本文作者:Henry Li,DeerFlow 团队
摘要
很多人第一次接触 Loop Engineering,容易把它想成 "让 Agent 自动跑起来"。但真正的分水岭,其实是你站在哪个位置:是继续当那个在旁边逐句下指令、盯着每一步的人,还是退后一步,搭一个能替你转动的机制。
这个机制要替你做的,是一连串原本得你亲自来回操作的事:它得自己醒过来开工,而不是等你点一下;它得知道资料藏在哪、怎么去取;它得在干完之后回头掂量一下成果到底成不成;遇到失败,它得自己判断值不值得再试一遍;它还得随时把 "现在进展到哪儿" 这件事记下来,免得下一轮又从头来过。
而最容易被忽略的一点是:它得懂得在恰当的时候停手,把决定权重新交回到人手上。
把这些拼到一起,你会发现,Loop Engineering 并没有发明什么新东西:它依旧是一套工作流,只不过这套流程的驱动者,从 "你" 换成了 "AI"。
前言
过去几个月,很多人其实都在反复做同一件事:
-
写一段 Prompt → 交给 Coding Agent
-
等它跑完 → 查看结果、做个测试
-
不对 → 再写下一段 Prompt,直到满足心中的要求
时间一长你会意识到:这本身就是一个循环。 只不过那个负责"再来一轮"的循环体,是坐在屏幕前的人。
如果连"看守"这一步也交给 AI 呢? 把屏幕前的用户也换成 AI Agent,就引出了最近常被提起的热词:Loop Engineering。

这个名字听上去抽象,落到实处其实只有一句话:把 Loop 的执行者从人换成 Agent。
原本由你亲自跑的"发现问题---想办法---动手---检查"循环,现在交给 Agent 去跑。你要做的,只剩开头把目标(验收标准)说清楚。
不少 Coding Agent 重度用户早已通过 Skill 实践类似做法,只是叫法不一、颗粒度不同。
直到 Claude Code 作者 Boris 和 OpenClaw 作者 Peter 反复提及"Loop Engineering",它才逐渐流行。
本文是把这套做法的骨架梳理出来,让它从**"Early Adopter 的先进工作流"变成"你也能照做的步骤"。
有的人说:Loop Engineering 就是数字员工的开始。
