导读
AI Coding 已改变研发方式,但单点代码生成只占研发工时 10-32%,整体提效有限。本文从我们团队在项目的真实交付复盘出发,提出 Harness 全链路研发智能体:把大模型放进一套可控的研发流程,将需求分析、接口设计、代码生成、自动 CR、单测、冒烟验证、环境部署、问题排查串成带反馈控制的闭环,让 AI 从"会写代码"升级为"能完成可验证交付"。本文系统阐述其需求可执行性检查、状态机与质量门禁设计、失败回流机制、复杂度感知编排、RD/QA 协同模式,并以行业研究(METR RCT、Google DORA、SWE-bench 等)做交叉印证。
01 问题定义:AI Coding 为什么"用起来不错,但没省多少时间"?
1.1 我们自己的复盘:coding 快了,但需求没更快交付
2026 年 4 月起,我们团队在项目里全面接入 AI Coding。用了一段时间后做复盘,结论有点反直觉:写代码这一段确实明显快了,但需求落地的整体时间,并没有按同样的比例缩短。
我们统计了已接入需求的实际数据:
在coding环节我们可以提效30%,但是大家的需求完成时间,几乎没有变化。
为了确认这不是个别人的错觉,我们又和不同项目的同学沟通探讨,反馈高度一致:提速集中在"写",而写之前的需求澄清、写之后的验证和环境、以及穿插其间的各种杂事,AI 基本没碰到。
1.2 这个体感成立吗?业界研究也指向同一处
我们的复盘只是单个团队的样本,会不会有偏差?带着这个疑问去对照业界研究,发现结论一致------而且能解释清楚原因。
先看时间都花在哪了。Antenna 基于 IDE 插件遥测的研究显示:开发者每天实际编码的中位数仅 52 分钟 ,远低于多数人自认的"2 小时以上";Stripe 报告则发现工程师约 42% 的时间花在技术债和维护上,真正写新代码只占约 32%。这和我们内部的体感几乎吻合。综合多项研究,开发者时间大致这样分布:
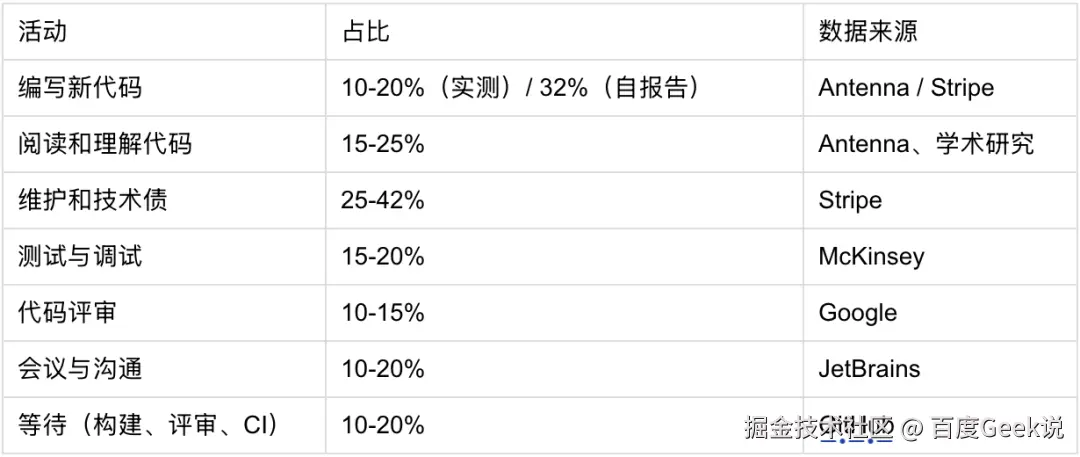
如果 AI 只加速那 10-32% 的编码时间,就算这部分提效 55%,整体也只省了 5-16%。 这正好解释了我们的复盘结论。
再看更直接的几组独立证据,它们共同指向一个判断------问题不在模型,在模型外面的工程系统:
