
🔥个人主页:Cx330🌸
❄️个人专栏:《C语言》《LeetCode刷题集》《数据结构-初阶》《C++知识分享》
《优选算法指南-必刷经典100题》《Linux操作系统》:从入门到入魔
《Git深度解析》:版本管理实战全解 《Qt 极境架构》MySQL 核心技术与实战
🌟心向往之行必能
🎥Cx330🌸的简介:

目录
[💡 前言](#💡 前言)
[一. 基础查询回归(温故知新)](#一. 基础查询回归(温故知新))
[📌 场景实战案例](#📌 场景实战案例)
[① 复合条件与模糊查询](#① 复合条件与模糊查询)
[② 多字段组合排序](#② 多字段组合排序)
[③ 别名与空值处理(IFNULL)](#③ 别名与空值处理(IFNULL))
[④ 标量子查询初步](#④ 标量子查询初步)
[⑤ 聚合、分组与过滤(GROUP BY vs HAVING)](#⑤ 聚合、分组与过滤(GROUP BY vs HAVING))
[二. 多表查询(突破单表限制)](#二. 多表查询(突破单表限制))
[2.1 什么是笛卡尔积(Cartesian Product)?](#2.1 什么是笛卡尔积(Cartesian Product)?)
[2.2 过滤笛卡尔积:等值连接](#2.2 过滤笛卡尔积:等值连接)
[📌 典型多表查询案例](#📌 典型多表查询案例)
[三. 自连接(Self-Join)](#三. 自连接(Self-Join))
[4. 子查询(Subqueries / 嵌套查询)](#4. 子查询(Subqueries / 嵌套查询))
[4.1 单行子查询](#4.1 单行子查询)
[4.2 多行子查询](#4.2 多行子查询)
[① IN 关键字](#① IN 关键字)
[② ALL 关键字(必须满足所有条件)](#② ALL 关键字(必须满足所有条件))
[③ ANY 关键字(满足任意一个条件即可)](#③ ANY 关键字(满足任意一个条件即可))
[4.3 多列子查询](#4.3 多列子查询)
[4.4 在 FROM 子句中使用子查询(临时表技术,核心必会)](#4.4 在 FROM 子句中使用子查询(临时表技术,核心必会))
[📌 场景实战案例](#📌 场景实战案例)
[案例 A:显示高于自己部门平均工资的员工信息](#案例 A:显示高于自己部门平均工资的员工信息)
[案例 B:查找每个部门工资最高的人的姓名、工资、部门、最高工资](#案例 B:查找每个部门工资最高的人的姓名、工资、部门、最高工资)
[案例 C:显示每个部门的信息(部门名,编号,地址)和人员数量](#案例 C:显示每个部门的信息(部门名,编号,地址)和人员数量)
[五. 合并查询(Set Operations)](#五. 合并查询(Set Operations))
[5.1 UNION(去重并集)](#5.1 UNION(去重并集))
[5.2 UNION ALL(不去重并集)](#5.2 UNION ALL(不去重并集))
[六. 表的内连和外连(核心重难点)](#六. 表的内连和外连(核心重难点))
[6.1 内连接 (Inner Join)](#6.1 内连接 (Inner Join))
[📌 语法格式](#📌 语法格式)
[📌 案例对照:显示 SMITH 的名字和部门名称](#📌 案例对照:显示 SMITH 的名字和部门名称)
[6.2 外连接 (Outer Join)](#6.2 外连接 (Outer Join))
[6.2.1 左外连接 (Left Join)](#6.2.1 左外连接 (Left Join))
[6.2.2 右外连接 (Right Join)](#6.2.2 右外连接 (Right Join))
[💻 经典外连练习题](#💻 经典外连练习题)
[七. 🏆 硬核实战真题精讲(牛客网 & LeetCode)](#七. 🏆 硬核实战真题精讲(牛客网 & LeetCode))
