上下文压缩是什么,为什么要做?
在 Claude Code 这类 Agent 里,它不是简单把历史消息砍短,也不是让模型选择性失忆,而是在上下文快装不下时,重新整理信息:哪些必须继续给模型看,哪些可以挪到磁盘,哪些可以总结成 summary,哪些运行状态需要压缩后再补回来。
为什么要这么麻烦?因为编码 Agent 的上下文增长太凶了。普通聊天可能是一句一句往上加,Claude Code 则经常是 Read 一个大文件、Bash 跑出几万行日志、Grep 搜出一堆匹配、多个工具还可能并发返回。工具结果刚出来时很重要,但过了几轮以后,它的价值往往下降。如果还把几千行旧文件内容、几万行旧日志一直塞在上下文里,就像开完会还背着投影仪继续赶地铁,精神可嘉,肩膀遭罪。
所以,上下文压缩的核心不是"忘掉过去",而是"带着必要信息继续干活"。Claude Code 的做法也不是等爆窗后原地抢救,而是分层处理:
text
大工具输出:先落盘,只留预览和路径
旧工具结果:能清就清,别长期占座
上下文压力:用阈值判断是否需要完整 compact
旧对话语义:必要时总结成可交接的 summary
运行现场:压缩后补回文件、计划、工具、hooks 等状态一句话概括:上下文压缩不是把聊天记录变短,而是把"模型继续工作真正需要的东西"重新打包。 如果压缩完模型还要问"所以我接下来做什么?",那就不是压缩,是交接事故。
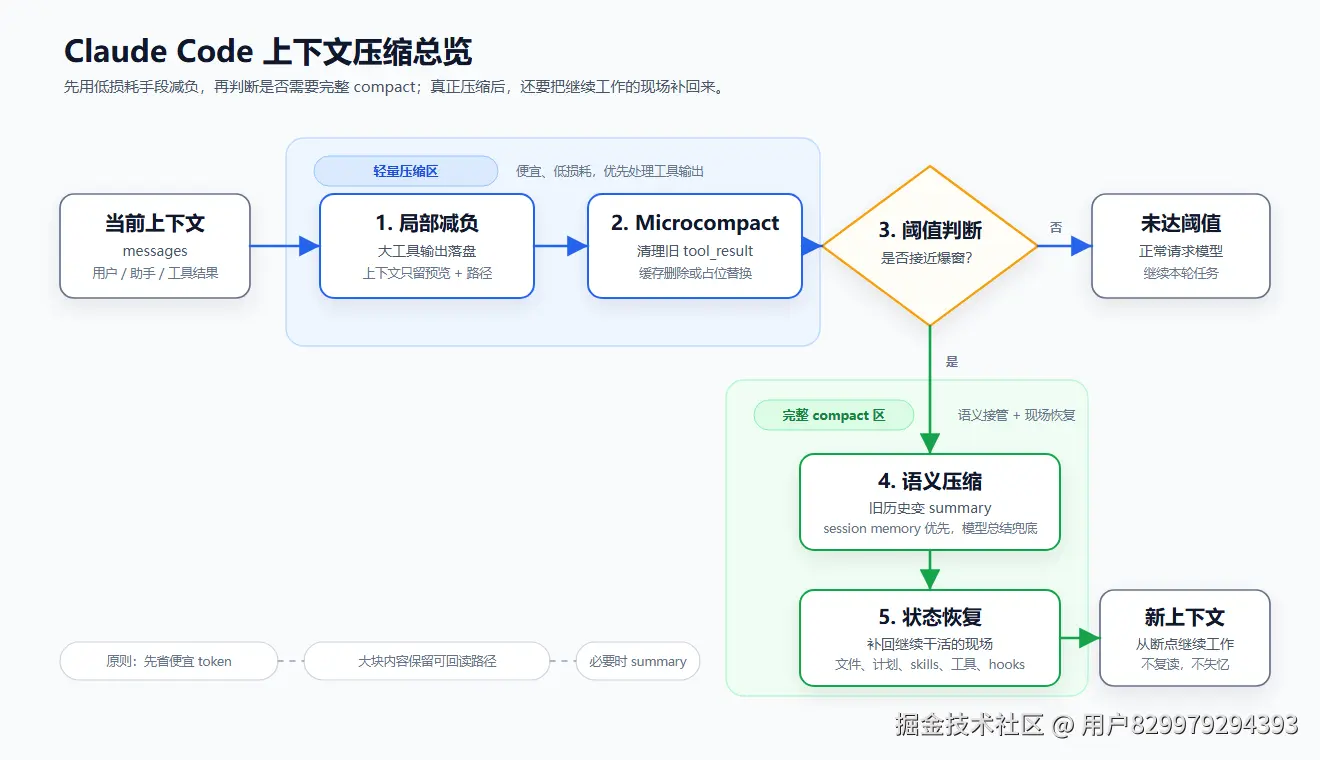
第一部分:局部减负
前面我们说过,Claude Code 的上下文压缩不是一上来就把整段历史总结成 summary。真正进入完整 compact 之前,它会先做一层更轻量的处理:局部减负。
局部减负要解决的问题很具体:
text
工具刚刚返回了一大段结果,
这段结果可能有用,
但不能不加控制地完整塞进模型上下文。这里的重点是"刚刚返回"。它和后面要讲的 Microcompact 不一样:
text
局部减负:处理新产生的大工具输出。
Microcompact:清理历史里已经变旧的 tool_result。所以局部减负不是总结对话,也不是删除历史语义。它只是改变"大工具输出"在上下文里的呈现方式:完整内容保留下来,但模型当前上下文里只放一个更轻的引用和预览。
为什么工具结果要单独处理?
