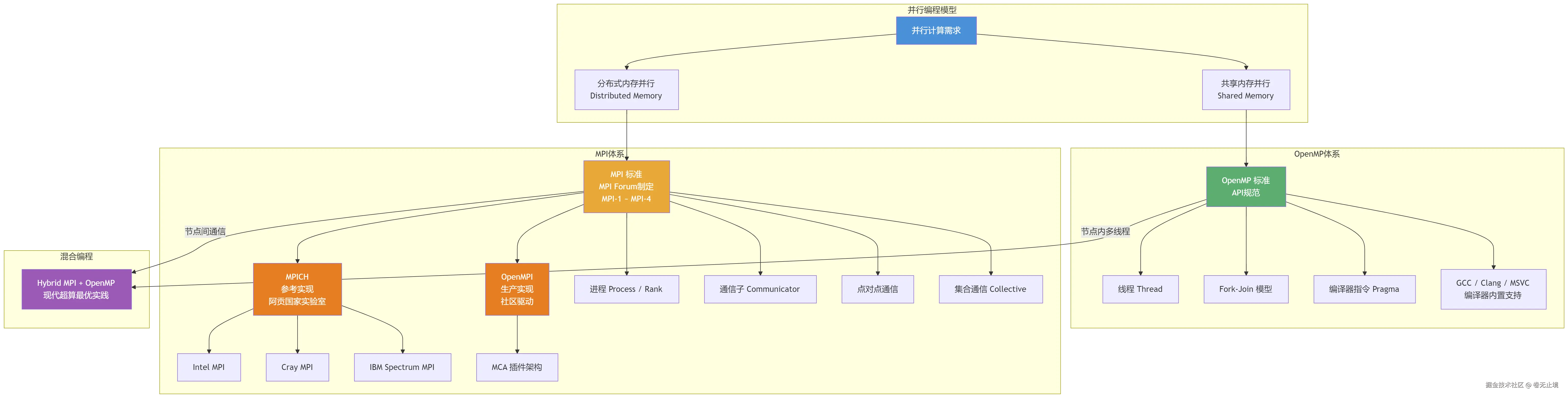
并行计算领域有三个名字长得有点像、却经常让人搞混的技术------OpenMPI 、MPICH 和 OpenMP。它们不是竞争关系,也不是同一件事的不同叫法,而是在高性能计算(HPC)体系里各司其职、甚至可以协同工作的不同层次的工具。理清它们的关系,是真正理解现代并行程序设计的第一步。
一、从"名字游戏"说起:三者的本质区别
先把最容易混淆的地方说清楚:OpenMP 和 MPI(含 OpenMPI、MPICH) 是两个完全不同维度的东西。
- OpenMP 是一套针对共享内存 (Shared Memory)架构的并行编程 API,靠的是线程(Thread) 。你在一台多核机器上跑,所有核心共用同一块内存,OpenMP 用编译器指令(
#pragma omp parallel)把任务分给不同线程。 - MPI(Message Passing Interface) 是一套消息传递 标准,针对的是分布式内存(Distributed Memory)架构------多台机器、多个节点,每个进程有自己独立的内存空间,靠"发消息"来通信。
- OpenMPI 和 MPICH 则是 MPI 标准的两种具体实现(Implementation),就像 Chrome 和 Firefox 都实现了 HTML 标准一样。
用一句话总结:OpenMP 管一台机器内部的多核并行;MPI 管多台机器之间的并行协作;OpenMPI 和 MPICH 是 MPI 的两个主流实现版本。
二、MPI 标准:OpenMPI 与 MPICH 的共同祖先
MPI 标准由 MPI Forum 制定,从 1992 年开始演化,目前已到 MPI-4。它定义了进程间通信的接口规范,但不管具体怎么实现。
MPICH:参考实现,学术血统
MPICH 诞生于 1992 年,名字来自"MPI over CHameleon",最初就是为了给 MPI Forum 的标准制定过程提供反馈而开发的------换句话说,它是 MPI 标准的官方参考实现。
- 由美国阿贡国家实验室(Argonne National Laboratory)主导开发
- 目标是高性能、高可移植性,支持 MPI-1 到 MPI-4 全部标准
- 2025 年荣获 ACM Software System Award,与 TCP/IP、GCC、Unix 同列
- 更重要的是,MPICH 是一个派生实现的基础平台------Intel MPI、Cray MPI、IBM Spectrum MPI 等商业实现都基于 MPICH 的代码框架
OpenMPI:工程导向,社区驱动
OpenMPI 诞生于 2004 年,由 LAM/MPI、FT-MPI、LA-MPI 等多个项目合并而来,走的是另一条路:
- 面向生产环境 和常见使用场景优化
- 采用模块化插件架构(MCA,Modular Component Architecture),网络支持灵活
- 社区活跃,文档丰富,在学术界和工业界使用率极高
- 对 InfiniBand、RoCE、10GbE 等高速网络有良好支持
两者的核心差异一览
| 维度 | MPICH | OpenMPI |
