摘要
无人机(UAV)图像中的目标检测已广泛应用于各种场景。然而,无人机航拍图像对检测算法提出了独特的挑战,包括复杂的背景、显著的尺度变化以及密集分布的小目标。现有方法主要依赖单域建模或采用全局同构的频率调制策略,无法充分满足不同目标对多样化上下文信息的需求。为了解决这一问题,我们提出了SFS-DETR,这是一种用于无人机航拍图像的高效检测框架,它通过多域学习和自适应选择机制重新思考上下文建模。作为主干网络的选择性空间-频率网络(Selective Spatial-Frequency Network),通过联合空间和频率域选择,自适应地整合局部细节和全局语义特征,从而有效地对航拍场景中不同目标的多变上下文进行建模。同时,我们设计了语义对齐融合(Semantic-Aligned Fusion),以有效缓解多尺度特征之间的语义未对齐问题,防止小目标特征在融合过程中被稀释。最后,我们进一步引入了多分支特征增强器(Multi-branch Feature Enhancer),通过并行增强策略提高了小目标特征与背景之间的可区分性。在VisDrone、UAVDT、CODrone、UAVVaste和SIMD等基准数据集上进行的大量实验,证明了我们方法的卓越性能和泛化能力。
1. 引言 (Introduction)
近年来,无人机(UAV)图像中的目标检测已被广泛应用于各个领域16, 29,包括航拍监控、灾难救援和交通管理。然而,如图1所示,无人机捕获的图像通常表现出复杂的背景、显著的尺度变化以及密集的小目标分布11。在这种情况下,仅依赖局部特征会阻碍精确的定位,而利用周围环境的上下文信息对于提高目标识别和定位精度至关重要26。
最近,出现了一些专门针对无人机图像的方法。然而,如图1所示,传统方法23, 32在特征提取过程中主要依赖空间域建模,并通过堆叠卷积层来实现信息传递,这从根本上限制了它们整合局部细节与全局语义的能力。相比之下,通过傅里叶方法变换的频率域编码了全局结构信息。尽管最近的进展(如UAV-DETR 37)引入了频率域处理以捕获全局依赖关系,但它们采用了全局同构的调制策略。具体而言,在将特征变换到频率域后,它们使用单一的一组参数对所有频率域位置进行相同的调制。这种与位置无关的处理方式缺乏对关键频率分量的自适应选择,并将频率响应与局部空间上下文解耦。因此,它们无法自适应地满足不同目标之间不同的上下文需求。例如,密集的小目标需要局部细节和直接的周围环境,而较大的目标或背景区域则主要依赖整体结构语义13。
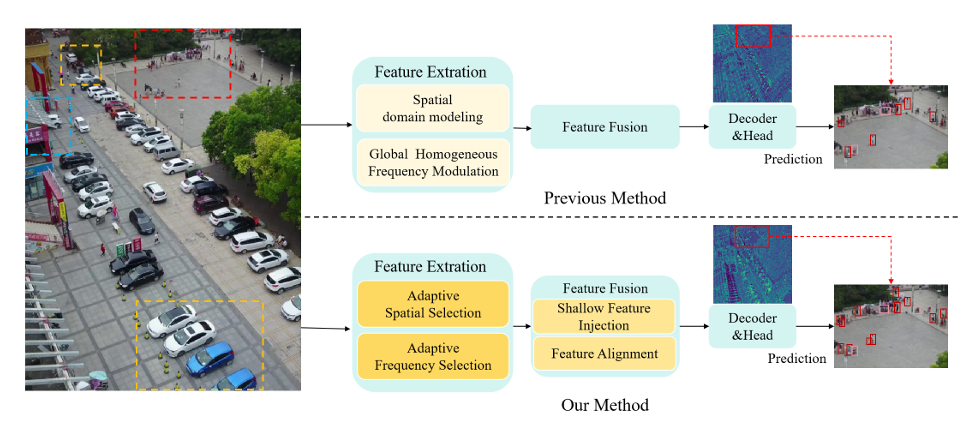
图1. 以前的方法要么仅依赖空间域建模,要么采用全局同构的频率调制。我们的方法引入了自适应空间-频率选择,以针对不同的目标建模上下文。此外,我们注入了来自骨干网络的浅层特征并结合了特征对齐,缓解了特征融合过程中小目标特征的稀释。
此外,无人机图像中的小目标在特征图中占据极其稀疏的像素区域,因此需要有效的多尺度特征融合来增强其表征能力5。然而,多尺度特征之间通常存在显著的语义鸿沟:浅层特征保留了细粒度的细节但缺乏高级语义信息,而深层特征捕获了丰富的全局上下文但牺牲了空间精度15, 17。这种未对齐(misalignment)不仅阻碍了互补信息的有效整合,还导致弱小的目标特征在融合过程中被稀释。以前的方法未能充分解决这种未对齐问题。
为了解决这些局限性,本文提出了SFS-DETR,这是一种用于无人机目标检测的高效基于Transformer的框架。如图1所示,SFS-DETR引入了在空间和频率域中联合运行的新型自适应选择机制。
具体而言,在空间域中,利用多个并行的深度卷积(depthwise convolutions)提取密集的纹理特征,随后进行通道选择以自适应地整合这些特征。在频率域中,特征被分解为多组分量并分别进行调制,并通过感知位置的选择权重进行处理,这些权重根据局部内容动态地重新校准频率响应。这种感知位置的频率选择机制能够精确适应航拍场景中不同目标的特征。此外,在特征融合过程中,我们整合了从主干网络提取的浅层特征。同时,我们采用语义引导的渐进对齐机制来缓解多尺度特征之间的未对齐问题,并集成自适应通道选择以强调关键信息,从而减轻融合过程中的特征稀释。最后,通过并行处理策略进一步增强多尺度融合特征,以提高小目标特征与背景区域之间的可区分性。我们的主要贡献总结如下:
- 我们引入了选择性空间-频率网络主干(Selective Spatial-Frequency Network Backbone),它结合了新颖的空间-频率选择机制,为不同的航拍目标提供自适应的上下文信息。
- 我们设计了语义对齐融合(Semantic-Aligned Fusion),通过语义引导的渐进对齐和自适应通道选择,防止关键的小目标特征在融合过程中被稀释。
- 我们提出了多分支特征增强器(Multi-branch Feature Enhancer),它采用并行多分支处理来提高小目标特征与背景区域之间的区分度。
2. 相关工作 (Related Work)
2.1. 无人机图像中的目标检测
与自然场景目标检测相比,无人机图像检测面临更大的挑战。近年来,已经开发了专门针对无人机图像的方法。FBRT-YOLO31通过在特征提取过程中将空间细节与深层语义特征对齐来增强小目标检测。基于RT-DETR38,OWRT-DETR 20结合了跨尺度特征交互和局部感知增强机制,在航拍场景中实现了显著的精度提升。UAV-DETR专注于高频特征,通过空间-频率增强和多尺度融合提高了小目标的检测性能。然而,现有方法在特征提取过程中主要依赖单域建模或采用全局同构的频率调制,无法充分满足不同目标的多样化上下文需求。在本文中,我们提出了SFS-DETR,这是一种利用多域学习和自适应选择机制来解决这些局限性的高效航拍目标检测框架。大量的实验结果证明了我们提出方法的优越性。