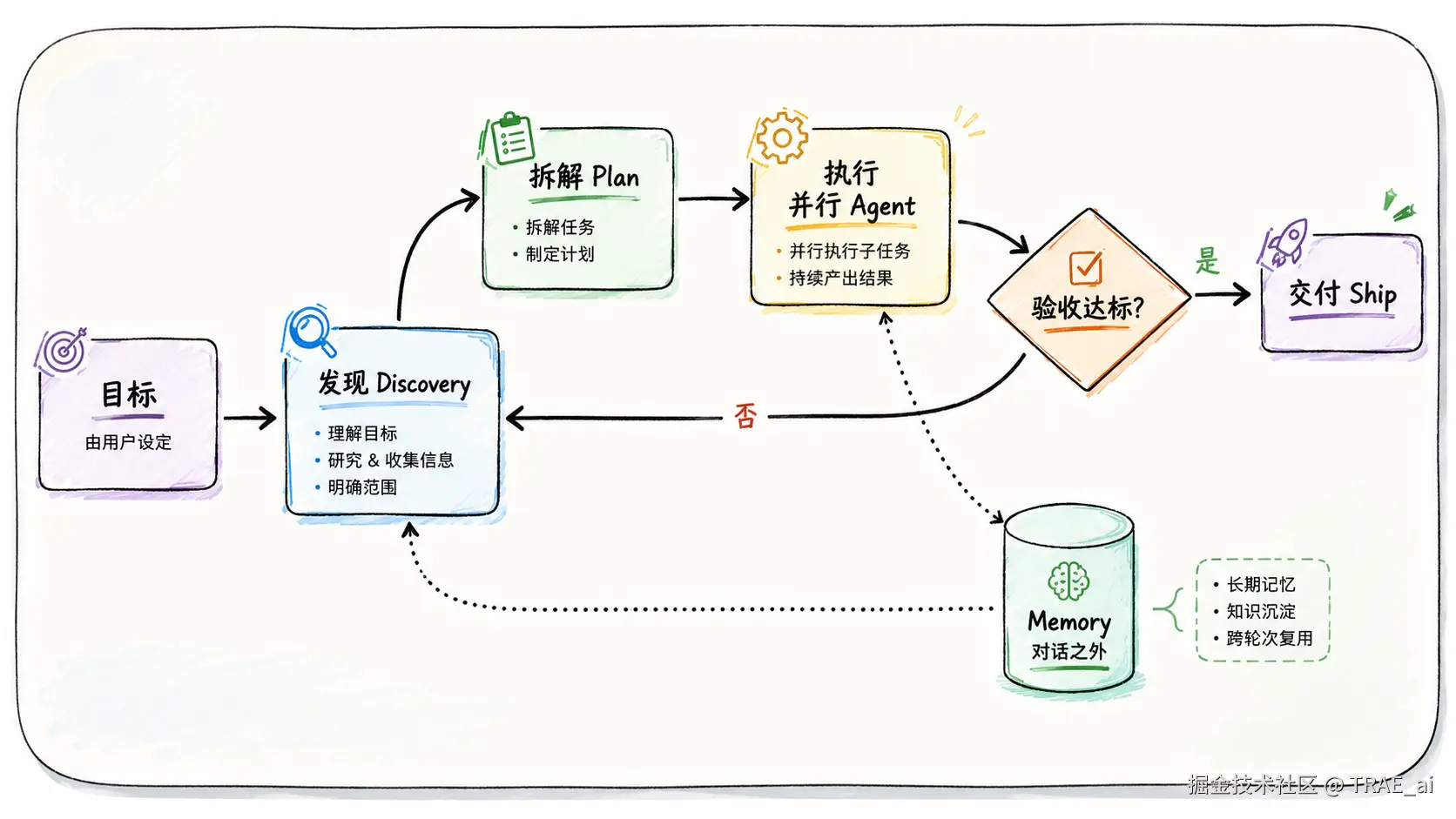
先看一张全景图,后文要展开的环节都在这幅 Closed Loop 里:
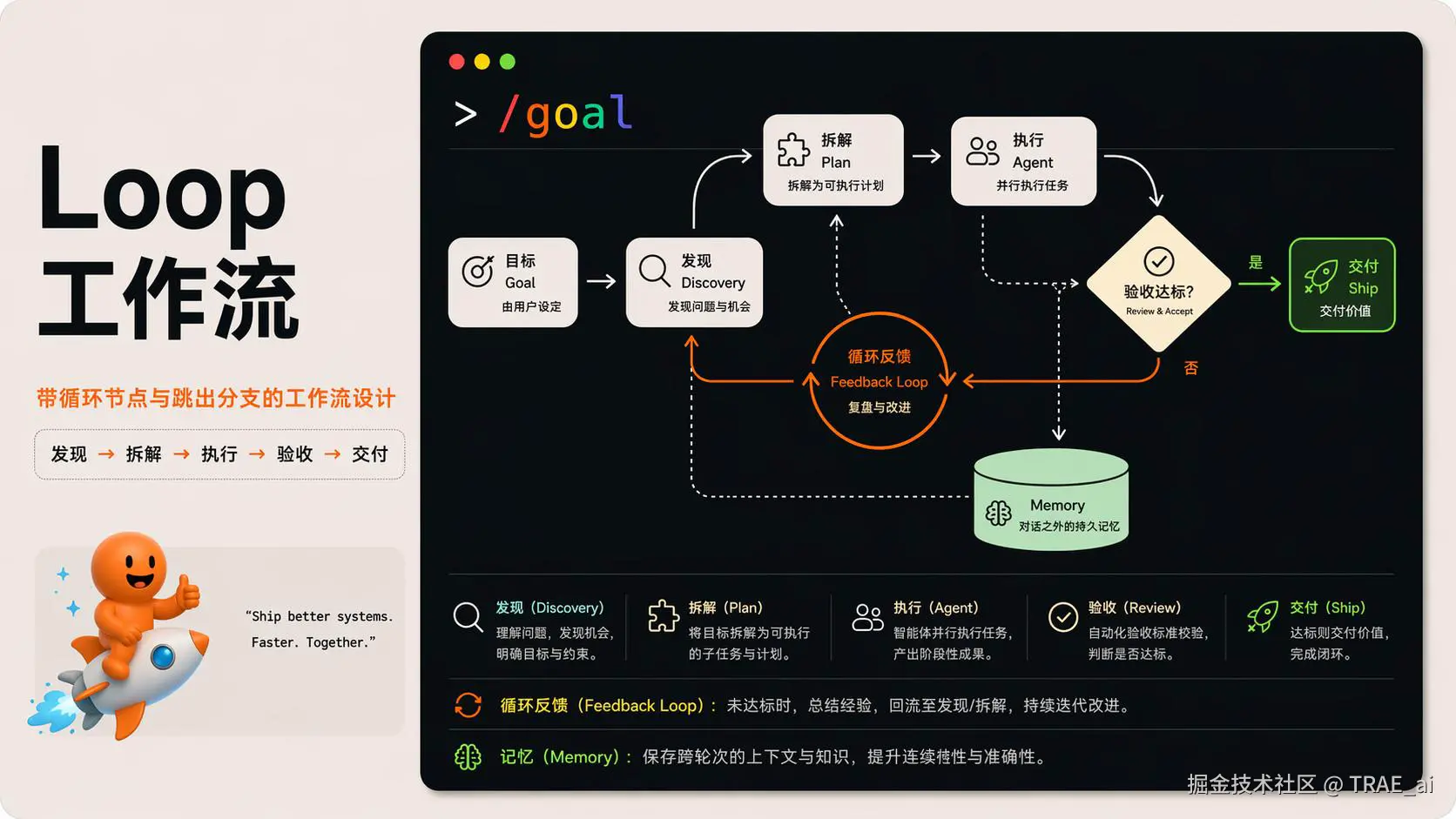
-
目标由用户设定
-
之后 Discovery → Plan → Execute → Verify 依次接力
-
达标就 Ship,不达标就回到 Discovery 再来一轮
-
Memory 位于对话之外,为每一轮递上进度的"接力棒"
知识点:让 AI 给自己写下一个 Prompt? 循环工程里有个思路叫 self-prompting:上一轮跑完后,不由人来想"下一步该问什么",而是让 Agent 根据已有进展,自己写下一轮要执行的 Prompt。这一步看似不起眼,却是把"人当循环体"换成"Agent 当循环体"的关键拼图。人不再负责接力,循环自己续上了。
手工循环:你就是循环的执行者
回想过去几个月,与 Coding Agent 打交道的节奏大概是这样:
你写 Prompt → Agent 干活 → 产出结果 → 你读结果、判断哪里不对 → 再写下一段 Prompt......如此往复,直到做完。
这套节奏熟练到让人忽略了一个事实:它本身就是一个完整的循环。
发现问题、想办法、动手、检查结果,每个环节都在,循环也确实在转。区别只在于:循环体的执行者是你自己。
Agent 干完一轮就停下,安静等着。
真正负责"判断、决定、再来一轮"的角色,由人来扮演。换句话说:这一轮里,是机器在等你。
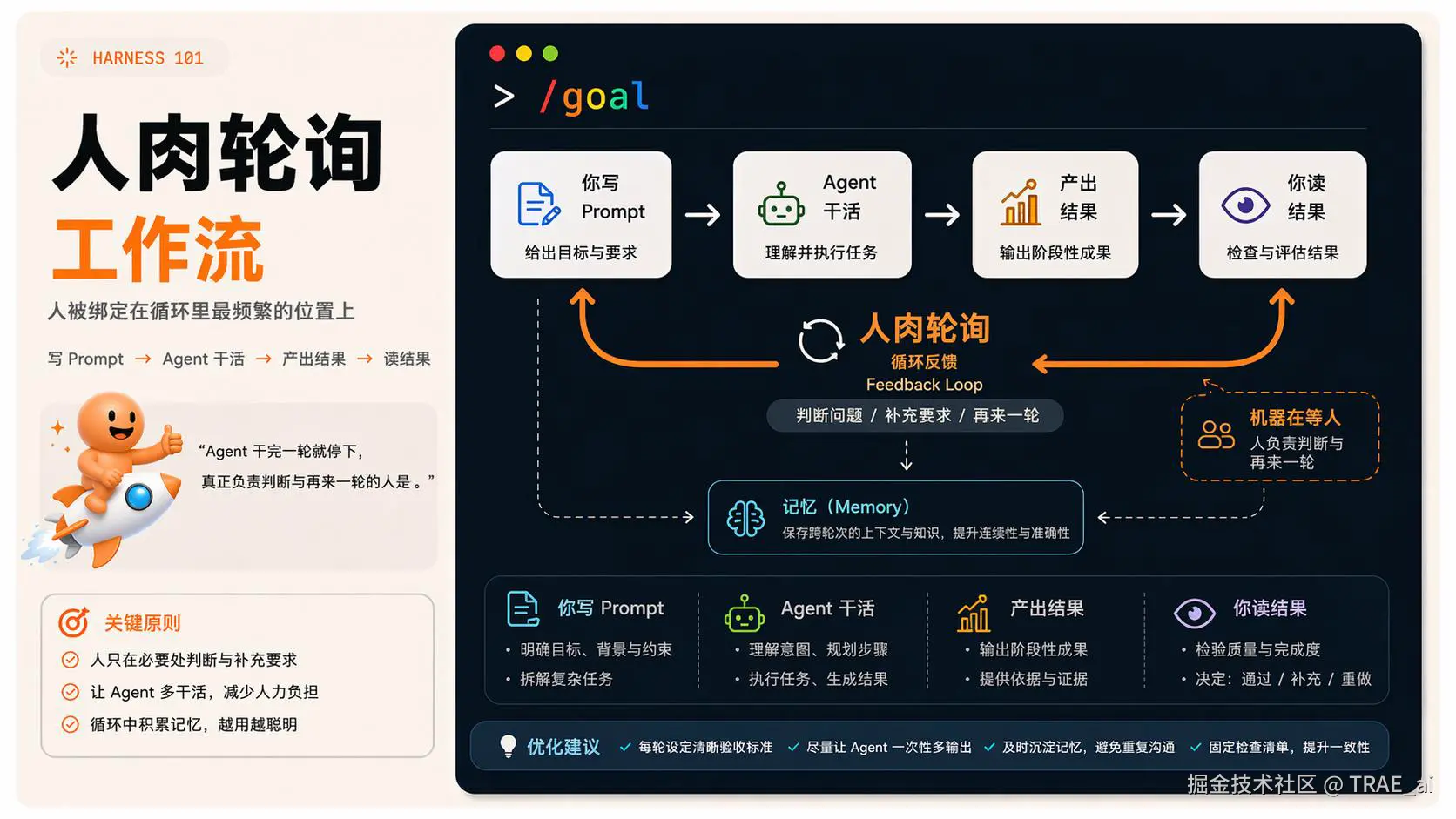
图里最关键的是那条折返线:从"你读结果"回到"你写 Prompt",标着"人肉轮询"。
人,被绑在了循环里最频繁的那个位置上。
代价就藏在这条红线里:
-
Agent 每跑完一轮,你都得回到屏幕前查看,否则循环就停在那儿不动
-
注意力被反复切走又切回,刚开始写另一份文档,那边一声"完成"提示音,又得切回来
-
一天下来,注意力被切得很碎,上下文在几件事间反复搬运,真正连续投入的时间反而不多
