by 雪隐_上班了 from juejin.cn/user/143341...
欢迎分享与聚合,全文转载就不必了,尊重版权,圈子就这么大,若急用可联系授权。
前言:我的 5060Ti 越来越全能了,它现在是我同事
前两回咱们聊了啥?
第一回 :5060Ti 学会了画画(FLUX.2 Klein),从此产品经理不再追着我改图。
第二回:5060Ti 学会了学人说话(Qwen3-TTS),老板的声音被我克隆后,我说啥就是啥。
这回更狠------我让它学会了 自己跟自己聊天。
没错,本地大语言模型(LLM)部署,让我的 5060Ti 16G 变成了一个可以随时对话的 AI 同事。不用联网、不用 API 花钱、不用担心敏感数据传到云端,想聊多久聊多久,它还永远不会嫌你烦。
这次我用的是 LM Studio + Qwen3.6-35B-A3B,一个 MoE(混合专家)架构的大家伙------总参数量 350 亿,但激活的只有 30 亿,相当于一个大力士平时只出三分力,省电又高效。
而我的 5060Ti 16G,刚好够喂饱它(量化后 Q4_K_M 版本约 16GB,卡在满显存的边缘,刺激吧?)。
项目概览(看看我的"赛博同事"的配置)
硬件环境(就是我的宝贝电脑)
| 配置 | 我的实际情况 | 吐槽 |
|---|---|---|
| 显卡 | RTX 5060 Ti 16GB | 买它的时候肉疼,现在越用越觉得值 |
| 内存 | 32GB(DDR5,咬牙上的) | AI 吃内存像饿了三天的人吃自助餐,32GB 勉强够 |
| 硬盘 | 还剩 50GB 空余 | 为了给模型腾地方,删了一堆学习资料(别问是哪种) |
| 系统 | Windows 11 | 稳定得像我每天准点摸鱼的习惯 |
软件环境(全是免费工具,良心)
| 软件 | 说明 | 我的评价 |
|---|---|---|
| LM Studio | 本地大模型部署神器,开箱即用 | 比 Python 环境好伺候一万倍,双击就能跑 |
| 显卡驱动 | NVIDIA Driver 535+ | 装好就行,不用折腾 CUDA,LM Studio 全包了 |
| CUDA | LM Studio 内置 | 它自己偷偷装好了,你甚至不用知道它在哪 |
关于模型:Qwen3.6-35B-A3B,它是个"节省大师"
这是阿里通义实验室开源的 MoE(混合专家)架构 模型,翻译成人话就是:
它不是让全公司 350 亿个员工一起干活,而是根据任务类型,只叫醒最擅长的那 30 亿个专家,其他人继续睡觉。
------所以叫"稀疏激活",省电、省显存、还快。
| 参数 | 数值 | 翻译 |
|---|---|---|
| 总参数量 | 350 亿 | 公司总员工数 |
| 激活参数 | 30 亿 | 每次只叫醒这些人干活 |
| 架构 | 稀疏混合专家 (MoE) | 术业有专攻,各管一摊 |
| 上下文长度 | 262K token | 相当于一口气看完《三体》三部曲还能记住细节 |
MoE 架构有多香?
350 亿的能力,30 亿的计算量,我的 5060Ti 16G 跑起来风扇都懒得加速。
量化版本怎么选?看你的显存,别贪心
模型文件分不同"量化等级",就像压缩图片:压缩越多,质量略降,但体积小很多。
| 量化级别 | 显存需求 | 质量 | 适合谁 |
|---|---|---|---|
| Q4_K_M | ~16GB | 高(基本感觉不到损失) | 我的 5060Ti 用户,刚好卡在满显存,用起来很刺激 |
| Q5_K_S | ~18GB | 很高 | 显存 20GB+ 的大户人家 |
| Q8_0 | ~22GB | 接近无损 | 土豪,请随意 |
我选的是 Q4_K_M ------16GB 显存几乎吃满,但推理速度依然流畅。
每次看到 LM Studio 底部显示 VRAM: 15.8GB / 16.0GB,我都觉得像在走钢丝,但就是不掉下去,爽。
LM Studio 是什么?一句话:显卡的"傻瓜相机"
为什么非要用它?
