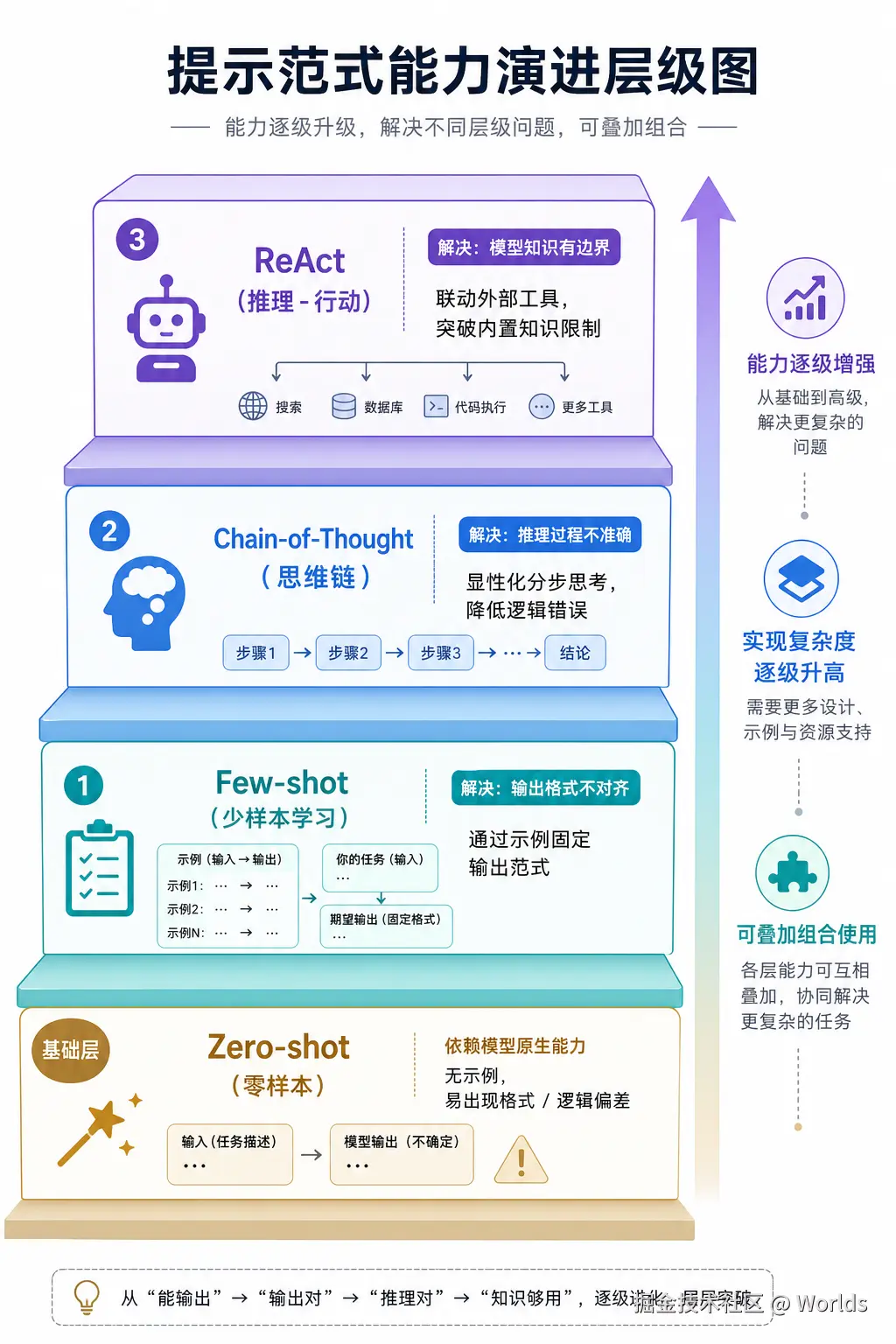
一、前置基础:三种范式的演进背景
在讲解具体方法前,先明确两个基础认知,理解这三类技术的诞生逻辑:
- 零样本(Zero-shot):大模型的原生提问方式直接向模型提出任务要求、不提供任何示例,就是零样本提问。它依赖模型训练阶段学到的通用能力,适合简单日常对话,但在格式要求严格、逻辑复杂、需要外部信息的场景下,容易出现格式跑偏、逻辑跳步、事实幻觉等问题。
- 三类范式的能力演进路径Few-shot、Chain-of-Thought、ReAct 是提示工程领域三个经典的、逐级升级的解决方案,对应三个不同的问题层级:
- 第一层:解决「输出不对齐」的问题 → Few-shot(给例子学格式)
- 第二层:解决「推理不准确」的问题 → Chain-of-Thought(显式写思考步骤)
- 第三层:解决「知识有边界」的问题 → ReAct(调用外部工具补信息)三者并非互斥关系,而是可以组合叠加,共同支撑从简单到复杂的各类大语言模型应用。
二、核心范式逐一拆解
2.1 Few-shot(少样本学习)
定义
Few-shot(少样本学习)是指在提示词中提供少量「输入 - 输出」的完整示例,让模型从范例中自主学习任务规则、输出格式与边界标准,再执行真实任务的提示方法。提供 1 个示例称为 1-shot,3 个称为 3-shot,以此类推;与之相对、不提供任何示例的方式称为 Zero-shot(零样本)。
底层原理
该技术的核心基础是大模型的 ** 上下文学习(In-Context Learning)** 能力:无需修改模型参数、无需额外训练,仅通过上下文内的范例,模型就能捕捉到任务的模式特征,对齐输出标准。相比纯文字描述任务要求,具象示例的对齐精度更高,能显著降低模型 "自由发挥" 带来的偏差。
具象示例
以中英翻译任务为例:
arduino
请按照示例风格完成翻译任务。
例1:英文 "Hello" → 中文 "你好"
例2:英文 "Thank you" → 中文 "谢谢"
例3:英文 "Good morning" → 中文 "早上好"
实际任务:英文 "How are you?" → 中文 "模型会从 3 组示例中学习到「英文单词→对应中文翻译」的输出格式,严格按照相同结构输出结果。
核心特点
- 通常使用 1~5 个示例即可,边际收益随数量增加逐步递减
- 示例质量优先于数量,需覆盖任务的主要变体与边界情况
- 相比零样本,能显著降低格式错误、风格偏离的概率
- 成本是会消耗更多的上下文 Token,占用窗口空间
适用场景
格式转换、文本分类、风格模仿、结构化数据提取、标准化输出等对输出形式有明确要求的任务。
2.2 Chain-of-Thought (CoT / 思维链)
定义
Chain-of-Thought(简称 CoT,中文常称思维链)是一种引导模型「先逐步推理,再输出结论」的提示技术。它要求模型在输出最终答案前,显式写出完整的中间推理步骤,模拟人类 "一步步想问题" 的思考过程。
