一、背景介绍
代码评审是把控研发质量、规范编码风格的核心环节,在实际落地过程中,传统人工评审、通用静态扫描工具以及直接将原始代码交由大模型审查的方式,均存在明显短板,难以满足团队高质量、高效率的代码管控需求。
1、人工Review效率低,审查标准不统一,落地困难
日常研发任务紧张,人工评审需要耗费大量精力处理重复问题,效率偏低。同时不同人员评判标准存在差异,评审结果主观性强,难以保障代码质量稳定。
2、现有的静态分析工具存在局限
SonarQube 等工具采用全量扫描,会产生大量无关告警,噪音干扰严重。且这类工具仅依靠规则匹配,无法解析代码语义、梳理调用关系,难以识别深层次代码问题。
3、直接使用原始代码调用大模型,方式粗放且不可靠
未经处理的代码包含冗余内容,易超出大模型上下文限制,还存在 Prompt 注入风险。缺少全局上下文与评审规则会导致分析片面,加之大模型存在幻觉问题,常输出定位模糊、无法落地的建议,额外增加研发负担。
为此,我们采用多层约束架构,结合 AST 语义分析与 LLM 多模型调度能力,打造智能化增量代码审查系统。通过全流程管控输入、执行、评审、输出环节,实现增量代码自动化、精准化审查,提升评审整体效率与质量。
二、实践目标
基于AI大模型的能力,搭建一套智能化增量代码自动评审系统,实现以下目标:
- 自动识别增量代码中的逻辑错误、安全漏洞、性能隐患等问题,生成带有修复建议的审查报告
- 结合项目全局上下文进行审查,不仅看变更文件本身,还理解它在项目中的调用关系和依赖
- 过滤噪音,区分纯格式化改动和真正的逻辑变更,减少无意义的审查告警
- 支持多种部署方式,CLI本地使用、Web服务团队共享、CI/CD流水线自动触发
- 与QA人员形成互补,AI处理80%的规律性问题,人工专注于业务逻辑和架构决策
三、解决方案
3.1 整体架构
整体技术方案采用五层架构设计,从输入约束到可观测性,层层把关审查质量:
sql
┌───────────────────────────────────────────────────────────────┐
│ AI增量代码审查系统 │
└───────────────────────────────────────────────────────────────┘
第1层:输入约束 ------ 解决"送什么给AI"
├─ DiffExtractor Git Diff提取(GitPython + unidiff)
├─ SemanticDiffExtractor AST语义分析(过滤纯格式化改动)
├─ TokenBudgetManager 上下文预算管理(128K字符上限)
└─ PromptInjectionGuard Prompt注入防护
第2层:执行约束 ------ 解决"AI怎么审查"
├─ ContextCollector 全局上下文采集
│ ├─ 依赖分析(直接/间接依赖)
│ ├─ 函数调用图(跨文件调用链)
│ ├─ 架构分层检测
│ └─ 项目规范集成
├─ ChangeClassifier 变更类型分类
├─ StrategyRouter 策略路由
└─ CommitIntentValidator Commit意图校验
第3层:AI评审 ------ 六维度审查
├─ code_style 代码规范与质量
├─ security 安全漏洞(OWASP Top 10)
├─ performance 性能优化
├─ architecture 架构兼容性
├─ test_coverage 测试覆盖
└─ documentation 文档一致性
第4层:输出约束 ------ 确保建议可用
├─ HunkAnchor Hunk锚定(丢弃无法定位的建议)
├─ ConfidenceGate 置信度门控(折叠低置信度建议)
└─ ActionabilityValidator 可执行性校验(降级模糊建议)
第5层:可观测性 ------ 持续改进
├─ ObservabilityCollector 指标收集
├─ SilenceListManager 误报静默
└─ 质量评分(0-100分)设计理念是:AI不直接面对原始代码,也不直接输出最终结论------每一层都有约束和校验,确保最终呈现给用户的建议是可定位、可信赖、可执行的。
3.2 技术选型