在编码 Agent 里,上下文膨胀最快的往往不是用户消息,也不是 assistant 的普通回复,而是工具结果。
比如:
text
Read -> 返回文件内容
Bash -> 返回测试日志、构建日志、命令输出
Grep -> 返回大量匹配结果
Glob -> 返回大量文件路径
WebFetch -> 返回网页正文
Edit/Write -> 返回修改结果或校验信息这些内容有两个特点:
text
1. 体积大:很容易一次返回几万甚至几十万字符。
2. 时效强:刚返回时很重要,但不一定需要每一轮都完整携带。如果工具结果每次都原样进入上下文,会带来几个直接后果:
text
请求 token 增加
prompt cache 更容易被破坏
下一轮更接近上下文窗口上限
后续真正重要的近期消息被工具输出挤占空间因此 Claude Code 先做一件低成本的事:不急着压缩整段对话,先把工具结果这类高体积内容处理掉。
第一层:单个工具结果过大,先持久化到磁盘
源码里这一层主要在 src/utils/toolResultStorage.ts。
当某个工具返回结果后,Claude Code 会把它映射成 API 能识别的 tool_result block。随后会进入类似 maybePersistLargeToolResult 的处理逻辑,判断这个结果是否过大。
整体流程可以简化为:
text
工具执行完成
-> 生成 tool_result
-> 判断结果大小是否超过阈值
-> 如果超过阈值,把完整内容写入 tool-results 文件
-> 上下文里只放 persisted-output 预览消息也就是说,模型上下文里看到的不是完整大输出,而是类似这样的内容:
text
<persisted-output>
Output too large (...). Full output saved to: .../tool-results/toolu_xxx.txt
Preview (first 2KB):
这里是前面一小段输出内容
...
</persisted-output>这里有几个细节值得注意。
第一,完整内容没有丢。它被保存到了当前 session 目录下的 tool-results 子目录里,文件名通常和 tool_use_id 相关。
text
projectDir/sessionId/tool-results/{tool_use_id}.txt
projectDir/sessionId/tool-results/{tool_use_id}.json如果后续模型确实需要完整结果,它至少知道完整内容在哪里,可以通过路径重新读取。
第二,预览不是随便截一刀。源码里有 PREVIEW_SIZE_BYTES = 2000,并且生成预览时会尽量在换行处截断,避免把一行内容切到一半。
第三,输出外面包了一层 <persisted-output> 标签。这个标签的作用是让模型明确知道:
text
这是一个被持久化的大输出
当前只展示预览
完整内容在某个文件路径里这比直接写一句"输出太长省略了"更可靠。因为模型不仅知道内容被省略,还知道去哪里找。
第二层:不同工具有不同的结果上限
不是所有工具都用同一个策略。
源码里有一个全局默认上限:
ts
DEFAULT_MAX_RESULT_SIZE_CHARS = 50_000同时,不同工具会声明自己的 maxResultSizeChars。例如:
text
Bash: 30_000
Grep: 20_000
Glob: 100_000
WebFetch: 100_000
Edit: 100_000
Write: 100_000
Read: Infinity实际判断时,会把工具自己的上限和全局默认上限结合起来。通常可以理解为:
text
工具声明一个上限
系统再用全局默认上限做保护
最终得到这个工具的持久化阈值例如 Bash 很容易产生大量日志,所以它的上限比默认值更低:
text
Bash maxResultSizeChars = 30_000Grep 也类似,因为一次搜索可能返回大量匹配行:
text
Grep maxResultSizeChars = 20_000而 Read 比较特殊:
text
Read maxResultSizeChars = Infinity这表示它不会走普通的"输出过大就持久化成 tool-results 预览"逻辑。原因也很直接:Read 自身已经有读取范围控制,例如 offset、limit、maxTokens 等。把 Read 的结果再保存成一个文件,然后让模型再 Read 这个保存文件,会让链路变得绕,而且收益不明显。
所以这里不是"所有工具一刀切",而是按工具特性分开处理:
text
Bash / Grep:容易产生巨量文本,更积极限制。
WebFetch / Glob / Edit / Write:也可能很大,需要系统默认保护。
Read:读取阶段本身就受控,不走普通持久化回读。第三层:单个结果没超限,但一轮结果合起来可能超限
上面讲的是"单个工具结果过大"的情况。但真实 Agent 执行时,还有一个更隐蔽的问题:单个结果都不大,但一轮并发工具结果加起来很大。
例如一轮里并发跑了多个工具:
text
tool_result A: 40K
tool_result B: 40K
tool_result C: 40K
tool_result D: 40K
tool_result E: 40K
tool_result F: 40K每个结果单看都没超过 50K,但这一轮合起来就是:
text
40K × 6 = 240K这时如果全部塞进一个 user message,仍然会给上下文造成很大压力。
所以 Claude Code 还有一层"单轮聚合预算"。源码里对应的常量是:
ts