不知你是否也有同感,用 AI Coding 之后,类似 ADHD(注意缺陷多动障碍,俗称"多动症")的状态反而更明显了?
社区里甚至出现过用软件通知、ESP32 硬件来提醒"Agent 已经跑完了"的小工具,从侧面也可以证"人盯着循环"这件事有多普遍。
当你把代价摆在手工循环旁边,问题就清楚了:循环本身没问题,问题在于让人去当那个一刻不能离开的循环体。
既然其余环节 Agent 都能跑,那个"再来一轮"的位置,是不是也能交给 Agent?这正是循环工程要回答的问题。
循环工程:把循环体交给 Agent
Loop Engineering 的本质,一句话:把循环体的执行者从"你"换成"Agent"。
手工循环里那个一刻不能离开的位置,现在让 Agent 顶上。你要做的,是从"每一轮都判断、都接力",缩减成"开头把目标说清楚一次"。
这个新循环并不神秘,就是把你脑子里那几步,显式地交给 Agent 去走:
-
目标 :由 human 通过
/goal设定一次。这是整个循环里 human 唯一必须做、也唯一不该交出去 的事:方向得你来定。你也可以借助 grill-me 等机制,让 AI 采访你之后总结成最终目标。 -
Discovery:Agent 自己去发现这一轮要做什么,而不是等你逐条派活。
-
Plan:把发现的事,拆成清晰、可执行的步骤。
-
Execute:动手做。可以采取 fan-out 模式,同时开多个 Agent 并行,各自完成一件互不相干的子任务。
-
Verify :检查目标有没有达成。这是 Loop Engineering 里我认为最重要的一环。 它是 AI 充分理解需求后拆出的验收条件(Rubric),极其考验模型的推理能力,包括但不限于 Lint、编译、单元测试、E2E 测试等。达标就 Ship ,不达标就带着这一轮暴露的问题回到前面 Iterate(用的正是前面说的 self-prompting)。
-
Memory:最容易被忽视的一环,下一节重点展开。
-
可选一步:Ship 之后,让 Agent 想想"接下来该做什么",把下一轮入口也备好,循环就能自己续下去。
Memory:活在对话之外
一轮循环跑完,进展得留下来,下一轮才接得上。
问题是:进展该留在哪里?失败的教训放在哪里?