2.2. 航拍图像的特征提取主干
近年来,为了解决航拍图像中的挑战,提出了一些专门的特征提取主干。LSKNet13采用大核分解和空间选择的核选择机制,动态适应不同上下文需求的感受野。PKINet1利用Inception风格的并行多核卷积设计来增强尺度变化的鲁棒性,并引入上下文锚点注意力机制来捕获长距离上下文信息。StripNet34专为高长宽比的航拍目标设计,通过序列化的水平和垂直条带卷积实现了正交大条带卷积结构,从而捕获几何特征。然而,这些方法存在明显的局限性。LSKNet由于大核卷积而受到背景噪声的干扰。PKINet由于多重大核卷积结构而表现出高计算复杂度和特征冗余。StripNet虽然对高长宽比目标有效,但在建模不同目标几何形状和捕获全局上下文依赖关系方面能力有限。在本文中,我们提出了SSFNet,通过创新的空间和频率域选择来自适应地建模航拍图像的上下文信息。
2.3. 多尺度特征融合
无人机图像中的小目标在特征图中占据极小的像素区域,需要有效整合多尺度层次特征以提升其表征能力。然而,跨尺度的显著语义鸿沟和空间未对齐会降低检测性能,特别是对于需要精确定位的小目标。CoF-Net35自适应地学习像素级变换,以建立多尺度特征之间的精确对应关系。AlignYOLO12采用可学习的自适应插值来缓解特征融合过程中的层级间未对齐。CAF2ENet5通过交叉注意力机制解决了上采样融合过程中固有的空间错位问题。在这项工作中,我们提出了语义对齐融合(Semantic-Aligned Fusion)来自适应地融合多尺度特征,从而保留对鲁棒的小目标检测至关重要的更丰富的小目标特征。
3. 方法 (Method)
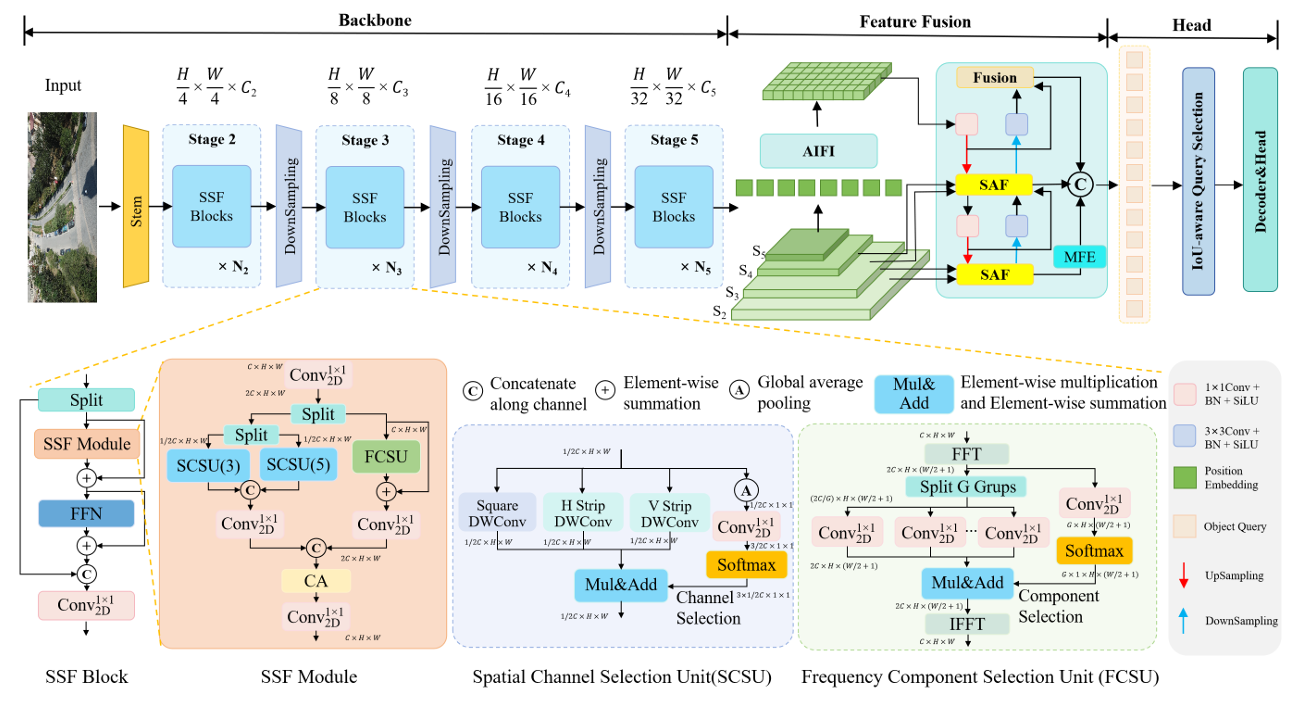
图2. SFS-DETR概览。主干网络选择性空间-频率网络(SSFNet)由多个阶段组成,用于提取和建模自适应空间-频率上下文特征;语义对齐融合(SAF)缓解了融合过程中的多尺度特征未对齐和小目标特征稀释问题;多分支特征增强器(MFE)进一步提高了小目标特征与背景区域之间的可区分性,支持精确的无人机航拍目标检测。
表1. SSFNet主干的变体。 CiC_iCi:特征通道数;DiD_iDi:SSF块的数量;i=2,3,4,5i= 2, 3, 4, 5i=2,3,4,5。
| 模型 | CiC_iCi | DiD_iDi | 参数量(M) | FLOPs |
|---|---|---|---|---|
| SSFNet-S | 128, 256, 384, 384 | 1, 1, 1, 3 | 9.9 | 30.9G |
| SSFNet-M | 128, 256, 384, 512 | 2, 2, 2, 3 | 16.6 | 49.8G |
如图2所示,基于RT-DETR框架,我们的SFS-DETR结合了三个核心改进,即选择性空间-频率网络(SSFNet)、语义对齐融合(SAF)和多分支特征增强器(MFE)。此外,为了进一步增强小目标检测性能并加速模型收敛,我们引入了Inner-MPDIoU损失函数,它协同结合了Inner-IoU 36和MPDIoU 19的优势。
3.1. 选择性空间-频率网络 (Selective Spatial-Frequency Network)
传统的特征提取网络通常依赖空间域建模,难以充分满足不同目标多样化的上下文需求,特别是在复杂的航拍场景中。为了解决这一根本局限性,我们提出了主要由如图2所示的基本块组成的SSFNet。
SSF Block(SSF块)采用跨阶段部分(cross-stage partial)策略。输入特征被平均分为两个子集:一个被送入SSF Module(SSF模块)进行特征变换,另一个作为恒等分支。在SSF模块内,输入特征 x∈RC×H×Wx \in \mathbb{R}^{C \times H \times W}x∈RC×H×W 经过 1×11 \times 11×1 卷积,并分为两个子特征 x1∈RC×H×Wx_1 \in \mathbb{R}^{C \times H \times W}x1∈RC×H×W 和 x2∈RC×H×Wx_2 \in \mathbb{R}^{C \times H \times W}x2∈RC×H×W,分别用于后续的空间域和频率域处理。
空间域通道选择 (Spatial-Domain Channel Selection) 。在空间分支中,x1x_1x1 沿通道维度被分为 x11x_{11}x11 和 x12x_{12}x12,然后分别送入具有不同配置的两个空间通道选择单元(SCSU)。在SCSU内,特征 x11x_{11}x11 由三个并行的深度卷积处理,使用的核大小分别为 k×kk \times kk×k (k=3k=3k=3)、1×(3k+2)1 \times (3k+2)1×(3k+2) 和 (3k+2)×1(3k+2) \times 1(3k+2)×1,分别提取局部、水平和垂直特征。为了生成通道选择权重,输入特征 x11x_{11}x11 首先经过全局平均池化(GAP),将空间信息聚合为通道级统计量。随后,通道维度被扩展并调整为 (3×12C×1×1)(3 \times \frac{1}{2}C \times 1 \times 1)(3×21C×1×1) 的形状。最后,沿第一维度执行softmax操作,产生反映每个卷积分支对不同通道重要性的权重。
WSK=Softmax(View(Conv1×1C/2→3C/2(GAP(x11))))(1)W_{SK} = \text{Softmax}(\text{View}(\text{Conv}{1 \times 1}^{C/2 \to 3C/2}(\text{GAP}(x{11})))) \quad (1)WSK=Softmax(View(Conv1×1C/2→3C/2(GAP(x11))))(1)