[💻 题目一:牛客 查找所有员工入职时候的薪水情况](#💻 题目一:[牛客] 查找所有员工入职时候的薪水情况)
[💻 题目二:牛客 针对库中的所有表生成行数统计 SQL](#💻 题目二:[牛客] 针对库中的所有表生成行数统计 SQL)
[💻 题目三:牛客 获取所有非 manager 的员工编号](#💻 题目三:[牛客] 获取所有非 manager 的员工编号)
[💻 题目四:牛客 获取所有员工当前的 manager](#💻 题目四:[牛客] 获取所有员工当前的 manager)
[💻 题目五:LeetCode-178 分数排名 (Rank Scores)](#💻 题目五:[LeetCode-178] 分数排名 (Rank Scores))
[💻 题目六:LeetCode-626 换座位 (Exchange Seats)](#💻 题目六:[LeetCode-626] 换座位 (Exchange Seats))
[✍️ 结语](#✍️ 结语)
💡 前言
在实际的项目开发中,单纯对单张表进行简单的增删改查是远远不够的。企业级业务场景下的数据往往错综复杂,它们分布在不同的表中,彼此关联。如何高效、准确地将这些零散的数据整合并检索出来,是每一位后端及底层开发人员(尤其是我们 C++ 开发者在构建高性能后台服务时)必须攻克的硬核关卡。
本期博文将带大家深度拆解 MySQL 复合查询(Composite Queries),从多表联查的底层逻辑,到自连接、嵌套子查询的精妙设计,再到合并查询的实操演练,最后辅以大厂高频面试真题。一文带你彻底通关!
一. 基础查询回归(温故知新)
在正式切入多表复合查询前,我们先通过一组典型的单表查询案例,快速复习和巩固一下常用的过滤、排序、分组以及聚合函数。
假设我们有一张雇员表 EMP,其字段包含:ename(姓名)、job(岗位)、sal(薪资)、comm(奖金)、deptno(部门号)等。
📌 场景实战案例
① 复合条件与模糊查询
需求 :查询工资高于 500 或岗位为 MANAGER的雇员,同时还要满足他们的姓名首字母为大写 J。
SELECT * FROM EMP
WHERE (sal > 500 OR job = 'MANAGER')
AND ename LIKE 'J%';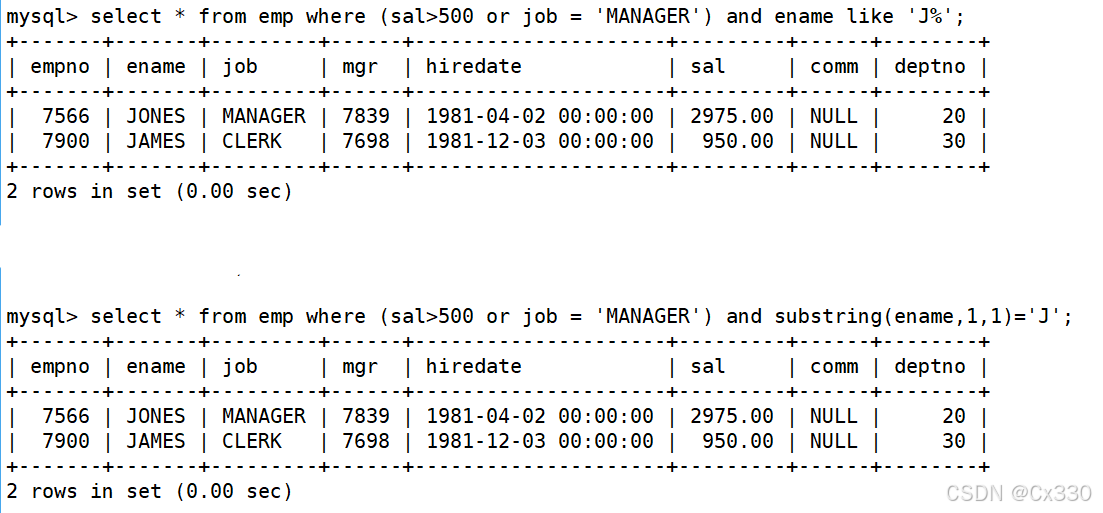
- 核心考点 :AND的优先级高于 OR,因此多条件组合时必须合理使用括号 () 来明确逻辑顺序;LIKE 'J%' 用于匹配以大写 J开头的字符串。
② 多字段组合排序
需求:按照部门号升序排序,若部门号相同,则按雇员的工资降序排序。
SELECT * FROM EMP
ORDER BY deptno ASC, sal DESC;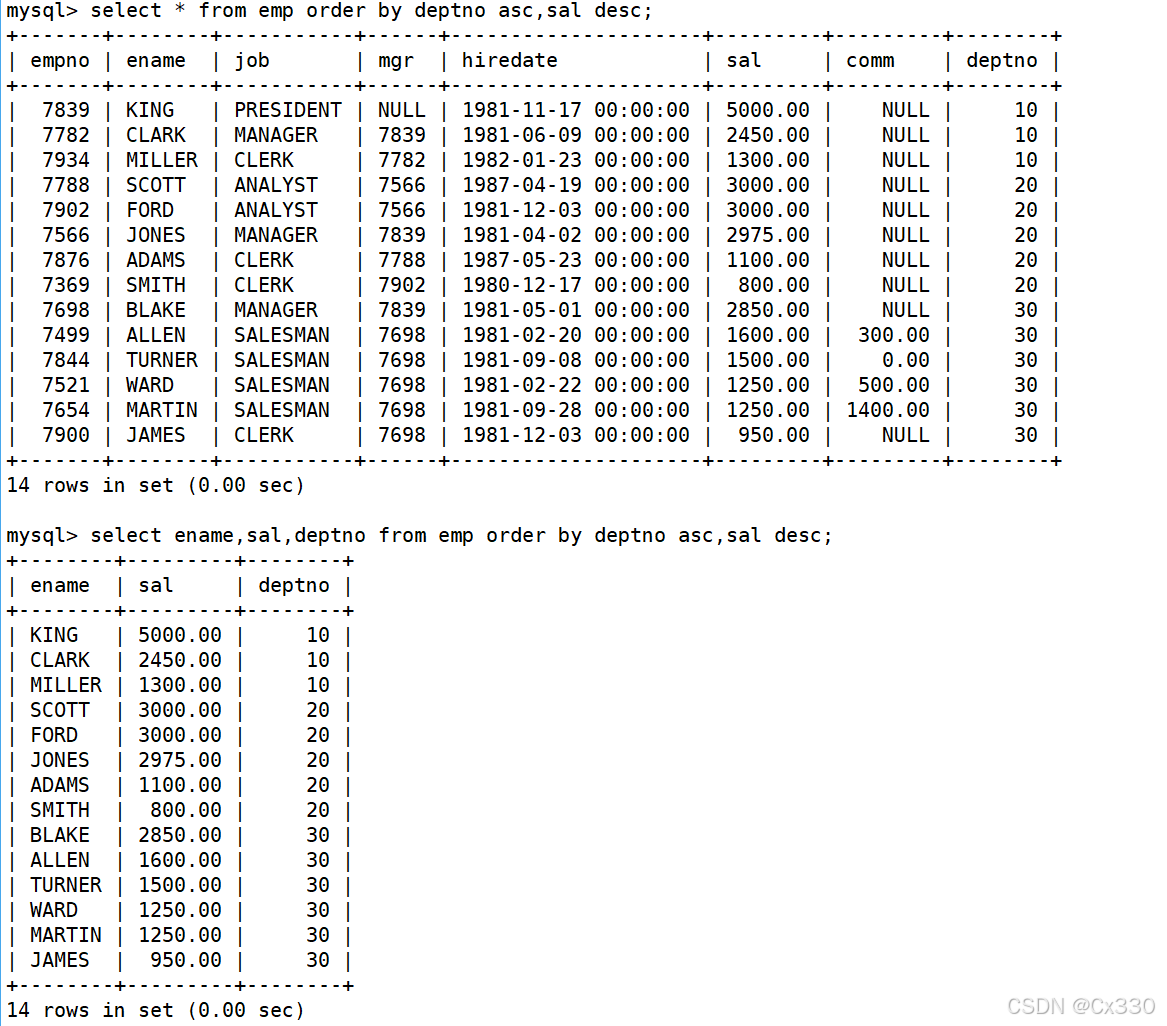
- 核心考点 :ORDER BY后面可以跟多个字段。排序规则从左到右应用,只有当第一个字段相同时,才会使用第二个字段排序。
③ 别名与空值处理(IFNULL)
需求:使用年薪(包含基本工资和奖金)进行降序排序。
SELECT ename, sal * 12 + IFNULL(comm, 0) AS '年薪'
FROM EMP
ORDER BY 年薪 DESC;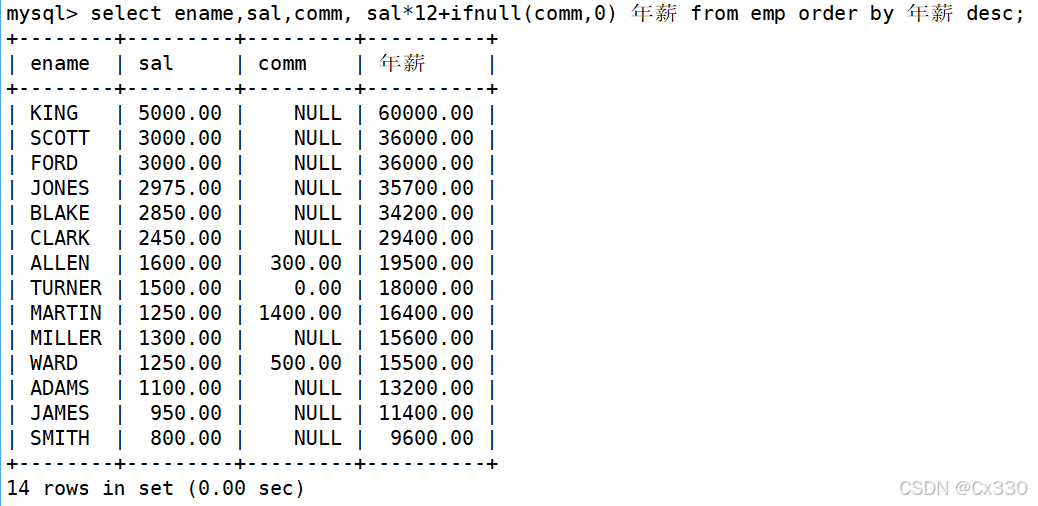
- 核心考点 :奖金 comm字段可能为 NULL,在 SQL 中任何数值与 NULL进行算术运算结果都会变成 NULL。因此必须使用IFNULL(comm, 0) 函数进行安全转换;同时,在 ORDER BY 中可以直接使用 SELECT中定义的别名
'年薪'。
④ 标量子查询初步
需求:显示工资最高的员工的名字和工作岗位。
SELECT ename, job
FROM EMP
