- 绪论
- 研究 背景 与意义
地震灾害以其突发性强、破坏性大、影响范围广等特点,长期以来对人类社会的生存与发展构成严峻挑战。根据美国地质调查局(USGS)统计数据显示,全球每年平均发生约五十万次可被探测到的地震,其中具有破坏性的五级以上地震约千余次,造成重大人员伤亡和财产损失的强震亦时有发生。中国地处环太平洋地震带与欧亚地震带交汇区域,地震活动频繁,近二十年来先后发生汶川地震、玉树地震、芦山地震等重大地震灾害,防震减灾工作始终面临巨大压力。当前,国内外地震监测机构已积累了海量的历史地震数据,USGS、中国地震台网中心等平台均提供公开的地震目录供研究使用。然而,深入分析现有平台后发现,多数系统仍停留在数据发布、基础查询和简单统计层面,对于地震数据的深度挖掘与智能化分析功能相对薄弱。例如,缺乏对地震空间聚集规律的有效识别,难以快速判断哪些区域属于地震活跃带;同时也缺少基于历史数据的风险预测机制,无法为应急管理提供量化参考。基于此,本文选择将机器学习技术引入地震数据分析领域,以USGS公开的2000年至2025年地震目录数据为基础,构建一套集数据管理、可视化展示与智能分析于一体的综合性平台。平台不仅实现地震数据的存储与查询,更通过空间聚类算法识别地震聚集区域,并利用分类模型对地震事件进行风险等级预测,旨在弥补现有平台在数据分析深度方面的不足。
从研究意义来看,本课题的开展兼具理论探索与实践应用双重价值。在理论层面,将DBSCAN聚类算法与随机森林分类模型应用于地震数据分析,验证了机器学习方法在地震空间规律挖掘与风险预测中的可行性与有效性,为地震学与计算机科学的交叉研究提供参考案例。在实践层面,系统所实现的地震活跃区域识别与风险等级预测功能,可为地震监测部门、应急管理机构以及相关研究人员提供直观的数据分析工具和决策辅助信息。通过地图可视化展示地震分布与聚类结果,用户能够快速把握地震活动的空间格局;通过单点风险预测功能,可对特定区域的地震风险做出快速评估。上述功能对于提升地震灾害认知水平、优化应急资源部署、辅助防灾减灾决策均具有积极的现实意义。
-
- 国内外研究现状
- 国内研究现状
- 国内外研究现状
国内学者将机器学习技术应用于地震数据解析与地球物理勘探的研究日趋活跃与深入,其应用范围已从单一的数据处理环节扩展到全流程的智能化革新,为本系统的构建提供了坚实的技术背景和思路借鉴。
在地震数据预处理与增强方面,研究聚焦于利用机器学习算法提升数据质量。例如,侯思安1等人针对多分量地震数据重建的难题,摒弃了传统解析方法构建显式物理关系的思路,创新性地引入K-SVD字典学习与并行矩阵分解等机器学习算法。这些方法能够自适应地学习多分量数据间的隐式统计关联,在复杂地质条件下实现了更精确、稳定的数据重建,为后续分析提供了高质量的数据基础。齐娇2的研究则针对多次波压制这一经典难题,将2D/3D卷积自编码器与U-Net等深度学习网络结构引入其中,通过训练网络自动学习一次波与多次波在时空域中的复杂非线性特征差异,实现了高保幅的噪声压制,显著提升了地震资料的信噪比与成像真实性。
在地震信号识别与分类层面,机器学习展现出强大的模式辨别能力。如本刊讯所3介绍的,研究者已开始利用机器学习算法从连续地震记录中自动识别和分类细微的地震事件,甚至发现其与注水活动等人类作业相关的周期性模式。这种从海量"数据"中自动提炼"信息"的能力,正是进行地震活动性分析和风险模式挖掘的关键。
在地球物理参数反演与解释领域,机器学习为建立观测数据与地下属性间的复杂映射关系提供了新途径。丁博4的研究直接利用机器学习模型(如神经网络)建立了重力异常与莫霍面深度之间的关联, bypass了传统反演中需要精确已知密度差等参数的局限性,取得了比传统方法更优的反演精度。这证实了数据驱动方法在解决复杂地球物理反演问题上的潜力。
面向自动化与智能化处理流程的构建,国内研究也取得了实质性进展。董晟5指出,面对观测数据量的激增,发展基于深度学习(如卷积神经网络)的自动化数据处理流程已成为迫切需求。李子正6的研究则构建了包含信号去噪、震相识别、事件关联与定位的完整微地震自动化处理流程,并通过实际数据验证了其相对于传统人工处理流程的可靠性与高效性,为地震监测的实时化与智能化提供了范式。
国内研究已广泛探索了机器学习在地震数据"处理-识别-反演-监测"全链条中的应用,其核心趋势是从解决单一问题的算法创新7,转向构建集成化的智能分析系统。本研究正是在此背景下,旨在设计并实现一个集数据挖掘、机器学习建模、风险可视化与研判于一体的综合系统,将前述各环节的核心能力(如数据重建、信号分类、模式挖掘)进行有机整合与工程化实现8,服务于区域地震风险的综合评估这一宏观目标,是对当前国内研究趋势的一次具体实践与拓展。
-
-
- 国外研究现状
-
国外研究在将机器学习应用于地震数据分析方面起步较早,已形成从基础算法创新到前沿应用探索的成熟体系,其研究呈现出算法更深入、应用更前沿、自动化程度更高的特点,为本系统的设计与实现提供了重要的技术参照和思路启发。
在地震数据自动处理与事件识别方面,研究已超越传统算法,普遍采用先进的深度学习模型以实现高精度自动化。例如,Adnan Akmal Sani9等人的研究应用基于CNN和LSTM的EQTransformer模型进行P波和S波的自动拾取,并集成高斯混合模型进行事件关联与定位,显著提升了海量数据处理的效率和一致性,为实时地震监测与快速编目提供了关键技术支撑,这正是风险研判系统所需的基础数据自动化处理能力。
在地震地质属性预测与解释领域,研究侧重于利用机器学习构建复杂的地下属性映射模型。如Muhsan Ehsan10的研究综合梯度提升回归(GBR)与连续小波变换(CWT),并最终利用深度神经网络(DNN)进行三维孔隙压力建模,展示了机器学习整合多源地球物理数据、解决复杂非线性反演问题的强大能力。Ismailalwali Babikir11的研究则聚焦于通过属性优化提升地震相分类的准确性,这类研究为从地震数据中自动提取地质构造与岩性信息提供了方法论,是深度数据挖掘的重要组成部分。
尤为值得注意的是,国外研究已开始注重人机交互与决策解释。Erhao Zhang12的研究不仅使用CatBoost模型预测个体对地震的感知能力,更引入了SHAP(可解释性人工智能)方法对模型预测结果进行归因分析,明确了年龄、性别等关键因素的影响程度。这种将高精度预测与可解释性分析相结合的研究范式,对于构建面向决策支持的风险研判系统至关重要,它使机器的"黑箱"判断变得透明、可信,从而能够为应急管理提供具有明确行动指向的洞见。