然后,通过通道选择权重对提取的多尺度特征进行自适应增强和抑制。
xlocal1=∑iWSK(i)⊗DWConvi(x11)(2)x_{\text{local}}^1 = \sum_i W_{SK}^{(i)} \otimes \text{DWConv}i(x{11}) \quad (2)xlocal1=i∑WSK(i)⊗DWConvi(x11)(2)
其中 DWConvi\text{DWConv}iDWConvi 表示三个深度卷积,WSK(i)∈R12C×1×1W{SK}^{(i)} \in \mathbb{R}^{\frac{1}{2}C \times 1 \times 1}WSK(i)∈R21C×1×1 表示每个通道学习到的选择权重,⊗\otimes⊗ 表示逐元素乘法。
特征 x12x_{12}x12 被送入配置了更大卷积核(k=5k=5k=5)的SCSU进行处理。两个SCSU的输出沿通道维度拼接,随后经过 1×11 \times 11×1 卷积,产生综合的多尺度局部特征 xlocalx_{\text{local}}xlocal。
频率域感知位置的分量选择 (Frequency-Domain Position-aware Component Selection) 。为了捕获不同目标的关键长距离全局依赖关系,我们引入了在频率域中运行的频率分量选择单元(FCSU)。给定特征 x2∈RC×H×Wx_2 \in \mathbb{R}^{C \times H \times W}x2∈RC×H×W,FCSU首先应用快速傅里叶变换(FFT)将其映射到频率域。在分别提取其实部和虚部并沿通道维度拼接这些分量后,构建频率域特征 xF∈R2C×H×(W/2+1)x_F \in \mathbb{R}^{2C \times H \times (W/2+1)}xF∈R2C×H×(W/2+1)。与以前方法中对所有频率分量进行一致调制的策略不同,在本文中,xFx_FxF 沿通道维度被划分为 GGG 组 xF(i=1,...,G)∈R2C/G×H×(W/2+1)x_F^{(i=1,\dots,G)} \in \mathbb{R}^{2C/G \times H \times (W/2+1)}xF(i=1,...,G)∈R2C/G×H×(W/2+1),其中每个划分通过 1×11 \times 11×1 卷积独立调制和适应,以捕获特定任务的频率模式,从而涵盖更多样化的频率域模式,以适应航拍场景中不同目标的不同上下文需求。
此外,为了生成感知位置的选择权重,原始频率域特征 xFx_FxF 首先通过 1×11 \times 11×1 卷积进行维度压缩和适应,以聚合通道级频率信息(形状为 G×H×(W/2+1)G \times H \times (W/2+1)G×H×(W/2+1)),随后沿通道维度执行softmax操作,以编码不同频率分量的空间重要性。
WFC=Softmax(Conv1×12C→G(xF))(3)W_{FC} = \text{Softmax}(\text{Conv}_{1 \times 1}^{2C \to G}(x_F)) \quad (3)WFC=Softmax(Conv1×12C→G(xF))(3)
然后,这些 GGG 组独立调制的频率域特征通过感知位置的选择权重进行自适应整合:
xF′=∑iWFC(i)⊗Conv1×1(xF(i))(4)x_F' = \sum_i W_{FC}^{(i)} \otimes \text{Conv}_{1 \times 1}(x_F^{(i)}) \quad (4)xF′=i∑WFC(i)⊗Conv1×1(xF(i))(4)
其中 WFC(i)∈R1×H×(W/2+1)W_{FC}^{(i)} \in \mathbb{R}^{1 \times H \times (W/2+1)}WFC(i)∈R1×H×(W/2+1) 表示学习到的感知位置的选择权重,xF(i)x_F^{(i)}xF(i) 表示 xFx_FxF 的第 iii 组。整合后的特征 xF′x_F'xF′ 然后通过逆快速傅里叶变换转换回空间域。通过与原始 x2x_2x2 的残差连接,随后进行 1×11 \times 11×1 卷积,获得最终的全局语义特征 xglobalx_{\text{global}}xglobal。
特征聚合 (Feature Aggregation) 。局部细节特征 xlocalx_{\text{local}}xlocal 和全局语义特征 xglobalx_{\text{global}}xglobal 随后沿通道维度拼接。接着,拼接后的特征通过通道注意力机制7进行重新校准,以强调信息丰富的通道。最后,重新校准的特征通过 1×11 \times 11×1 卷积进行细化和压缩。
为了进一步增强特征表征能力,我们采用卷积GLU22作为FFN(前馈网络),以促进通道混合和特征细化。
通过空间域通道选择和频率域感知位置的分量选择的协同操作,SSFNet实现了局部多尺度特征和全局语义表征的自适应整合,从而为后续检测提供多样化的上下文信息。
3.2. 语义对齐融合 (Semantic-Aligned Fusion)
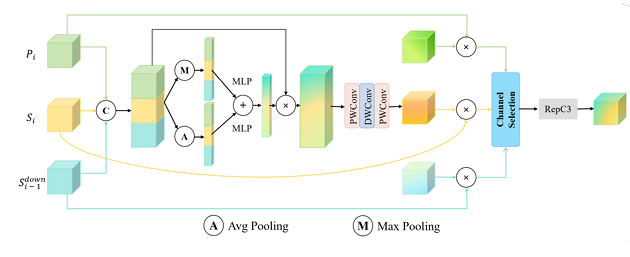
图3. 语义对齐融合的结构。Si−1downS_{i-1}^{\text{down}}Si−1down、SiS_iSi 来自特征提取主干SSFNet,PiP_iPi 来自特征聚合阶段。
