Open Code Review 是阿里开源的 AI 代码审查 CLI,核心入口是 ocr 命令。它读取 Git diff,将变更文件交给具备工具调用能力的 Review Agent,并生成带文件路径和行号的结构化审查意见。
这里的 Review Agent,可以先理解成一个围绕单个文件 diff 工作的审查执行单元:它会读取当前 diff,必要时调用工具补上下文,并通过 code_comment 提交结构化评论。
相比直接使用编码 Agent 自带的 code review,Open Code Review 更偏工程化:
- 审查范围来自明确的 diff,审查规则可以通过
rule.json随仓库维护,结果可以按 text 或 json 输出给开发者、CI 或其他 Agent。 - 规则、输入范围和输出格式都被固定下来,不同编码 Agent 接入时也更容易保持一致表现
它解决的不是"让模型看一眼代码",而是把代码审查变成可配置、可复用、可集成的流程。
使用:安装、运行与配置规则
Open Code Review 推荐通过 npm 安装:
bash
npm install -g @alibaba-group/open-code-review安装后可以直接在 Git 仓库里运行审查:
bash
# 审当前工作区还没提交的变更
ocr review
# 审 feature/pay 相对 main 新增的变更
ocr review --from main --to feature/pay
# 只审某个提交引入的变更
ocr review --commit abc123
# 输出给 CI 或其他 Agent 消费
ocr review --format json如果要调整审查规则,可以在项目里放一份 .opencodereview/rule.json:
json
{
"rules": [
{
"path": "src/pay/**/*.go",
"rule": "重点检查金额计算、错误处理和并发安全"
},
{
"path": "**/*mapper*.xml",
"rule": "检查 SQL 注入风险、参数错误和缺少闭合标签"
}
],
"exclude": ["**/generated/**", "vendor/**"]
}这份 rule 配置会影响两件事:
rules决定某个文件进入审查时,Review Agent 会拿到什么审查规则。include/exclude决定哪些文件进入审查队列。上面的示例只配置了exclude,用于排除生成代码和第三方目录。
规则来源有优先级:
- 命令行
--rule指定的规则文件最高 - 其次是项目内
.opencodereview/rule.json - 再其次是用户全局