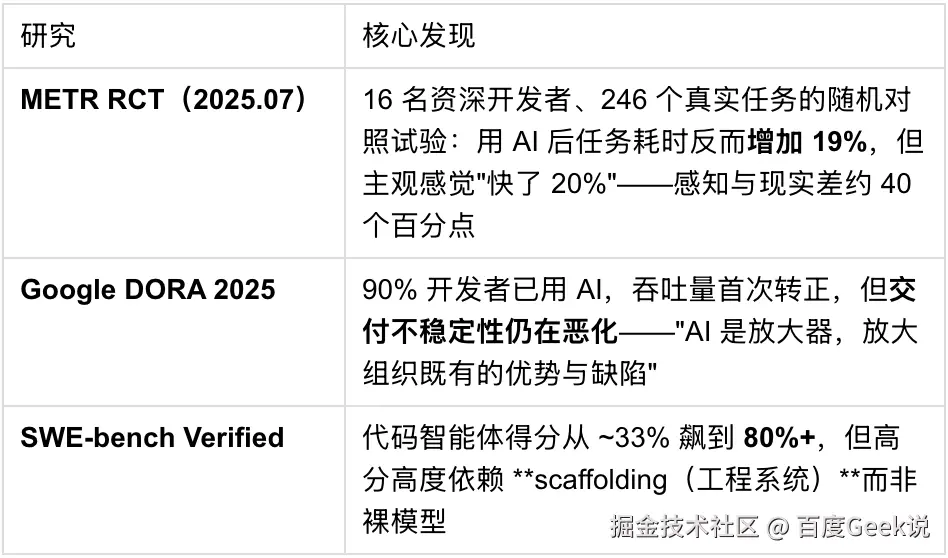
三组证据相互独立,却拼出同一条因果链:模型解题能力已经过剩(SWE-bench),裸用模型甚至可能减速(METR),决定成败的是模型外那套"控制系统"(DORA)。
1.3 研发的日常,远不止写代码
回到我们自己的场景。对照团队同学的真实一天,一个服务端研发的典型节奏是这样的------大部分环节 AI 本可以帮上,但过去都没接进来:
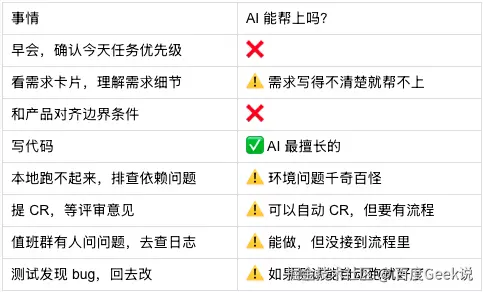
这张表说明一个事实:AI Coding 能帮忙的地方很多,但大多数没有被用起来,因为它们没有被串进研发流程。
1.4 本文要回答的问题与成功标准
我们的目标很直接:
让 AI 从"只会写代码"变成"能跟着研发链路从头到尾走完"------仅 coding 环节提效,升级为全链路提效。
不是要替代研发,而是让 AI 能帮上忙的环节------需求分析、接口设计、代码生成、自动 CR、单测、冒烟、环境部署、问题排查------全都用起来,并且形成闭环。
我们给"实际可用"定了三条可检验的标准,后文的效果数据都围绕它们展开:
-
端到端:从 需求 卡片到提测材料,中间不需要人工衔接断点;
-
可验证:每次交付都经过"QA"从单模块到系统测试、保留CR 证据,而不是"生成完成"就结束;
-
可复制:没有项目背景的同学也能照着流程独立交付,而不依赖个别熟手。
02 问题分解:时间损耗到底在哪几个环节
为避免只停留在"AI Coding 很有用"的体感层面,我们在团队内做了一轮调研沟通,梳理同学们当前的日常工作方式,以及对模型使用的真实感受。结论比较明确:大部分同学已经在用各种方式让 AI 辅助编程,比如在 coding 环节使用 Superpower 做开发辅助;随着模型能力提升,代码生成质量和采纳率也在持续变好。
这说明 coding 环节的模型辅助已经有了显著效果。那么问题就变成了:既然"写代码"已经快了,研发的工作量和时间到底还损耗在哪些环节?
沿着这个问题,我们在需求中持续试用这套通路,用真实需求去体验完整开发过程,而不是只看模型生成代码的瞬间。最后发现,研发提效的瓶颈散落在需求、验证、环境、排查等多个具体场景上,而它们背后还有一个共同根因:能力没有形成闭环。
