讲完 journal 和持久化,这一篇讲存储引擎阶段的最后一个机制------压缩。它看起来只是「省磁盘」的功能,但实际上压缩同时影响三个性能维度:磁盘占用、Cache 效率、CPU 开销。选错压缩方式,要么浪费存储,要么把 CPU 打满,要么拖慢查询。
理解压缩的取舍,能解释几个现象:为什么同样的数据,MongoDB 磁盘占用比预期小很多(压缩生效)?为什么换了压缩率更高的算法,查询反而变慢了(CPU 成本上升)?这些都落在压缩的三方权衡上。
先把机制边界说清楚
WiredTiger 对每个 B-tree 页做压缩。页在磁盘上是压缩存储的,加载进 Cache 时解压(也有 compressed cache 模式,但默认是解压后放 Cache)。所以压缩影响的是「磁盘上的页」和「进出 Cache 的解压/压缩开销」。
压缩的三个杠杆:
- 磁盘:压缩率高,页更小,磁盘占用少,单页能装更多数据。
- Cache:页压缩后更小(如果 Cache 存压缩页)或解压后占原大小(默认解压存 Cache)。压缩对 Cache 的影响取决于具体模式。
- CPU:每次页进出 Cache 都要压缩/解压,压缩率越高的算法,CPU 开销越大。
这三者是个三角:压缩率、CPU 开销、随机访问效率,通常不能同时最优。选压缩算法就是在这个三角里找平衡点。
三种压缩方式对比

把三种主要块压缩算法放在一起,各自的定位立刻清晰。
snappy(默认)。Google 的高性能压缩库,压缩率中等(通常 50%--70%),但压缩和解压都极快,CPU 开销低,对随机访问友好。它是 WiredTiger 的默认压缩算法,也是绝大多数 OLTP 场景的最佳选择------平衡压缩率和性能,基本不需要动。如果你不确定选什么,就用 snappy(也就是保持默认)。
zstd。Facebook 的高压缩率算法,压缩率比 snappy 高(通常 70%--85%),但压缩和解压的 CPU 开销也明显更高。它适合「存储敏感、读写比偏写」的场景:归档数据、历史数据、冷数据。这类数据写入后很少读,省存储的价值大于 CPU 开销。但对高 QPS 的热数据,zstd 的解压 CPU 可能成为瓶颈,查询延迟反而上升。
zlib。经典压缩算法,压缩率和 CPU 开销都介于 snappy 和 zstd 之间(压缩率比 snappy 高、比 zstd 略低,CPU 开销也较高)。它是可选项里历史最久的,但在 zstd 出现后基本被 zstd 替代------zstd 在同等或更高压缩率下速度更快。今天新选型很少用 zlib,主要出现在老配置里。
需要先说清一个常见误解:MongoDB 没有「列式压缩」这种集合级压缩选项。WiredTiger 提供的是 block compressor(块压缩) ,按页压缩,snappy/zstd/zlib/none 四选一。真正的列存分析能力要靠 Atlas 的列存索引或外部分析引擎,不是 WiredTiger 的块压缩参数。WiredTiger 另有索引前缀压缩(prefix compression),对重复度高的索引键省空间,但只作用于索引,不作用于集合数据。
压缩率不是越高越好
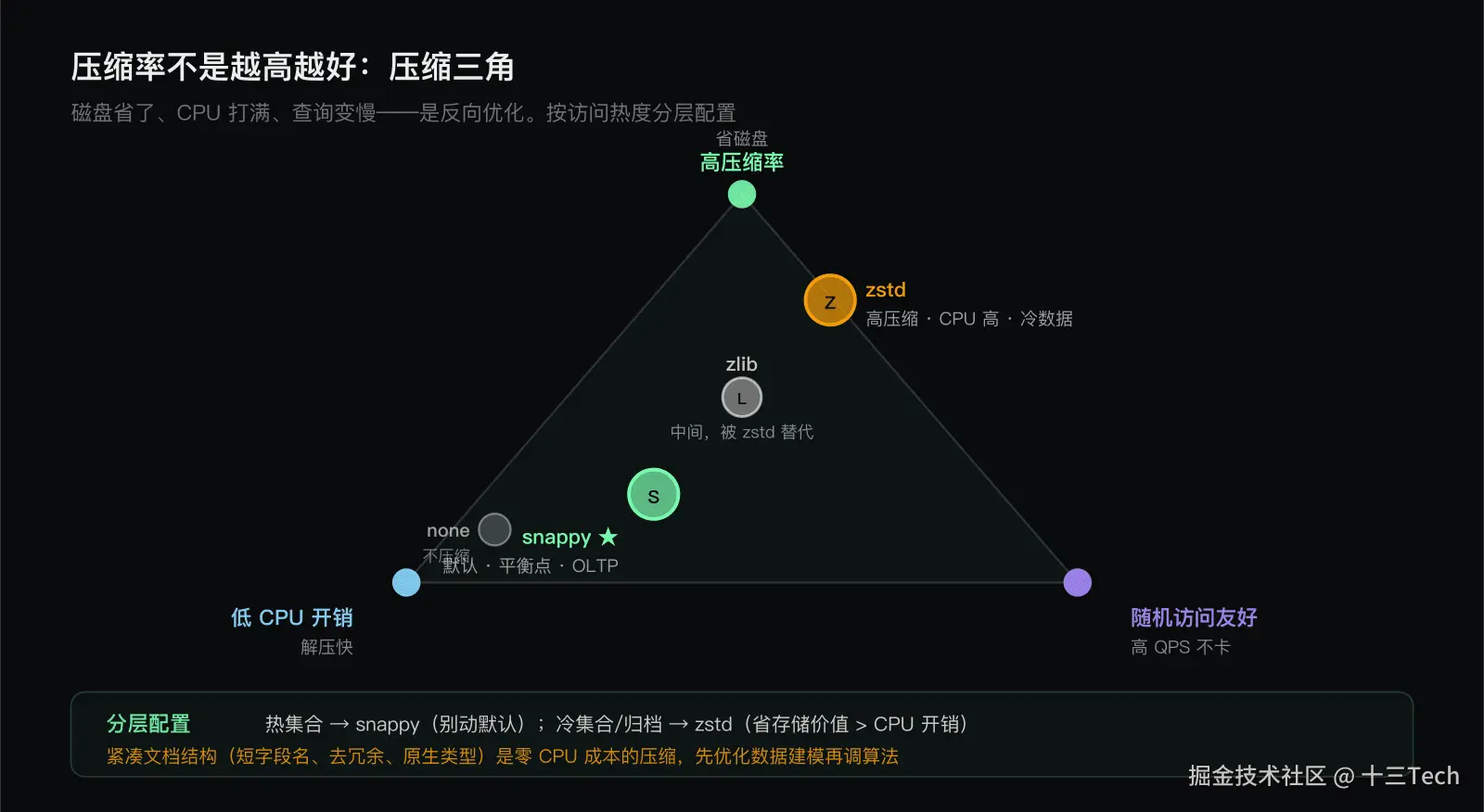
这是压缩最常见的误区。看到 zstd 压缩率比 snappy 高,就全局换成 zstd,结果发现查询变慢了。原因就是忽略了 CPU 成本:
- 每次从磁盘加载页到 Cache,要解压。压缩率越高,解压越慢。
- 每次脏页刷盘,要压缩。压缩率越高,压缩越慢。
