FlinkCDC 任务 EOF 异常排查复盘:从"误判损坏"到"精准调优"
一、 背景
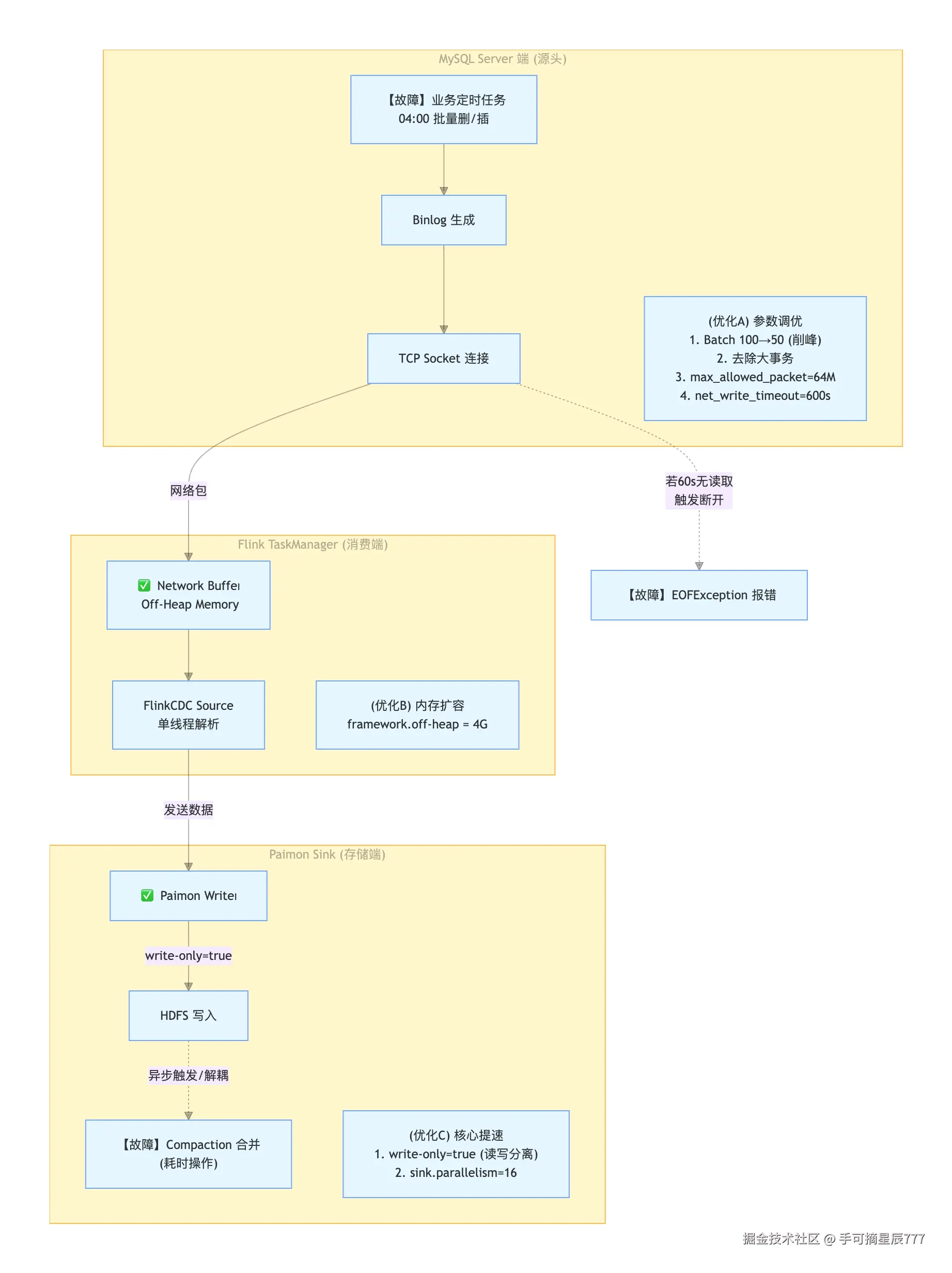
任务架构 :
MySQL (Master/Slave) -> FlinkCDC (3.3.0) -> Flink TaskManager -> Paimon (On HDFS)
故障现象 :
FlinkCDC 同步任务频繁报错 EOFException,报错位置固定在 EXT_WRITE_ROWS 事件解析时。报错时间点集中在凌晨 4:00 到 4:30 之间。MySQL 端开启 binlog_checksum=CRC32。

二、 排查心路历程
第一阶段:迷雾重重------误以为是 Binlog 损坏
起初,面对 EOFException 和 Failed to deserialize data,我们的第一反应是数据流被打断了。结合网上的资料,我们怀疑是 Binlog 文件物理损坏 或者 MySQL 5.6 版本的 Bug。
-
排查 Slave 与 Proxy:因为生产环境 MySQL Master 下挂载了多个 Slave 实例,且应用端可能通过 Proxy 访问。我们怀疑是 Slave 同步延迟或者 Proxy 转发异常导致的数据包截断。
-
尝试切换 Master :为了排除中间环节的干扰,我们将 FlinkCDC 的连接源从 Slave/Proxy 切换到了 Master 实例。
-
结果:问题依旧。这让我们意识到,问题不在网络链路(Proxy)或从库同步机制上,根源就在 Master 实例本身产生的 Binlog 数据流上。

第二阶段:抽丝剥茧------锁定"案发"时间窗口
排除了基础设施问题后,我们开始深挖日志规律。
-
时间戳线索 :通过分析多次报错的 Flink 日志,发现一个惊人的规律------所有
EOFException发生的时间点都在 凌晨 4:00 到 4:30 之间。报错日志中的EventHeaderV4 timestamp精准地指向了这个时间段。 -
业务侧确认 :拿着这个时间窗口去询问业务开发,得到的反馈让我们豁然开朗:这个时间点有一个定时数据迁移任务。
- 操作内容:将 A 库 A 表的数据迁移到 B 库。
- 执行逻辑:先批量删除 B 库旧数据,再批量插入新数据。
-