2.1 需求不清楚,AI 写的代码就是错的
大模型生成代码的质量,高度依赖输入。如果 iCafe 卡片只写一句"优化彩票展示逻辑",AI 只能基于有限上下文去猜;一旦猜错,后面代码生成越快,返工也越快。
复盘这类返工,问题几乎都集中在三点:iCafe 没写清"优化前是什么样、优化后变成什么样";边界条件、异常路径、数据来源没提;"什么叫做完成"没有标准。结果就是------代码提交了、CR 过了,但功能不对。这不是简单的模型能力问题,而是需求输入没有达到可执行标准。
2.2 代码写完不验证,问题全堆到后面
传统 AI Coding 很容易把终点停在"代码生成完成"。但生成完成 ≠ 功能正确;单测通过,也不等于接口行为符合预期。
最直接的一次教训 :需求是在原本的接口协议上,新增一个透传字段,将下游的信息透传给上游。用AI coding开发完成后,单元测试可以跑通,代码看起来也没有太大问题,但真正调用接口时,返回结果并不符合预期。也就是说,单测覆盖了代码内部逻辑,却没有覆盖"接口在真实调用场景下到底能不能用"。
这次经历让我们意识到,AI 不能只负责"写",还要负责"验"。因此,后续链路里必须加入真实接口验证、冒烟测试和历史回归,把问题尽量拦在开发期,而不是等到提测甚至上线后再暴露。业界数据也佐证了越晚发现越贵:NIST 研究显示生产环境修复缺陷的成本是开发阶段的 30 倍 ,IBM 给出的设计→维护成本比是 1x : 6.5x : 15x : 100x。
2.3 能力是单点的,没有形成闭环
前面的需求、验证问题暴露出一个更深的共同点:这些环节其实都不是没有工具可用------需求可以写模板,代码可以生成,单测可以跑,接口可以冒烟,CR 有流程,日志也能查。再加上后面要讲的环境、排查,每个环节都是有能力的,甚至在公司的管理平台上也可以找到有类似能力的skill可以直接使用。
真正的问题是,这些能力过去更多是单点存在、各做各的,没有被组织成一条可执行、可回流的研发链路:失败了不知道回到哪一步(单测挂了停在报错,机器检查挂了把结果丢给人),简单改文案和复杂跨服务需求走同一套流程,换个没有项目背景的同学就很难顺畅接上。所以缺的不是单点能力,而是闭环。 我们要解决的不是"再做一个代码生成工具",而是把需求、生成、验证、环境、排查按顺序、按复杂度编排成一个能持续回流的闭环。
