的油量
axes1: plt.Axes = axes[0]
axes1.bar(countries, values,width=0.5,color="skyblue") # 绘制柱状图 width:柱状图宽度 color:柱状图颜色
axes1.set_title("世界石油储备",fontsize=16) # 设置标题
axes1.set_xlabel("国家",fontsize=12) # 设置X轴标签
axes1.set_ylabel("油量(亿桶)",fontsize=12) # 设置Y轴标签
axes1.grid(linestyle='--',alpha=0.3,color="gray") # 设置网格线 linestyle:线型 alpha:透明度
# 图二:饼状图(世界人口) ---->擅长比例分析---->pie
countries = ["印度","中国","美国","日本","英国","法国","德国","其他"]
values = [14.51,14.09,3.4,1.05,9.01,8.05,7.4,30]
axes2: plt.Axes = axes[1]
axes2.pie(values,labels=countries,autopct="%.1f%%")
axes2.set_title("世界人口比例",fontsize=16) # 设置标题
axes2.legend(loc="lower center",fontsize=12,bbox_to_anchor=(0.5, -0.1),ncol=5) # 设置图例 loc:位置 ncol:列数 bbox_to_anchor:位置(控制左右距离,控制上下距离)
#保存图片
plt.savefig("data/世界人口比例.png")