| 特性 | 对我这种懒人的意义 |
|---|---|
| 🎯 开箱即用 | 下载 → 双击安装 → 打开 → 选模型 → 开聊,全程不用打开命令行 |
| 🔧 简单到过分 | 界面就几个按钮,比 Word 还简单 |
| 🔥 GPU 加速 | 自动识别我的 5060Ti,一键开启,不需要设置 CUDA_VISIBLE_DEVICES |
| 🌐 本地 API | 提供和 OpenAI 一模一样的 API,我的代码无缝切换 |
| 📁 内置模型下载器 | 在软件里搜索模型,点一下就能下载,不用去网页翻 |
安装步骤(真的只需三步,骗你是小狗)
第一步:下载 LM Studio
访问官网:lmstudio.ai/
点击下载 Windows 版本,安装包约 200MB,比你下个游戏补丁还快。
安装过程就是一路 "下一步 → 下一步 → 我同意 → 完成",没有任何坑。
第二步:下载模型(两个方法,推荐第二个)
方法一:LM Studio 内置下载器(适合网络好的)
- 打开 LM Studio,点击左侧「Search」图标
- 搜索
Qwen3.6-35B - 在结果里找到
Q4_K_M版本(记得看文件大小,约 16GB) - 点击 Download,然后去泡杯咖啡,等它下完
方法二:ModelScope 下载(适合国内,速度起飞)
我强烈推荐这个,因为 HuggingFace 在国内慢得像蜗牛爬:
bash
pip install modelscope
modelscope download --model LLM-Research/Qwen3.6-35B-A3B-GGUF --local_dir ./models下载完大概 16GB,花了我一顿外卖的时间(约 20 分钟)。
然后把下载的 .gguf 文件拖到 LM Studio 的模型文件夹里(或者直接拖进软件窗口,它也认)。
第三步:加载模型,开始对话
- 在 LM Studio 中间区域点击加载,或直接把
.gguf文件拖进去 - 等待约 1-2 分钟(它在把模型装进显存)
- 看到底部显示
Qwen3.6-35B-A3B-Q4_K_M - 15.8GB/16.0GB,说明成功了 - 在下方输入框打字,按回车,它就开始回答了
快捷键(记住两个就够了):
Ctrl + Enter:发送消息Ctrl + Shift + Delete:清空对话(假装什么都没发生过)
本地 API 服务:让我的代码也能调戏它
LM Studio 自带一个兼容 OpenAI 的 API 服务器,这意味着我可以用任何调用 OpenAI 的代码,无缝切换成本地模型。
开启 API 服务器(一键操作)
- 点击左侧「Server」图标(像个插头)
- 点击「Start Server」按钮
- 看到地址:
http://localhost:1234/v1
就这?就这。不需要配置环境变量,不需要 uvicorn,一键搞定。
Python 调用(和调用 GPT 一毛一样)
python
from openai import OpenAI
# 把 base_url 改成 LM Studio 的地址,其他完全不变
client = OpenAI(
base_url="http://localhost:1234/v1",
api_key="lm-studio" # 随便填,它不验证
)
response = client.chat.completions.create(
model="Qwen3.6-35B-A3B", # 模型名字随便写,它会自动用当前加载的
messages=[
{"role": "system", "content": "你是一个有帮助的助手"},
{"role": "user", "content": "用一句话解释什么是 MoE 架构"}
]
)
print(response.choices[0].message.content)
# 输出:MoE架构就像一个专家团队,每次只让最擅长该任务的小组干活,省时省力。curl 调用(给不喜欢 Python 的人)
bash
curl http://localhost:1234/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen3.6-35B-A3B",
"messages": [{"role": "user", "content": "你好,你是谁?"}]
}'就这样,我的本地 AI 同事正式上岗了。
Docker 部署 Open WebUI(给模型穿件漂亮衣服)
LM Studio 自带的聊天界面比较简陋,像个毛坯房。
如果你想要一个更高级的 Web 界面,可以安装 Open WebUI,它长得像 ChatGPT,功能也更全。
第一步:安装 Docker Desktop
去 www.docker.com/products/do... 下载 Docker Desktop,安装后重启电脑。
第二步:启动 LM Studio 的 API 服务器
(跟上面一样,点一下「Start Server」,保持运行)
第三步:用 Docker 启动 Open WebUI
在命令行执行:
bash
docker run -d \
--name open-webui \
-p 3000:8080 \
-v open-webui:/app/backend/data \
-e OPENAI_API_BASE_URL=http://host.docker.internal:1234/v1 \
-e OPENAI_API_KEY=lm-studio \
--restart unless-stopped \
ghcr.io/open-webui/open-webui:main几个关键点(免得你踩坑):
host.docker.internal是 Docker 里访问宿主机的固定写法,不要改成localhost- 端口
1234是 LM Studio 的 API 端口 - 端口
3000是 Open WebUI 的访问端口
第四步:访问并使用
- 打开浏览器访问:http://localhost:3000
- 首次打开要注册一个账号(本地存储,随便填,密码别太复杂,你自己记住就行)
- 登录后,在设置里确认它连接的是 LM Studio
Open WebUI 比 LM Studio 自带界面强在哪?