| 模块 | 技术选型 | 选型理由 |
|---|---|---|
| Git操作 | GitPython | 原生Python接口,支持三种Diff模式 |
| Diff解析 | unidiff | 高效解析unified diff格式 |
| AST分析(Python) | 内置ast模块 | 标准库零依赖,精确解析 |
| AST分析(Java/JS/TS/Go) | tree-sitter | 增量解析、多语言统一接口、可选依赖 |
| LLM适配 | OpenAI SDK | 兼容OpenAI/DeepSeek/Qwen/阿里百炼等 |
| CLI框架 | Click + Rich | 交互式命令行 + 终端彩色输出 |
| Web服务 | FastAPI + Uvicorn | 异步高性能,自动生成API文档 |
| 配置管理 | PyYAML | 人类可读,层级清晰 |
| 部署 | Docker + Nginx | 一键部署,支持HTTPS |
3.3 模型选取
我们支持多种模型后端,通过适配器模式统一接口:
- OpenAI Compatible:兼容OpenAI API的所有服务,包括阿里百炼(DashScope)、DeepSeek API、Qwen等
- Ollama:本地部署的开源模型
- DeepSeek TUI:终端原生DeepSeek
- Gemini:Google Gemini
分阶段模型配置是一个实用的成本优化策略:
yaml
# .audit-inc.yml
review_model:
model_name: deepseek-v4-pro # 最强模型用于审查(质量优先)
test_gen_model:
model_name: qwen3.6-flash # 快速模型用于测试生成(速度优先)
analysis_model:
model_name: deepseek-v4-flash # 性价比模型用于归因分析(成本优先)3.4 核心功能实现
核心流程分为5步:
- 通过git diff提取增量代码,支持三种模式:工作区未提交变更、分支对比、commit区间
- AST语义分析,区分格式化改动和逻辑变更,提取函数签名、调用链等结构化信息
- 采集项目全局上下文(依赖关系、函数调用图、架构分层),构造结构化Prompt
- 调用LLM进行六维度审查,输出带行号和修复代码的建议
- 三层质量门控过滤(Hunk锚定 + 置信度门控 + 可执行性校验),生成最终报告
以下对关键步骤进行详细介绍。
1、AST语义Diff提取
传统的文本Diff将所有改动一视同仁,一个空格调整和一个函数签名变更在Diff看来没有区别。我们通过AST分析来区分:
python
# 改动1:纯格式化(应跳过审查)
- def foo(x,y): return x+y
+ def foo(x, y): return x + y # 仅调整空格,AST结构不变
# 改动2:函数签名变更(需要重点审查)
- def foo(x): return x * 2
+ def foo(x, y): return x * y # 新增参数y,逻辑变化Python使用内置ast模块解析语法树,Java/JS/TS/Go通过tree-sitter提供精确分析。我们设计了一个LanguageParser抽象层,统一多语言的解析接口:
python
class LanguageParser(ABC):
def extract_functions(source, file_path) -> List[FuncDef]
def extract_calls(source, file_path) -> List[CallInfo]
def extract_imports(source, file_path) -> List[ImportInfo]tree-sitter作为可选依赖,不安装时自动降级为正则解析,不影响工具正常运行:
bash
pip install audit-inc # 基础安装
pip install audit-inc[tree-sitter] # + Java AST分析
pip install audit-inc[tree-sitter-full] # + Java/JS/TS/Go全部AST分析以 Java 语言为例,tree-sitter 相比传统正则解析能力优势显著:
| 能力 | 正则解析 | tree-sitter解析 |
|---|---|---|
| 函数提取 | 漏掉注解、泛型、多行签名 | 精确到方法体边界 |
| 调用关系caller | 全部为<module> |
精确到所在方法名 |
| 语义分类 | 全部LOGIC_CHANGE |
区分NEW_FUNCTION / CLASS_CHANGE / NEW_CALL_CHAIN |
2、函数调用图分析
调用图让AI理解代码在项目中的位置------不仅看当前文件,还知道它调用了谁、谁又调用了它。
java
// 变更代码
public void processOrder(String orderId) {
Order order = orderService.findById(orderId);
double total = order.calculateTotal(); // 空指针风险
}
// 调用图分析输出
[MAJOR] 稳定性 - findById可能返回null
调用链:processOrder → OrderService.findById
└─ 返回值类型:@Nullable Order
修复:添加空值检查 if (order == null) throw new OrderNotFoundException(orderId)调用图构建采用一次扫描建立索引 + O(1)字典查询的设计,配合15秒超时保护,不会拖慢审查速度。系统为不同语言实现了空值检查模式的识别:
| 语言 | 检测模式 |
|---|---|
| Python | if x is None / if not x |
| JavaScript | if (x === null) / if (!x) |
| Go | if x == nil / if err != nil |
| Java | if (x == null) / Objects.requireNonNull |
3、Token预算管理
LLM的上下文窗口有限,需要按优先级分配空间:
优先级1:变更行 + Diff Hunk → 永不裁剪
优先级2:直接依赖摘要 → 超限截断
优先级3:调用图摘要 → 超限截断
优先级4:项目规范约束 → 超限截断
优先级5:间接引用 → 预算耗尽时丢弃核心原则:变更行永远完整保留,上下文按需裁剪。
4、输出质量门控
LLM存在幻觉问题,可能给出无法定位或模糊的建议。我们加了三道门控:
| 门控 | 做什么 | 不通过的后果 |
|---|---|---|
| HunkAnchor | 将建议绑定到具体DiffHunk,±5行容差 | 丢弃 |
| ConfidenceGate | 按敏感度检查置信度(默认阈值0.8) | 折叠为nit |
| ActionabilityValidator | 检查修复代码是否可直接应用 | 降级为question |
置信度阈值可按敏感度调整:
| 敏感度 | 阈值 | 场景 |
|---|---|---|
| low | 0.6 | 重构、格式化 |
| medium | 0.8 | 新功能、Bug修复(默认) |
| high | 0.85 | 核心模块变更 |
| critical | 0.9 | 配置变更、权限相关 |
5、结果存储与报告生成
审查结果支持三种格式输出:
- Markdown:6个章节------审查概览、问题清单、维度分析、优化优先级、修复代码示例、测试验证结果
- HTML:带质量分数徽章、问题卡片、维度柱状图的可视化报告
- 终端输出:Rich渲染的彩色表格,直接在命令行展示
质量评分公式:
ini
score = clamp(80 - 20×critical - 5×major + 1×minor, 0, 100)3.5 使用方式
CLI本地使用
bash
# 安装
pip install "audit-inc[tree-sitter-full]"
# 初始化配置
cd your-project
audit-inc --init
# 编辑 .audit-inc.yml,填入API Key
# 审查
audit-inc # 审查工作区未提交代码
audit-inc --branch main # 审查当前分支 vs main