定位根因:这不仅是简单的 Insert,而是**"大批量 Delete + 大批量 Insert"** 的高压操作。这种操作会在短时间内产生极高密度的 Binlog Event,且事务较大。至此,问题定位从"数据损坏"转向了"大批量写入导致的瞬时压力"。
三、 解决过程:步步为营的优化尝试
确定了是高负载导致的问题后,我们开始分步骤进行优化,每一步都针对性地解决一个可能的瓶颈。
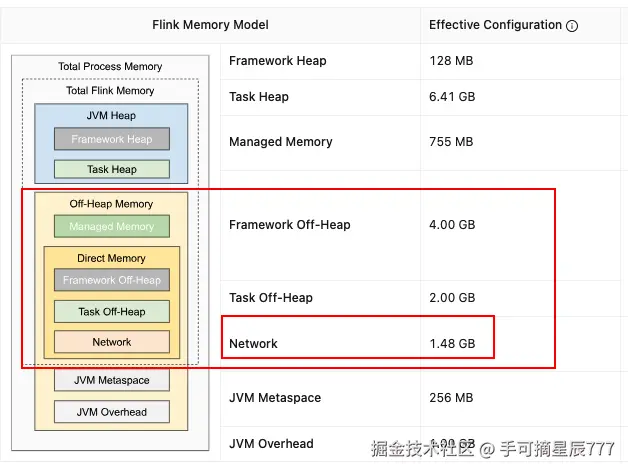
第一步:调大 Flink TM 堆外内存(缓解 GC 压力)
-
思路:我查阅 Flink 官方资料发现,网络数据接收时会先塞入网络缓冲区。如果内存不足,TaskManager 会频繁 GC 甚至卡顿,导致来不及读取 Socket 数据。
-
操作 :将
taskmanager.memory.framework.off-heap.size从默认值调大到 4G。 -
效果 :有明显缓解。之前出现 EOF 异常时,任务重试多少次都过不去;调整后,异常发生时有概率能重试成功。
-
结论:增大内存缓解了"处理卡顿"的问题,但并没有彻底解决"数据发太快、处理太慢"的矛盾,一旦数据量更大,还是会卡死。
第二步:业务侧"削峰"------调整 Batch 大小
- 思路:既然是凌晨的大批量操作导致的,最直接的办法是降低瞬时峰值。
- 操作 :协调业务开发,调整服务端代码。将每条 SQL 的 Insert Batch 大小从 100条降低到 50条。
- 效果:EOF 问题得到进一步改善。
- 结论:减小 Batch Size 虽然没有减少总数据量,但把"大包"拆成了"小包",降低了单次 Binlog Event 的体积和处理耗时,让 Flink 有喘息机会。
第三步:协议层防护------调整 max_allowed_packet
- 思路:Batch 虽然减小了,但考虑到字段内容可能较大,为了防止个别大包超过 MySQL 协议限制被截断,我们进行了保险配置。
- 操作 :将 MySQL Server 端的
max_allowed_packet从 16M 增大到 64M。 - 效果:感觉有所缓解,作为一项兜底保障固定下来。
第四步:解除事务"捆绑"------去掉大事务
- 思路:之前的业务逻辑是"每次事务包含 3 张表的 Insert,每张表 50 条"。这意味着 FlinkCDC 必须读完这三张表的所有数据(作为一个完整事务)才能提交,导致处理周期变长。
- 操作 :调整业务逻辑,去掉事务包装,改为单条 SQL 自动提交模式。
- 效果:数据流变得更加平滑,避免了"等待大事务完整性"带来的长时间阻塞。