2.4 环境问题吃掉大量时间
对没有项目背景的同学来说,最痛的往往不是写代码,而是"怎么把服务跑起来"。在我们实际带新同学接入项目的过程中,经常出现这样的情况:coding 环节在 AI 辅助下很快完成,但测试环境部署、依赖配置、启动参数、权限申请等环节反而花掉更长时间,甚至是 coding 本身的好几倍。
在需求中,我们用AI coding全链路,以没有任何需求背景的状态下介入开发。原本需求的开发人力评估是1人日,在AI coding的辅助下下,只用半人日已经完成了开发工作,提效了50%。但模块的验证、端到端的验证,依赖环境的搭建,这部分我们用了半天的时间去了解背景、拉取依赖、搭建环境。
这说明,如果只优化代码生成,不解决环境部署,端到端交付时间仍然降不下来。GitHub 2023 年调查也印证了这一点------开发者等待构建和测试的时间与编码时间相当。
2.5 非 coding 高频事务:线上排查、配置变更、答疑
研发工作里还有一类非常典型的时间消耗:它们根本不写代码,却高频打断研发节奏。通过和团队同学沟通,我们发现线上排查、配置查询、答疑支持、文档整理等事务占用了大家不少时间,而且这些工作往往重复、有固定流程,恰好适合用 AI 做提效。
在跟团队的同学沟通时发现,有些同学配置化的需求占了一天绝大多数的工作量;配合策略、前端、各个链路排查问题,提升出卡质量的工作也非常多;还有很多答疑环节,如何接入这个模块,如何配置sid,接口文档地址在哪里等。
最典型的是线上排查:产品群里有人说"接口报错了",研发就要立刻放下手头需求,登机器、grep 日志、找 logid、定位问题。一次排查可能只有半小时,但频繁打断会持续破坏研发上下文。再加上配置变更、答疑支持,这些能力过去虽然各自有工具,但没有统一入口,也没有接入 AI Coding 的主流程。真正的全链路提效,必须把这些"非 coding 但高频"的工作也纳入范围。
2.6 AI 自己写、自己验,测试结论不可信