底层原理
大模型直接输出答案时,容易出现逻辑跳步、计算错误、因果倒置等问题,本质是隐性思考过程缺乏约束。思维链通过强制输出中间步骤,把模型的隐性推理显性化,每一步推导都被上下文记录和约束,大幅减少幻觉和逻辑跳跃,显著提升多步骤复杂任务的准确率。
核心变体
- Zero-shot CoT(零样本思维链) :无需提供示例,只需在问题末尾补充一句「请逐步思考」或「Let's think step by step」,即可触发模型的分步推理,是成本最低的 CoT 用法。
- Few-shot CoT(少样本思维链) :提供带完整推理链的示例,引导模型模仿推理逻辑,效果优于零样本思维链,适合高复杂度任务。
- Self-Consistency(自一致性策略) :让模型独立生成多条推理链,最终投票选出出现次数最多的答案,进一步降低单条推理路径出错的概率。
具象示例
以经典的鸡兔同笼问题为例,对比普通提示与 CoT 提示的差异:
-
普通提示(易出错):
一个农场有鸡和兔共35只,脚共94只。鸡有几只?
-
CoT 提示(更准确):
一个农场有鸡和兔共35只,脚共94只。请逐步思考并给出答案。
模型输出的推理过程:
设鸡有 x 只,兔有 y 只。
- 总数量:x + y = 35
- 总脚数:2x + 4y = 94
- 由第一式得 y = 35 - x
- 代入第二式:2x + 4 (35-x) = 94
- 计算得:2x + 140 - 4x = 94 → -2x = -46 → x = 23答案:鸡有 23 只。
适用场景
数学计算、逻辑推理、多步骤决策、代码调试、方案拆解等需要严谨中间过程的复杂任务。
2.3 ReAct(Reasoning + Acting / 推理 - 行动范式)
定义
ReAct 是将「推理思考(Reasoning)」与「外部行动(Acting)」交替执行的提示框架,让模型遵循「思考→行动→观察结果→继续思考」的循环模式,能够主动调用外部工具、与环境交互,突破大模型自身的知识与能力边界。它是当前构建 AI 智能体(AI Agent)的核心理论基础。
底层原理
纯文本推理(如 CoT)完全依赖模型训练时的内置知识,无法获取实时信息,也容易出现事实幻觉。ReAct 把完整的问题解决过程拆分为可迭代的三步循环:通过思考明确下一步目标,通过行动调用外部工具获取真实信息,通过观察拿到结果后再推进推理,既保留了大模型的逻辑推理能力,又引入了外部世界的实时、准确数据,实现了 "认知" 与 "行动" 的闭环。
标准工作流程
- 思考(Thought) :分析当前状态与已有信息,判断下一步需要做什么
- 行动(Action) :执行一个具体操作,如搜索、调用 API、运行代码、查询数据库
- 观察(Observation) :获取行动返回的结果,作为下一轮思考的输入循环往复,直到模型判断信息充足,输出最终答案。
具象示例
以查询 2024 年诺贝尔物理学奖得主信息为例:
yaml
用户:2024年诺贝尔物理学奖得主是谁?他们获得过哪些其他奖项?
