都AI时代了,谁还在花时间写重复的底层逻辑,浪费时间就算了,还容易出 Bug。优秀的开发者,像我,通常会积极寻找已经过验证的开源工具。
我精选了 9 个实用的 Python 第三方库,涵盖文件监控、音频处理、解析、日志以及任务调度等常见场景。合理利用这些工具,可以显著优化代码库,帮助团队专注于核心业务逻辑。
Watchdog:高效的 Python 文件监控方案
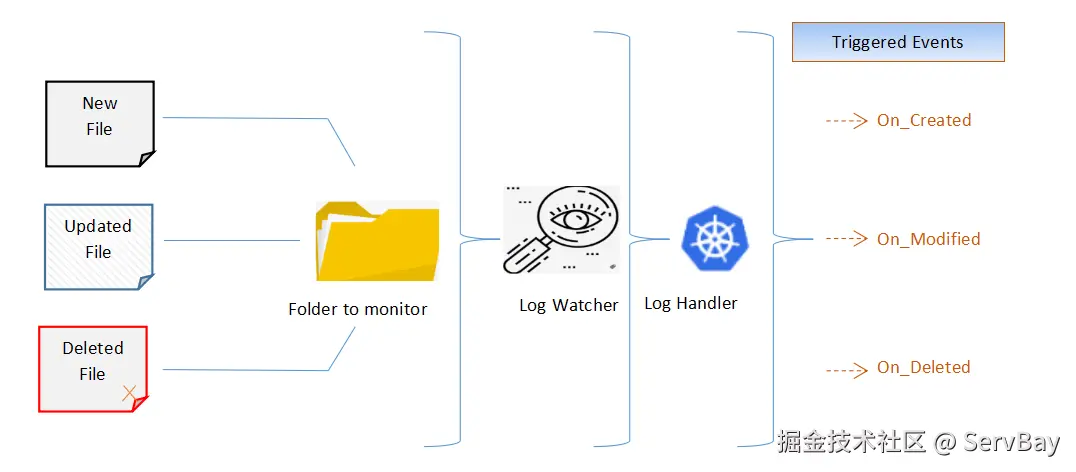
数据处理或日志清晰时,需要实时获取特定目录下的文件变化。如果使用循环加延时的方法去轮询检测,不仅浪费 CPU 资源,还会产生明显的反应滞后。
Watchdog 直接对接操作系统的内核事件(例如 Linux 的 inotify 或 Windows 的 ReadDirectoryChangesW),在文件发生创建、修改或删除时立即触发回调,运行开销极低。
python
import time
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
class JsonConfigHandler(FileSystemEventHandler):
def on_modified(self, event):
# 仅监控 json 文件的修改事件
if event.src_path.endswith('.json'):
print(f"检测到配置文件修改,文件路径为 {event.src_path}")
observer = Observer()
# 监控当前目录下的 config 文件夹
observer.schedule(JsonConfigHandler(), path="./config", recursive=False)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()- 使用建议:如果监控的是网络挂载盘(如 NFS 卷),由于操作系统底层的限制,事件通知可能会存在延迟或丢失,在分布式存储环境下需谨慎测试。
Pydub:告别复杂命令的 Python 音频处理库
处理音频数据时,调用底层 ffmpeg 命令行虽然能解决问题,但维护拼装好的 shell 字符串会让代码变得难以阅读和调试。
Pydub 封装了底层的音频解析细节,提供了简洁的 Python 接口。开发者可以通过几行代码完成音频合并、音量调整以及格式转换等日常操作。
python
from pydub import AudioSegment
# 导入不同的音频文件
intro = AudioSegment.from_mp3("intro.mp3")