~/.opencodereview/rule.json - 最后才是 OCR 内置规则。
没有配置自定义 rule 时,OCR 也不会裸跑。它内置了按文件类型匹配的审查规则,例如 *.ts、*.tsx、*.js、*.jsx 会使用同一组前端规则,覆盖 TypeScript 类型、React Hooks、副作用处理、异步错误处理和常见安全问题。其他常见文件类型也有对应规则,未命中特定类型时会回退到默认规则。
项目协作里通常把项目级 rule 提交到仓库;临时验证某套规则时,可以用 --rule 指向一份单独的 JSON 文件。
自定义配置不会直接把内置规则整体替换掉。rules 是按文件路径逐层匹配:
- 只有当前文件命中自定义规则时,才使用自定义规则;
- 如果没有命中,会继续查找下一层
- 最终仍可能使用内置规则。
include / exclude 的处理方式不同。程序会选择最高优先级中配置了过滤条件的那一层整体生效,不会把多层过滤条件合并。exclude 始终优先;include 也不是"只审这些文件"的 allowlist,而是用来把默认会被排除的文件显式纳入审查,例如测试文件。没有命中 include 的普通业务文件,仍会继续走默认过滤判断。
原理:从命令入口到结构化评论
主流程可以拆成 7 个节点:

1. 从 npm 命令进入 Go CLI
这个入口看起来是 npm 包,但核心审查逻辑运行在 Go 程序里。
npm 包主要负责安装和暴露 ocr 命令,并把用户输入的参数转交给当前平台可执行的 Go CLI。
这个节点的产物很简单:Go CLI 拿到一组命令参数。后续会判断用户是不是要执行 review 子命令,并进入本次审查配置整理。
2. 归一化本次审查配置
进入 review 子命令后,程序不会立刻调用模型,而是先整理本次审查的配置。这里处理的是"运行前准备":把命令行参数、项目配置、用户全局配置和内置默认值合并成一份可执行的审查配置。
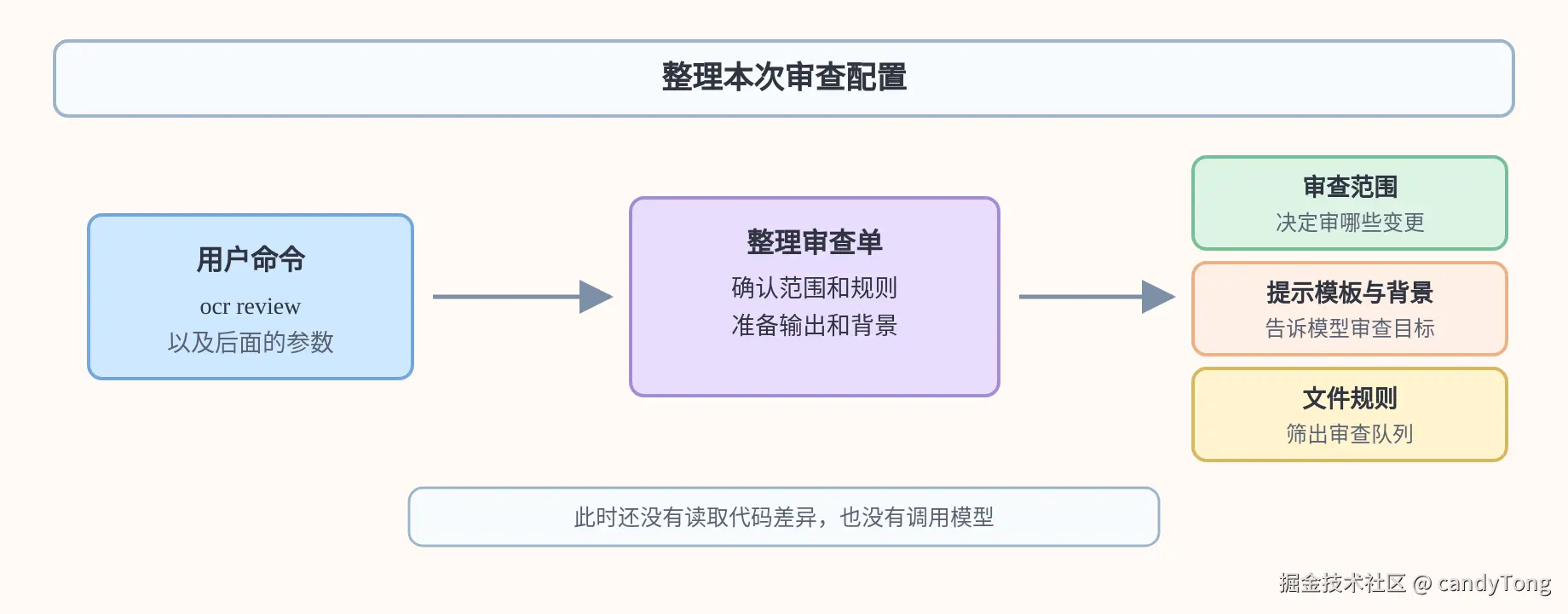
这个节点的产物不是评论,也不是最终 prompt,而是一组装配 Review Agent 运行上下文所需的材料,例如审查范围、规则来源、文件过滤器、输出格式、并发度和可选的需求背景。规则怎么注入、文件怎么筛选、prompt 怎么填充,都会在后续节点里展开。
3. 根据 Git diff 生成审查队列
Agent 开始执行后,第一件事是读取本次代码差异。不同输入范围会走不同 diff 来源:
ocr review:读取当前工作区变更。ocr review --from main --to feature/pay:读取两个引用之间的差异。ocr review --commit abc123:读取单个提交引入的差异。