❌ 常见误区:把所有进展都堆回 Context Window,指望 Agent "记得"上一轮干了什么。
但工作记忆 Context 是有限的,也容易因 attention 流失而被"遗忘",就是大家常说的 AI 失忆。
✅ 正确做法:把进度记录在对话之外。
-
写进文件、写进一份结构化的状态记录,让它独立于任何一次对话而存在。
-
下一轮无论由哪个 Agent 来跑,都能读到"现在到哪儿了"。
Memory 不在对话里,循环才稳得住。
在我看来,Memory 才是真正区别于"前几个月大家自行探索的 Loop" 与 "Boris 等人提出的 Loop Engineering"的地方:它让 Agent 看上去更像真人了。
Orchestrator(编排):掌管目标的那个 Agent
知识点:Fan-out / Fan-in 是什么? - Fan-out :一个 Orchestrator 把任务拆开,同时派给多个 Agent 并行去做。 - Fan-in :这些 Agent 各自跑完后,结果再汇聚回来,由一处统一收口、汇总。 这一散一聚,是并行循环的基本骨架:散出去是为了快,收回来是为了不乱。
Fan-out、验收、接力这些环节,需要一个总控角色统一管起来。
它掌管目标、负责派活,等各路 Agent 干完后汇总结果,再决定是 ship 还是 iterate(迭代)。
这个角色就是 Orchestrator(编排)。
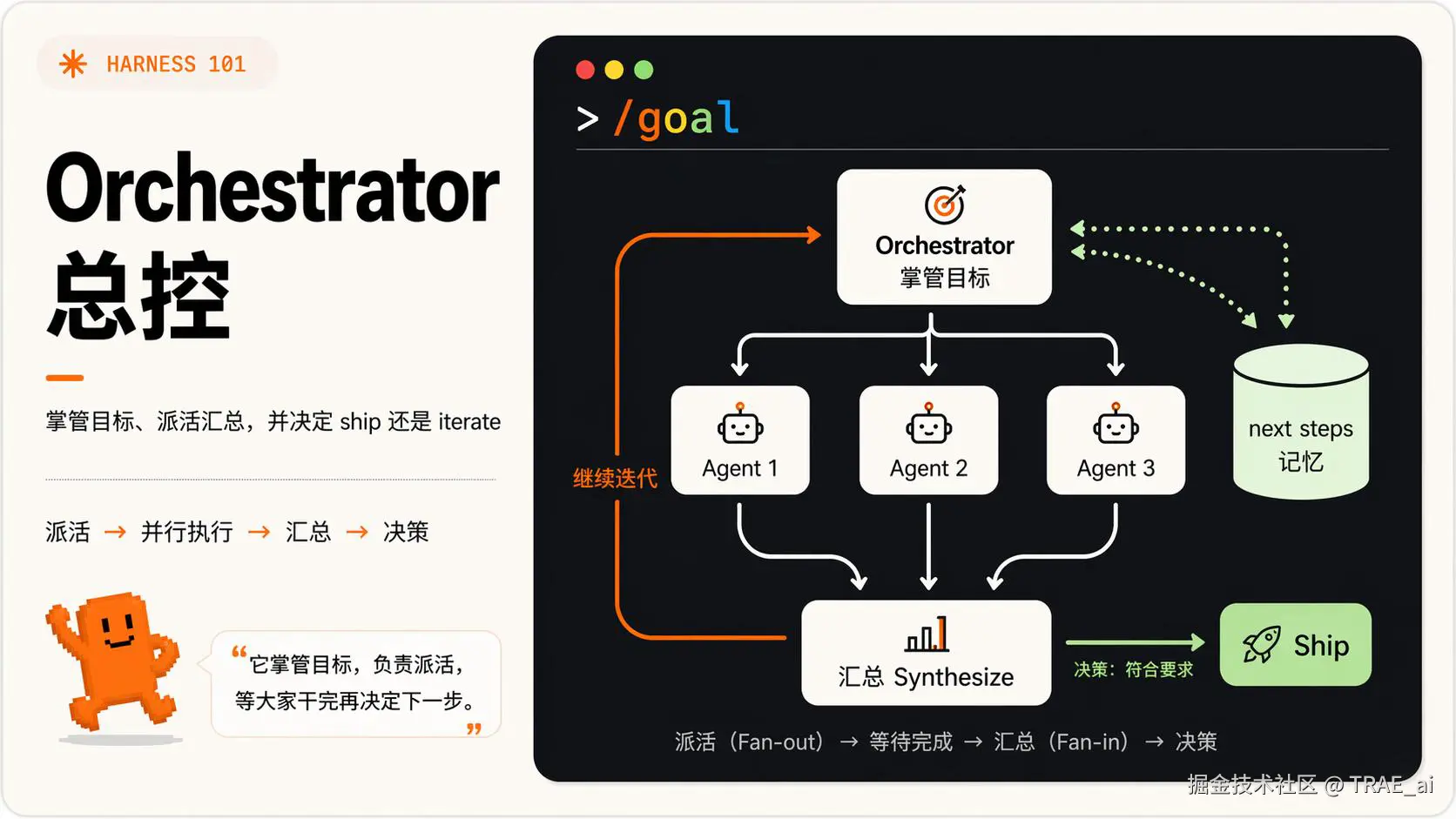
到这里,循环工程的轮廓就完整了:
用户设定目标 → Orchestrator 接手 → fan-out 并行执行 → 验收后 Ship 或 Iterate → 进度写进对话之外的 Memory,让循环接力下去。
接下来的问题是:这个 Loop 该敞开探索,还是该框定边界?