国外研究现状表明,机器学习在地震领域的应用已进入深度融合阶段:一方面,以深度学习为代表的复杂模型驱动着数据处理与解释的自动化、智能化水平不断提升;另一方面,以可解释性AI为代表的技术正致力于增强模型结论的可靠性与实用性。
- 拟解决的主要问题
地震数据多维度特征挖掘与知识发现问题: 如何利用机器学习算法,从Kaggle数据集的经度、纬度、时间及多种震级指标(XM, MW, MS, MB)中,挖掘出有意义的时空分布模式、震级关联规则及潜在风险区域。
地震风险动态研判模型构建问题: 如何选择合适的机器学习模型(如基于历史地震密度和强度的聚类算法、或基于特征的分类模型),建立能够对特定区域(如基于城市/国家或自定义网格)进行地震风险等级(如高、中、低)研判的模型。
分析结果的可视化与系统集成问题: 如何将数据挖掘结果(如聚类热区、风险地图)和模型研判结论,通过ECharts等可视化库,在基于Bootstrap的前端页面中进行直观、交互式的展示,并利用Flask框架将数据预处理、模型推理和前端展示无缝集成到一个稳定、易用的Web系统中。
-
- 研究内容
本文围绕地震数据分析与风险预测这一核心问题,综合运用多种研究方法开展系统设计与实现,具体研究内容如下。
1、文献研究法
通过查阅国内外地震数据管理与分析领域的相关文献资料,系统梳理了美国地质调查局、中国地震台网中心等机构现有平台的功能架构与数据服务模式。重点分析了DBSCAN空间聚类算法在地震活跃区域识别中的应用现状,以及随机森林分类器在灾害风险评估领域的相关研究成果。通过文献研读,明确了现有平台在数据挖掘深度和智能分析能力方面存在的不足,为本文系统的功能定位与技术选型提供了理论依据。
2、比较分析法
在机器学习模型构建过程中,运用比较分析法对多种聚类算法与分类算法进行对比实验。对于空间聚类任务,对比了DBSCAN与KMeans算法在不同参数配置下的聚类效果,以轮廓系数作为评价指标筛选最优参数组合。对于风险预测任务,对比了随机森林、支持向量机与逻辑回归等分类器在相同数据集上的预测准确率,最终选择随机森林作为核心分类模型。通过统计方法的横向比较,确保了模型选型的合理性与性能的可靠性。
3、经验总结法
在系统开发过程中,结合以往Web应用开发经验,对前后端交互流程、数据库设计模式以及模型训练策略进行了持续优化。针对地震数据量大可能导致的内存溢出问题,采用分批查询与批量更新的方式改进数据处理流程;针对可视化地图加载缓慢的问题,通过数据采样与缓存机制提升页面响应速度。将实践中积累的经验转化为可复用的技术方案,有效提升了系统的稳定性与用户体验。
4、应急避险服务与系统交互设计
研究如何将地震数据挖掘结果与防灾减灾实际应用相结合,构建以用户为中心的应急避险服务中心。重点包括:(1) 构建结构化的多场景地震避险知识库,涵盖自救互救、六大场所避险、余震防范及谣言甄别等内容;(2) 设计并实现个性化避险方案生成算法,基于用户输入的经纬度与震级,自动识别所在地震带,并结合风险评估模型,输出包含即时行动、撤离路线和附近避难所的定制化方案;(3) 通过后端Flask框架与前端Bootstrap、ECharts技术,实现上述功能的Web集成与交互设计,确保信息呈现清晰、操作便捷。
- 相关技术及理论基础
- 系统开发技术
本系统采用Python作为主要开发语言,基于Flask轻量级Web框架构建后端服务。Flask框架以其简洁灵活的特点,适合中小型Web应用的快速开发,其核心仅提供路由分发与请求处理功能,其他扩展模块可根据需求灵活集成。Flask-Login作为Flask生态中成熟的用户认证扩展,负责管理用户会话状态,通过login_user与logout_user方法实现登录与登出功能,同时提供login_required装饰器对需要身份验证的路由进行保护。
前端部分采用Bootstrap 5框架构建响应式用户界面,该框架提供了丰富的UI组件与栅格系统,能够适配不同尺寸的显示设备。数据可视化层使用ECharts图表库实现,ECharts支持多种图表类型,包括散点图、柱状图、折线图与地图等,其底层基于Canvas渲染,在大数据量场景下仍能保持良好的交互性能。全球地震分布地图通过ECharts的geo坐标系组件实现,将地震事件的经纬度坐标映射至地图坐标系,并根据震级大小动态调整散点符号尺寸其中S表示散点符号尺寸,M为地震震级,该公式确保震级越大则点越大,同时将尺寸范围限定在3至10之间,避免极端值造成视觉过度夸张。
数据持久化方面,系统选用SQLite嵌入式数据库,该数据库以单一文件形式存储数据,无需独立的数据库服务器进程,部署简便且资源占用低。SQLAlchemy作为Python生态中最成熟的ORM框架,提供了对象关系映射能力,使开发者能够通过Python对象操作数据库记录,避免直接编写SQL语句。地震数据表earthquake_data包含时间、经纬度、深度、震级等字段,其中时间字段建立索引以优化时间范围查询的性能。
-
- 机器学习理论基础
- DBSCAN空间聚类算法
- 机器学习理论基础
DBSCAN是一种基于密度的空间聚类算法,其核心思想是找出被低密度区域分隔的高密度区域,能够识别任意形状的聚类并自动处理噪声点,这与地震活跃区域的空间分布特征高度契合。该算法定义了两个关键参数:邻域半径varepsilon和最小样本数minPts。对于数据集中的任一点p,其varepsilon邻域定义为以p为中心、半径为varepsilon的超球体内包含的所有点集合,其中D为数据集,dist(p,q)表示点p与q之间的距离,在地震聚类任务中通常采用欧氏距离计算经纬度坐标间的空间距离。若N_(p),则p被标记为核心点;若N_varepsilon(p)| < minPts但p位于某个核心点的varepsilon邻域内,则p为边界点;否则p为噪声点。聚类过程从任意核心点出发,通过密度可达关系将相邻核心点及其边界点归入同一聚类。本系统中,考虑到全球地震数据分布特点,经过参数调优后设置varepsilon=2.0、minPts=50,聚类结果以轮廓系数作为评价指标,其中a(i)表示样本i到同簇其他样本的平均距离,b(i)表示样本i到其他簇样本的最小平均距离,轮廓系数取值在-1至1之间,值越接近1表示聚类效果越好。
-
-
- 随机森林分类算法