无论来源是什么,读出来以后都会整理成按文件拆分的 diff 列表。Agent 会先把这些 diff 注入只读的 DiffMap,供后续工具按路径查询;随后再筛出真正要逐文件审查的队列。
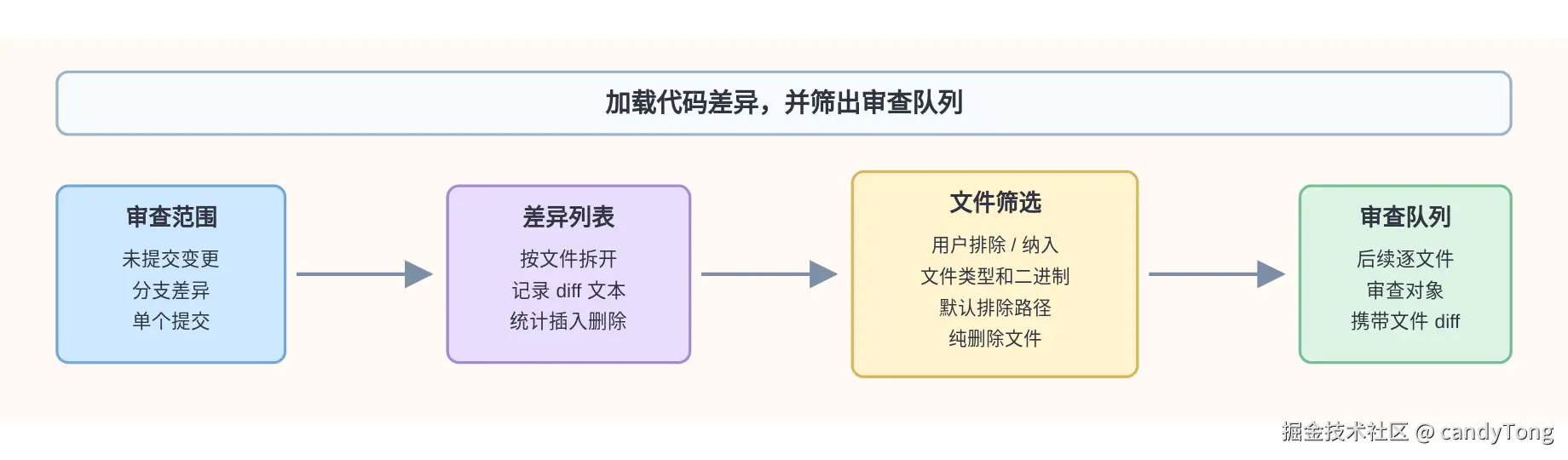
为什么要筛选?因为一次 diff 里可能混有二进制文件、生成代码、默认排除路径、用户明确排除路径,或者纯删除文件。它们可以作为 DiffMap 里的上下文存在,但不一定都适合作为主审文件启动一次模型审查。
举个例子,假设本次变更有四个文件,并且规则排除了 src/pay/generated/**:
| 文件 | 处理结果 | 原因 |
|---|---|---|
src/pay/service.go |
进入审查队列 | 业务代码变更,适合作为主审对象 |
src/pay/coupon.go |
进入审查队列 | 业务代码变更,适合作为主审对象 |
src/pay/service_test.go |
不进入审查队列 | 测试文件默认不作为主审对象 |
src/pay/generated/client.go |
不进入审查队列 | 命中用户排除路径 |
筛选完成后,审查队列里每个文件都会形成一个任务。其中 src/pay/service.go 的任务可以理解成这样:
go
[]ReviewTask{
{
File: "src/pay/service.go",
Diff: `
@@ -42,6 +42,9 @@ func (s *Service) Pay(req PayRequest) error {
amount := req.Amount
+ if req.CouponID != "" {
+ amount = s.coupon.Apply(req.CouponID, amount)
+ }
return s.gateway.Charge(amount)
}
`,
},
}这个节点的产物是"审查队列"。后续只会围绕队列里的文件启动单文件审查任务;被过滤掉的文件不会变成主审任务,但它们的 diff 仍可能通过 file_read_diff 按路径查询。
4. 补齐 Review Agent 运行上下文
审查队列确定后,后续审查会围绕队列里的文件逐个展开。每个文件进入审查前,程序都会拼装一份完整的运行上下文:当前文件路径、当前文件 diff、过滤后仍在审查队列里的其他变更文件列表、需求背景、可用工具,以及当前文件对应的审查规则。
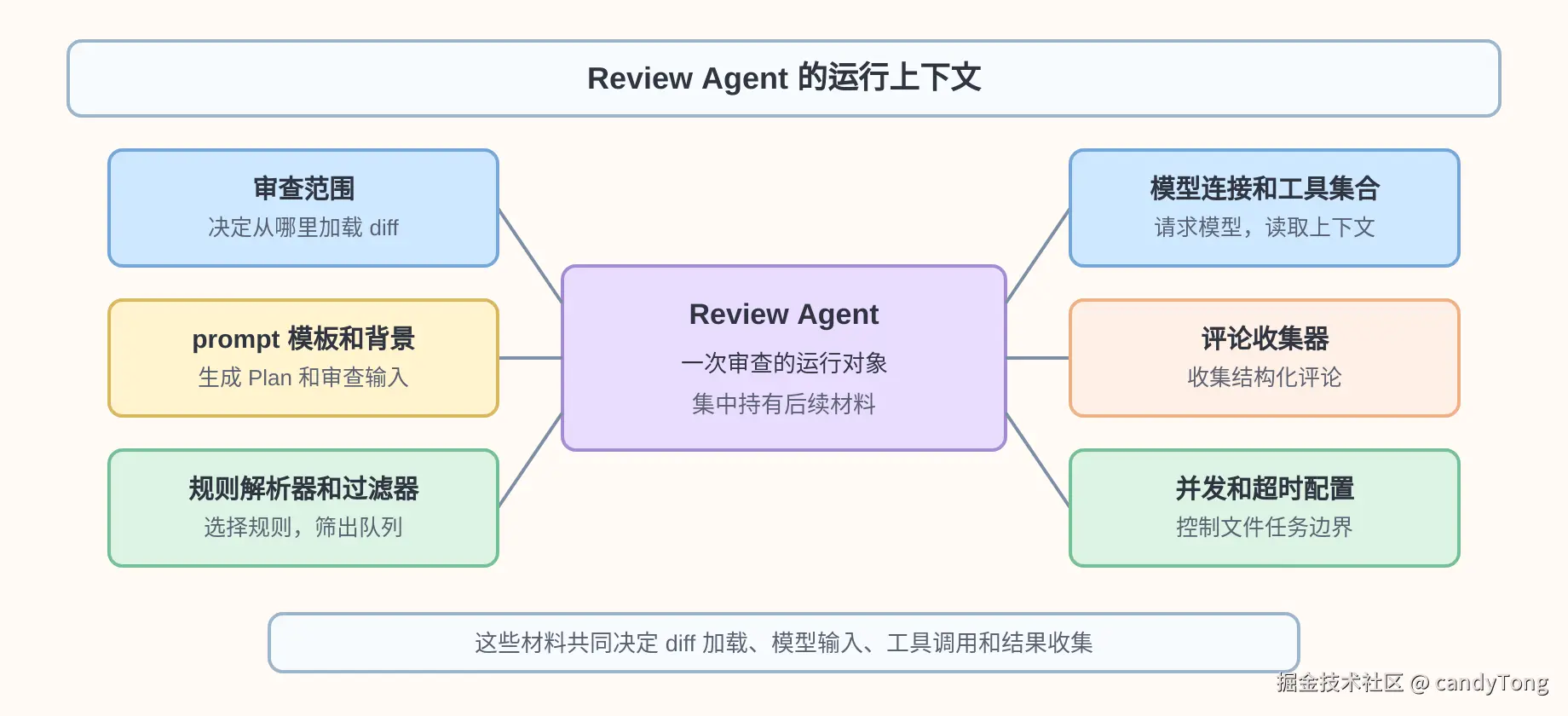
审查规则不是提前固定的一段文本,而是按当前文件来选择。进入单文件审查时,程序会根据文件路径和文件类型匹配 rule.json 或内置规则,把命中的规则文本传入 Plan 和 Review Agent 的 prompt。这样,同一次审查里的 Go 文件、前端文件、XML 文件可以拿到不同的审查重点。