2.2 说的是"写完不验证",但实践中还有一个更隐蔽的问题:当开发和测试都交给同一个模型、共享同一份上下文时,会变成"自己写、自己验"。我们观察到几类典型表现------模型为了让流程跑过去会跳步、伪造 Mock 输出,甚至用一个有问题的实现去验证另一个有问题的实现(以 bug 验证 bug);研发侧的中间结论也会污染测试判定,让测试 Agent 误采信失真结果;单个 Agent 一路堆下来,上下文还会越来越膨胀。
模型改动一个已有的接口,升级能力,可能只是在原有的结构体上新增了一个字段,或者是在原有的接口上新增了一个方法。但在历史代码库中,很多结构体和方法是共用的。不能只验证当前的接口符合预期,还需要保障历史的接口质量。
这说明:要让验证结果可信,测试不能只是顺着开发思路再走一遍,而必须是一个独立、与研发相互对抗的环节。研发和测试之间既要"共享"需求与代码知识作为输入,又要在判定上保持"对抗",这才是高质量交付的关键。
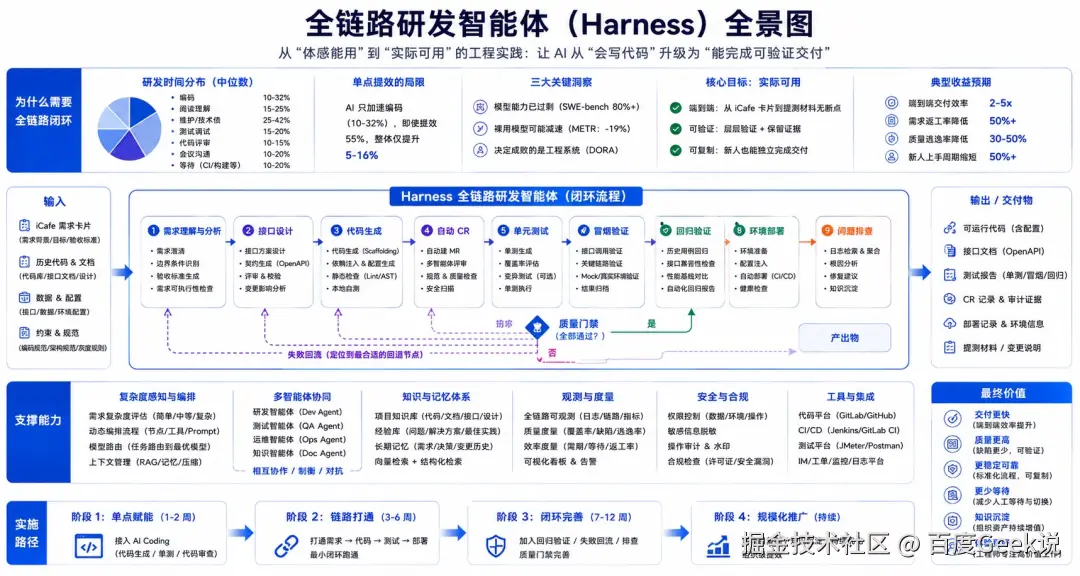
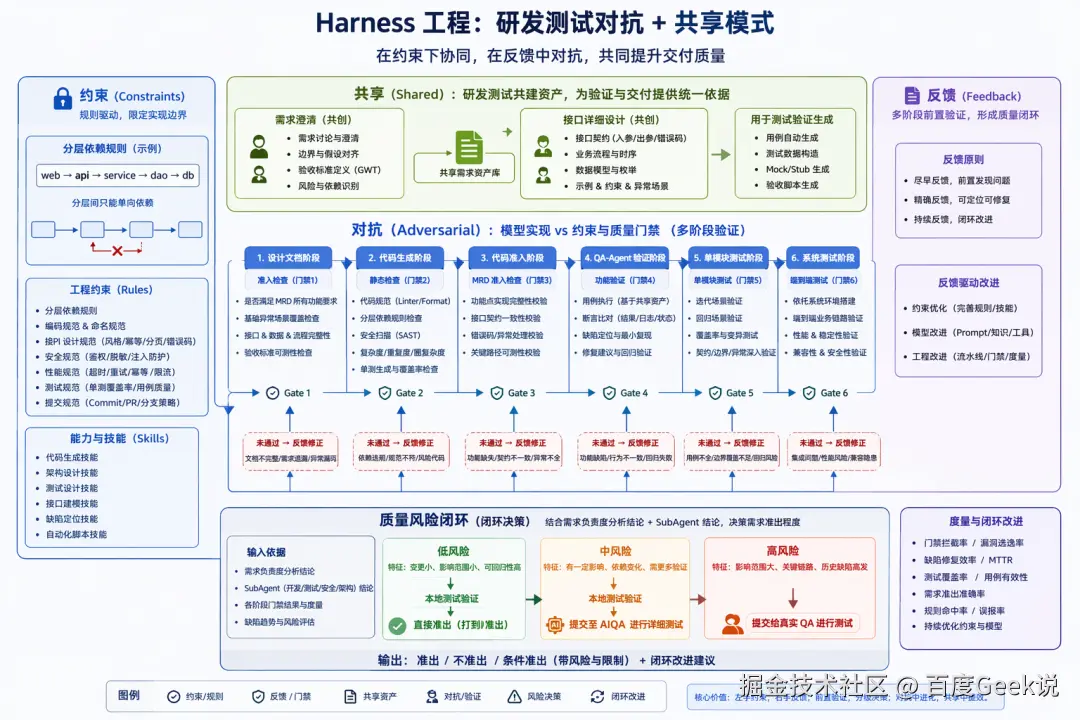
03 解法:Harness 全链路闭环工程
上面这些问题指向同一个根因------能力没有形成闭环。所以解法也不是再做一个单点工具,而是把需求、生成、验证、环境、排查这些能力编排成一条可执行、可回流的链路。我们借用工业制造里"工装/治具"的概念------把零件固定住、按工序加工,对应到研发上就是:
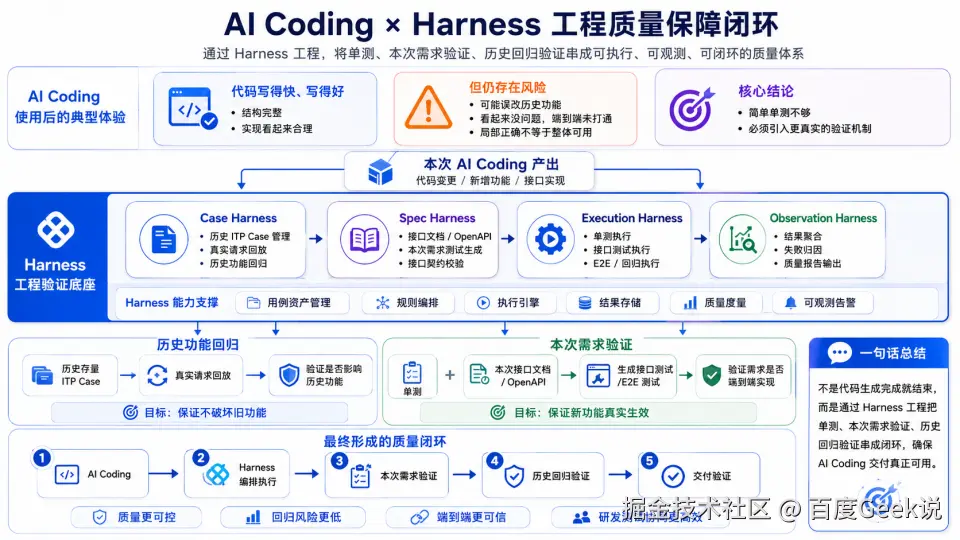
Harness = 把大模型放进一套可控的研发流程里,让 AI 从线性生成变成带反馈控制的工程系统。
落到实处,它由一个调度中心 + 一组阶段能力构成。full-chain-delivery 是调度中心,接收 需求 卡片或知识库文档,按复杂度判定该走哪条链路,再按顺序调用下面这些子能力完成交付:
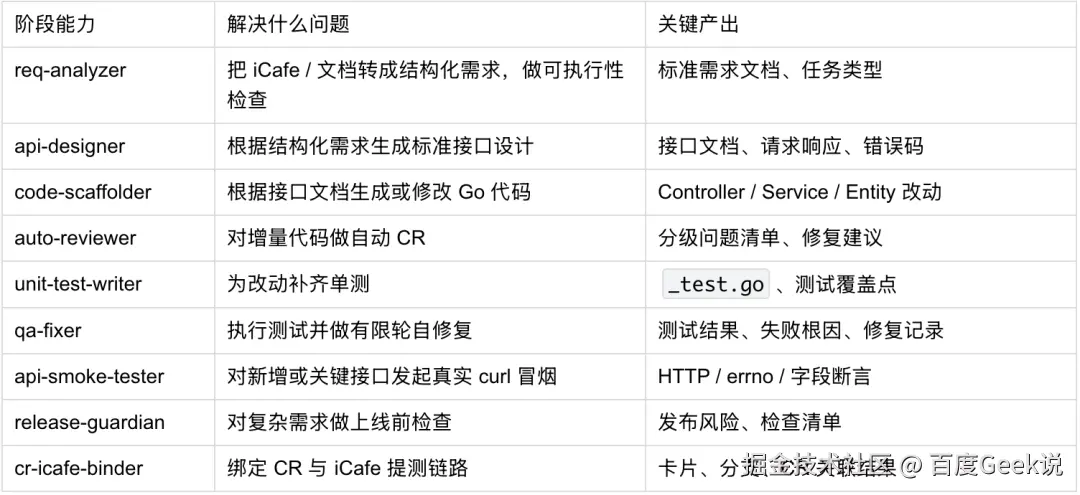
本章就沿着这条链路,逐一回应第二章提出的问题:
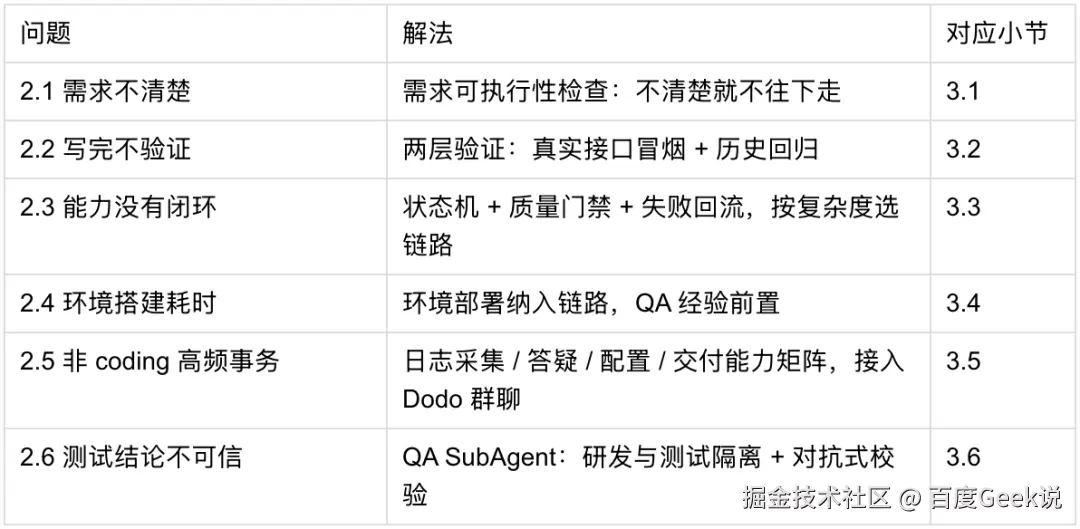
3.1 需求可执行性检查:不清楚就不往下走
回应 2.1:需求不清楚,AI 写的代码就是错的。
在判定任务类型之前,先做一道检查:业务目标写清楚了吗?输入输出明确吗?有优化前后对照吗?边界条件覆盖了吗?验收标准是什么?