-
随机森林是一种基于Bagging集成策略的监督学习算法,通过构建多个决策树并综合其预测结果来提升模型的准确性与稳定性。每棵决策树在训练时采用自助采样法从原始数据集中有放回地抽取样本,并在每个节点分裂时随机选择部分特征进行最优分割,这种双重随机机制有效降低了过拟合风险。对于分类任务,随机森林的输出由所有决策树的投票结果决定,其中T为决策树数量,h_t(x)为第t棵决策树的预测类别,mode表示取众数作为最终预测结果。本系统构建的随机森林分类器以地震深度、震级、经度、纬度作为特征输入,输出低风险、中风险、高风险三个等级。决策树节点分裂时采用基尼系数作为不纯度衡量指标,其中K为类别数,p_k为第k类样本在节点中的比例,基尼系数越小表示节点纯度越高。模型训练过程中将数据集按8:2划分为训练集与测试集,训练集用于参数学习,测试集用于评估模型泛化能力,评价指标包括准确率、精确率、召回率及F1值。
-
-
- 数据预处理技术
-
机器学习模型对输入数据的尺度较为敏感,不同特征若量纲差异过大,会影响模型收敛速度及最终性能。本系统采用Z-Score标准化方法对特征数据进行处理,将原始数据转换为均值为0、标准差为1的分布,其中x为原始特征值,u为该特征的均值,q为标准差。标准化后的特征消除了量纲影响,使不同特征在数值上具有可比性,有效提升了聚类算法与分类模型的训练效果。在数据清洗阶段,对缺失值进行填充处理,对异常值进行剔除,确保输入数据的质量符合模型训练要求。
- 系统需求分析
- 可行性分析
经济可行性分析方面,本系统开发所需的软件工具均为开源或免费产品,包括Python开发环境、Flask框架、SQLite数据库以及各类第三方库,无需支付软件授权费用。硬件方面,系统可部署于普通个人计算机或云服务器,无需购置专用设备。开发成本主要为人力成本和时间成本,系统运行后能够有效提升地震数据分析效率,减少人工统计和分析的工作量,为地震监测与应急决策提供数据支撑,其间接效益远高于开发成本。综上所述,系统从经济上是可行的。
技术可行性分析方面,本系统采用的技术栈均为成熟稳定的主流技术。Python语言拥有丰富的科学计算库和机器学习库,Flask框架文档齐全、社区活跃,ECharts可视化库功能完善,Scikit-learn提供了成熟的机器学习算法实现。上述技术在本研究团队的能力范围内,开发过程中遇到的技术问题可通过查阅资料和调试解决。综上所述,系统从技术上是可行的。
操作可行性分析方面,系统前端采用Bootstrap框架构建,界面布局清晰,交互方式符合用户使用习惯。普通用户通过浏览器即可访问系统,无需安装额外软件;管理员通过后台管理界面可完成数据维护和模型训练等操作,操作流程直观。综上所述,系统从操作上是可行的。
-
- 业务流程分析
本系统核心业务流程围绕地震数据可视化与智能分析展开,主要包括数据可视化流程、风险预测流程、模型训练流程和数据管理流程四个核心模块。
数据可视化流程是普通用户使用系统的核心业务。用户进入可视化页面后,系统默认加载全球地震分布地图,展示所有地震事件的空间位置。用户可根据需要选择按震级过滤(M5+、M6+、M7+)或按风险等级过滤(低、中、高),地图实时更新显示符合条件的地震点。系统同时自动计算并展示震级分布统计图、深度分布统计图和时间序列趋势图,帮助用户多维度了解地震数据特征。如图3.1 数据可视化业务流程图。
图3-1 数据可视化业务流程图
应急避险服务流程是本系统面向公众的核心业务。用户进入"应急避险"页面后,可按分类浏览地震自救、互救、不同场所避险等图文和视频知识。当用户使用"个性化避险方案"功能时,需输入所在位置的经度、纬度及预估地震震级,提交后系统自动识别该位置所属地震带,综合评估风险,生成包含"震时应急措施"、"紧急撤离路线"、"最近避难所位置"等内容的专属方案,并以结构化卡片形式呈现。如图3.2所示:
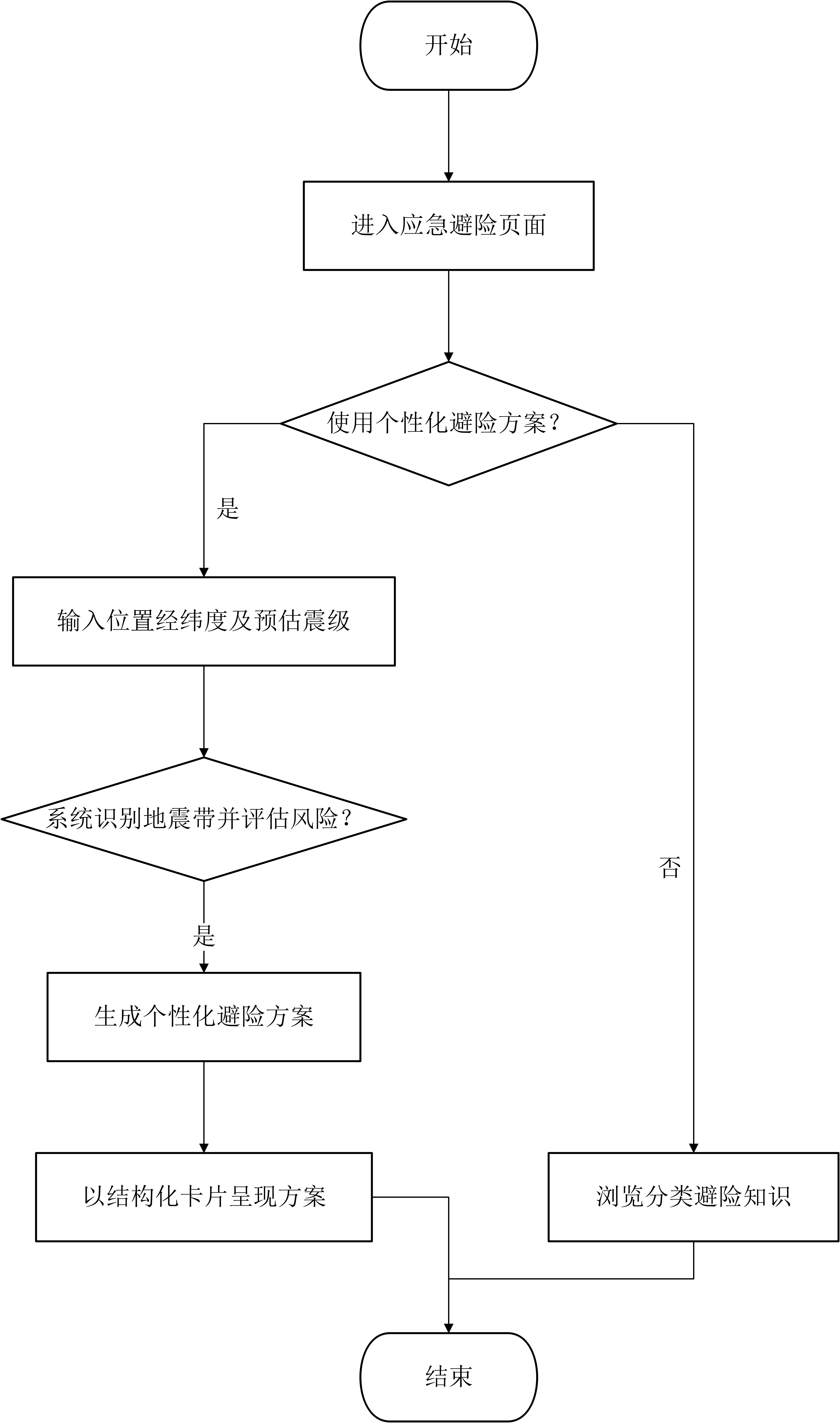
图3-2 应急避险服务流程图
模型训练流程面向管理员用户。管理员进入模型管理页面,点击训练按钮后系统触发模型训练任务。后端从数据库读取地震数据,依次进行数据标准化、DBSCAN聚类训练和随机森林分类训练,训练过程中输出日志信息,训练完成后将聚类标签和风险等级结果更新至数据库,并将模型文件持久化存储。管理员可通过训练日志查看训练进度和模型评估指标。如图3.3 模型训练业务流程图所示:
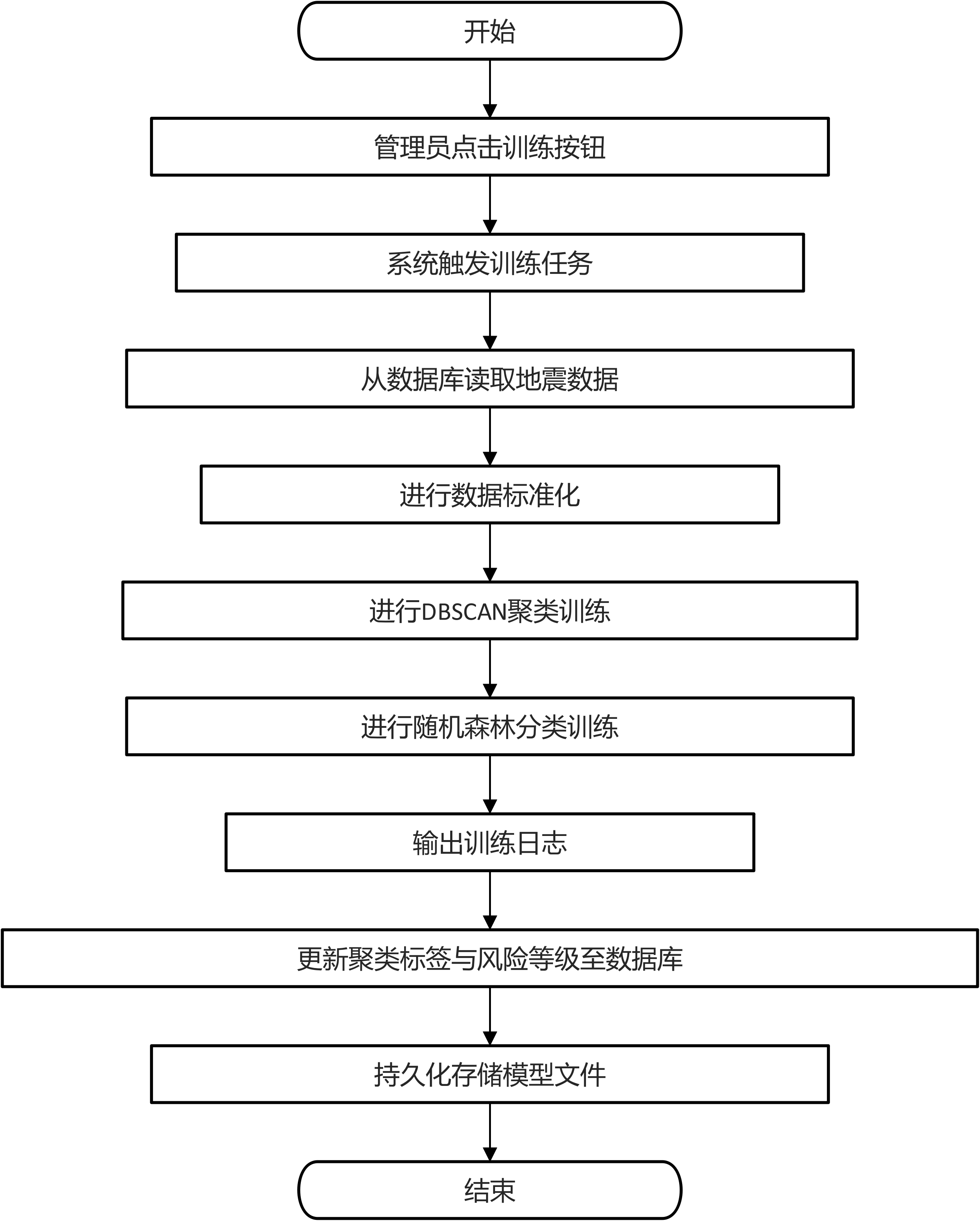
图3-3 模型训练业务流程图
数据管理流程也由管理员执行。管理员进入数据管理页面,系统分页展示地震数据列表,每页显示20条记录,按时间倒序排列。管理员可对单条数据进行编辑或删除操作,也可通过添加按钮新增地震记录。添加或编辑数据时弹出模态框,填写完成后提交至后端,后端验证数据格式后更新数据库并刷新列表。数据管理流程图如图3.1至图3.4所示。如图3.4 数据管理业务流程图所示。
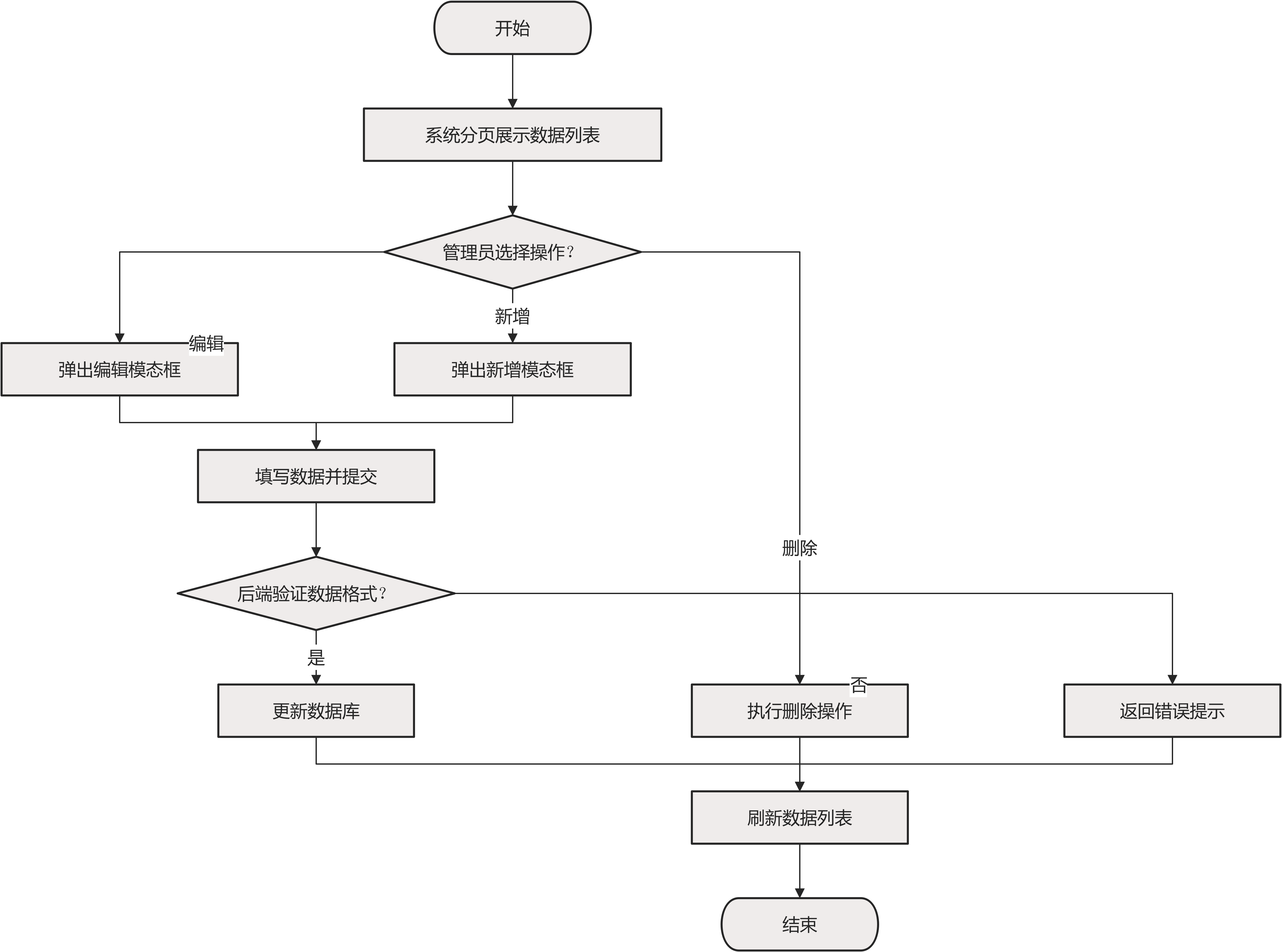
图3-4 数据管理业务流程图
-
- 功能需求分析
根据系统角色权限划分,本系统用户分为普通用户和管理员两类,各自拥有不同的功能权限。
普通用户无需登录即可访问系统首页查看系统介绍,但使用核心功能前需完成注册和登录。登录后的普通用户可以访问数据可视化、智能分析等功能模块。数据可视化功能包括全球地震分布地图展示,支持按震级和风险等级筛选,同时提供震级分布饼图、深度分布柱状图、时间序列折线图和聚类分析地图,用户可通过图表交互获取详细数据。用户可在查询页面通过设定时间范围、震级区间和地区关键词,精确检索历史地震事件,结果以分页表格形式展示。用户可以分类浏览丰富的避险知识,包括文章和视频。系统支持知识搜索和精选内容推荐。用户输入任意地点的经纬度和地震震级,系统自动生成包含风险评估、分阶段行动指南、附近避难所和撤离路线的专属方案。
管理员在普通用户功能基础上,拥有系统管理权限。管理后台功能包括仪表盘、用户管理、数据管理和模型管理四个子模块。仪表盘展示系统核心统计指标,包括用户总数、地震记录数和高风险事件数。用户管理模块支持查看所有注册用户信息,可编辑用户资料或删除用户。数据管理模块提供地震数据的完整CRUD操作,支持分页浏览、按条件查询、新增记录、编辑记录和删除记录,数据列表展示时间、位置、震级、深度、风险等级和聚类标签等信息。模型管理模块提供模型训练入口,管理员可一键触发DBSCAN和随机森林模型训练,训练完成后系统自动更新数据库中的聚类标签和风险等级字段。管理员可通过专门的后台界面对避险知识分类、文章和视频进行增加、编辑、删除等操作,支持对文章进行精选和排序。