这里可以先看 Review Agent prompt 的结构。它不是此刻就发送给模型,而是作为后续逐文件审查的拼装模板:等轮到某个文件时,再把当前文件路径、diff、匹配到的规则和可选的 Plan 结果填进去。
用中文示意,拼装前的 Review Agent prompt 大致是这样的:
System prompt 模板(简化版本,并非真实 prompt):
markdown
你是代码审查助手。
只审查当前文件 diff 中新增或修改的代码。
如果需要更多上下文,可以调用工具。
如果确认发现问题,必须通过 `code_comment` 提交结构化评论。
如果当前文件已经审查完成,调用 `task_done` 结束任务。User prompt 模板(简化版本,并非真实 prompt):
markdown
其他变更文件:
{{change_files}}
当前文件:
{{current_file_path}}
当前文件 diff:
{{diff}}
需求背景:
{{requirement_background}}
审查规则:
{{system_rule}}
审查计划(可选,来自大文件场景下的 Plan 阶段):
{{plan_guidance}}
请审查当前文件 diff。这段模板里的占位符,要到单文件审查阶段才会被替换成真实内容。运行上下文补齐后,Agent 才开始按审查队列分发文件子任务。
5. 按并发度分发文件子任务
加载 diff 后,Agent 手里已经有一个审查队列。并发分发节点要做的事情很单纯:把队列里的文件按并发度分发出去。
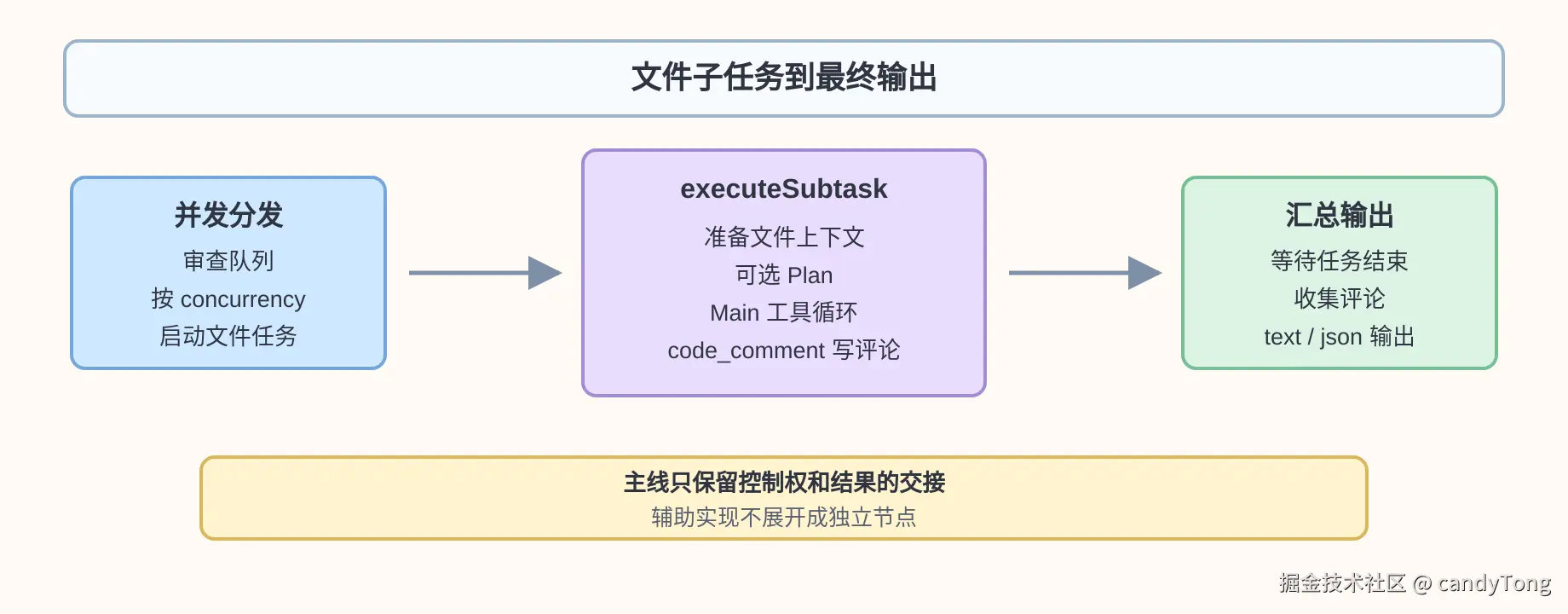
分发前还会做一次大 diff 预过滤,避免单个文件的 diff 过大,直接撑爆后面的 prompt。超过阈值的文件不会启动完整的单文件审查任务,而是被跳过并记录 warning。随后程序按 --concurrency 控制同时运行的文件任务数量。
每个文件任务都会把前面看到的 prompt 模板填成一份实际输入:
- 当前文件路径
- 当前文件 diff
- 其他变更文件
- 需求背景
- 匹配到的审查规则
- 可选的 Plan 结果
后续的单文件审查,就是围绕这份输入展开。
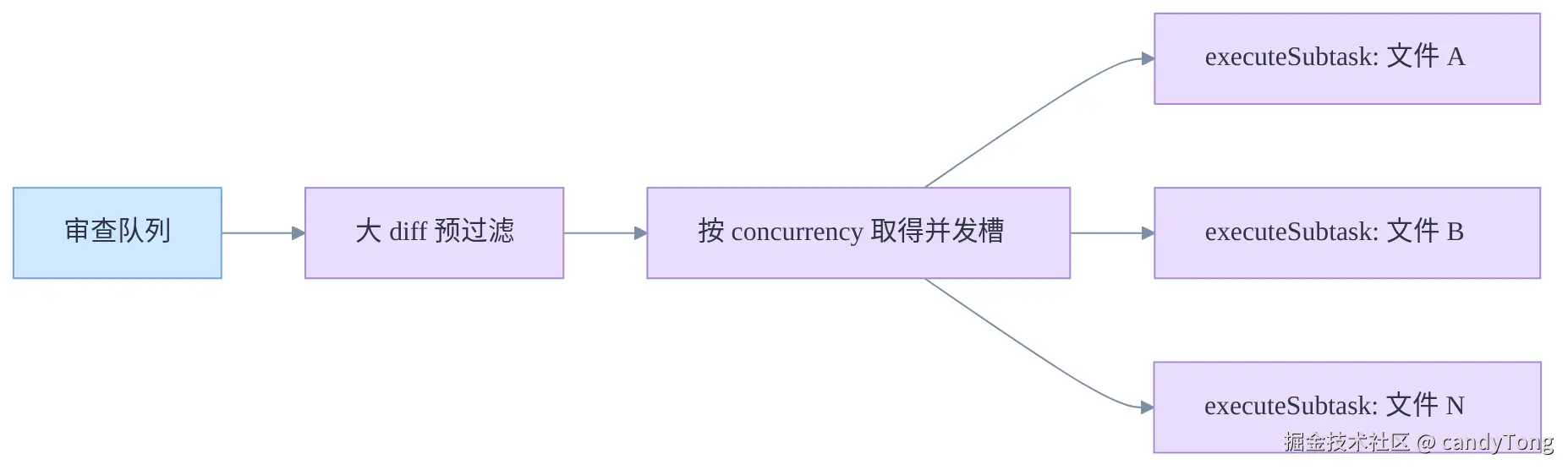
6. 完成单文件 Agent 审查
executeSubtask 是单个文件的审查单元。它接收一个文件 diff,负责把这个文件审完,并把确认后的结构化评论写入评论收集器。
主流程如下:
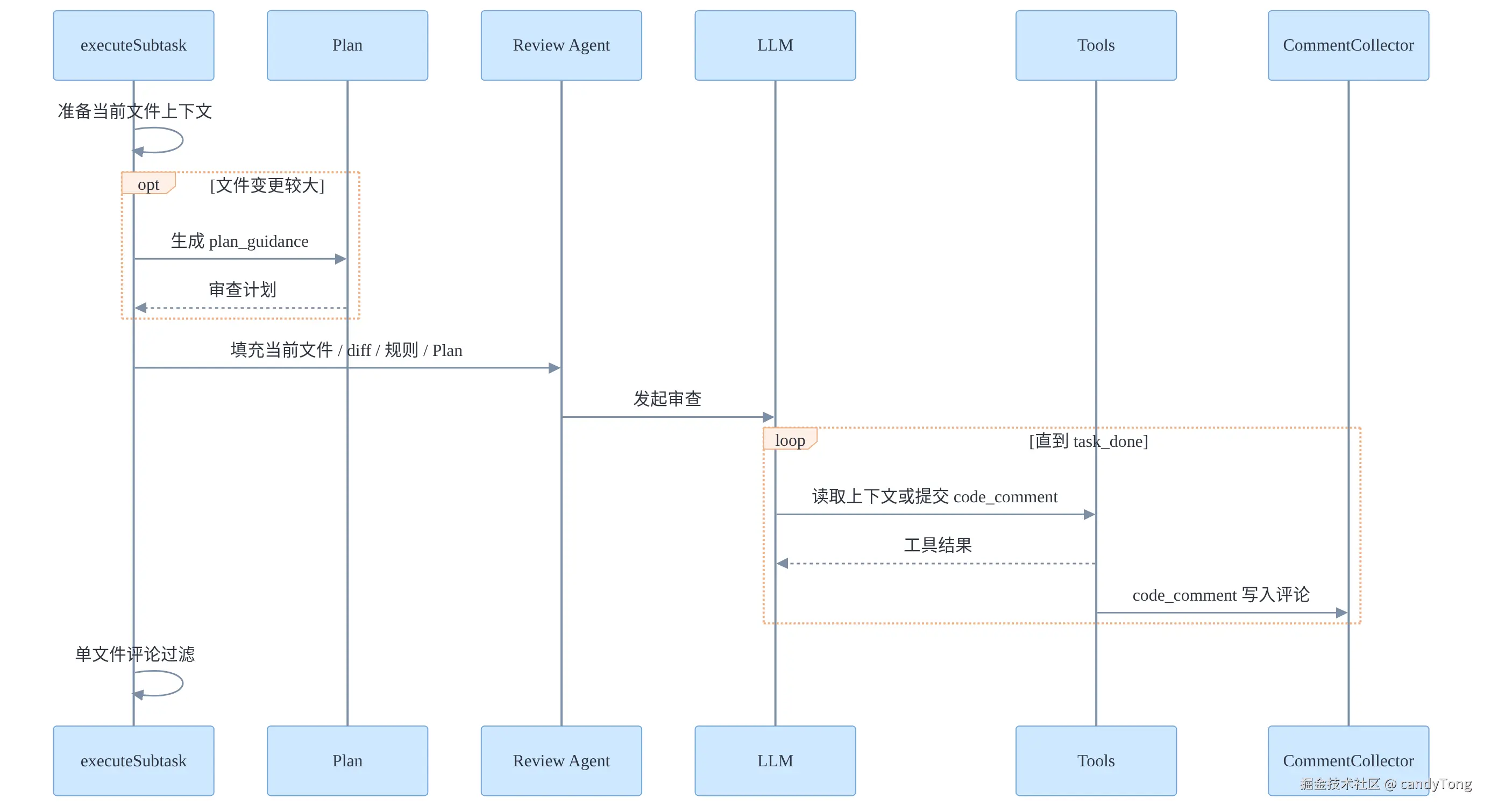