MAX_TOOL_RESULTS_PER_MESSAGE_CHARS = 200_000这个预算的单位是"一条 user message 里的所有 tool_result"。它不是统计整段历史,也不是统计整个会话,而是看这一轮工具返回结果的合计大小。
源码注释里也强调了这一点:
text
Messages are evaluated independently.也就是说:
text
第 1 轮有 150K tool_result:不处理
第 2 轮又有 150K tool_result:也不处理
同一轮里合计超过 200K:才触发这一层预算这样设计的原因是,问题主要出现在"同一轮并发工具结果过多"。如果每轮都只有一个中等大小结果,系统不一定要强行替换;但如果一轮里多个工具同时返回,就需要避免这一轮直接把上下文撑得过大。
第四层:超过单轮预算后,优先替换最大的 fresh 结果
当某条 user message 里的多个 tool_result 合计超过预算时,Claude Code 不会把所有结果都替换掉,而是会优先选择最大的、刚出现的结果。
可以简化理解为:
text
1. 收集当前 user message 里的 tool_result
2. 计算合计大小
3. 如果超过 200K,就从最大的 fresh tool_result 开始替换
4. 每替换一个,就把完整内容落盘,上下文里放预览
5. 直到这一组结果回到预算以内这里有两个关键词:最大 和 fresh。
"最大"很好理解。要降低上下文压力,优先处理体积最大的结果收益最高。
"fresh"更关键。它表示这个工具结果以前没有被预算机制处理过。如果某个结果之前已经被系统决定"保留原文"或"替换成预览",后续就不会随便改变决定。
这就引出下一点:稳定性。
第五层:替换决策必须稳定,不能每轮变化
Claude Code 对上下文稳定性非常敏感。原因是 prompt cache。
如果同一个 tool_result 第一轮是完整内容,第二轮突然变成预览,第三轮又因为某些条件变化变回完整内容,那么模型看到的历史前缀就会不断变化。这样会影响 prompt cache,也会让上下文表现变得不稳定。
所以源码里维护了一个 ContentReplacementState:
ts
type ContentReplacementState = {
seenIds: Set<string>
replacements: Map<string, string>
}它的含义可以这样理解:
text
seenIds:
这个 tool_result 是否已经被预算机制看过。
replacements:
如果它被替换过,这里保存模型当时看到的那份预览文本。一旦某个工具结果被处理过,它的命运就固定了:
text
之前保留原文的:后面继续保留原文。
之前替换成预览的:后面继续用完全相同的预览文本。注意,是完全相同。
不是重新生成一份看起来差不多的预览,而是直接从 replacements 里取出之前保存的字符串,原样应用。这样可以保证后续请求里的 prompt 前缀保持稳定。
源码里还会把新的替换记录写入 transcript,方便 resume 后重建相同的替换状态。否则用户恢复会话后,同一个工具结果可能因为代码版本、路径格式、预览模板变化而生成不同文本,导致上下文前缀发生变化。
这一点是这套机制能长期稳定运行的关键:
text
局部减负不只是减少 token。
它还要保证减少 token 的方式是可重复、可恢复、可缓存的。小结
局部减负是 Claude Code 上下文压缩链路里的第一道轻量处理。
它的核心逻辑可以概括为:
text
单个工具结果过大:
完整内容保存到 tool-results
上下文里只保留 persisted-output 预览和路径
一轮工具结果合计过大:
按 user message 聚合 tool_result
超过预算后优先替换最大的 fresh 结果
替换决策:
用 seenIds 和 replacements 固定下来
保证后续请求和 resume 后都能稳定复现所以,局部减负不是"压缩整段上下文",而是先处理最容易膨胀的工具输出。它用很低的语义损耗换来明显的 token 减压,并且为后面的 Microcompact 和 Auto Compact 判断争取空间。
第二部分:Microcompact
讲完"局部减负"以后,我们再看 Claude Code 上下文压缩链路里的第二层:Microcompact。
局部减负处理的是"工具结果刚产生时太大怎么办"。Microcompact 处理的是另一个问题:
text
工具结果已经进入历史上下文了,
后面又经过了很多轮对话,
这些旧 tool_result 是否还需要继续完整保留?所以 Microcompact 的核心不是总结对话,而是清理旧工具结果。它不负责理解用户需求,也不负责把历史对话改写成 summary。它只针对一类内容:历史里的可清理工具结果。
可以先用一句话理解:
text
Microcompact = 在不重写对话语义的前提下,减少旧 tool_result 占用的上下文空间。它和局部减负有什么区别?
这两个机制都和 tool_result 有关,所以容易混在一起。但它们处理的时间点不一样。
text
局部减负:
工具结果刚返回时,如果单个结果过大,或同一轮结果合计过大,
就把完整结果落盘,只在上下文里放预览和路径。
Microcompact:
工具结果已经进入历史,后续上下文继续增长,
系统再判断哪些旧 tool_result 可以从当前上下文里清理。换成执行顺序看,大致是:
text
工具刚返回
-> 局部减负先判断它是否太大
-> 结果进入历史上下文
-> 后续多轮请求继续携带这些历史
-> Microcompact 再清理较旧的工具结果也就是说,局部减负是"入口处理",Microcompact 是"历史维护"。
为什么 Microcompact 主要盯着 tool_result?