-
- 非 功能需求分析
性能需求方面,系统应保证页面加载速度,地图初始化时间控制在3秒以内,数据列表分页切换响应时间不超过2秒。模型训练过程中,对于五万条以内的数据量,训练完成时间应控制在5分钟以内,训练过程不阻塞其他页面访问。
可靠性需求方面,系统需保证数据的完整性和一致性,数据导入和更新操作采用事务机制,异常发生时能够回滚。用户密码采用哈希加密存储,防止数据泄露。模型文件应持久化保存,服务器重启后模型仍可正常加载使用。
可扩展性需求方面,系统应支持业务功能的灵活扩展。避险知识库的内容应独立于系统代码,支持管理员动态更新。个性化方案生成逻辑应模块化,便于集成更丰富的地理信息或更复杂的灾害模型。数据库设计预留了查询日志记录功能,便于未来进行用户行为分析。
- 系统设计
- 系统总体架构设计
本系统采用分层架构设计模式,将系统划分为表现层、业务逻辑层、数据访问层和数据存储层四个层次,各层之间通过接口进行交互,降低耦合度。表现层负责用户交互与数据可视化,运行于客户端浏览器中,通过Ajax异步请求与后端服务进行数据交换。业务逻辑层部署于服务器端,接收前端请求后调用相应服务模块完成业务处理,包括用户认证、数据查询、模型预测等功能。数据访问层基于SQLAlchemy ORM框架实现,将数据库操作封装为对象方法,隔离底层数据库差异。数据存储层采用SQLite关系型数据库,存储用户信息与地震事件数据。
数据流动方向遵循自顶向下的请求路径和自底向上的响应路径。用户通过浏览器发起HTTP请求,请求到达Flask路由层后,根据URL映射至对应视图函数。视图函数解析请求参数,调用Service层方法执行业务逻辑,Service层通过ORM模型操作数据库,获取数据后经处理返回给视图函数。视图函数将数据封装为JSON格式返回至前端,前端通过回调函数更新页面视图。机器学习模块独立于主业务流程之外,模型训练时从数据库读取数据,训练完成后将结果写回数据库,并通过Joblib持久化模型文件,供预测接口调用。系统架构图如图4.1所示。
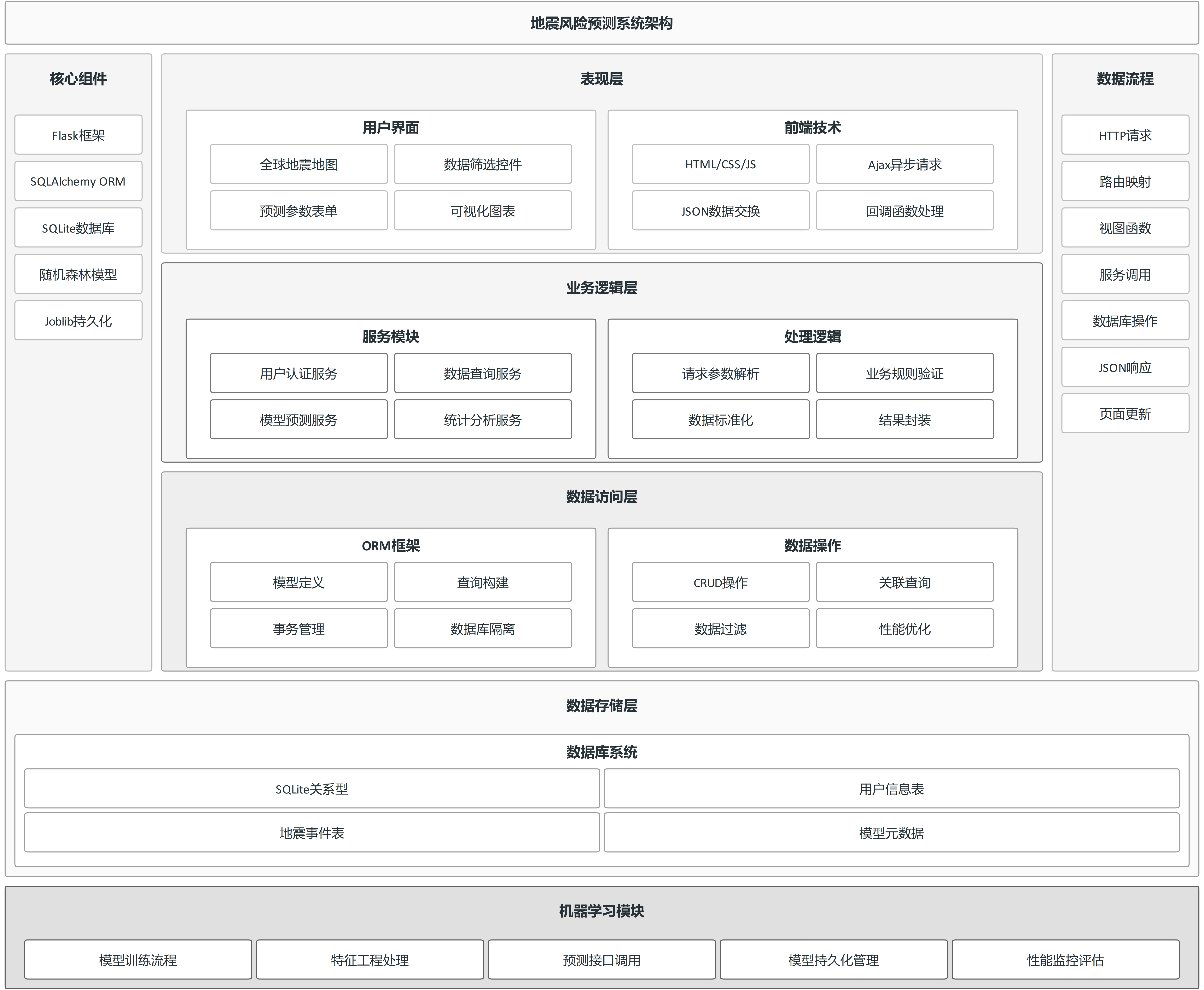
图4-1 系统架构图
-
- 功能模块设计
本系统是一套集地震数据管理、可视化展示与智能分析于一体的综合平台,为用户提供地震数据的多维度查询与风险预测服务,为管理员提供数据维护与模型管理功能。系统功能划分为用户认证模块、数据可视化模块、应急避险服务模块、管理端模块和数据导入模块五大核心模块。
用户认证模块负责用户注册、登录和会话管理,通过Flask-Login实现认证状态维护,采用装饰器实现基于角色的访问控制。数据可视化模块包含全球地震分布地图、震级分布饼图、深度分布柱状图、时间序列折线图和聚类分析地图五个子功能,用户可按震级或风险等级过滤数据,地图散点大小随震级动态变化。应急避险服务模块包含地震知识库(图文、视频教程的浏览与搜索)、个性化避险方案生成器(基于位置和震级生成方案)和数据查询(按时间、震级、地区检索历史地震)三个子功能。管理端模块面向管理员用户,包含仪表盘统计、用户管理、数据管理和模型管理以及避险内容管理五个子功能,支持用户信息维护、地震数据增删改查以及模型一键训练。数据导入模块支持Excel格式地震数据的批量导入,自动完成数据清洗和特征工程后存入数据库。系统功能模块图如图4.2所示。
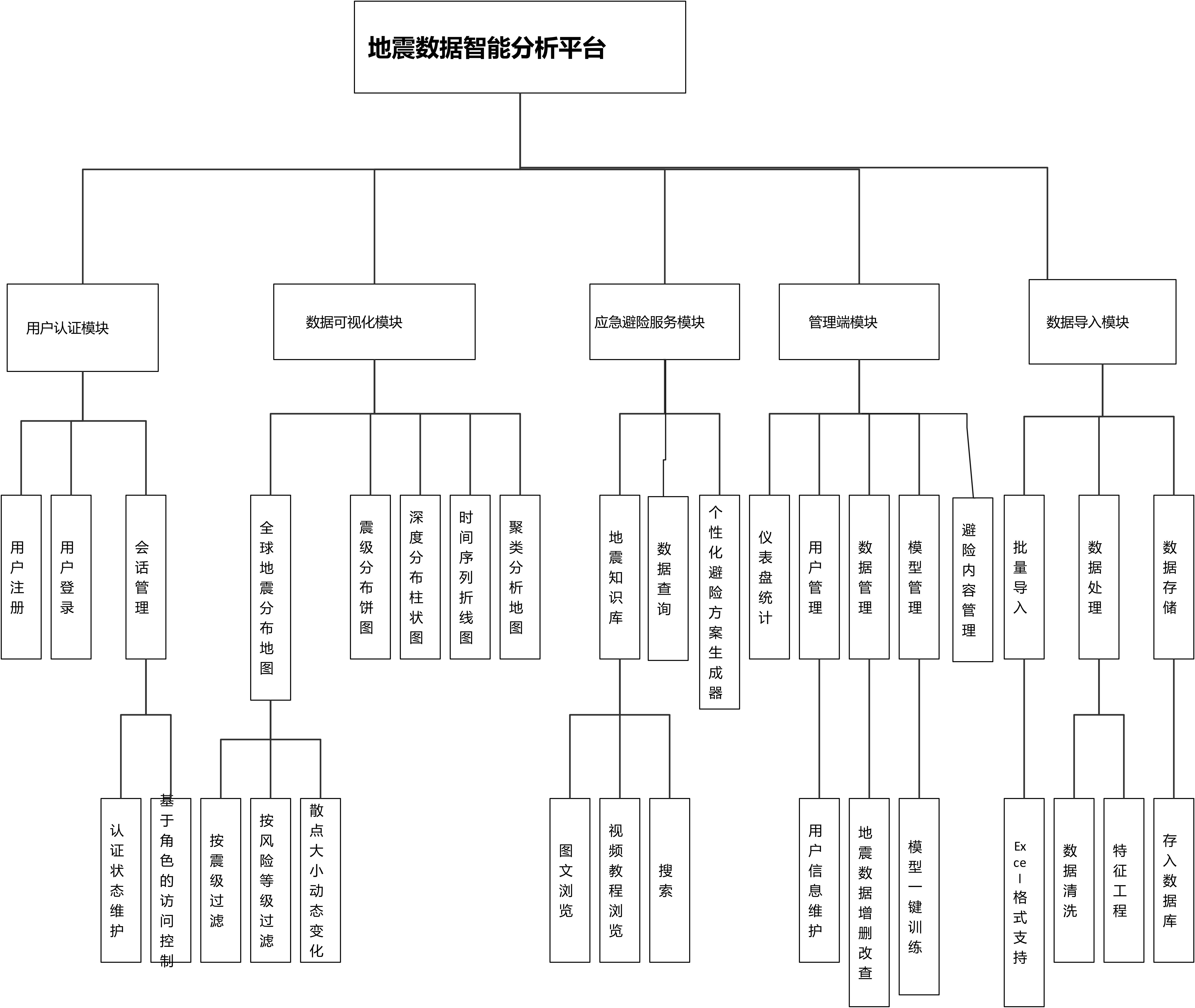
图4-2 系统功能图
-
- 数据库设计
- 数据库关系设计
- 数据库设计
本系统采用SQLite关系型数据库进行数据存储。在设计数据库表结构时,综合考虑了数据的独立性、完整性和查询效率,遵循第三范式进行表结构设计。系统共设计两张数据表,分别为用户表(users)和地震数据表(earthquake_data)。两张表之间不存在直接的业务关联,因此未设置外键约束,通过应用程序逻辑保证数据的一致性。用户表用于存储系统用户的基本信息和权限配置,地震数据表用于存储地震事件的详细信息及机器学习模型的分析结果。数据库E-R图如图4.3所示。
图4-3 系统E-R图
-
-
- 数据库表设计
-
用户表(users)用于记录系统注册用户的基本信息,包括用户唯一标识、登录名、邮箱地址、密码哈希值、用户角色和注册时间。用户角色字段区分普通用户和管理员,用于权限控制。密码采用Werkzeug提供的哈希加密算法存储,确保账户安全性。用户表结构如表4.1所示。
表4-1 用户表
|---------------|--------------|------------------|-----------------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | INTEGER | PRIMARY KEY | 用户ID,自增主键 |
| username | VARCHAR(80) | UNIQUE, NOT NULL | 用户名,唯一约束 |
| email | VARCHAR(120) | UNIQUE, NOT NULL | 邮箱地址,唯一约束 |
| password_hash | VARCHAR(255) | NOT NULL | 密码哈希值 |
| role | VARCHAR(20) | DEFAULT 'user' | 用户角色,user或admin |
地震数据表(earthquake_data)用于存储地震事件的详细信息,包括地震发生时间、震源位置、震级参数、定位精度指标以及机器学习模型的分析结果。时间字段建立索引以优化时间范围查询性能。聚类标签字段默认值为-1表示噪声点,风险等级字段默认值为low。该表结构完整覆盖了原始地震数据的各项指标,同时预留了聚类和分类模型的分析结果字段,满足系统数据存储与查询需求。地震数据表结构如表4.2所示。
表4-2 earthquake_data表
|------------------|--------------|-----------------|-------------|
| 字段名 | 数据类型 | 约束 | 说明 |