WHERE sal = (SELECT MAX(sal) FROM EMP);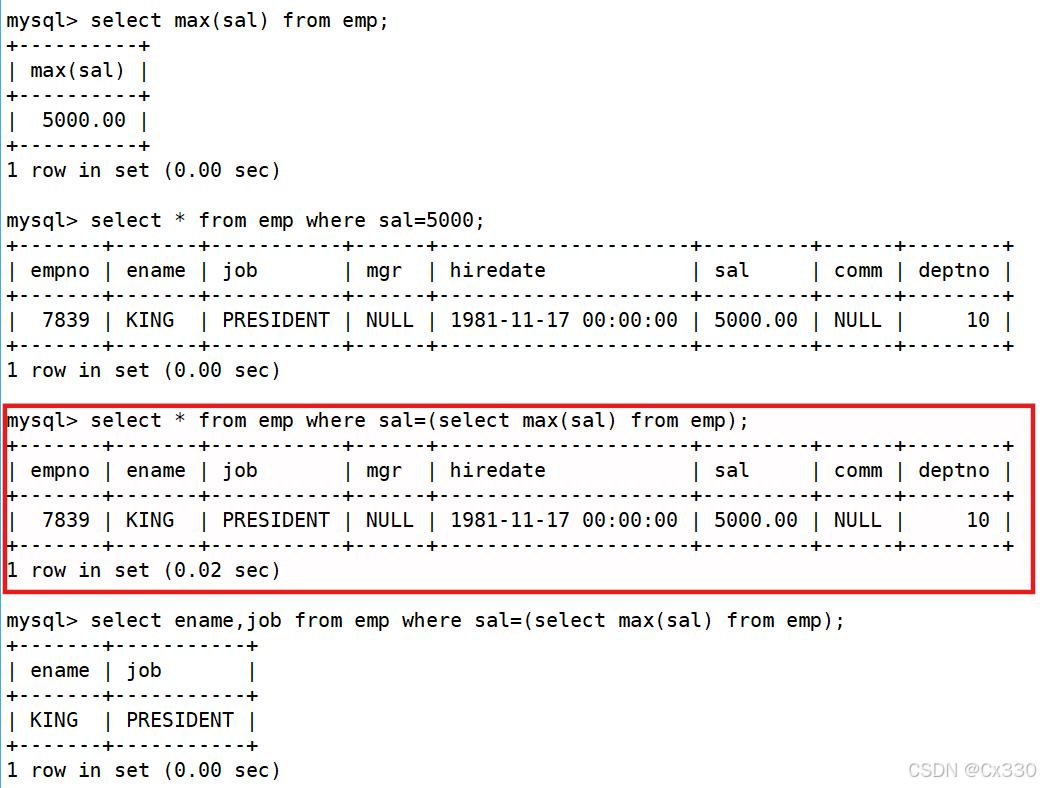
- 核心考点 :利用嵌套的 SELECT MAX(sal) 计算出最高薪资,外层再将其作为过滤条件。
⑤ 聚合、分组与过滤(GROUP BY vs HAVING)
-
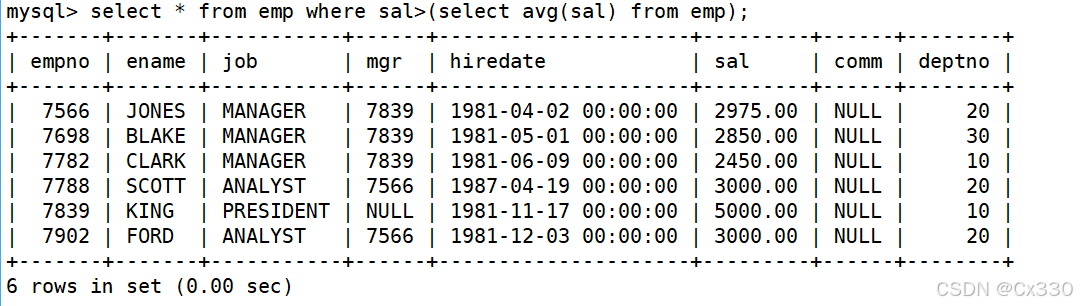
显示工资高于平均工资的员工信息:
SELECT ename, sal FROM EMP WHERE sal > (SELECT AVG(sal) FROM EMP);
-
显示每个部门的平均工资和最高工资:
SELECT deptno, FORMAT(AVG(sal), 2) AS avg_sal, MAX(sal) AS max_sal FROM EMP GROUP BY deptno;

-
显示平均工资低于 2000 的部门号和它的平均工资:
SELECT deptno, AVG(sal) AS avg_sal FROM EMP GROUP BY deptno HAVING avg_sal < 2000;

-
显示每种岗位的雇员总数、平均工资:
SELECT job, COUNT(*), FORMAT(AVG(sal), 2) FROM EMP GROUP BY job;

🔥 经典面试问答:WHERE 与 HAVING 的区别是什么?
WHERE 作用于表中的每一行数据,是在分组前 进行数据过滤,里面不能直接使用聚合函数(如 AVG, COUNT)。
HAVING作用于分组后的组数据,是在**分组后(GROUP BY 后)**进行数据过滤。
二. 多表查询(突破单表限制)
在实际业务场景中,数据往往被规范化存储在不同的实体表中。例如:
-
EMP(员工表)
-
DEPT(部门表)
-
SALGRADE(薪资等级表)
要将这些表里的数据拼凑成一张有意义的视图,就需要使用多表查询。
2.1 什么是笛卡尔积(Cartesian Product)?
如果我们直接执行下面的 SQL,不加任何过滤条件:
SELECT * FROM EMP, DEPT;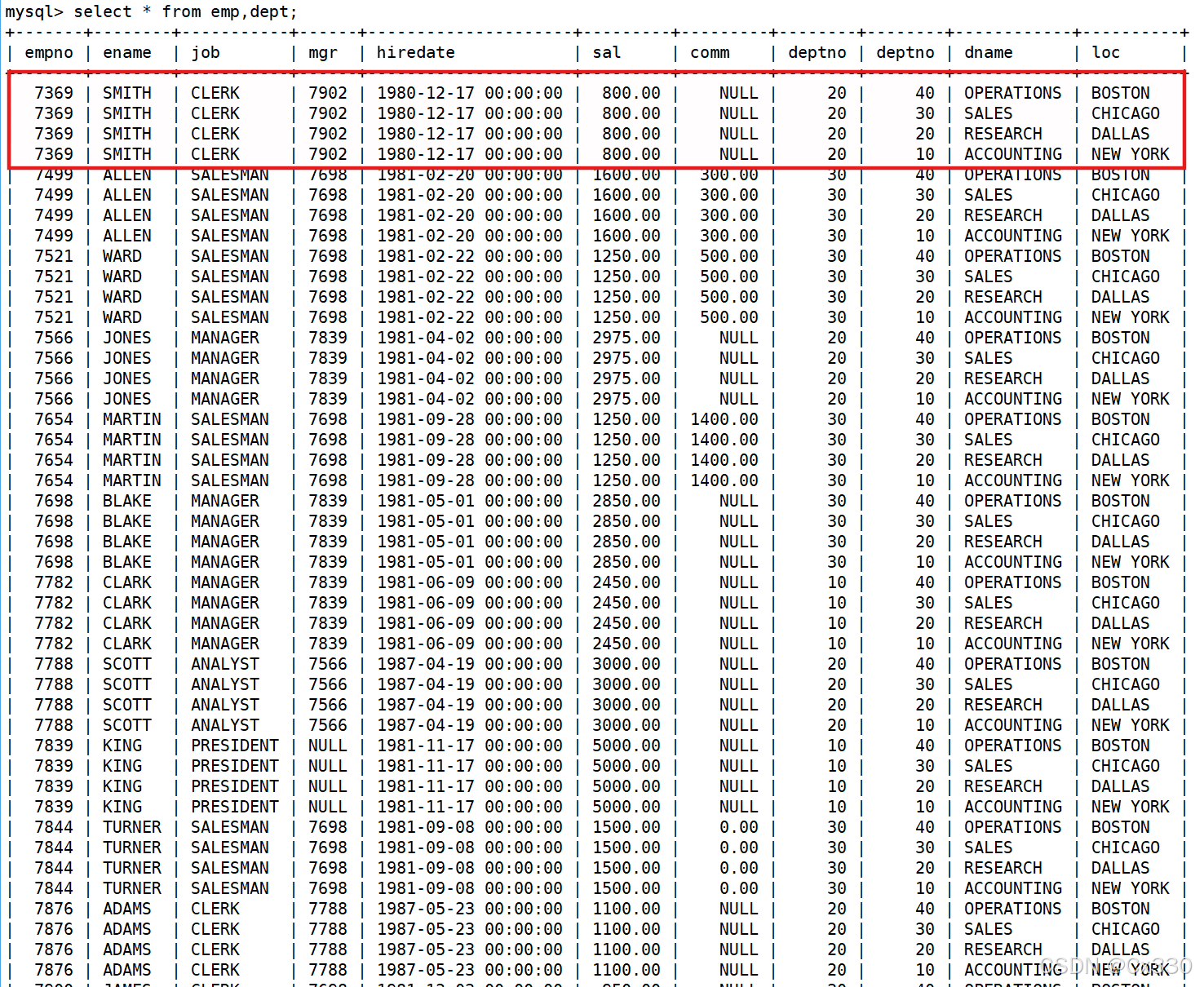
MySQL 会执行笛卡尔积操作:
-
从第一张表 EMP 中取出第一条记录,与第二张表 DEPT的所有记录进行组合。
-
再从
EMP中取出第二条记录,与 DEPT 的所有记录进行组合...... -
最终结果集的行数等于 EMP的行数 * DEPT的行数。
2.2 过滤笛卡尔积:等值连接
无差别的笛卡尔积会产生大量无意义的"垃圾数据"。我们通常只需要满足EMP.deptno = DEPT.deptno(员工表中的部门号等于部门表中的部门号)的记录。这叫做等值连接。
select ename,sal,dname from emp,dept where emp.deptno=dept.deptno;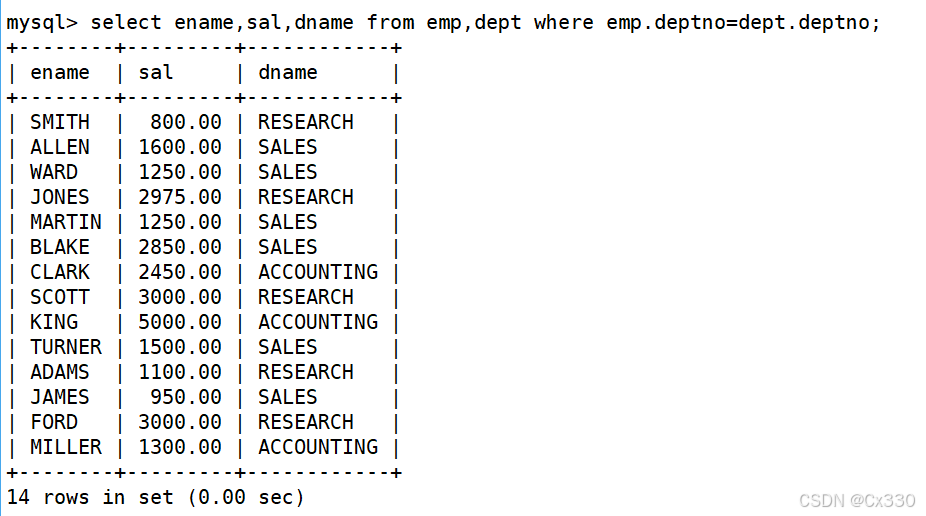
📌 典型多表查询案例
-
显示部门号为 10 的部门名、员工名和工资:
SELECT ename, sal, dname FROM EMP, DEPT WHERE EMP.deptno = DEPT.deptno AND DEPT.deptno = 10;
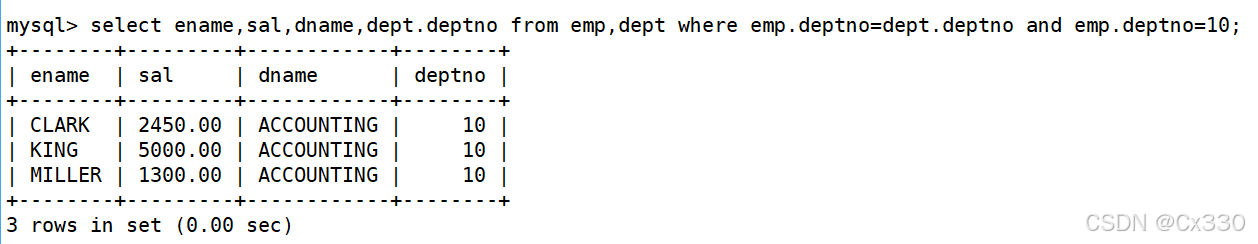
-
显示各个员工的姓名、工资及工资级别(非等值连接):
SELECT ename, sal, grade FROM EMP, SALGRADE WHERE EMP.sal BETWEEN losal AND hisal;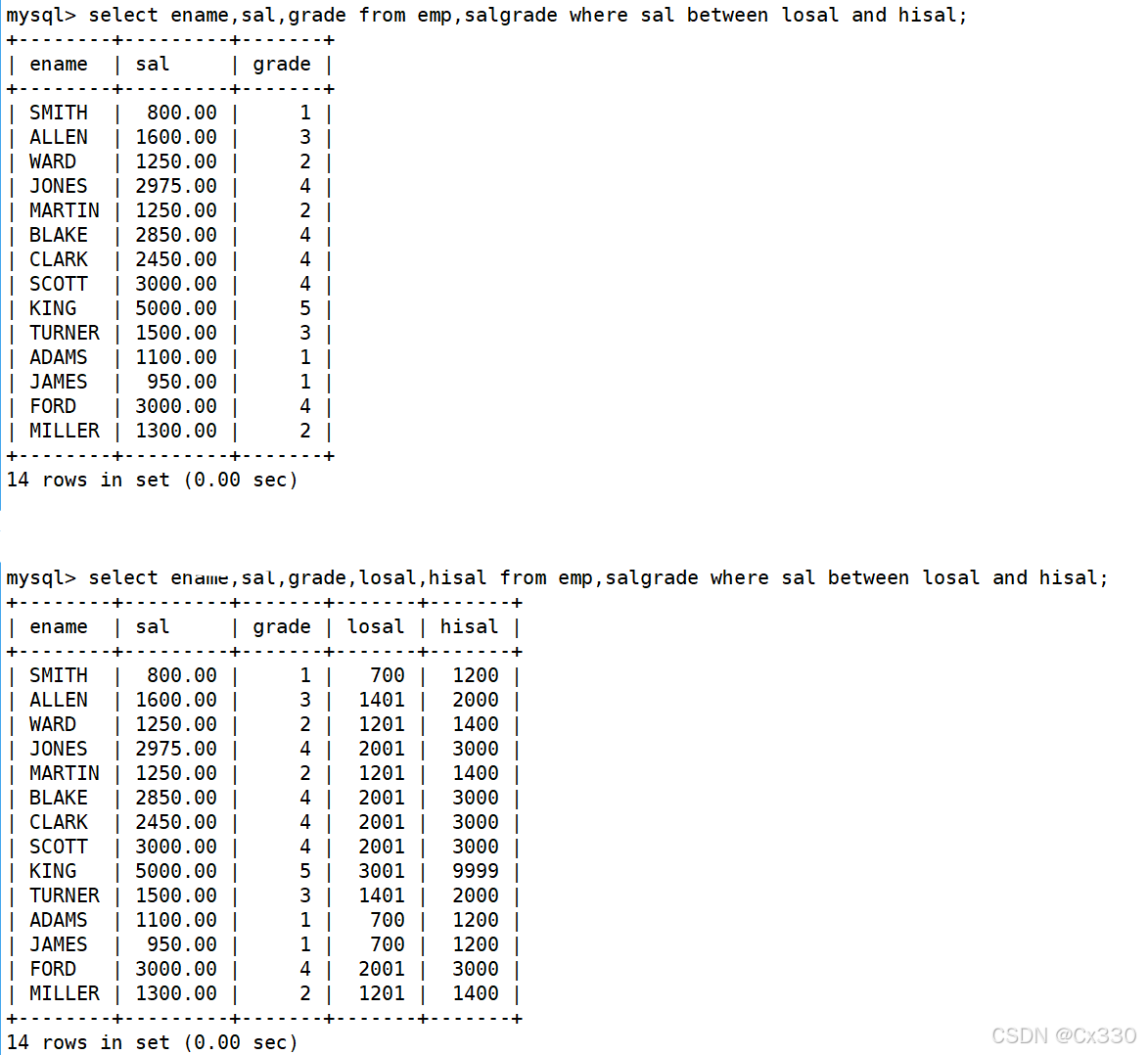
(注:这里通过