因为在 Claude Code 这类编码 Agent 里,tool_result 通常同时满足两个条件:
text
1. 体积大
2. 信息价值会随时间下降比如模型读过一个文件:
text
assistant: 调用 Read
tool_result(Read): 返回 src/main.ts 的完整内容
assistant: 根据文件内容定位问题
assistant: 修改代码
assistant: 跑测试
assistant: 总结修复结果刚读完文件时,完整 tool_result 很重要。但经过几轮分析和修改后,模型可能已经把关键结论写进了后续回复,或者已经通过编辑结果体现了这些信息。此时旧的完整文件内容继续留在上下文里,价值就不一定匹配它占用的 token。
但用户消息和 assistant 消息不一样。
用户消息可能包含真实需求、约束、纠正意见。assistant 消息可能包含已经形成的任务判断、计划和下一步意图。如果 Microcompact 随便清这些内容,就会直接影响对话语义。
所以它只选择相对可控的一类目标:
text
旧 tool_result这也是为什么它叫 Microcompact,而不是 full compact。它只做局部清理,不做语义总结。
哪些工具结果可以被 Microcompact 处理?
源码里有一个集合叫 COMPACTABLE_TOOLS,用来限定 Microcompact 可以处理哪些工具的结果。
它主要包括:
text
Read
Shell / Bash 类工具
Grep
Glob
WebSearch
WebFetch
Edit
Write源码逻辑不是直接扫描所有 tool_result,而是先从 assistant 消息里收集可压缩工具的 tool_use id:
text
assistant message
-> 找 tool_use
-> 如果 tool name 在 COMPACTABLE_TOOLS 中
-> 记录这个 tool_use.id随后再去 user 消息里找对应的 tool_result:
text
user message
-> 找 tool_result
-> 如果 tool_result.tool_use_id 在可压缩 id 集合里
-> 这个结果才有资格被 Microcompact 处理这点很重要。Microcompact 不是只看 tool_result 本身,它会通过 tool_use_id 把工具调用和工具结果对应起来。这样系统就知道:
text
这个结果来自哪个工具
这个工具是否属于允许清理的类型Microcompact 有两条主要路径
Microcompact 的两条路径,核心区别在于:当前还要不要尽量保护 prompt cache。
如果 prompt cache 仍然可用,直接修改本地历史消息会破坏缓存前缀。更稳的做法是:本地 messages 不动,只在请求层告诉服务端,哪些旧工具结果对应的缓存内容可以删除。这就是 Cached Microcompact 的思路。
如果会话已经空闲较久,服务端缓存大概率已经失效,那么继续保护缓存前缀的意义就变小了。这时可以更直接地修改本地上下文,把更早的旧 tool_result 正文替换成占位符。这就是 Time-based Microcompact 的思路。
可以这样对比:
text
Cached Microcompact:
本地 messages 不变
通过 cache_edits 删除服务端缓存里的旧 tool_result
重点是尽量不破坏已有缓存前缀
Time-based Microcompact:
直接修改本地 messages
把旧 tool_result 正文替换成固定占位符
重点是减少下一次请求实际发送的内容这两个路径都不是语义压缩。它们不会生成 summary,也不会重新整理用户需求。
第一条路径:Cached Microcompact
Cached Microcompact 的处理对象不是本地消息正文,而是服务端缓存中的旧工具结果。
它的大致过程是:
text
1. 记录历史里有哪些可压缩 tool_result
2. 判断哪些旧工具结果可以删除缓存
3. 生成 cache_edits 删除指令
4. 在下一次 API 请求里带上这些删除指令这样做的结果是:
text
本地对话历史仍然完整
模型请求里的消息结构不被重写
服务端可以释放部分旧工具结果的缓存内容这里有一个细节:cache_edits 本身也要放在稳定的位置。
如果这次把删除指令放在某个 user message 后面,下次又换到另一个位置,那么请求前缀仍然会变化。为了避免这种情况,系统会把这些删除指令固定在原来的插入位置,后续请求继续按相同位置发送。
所以 Cached Microcompact 的关键点是:
text
不改本地 messages
删除动作通过 cache_edits 表达
cache_edits 的位置也要稳定不过要注意:在 pengchengneo/Claude-Code 这份源码里,Cached Microcompact 属于 feature-gated 的内部路径,相关模块没有完整展开。这里重点看它的机制设计,不把它当成所有构建默认启用的能力。
第二条路径:Time-based Microcompact
Time-based Microcompact 的判断依据是会话空闲时间。
如果距离上一次主循环 assistant 消息已经超过阈值,例如 60 分钟,那么服务端 prompt cache 大概率已经过期。下一次请求本来就需要重新建立缓存前缀,这时继续保留大量旧工具结果的收益就不高。
这条路径会直接处理本地消息:
text
1. 收集所有可压缩工具的 tool_use_id
2. 保留较新的工具结果
3. 把更早的旧 tool_result 正文替换成占位符占位符是固定字符串:
text
[Old tool result content cleared]替换前后可以理解为:
text
替换前:
tool_result(Read):
很长的文件内容......