- 高 QPS 场景,频繁的页加载和刷盘,压缩解压的 CPU 累积起来可能打满 CPU。
所以压缩率的取舍是:热数据用低 CPU 开销的(snappy),冷数据可以用高压缩率的(zstd)。MongoDB 允许按集合/索引单独配置压缩算法,所以最佳实践是按访问热度分层:热集合 snappy,冷集合 zstd。
压缩与 Cache 的关系
压缩对 Cache 的影响比较微妙,取决于 WiredTiger 的 cache 模式:
- 默认(解压后存 Cache):页加载进 Cache 时解压,Cache 里存的是解压后的页。这种模式下,压缩省的是磁盘,不省 Cache。Cache 能装的页数取决于解压后的大小。
- compressed cache(部分场景):页以压缩形式留在 Cache,访问时再解压。这种模式 Cache 能装更多页,但每次访问要解压,增加 CPU。
对大多数场景,默认模式(解压存 Cache)就够了。只有当 Cache 紧张、想多缓存一些页时,才考虑 compressed cache,但要接受访问时的解压开销。
一个被忽略的点:紧凑的文档结构本身就压缩了空间。短字段名、避免冗余字段、合理的数据类型,能让单页装更多文档,等效于提升 Cache 效率。这是不花 CPU 就能获得的「压缩」。
怎么选压缩策略
把压缩选择收敛成几条原则:
- 通用 OLTP → snappy(默认)。别动默认,它在压缩率和 CPU 之间平衡得最好。
- 存储敏感、读少写多 → zstd。归档、历史、冷数据,省存储价值大于 CPU 成本。
- 老配置或特定兼容需求 → zlib。zstd 出现后基本没必要新选 zlib,主要在历史配置里见到。
- 热集合 vs 冷集合分层。不要全局一个算法,按访问热度分层配置。
- 紧凑文档结构。短字段名、去冗余、用原生类型,是零 CPU 成本的压缩。
配置方式是创建集合/索引时指定:
javascript
db.createCollection("archive", {
storageEngine: { wiredTiger: { configString: "block_compressor=zstd" } }
})取舍与边界
压缩的边界要记住:
- 压缩率高的算法不等于更好。CPU 开销可能抵消存储节省带来的收益。
- 压缩不能替代合理的数据建模。文档结构臃肿,压缩率再高也是治标。
- 压缩算法一旦选定,切换有成本。改压缩算法要重建集合(rewrite),大集合上是大操作。
- MongoDB 没有集合级「列式压缩」。块压缩只有 snappy/zstd/zlib/none 四个块压缩选项;列存分析要靠 Atlas 列存索引或外部引擎,别在 WiredTiger 的压缩参数里找。
判断框架
- 默认 snappy,除非有明确的存储或访问模式理由才换。
- 热→snappy,冷→zstd,按访问模式分层。
- 换压缩算法前评估 CPU:高 QPS 场景,解压 CPU 可能成为瓶颈。
- 紧凑文档结构是零成本的压缩,先优化数据建模再考虑压缩算法。
- 想要「列存」效果要靠 Atlas 列存索引或外部引擎,不是 WiredTiger 块压缩。
- 压缩率不是 KPI,存储省了但查询慢了,是反向优化。
下一篇是存储引擎阶段的收尾,讲大集合与工作集超过内存时怎么办。
关于十三Tech
All in AI Agent 方向的架构师,专注 AI 工程实践。
相信 AI 是程序员的最佳搭档,帮助每一位开发者驾驭 AI。
公众号搜索「十三Tech」