Thought 1: 用户需要知道2024年诺贝尔物理学奖得主,这是实时信息,我需要先通过搜索获取。
Action 1: Search["2024 诺贝尔物理学奖 得主"]
Observation 1: John J. Hopfield 和 Geoffrey E. Hinton 获得2024年诺贝尔物理学奖。
Thought 2: 已经得到两位得主的姓名,接下来需要分别查询两人获得的其他奖项,先查Hopfield。
Action 2: Search["John J. Hopfield 获得奖项"]
Observation 2: John J. Hopfield 曾获费米奖、狄拉克奖等多项学术荣誉。
Thought 3: 继续查询Hinton的其他奖项信息。
Action 3: Search["Geoffrey Hinton 获得奖项"]
Observation 3: Geoffrey Hinton 曾获2018年图灵奖、神经网络先驱奖等。
Thought 4: 已收集到全部所需信息,可以整理最终答案。
Final Answer: 2024年诺贝尔物理学奖得主是John J. Hopfield与Geoffrey E. Hinton......核心特点
- 模型不再局限于自身知识,可通过工具获取实时、准确的外部信息
- 每一步思考与行动都有明确记录,天然具备可解释性与可追溯性
- 与 CoT 的核心区别:CoT 是纯内部文本推理,ReAct 是推理 + 外部交互的闭环
适用场景
实时信息查询(天气、股价、新闻)、多工具协同任务、复杂调研分析、自动化工作流、各类 AI 智能体开发。
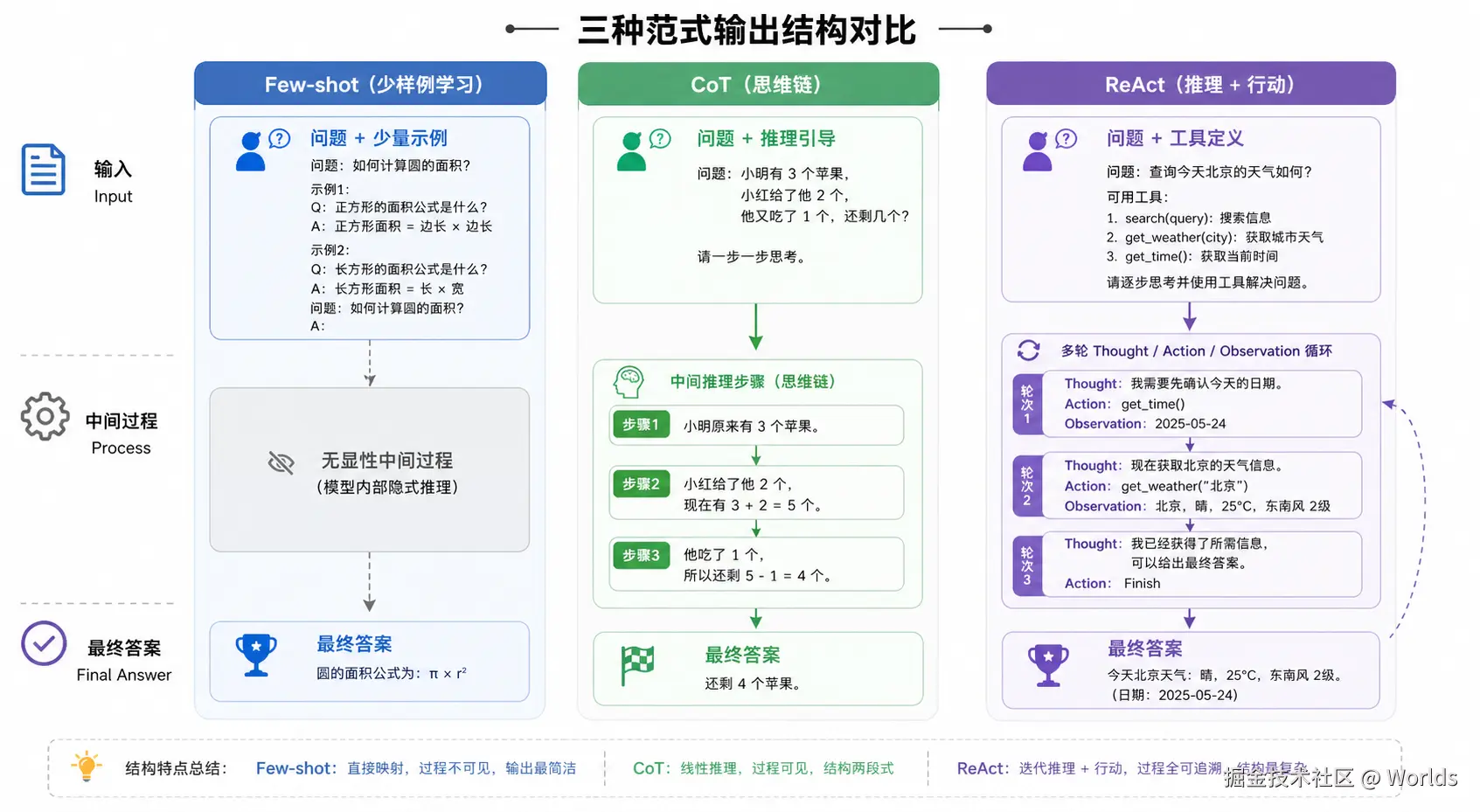
三、三者横向对比