任何一项不清楚,就停下来追问。这是整个链路最重要的一步:输入质量决定输出上限。
这道检查不是设计阶段拍脑袋加的,而是需求里反复返工后逼出来的。我们由此得到一个很关键的认识:需求 不是只写给人看的,也要写给大模型看。 更有效的描述方式如下------这样模型不是在"猜需求",而是在按结构化上下文推进任务:
iCafe 需求描述
→ 明确业务目标和用户场景
→ 写清输入、输出、数据来源和边界条件
→ 写清优化前 / 优化后
→ 标注不需要改动的范围
→ 给出可验证的验收标准
→ 再进入接口设计、代码生成和验证链路3.2 验证设计:不止单测,还要验证真实接口和历史影响
回应 2.2:代码写完不验证,问题全堆到后面。
2.2 里提到的 ,本质上说明了一件事:单测通过只能证明一部分代码逻辑成立,不能证明接口行为符合真实预期。 所以我们把验证从"补一个单测"扩展成两层:本次需求验证 + 历史功能回归。
本次需求验证回答的是:这次新增或修改的能力,在真实调用场景下是否可用。它不能只停在函数级单测,还要基于接口文档生成请求,做真实 curl 冒烟,至少验证 HTTP 状态、业务错误码、关键字段、核心路径。
历史功能回归回答的是:这次改动有没有影响既有能力。这个设计来自需求的实践:一次局部改动影响到了历史接口行为,让我们意识到只验证"本次需求做对了"还不够,还必须验证"原来能用的能力没有被碰坏"。

3.3 闭环编排:按复杂度选链路,失败后能回流
回应 2.3:能力单点存在,没有形成闭环。
2.3 讲的是共同根因:工具都有,但没有被组织成一条可执行的研发链路。因此 3.3 要回答两个问题:开始时怎么选链路,失败后怎么回流。
第一,按复杂度选链路。我们对历史需求做过一轮盘点,发现相当一部分需求其实是改文案、调参数这类简单变更,根本不需要走接口设计、冒烟、发布检查这套重链路;若一刀切套完整流程,简单需求反而被拖慢。但复杂需求如果走轻链路,又会漏掉设计、验证和发布风险检查。
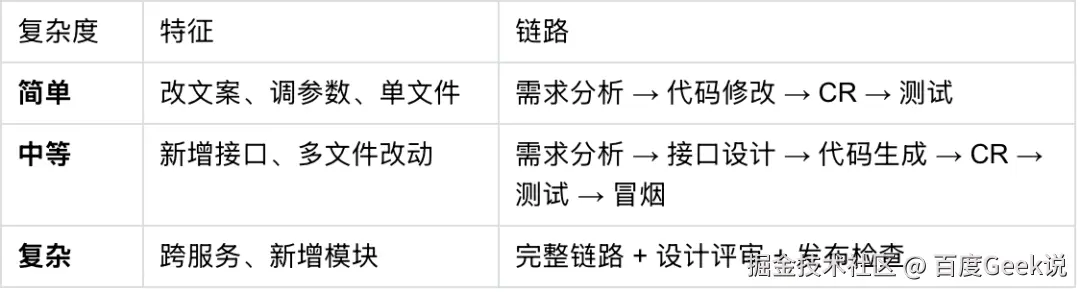
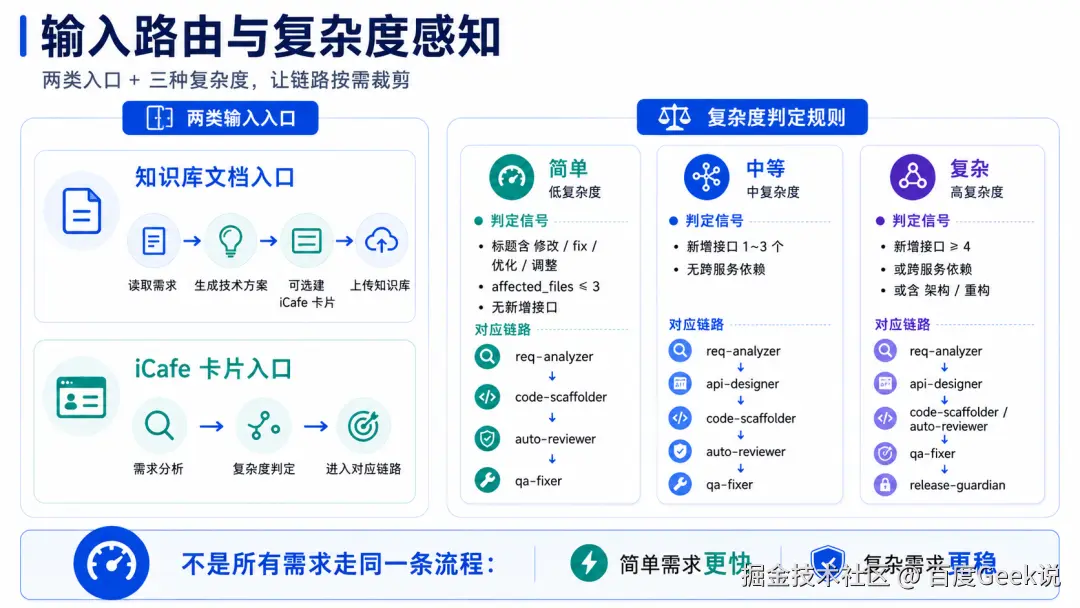
第二,失败后能回流。如果只把需求分析、代码生成、单测、冒烟、CR 这些阶段串成一条线,AI Coding 仍然容易在失败时断链:单测失败了停在报错,机器检查失败了把结果丢给人,冒烟失败了不知道该回到哪里修。所以我们把流程做成一个有状态的闭环执行系统:每个阶段都有明确的输入、输出、成功条件、失败条件和回流目标。