audit-inc --commit abc..def # 审查commit区间
audit-inc --verify # Critical问题二次校验Web服务团队共享
bash
audit-inc serve # 启动服务(默认8000端口)API接口:
| 方法 | 路径 | 说明 |
|---|---|---|
| POST | /audit |
提交审查任务 |
| GET | /audit/{task_id} |
查询任务状态 |
| GET | /audit/{task_id}/report |
获取报告 |
CI/CD自动触发
yaml
# GitHub Actions
- run: pip install "audit-inc[tree-sitter-full]"
- run: audit-inc --branch ${{ github.base_ref }}
env:
DASHSCOPE_API_KEY: ${{ secrets.DASHSCOPE_API_KEY }}Docker一键部署
bash
cd deploy/ && docker-compose up -d --buildDocker镜像默认包含全语言tree-sitter支持,配合Nginx可实现HTTPS部署。
3.6 使用场景
- 提测前:开发提交代码后,自动触发审查,提前发现问题
- Bug修复后:验证修复是否引入新问题
- 代码合并前:PR自动审查,审查结果作为评论发布
- 日常巡检:定时对主分支进行增量审查
支持手动触发和自动触发,目前主要通过CLI手动执行和CI/CD流水线自动触发。
四、落地实践效果
结合实际落地案例,展示系统应用成效:
案例1:认证逻辑缺失返回,引发空指针异常
问题描述:用户认证为空时,代码执行了错误响应构造,但未主动return终止流程,后续代码继续执行并访问空对象,触发空指针异常,属于高危安全问题,需立即修复。
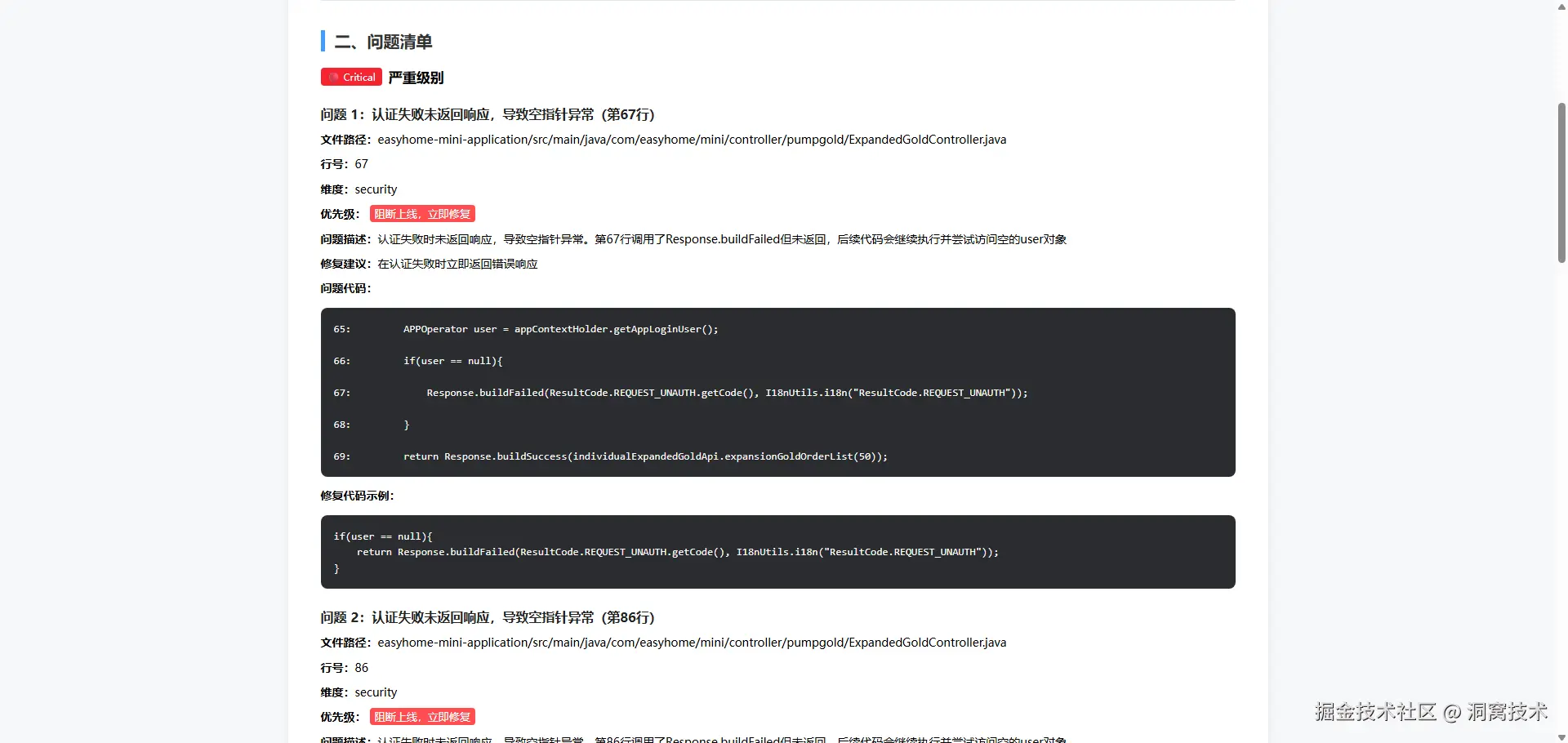
修复方案:认证失败后直接返回错误响应,阻断后续代码执行。
案例2:MQ消息处理器逻辑漏洞,导致消息重复重试
问题描述 :更新客户信息的逻辑执行完成后未添加return语句,程序继续执行新增客户逻辑,因手机号重复导致报错,进而引发MQ消息无限重试。

修复方案:更新客户信息后增加return,将新增逻辑放入else分支。
案例3:枚举与基础类型错误比对,功能过滤失效
问题描述 :使用枚举对象直接与Integer数值做equals比对,该逻辑永远返回false,导致业务状态过滤功能完全失效。

修复方案 :调用枚举getCode()方法取出数值后再做比对。
补充说明:工具仅提供智能化评审建议,最终问题是否修复、方案是否适配业务,仍需研发人员结合实际业务场景综合判断。
五、后续规划
目前已实现对Python/Java/JS/TS/Go的增量代码审查,取得一定效果,后续计划包括:
-
扩展语言支持
- 完善tree-sitter对更多语言的AST分析(Rust、C/C++等)
-
智能化提升
- 基于历史审查数据训练误报预测模型
- 多Agent协作(安全专家Agent、性能专家Agent等分工审查)
-
团队协作
- 支持评论、讨论、任务分配等协作功能
六、总结
在 AI 赋能代码质量管控的探索中,我们意识到单纯把原始代码直接交给大模型审查存在诸多短板:无筛选的输入会夹杂大量格式冗余、突破上下文限制,还存在提示注入风险;缺少规则与上下文支撑会导致评审片面;大模型本身的幻觉问题,也会产出大量定位模糊、无法执行的无效建议。
为此我们设计五层约束架构,将代码审查拆解为输入约束、执行约束、AI 评审、输出约束、可观测运维五大环节,搭配 AST 语义分析、跨文件调用图构建、Token 管理、多模型适配等核心能力,打造出一套完整、可靠的增量代码自动审查方案。该方案补齐了人工评审与传统静态扫描工具的能力短板,形成标准化、自动化的代码质量防线。
落地实践证明,这套架构能够充分发挥大模型的能力,同时通过多层校验约束其缺陷,实现 AI 与人工评审的合理分工。当前系统已稳定服务于多语言项目,后续我们将围绕语言拓展、智能模型优化、团队协作场景持续迭代,不断打磨产品能力,让 AI 代码审查成为研发流程中常态化、高可靠的质量保障工具。