这就要分 「Open Loop」 和 「Closed Loop」 两种形态来谈。
Open Loop 与 Closed Loop:预算花在哪里
把循环体交给 Agent 之后,最先要面对的不是"它能不能干",而是"它要花多少"。
同样一句目标,落到不同形态的 Loop 上,开销能差出一个量级。
业界把这两类形态叫做 Open Loop 与 Closed Loop :差别不在谁更聪明,而在于预算花在哪里、花到什么时候为止**。
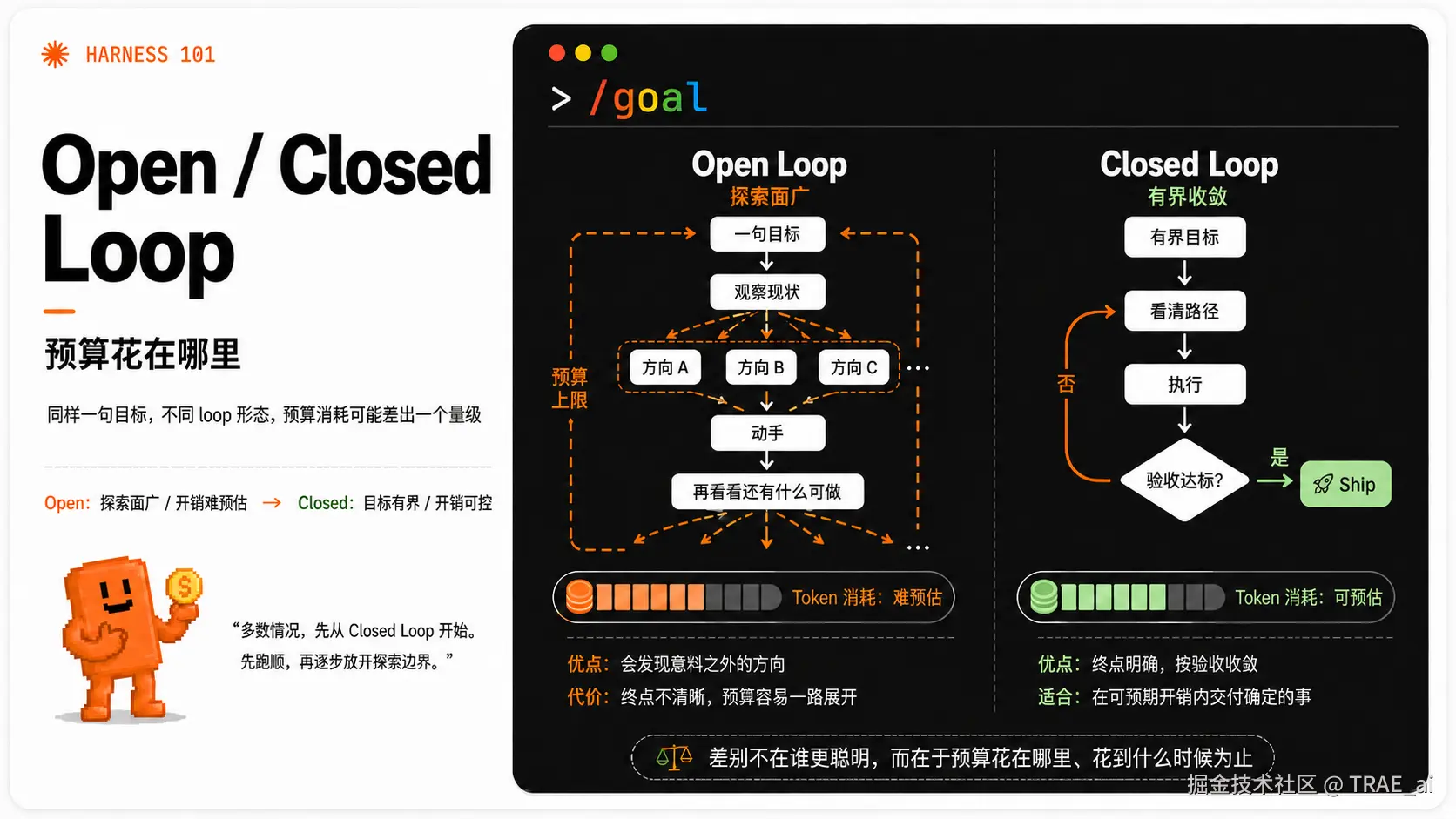
Open Loop:探索面广,但开销难预估
Open Loop 的入口很轻,你只需要给一句话:"去看看该做什么,然后把它做了",剩下的全交给 Agent 自己展开。
它的运转方式是:
-
先观察现状(你需要给它一系列 Connectors 或 Probes);
-
列出一堆候选方向,挑一个动手;
-
做完不停,回头看看还有什么可做,接着展开下一个。
第一次听到 Open Loop,多数人会觉得有些玄乎。但 我朋友的创业公司 Crewlet** **在这条路上已经走了 2 个月。
他们把这些数据源全部交给了一个类似中央处理器的 OpenClaw Agent:
GitHub 代码仓库、Sentry 日志、Google Analytics 埋点与行为数据、Supabase 业务主库、AB 实验数据,以及 Stripe 支付、X / Discord 社交数据、SEO、GEO......
这个 Agent 每隔一段时间"醒来",自主查看核心经营数据与近期错误日志,能做的事包括:
-
发现经营指标问题并归因
-
从错误日志中定位 Bug,直接改 GitHub 代码并提交 PR 上线
-
发现大量用户卡在付费这一步,原因是 Max / Pro 账号页面说明不清
-
给即将到期的用户发送挽回邮件
-
改 Agent 代码、增强 Prompt Caching,提性能、省开支
-
发起 AB 实验并分析报告,进而迭代自身功能
效果出奇地好。
-
好处:探索面广。 Agent 常会发现你事先没想到的方向,例如某个被忽略的边界条件、一处可顺手改进的地方、一个你没意识到的依赖。它不受"我只想要 X"的约束,能把问题空间走得更远。
-
代价:开销难估。 因为没有清晰的终点,它可以朝任意方向持续展开,Token 消耗难以事前预估,只能靠一个外部预算上限兜住。
所以 Open Loop 更适合预算充裕、以探索为目的的场景:你要的本就是"它能帮我发现什么",而不是"在固定开销内交付一件确定的事"。
Closed Loop:有界目标,开销可控
Closed Loop 换了个起点:从一个有界目标出发。
-
目标确定,路径大致看得清
-
每一步做完都有明确验收
-
Agent 沿路径推进,用验收结果决定是收敛、还是回上一步重做,达标即停
正因为终点和验收事先定好,开销也跟着可控:你能比较有把握地估出"大概几轮收敛",也不太担心它绕到无关方向上去。
代价是探索面窄:它基本不会给你意外惊喜。
但这恰恰是交付场景想要的:把一件确定的事,在可预期的开销内做完。
两类循环对照
| 维度 | Open Loop | Closed Loop |
|---|---|---|
| 目标 | 开放,边走边定 | 有界,事先定好 |
| 路径可见性 | 走的时候才知道 | 大致看得清 |
| 验收 | 模糊,靠 Agent 自判 | 明确,每步可判定 |
| 开销 | 难预估 | 可控、可估 |
| 适用场景 | 探索、找方向 | 交付确定的事 |
作者建议:多数情况先从 Closed Loop 开始。 先把一件目标清楚的事用 Closed Loop 跑顺,摸清 Agent 在你这套流程里的脾气,再按需把边界一点点放开。反过来,一上来就 Open Loop,往往开销和结果都不容易把控。
接下来,我将用一个验收标准明确的研发任务来演示 Closed Loop。