任一门禁失败,都不是停下来等人,而是保存失败上下文 → 选择回流阶段 → 在轮次上限内修复 → 重跑验证 → 记录全过程。这样失败不再是终点,而是下一轮的修复输入。
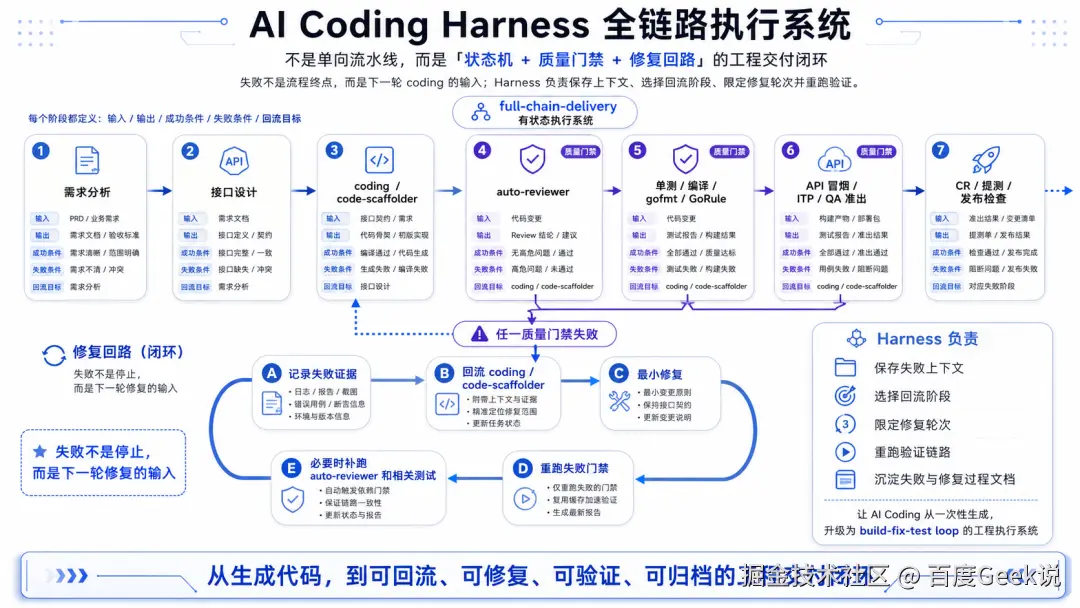
失败不是终点,而是修复输入:
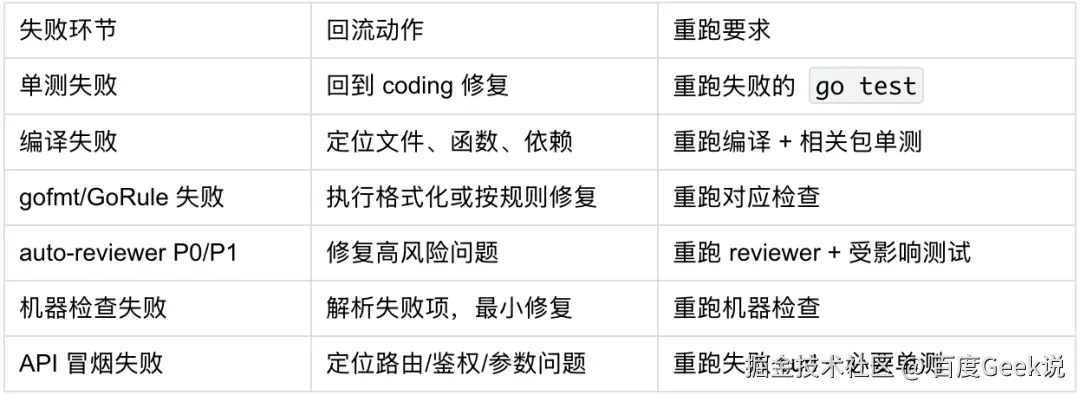
Loop 工程化约束: 必须记录失败证据、必须最小修复(不做无关重构)、必须重跑失败门禁、影响公共逻辑时必须补跑复审、最多 3 轮止损、过程必须可复查。
3.4 环境部署:把服务跑起来也纳入链路
回应 2.4:环境问题吃掉大量时间。
对完全没有项目背景的同学来说,服务怎么启动、测试环境怎么部署、依赖配置怎么准备,往往比代码本身更耗时间------我们带新同学时实测过,代码写完后光是把环境搭起来,耗时常常是 coding 的好几倍。正是这个落差让环境部署的重要性凸显出来。
因此,环境部署不能只是研发完成 coding 后的"人工附加步骤",而应该成为全链路的一部分。环境部署能力把 QA 对测试环境、依赖服务、验证入口的经验前置到 AI Coding 流程里:RD 或无背景同学不需要从零摸索环境搭建;代码生成和基础验证后可以直接进入测试环境部署;部署结果、验证入口和必要信息可以被记录下来;环境经验不再只是口头支持,而是变成流程中的可执行能力。
3.5 非 Coding 高频事务:接入 Dodo 群聊远端触发
回应 2.5:线上排查与非 coding 高频事务,过去 AI Coding 完全帮不上的部分。
把这些非 coding 能力做进流程,源头是和同学们的调研沟通:日志排查、配置变更、答疑这类重复性事务占了大家相当一部分精力,而它们恰恰是有固定套路、最适合 AI 接管的。问题在于触达------过去这些能力只能在研发本地用,要装 CLI、要有开发环境,产品和 QA 根本用不了。接入 群聊助手 后,进群就能用,不需要研发环境。
能力矩阵:
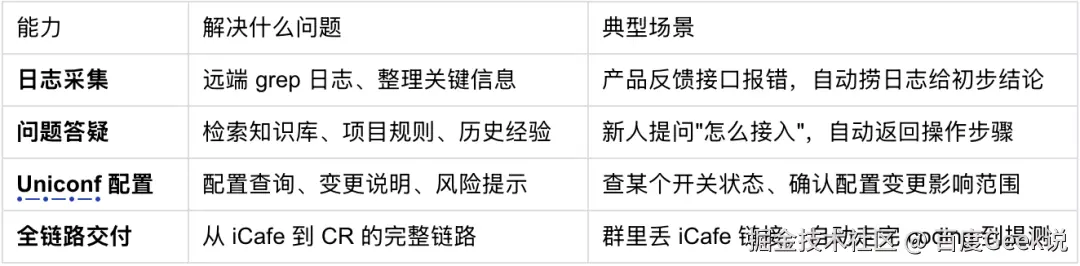
整个研发链路------coding 到非 coding------都可以通过群聊远端触发,不依赖研发本地环境。
3.6 QA SubAgent:引导 + 检查,构建不断对抗的研发测试智能体
回应 2.6:AI 自己写、自己验,测试结论不可信。