BETWEEN ... AND ...建立非等值关联,将薪资映射到薪资等级表的区间中。)
三. 自连接(Self-Join)
自连接 是指在同一张表 内进行关联查询。当表中的某条记录与该表中的另一条记录存在父子级或关联关系时(例如:员工与上级领导都在 EMP表中,通过 mgr字段指向 empno),就需要用到自连接。
需求 :显示员工 FORD的上级领导的工号和姓名。
方法一:使用嵌套子查询
我们可以先查出 FORD 的 mgr(领导工号),再查这个工号对应的名字:
SELECT empno, ename
FROM emp
WHERE emp.empno = (SELECT mgr FROM emp WHERE ename = 'FORD');
方法二:使用自连接(多表查询变体)
我们需要将同一张 emp表在内存中"复制"成两份,并给它们起不同的别名以作区分:
-
e1:代表员工表
-
e2:代表领导表
SELECT e2.empno, e2.ename
FROM emp e1, emp e2
WHERE e1.ename = 'FORD'
AND e1.mgr = e2.empno;
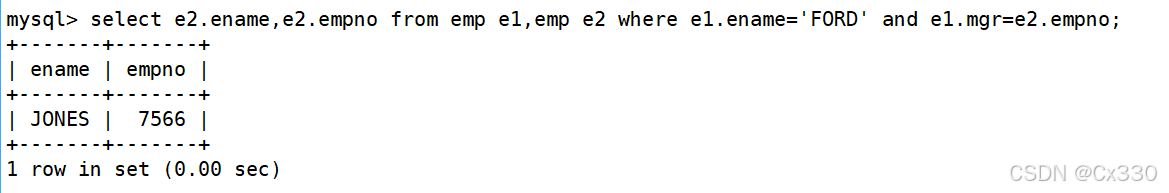
💡 避坑指南 :在进行自连接时,必须为表起别名,否则 MySQL 无法识别你正在操作哪个维度的表字段。
4. 子查询(Subqueries / 嵌套查询)
子查询是指嵌套在其他 SQL 语句(如 SELECT、UPDATE、DELETE)内部的 SELECT语句。
4.1 单行子查询
子查询的返回结果只有单列单行 (即一个具体的值),可以使用 =, >, < , >=, <=, <> 等操作符。
需求 :显示与 SMITH同一部门的员工信息。
SELECT * FROM EMP
WHERE deptno = (SELECT deptno FROM EMP WHERE ename = 'SMITH');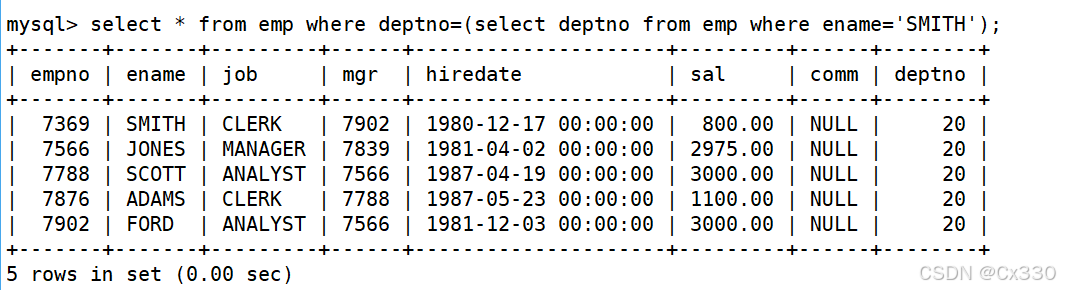
4.2 多行子查询
子查询返回的结果包含单列多行 。此时无法直接使用 =, 必须使用集合操作符:IN, ALL, ANY。
① IN 关键字
需求:查询和 10 号部门的工作岗位相同的雇员的名字、岗位、工资、部门号,但不包含 10 号部门本身的员工。
SELECT ename, job, sal, deptno
FROM emp
WHERE job IN (SELECT DISTINCT job FROM emp WHERE deptno = 10)
AND deptno <> 10;
② ALL 关键字(必须满足所有条件)
需求 :显示工资比 30 号部门所有员工的工资都要高的员工姓名、工资和部门号。
SELECT ename, sal, deptno
FROM EMP
WHERE sal > ALL (SELECT sal FROM EMP WHERE deptno = 30);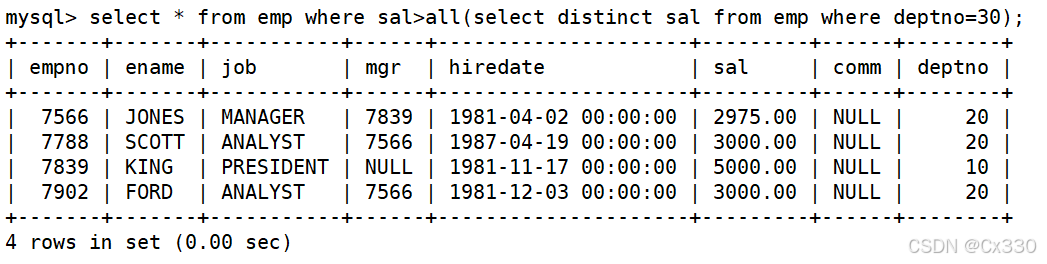
(注:等价于外层工资大于 30 号部门的最高工资。)
③ ANY 关键字(满足任意一个条件即可)
需求 :显示工资比 30 号部门任意一个员工工资高的员工姓名、工资和部门号。
SELECT ename, sal, deptno
FROM EMP
WHERE sal > ANY (SELECT sal FROM EMP WHERE deptno = 30);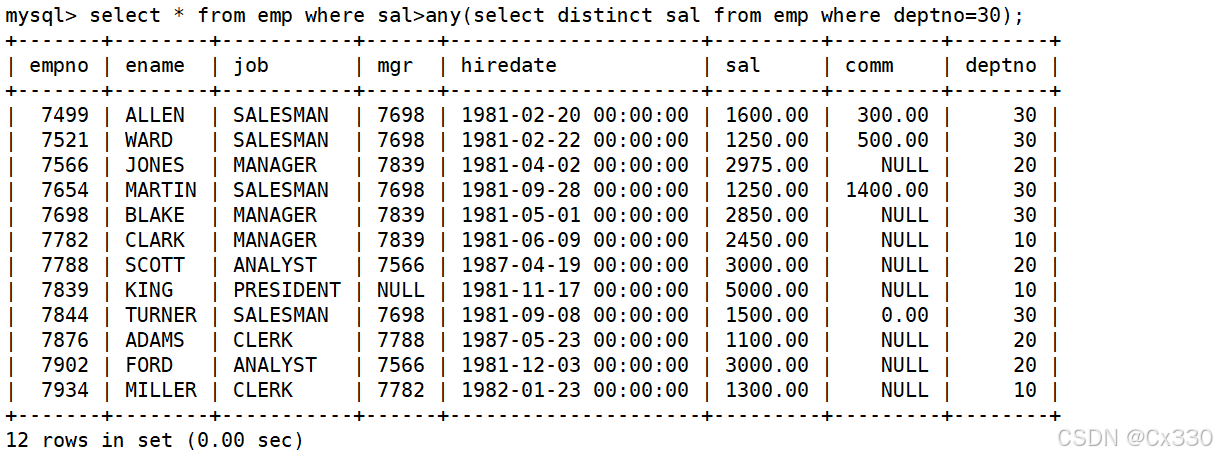
(注:等价于外层工资大于 30 号部门的最低工资。)
4.3 多列子查询
子查询返回的结果包含多列多行。MySQL 支持直接进行元组/多列的比对。
需求 :查询和 SMITH的部门和岗位完全相同的所有雇员(不含 SMITH本人)。