podcast = AudioSegment.from_mp3("podcast.mp3")
# 合并两段音频,并为结尾添加 2000 毫秒的淡出效果
combined_audio = intro + podcast
final_output = combined_audio.fade_out(2000)
final_output.export("final_podcast.mp3", format="mp3")- 使用建议:使用该库前,系统环境变量中必须正确配置好 ffmpeg 的路径,否则将无法处理 mp3 等非 WAV 格式的音频。
Selectolax:速度大幅提升的 BeautifulSoup 替代方案
如果你需要解析海量网页数据的爬虫或数据挖掘项目,BeautifulSoup 的解析速度在大规模高并发场景下有可能会成为瓶颈。
Selectolax 底层采用 C 语言编写的 Modest 或 Lexbor 引擎,在保持 CSS 选择器语法习惯的同时,解析速度和内存占用表现出色,非常适合处理复杂的 HTML 文档。
python
from selectolax.parser import HTMLParser
html_content = """
<div class="product-list">
<div class="product">
<span class="title">Python入门教程</span>
<span class="price">99.00</span>
</div>
</div>
"""
tree = HTMLParser(html_content)
# 使用 CSS 选择器快速定位元素并提取文本
title_node = tree.css_first(".title")
price_node = tree.css_first(".price")
if title_node and price_node:
print(f"解析结果为 书名 {title_node.text()}, 价格 {price_node.text()}")-
使用建议:由于 Selectolax 更加专注于解析效率,它的社区文档和周边生态相对 BeautifulSoup 较少,遇到复杂解析场景时需阅读其官方文档中的选择器规范。
Pendulum:解决复杂时区转换的 Python 日期库

Python 原生的 datetime 模块在处理时区转换、夏令时以及跨区域时间差时,代码往往较为繁琐,一不小心就可能引入导致业务受损的时区 Bug。
Pendulum 能够完全兼容原生的 datetime,同时提供了更加直观的时间跨度计算和时区切换功能,避免了繁琐的转换步骤。
python
import pendulum