需要特别说明的是:TRAE 当前还不支持 Loop(很快会支持),大家可以先从这两个 Case 中更直观了解 Loop。
实践场景 1:为工具库补测试
这是一个研发场景:给一个工具库补测试、顺手修掉暴露出来的 bug。
它的好处是验收标准天然客观:这三条都能由机器给出 0/1 判定,不需要任何人主观拍板"算不算做完了":
-
一组 acceptance test 全过
-
typecheck 通过
-
不破坏现有测试
这正是 Closed Loop 最干净的示范。
从定义目标开始
把循环工程的解剖(目标 → Discovery → Plan → Execute → Verify → Ship/Iterate,Memory 在对话之外)放进这个任务,每一步都落得很实:
| 步骤 | 说明 |
|---|---|
| 目标 = 验收标准 | 不写"把测试补好"这种含糊话。 **而是写成可机器判定的条件:**指定的一组 acceptance test 全绿、npm run typecheck 无报错、现有测试不变红。目标和验收是同一份东西。你真正需要参与的,只有这一步! |
| Discovery = 找出哪里红、哪里没覆盖 | Agent 先跑现有测试和覆盖率报告,摸清"哪些模块没被测到"、"哪些用例当前失败"。这一步不动手改,只产出一张现状清单。 |
| Plan = 把工作拆成模块 | 按文件或功能分块:这块缺边界用例,那块某函数有 bug 需先修。拆出来的每一块,最好彼此独立、互不踩脚。 |
| Execute = 并行开多个 Agent 各补一块 | 模块无依赖时,同时开几个 Agent:一个补 parser 的测试,一个补 serializer 的测试,互不干扰。这是 Plan 拆得干净带来的直接好处。 |
| Verify = 跑测试 | 这是 Closed Loop 的闸门:全绿就 ship;只要有红,就把失败信息原样塞回循环。哪个用例失败、报错栈是什么,一字不改地交回去,强制下一轮针对性去修,而不是让 Agent 凭印象猜。 |
| Memory = 记下哪些模块已绿、哪些还差 | 在对话之外维护一份进度,避免重复测已绿的模块,也避免把修好的地方又改坏。 |
把这套流程画出来,就是下面这个环:红就回到实现,绿就交付,没有第三种出口。
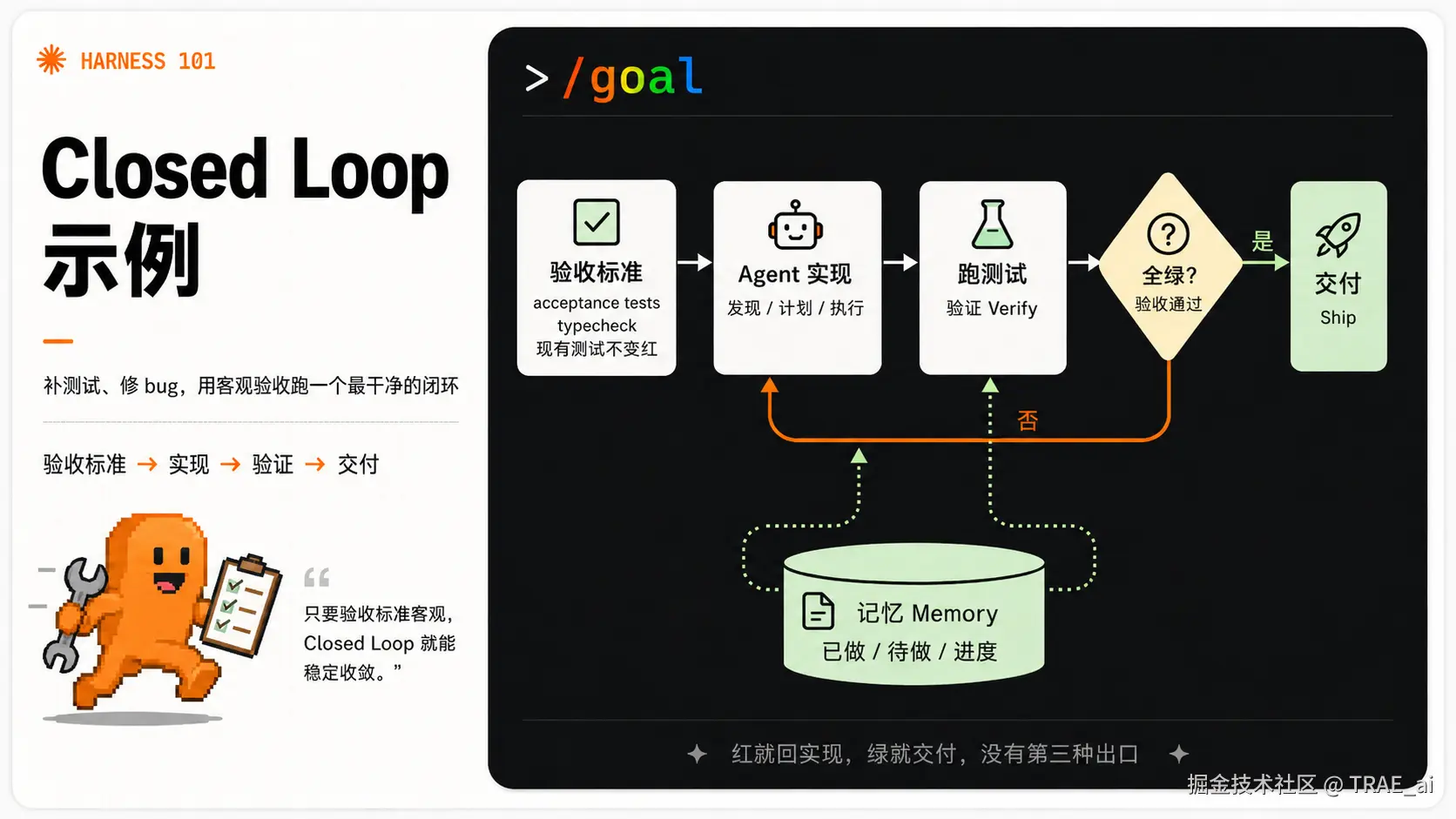
Closed Loop 为什么能成立
关键就一条:验收是客观的。
测试、typecheck、benchmark 给出的是 0/1 信号:要么全绿,要么有红,没有中间地带。Agent 不需要去猜"我做完了没""够不够好",那个判断被外包给了一套确定性检查。
Open Loop 开销难估,根源在于"何时停"由 Agent 自己回答。
而这里,"何时停"被一句 npm test 全绿替代了。
循环有了必须收敛的客观靶子,轮数和开销也就有了大致上界。
把模糊的"做好"换成可判定的"全绿",Closed Loop 就立住了。
循环 Prompt 的骨架
下面是这个循环的 Prompt 骨架,去掉细节只留结构。它干的事很简单:先把目标和验收标准摆明,再给一个硬性循环条件:只要测试不全绿就继续修,全绿才停。
Plain
/goal 目标:为 <工具库> 补齐测试并修复其中的 bug。
验收标准(全部满足才算完成):
- tests/acceptance/ 下的所有用例通过
- `npm run typecheck` 无报错
- 现有测试不出现新的失败
循环规则:
- 跑 `npm test`。
- 若未全绿:读取失败用例与报错,定位并修复,然后重跑。
- 只要不全绿,就重复上一步,直到全绿再停。