替换后:
tool_result(Read):
[Old tool result content cleared]注意,这里仍然保留了 tool_result 这个 block 本身,也保留了它的 tool_use_id。被替换的是内容正文。
这样做是为了保留工具调用结构的合法性。Claude 的工具调用通常是:
text
assistant: tool_use(id = xxx)
user: tool_result(tool_use_id = xxx)如果直接删除整个 tool_result,就可能破坏 tool_use / tool_result 的对应关系。Time-based Microcompact 选择替换正文,而不是删除消息,就是为了在减少 token 的同时保留结构完整性。
小结
Microcompact 是 Claude Code 上下文管理里的轻量清理机制。
它的核心逻辑可以概括为:
text
处理对象:
历史里的可压缩 tool_result
不处理:
用户消息
assistant 普通回复
对话语义 summary
两条路径:
Cached Microcompact:通过 cache_edits 清理服务端缓存,不改本地 messages
Time-based Microcompact:缓存大概率失效后,直接把旧 tool_result 正文替换成占位符
核心价值:
清理旧工具结果占用
保持消息结构合法
尽量避免直接重写对话语义所以,Microcompact 不是"把对话压缩成摘要"。它更准确的定位是:在完整语义压缩之前,先清理历史里低时效、高体积的工具结果。
第三部分:阈值判断
前面两层已经做了轻量减负:
text
局部减负:处理刚产生的大工具输出。
Microcompact:清理历史里的旧 tool_result。但清理完以后,还要判断一个问题:
text
当前上下文是否已经接近模型窗口上限?
如果继续正常请求,会不会没有足够空间完成下一轮?这就是阈值判断的作用。
它本身不压缩内容,只负责决定是否触发完整 Auto Compact。
核心判断公式
Claude Code 不会等上下文窗口真正用满才 compact,因为 compact 本身也需要输出空间。完整 compact 要让模型生成 summary,如果窗口已经被输入占满,summary 就没有足够空间输出。
所以它会先预留一段 summary 输出空间:
ts
MAX_OUTPUT_TOKENS_FOR_SUMMARY = 20_000然后得到一个有效窗口:
text
effectiveWindow = contextWindow - reservedSummaryOutputTokens接着还要再扣一段安全 buffer:
ts
AUTOCOMPACT_BUFFER_TOKENS = 13_000这个 buffer 和前面的 summary 输出预留不是一回事。
summary 输出预留,是给 compact 之后模型生成摘要用的;这里的 13k buffer,是给"当前请求继续膨胀"留的余量。因为在真正发起下一次模型请求前,上下文里可能还会追加系统提示、附件、工具说明、hook 结果,token 估算本身也可能有误差。如果等到刚好贴着 effectiveWindow 才 compact,就很容易在实际请求时超过窗口。
最终触发线可以简化成:
text
autoCompactThreshold = effectiveWindow - 13_000
shouldCompact = currentTokenCount >= autoCompactThreshold举个数字例子:
text
模型总窗口:200k
summary 输出预留:20k
effectiveWindow:180k
Auto Compact buffer:13k
触发线:167k也就是说:
text
当前上下文 >= 167k tokens
=> 先 Auto Compact
当前上下文 < 167k tokens
=> 继续正常请求小结
阈值判断是 Auto Compact 前的一层决策逻辑。
它的核心就是:
text
先扣 summary 输出预留
再扣安全 buffer
得到 Auto Compact 触发线
再用当前上下文 token 数和触发线比较如果没到触发线,继续正常请求;如果到了触发线,就先进入完整 compact。它不负责压缩内容,只负责决定什么时候必须压缩。
第四部分:语义压缩
前面的几层都还属于轻量处理:
text
局部减负:把大工具输出换成预览和路径。
Microcompact:清理历史里的旧 tool_result。
阈值判断:判断是否已经需要完整 compact。如果阈值判断发现上下文已经接近上限,Claude Code 就会进入完整 compact。这个阶段才是真正的语义压缩。
语义压缩要解决的问题是:
text
旧对话太长,不能继续完整塞进上下文;
但旧对话里有任务目标、技术结论、修改记录、错误处理、当前进度,
这些信息不能直接丢。所以它不是简单删历史,而是把旧历史改写成一份 compact summary,让模型能继续理解当前任务。
一句话概括:
text
语义压缩 = 用一份更短的 summary 承接旧对话里的任务语义。语义压缩的两条来源
Claude Code 生成 compact summary 主要有两条来源:
text
1. 优先尝试使用 session memory
2. 如果不可用,再调用模型生成 summary1. 使用 session memory
session memory 可以理解成会话过程中沉淀下来的任务记忆。它不是等到 compact 触发时才临时生成,而是在会话推进过程中就可能记录一些长期信息。
它通常会包含:
text
用户目标
当前任务进度
关键文件
重要技术决策
已经解决的问题
后续要继续做的事情如果 session memory 存在、不是空模板,并且用它压缩后上下文仍然足够短,系统就可以直接把它包装成 compact summary。
这条路径的优势是:
text
不需要再调用模型重新总结整段历史
速度更快
成本更低
失败概率更小但它不是无条件使用。系统会检查:
text
session memory 是否存在
内容是否为空
是否能确定哪些消息已经被总结过
压缩后的上下文是否仍然超过阈值如果这些条件不满足,就会进入传统 compact。
2. 调用模型生成 compact summary
如果 session memory 不可用,Claude Code 会发起一次专门的 compact 调用,让模型总结旧对话。
这次调用和普通对话不同。它的任务非常明确:
text
只生成总结
不继续执行用户任务
不调用工具compact prompt 会要求模型重点保留这些内容:
text
1. 用户的主要请求和真实意图
2. 关键技术概念
3. 看过、改过、创建过的文件和代码片段
4. 遇到的错误以及修复方式
5. 已解决的问题和仍在处理的问题
6. 所有非工具类用户消息
7. 待办任务
8. 当前正在做什么
9. 下一步应该做什么这说明 compact summary 不是普通摘要。
普通摘要可能只写:
text
用户在讨论上下文压缩,并要求写文章。这类摘要对 Agent 继续工作帮助很小。
Claude Code 需要的是能继续执行的 summary,例如:
text
用户正在写一篇关于 Claude Code 上下文压缩的技术文章。
文章拆成局部减负、Microcompact、阈值判断、语义压缩、状态恢复五部分。
已完成前三部分的讲解,要求整体风格专业、直观,并尽量贴近源码机制。
当前正在撰写语义压缩部分,下一步应解释 full compact 如何把旧历史变成 summary。这种 summary 才能承接任务状态。
为什么还要保留最近消息?