executeSubtask 的输入来自并发分发节点交出的队列项。
以 src/pay/service.go 为例,进入 executeSubtask 时,当前文件上下文大致是:
go
ReviewTask{
File: "src/pay/service.go",
OtherChangedFiles: []string{
"src/pay/coupon.go",
},
RequirementBackground: "本次需求为支付流程增加优惠券抵扣能力。",
ReviewRule: "只审查 Go 业务代码中新增和修改的逻辑;优先关注金额计算、错误处理和并发安全。",
}进入单文件审查后,规则选择会以当前文件路径为准。src/pay/service.go 会先去匹配自定义 rule;如果命中 src/pay/**/*.go,就使用这条规则。如果没有命中自定义规则,则继续查全局规则和内置规则。最终选出的规则文本会在拼装 prompt 时替换成审查规则。
注意,这里的 OtherChangedFiles 只来自过滤后的审查队列,所以示例里不会列出 service_test.go 或 generated/client.go。如果 Review Agent 后续确实需要确认这些文件的 diff,它可以通过 file_read_diff 按路径查询 DiffMap。
这里的设计约束是:同一个文件只会得到一条最终规则;命中更高优先级规则后,不再把后面的规则合并进来。
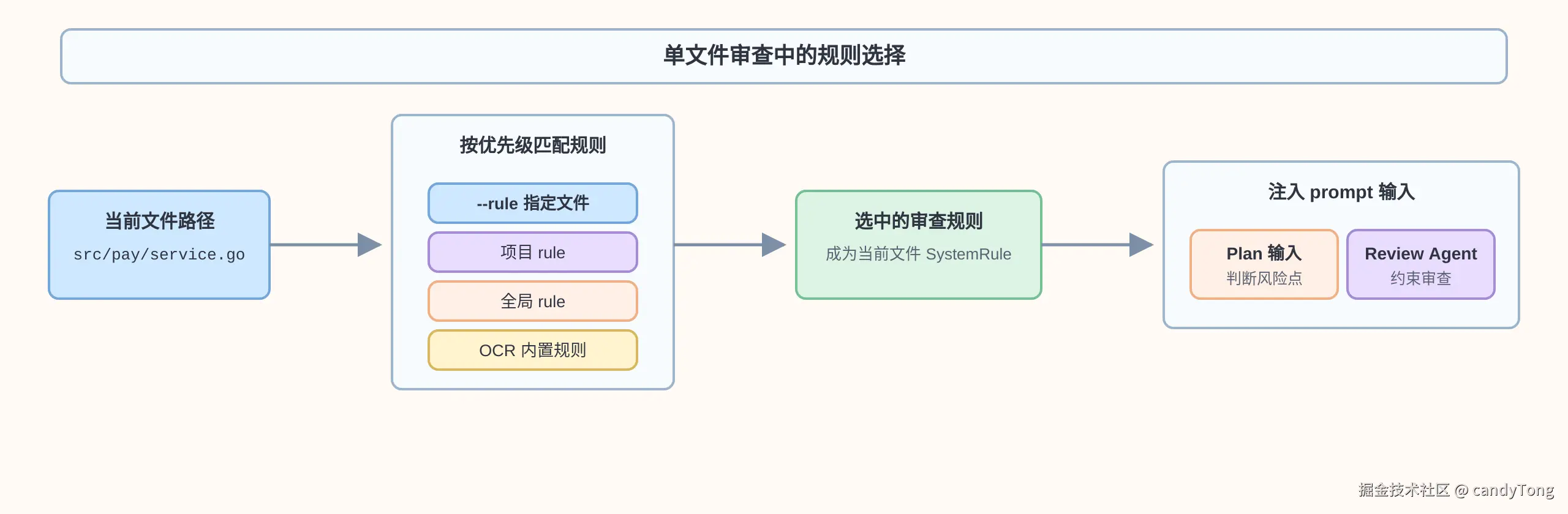
这条规则会被放进两个地方:
- Plan 输入:让 Plan 在分析风险点时知道当前文件应该按什么标准审。
- Review Agent 输入:填入后面的"审查规则"区块,约束正式审查时关注哪些问题。
如果文件变更比较大,executeSubtask 会先跑 Plan。Plan 可以理解成"正式审查前的路线图":它会先梳理当前文件的主要变化和潜在风险,并建议 Review Agent 优先读取哪些文件或 diff 来辅助判断。
Plan system prompt(简化版本,并非真实 prompt):
markdown
你是代码审查计划助手。
职责是分析当前文件 diff,识别潜在风险点,并为每个风险点规划需要读取的上下文。
可用工具:
- file_read:读取文件内容。
- file_read_diff:查看其他变更文件的 diff。
- code_search:搜索调用点、同名方法或相似实现。
- file_find:按文件名线索查找文件。
输出要求:
只输出 JSON,不输出额外解释。
JSON 字段包括 change_summary、issues、severity、description、tool_guidance。