| 对比维度 | Few-shot(少样本学习) | Chain-of-Thought(思维链) | ReAct(推理 - 行动范式) |
|---|---|---|---|
| 核心解决的问题 | 输出格式与风格对齐 | 提升内部推理准确率 | 突破知识边界,实现外部交互 |
| 是否需要示例 | 必须提供示例 | 可选(零样本 CoT 无需示例) | 通常需要定义工具格式与示例 |
| 输出形式 | 直接输出最终结果 | 中间推理步骤 + 最终答案 | Thought→Action→Observation 循环 + 最终答案 |
| 外部交互能力 | 无 | 无 | 支持搜索、API、数据库、代码执行等 |
| 可解释性 | 低 | 中高(可查看完整推理链) | 高(每一步思考与行动都可追溯) |
| 实现复杂度 | 低 | 中 | 高 |
| 典型应用场景 | 文本分类、格式转换、风格仿写 | 数学题、逻辑推理、代码调试 | AI 智能体、自动化任务、实时信息查询 |
四、常见认知误区
- 误区一:示例数量越多,效果越好纠正:Few-shot 的效果随示例数量上升的边际收益快速递减,通常 2~3 个高质量示例即可,超过 5 个后提升非常有限,反而会大量占用上下文窗口,甚至引入冗余噪声。示例的质量(是否覆盖边界场景、格式是否标准)远比数量重要。
- 误区二:思维链只能用来解数学题纠正:思维链的核心是「显性化分步思考」,适用于所有多步骤任务。除了数学计算,文案拆解、故障排查、方案设计、法律分析等场景,都可以通过分步思考提升逻辑完整性和结果准确率。
- 误区三:ReAct 就是调用工具纠正:调用工具只是 ReAct 中的「行动」环节,其核心是「推理 - 行动 - 观察」的闭环逻辑。如果只是按固定脚本调用工具,没有自主思考与决策过程,不属于 ReAct 范式。思考环节的存在,让模型能自主判断下一步动作、动态调整路径,这才是智能体的核心。