SELECT ename FROM EMP
WHERE (deptno, job) = (SELECT deptno, job FROM EMP WHERE ename = 'SMITH')
AND ename <> 'SMITH';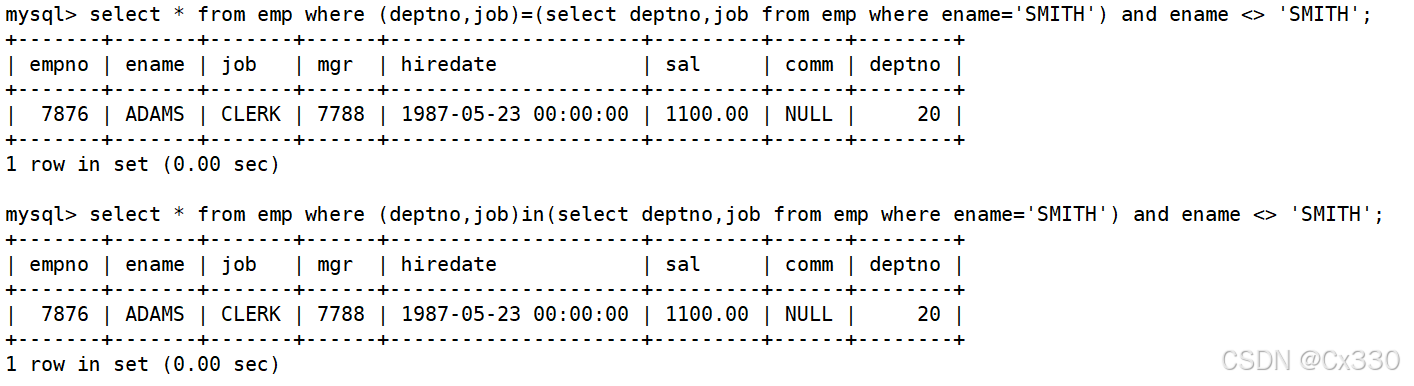
4.4 在 FROM 子句中使用子查询(临时表技术,核心必会)
这是一个极为重要的 SQL 调优与解题技巧。我们将一个子查询的执行结果当成一个动态生成的临时表(tmp),然后将其与其他实体表进行多表关联。
📌 场景实战案例
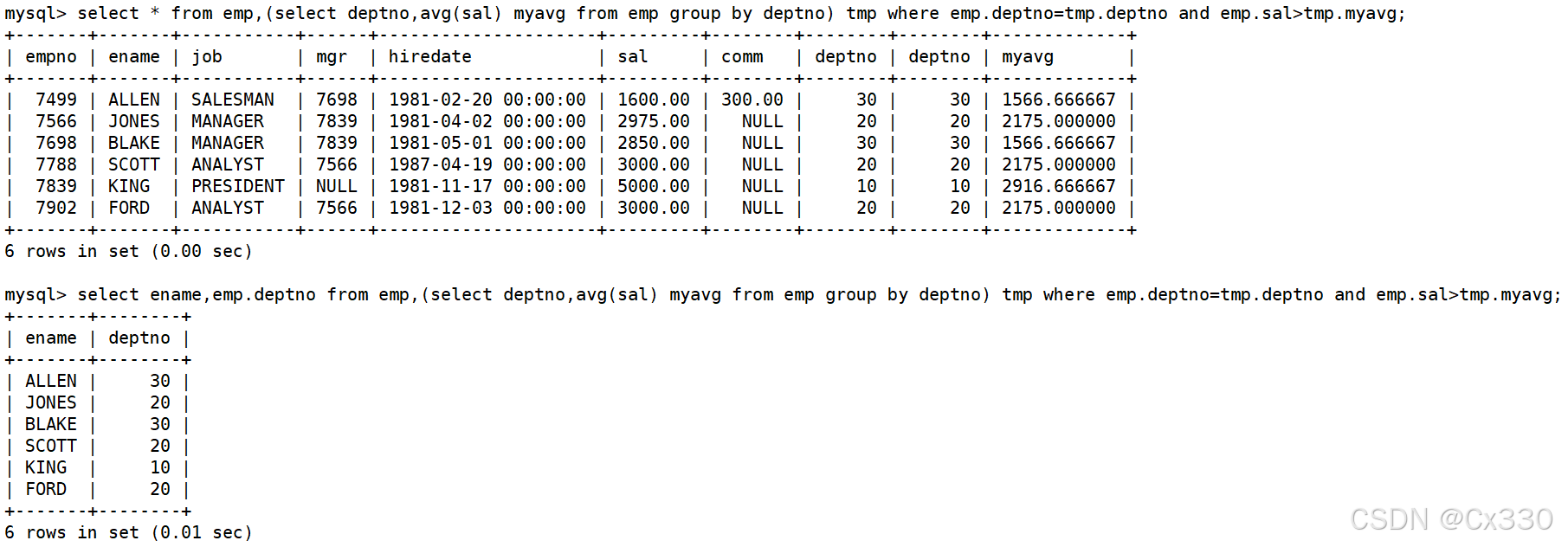
案例 A:显示高于自己部门平均工资的员工信息
-
解题思路:
-
先分组查询出每个部门的平均工资:SELECT AVG(sal) asal, deptno dt FROM EMP GROUP BY deptno。
-
将其作为临时表 tmp,与 EMP主表进行联查。
SELECT ename, deptno, sal, FORMAT(asal, 2) AS dept_avg_sal
FROM EMP, (SELECT AVG(sal) asal, deptno dt FROM EMP GROUP BY deptno) tmp
WHERE EMP.deptno = tmp.dt
AND EMP.sal > tmp.asal; -
案例 B:查找每个部门工资最高的人的姓名、工资、部门、最高工资
-
解题思路:
-
先查出每个部门的最高工资:SELECT MAX(sal) ms, deptno FROM EMP GROUP BY deptno。
-
将其作为临时表联查,通过部门号和最高工资的双重绑定,定位到具体的员工。
SELECT EMP.ename, EMP.sal, EMP.deptno, tmp.ms
FROM EMP, (SELECT MAX(sal) ms, deptno FROM EMP GROUP BY deptno) tmp
WHERE EMP.deptno = tmp.deptno
AND EMP.sal = tmp.ms; -
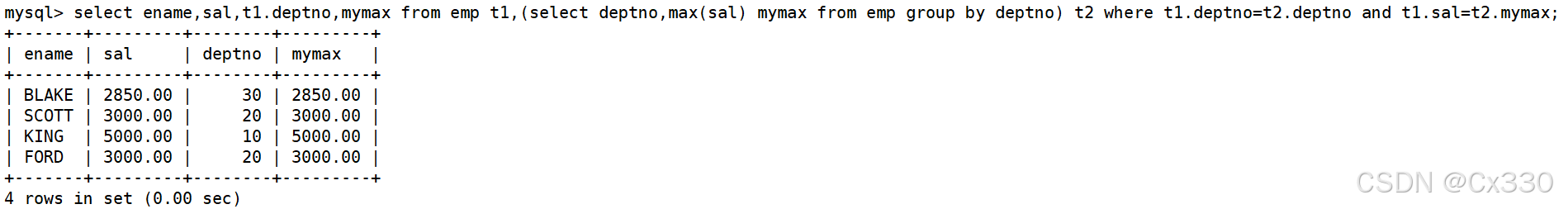
案例 C:显示每个部门的信息(部门名,编号,地址)和人员数量
-
解题方法 1:多表直接分组(简单直观)
SELECT DEPT.dname, DEPT.deptno, DEPT.loc, COUNT(*) AS '部门人数' FROM EMP, DEPT WHERE EMP.deptno = DEPT.deptno GROUP BY DEPT.deptno, DEPT.dname, DEPT.loc;

-
解题方法 2:子查询(高内聚,适合大数据量调优)
-- 1. 先对 EMP 表按部门统计人数得到临时表 tmp -- 2. 将临时表与 DEPT 实体表进行等值连接 SELECT DEPT.deptno, dname, mycnt, loc FROM DEPT, (SELECT COUNT(*) mycnt, deptno FROM EMP GROUP BY deptno) tmp WHERE DEPT.deptno = tmp.deptno;

五. 合并查询(Set Operations)
合并查询用于合并两个或多个 SELECT 语句的结果集。
5.1 UNION(去重并集)
取得两个结果集的并集,并自动去除重复行。
需求 :将工资大于 2500 或职位是 MANAGER的人找出来。
SELECT ename, sal, job FROM EMP WHERE sal > 2500
UNION
SELECT ename, sal, job FROM EMP WHERE job = 'MANAGER';5.2 UNION ALL(不去重并集)