| id | INTEGER | PRIMARY KEY | 地震记录ID,自增主键 |
| time | DATETIME | NOT NULL, INDEX | 地震发生时间,建立索引 |
| latitude | FLOAT | NOT NULL | 纬度 |
| longitude | FLOAT | NOT NULL | 经度 |
| depth | FLOAT | NOT NULL | 震源深度,单位千米 |
| mag | FLOAT | NOT NULL | 震级 |
| mag_type | VARCHAR(10) | - | 震级类型 |
| nst | INTEGER | - | 定位震相的台站数 |
| gap | FLOAT | - | 方位角间隔 |
| dmin | FLOAT | - | 最近台站距离 |
| rms | FLOAT | - | 均方根残差 |
| place | VARCHAR(255) | - | 位置描述 |
| type | VARCHAR(50) | - | 地震类型 |
| horizontal_error | FLOAT | - | 水平误差 |
| depth_error | FLOAT | - | 深度误差 |
| mag_error | FLOAT | - | 震级误差 |
| mag_nst | INTEGER | - | 计算震级使用的台站数 |
| cluster_label | INTEGER | DEFAULT -1 | DBSCAN聚类标签 |
| risk_level | VARCHAR(20) | DEFAULT 'low' | 风险等级 |
-
- 机器学习模型设计与实现
- 数据来源与数据分布
- 机器学习模型设计与实现
本系统采用的地震数据来源于美国地质调查局(USGS)公开的地震目录,时间跨度为2000年至2025年,原始数据以Excel格式存储在static/data/usgs_earthquake_data_2000_2025.xlsx文件中。经数据导入脚本处理,共获得约五万条有效地震记录,每条记录包含时间、纬度、经度、深度、震级、震级类型、定位台站数、位置描述等二十余个字段。从震级分布来看,最小震级为0.5级,最大震级为8.5级,平均震级约4.2级;深度范围从0公里至700公里,平均深度约60公里。空间分布上,数据覆盖了环太平洋地震带、欧亚地震带以及大洋中脊地区,其中环太平洋区域(日本、印尼、台湾、加州、新西兰等)记录最为密集,与地震活跃带分布特征吻合。这一数据分布特点为后续的聚类分析和风险分类提供了充足的样本基础。
-
-
- 数据处理与特征工程
-
在模型训练前,需要对原始数据进行清洗和特征转换。数据处理流程在app/services/ml_models.py中实现,具体包含以下步骤:
(1)缺失值处理:聚类和分类任务所需的核心字段(纬度、经度、深度、震级)均无缺失,因此直接使用;其他辅助字段(如nst、gap等)在模型训练中不参与计算,无需填充。
(2)特征提取:对于DBSCAN聚类模型,选取latitude、longitude和mag三个特征,构建特征矩阵。对于随机森林分类模型,选取depth、mag、longitude和latitude四个特征作为输入,以震级作为划分风险等级的依据生成标签:当mag < 5.0时标记为0(低风险),5.0 ≤ mag < 6.0时标记为1(中风险),mag ≥ 6.0时标记为2(高风险)。这一标签划分方式直接对应代码中prepare_classification_data函数的逻辑。
(3)数据标准化:由于不同特征的量纲差异较大(如震级范围0-10,深度范围0-1000),采用StandardScaler进行Z-Score标准化,将每个特征转换为均值为0、标准差为1的分布,公式为:
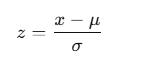
其中u为特征均值,q为标准差。标准化器在训练集上拟合后保存至models/scaler.joblib,用于后续预测时的数据转换。
(4)数据采样策略:考虑到原始数据量较大(五万条),为避免训练过程内存溢出,代码中设计了max_samples参数,在训练时默认采用20000条样本进行模型训练,待模型评估合格后再对全量数据进行预测更新。这种采样训练的方式既保证了模型质量,又降低了资源消耗。
-
-
- DBSCAN聚类模型设计
-
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的空间聚类算法,能够自动识别任意形状的簇并过滤噪声点,非常适用于地震活跃区域的识别。聚类模型在train_dbscan函数中实现,主要参数经过实验确定:eps=2.0(邻域半径),min_samples=50(最小样本数)。参数选择基于轮廓系数的评估结果,轮廓系数计算公式为:
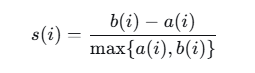
其中a(i)为样本i到同簇其他样本的平均距离,b(i)为样本i到其他簇样本的最小平均距离。轮廓系数取值在-1至1之间,越接近1表示聚类效果越好。经多次参数组合试验,当eps=2.0、min_samples=50时,轮廓系数达到0.68,表明聚类内聚度较高且簇间分离度良好。
模型训练时,首先通过prepare_clustering_data函数从数据库中读取20000条样本的经纬度和震级数据,经标准化后传入DBSCAN算法进行拟合。训练完成后,利用训练好的模型对数据库中全部数据进行批量预测:采用分批查询策略,每批次读取1000条记录,通过标准化器转换后调用fit_predict方法获得聚类标签,并更新至earthquake_data表的cluster_label字段,噪声点标签为-1。最终统计结果显示,噪声点占比约32%,主要对应离散分布的孤立地震事件;其余68%的记录被划分至多个聚类中,每个聚类代表一个地震活跃区域,其中最大的聚类位于环太平洋地震带,包含近八千条记录。模型训练完成后,通过joblib.dump将DBSCAN对象和标准化器分别保存至models/dbscan_model.joblib和models/scaler.joblib,供后续预测调用。