分析规则:
1. 只分析新增和修改代码,忽略删除代码。
2. issues 按 high、medium、low 排序。
3. 工具只用于规划,不在 Plan 阶段实际调用。
4. description 需要说明问题位置、问题性质和潜在影响。Plan user prompt(简化版本,并非真实 prompt):
markdown
其他变更文件:
src/pay/coupon.go
当前文件:
src/pay/service.go
当前文件 diff:
@@ -42,6 +42,9 @@ func (s \*Service) Pay(req PayRequest) error {
amount := req.Amount
- if req.CouponID != "" {
- amount = s.coupon.Apply(req.CouponID, amount)
- }
return s.gateway.Charge(amount)
}
需求背景:
本次需求为支付流程增加优惠券抵扣能力。
审查规则:
只审查 Go 业务代码中新增和修改的逻辑;优先关注金额计算、错误处理和并发安全。
任务:
分析上述代码变更,输出结构化审查计划,使用 JSON。Plan 输出会成为后续的 plan_guidance,大致长这样:
json
{
"change_summary": "支付前根据 CouponID 调整扣款金额",
"issues": [
{
"severity": "medium",
"description": "需要确认优惠券抵扣后的金额边界,避免出现负数或零金额扣款",
"tool_guidance": [
{
"name": "file_read",
"reason": "查看 coupon.Apply 的返回值约束",
"arguments": "src/pay/coupon.go"
}
]
}
]
}这段 JSON 会作为 plan_guidance 填入 Review Agent 的 user prompt。Review Agent 看到这些建议后,可以据此优先读取相关文件、查询相关 diff,再决定是否提交 code_comment。如果文件变更不大,Plan 会被跳过,审查 prompt 里不会保留空的审查计划区块。
随后 executeSubtask 生成 Review Agent prompt。它同样由 system prompt 和 user prompt 组成。
Review Agent system prompt(简化版本,并非真实 prompt):
markdown
你是代码审查助手。
只审查当前文件 diff 中新增或修改的代码。