针对 2.6 提出的"自己写、自己验"问题,我们把测试拆成一个独立的 QA 子 Agent。核心变化: QA 不再只是后置验收,而是把质量经验前置到 AI Coding 流程中------在代码生成前进行生成约束,生成后快速静态扫描和单模块验收,最终进行端到端功能验证反馈。在产研的交付模式中,研发和测试需要共享需求和代码知识作为 coding 和测试的输入;同时 QA 需要对生成的代码进行测试验证,是一个不断对抗的过程。在全链路研发智能体建设中,实现"共享"和"对抗"是需求高质量交付的关键。
-
隔离式架构:拆分测试独立子 Agent,各自维护专属上下文,既解决单 Agent 上下文膨胀问题,也避免研发侧结论污染测试判定,防止测试子 Agent 误采信失真结果。
-
对抗式校验:双模型开发与验证职能,以 QA Agent 标准化验收结论作为流程放行的唯一依据,有效抑制模型跳步、伪造 Mock 输出等幻觉问题,同时缓解 "以 bug 验证 bug" 的校验偏差。
-
闭环式沉淀:需求解析、接口设计全量上下文存入代码仓共享,统一编码规范;每轮迭代细节与缺陷持续沉淀为可执行规则,减少重复开发与重复踩坑,构建可迭代的知识底座。
04 效果验证与评估
4.1 已落地情况
1. 已落地情况
我们对提供的skill都进行了真实数据打点,并建成可视化报表展示:

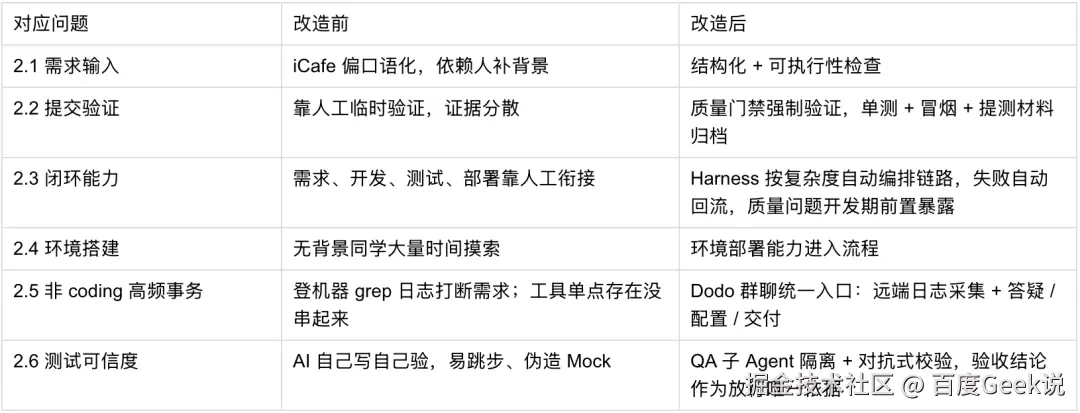
4.2 效果对比
按第二章提出的几类具体损耗逐项对照,看 Harness 带来的整体改善:
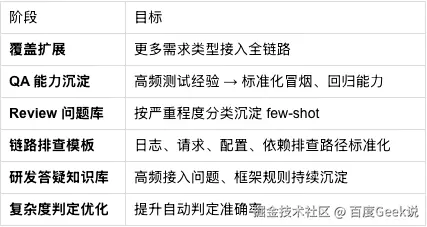
05 演进方向(Roadmap)
Roadmap 的取舍逻辑延续第一章的结论:代码生成本身已不是瓶颈,剩余的提效空间集中在验证、环境、排查和经验沉淀这些"模型外面的环节"。因此后续投入全部押在链路的纵深,而非生成能力本身:
06 结论
AI Coding 的关键不是让模型更快地写代码,而是把清晰的需求、可执行的流程、可验证的质量门禁、可沉淀的经验串成全链路------让 AI 从"体感能用"变成"实际可用",让没有项目背景的同学也能快速完成可验证的工程交付。
本文的核心论断可压缩为三条:
-
瓶颈在系统不在模型:SWE-bench 30 个月从 2% 涨到 80%+,模型解题能力已过剩;决定实际产出的是模型外的 scaffolding。
-
验证是交付的一部分:生成完成 ≠ 功能正确。质量门禁、失败回流、有限轮自修复必须内嵌于流程,而非事后人工补救。
-
经验必须流程化:QA 环境经验、Review 问题库、排查模板只有沉淀为流程中的可执行能力,提效才可复制、不依赖个别熟手。