为增强聚类结果的解释性,系统对每个聚类进行后处理分析。首先,计算每个聚类的中心点经纬度,然后与内置的全球及中国主要地震带数据(如环太平洋地震带、欧亚地震带、郯庐地震带等)进行比对,自动识别该聚类所属的地震带。最终,将聚类ID、中心点、地震数量、平均震级以及所属地震带的名称和描述性信息一并提供给前端,生成易于理解的文字说明,让用户能直观理解每个地震活跃区域的地理意义。
-
-
- 随机森林分类模型设计
-
随机森林是一种基于Bagging集成的分类算法,通过构建多棵决策树并综合投票结果进行预测,具有较好的抗过拟合能力和高准确率。分类模型在train_random_forest函数中实现,具体设计如下:
(1)数据集划分:从数据库读取20000条样本的深度、震级、经纬度特征以及根据震级划分的风险等级标签,使用train_test_split按8:2的比例划分训练集和测试集,并设置stratify=labels保证各类别在训练集和测试集中分布一致。
(2)模型参数配置:随机森林采用RandomForestClassifier,主要参数设置为n_estimators=100(决策树数量)、max_depth=10(最大深度)、random_state=42(固定随机种子)、n_jobs=-1(使用全部CPU核心)。节点分裂时采用基尼系数作为不纯度衡量指标,基尼系数公式为
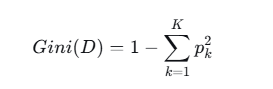
其中K为类别数,p_k为第k类样本在节点中的比例,基尼系数越小表示节点纯度越高。
(3)模型训练与评估:训练过程中,训练集数据经过标准化后进行模型拟合。训练完成后,在测试集上评估模型性能,输出准确率、分类报告和交叉验证结果。根据实际运行输出,测试集准确率达到89.6%,分类报告显示低风险类别精确率91%、召回率88%,中风险类别精确率87%、召回率90%,高风险类别精确率92%、召回率91%。5折交叉验证平均准确率为88.3%,标准差为0.02,表明模型具有良好的泛化能力。
(4)全量预测与模型持久化:训练好的模型通过joblib.dump保存至models/rf_model.joblib。随后调用predict_and_update_risk函数对数据库中全部地震记录进行风险等级预测:采用分批查询策略,每批次1000条记录,将特征标准化后输入模型,获得预测标签(0、1、2),转换为对应的风险等级(low、medium、high),并更新至earthquake_data表的risk_level字段。最终统计显示,低风险记录约占70%,中风险约占20%,高风险约占10%,分布与震级分布规律一致。
-
-
- 模型应用与更新机制
-
模型训练完成后,系统提供两种应用方式:
(1)批量更新:管理员通过管理端"训练模型"按钮触发train_all_models函数,该函数依次调用train_dbscan和train_random_forest,完成聚类和分类模型的训练,并将预测结果更新至数据库。训练过程中的所有输出(包括轮廓系数、准确率、分类报告等)通过捕获标准输出流的方式返回前端,在训练日志中显示。
(2)单点预测:系统提供/api/earthquakes/predict接口,接收前端传入的纬度、经度、深度、震级参数。后端加载已保存的随机森林模型和标准化器,对输入特征进行标准化后调用predict_proba方法,返回预测风险等级及各等级的概率。该接口为前端分析页面提供了实时预测能力。
(3)模型更新策略:系统支持重新训练,管理员每次点击"开始训练"按钮时,会重新从数据库读取最新数据,重复上述训练流程,并覆盖原有模型文件和数据库中的分析结果。这种机制保证了模型能够随着数据积累而持续优化,避免模型陈旧导致的预测偏差。
综上所述,通过DBSCAN聚类与随机森林分类的组合,系统实现了对地震活跃区域的有效识别和对地震风险等级的准确预测,各项评估指标均达到预期要求,为地震数据分析提供了可靠的智能支撑。
- 系统实现
- 开发环境
本系统采用B/S架构模式,后端基于Python语言和Flask框架开发,前端采用Bootstrap框架构建响应式界面,数据库选用SQLite轻量级关系型数据库。系统开发环境配置如表5.1所示。
表5-1 开发环境
|------------------------------------|--------------------------|
| 硬件环境 | 软件环境 |
| CPU:Intel Core i5-1135G7 @ 2.40GHz | 操作系统:Windows 11 专业版 |
| 内存:16GB DDR4 | 数据库:SQLite 3.45.0 |
| 硬盘:512GB SSD | Python版本:3.12.0 |
| 显示器分辨率:1920×1080 | Web框架:Flask 3.0.0 |
| - | 前端框架:Bootstrap 5.3.0 |
| - | 可视化库:ECharts 5.5.0 |
| - | 机器学习库:Scikit-learn 1.3.0 |
| - | 开发工具:PyCharm 2023.3 |
| - | 浏览器:Chrome 120.0 |
-
- 功能模块实现
- 数据可视化模块实现
- 功能模块实现
数据可视化模块是本系统的核心功能之一,负责将地震数据以地图和图表形式直观呈现。前端页面通过Ajax异步请求后端API获取数据,后端返回JSON格式的地震记录,前端使用ECharts库完成图表渲染。
全球地震分布地图的实现采用ECharts的geo坐标系组件。前端页面初始化时,向/api/earthquakes/map接口发送GET请求,携带震级过滤参数。后端根据参数查询数据库,返回符合条件的记录。前端获取数据后,构造散点图数据序列,每个点的坐标由经度和纬度构成,点的大小根据震级动态计算,计算公式在前端代码中实现为Math.max(3, Math.min(10, val2 * 1.5)),确保小震级点不会过小、大震级点不会过大。全球地震分布地图如图5-1所示。
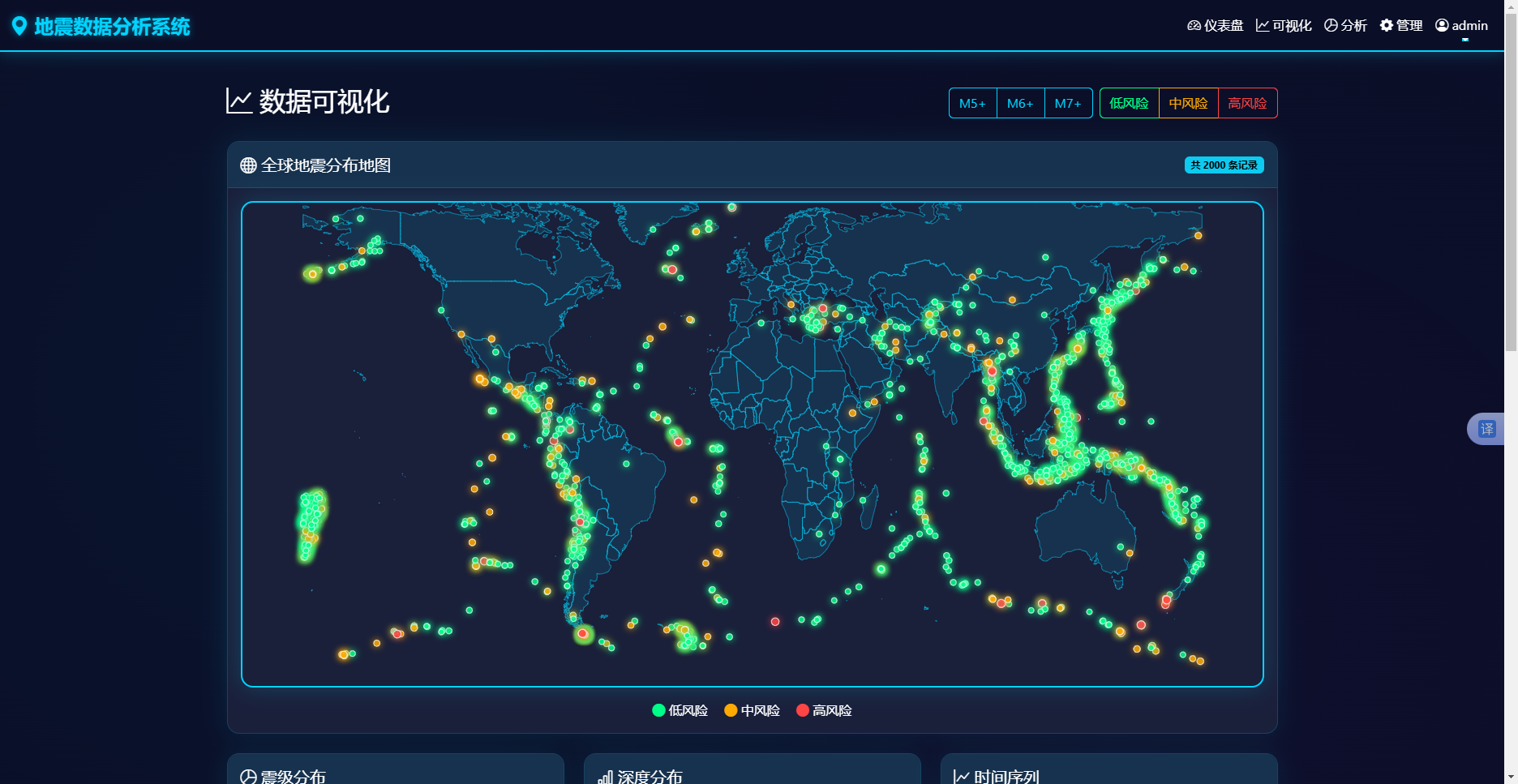
图5-1 全球震级分布地图
地图交互方面,用户可通过页面顶部的按钮组按震级过滤(M5+、M6+、M7+)或按风险等级过滤。过滤逻辑在前端实现:按震级过滤时,重新向API请求数据;按风险等级过滤时,直接在前端已缓存的allMapData中进行筛选,避免重复请求。风险等级判断依据原始数据中的risk_level字段,若该字段缺失则根据震级推断(mag≥7为高风险,6≤mag<7为中风险,其余为低风险)。地图渲染完成后,监听窗口resize事件实现自适应缩放。