如图3所示,我们考虑三个不同层级的输入特征,表示为 {Si−1down,Si,Pi}\{S_{i-1}^{\text{down}}, S_i, P_i\}{Si−1down,Si,Pi}。具体来说,SiS_iSi 和 PiP_iPi 表示对应层级的输入特征,其中 SiS_iSi 来自SSFNet主干,PiP_iPi 来自特征聚合阶段。同时,Si−1downS_{i-1}^{\text{down}}Si−1down 表示来自SSFNet主干前一层的下采样特征,它保留了更多的浅层细节信息。语义对齐融合(SAF)模块首先通过独立的 1×11 \times 11×1 卷积统一它们的维度,产生特征 x1,x2,x3∈RC×H×Wx_1, x_2, x_3 \in \mathbb{R}^{C \times H \times W}x1,x2,x3∈RC×H×W。
多尺度特征沿通道维度拼接,形成 xc∈R3C×H×Wx_c \in \mathbb{R}^{3C \times H \times W}xc∈R3C×H×W。为了提取每个通道的全局上下文,同时采用全局最大池化和全局平均池化。随后,共享权重的MLP促进跨尺度的语义交互,接着通过sigmoid层生成通道对齐权重 Wc∈R3C×1×1W_c \in \mathbb{R}^{3C \times 1 \times 1}Wc∈R3C×1×1:
Wc=σ(MLP(Gmax(xc)+Gavg(xc)))(5)W_c = \sigma(\text{MLP}(\text{Gmax}(x_c) + \text{Gavg}(x_c))) \quad (5)Wc=σ(MLP(Gmax(xc)+Gavg(xc)))(5)
对 xcx_cxc 与 WcW_cWc 执行逐元素乘法以实现初步对齐,产生 xalignedchannelx_{\text{aligned}}^{\text{channel}}xalignedchannel。
在通道级对齐特征的基础上,我们进一步在空间维度上执行细化对齐。xalignedchannelx_{\text{aligned}}^{\text{channel}}xalignedchannel 经过深度可分离卷积以捕获空间依赖性和位置相关性,从而生成最终的对齐权重 W∈R3C×H×WW \in \mathbb{R}^{3C \times H \times W}W∈R3C×H×W:
W=Conv1×1(DWConv(Conv1×1(xalignedchannel)))(6)W = \text{Conv}{1 \times 1}(\text{DWConv}(\text{Conv}{1 \times 1}(x_{\text{aligned}}^{\text{channel}}))) \quad (6)W=Conv1×1(DWConv(Conv1×1(xalignedchannel)))(6)
具体来说,输入特征的对齐是通过将 WWW 沿通道维度分为三个相等的部分,然后与初始输入特征 x1,x2,x3x_1, x_2, x_3x1,x2,x3 进行逐元素乘法来完成的。
为了实现最佳的特征整合,引入了可学习的通道级选择权重,以自适应地平衡来自不同尺度特征的贡献。最后,采用RepC338模块执行更细粒度的融合:
xfused=RepC3(Conv1×1(∑ixalignedi⊗λi))(7)x_{\text{fused}} = \text{RepC3}\left(\text{Conv}{1 \times 1}\left(\sum_i x{\text{aligned}}^i \otimes \lambda_i\right)\right) \quad (7)xfused=RepC3(Conv1×1(i∑xalignedi⊗λi))(7)
其中 λi=1,2,3∈RC×1×1\lambda_{i=1,2,3} \in \mathbb{R}^{C \times 1 \times 1}λi=1,2,3∈RC×1×1 是初始化为 1/31/31/3 的可学习参数,xalignedix_{\text{aligned}}^ixalignedi 表示渐进对齐后的多尺度特征。
通过渐进的通道级语义对齐、空间细化对齐、自适应通道级选择和更细粒度的融合,SAF有效地缓解了多尺度特征之间的语义未对齐问题。这防止了小目标特征在融合过程中的稀释,特别是在无人机场景中。
3.3. 多分支特征增强器 (Multi-branch Feature Enhancer)
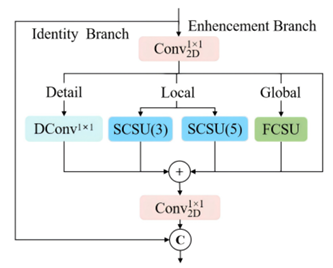
图4. 多分支特征增强器的结构。
为了进一步增强由语义对齐融合(SAF)融合的多尺度特征的可区分性,我们提出了一种采用多分支并行增强的多分支特征增强器(MFE)。
如图4所示,MFE采用跨阶段部分策略,将输入 x∈RC×H×Wx \in \mathbb{R}^{C \times H \times W}x∈RC×H×W 沿通道维度按比例 α\alphaα 划分为 x1∈RαC×H×Wx_1 \in \mathbb{R}^{\alpha C \times H \times W}x1∈RαC×H×W 和 x2∈R(1−α)C×H×Wx_2 \in \mathbb{R}^{(1-\alpha)C \times H \times W}x2∈R(1−α)C×H×W。
增强分支 x1x_1x1 经过 1×11 \times 11×1 卷积,然后进行GELU激活以激活特征表征,产生 xwx_wxw。随后,xwx_wxw 通过四个并行分支进行处理:捕获像素级空间细节的 1×11 \times 11×1 深度卷积、核大小为 k=3k=3k=3 和 k=5k=5k=5 提取多尺度局部特征的空间通道选择单元(SCSU)、用于全局增强的频率分量选择单元(FCSU),以及保留原始信息的恒等连接:
xenhance=DWConv(xw)+SCSU(xw)+FCSU(xw)+xw(8)x_{\text{enhance}} = \text{DWConv}(x_w) + \text{SCSU}(x_w) + \text{FCSU}(x_w) + x_w \quad (8)xenhance=DWConv(xw)+SCSU(xw)+FCSU(xw)+xw(8)
最终输出是通过将恒等分支 x2x_2x2 与增强特征 xenhancex_{\text{enhance}}xenhance 拼接,然后进行 1×11 \times 11×1 卷积进行通道混合而获得的。
利用多分支并行增强策略,MFE模块有效地融合了像素级空间细节、多尺度局部语义和全局频率域信息,同时保留了原始特征上下文。这不仅显著提高了航拍场景中复杂背景下小目标特征的区分能力,而且产生了紧凑且高质量的融合特征,以支持后续检测管道的操作。
4. 实验 (Experiments)
4.1. 实验设置
我们在涵盖无人机航拍图像目标检测和遥感目标检测的五个数据集上进行了广泛的实验,包括VisDrone39、UAVDT4、CODrone33、UAVVaste10以及遥感目标检测数据集SIMD6。所有实验均在NVIDIA GeForce RTX 4090上进行。SFS-DETR支持两种模型大小:SFS-DETR-S和SFS-DETR,它们分别采用SSFNet-S和SSFNet-M作为主干网络。所有模型均训练350个epoch,批次大小(batch size)为4,并实施了耐心值(patience)为40的早停机制。在训练期间,我们采用AdamW优化器,学习率为0.0001,动量为0.9。我们将输入图像统一调整为 640×640640 \times 640640×640 像素,并应用与RT-DETR相同的数据增强策略。此外,我们应用Mosaic和mixup技术,Mosaic概率设置为1.0,mixup概率设置为0.2,这与UAV-DETR一致。
4.2. 对比实验
VisDrone数据集上的结果。如表2所示,在VisDrone数据集上,与基线RT-DETR-R18相比,SFS-DETR-S仅增加了1.1M参数和8.5 GFLOPs的计算量,就实现了AP提升4.7%和AP50提升6.4%。SFS-DETR在使用更少参数(38.7M)和更低计算成本(122 GFLOPs)的同时,实现了AP提升4.1%和AP50提升5.2%。在相当的计算范围内,SFS-DETR-S以68.5 GFLOPs取得了最佳性能,AP达到31.3%,显著优于其他方法,包括FBRT-YOLO-X(185.8 GFLOPs)。SFS-DETR在所有比较方法中表现出最佳性能。与目前最先进的UAV-DETR-R50相比,它将计算成本降低了28%,同时将AP提高了0.9%,AP50提高了1.2%。这些实验证明了我们的SFS-DETR的优越性。
表2. VisDrone数据集上不同目标检测器的AP(%)和Params/GFLOPs对比。
| 模型 | 出处 | 输入尺寸 | 参数量(M) | GFLOPS | AP | AP50 |
|---|---|---|---|---|---|---|
| YOLOv8-M | - | 640×640 | 25.9 | 78.9 | 24.6 | 40.7 |
| YOLOv8-L | - | 640×640 | 43.7 | 165.2 | 26.1 | 42.7 |
| YOLOv10-M | arXiv2024 | 640×640 | 15.4 | 59.1 | 24.5 | 40.5 |
| YOLOv10-L | arXiv2024 | 640×640 | 24.4 | 120.3 | 26.3 | 43.1 |
| YOLOv11-M | arXiv2024 | 640×640 | 20.0 | 67.7 | 26.1 | 43.1 |
| YOLOv11-X | arXiv2024 | 640×640 | 56.8 | 194.5 | 28.1 | 45.6 |
| YOLOv12-L | arXiv2025 | 640×640 | 26.4 | 88.9 | 25.7 | 42.5 |
| HIC-YOLOv5 | ICRA2024 | 640×640 | 9.4 | 31.2 | 20.8 | 36.1 |
| FBRT-YOLO-L | AAAI2025 | 640×640 | 14.6 | 119.2 | 29.7 | 47.7 |
| FBRT-YOLO-X | AAAI2025 | 640×640 | 22.8 | 185.8 | 30.1 | 48.4 |
| DETR | ECCV2020 | 1333×750 | 60.0 | 187.0 | 24.1 | 40.1 |
| Deformable DETR | ICLR2020 | 1333×800 | 40.0 | 173.0 | 27.1 | 42.2 |
| Sparse DETR | ICLR2022 | 1333×800 | 40.9 | 121.0 | 27.3 | 42.5 |
| RT-DETR-R18 | CVPR2024 | 640×640 | 20.0 | 60.0 | 26.6 | 44.5 |
| RT-DETR-R50 | CVPR2024 | 640×640 | 42.0 | 136.0 | 28.3 | 47.1 |
| Mamba-YOLO-B | AAAI2025 | 640×640 | 21.8 | 49.6 | 24.7 | 42.4 |
| UAV-DETR-R18 | CVPR2025 | 640×640 | 21.2 | 73.0 | 29.8 | 48.8 |
| UAV-DETR-R50 | CVPR2025 | 640×640 | 43.0 | 170.0 | 31.5 | 51.1 |