# 获取当前上海时间
now = pendulum.now("Asia/Shanghai")
# 增加 2 周零 3 天
future_time = now.add(weeks=2, days=3)
# 计算时间间隔
time_difference = future_time.diff(now)
print(f"相差天数共 {time_difference.in_days()} 天")
print(f"格式化日期为 {future_time.to_date_string()}")- 使用建议:当涉及到金融、账单、跨国排程等对时间精度要求极高的场景,使用 Pendulum 可以显著降低时区计算出错的概率。
IceCream:替代传统 print 的 Python 调试工具
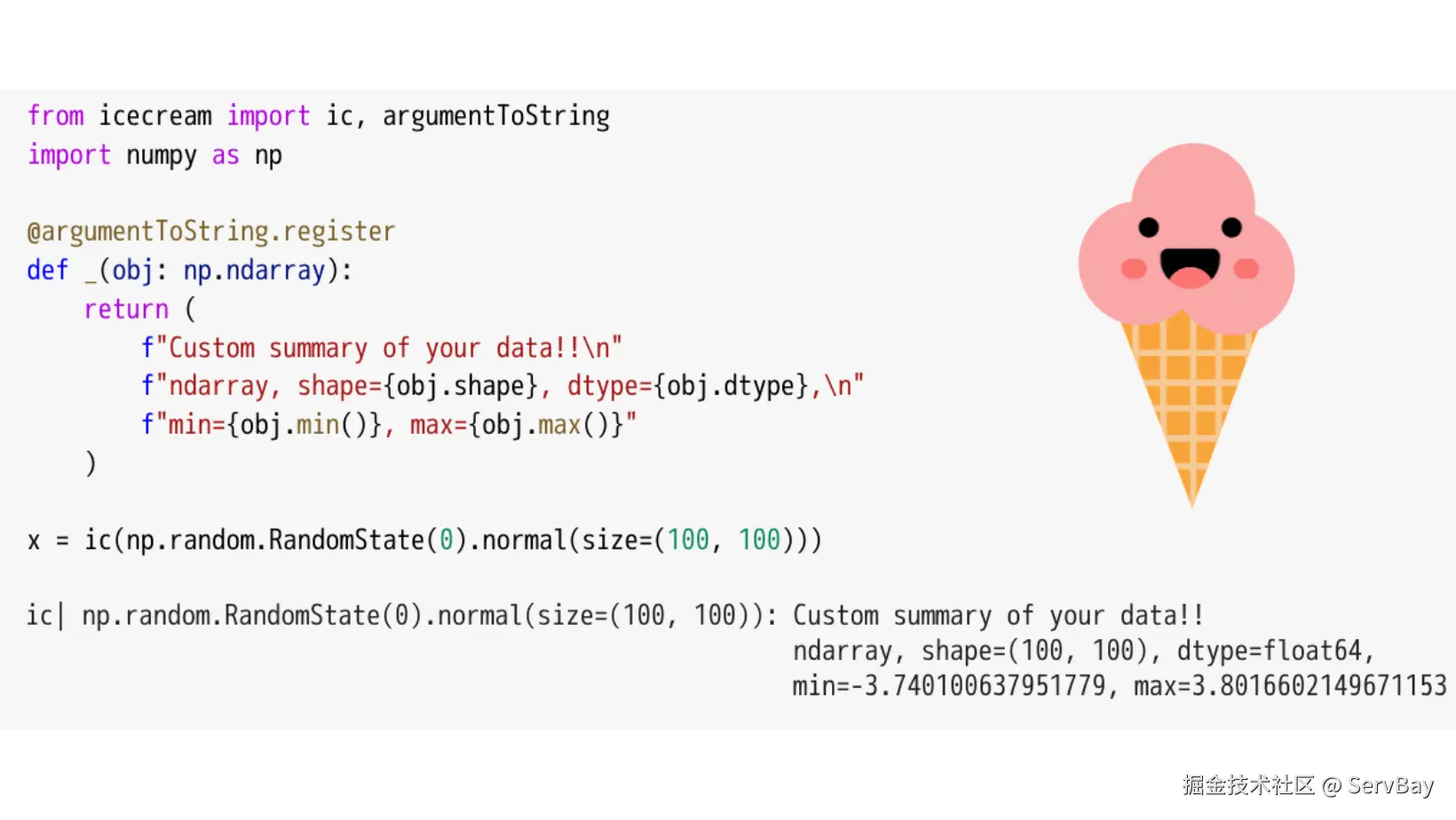
许多开发者习惯在代码中穿插 print(value) 来定位问题,但输出的内容如果没有上下文,在终端中很难分辨其对应的变量名以及具体的调用行数。
IceCream 专为本地开发和排查问题设计,调用时不仅输出变量值,还能自动附带变量名、函数名以及所在的文件行号。
python
from icecream import ic
user_data = {"id": 101, "role": "admin"}
# 自动打印变量名、所在行以及内容
ic(user_data)
def get_discount(level):
return 0.15 if level > 5 else 0.05
# 打印函数调用结果和传入参数
ic(get_discount(8))- 使用建议:该库主要用于本地调试阶段,项目正式部署到生产环境之前,应当将其替换为标准的日志系统。
Loguru:开箱即用的现代 Python 日志库
标准的 logging 模块配置繁多,对于中小型项目,则需要编写几十行初始化代码才能实现日志颜色分类、文件自动轮转和压缩。
Loguru 精简了配置流程,提供了极简的 API 设计,并默认开启美观的控制台输出,支持自动归档和错误回溯。
python
from loguru import logger
# 添加日志文件,设置每天凌晨自动切分归档
logger.add("app_error.log", level="ERROR", rotation="00:00")
logger.info("系统启动成功,核心模块已加载")
logger.error("数据库连接超时,正在尝试自动重连")- 使用建议:在多模块协作的超大型项目中,如果其他依赖库强绑定了标准库的 logging,可以使用 Loguru 提供的适配器进行全局劫持和重定向。