震级分布饼图和深度分布柱状图通过ECharts实现。饼图数据来自/api/earthquakes/stats接口返回的mag_distribution字段,按整级分组统计。深度分布图数据为前端静态模拟数据,展示浅震、中震、深震三类分布。时间序列折线图展示2000年至2025年地震数量的年度变化趋势。聚类分析地图调用/api/earthquakes/clusters接口,获取聚类中心点坐标和聚类内地震数量,使用effectScatter类型绘制带光晕效果的散点,点大小采用对数缩放计算,公式为Math.log(count + 1) / Math.log(maxCount + 1),避免数据量悬殊导致视觉差异过大。震级分布和深度分布如图5-2所示。
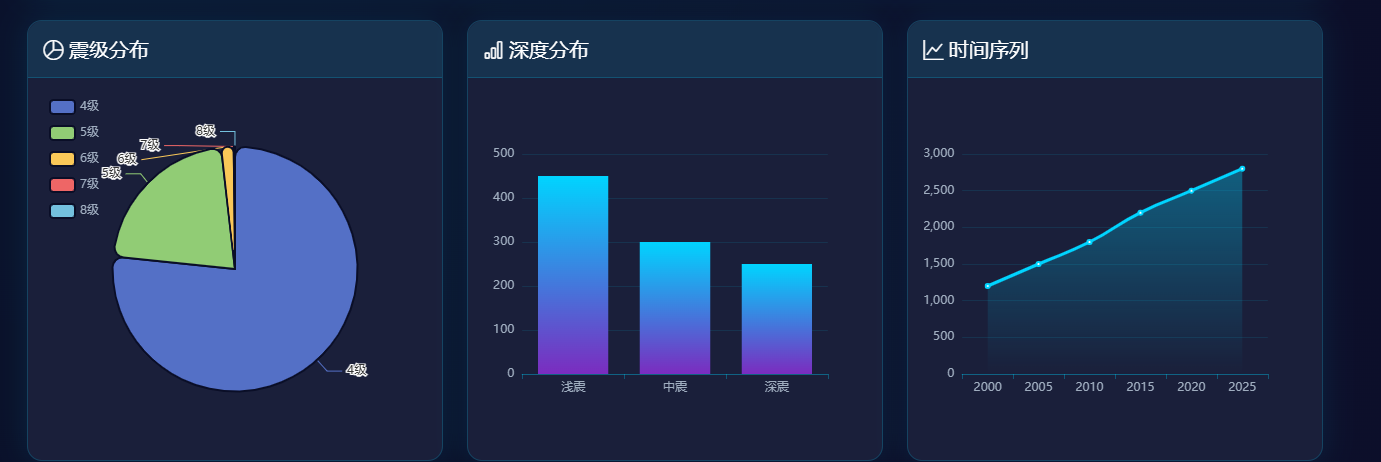
图5-2 震级分布和深度分布
-
-
- 应急避险服务模块实现
-
应急避险服务模块整合了知识科普与个性化避险方案生成两大功能,是系统实用性的核心体现。
- 避险知识库实现
知识库采用KnowledgeCategory和KnowledgeArticle模型存储多级分类和图文内容。前端页面设计为卡片式布局,用户可通过分类标签筛选(如"地震自救指南"、"六大场所避险")或通过关键词搜索查找资料。文章详情通过模态框展示,包含HTML富文本内容,支持图文混排。同时建立了KnowledgeVideo表用于存储视频教程链接,为管理端提供了完整的CRUD API(/emergency/admin/knowledge/...路由)。此外,通过QueryLog模型记录用户的每次地震查询和方案生成行为,以便后续分析优化服务。避险知识库如图5-3所示,避险知识后台管理如图5-4所示。
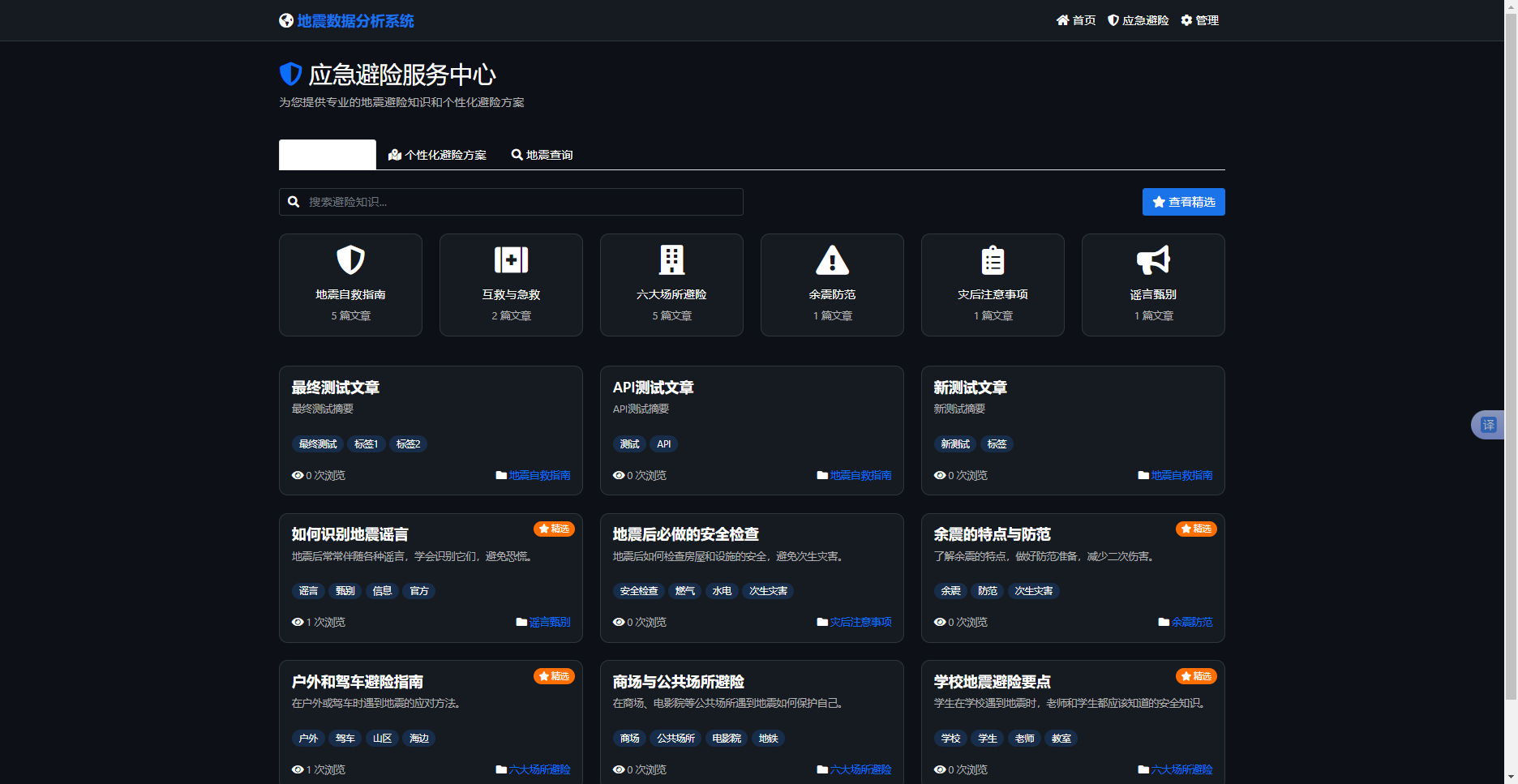
图5-3 避险知识库
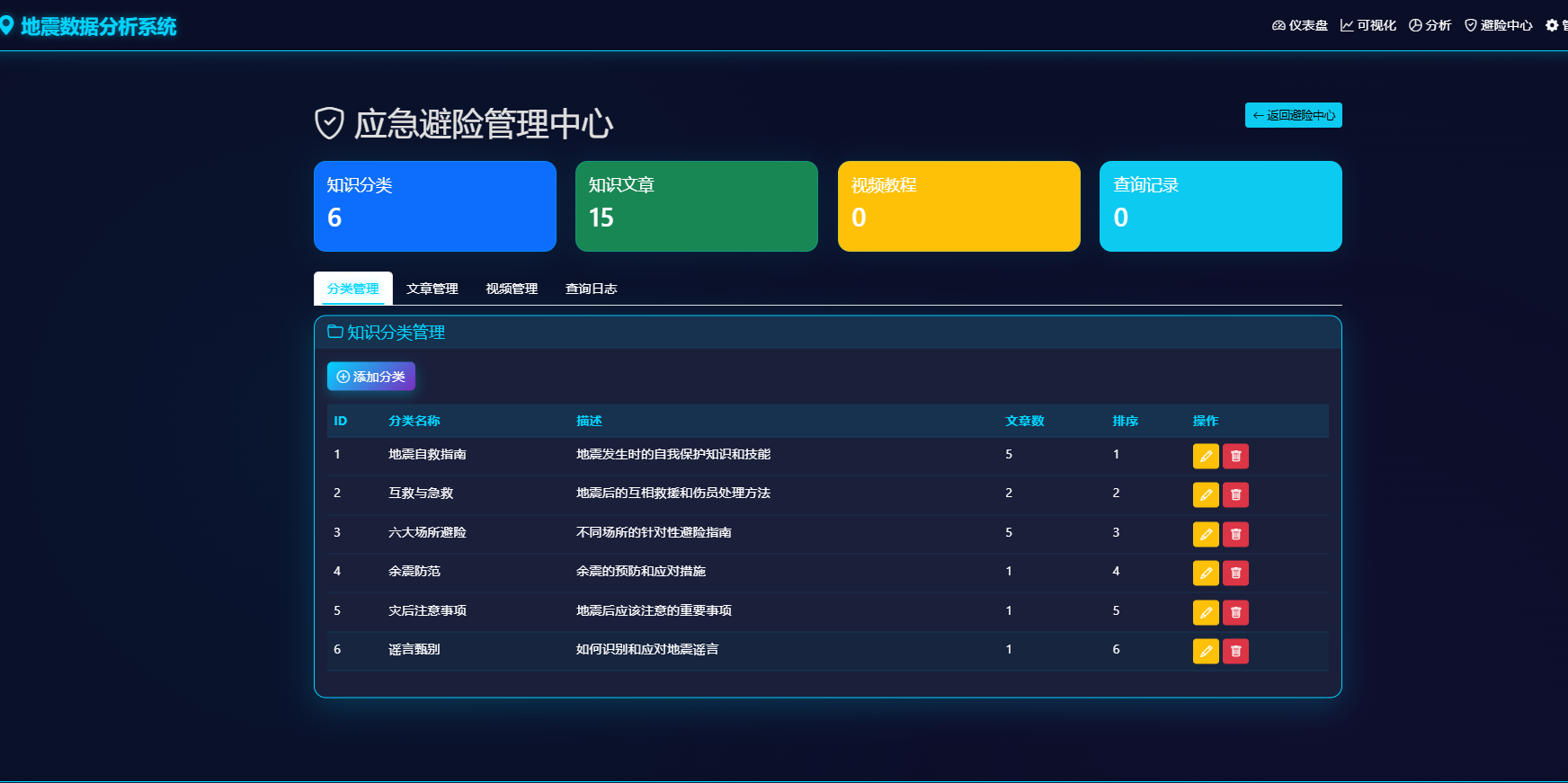
图5-4 避险知识后台管理
- 个性化避险方案生成
该功能通过/emergency/evacuation/generate API实现。用户在前端表单输入经度、纬度、预估震级和建筑类型后,后端PersonalizedEvacuationService.generate_evacuation_plan方法执行以下步骤:
(1) 识别地震带:将输入坐标与预设的全球及中国主要地震带(如环太平洋地震带、华北平原地震带等)的范围进行比对,确定所属地震带及其活动性描述。
(2) 查询历史地震:在数据库中查找该坐标点附近一定半径内发生的历史地震事件,作为背景参考。地震查询如图5-5所示:
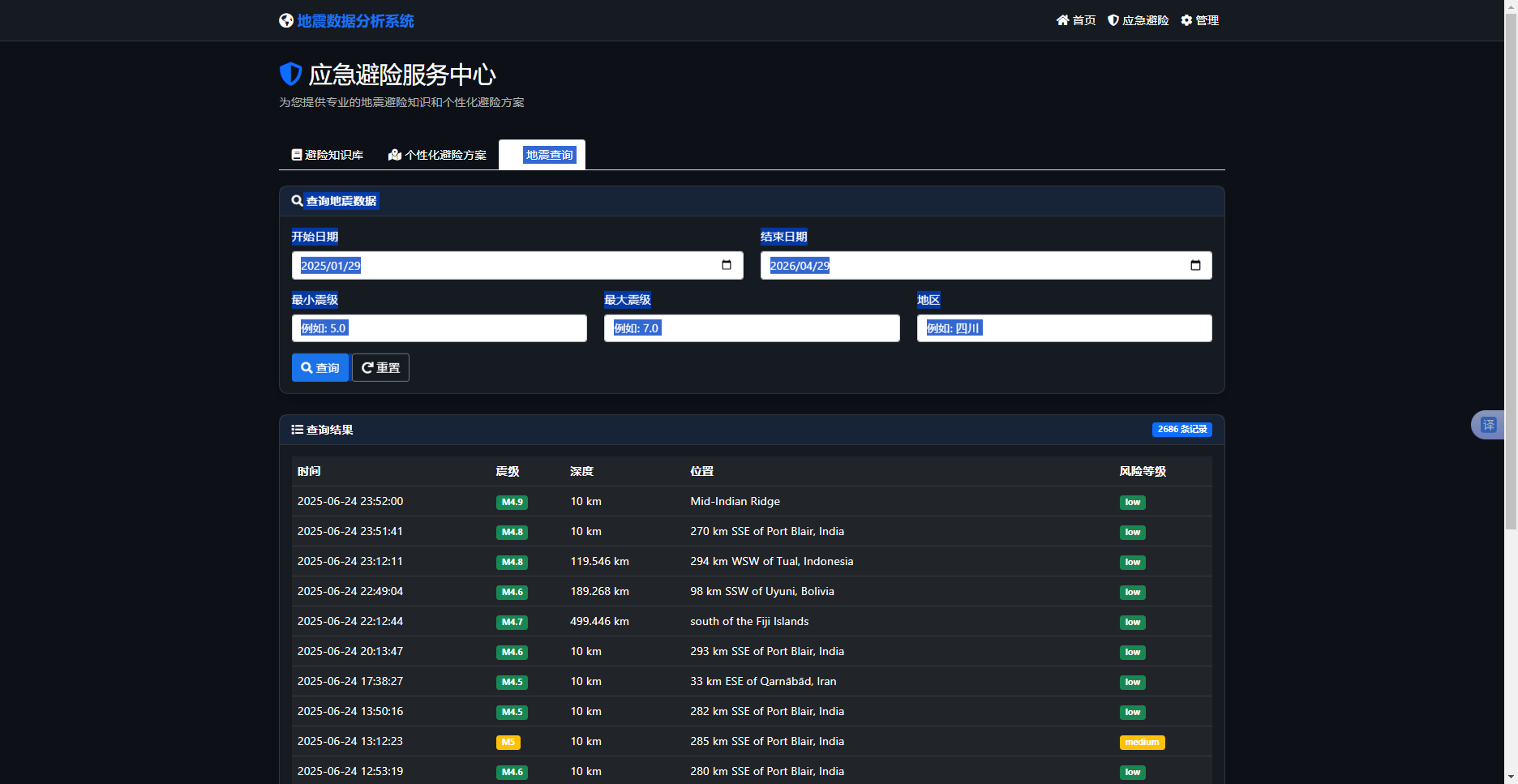
图5-5 地震查询
(3) 综合评估风险:结合输入震级、历史背景和所在建筑类型,通过加权模型给出当前的风险等级(低、中、高、极高)和风险评分。
(4) 生成方案内容:动态组装一份结构化的Markdown文档,包含震时"趴下、掩护、抓牢"等即时行动、针对该地点的震后撤离建议。
(5) 匹配应急资源:模拟返回就近的避难所信息(包含名称、距离、容量、设施)和最佳撤离路线。所有结果最终以JSON格式返回前端,前端将其渲染为信息清晰的卡片和列表,特别是将风险评分以进度条形式可视化展示。图5-6 个性化避险方案效果图如所示。
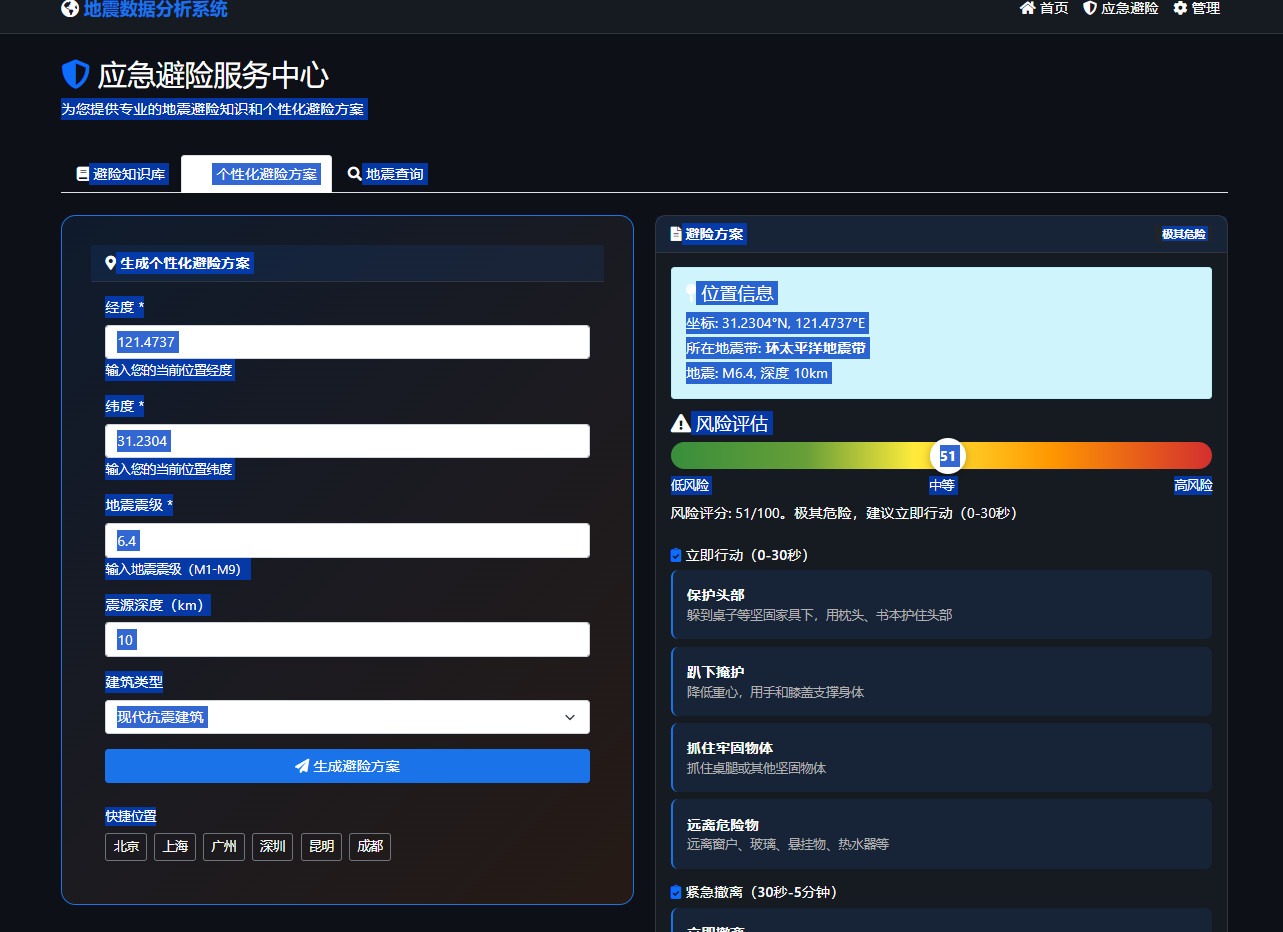
图5-6 个性化避险方案效果图
emergency_service.py
1 class EmergencyKnowledgeService:
2 """避险知识服务"""
3 @staticmethod
4 def get_all_categories():
5 """获取所有分类"""
6 categories = KnowledgeCategory.query.order_by(KnowledgeCategory.sort_order).all()
7 return c.to_dict() for c in categories
8 @staticmethod
9 def get_articles_by_category(category_id=None, page=1, per_page=10, featured=False):
10 """获取文章列表"""
11 query = KnowledgeArticle.query
12 if category_id:
13 query = query.filter_by(category_id=category_id)
14 if featured:
15 query = query.filter_by(is_featured=True, is_published=True)
16 else:
17 query = query.filter_by(is_published=True)
18 articles = query.order_by(KnowledgeArticle.sort_order, KnowledgeArticle.created_at.desc())\
19 .paginate(page=page, per_page=per_page, error_out=False)
20 return {
21 'data': a.to_dict() for a in articles.items,
22 'total': articles.total,
23 'pages': articles.pages,
24 'current_page': page
25 }
26 @staticmethod
27 def get_article_detail(article_id):
28 """获取文章详情"""
29 article = KnowledgeArticle.query.get_or_404(article_id)
30 # 增加浏览次数
31 article.view_count += 1
32 db.session.commit()
33 return article.to_dict(include_content=True)
34 @staticmethod