完整 compact 并不是把所有旧消息都替换成 summary。
原因是 summary 适合承接较早的历史,但最近几轮通常包含更具体的现场信息,例如:
text
用户刚刚提出的修正意见
刚刚生成或修改的内容
刚刚执行的工具结果
最后一步卡在哪里这些内容如果全部进入 summary,可能会丢失细节。
所以 Claude Code 会保留一段最近原始消息,并且在保留时注意消息结构合法性,尤其不能拆开工具调用关系:
text
assistant: tool_use(id = xxx)
user: tool_result(tool_use_id = xxx)如果只保留 tool_result,却删掉对应的 tool_use,API 会认为这个工具结果没有来源。因此保留最近消息时,需要确保 tool_use / tool_result 成对存在。
这一步的目的不是保存更多历史,而是避免 compact 后的上下文结构出错,同时保留最近现场。
compact summary 会被包装成一条继续执行指令
模型生成 summary 之后,Claude Code 不会直接把原始 summary 原封不动塞回上下文。
它会把 summary 包装成一条新的用户消息,大意是:
text
这个会话是从之前一个上下文不足的会话继续来的。
下面是旧会话的摘要。
请直接从断点继续,不要重新问用户,不要复述摘要。这个包装很关键。
因为 compact 后,模型看到的是一个新的上下文。如果只给它一段 summary,而不告诉它"继续执行",模型可能会把 summary 当成普通资料阅读,然后重新询问用户下一步。
Claude Code 希望的是:
text
模型读完 summary 后,直接接着之前的任务继续。所以 compact summary 不只是信息压缩结果,也带有继续执行的指令。
compact boundary 的作用
完整 compact 后,系统会创建一个 compact_boundary。
它的作用是标记:
text
旧历史到这里已经被压缩。
后续恢复会话时,从这个边界之后重建上下文。压缩后的上下文大致是:
text
旧消息
旧消息
旧消息
compact boundary
compact summary
最近保留的原始消息
必要的附件和 hook 结果这里先只关注前两项:
text
boundary:标记旧历史已经压缩
summary:承接旧历史语义后面的附件、hook、文件状态、计划状态等内容,会在"状态恢复"部分单独讲。
小结
语义压缩是完整 compact 的核心。
它不是清理某个工具结果,也不是简单截断历史,而是把旧对话里的任务语义转换成 compact summary。
核心流程可以概括为:
text
1. 触发完整 compact
2. 优先尝试使用 session memory
3. 如果不可用,调用模型生成 compact summary
4. 保留必要的最近原始消息
5. 创建 compact boundary
6. 把 summary 包装成"继续执行"的上下文消息最终目标是:
text
旧历史不再完整占用上下文,
但模型仍然知道任务目标、当前进度和下一步方向。第五部分:状态恢复
语义压缩完成之后,上下文并不是只剩下一段 summary 就结束了。
summary 解决的是"历史发生过什么"的问题,但 Claude Code 继续执行任务时,还需要很多更具体的运行信息:
txt
最近读过哪些文件?
这些文件当前内容是什么?
当前有没有 plan?
是否仍然处于 plan mode?
之前调用过哪些 skills?
当前有哪些工具、Agent、MCP 说明需要重新告诉模型?
有没有后台 agent 还在运行,或者结果还没取回?
项目规则、环境说明、hooks 注入内容是否还需要补回来?这些内容不完全属于"对话历史"。它们更接近任务运行时的状态。如果压缩后只保留 summary,模型可能知道任务大方向,却缺少继续执行所需的文件、计划、工具和规则。
所以 Claude Code 在 compact 之后还会做一层状态恢复:把继续工作必需的运行状态重新拼回压缩后的上下文。
压缩后的上下文长什么样?