- 中途若验收标准本身有歧义,先提问,不要自行猜测。实践中,这个"把验收结果塞回循环"的动作可以自动化:用 hook 或 CLI 命令的退出码来驱动。比如约定退出码非 0 即失败,配合 Claude Code 的 PostToolUse 钩子,让每次测试结果自动回流到下一轮,省去人工搬运。骨架是同一个,只是接缝处更顺滑。
在真实工作中,你并不需要自己写出这么清晰的验收标准和循环规则------模型已经足够聪明,能从仓库里自行推理出这些规则。
知识点:什么是 Acceptance Criteria(验收标准)? 它是一组事先约定、客观可判定的条件,用来回答"这件事到底算不算做完",把"完成"从主观感受变成一个 0/1 信号。 Simon Willison 在 2025 年给过 agent 一个被广泛接受的极简定义------"An LLM agent runs tools in a Loop to achieve a goal"(一个 LLM agent 在循环里调用工具以达成一个目标)。这里的"a goal"若是一份可机器判定的 acceptance criteria,那个循环就有了明确的收敛靶子------这恰好是 Closed Loop 能成立的原因。
实践场景 2:网店做增长
前面那个研发循环好讲,是因为验收标准足够硬:测试全绿就达标,红了就再转一圈。
可现实里不是每件事都这么干净利落。
一个想自我增长的电商小店 ,目标是"让网店 GMV 持续增长"。
我们给它装上循环条件,让它在一个收敛的范围里运转。
这一轮,主角换成了一个 Orchestrator(编排)。它掌管这个开放目标,但真正做的事很具体:
开工前,先读上一轮留下的
next_steps------那是一份记忆,记着上次没做完、值得这轮接着做的事。读完才决定,这轮派谁去干什么。
Orchestrator(编排) 派出三个 Sub-Agent,并行工作、各管一摊:
| Sub-agent | 职责 |
|---|---|
| Builder | 负责做产出。做一个轻量、可分享的小测验(quiz)当作 lead magnet。用户做完测验,结尾顺势留下邮箱。测验本身要做得让人愿意转发,这样它才能自己往外走。 |
| Scout | 负责找选题。去 Reddit、相关论坛、搜索趋势和竞品站,看目标用户真正在讨论什么、搜什么、被什么困扰。选题按四个维度打分(受众规模、购买意图、内容缺口、能否做成 quiz / 小工具),排序后输出 top N。循环条件:攒够 ≥3 条尚未消化的新选题才停。 |
| Growth | 负责落地。读站点和 Builder 刚做好的 quiz,产出一组可执行动作:quiz 链接放在站点哪几处、一封上线通知邮件、几条按各平台调性写的社媒文案,再加一条下一个 lead magnet 的建议。它还会核对上轮建议哪些没落地、有没有撞车,写进笔记避免重复。 |
知识点:什么是 Lead Magnet? Lead Magnet(直译"引流磁铁")是一份免费、对用户有点用的小东西。一份清单、一个测算工具、一个小测验,用它换取访客的联系方式(通常是邮箱)。它不直接卖货,而是先把陌生流量变成你能再次触达的潜在客户。本案例里那个小测验,扮演的就是这个角色。
三个 Sub-Agent 各自跑完,产出还是散的。汇总与记忆由 Orchestrator 收口:
-
把 Builder 的 quiz、Scout 的选题排序、Growth 的落地动作,合并成一份统一的行动计划;
-
写回
next_steps------这份文件就是这套循环的跨周期记忆。
下一轮开工,Orchestrator 第一件事就是再读它。于是这轮的尾,接上了下轮的头。
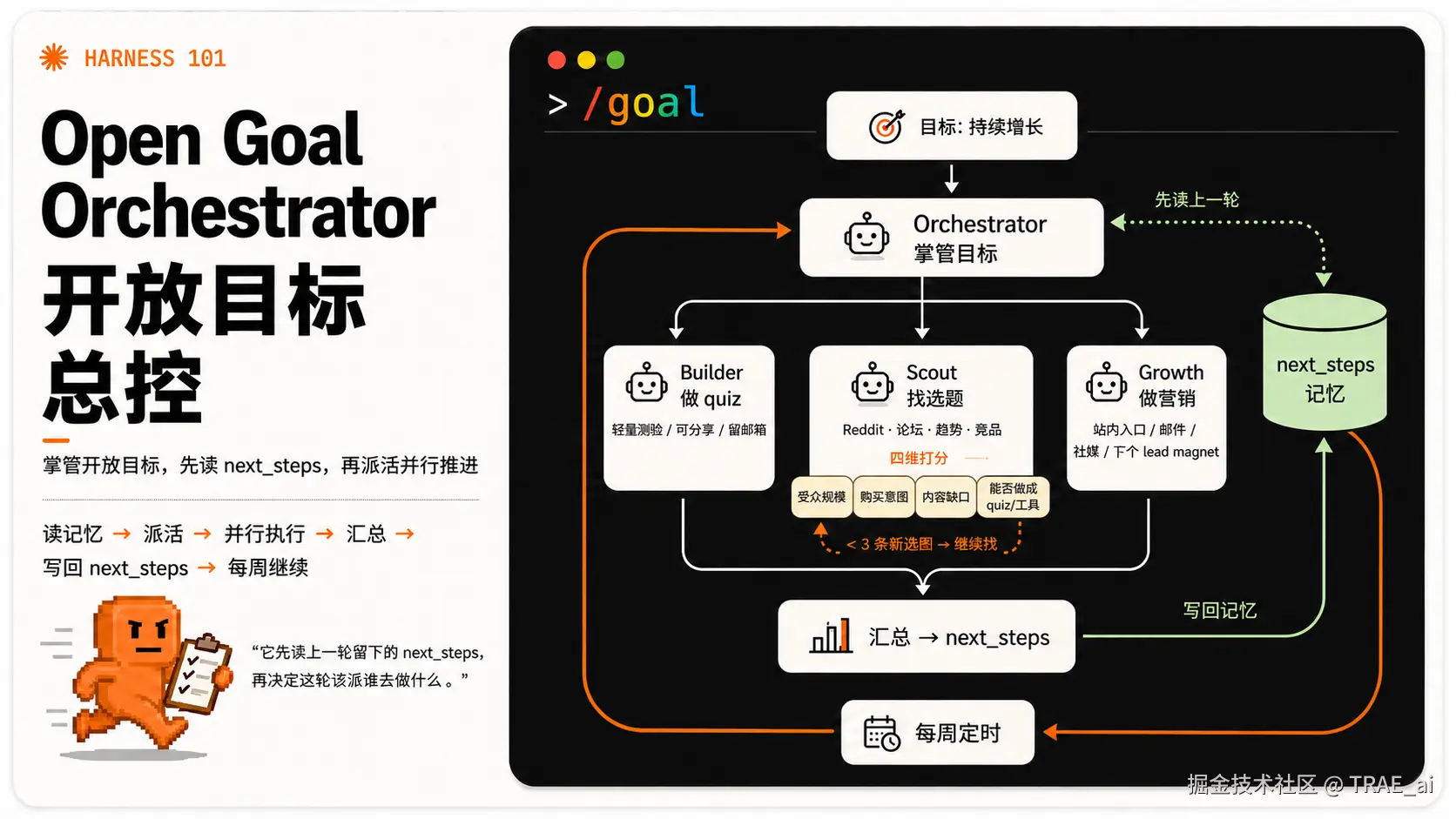
剩下的是定时和循环条件 。这套环每周由定时器触发一次(Claude Code 里可用 /Loop 命令),不必时刻盯着。
每轮结束时,Orchestrator 用几条简单条件判断要不要继续:
-
站点这周是否还在增长?
-