plt.show()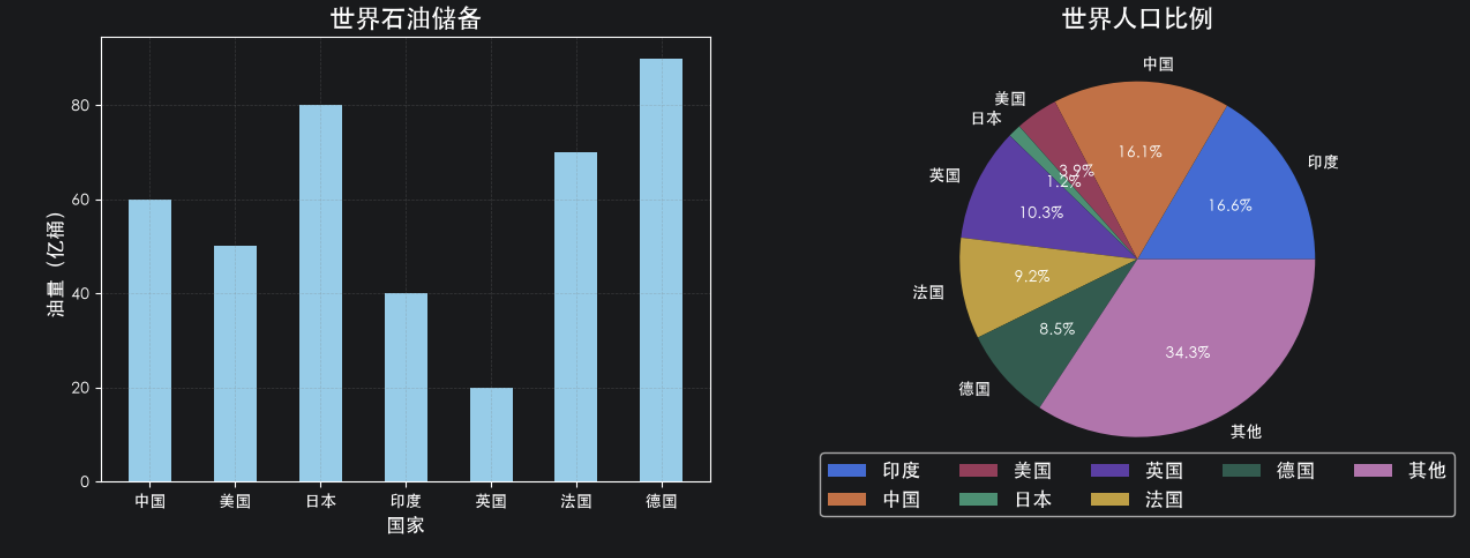

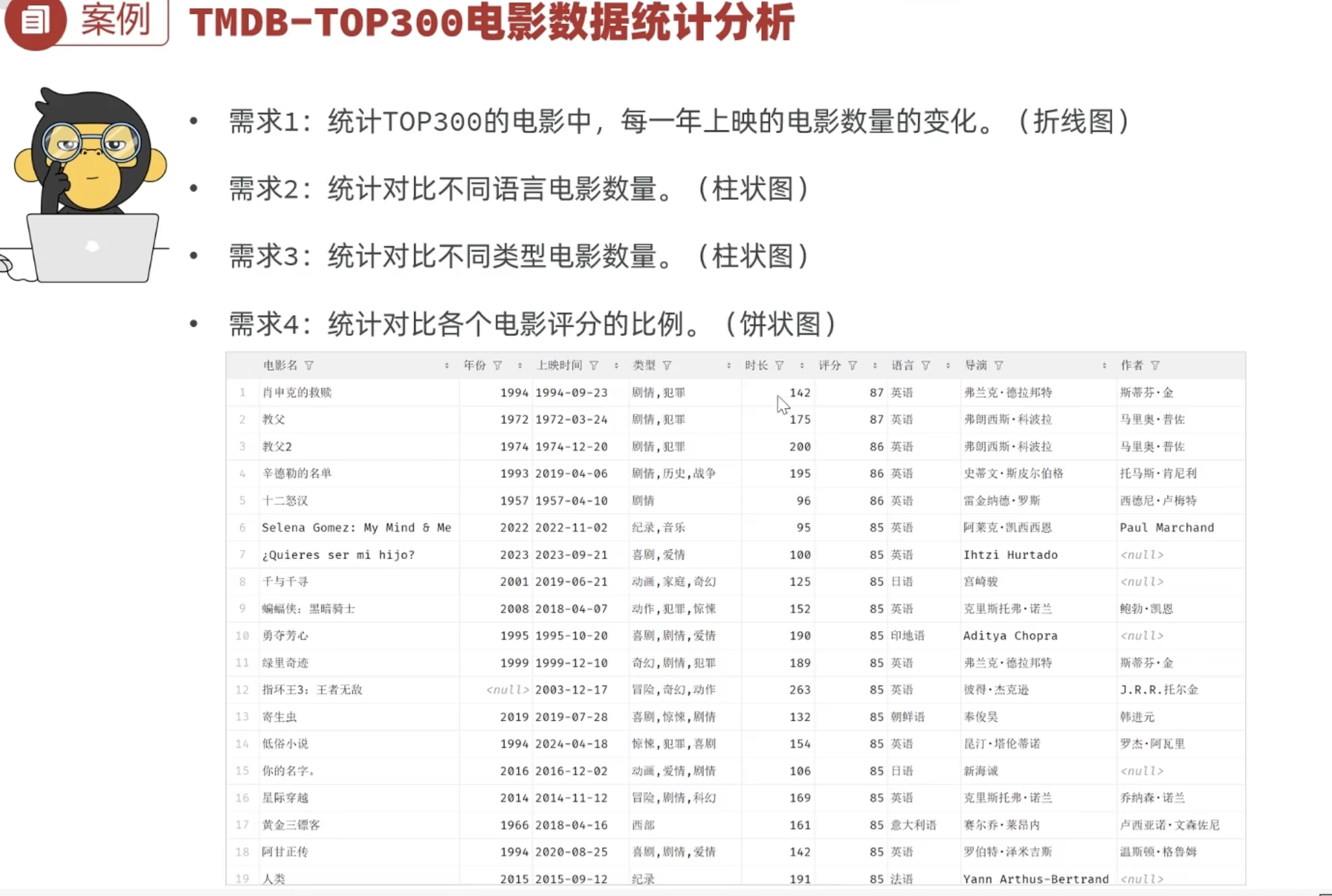
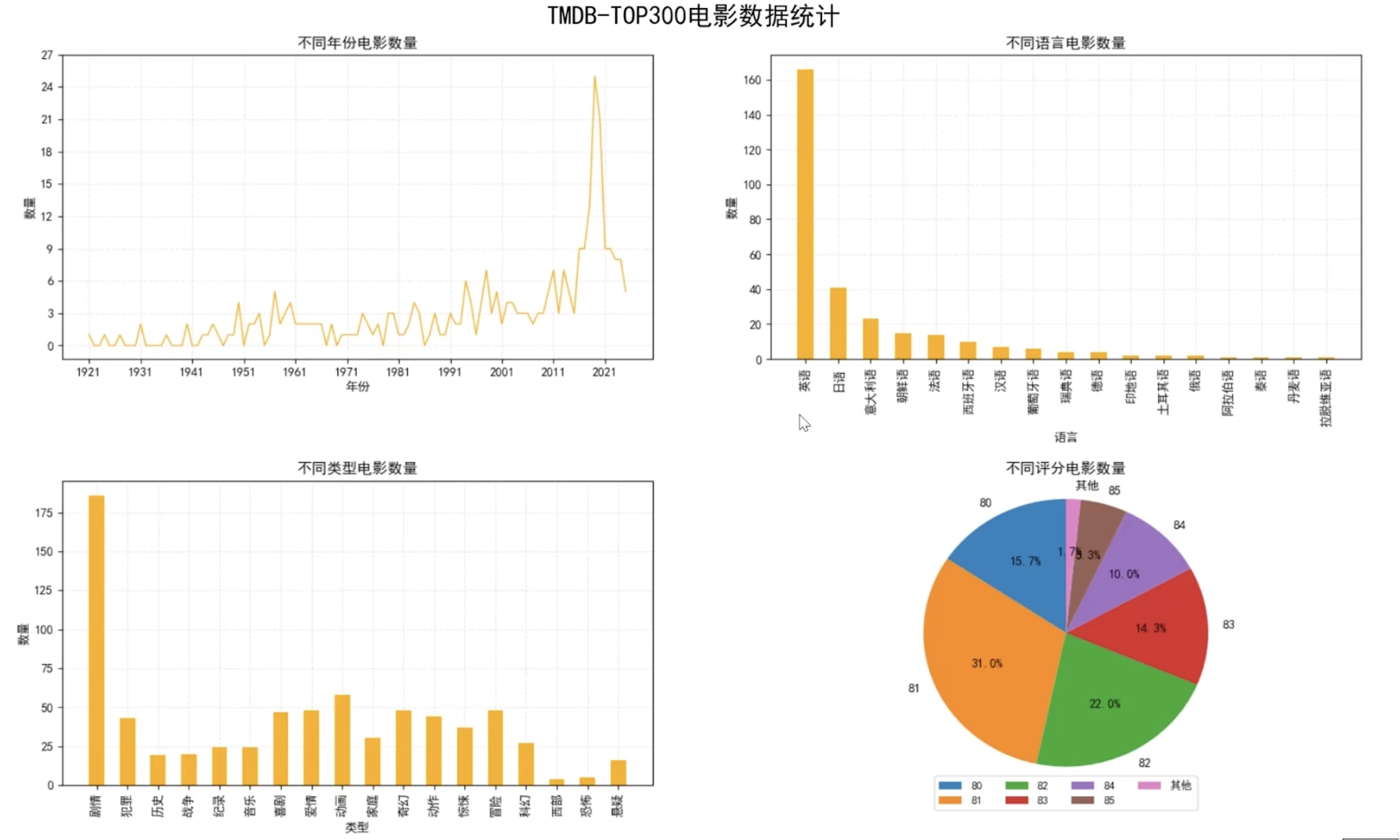
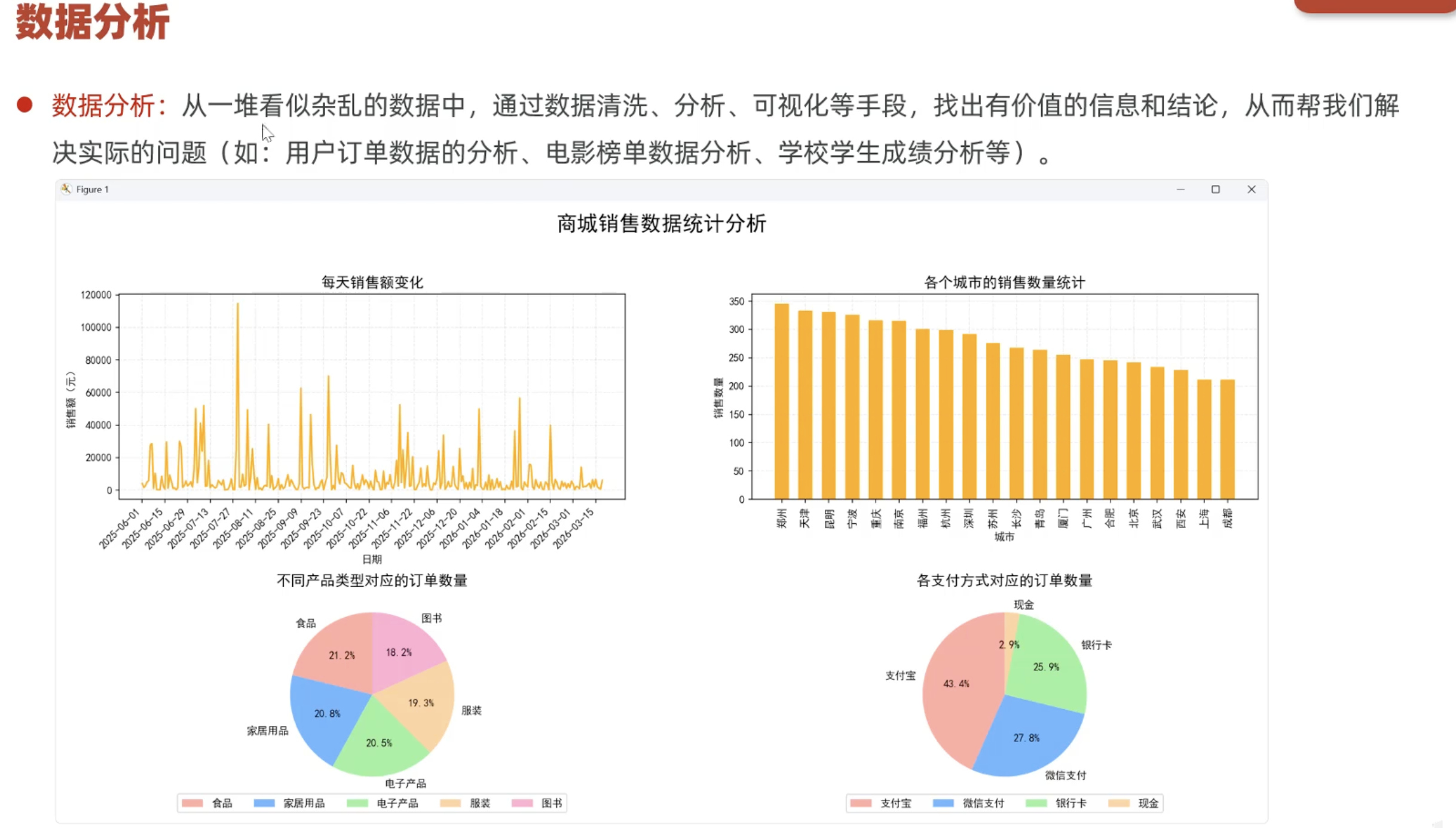
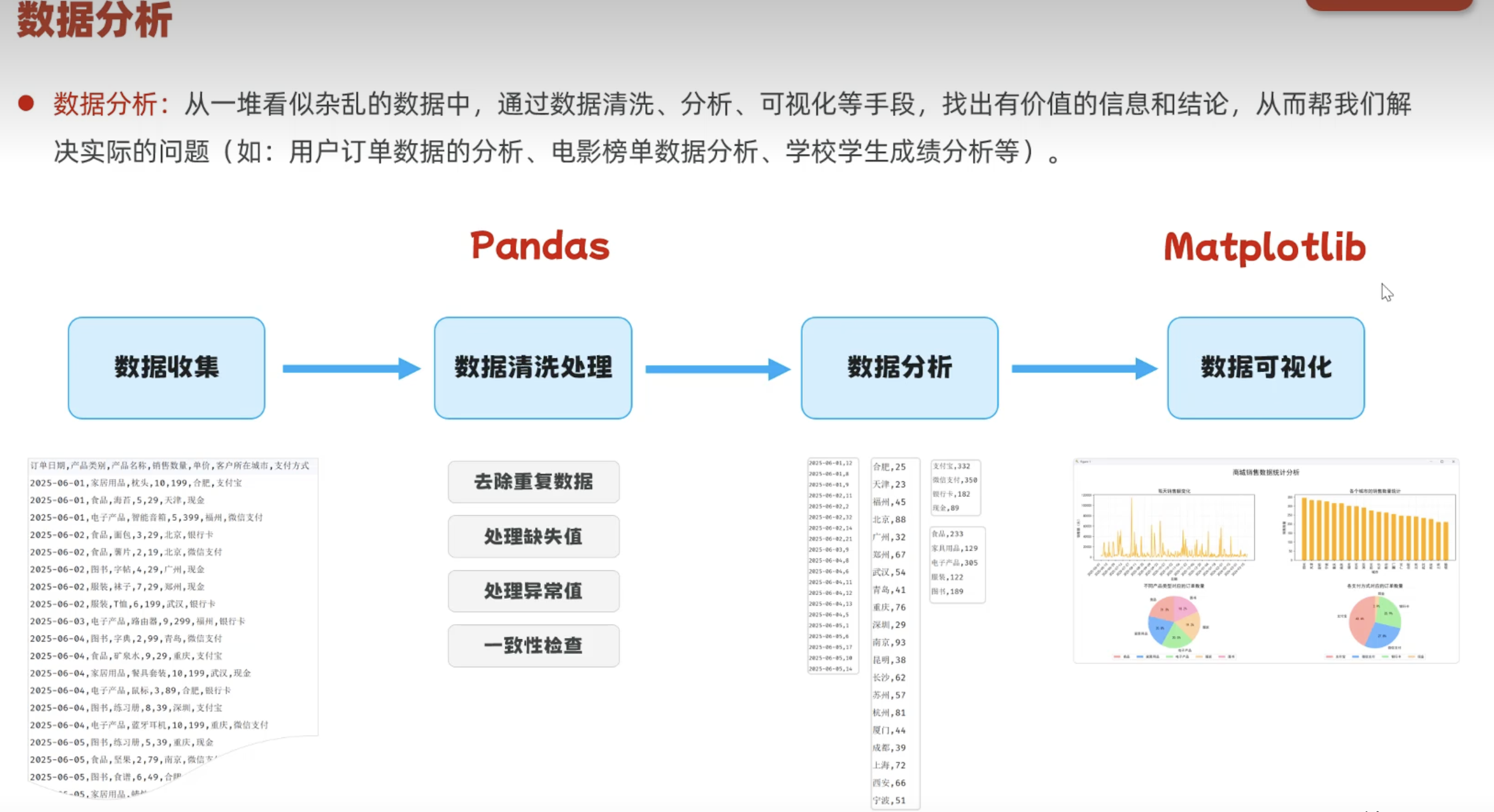
五、数据分析案例