第五步:临时方案------提升 Paimon 消费速度
-
思路:经过一系列的排查,都没有从根本原因去解决。由于InsertBatch产生比较大的数据包,mysql在网络传输时拆成多个小的packet进行传输,由于Flink端消费慢,一些packet在socket上还未进行读取,但是mysql server端配置了net_write_timeout=60s, 超过60s没有读取socket连接会被断开,此时Flink再去socket读取剩余的packet时发现没有读取到这些packet,然后进行crc32校验时发现packet不完整,就会抛出我们所看到的EOFException, 从而导致任务失败。所以必须加快Paimon写入速度才能避免这个问题。
-
操作:1. 设置write-only=true,消费任务只做写入不做Compact,启用专用Compact任务
- 与DBA沟通,将
net_write_timeout从60s调整到180s,给予flink任务更多的时间。
- 与DBA沟通,将
-
副作用:设置
write-only=true后,由于改表开启了deletion-vector,所以默认level0的数据不可见(参考文档paimon.apache.org/docs/1.1/pr...),所以需要等待compact-job将level0数据compact后才能查询到,所以数据现在存在20分钟左右的延迟
四、 任务链路与优化点全景图
五、 总结
这次排查是一次典型的从"误入歧途"到"直击核心"的过程:
-
起因误判:起初以为是 Binlog 损坏或网络链路问题,通过切换 Master 排除了干扰。
-
定位真相:通过日志时间戳与业务操作的比对,锁定了"凌晨大批量迁移任务"这一特定场景。
-
多维优化:
- 内存层面:增大 Off-Heap 内存,缓解了 GC 停顿导致的读取延迟。
- 业务层面:减小 Batch Size、拆解事务,实现了对数据流的"削峰填谷"。
- 协议层面 :增大
max_allowed_packet和net_write_timeout,消除了协议截断风险并增加了容错窗口。 - 性能层面:最终通过提升 Paimon Sink 并发度和优化写入配置(关闭同步 Compact),解决了"消费慢于生产"的根本矛盾。
最终,通过**"削峰(业务侧)+ 扩容(内存)+ 提速(Sink端)+ 兜底(超时时间)"**的组合拳,彻底解决了 EOF 问题。