| 功能 | 说明 | 我的使用场景 |
|---|---|---|
| 🤖 多模型切换 | 一个界面切换不同模型 | 同时加载 Qwen 和 Llama,对比回答 |
| 📝 对话历史 | 自动保存,可搜索 | 上周问的问题这周还能翻出来 |
| 📁 文件上传 | 上传 PDF/Word 让 AI 分析 | 把公司文档扔进去让它总结(反正数据不出本地) |
| 🧩 插件系统 | 装各种扩展 | 支持联网搜索、代码执行等 |
| 🌐 主题切换 | 深色/浅色 | 晚上调深色,保护眼睛 |
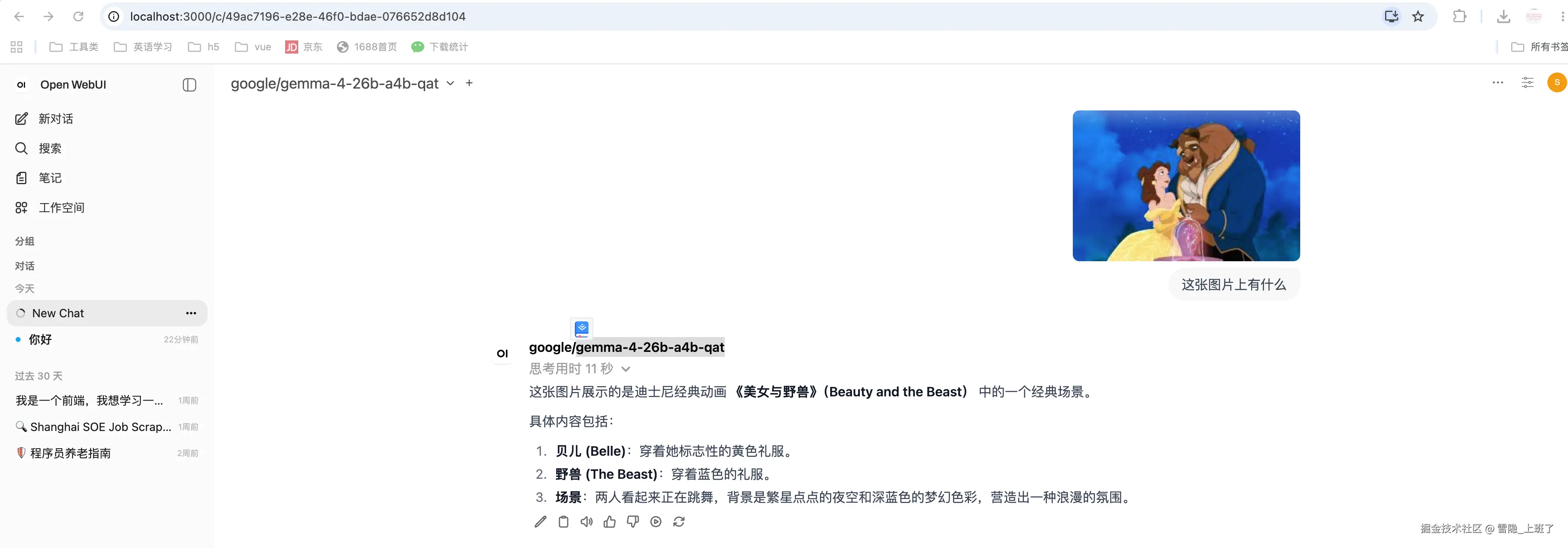
又比如之前用的带视觉的gemma-4-26b-a4b-qat,如果用LM sudio,根本没办法上传图片,但是openwebui可以
Docker 常用命令(贴在这里备用)
bash
# 看看容器有没有在跑
docker ps
# 出问题了看日志
docker logs -f open-webui
# 停掉它
docker stop open-webui
# 删掉重来(配置还在,因为挂了 volume)
docker rm open-webui
# 重新启动
docker start open-webui性能优化:我的 5060Ti 16G 如何满血运行
推荐配置(在 LM Studio 右侧的「Model Settings」里调)
json
{
"context_length": 8192, // 日常 8K 够用,别开 262K,会爆显存
"gpu_layers": 35, // 所有层都扔 GPU,速度拉满
"threads": 8, // 我的 CPU 有 8 个核,全用上
"batch_size": 512 // 默认值,不用动
}三招保显存(血泪经验)
-
别把上下文拉满
Qwen3.6 支持 262K token,但那是给多卡土豪用的。16GB 显存老老实实开 8K-16K,稳如老狗。
-
关掉其他占显存的程序
浏览器、IDE、Chrome 都是显存杀手。我每次跑模型前都关掉多余的 Chrome 标签页,省出 1-2GB。
-
如果还是爆显存,选更低的量化
Q4_K_M 是 16GB,如果还爆,试试 Q3_K_M(约 12GB),质量略降但流畅度提升。
我能拿它干什么?(不止是聊天)
1. 编程助手(我最常用的)
python
# 问它写代码,它从不抱怨需求变更
response = client.chat.completions.create(
model="Qwen3.6-35B-A3B",
messages=[
{"role": "user", "content": "用 Python 写一个快速排序,要加注释"}
]
)2. 私有文档问答(公司代码不外传)
把公司内部文档喂给它,问啥答啥,数据永远不出本地服务器。
3. 接入 LangChain(玩出花)