|---|---|---|
| 定位 | MPI 标准参考实现 | 生产环境通用实现 |
| 起源 | 1992,阿贡国家实验室 | 2004,多项目合并 |
| 架构 | 模块化,易于派生 | MCA 插件架构 |
| 派生实现 | Intel MPI、Cray MPI 等 | 独立演进 |
| API 兼容性 | 完全符合 MPI 标准 | 完全符合 MPI 标准 |
| 适用场景 | 研究、超算、需要定制 | 通用集群、生产部署 |
两者 API 完全一致------同一份 MPI 代码,换个编译器链接不同实现即可运行,无需修改源码。
三、核心概念速查
MPI 体系的核心概念
- 进程(Process) :MPI 程序的基本执行单元,每个进程有独立内存空间
- 通信子(Communicator) :进程组的抽象,
MPI_COMM_WORLD是默认的全局通信子 - Rank:进程在通信子中的编号(从 0 开始)
- 点对点通信 :
MPI_Send/MPI_Recv,一对一消息传递 - 集合通信(Collective) :
MPI_Bcast(广播)、MPI_Reduce(规约)、MPI_Scatter/Gather等 - 非阻塞通信 :
MPI_Isend/MPI_Irecv,发完消息不等待,提升性能
OpenMP 体系的核心概念
- 线程(Thread) :OpenMP 的执行单元,共享同一进程的内存
- Fork-Join 模型:主线程遇到并行区域时"分叉"出多个线程,结束后"合并"
- 编译器指令(Pragma) :
#pragma omp parallel for等,零侵入式并行化 - 数据共享属性 :
shared(共享变量)vsprivate(线程私有变量) - 竞态条件(Race Condition) :多线程同时写同一变量导致的错误,需用
critical或atomic保护
混合编程(Hybrid MPI + OpenMP)
现代超算节点往往是"多节点 × 多核"架构。最优策略是:
节点间用 MPI 通信,节点内用 OpenMP 多线程
这种混合模式可以大幅减少 MPI 进程数,降低通信开销,同时充分利用多核。研究表明,在 Cray XT5 这类八核节点上,混合模式相比纯 MPI 可节省高达 5 倍内存。
四、关系图
五、一句话总结
这三者构成了现代 HPC 并行编程的完整生态:OpenMP 负责单节点内的细粒度线程并行,MPI 标准定义了跨节点的消息传递规范,而 MPICH 和 OpenMPI 是这套规范在现实世界里的两种主流落地方式------前者是学术界的参考基准和商业实现的母体,后者是工程实践中最常见的开箱即用选择。三者并不互斥,混合使用才是榨干现代超算性能的正确姿势。
参考来源:
- OpenMP 官方文档及 CS Hunter 课程讲义 --- 共享内存与线程模型
- Stack Overflow: MPICH vs OpenMPI --- 实现差异深度对比
- MPICH 官网 Overview --- MPICH 历史、定位与获奖记录
- OpenMP.org --- Hybrid MPI and OpenMP Parallel Programming 混合编程研究