| SFS-DETR-S(Ours) | - | 640×640 | 21.1 | 68.5 | 31.3 | 50.9 |
| SFS-DETR(Ours) | - | 640×640 | 38.7 | 122.0 | 32.4 | 52.3 |
为了评估我们方法的泛化能力,我们在UAVDT、CODrone、UAVVaste和SIMD数据集上使用SFS-DETR-S进行了对比实验。
UAVDT数据集上的结果。如表3所示,对于UAVDT数据集,我们的方法实现了25.2%的AP,优于现有方法如FBRT-YOLO-X(18.4%)和UAV-DETR-R18(24.1%)。与基线RT-DETR-R18相比,SSF-DETR-S在AP上实现了4.1%的提升,在AP50上实现了6.0%的提升,展现出出色的检测能力。
表3. UAVDT数据集上的实验结果。
| 模型 | AP | AP50 | AP75 |
|---|---|---|---|
| CEASC3 | 17.1 | 30.9 | 17.8 |
| FBRT-YOLO-X | 18.4 | 31.1 | 18.9 |
| RT-DETR-R18 | 20.1 | 34.4 | 22.2 |
| UAV-DETR-R18 | 24.1 | 38.7 | 26.8 |
| SFS-DETR-S(Ours) | 25.2 | 40.4 | 28.2 |
CODrone数据集上的结果。CODrone数据集具有更高的图像分辨率以及更广泛的飞行高度和拍摄角度,带来了更大的检测挑战。为了验证我们提出的方法在高分辨率航拍图像上的性能,我们在CODrone数据集上进行了评估,在训练期间使用原始图像输入而不进行裁剪。如表4所示,SFS-DETR-S模型在CODrone测试集上实现了17.9%的AP。与RT-DETR-R18和UAV-DETR-R18相比,该结果分别代表了3.0%和1.2%的提升。这些实验充分证明了我们的方法在复杂高分辨率航拍图像目标检测上的有效性。
表4. CODrone数据集上的实验结果。
| 模型 | AP | AP50 | AP75 |
|---|---|---|---|
| YOLOv8-M | 13.4 | 26.5 | 12.2 |
| YOLOv11-M | 14.5 | 27.9 | 13.1 |
| FBRT-YOLO-X | 16.3 | 31.2 | 15.1 |
| RT-DETR-R18 | 14.9 | 30.0 | 13.1 |
| UAV-DETR-R18 | 16.7 | 33.6 | 14.6 |
| SFS-DETR-S(Ours) | 17.9 | 34.8 | 16.2 |
UAVVaste数据集上的结果。表5展示了在UAVVaste数据集上的对比结果,其中SFS-DETR-S保持了相对于其他模型的性能优势。具体来说,它比基线RT-DETR-R18实现了4.3%的AP提升,比UAV-DETR-R18实现了1.0%的AP提升。值得注意的是,UAVVaste数据集仅包含772张标注图像。这一结果表明,我们的方法在不依赖大规模标注数据的情况下实现了强大的性能。
表5. UAVVaste数据集上的实验结果。
| 模型 | AP | AP50 |
|---|---|---|
| HIC-YOLOv5 | 40.5 | 66.8 |
| YOLOv8-M | 40.5 | 68.6 |
| RT-DETR-R18 | 42.4 | 71.1 |
| UAV-DETR-R18 | 45.7 | 74.7 |
| SFS-DETR-S(Ours) | 46.7 | 77.0 |
SIMD数据集上的结果。我们还在遥感目标检测数据集SIMD上进行了对比实验。SFS-DETR-S获得了66.1%的AP和81.2%的AP50。与基线相比,它在AP和AP50上分别实现了2.4%和2.6%的相对提升,充分证明了我们方法的泛化能力。
此外,我们使用PyTorch实现在32位浮点精度下计算了基线模型和SFS-DETR模型的每秒帧数(FPS)。SFS-DETR-S达到了96的FPS,这表明SFS-DETR满足了实时性要求。
为了评估提出的SSFNet主干的有效性,我们在VisDrone数据集上将SSFNet与其他特征提取网络进行了比较,使用RT-DETR-R18作为基线。为了公平比较,所有模型均采用RT-DETR的默认参数设置,并训练300个epoch。如表6所示,SSFNet-S以最小的参数和计算成本实现了28.6%的AP和47.4%的AP50,超越了所有其他特征提取网络14, 18, 28。这证明了多域学习和选择机制在无人机航拍图像目标检测中的有效性。
表6. 在VisDrone数据集上,使用RT-DETR-R18作为基线的不同主干的AP(%)和AP50对比。
| 主干 | 参数量(M) | GFLOPs | AP | AP50 |
|---|---|---|---|---|
| ResNet-18 | 11.2 | 38.1 | 26.6 | 44.5 |
| LSNet-S | 15.7 | 30.9 | 26.6 | 44.6 |
| EfficientFormerv2-l | 25.6 | 42.7 | 26.7 | 44.8 |
| PKINet-S | 13.7 | 70.2 | 26.8 | 44.7 |
| StripNet-S | 13.3 | 52.3 | 26.8 | 44.9 |
| LEGNet-S | 12.7 | 65.4 | 27.5 | 45.9 |
| LSKNet-S | 14.4 | 54.4 | 27.5 | 46.1 |
| SSFNet-S(Ours) | 9.9 | 30.9 | 28.6 | 47.4 |
4.3. 消融实验