Typer:快速生成 CLI 命令行工具

为开发团队编写辅助脚本时,命令行参数的校验和帮助文档通常要花费不少精力。
Typer 基于 Python 3 的类型提示功能,能够自动将普通的 Python 函数包装为规范的 CLI 命令行工具,并自动生成 --help 文档。
python
import typer
app = typer.Typer()
@app.command()
def backup(source_dir: str, target_dir: str, force_overwrite: bool = False):
if force_overwrite:
print(f"执行强制覆盖备份,从 {source_dir} 到 {target_dir}")
else:
print(f"执行常规备份,从 {source_dir} 到 {target_dir}")
if __name__ == "__main__":
app()- 使用建议:由于 Typer 是基于 Click 库构建的,它完美支持自动补全等进阶功能,但在超轻量、无外部依赖的单文件脚本中,原生 argparse 仍然是更轻量级的方案。
Faker:自动生成测试数据的得力助手

在前后端联调或编写单元测试时,构造各种逼真的用户数据真的是枯燥又麻烦。
Faker 支持高度本地化的数据数据生成,能够快速输出姓名、地址、电子邮箱、公司和职业等信息。
python
from faker import Faker
# 初始化中文数据源
generator = Faker("zh_CN")
# 批量生成 3 条模拟数据
for _ in range(3):
profile = {
"姓名": generator.name(),
"公司": generator.company(),
"职位": generator.job(),
"邮箱": generator.free_email()
}
print(profile)- 使用建议:生成的数据属于伪随机数据,只能用于非生产环境的功能测试或性能压测,不能替代真实业务逻辑中的复杂业务校验。
APScheduler:应用内轻量级 Python 定时任务框架
很多场景下,我们只需要在应用中定期执行一小段清理工作或状态同步,如果引入外部的 Celery 或配置操作系统的 Crontab,会增加运维部署的复杂性。
APScheduler 是一个运行在 Python 进程内的任务调度框架,支持秒级、分钟级、固定间隔以及类似 Cron 的定时设置。
python
import time
from apscheduler.schedulers.background import BackgroundScheduler