如果需要更多上下文,可以调用工具。
如果确认发现问题,必须通过 `code_comment` 提交结构化评论。
如果当前文件已经审查完成,调用 `task_done` 结束任务。Review Agent user prompt(简化版本,并非真实 prompt):
markdown
其他变更文件:
src/pay/coupon.go
当前文件:
src/pay/service.go
当前文件 diff:
@@ -42,6 +42,9 @@ func (s \*Service) Pay(req PayRequest) error {
amount := req.Amount
- if req.CouponID != "" {
- amount = s.coupon.Apply(req.CouponID, amount)
- }
return s.gateway.Charge(amount)
}
需求背景:
本次需求为支付流程增加优惠券抵扣能力。
审查规则:
只审查 Go 业务代码中新增和修改的逻辑;优先关注金额计算、错误处理和并发安全。
审查计划:
{
"change_summary": "支付前根据 CouponID 调整扣款金额",
"issues": [
{
"severity": "medium",
"description": "需要确认优惠券抵扣后的金额边界,避免出现负数或零金额扣款",
"tool_guidance": [
{
"name": "file_read",
"reason": "查看 coupon.Apply 的返回值约束",
"arguments": "src/pay/coupon.go"
}
]
}
]
}
请审查当前文件 diff。接下来进入 Review Agent 的审查循环。模型每一轮都会拿到当前 messages 和工具定义,可以做三类主流程动作:
- 读取上下文:例如查看相关文件或其他 diff。
- 提交评论:确认问题后调用
code_comment。 - 结束任务:当前文件审完后调用
task_done。
几个核心工具的作用如下:
| 工具 | 作用 | 典型场景 |
|---|---|---|
file_read |
读取变更后的文件内容 | 需要查看当前文件或相关文件的上下文 |
file_read_diff |
查看本次变更里其他文件的 diff | Plan 建议确认相关文件变更,或当前问题需要跨文件判断 |
code_search |
在代码库里搜索文本或正则 | 需要查调用点、同名方法、配置项或相似实现 |
file_find |
按文件名关键词找文件 | 只知道文件名线索,但不知道准确路径 |
code_comment |
提交结构化审查评论 | 已确认问题,需要进入最终评论列表 |