Scout 手里是否还压着 ≥3 条未消化的新选题?
-
下一个 lead magnet 是否已经定下来?
条件没满足就接着转;都满足了就暂停,等下个周期再来。开放目标的收敛,靠的就是这几条人为设定的边界。
落到操作上,这件事并不需要特殊基建:
-
省力做法:让一个 Orchestrator Agent 在同一会话内自动 spawn 出 Builder、Scout、Growth,由它统一派活、收口;
-
手动做法:自己开三个 tab,各跑一个 Agent,最后把结果汇到一处。
两种方式做的是同一件事,只是前者把编排也交给了机器。
你还可以这样玩转 Loops
研发循环和增长循环看着差别不小,框架却是同一副。抽干净后,剩下的就是这条线:
定时触发 → 去读点什么 → 打分 / 过滤 → 产出草稿 → 比对历史去重 → 必要时让人过目 → 记录下来 → 下一周期再从头转。
这副骨架并不专属于写代码,能套到很多别的事情上 。下面是四个速写场景,每个都按"触发时机 → 读什么 → 怎么处理 → 循环条件"来看。

🧑💻 自由职业者 每周五自动扫一遍各项目文件夹,看这周有什么变化。带着一份"客户记忆"(名字、项目目标、偏好语气),为每个客户起草个性化进度更新。草稿不直接发,丢进 review 文件夹等你过目,确认无误再寄出(这就是 human-in-the-Loop,人留在把关位置)。
循环条件:每个还在合作的客户,这周是否都更新到位?
🎓 学生 / 想追新的人 每周日趁你休息,搜一遍你所在领域过去一周最值得关注的进展。按"与你正在学的内容的相关度"打分,低于阈值的直接过滤,免得被噪声淹没。剩下的写成通俗简报,写前再比对过去几周,避免重复。
循环条件:这周是否有 ≥2 条真正算新的进展?没有就不硬凑。
🛒 网店老板 每月 1 号读一遍销售数据,看什么卖得好、什么没动静。挑出高流量却低转化的 3 个商品,重写描述,换更好的 hook、给更清楚的 CTA;再给 top 3 畅销品各写一段推广文案。每次改了什么、为什么改,都记录下来,方便下月回看哪些改动真起了作用。
**记录条件:**改了什么,为什么改,下个月回顾效果
✍️ 创作者 每周一读一遍完整选题清单,外加最近 90 天的内容表现数据。对照着看:哪些题材跑赢预期、哪些表现不佳,再结合当下趋势,给每个选题打分。最后输出排序后的 top 5,并标出哪些竞品已经做过,避免撞车。
补充说明:那个"相关度阈值"在拦什么? 学生场景里有一步"低于阈值的过滤掉"。它看似不起眼,却是循环能长期跑而不烦人的关键:每周新进展里大多是噪声,不设门槛,简报很快就会被无关信息塞满,读它反而成了负担。阈值的作用,是替你先把"勉强相关"的挡在外面,只让够格的进来。
最后提一句:这些循环跑得再顺,AI 也不是每一步都对。
尤其像"判断哪个选题会火"这种事,它并不可靠,给出的排序更多是一种有依据的猜测,而非结论。
所以更稳妥的用法,是把循环产出当作"多了一个有理有据的参考意见",而不是一个说了算的 Oracle。它替你把信息收齐、把初步判断摆出来;至于最后怎么取舍,仍留给自己。
写在最后
绕了一圈回到开头:Loop Engineering 其实没那么神秘。
它做的,无非是把你一直在手工跑的那个循环,连同一条明确的验收标准都交还给 Agent。
从前那个"再来一轮"的循环体是你;现在你从循环体里退出来,退回到设目标、定边界的位置。
变的不是循环本身,是谁来当那个一刻不能离开的执行者。
今天就能开一个最小 Closed Loop 试起来。建议的顺序是:
-
先 Closed,别一上来就放开边界
-
先小,挑一件验收标准能写清楚的事
-
先把"什么算达标"那条线划明白。
等这个小循环跑顺了,再考虑放开目标边界、加上 Orchestrator、接上定时触发,让它慢慢长成前面那种增长循环的样子。
说到底,这件事的乐趣或许就在于:你亲手把自己从循环里请了出来,又看着它替你转了起来。