def clean_expired_sessions():
print("定时任务触发,正在清理过期会话数据")
scheduler = BackgroundScheduler()
# 设置每隔 10 秒钟执行一次清理函数
scheduler.add_job(clean_expired_sessions, 'interval', seconds=10)
scheduler.start()
try:
while True:
time.sleep(1)
except (KeyboardInterrupt, SystemExit):
scheduler.shutdown()- 使用建议:该调度器属于单进程方案。如果项目部署在多实例的集群或容器云环境下,可能会导致定时任务在多台机器上重复执行,此时需要采用外部的锁机制,或者转向外部的分布式调度系统。
高效环境管理方案,多版本 Python 环境的一键部署
随着项目和业务的增加,不同的应用程序难免会依赖不同的第三方库版本,甚至不同的 Python 运行时。管理这些相互独立的开发环境,避免系统路径被污染,成了另一项耗费精力的基础工作。
对于在本地进行开发的团队,使用 ServBay 能够大幅简化本地环境的配置与日常维护。
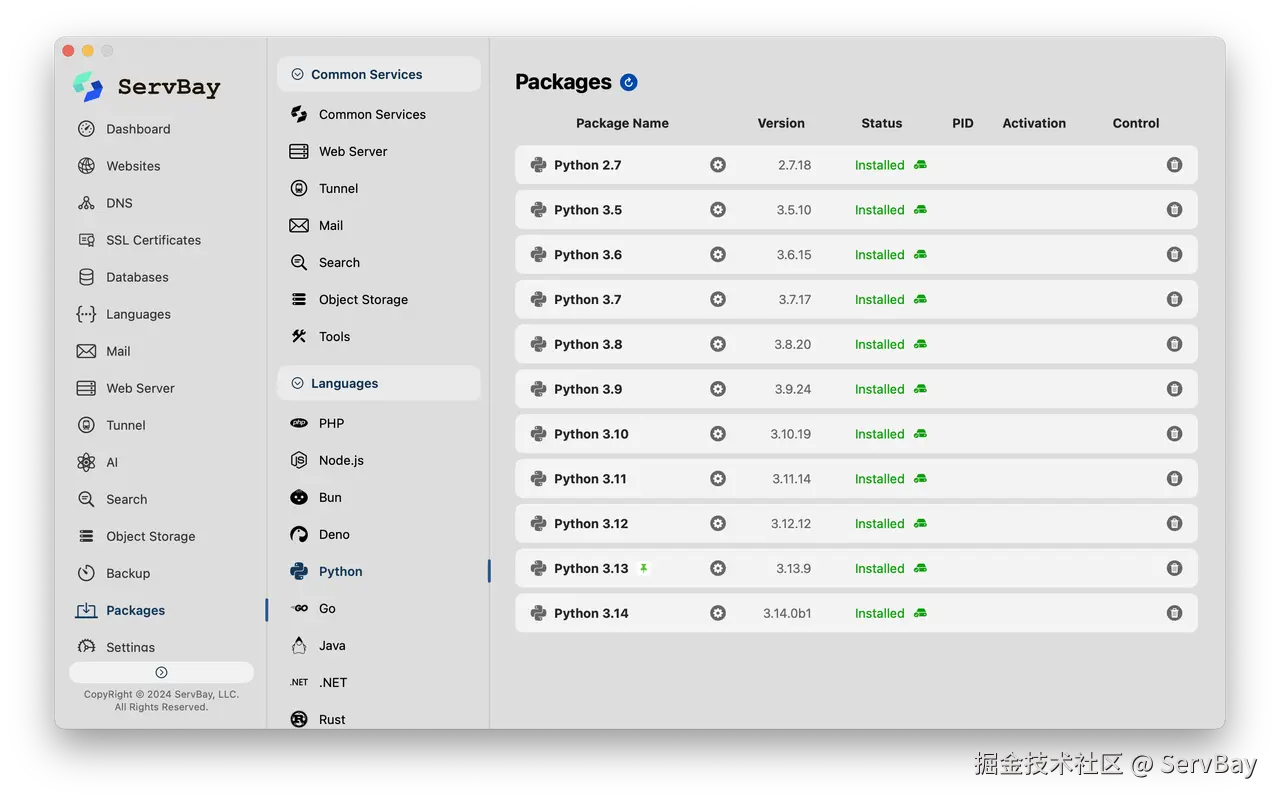
ServBay 支持在 macOS 和 Windows 操作系统下进行图形化一键部署Python。它提供了对多个 Python 版本的完整支持,从 legacy 2.7 以及 3.5 到最新的 3.14 版本)。
-
一键安装与升级:开发者无需编写复杂的 shell 脚本或手动配置复杂的系统环境变量,即可通过图形化界面快速部署指定的 Python 运行时。
-
多版本无冲突并存:不同的项目可能使用完全不同的 Python 版本进行开发。ServBay 支持多版本 Python 环境的并行运转,并自动接管虚拟环境的管理,隔离依赖,消除了因全局依赖冲突引发的问题。
通过配合使用 ServBay 管理底层开发环境,团队可以将更多精力保留在业务代码的编写和上述第三方库的集成应用上。
总结
在现代软件工程实践中,开发效率的优化往往来自于对底层细节的合理精简。本文介绍的 9 个第三方库,从文件监听(Watchdog)、音频转换(Pydub)、高效解析(Selectolax)到环境调试(IceCream、Loguru、Typer、Faker)及定时任务管理(APScheduler),分别在具体的应用维度上解决了常见的开发痛点。根据项目的实际规模和底层架构,合理选型这些工具与管理方案,有助于实现更加敏捷、稳定的项目交付。