源码里,压缩结果最后会通过 buildPostCompactMessages 重新组装成一组消息,顺序是:
txt
boundaryMarker
summaryMessages
messagesToKeep
attachments
hookResults也就是:
这里可以把它拆成两层理解:
txt
summaryMessages:负责承接旧历史
attachments / hookResults:负责补回继续执行所需的运行状态状态恢复主要发生在后半部分,也就是把各种 attachments 和 hookResults 补回去。
第一类:恢复最近文件内容
Claude Code 在 compact 前会记录 readFileState。这个状态里保存了模型最近读过的文件,以及这些文件的访问时间。
compact 成功后,它不会把所有读过的文件都重新塞回上下文,而是按最近访问时间排序,优先恢复最可能继续用到的文件。
恢复文件时有几个限制:
txt
最多恢复 5 个文件
每个文件最多约 5k tokens
文件恢复总预算约 50k tokens这个设计很关键。因为 summary 里写"正在修改 app.ts",并不等于模型真的看得见 app.ts 的当前内容。
如果不恢复最近文件,压缩后的模型可能只能依赖摘要判断代码状态。这样一来,要么它需要重新读取文件,要么它会基于不完整信息继续写代码。状态恢复就是为了减少这种断层:压缩历史可以变短,但关键文件内容要尽量重新放回模型眼前。
另外,源码里还会跳过已经包含在保留消息里的 Read 结果。也就是说,如果某个文件读取结果已经在 messagesToKeep 里,就没必要再通过 file attachment 重复注入一次。
第二类:恢复计划和 plan mode
如果当前会话里存在 plan,Claude Code 会生成一个 plan_file_reference attachment,把计划文件路径和计划内容一起放回上下文。
这一步解决的是任务进度问题。
summary 可能会写"接下来继续做状态恢复章节",但 plan 通常包含更结构化的任务分解、完成状态和下一步安排。把 plan 恢复回来,可以让模型压缩后继续沿着原来的任务计划推进,而不是只靠 summary 里的几句话重新判断。
如果当前仍然处于 plan mode,Claude Code 还会额外生成 plan_mode attachment。
这个 attachment 的意义是告诉模型:
txt
压缩发生了,但当前权限/工作模式没有变
如果压缩前还在 plan mode,压缩后仍然要按 plan mode 的规则工作否则模型可能在 compact 后丢失模式信息,把"只能规划,不能直接改文件"的阶段误当成普通执行阶段。
第三类:恢复已经调用过的 skills
如果压缩前调用过 skill,Claude Code 会把这些已经使用过的 skill 内容重新注入为 invoked_skills attachment。
这不是简单记录一句"之前用过某个 skill",而是把 skill 的具体规则重新提供给模型。原因很直接:summary 可以概括事实,但不能保证完整保留 skill 里的操作要求、约束和检查流程。
例如,压缩前如果使用过某个文档处理或前端设计 skill,后续继续工作时,模型仍然需要遵守那个 skill 的具体规则。只在 summary 里写一句"使用了某某 skill",约束力度是不够的。
不过这部分同样有预算控制:
txt
每个 skill 最多约 5k tokens
skills 总预算约 25k tokens
最近调用的 skill 优先保留这里的逻辑是:压缩后最应该恢复的,是近期仍可能影响当前任务的规则,而不是把所有历史 skill 无限追加回来。
第四类:恢复工具、Agent、MCP 说明
压缩会移除大量旧消息,其中可能包含工具说明、Agent 列表变化、MCP 服务说明等上下文。
所以 compact 后,Claude Code 会重新生成几类说明:
txt
deferred_tools_delta:当前有哪些延迟加载工具可通过 ToolSearch 使用
agent_listing_delta:当前有哪些 Agent 类型可用
mcp_instructions_delta:当前连接的 MCP 服务有哪些使用说明这部分恢复的不是任务内容,而是"模型现在能调用什么能力,以及这些能力应该怎么用"。
如果缺少这一步,模型可能还记得用户要做什么,但不知道当前工具环境是什么。例如它可能不知道某些 deferred tools 已经可用,也可能不知道某个 MCP server 提供了额外规则。
源码里在 compact 后会把这些 delta attachment 重新加回去,相当于对压缩后的模型重新声明当前可用能力。
第五类:恢复后台 agent 状态
Claude Code 还会检查当前是否存在异步 agent 任务。
如果某个后台 agent 还在运行,或者已经结束但结果还没有被取回,compact 后会生成 task_status attachment。它会告诉模型:
txt
后台任务的 taskId
任务描述
当前状态
进度摘要或错误信息
输出文件路径这一步主要是为了避免压缩后丢失后台任务状态。
否则模型可能不知道已经有一个 agent 在处理同类任务,于是重复启动新的 agent;或者它不知道某个 agent 已经完成,从而没有去读取已有结果。
对于压缩后的连续执行来说,后台任务不是普通聊天记录,而是仍然影响后续决策的运行状态。
第六类:执行 hooks
compact 前后还会涉及 hooks。
这部分可以分成三类:
txt
PreCompact hooks:压缩前执行,可以补充压缩相关指令
SessionStart hooks:压缩成功后执行,用 compact 作为触发来源
PostCompact hooks:压缩完成后执行,用于额外处理或展示其中最影响"状态恢复"的,是 compact 后重新执行的 SessionStart hooks。
因为 compact 后的上下文在某种意义上是一个新的起点,Claude Code 需要重新注入一些会话启动时才会出现的上下文,例如项目规则、环境说明、团队约定、安全限制等。
如果这些内容不补回来,模型可能保留了任务摘要,却丢掉了项目级约束。对于代码任务来说,这类约束往往比历史闲聊更重要。
小结
状态恢复不是再次总结历史,而是解决 compact 之后"还能不能继续正常工作"的问题。
语义压缩关心的是:
txt
旧上下文太长,能不能压成一段可继续理解的 summary?状态恢复关心的是:
txt
压缩之后,模型是否仍然拥有继续执行任务所需的文件、计划、工具、规则和后台任务状态?所以完整的 compact 不能只看 summary 生成得好不好,还要看 summary 后面有没有把关键运行状态补回来。
最终总结:上下文压缩到底在压什么?