task_done |
结束当前文件审查 | 当前文件没有更多问题,或评论已经提交完成 |
普通 assistant 文本不会直接变成最终结果。只有通过 code_comment 提交的结构化评论,才会进入评论收集器。单文件主循环结束后,还会做一次评论过滤,删除那些仅凭当前 diff 就能证明错误的评论。例如模型说"新增变量没有被使用",但当前 diff 后续新增代码已经使用了这个变量,这类评论就可以被过滤掉。
到这里,单文件审查结束。executeSubtask 的产物不是最终输出,而是写入评论收集器的评论;如果这个文件失败,它会被记录为 warning,其他文件任务仍然可以继续。
7. 汇总结构化评论并输出
并发分发会启动多个文件子任务,单文件审查会把评论写进评论收集器。汇总输出节点负责全局收尾:等文件都审完,把评论整理成用户能看到的结果。
这个收尾过程主要做四件事:
- 等待所有文件审查结束,确保评论都已经写入。
- 如果所有文件都审查失败,本次审查直接失败。
- 从评论收集器里取出评论列表。
- 对评论做最后整理,再输出给用户或其他系统。
输出前还会补一层结果整理:
- 根据代码变更位置补齐缺失的评论行号。
- 统计审查耗时、文件数、评论数和模型用量。
- 如果没有可审文件,json 模式下输出"已跳过"的状态。
- 根据
--format选择 text 或 json 输出。
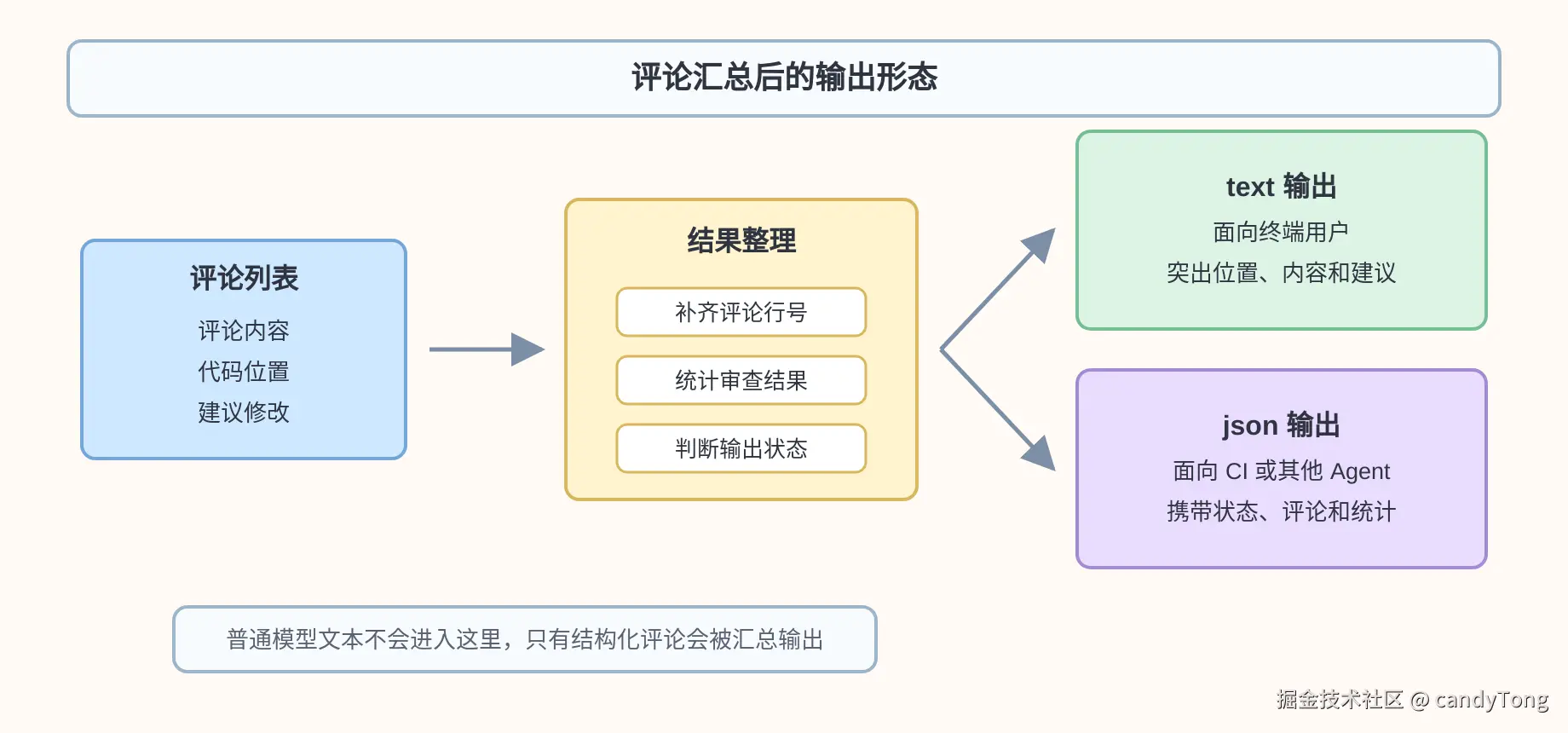
- text 输出面向终端用户,更关注评论位置、评论内容和建议修改。
- json 输出面向 CI 或其他 Agent,会带上 status、summary、comments、warnings 和统计信息。
整条链路到这里才结束:

总结:工程化的关键是可控审查
从工程化角度看,AI Code Review 的难点不只是"模型能不能看懂代码",而是一次审查能不能被稳定地组织起来。审查范围要明确,规则要能配置,执行过程要能补上下文,结果要能结构化输出,失败也要能被记录和处理。
ocr review 的价值正在这里。它没有把 diff 直接丢给一个通用 Agent,而是把审查拆进一条固定链路:用配置和规则约束输入,用审查队列控制范围,用 Plan 降低大文件审查的不确定性,用工具补齐上下文,用结构化评论承接最终结果。
这也是它和"让 Agent 帮我看看代码"的主要区别。前者更像一次可接入流水线的工程任务,后者更像一次临时问答。真正影响落地效果的,不只是模型最终说了什么,而是审查过程能不能被规则约束、被工具支撑、被系统消费。对一个 AI Code Review 工具来说,这些工程边界往往比单次回答质量更重要。
如果你觉得这篇文章有帮助,欢迎点赞、收藏,也可以关注我。