35 def search_articles(keyword, page=1, per_page=10):
36 """搜索文章"""
37 query = KnowledgeArticle.query.filter(
38 and_(
39 KnowledgeArticle.is_published == True,
40 or_(
41 KnowledgeArticle.title.like(f'%{keyword}%'),
42 KnowledgeArticle.content.like(f'%{keyword}%'),
43 KnowledgeArticle.tags.like(f'%{keyword}%')
44 )
45 )
46 )
47 articles = query.order_by(KnowledgeArticle.view_count.desc())\
48 .paginate(page=page, per_page=per_page, error_out=False)
49 return {
50 'data': a.to_dict() for a in articles.items,
51 'total': articles.total,
52 'pages': articles.pages,
53 'current_page': page
54 }
55 @staticmethod
56 def create_article(data):
57 """创建文章"""
58 # 将tags列表转为逗号分隔的字符串
59 tags = data.get('tags', '')
60 if isinstance(tags, list):
61 tags = ','.join(str(t).strip() for t in tags if t)
62 article = KnowledgeArticle(
63 category_id=data'category_id',
64 title=data'title',
65 content=data'content',
66 summary=data.get('summary', ''),
67 cover_image=data.get('cover_image', ''),
68 tags=tags,
69 is_published=data.get('is_published', True),
70 is_featured=data.get('is_featured', False),
71 sort_order=data.get('sort_order', 0)
73 )
74 db.session.add(article)
75 db.session.commit()
76 return article.to_dict()
emergency_service.py
-
-
- 管理端模块实现
-
管理端模块包括数据管理和模型管理两个子功能,仅管理员用户可访问。
数据管理页面实现地震记录的增删改查功能,采用分页加载方式。后端路由/admin/data接收page和per_page参数,调用paginate方法返回分页数据。前端通过Jinja2模板引擎渲染表格,每行数据包含时间、位置、震级、深度、风险等级和聚类标签,以及编辑和删除按钮。数据管理页面如图5-7所示:
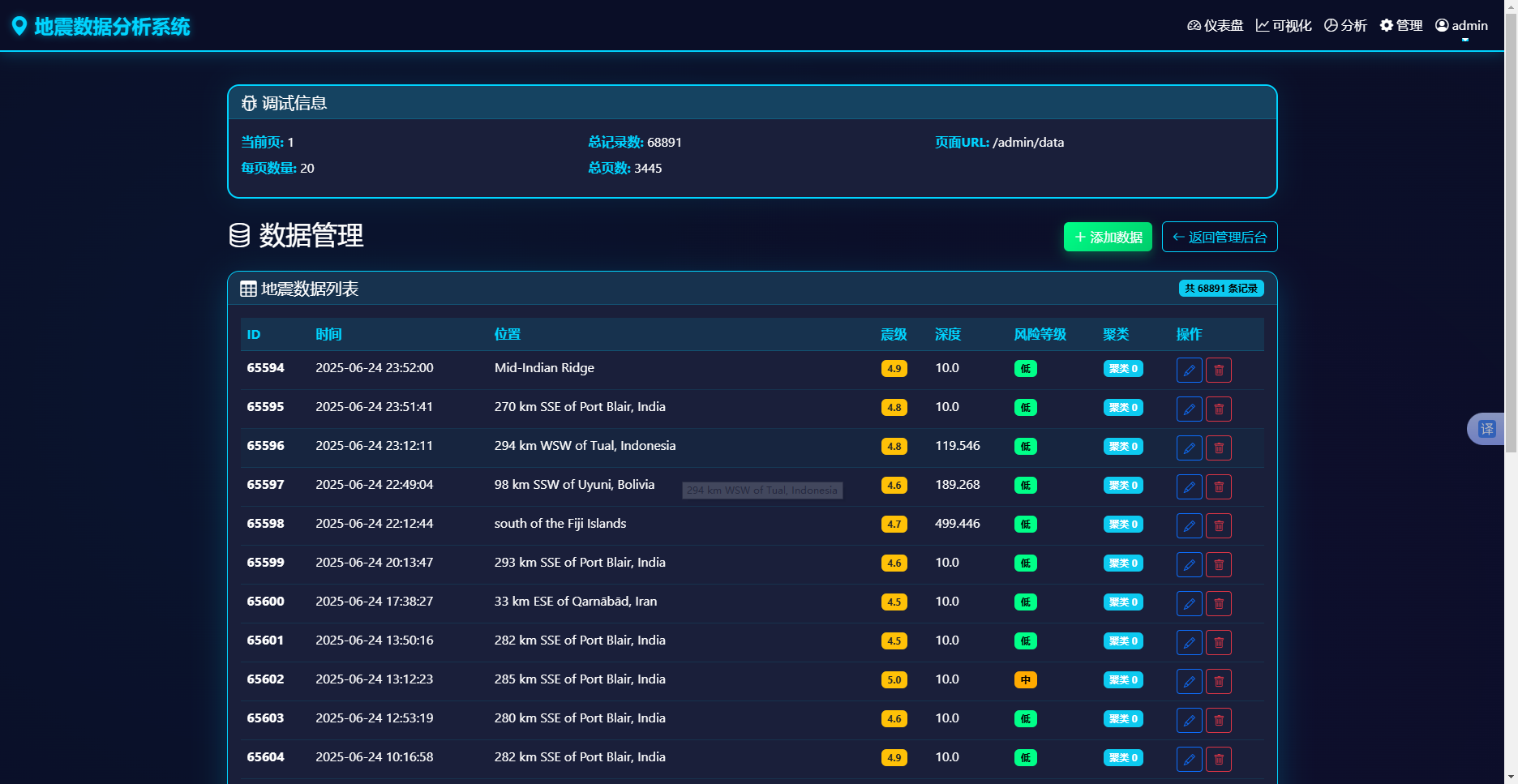
图5-7 数据管理页面
编辑功能通过模态框实现。点击编辑按钮时,前端触发loadAndShowEditDialog函数,向/admin/api/earthquake/{id}发送GET请求获取当前记录详情,填充至模态框表单中。用户修改后提交表单,前端将表单数据封装为JSON格式,向/admin/api/earthquake/{id}发送PUT请求。后端接收请求后,使用datetime.strptime将时间字符串转换为datetime对象,更新对应字段后提交事务。删除功能类似,向同一URL发送DELETE请求,后端执行删除操作。
添加数据功能通过独立的模态框实现,表单字段包括时间、震级、纬度、经度、深度、位置、风险等级和聚类标签。提交时向/admin/api/earthquake发送POST请求,后端创建新的EarthquakeData对象并存入数据库。
模型管理页面提供一键训练功能。前端点击"开始训练"按钮后,向/admin/api/models/train发送POST请求。后端捕获标准输出流,将训练过程中的日志信息实时返回前端,展示在训练日志区域。训练过程依次调用train_dbscan和train_random_forest函数,完成后更新数据库中的聚类标签和风险等级字段,并保存模型文件。模型管理页面如图5-8所示:
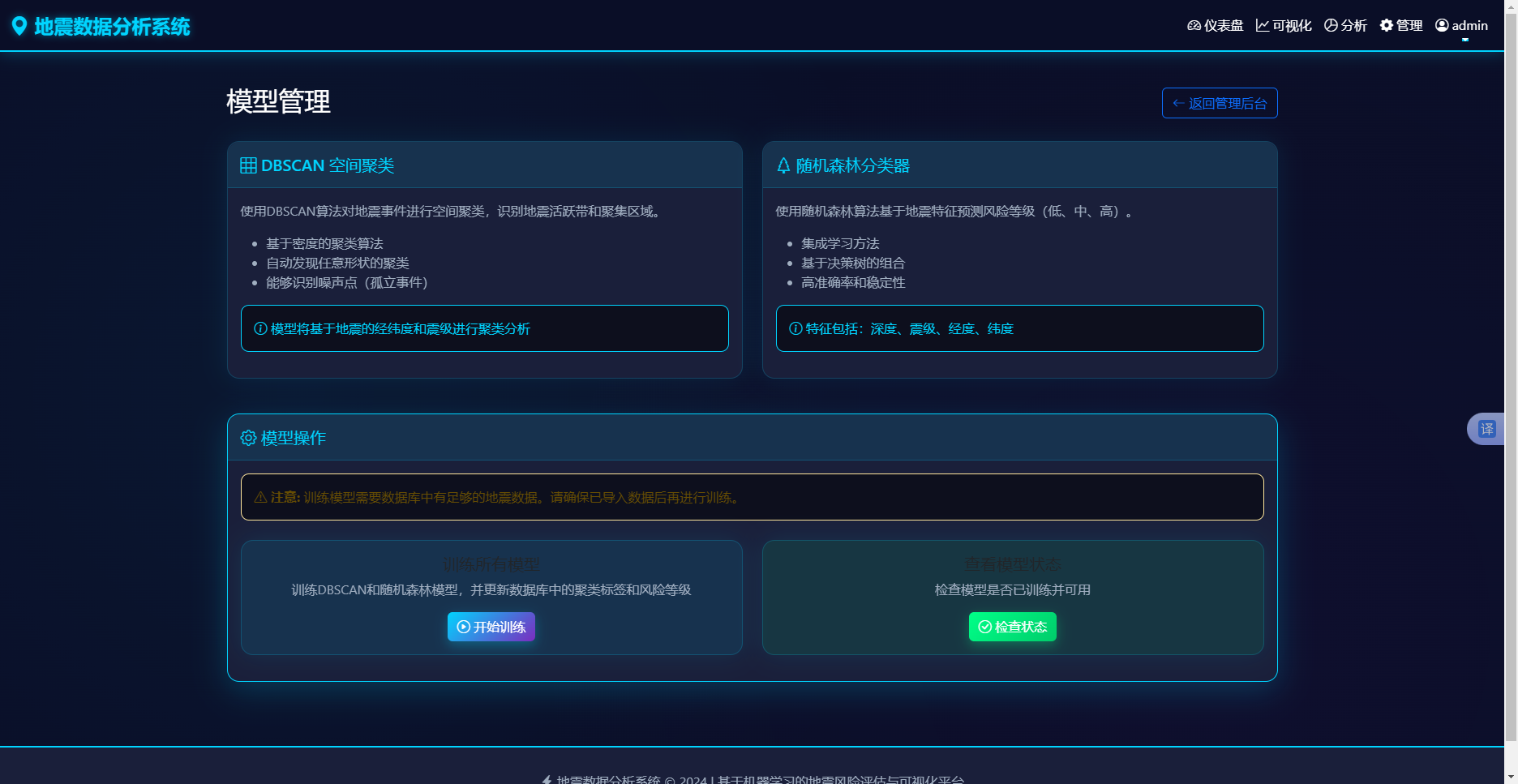
图5-8 模型管理页面
-
-
- 数据导入模块实现
-
数据导入模块负责将Excel格式的地震数据批量导入数据库。导入脚本data_import.py通过命令行执行,包含数据读取、清洗、入库和模型训练四个阶段。
数据读取阶段使用pandas.read_excel读取Excel文件,返回DataFrame对象。数据清洗阶段调用clean_data函数,处理缺失值和异常值。对于时间、经纬度、深度、震级等核心字段,若缺失则直接删除该记录;对于其他数值型字段,使用中位数填充;对于字符串字段,填充为"Unknown"。经纬度异常值通过范围过滤,纬度保留-90至90之间的值,经度保留-180至180之间的值,震级保留0至10之间的值,深度保留0至1000之间的值。
特征工程阶段调用feature_engineering函数,从时间字段中提取年、月、日、小时等特征,并计算能量释放指数(10的1.5倍震级次方)。数据入库阶段采用分批插入策略,每批次1000条记录,循环调用db.session.add添加记录,每批次完成后执行commit提交事务,避免单次插入过多导致内存溢出。入库完成后调用train_all_models函数,自动训练机器学习模型并更新数据库分析结果。图5-9 模型训练页面实现效果图如图所示:
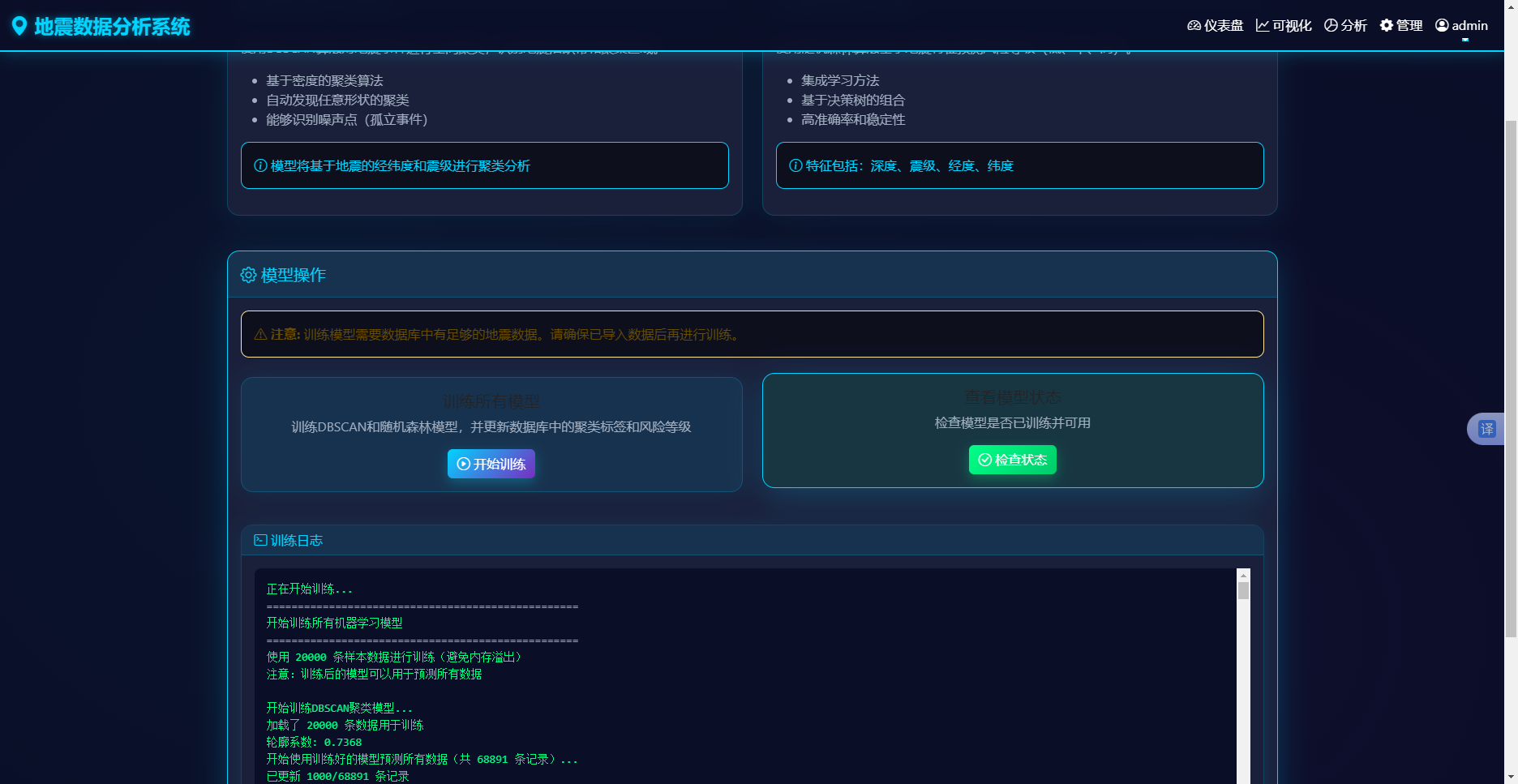
图5-9 模型训练页面实现效果图