我们在VisDrone数据集上使用SFS-DETR-S进行了一系列消融实验,以分析每个模块设计对最终检测精度的影响。表7展示了不同配置下的性能比较,其中DA表示与UAV-DETR一致的Mosaic和mixup数据增强,IM代表Inner-MPDIoU,SSFNet指选择性空间-频率网络,SAF表示语义对齐融合,MFE对应多分支特征增强器。
基线RT-DETR-R18实现了26.6%的AP、44.5%的AP50和18.4%的APs。采用Mosaic和mixup数据增强策略后,AP提升至27.5%。通过将特征提取网络替换为SSFNet主干,AP增加至28.6%,AP50上升至47.4%。经过进一步的数据增强,AP达到30.0%,AP50达到49.1%,APs达到22.0%,证明了SSFNet在航拍图像目标检测中的有效性。Inner-MPDIoU的引入将AP提升至30.2%,并且模型在训练期间收敛更快。我们采用SAF来实现多尺度特征对齐和融合,将AP50提升至50.2%,APs提升至22.7%。最后,结合MFE,SFS-DETR-S以31.3%的AP、50.9%的AP50和23.3%的APs取得了最佳性能,说明了每个模块对最终检测精度的累积影响。
表7. 在VisDrone数据集上我们提出方法的消融研究。
| DA | SSFNet | IM | SAF | MFE | AP | AP50 | APs |
|---|---|---|---|---|---|---|---|
| 26.6 | 44.5 | 18.4 | |||||
| ✓ | 27.5 | 45.8 | 19.2 | ||||
| ✓ | ✓ | 28.6 | 47.4 | 20.7 | |||
| ✓ | ✓ | ✓ | 30.0 | 49.1 | 22.0 | ||
| ✓ | ✓ | ✓ | ✓ | 30.2 | 49.4 | 22.2 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 30.7 | 50.2 | 22.7 |
| ✓ | ✓ | ✓ | ✓ | ✓ | 31.3 | 50.9 | 23.3 |
| (注:依据原文表格逻辑与正文描述,上表打勾顺序对应模块累加过程) |
表8展示了SSFNet中SCSU不同卷积核配置的影响。结果表明,SCSU的最佳配置为(3,5), (3,5), (3,5), (3,5)。这是因为较小的核难以有效捕获局部细节,而较大的核会引入对检测性能不利的背景噪声。如表9所示,当FCSU中的频率特征被分为4组时,实现了最佳检测效果。
表8. SCSU核大小配置对SSFNet主干的影响。
| SCSU Kernels | GFLOPs | AP | AP50 |
|---|---|---|---|
| (3,5)(3,5)(1,3)(1,3) | 68.5 | 29.7 | 49.6 |
| (5,7)(3,5)(3,5)(1,3) | 68.6 | 30.5 | 50.0 |
| (5,7)(5,7)(3,5)(3,5) | 68.7 | 31.2 | 50.8 |
| (3,5)(3,5)(3,5)(3,5) | 68.5 | 31.3 | 50.9 |
表9. FCSU分组数对SSFNet主干的影响。
| FCSU Groups | GFLOPs | AP | AP50 |
|---|---|---|---|
| 5 | 71.1 | 30.8 | 50.3 |
| 3 | 70.2 | 31.0 | 50.8 |
| 2 | 68.5 | 31.2 | 51.0 |
| 4 | 68.5 | 31.3 | 50.9 |
表10展示了不同 α\alphaα 参数值对实验结果的影响,其中 α\alphaα 表示MFE中增强分支和恒等分支之间的划分比例。结果表明,当 α=0.75\alpha=0.75α=0.75 时,检测性能最佳。此外,实验结果表明,将Inner-MPDIoU的比例设置为0.8是一个合适的选择。
表10. MFE模块中不同特征划分比例 α\alphaα 的实验。
| α\alphaα | 参数量(M) | GFLOPs | AP | AP50 |
|---|---|---|---|---|
| 1 | 21.4 | 70.5 | 30.1 | 49.8 |
| 0.25 | 20.6 | 66.2 | 31.0 | 50.5 |
| 0.5 | 20.8 | 67.1 | 31.0 | 50.7 |
| 0.75 | 21.1 | 68.5 | 31.3 | 50.9 |
4.4. 可视化

图5. RT-DETR-R18和SFS-DETR-S在VisDrone数据集上的热力图和检测结果。高亮区域表示模型对目标区域有更强的注意力。
为了更好地展示SFS-DETR在航拍图像检测中的优越性,我们在图5中可视化了基线和我们方法的热力图及检测结果。观察热力图可以发现,SFS-DETR更加关注密集小目标的周围环境,并利用这些上下文信息来区分复杂的背景。此外,如图5中的黄框所示,SFS-DETR能够实现对遮挡目标的精确定位。这些结果证明了所提出方法在特征选择和上下文建模方面的显著改进。
5. 结论 (Conclusion)
在本文中,我们提出了SFS-DETR,这是一种用于无人机航拍图像目标检测的端到端检测框架。该框架引入了三个核心创新:SSFNet通过多域学习和自适应选择机制有效地对不同目标的多变上下文进行建模;SAF通过语义引导的渐进对齐防止了小目标特征在多尺度特征融合中的稀释;MFE通过多分支并行增强策略增强了特征的可区分性。在VisDrone、UAVDT、CODrone、UAVVaste和SIMD数据集上的大量实验表明,SFS-DETR在相当的计算成本下实现了优于最先进方法的检测精度,同时保持了实时推理速度。
参考文献 (References)