取得两个结果集的并集,但保留所有的重复行。
需求 :将工资大于 2500 或职位是 MANAGER的人找出来(保留重复数据)。
SELECT ename, sal, job FROM EMP WHERE sal > 2500
UNION ALL
SELECT ename, sal, job FROM EMP WHERE job = 'MANAGER';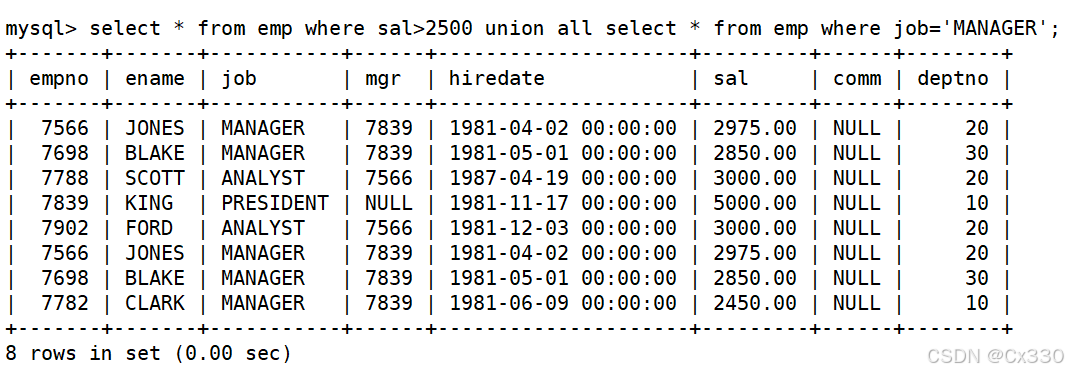
六. 表的内连和外连(核心重难点)
在多表关联查询中,根据"未匹配数据的处理方式",我们把连接方式分为内连接 与外连接。这是数据库设计和 SQL 调优中的重中之重。
6.1 内连接 (Inner Join)
内连接实质上是先对两张表形成笛卡尔积 ,然后利用 ON或 WHERE子句对组合数据进行筛选。只有两张表中同时满足连接条件的记录才会呈现在最终结果中。
💡 在前面的多表关联查询中,我们使用的逗号连接加 WHERE过滤,本质上就是一种隐式内连接。
📌 语法格式
SELECT 字段 FROM 表1 INNER JOIN 表2 ON 连接条件 AND 其他条件;📌 案例对照:显示 SMITH 的名字和部门名称
-
方法一:用前面学过的隐式内连接写法
SELECT ename, dname FROM EMP, DEPT WHERE EMP.deptno = DEPT.deptno AND ename = 'SMITH';
-
方法二:用标准的显式内连接写法(推荐,结构更清晰)
SELECT ename, dname FROM EMP INNER JOIN DEPT ON EMP.deptno = DEPT.deptno WHERE ename = 'SMITH';

6.2 外连接 (Outer Join)
当进行两表联合查询时,如果我们希望即使某张表中的某些记录在另一张表中没有匹配项,也能完整地显示出来 ,就必须使用外连接。外连接分为 左外连接 和 右外连接。
为便于演示,我们先构建两张关联测试表:stu(学生表)与 exam(成绩表)。
-- 创建学生表并插入数据
CREATE TABLE stu (id INT, name VARCHAR(30));
INSERT INTO stu VALUES (1, 'jack'), (2, 'tom'), (3, 'kity'), (4, 'nono');
-- 创建成绩表并插入数据
CREATE TABLE exam (id INT, grade INT);
INSERT INTO exam VALUES (1, 56), (2, 76), (11, 8);6.2.1 左外连接 (Left Join)
如果在联合查询时,左侧的表需要完全显示 ,而右侧表只显示匹配上的数据,未匹配的填 NULL,这就是左外连接。
-
语法格式:
SELECT 字段名 FROM 表名1 LEFT JOIN 表名2 ON 连接条件; -
案例分析:查询所有学生的成绩,即使这个学生没有成绩,也要将其个人信息显示出来。
-- 此时左表为 stu,即使其 id 3, 4 在成绩表中无对应记录,也必须完整显示 SELECT * FROM stu LEFT JOIN exam ON stu.id = exam.id;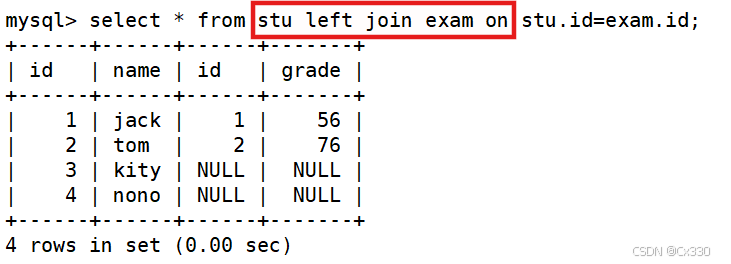
(当左表记录在右表无匹配时,右表字段对应位置自动填充为 NULL)
6.2.2 右外连接 (Right Join)
如果在联合查询时,右侧的表需要完全显示 ,而左表只显示匹配上的数据,未匹配的填 NULL,这就是右外连接。
-
语法格式:
SELECT 字段名 FROM 表名1 RIGHT JOIN 表名2 ON 连接条件; -