python
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(
base_url="http://localhost:1234/v1",
model="Qwen3.6-35B-A3B"
)
# 然后就和调用 GPT 完全一样了,但免费、私有、不限量4. 敏感数据处理(医疗/法律/财务)
客户数据不能上传云端?本地模型完美解决。
我有个做医疗信息化的朋友,就用这套方案处理病历摘要,合规又安全。
常见问题(都是我自己踩过的坑)
Q1: 显存爆了,怎么办?
- 换 Q3_K_M 版本(约 12GB)
- 把
context_length从 8192 降到 4096 - 关闭所有 Chromium 浏览器(它们吃显存像喝水)
Q2: 回答速度慢得像蜗牛?
- 检查 LM Studio 底部是不是显示
GPU Layers: 0/35,如果是,说明没用 GPU - 去「Settings」里确认 GPU 被勾选
- 把
threads调高(等于你 CPU 的核心数)
Q3: Open WebUI 连不上 LM Studio?
- 确认 LM Studio 的「Server」是绿色(Running)状态
- 确认端口 1234 没有被其他程序占用
- Docker 容器里用
host.docker.internal,不要用localhost
总结:我的 5060Ti 已经成了全能打工人
今天我们用 LM Studio + Qwen3.6-35B-A3B,给 5060Ti 又解锁了一个新技能:
✅ 本地部署零门槛 :LM Studio 双击即用,连我这种懒人都能跑起来
✅ MoE 架构省显存 :350 亿参数只激活 30 亿,16GB 刚好跑满
✅ 兼容 OpenAI API :代码零改动,从云端切换成本地
✅ Open WebUI 加持 :界面好看,功能强大,还能传文件
✅ 数据私有化:敏感信息不出本地,合规又安心
现在我的 5060Ti 已经会画画、会配音、会聊天,下次是不是该让它学会写代码了?
哦等等,它现在就在帮我写代码......那我是不是要失业了?🤔
本章代码拿走不谢
下期预告 :也许我会用 5060Ti 跑一下视频生成,或者搞个多模态模型,让它"看图说话"?
反正显卡已经买了,钱也花了,必须榨干它的每一滴算力!💪
参考链接(真的有用):
- LM Studio 官网:lmstudio.ai/
- Qwen3.6-35B-A3B 模型:huggingface.co/Qwen/Qwen3....
- ModelScope 模型:www.modelscope.cn/models/LLM-...
最后一句扎心忠告 :
本地模型再强,也写不出"我爱你"这种句子------它只会给你一首情诗,然后问你"要不要再优化一下"。
所以,别怕失业,你还是比 AI 多了一颗会心动的心脏。❤️