1 Xinhao Cai, et al. Poly kernel inception network for remote sensing detection. CVPR 2024.
2 Nicolas Carion, et al. End-to-end object detection with transformers. ECCV 2020.
3 Bowei Du, et al. Adaptive sparse convolutional networks with global context enhancement for faster object detection on drone images. CVPR 2023.
4 Dawei Du, et al. The unmanned aerial vehicle benchmark: Object detection and tracking. ECCV 2018.
5 Lihui Ge, et al. Regression-guided refocusing learning with feature alignment for remote sensing tiny object detection. IEEE TGRS 2024.
6 Muhammad Haroon, et al. Multisized object detection using space-borne optical imagery. IEEE JSTARS 2020.
7 Jie Hu, et al. Squeeze-and-excitation networks. CVPR 2018.
8 G. Jocher, et al. Ultralytics YOLOv8, 2023.
9 Rahima Khanam, et al. Yolov11: An overview of the key architectural enhancements. arXiv 2024.
10 Marek Kraft, et al. Autonomous, onboard vision-based trash and litter detection in low altitude aerial images collected by an unmanned aerial vehicle. Remote Sensing 2021.
11 Tin Lai. Real-time aerial detection and reasoning on embedded-uavs in rural environments. IEEE TGRS 2023.
12 Hao Li, et al. Alignyolo: A feature-aligned network for object detection. Expert Systems with Applications 2024.
13 Yuxuan Li, et al. Large selective kernel network for remote sensing object detection. ICCV 2023.
14 Yanyu Li, et al. Rethinking vision transformers for mobilenet size and speed. ICCV 2023.
15 Tsung-Yi Lin, et al. Feature pyramid networks for object detection. CVPR 2017.
16 Zhiwei Lin, et al. Rcbevdet: Radar-camera fusion in bird's eye view for 3d object detection. CVPR 2024.
17 Shu Liu, et al. Path aggregation network for instance segmentation. CVPR 2018.
18 Wei Lu, et al. Legnet: Lightweight edge-gaussian driven network for low-quality remote sensing image object detection. arXiv 2025.
19 Siliang Ma, et al. Mpdiou: a loss for efficient and accurate bounding box regression. arXiv 2023.
20 Shuai Ma, et al. Owrt-detr: A novel real-time transformer network for small object detection in open water search and rescue from uav aerial imagery. IEEE TGRS 2025.
21 Byungseok Roh, et al. Sparse detr: Efficient end-to-end object detection with learnable sparsity. arXiv 2021.
22 Dai Shi. Transnext: Robust foveal visual perception for vision transformers. CVPR 2024.
23 Baoye Song, et al. Daf-detr: A dynamic adaptation feature transformer for enhanced object detection in unmanned aerial vehicles. Knowledge-Based Systems 2025.
24 Shiyi Tang, et al. Hic-yolov5: Improved yolov5 for small object detection. ICRA 2024.
25 Yunjie Tian, et al. Yolov12: Attention-centric real-time object detectors. arXiv 2025.
26 Kang Tong, et al. Recent advances in small object detection based on deep learning: A review. Image and Vision Computing 2020.
27 Ao Wang, et al. Yolov10: Real-time end-to-end object detection. NeurIPS 2024.
28 Ao Wang, et al. Lsnet: See large, focus small. CVPR 2025.
29 Biao Wang, et al. Joint response and background learning for uav visual tracking. ICRA 2024.
30 Zeyu Wang, et al. Mamba yolo: A simple baseline for object detection with state space model. AAAI 2025.
31 Yao Xiao, et al. Fbrt-yolo: Faster and better for real-time aerial image detection. AAAI 2025.
32 Chenhongyi Yang, et al. Querydet: Cascaded sparse query for accelerating high-resolution small object detection. CVPR 2022.
33 Kai Ye, et al. More clear, more flexible, more precise: A comprehensive oriented object detection benchmark for uav. arXiv 2025.
34 X. Yuan, et al. Strip r-cnn: Large strip convolution for remote sensing object detection. arXiv 2025.
35 Cong Zhang, et al. Cof-net: A progressive coarse-to-fine framework for object detection in remote-sensing imagery. IEEE TGRS 2023.
36 Hao Zhang, et al. Inner-iou: more effective intersection over union loss with auxiliary bounding box. arXiv 2023.
37 Huaxiang Zhang, et al. Uav-detr: efficient end-to-end object detection for unmanned aerial vehicle imagery. arXiv 2025.
38 Yian Zhao, et al. Detrs beat yolos on real-time object detection. CVPR 2024.
39 Pengfei Zhu, et al. Detection and tracking meet drones challenge. IEEE TPAMI 2021.
40 Xizhou Zhu, et al. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020.