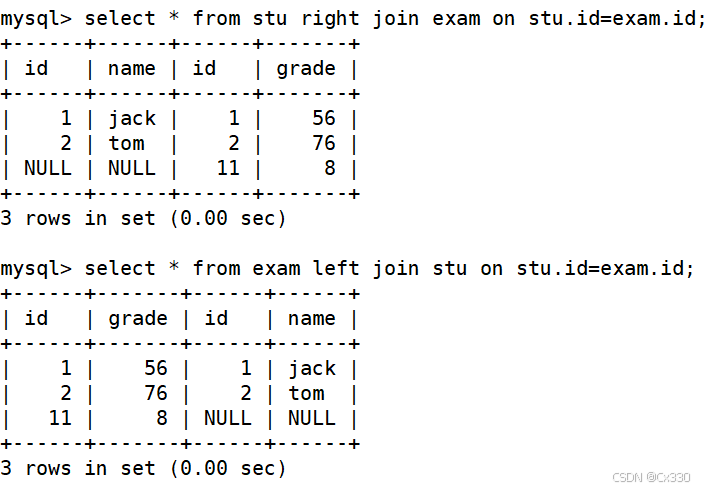
案例分析 :对 stu表和 exam表进行联合查询,要求把所有的成绩都显示出来,即使这个成绩没有学生与之对应,也要显示出来。
-- 此时右表为 exam,即使 grade 为 8 的 id (11) 在学生表中查无此人,也要全部展示 SELECT * FROM stu RIGHT JOIN exam ON stu.id = exam.id;
💻 经典外连练习题
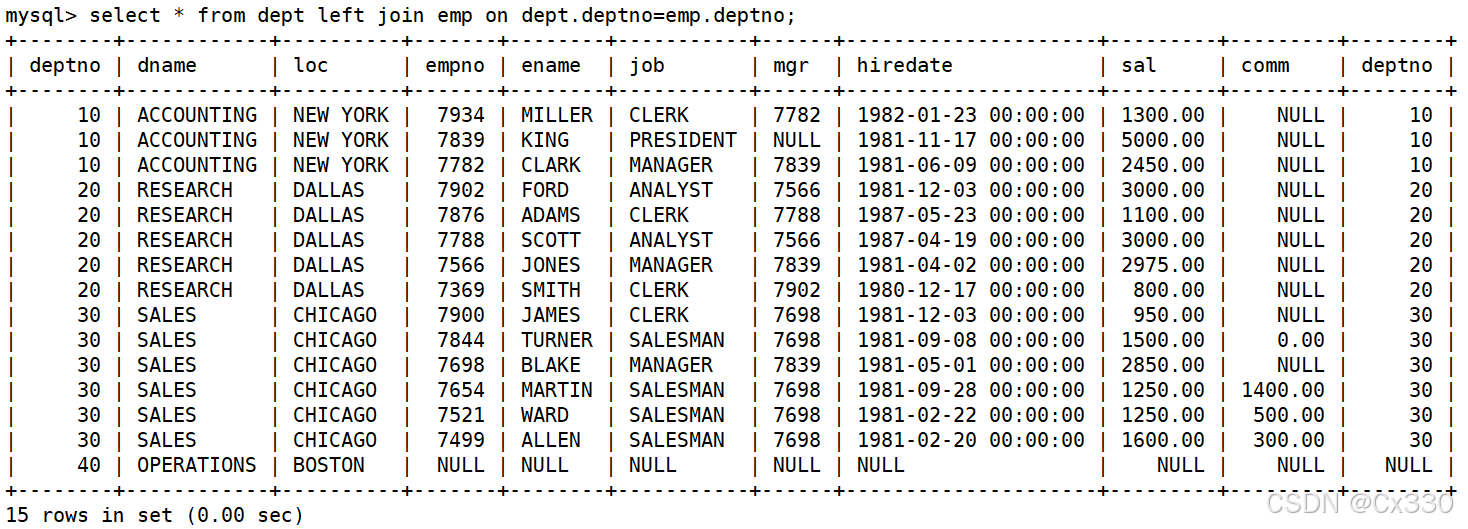
需求:列出部门名称和这些部门的员工信息,同时列出没有员工的部门。
-
解法一:使用左外连接(部门表 DEPT 作为左表)
SELECT d.dname, e.* FROM DEPT d LEFT JOIN EMP e ON d.deptno = e.deptno; -
解法二:使用右外连接(部门表 DEPT 作为右表)
SELECT d.dname, e.* FROM EMP e RIGHT JOIN DEPT d ON d.deptno = e.deptno;
七. 🏆 硬核实战真题精讲(牛客网 & LeetCode)
学完上面完整的复合查询与内外连接理论,我们直接拿几道经典的牛客网(Nowcoder)与 LeetCode 线上高频面试真题来练兵!
💻 题目一:牛客 查找所有员工入职时候的薪水情况
题目描述 :给出所有员工入职时候的薪水情况,输出 emp_no以及 salary,并按照 emp_no进行逆序排序。
-
思路点拨 :员工入职时的薪水通常由其入职时间 hire_date决定。我们需要联查员工表 employees和薪水表 salaries,并将关联条件锁定在入职时间与薪水生效时间一致的记录上。
-
精美 SQL 代码:
SELECT e.emp_no, s.salary
FROM employees e
INNER JOIN salaries s ON e.emp_no = s.emp_no
AND e.hire_date = s.from_date
ORDER BY e.emp_no DESC;
💻 题目二:牛客 针对库中的所有表生成行数统计 SQL
题目描述 :针对库中的所有表,自动生成 SELECT COUNT(*) FROM tableName
;对应的 SQL 语句。
-
思路点拨 :这道题考察的是元数据表 information_schema.TABLES 的应用。我们需要通过拼接字符串的形式,动态生成 SQL 代码。
-
精美 SQL 代码:
SELECT CONCAT('SELECT COUNT(*) FROM ', table_name, ';') AS query_sql
FROM information_schema.tables
WHERE table_schema = DATABASE(); -- 获取当前使用的数据库
💻 题目三:牛客 获取所有非 manager 的员工编号
题目描述 :获取所有非 manager 的员工 emp_no。
-
思路点拨:
-
方法 A:利用子查询找出所有的 manager 编号,然后在主查询中通过NOT IN排除。
-
方法 B:使用 LEFT JOIN 将员工表与 manager 表左外连接,筛选 manager 字段为 NULL的记录。
-
-
精美 SQL 代码(方法 A - 子查询):
SELECT emp_no
FROM employees
WHERE emp_no NOT IN (
SELECT DISTINCT emp_no
FROM dept_manager
WHERE emp_no IS NOT NULL
);
💻 题目四:牛客 获取所有员工当前的 manager
题目描述 :获取所有员工当前的 manager,如果当前的 manager 是员工自己的话则不显示,当前表示 to_date='9999-01-01'。