看到这里,我们可以把 Claude Code 的上下文压缩重新拉回到一条主线上。
它并不是等上下文快到上限了,再直接把前面的聊天记录截掉;也不是把所有内容丢给模型,让模型生成一段 summary 就完事。真正的上下文压缩,其实是一套分层处理机制。
这套机制大概可以这样理解:
txt
先处理最容易膨胀的工具结果
再清理历史里低时效的大块 tool_result
然后判断当前 token 是否真的接近危险线
如果必须完整压缩,再生成 compact summary
最后把继续工作所需的运行状态补回来也就是说,Claude Code 不是一上来就做"完整压缩"。它会先用更便宜、更局部的方式减轻上下文压力,只有当上下文真的接近上限时,才进入完整 compact。
五个部分串起来看
前面讲的五个部分,其实分别承担了不同职责:
txt
局部减负:
处理当前链路里过大的工具输出。
重点是别让某一次工具结果直接把上下文撑大。
Microcompact:
清理历史中已经不那么新鲜、但体积很大的 tool_result。
重点是减少旧工具结果长期占用上下文。
阈值判断:
判断现在是不是必须进入完整 compact。
重点是给 summary 输出和后续请求预留安全空间。
语义压缩:
把旧对话历史压成 compact summary。
重点是保留任务目标、关键进展、用户要求和下一步方向。
状态恢复:
在 summary 之外,把文件、计划、skills、工具说明、后台任务和 hooks 补回来。
重点是让模型压缩后还能继续正常工作。如果画成一条链路,就是:
这条链路里,每一层都不是重复工作,而是在解决不同问题。
关键点一:压缩不是越早越好
上下文压缩的目标不是"看到大上下文就压",而是在信息完整性和 token 成本之间做平衡。
如果压得太早,模型会丢掉本来还能直接利用的细节;如果压得太晚,又可能在下一次请求时直接撞到上下文窗口上限。
所以 Claude Code 需要阈值判断。
它会先扣掉 summary 输出预留,再扣掉安全 buffer,最后得到 Auto Compact 的触发线。只有当前上下文 token 数真正接近这条线,才会触发完整 compact。
这也是为什么上下文压缩不是一个单纯的"文本处理问题",它首先是一个预算管理问题。token 不会因为我们写得认真就自动变多,必要的预留和阈值必须算清楚。
关键点二:工具结果是最需要治理的对象
在 Agent 类应用里,真正容易把上下文撑大的,往往不是用户说了多少话,而是工具返回了多少东西。
一次搜索、一段日志、一个大文件读取结果、一批 shell 输出,都可能比普通对话大得多。
所以 Claude Code 的上下文压缩链路里,前两层都在处理工具结果:
txt
局部减负:处理当前这轮过大的工具结果
Microcompact:处理历史里旧的大块工具结果这说明一个很重要的设计思路:不要等所有内容都积累到难以处理时再统一压缩,而是先把最容易失控的部分管起来。
工具结果通常有一个特点:它们对当前任务很重要,但并不是所有原文都需要长期留在上下文里。该保留路径就保留路径,该替换占位符就替换占位符,该清理缓存就清理缓存。
关键点三:summary 不是压缩的终点
很多人一提到上下文压缩,第一反应就是"生成摘要"。
但在 Claude Code 里,summary 只是完整 compact 的核心之一,不是全部。
因为模型继续工作时,不只需要知道"之前发生了什么",还需要知道"现在手上有什么"。
比如:
txt
最近关键文件的真实内容
当前 plan 和 plan mode
已经调用过的 skills 规则
当前可用工具、Agent、MCP 说明
后台 agent 的运行状态
hooks 注入的项目规则和环境说明这些东西不适合全都塞进 summary。summary 应该承接历史语义,而运行状态应该通过 attachments 和 hookResults 重新补回来。
所以完整 compact 的重点不是"生成一段看起来不错的摘要",而是:
txt
旧历史能被 summary 接住,
新上下文还能支撑模型继续执行。最后再收束一下
如果只用一句话总结 Claude Code 的上下文压缩:
它不是简单缩短聊天记录,而是在有限 token 窗口里,尽量保留继续完成任务所需的信息。
这里的"信息"分成两类:
txt
语义信息:
用户目标是什么?
已经做了什么?
当前进展到哪里?
下一步应该做什么?
运行状态:
关键文件在哪里?
文件内容是什么?
当前计划是什么?
有哪些工具和规则可用?
后台任务有没有结果?理解了这两类信息,也就理解了为什么 Claude Code 要把上下文压缩拆成这么多层。
局部减负和 Microcompact 负责先把工具输出的压力降下来;阈值判断负责决定什么时候不能再拖;语义压缩负责把旧历史变成 summary;状态恢复负责让压缩后的模型还能接着干活。
上下文压缩真正难的地方,不是"少放点内容",而是知道哪些内容可以少放,哪些内容必须换一种形式继续保留。
这也是 Agent 工程里很核心的一点:上下文窗口再大,也不应该被随意消耗;窗口再有限,也不能压到模型失去工作能力。好的上下文压缩,应该让模型变轻,但不能让模型变糊涂。