- 误区四:三种范式是互斥的,只能选一种使用纠正:三者可以灵活组合使用。例如用 Few-shot + CoT 组成少样本思维链,兼顾格式对齐与推理准确性;在 ReAct 的思考环节中嵌入 CoT 逻辑,让每一步的推理更严谨。组合使用是复杂大语言模型应用的常态。
五、实操建议
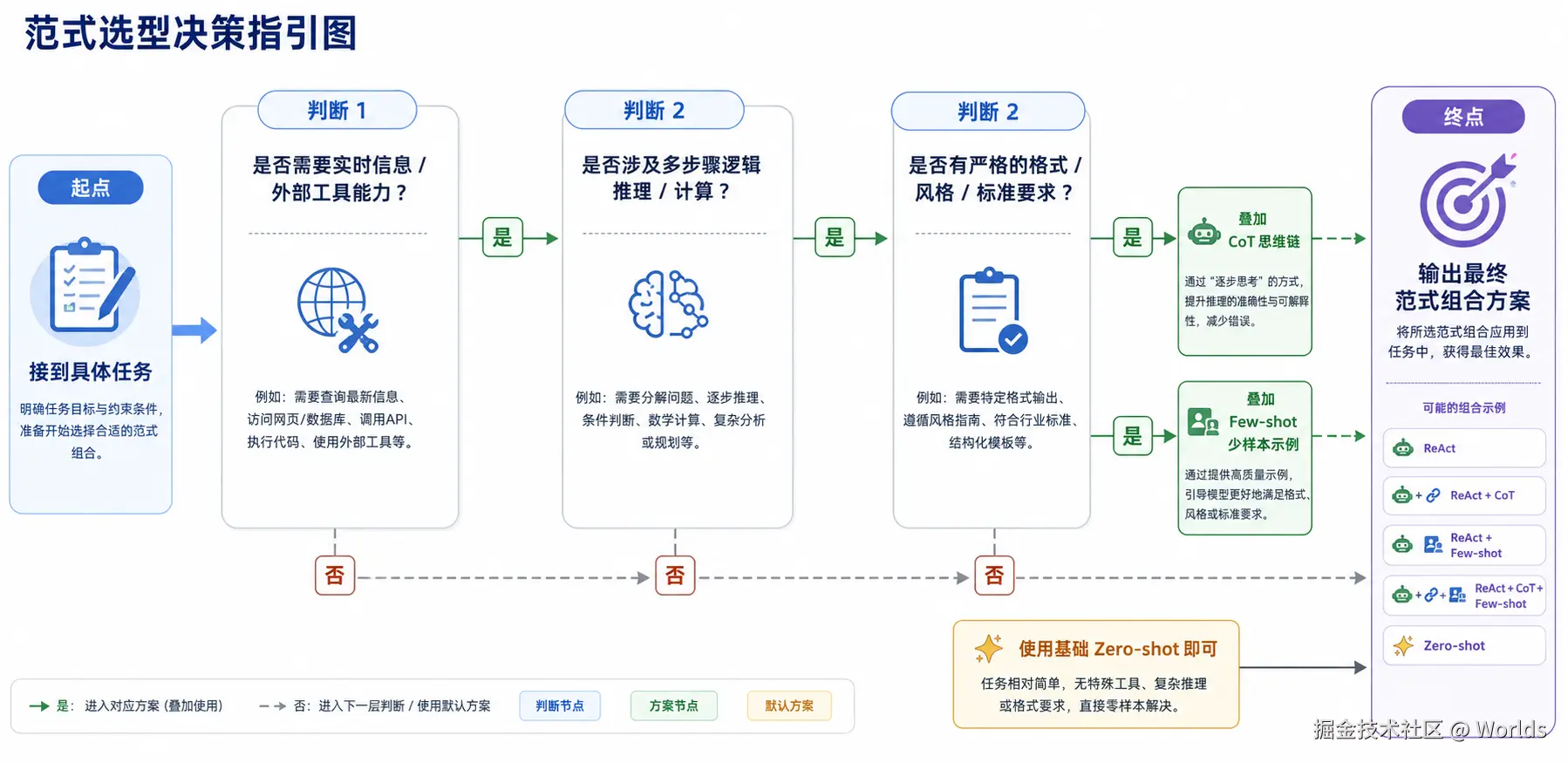
- 选型原则:从简到繁,按需叠加优先从最简单的方案开始尝试:简单格式对齐用 Few-shot,逻辑不准加 CoT,需要外部信息再上 ReAct。避免一开始就过度设计复杂方案,增加调试成本。
- Few-shot 优化要点
- 示例的输出格式、长度、风格要和真实任务的预期严格一致
- 优先覆盖边界场景、异常情况、易错点,而非重复相似示例
- 示例数量控制在 2~3 个,优先提升质量而非数量
- CoT 优化要点
- 简单任务直接用 Zero-shot CoT,在问题末尾追加「请逐步思考」即可
- 高要求任务用 Few-shot CoT,确保示例的推理步骤严谨、无逻辑错误
- 高容错成本场景可搭配 Self-Consistency,用多路径投票提升准确率
- ReAct 优化要点
- 先明确定义每个工具的输入、输出格式与使用场景
- 提供 1~2 轮完整的思考 - 行动 - 观察示例,帮助模型对齐循环格式
- 设置最大循环步数,避免模型陷入无效思考的死循环
- 组合使用建议三类范式叠加时,遵循「格式→推理→行动」的顺序优化:先用 Few-shot 固定输出格式,再用 CoT 提升推理质量,最后用 ReAct 补充外部能力,逐层验证效果后再叠加下一层。