-
思路点拨:
-
通过 dept_emp拿到员工及其所在的部门。
-
通过 dept_manager拿到该部门当前的经理(注意限定 to_date='9999-01-01')。
-
过滤掉员工编号 emp_no等于经理编号 dept_manager.emp_no 的数据。
-
-
精美 SQL 代码:
SELECT de.emp_no, dm.emp_no AS manager_no
FROM dept_emp de
INNER JOIN dept_manager dm ON de.dept_no = dm.dept_no
WHERE de.to_date = '9999-01-01'
AND dm.to_date = '9999-01-01'
AND de.emp_no <> dm.emp_no;
💻 题目五:LeetCode-178 分数排名 (Rank Scores)
题目描述:编写一个 SQL 查询来给予分数排名。如果两个分数相同,则两个分数排名相同。在排名相同的分数后,后续排名的整数应当是连续的(即 Dense Rank)。
-
思路一(现代窗口函数写法) : 在 MySQL 8.0+ 之后,我们可以直接使用内置窗口函数 DENSE_RANK(),优雅高效。
SELECT score, DENSE_RANK() OVER (ORDER BY score DESC) AS `rank` FROM Scores; -
思路二(复合/子查询传统写法,核心必会) : 若不使用窗口函数,如何得知一个分数的排名?排名实际上就是"大于或等于当前分数的不同(DISTINCT)分数的个数"。这恰好是一道完美的子查询经典案例:
SELECT s1.score, (SELECT COUNT(DISTINCT s2.score) FROM Scores s2 WHERE s2.score >= s1.score) AS `rank` FROM Scores s1 ORDER BY s1.score DESC;
💻 题目六:LeetCode-626 换座位 (Exchange Seats)
题目描述:小美想改变相邻学生座位的相邻顺序,请写出 SQL 来交换相邻两名学生的座位。如果学生人数是奇数,则最后一个学生的座位不进行交换。
-
思路点拨 : 此题可以通过 CASE WHEN 逻辑配合子查询动态计算。我们可以通过求余函数 MOD(id, 2):
-
如果 id是奇数,且不是 最后一个人,则让其 id + 1;
-
如果 id是奇数,且是 最后一个人(利用嵌套子查询获取 MAX(id) 锁定边界),则保持 id不变;
-
如果 id是偶数,则让其 id - 1。 最后将处理过的 id重新升序排序。
-
-
精美 SQL 代码:
SELECT CASE -- 如果是奇数且是最后一个人,id 保持不变 WHEN MOD(id, 2) = 1 AND id = (SELECT MAX(id) FROM seat) THEN id -- 如果是奇数且非最后一个人,id 往后移一位变成偶数 WHEN MOD(id, 2) = 1 THEN id + 1 -- 如果是偶数,id 往前移一位变成奇数 ELSE id - 1 END AS id, student FROM seat ORDER BY id ASC;
✍️ 结语
复合查询是整个 MySQL 体系中最核心的灵魂所在,涵盖了表的显/隐式内连接 、左/右外连接 、自连接 以及FROM 临时表子查询。掌握这些底层的数据检索逻辑,能够帮助我们后端及 C++ 开发者在构建高性能、低延迟的数据交互后台时,写出最优的 SQL 语句。
如果本文对你有所帮助,欢迎 👍点赞 、⭐收藏 、💬评论 三连支持!你的支持是我持续创作优质技术干货的最大动力!我们下期再见!👋