每日一言:最先掌握AI的人,将会比较晚掌握AI的人有竞争优势
什么是LLama Factory、Ollama?
LLama Factory 是一个大模型训练与微调平台
- 零代码微调:通过Web界面或命令行,轻松定制模型。
- 支持多种技术:集成了LoRA、QLoRA、DPO等前沿微调方法。
- 模型适配广:支持LLaMA、Qwen、ChatGLM等上百种主流模型。
Llama Factory 就像是一个 "模型锻造车间" ,你可以根据需求,将基础模型 "锻造成" 更锋利的专属工具。
比如:在医疗、法律等垂直领域,微调出更专业的模型
Ollama 是一个本地大模型运行与管理工具
- 一键运行模型:从下载模型到启动对话,操作非常简便。
- 提供API接口:可以方便地将模型集成到自己的应用中。
- 支持工具调用:模型可以联网搜索、调用外部工具,扩展能力。
而 Ollama 则像一个 "模型加油站" 或 "应用商店" ,让你能随时下载并启动别人造好的模型来使用。
比如:在自己电脑上运行DeepSeek,Qwen等模型、运行在 LLama Factory 微调好的模型。
安装Anconda
Anconada 用来给微调大模型提供一个干净、稳定、不冲突的运行环境、不先装它,直接跑微调代码几乎一定会报各种依赖错、版本错、环境错。
1、访问清华镜像网: https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
2 、下载最新的Anaconda安装包(Windows选.exe,Linux选.sh)、自行安装、记得修改安装路径
3、验证安装、在开始页面搜索 : Anaconda Prompt
4、打开并输入:
bash
conda --version看到版本号即为成功。
5、创建专用 Python 环境
bash
# 创建一个名为 lf 的环境(lf = LLaMA Factory),Python版本3.11
conda create -n lf python=3.11 -y
# 激活该环境
conda activate lf💡 以后每次做微调,都先运行 conda activate lf 进入这个环境。
6、确认 GPU 环境
bash
# 查看显卡驱动和CUDA版本
nvidia-smi
7、安装与 CUDA Version 对应的 Pytorch
访问 pytorch.org,选择对应配置获取安装命令、下面这是支持 12.0 / 12.1的
bash
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121验证 GPU 是否可用
bash
python -c "import torch; print(torch.cuda.is_available())"输出 True 即表示环境就绪
安装 LLama Factory
bash
# 克隆项目
git clone https://github.com/hiyouga/LLaMA-Factory.git
# 进入目录
cd LLaMA-Factory
# 安装核心依赖
pip install -e ".[torch,metrics,webui]"启动 WebUI 图形化界面
bash
llamafactory-cli webui浏览器访问 http://localhost:7860 即可打开操作界面。
准备微调数据
json
{
"instruction": "计算这些物品的总费用。",
"input": "汽车 - $3000,衣服 - $100,书 - $20。",
"output": "总费用为 $3000 + $100 + $20 = $3120。"
}这是一个 Alpaca格式 数据、可以让 AI 依据你想微调的方向生成很多数据示例,最开始可以先几百条。
进入 LLaMA-Factory/data/ 目录、创建你的数据集 : my_data.json 、将 AI 的数据放进去。
打开 dataset_info.json 文件, 将下面代码粘进去
json
"my_data": {
"file_name": "my_data.json",
"formatting": "alpaca",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
},打开 WebUI 微调
1、 填写关键参数,根据自己的GPU和显存,我是8GB,如果跟我一样可以按照我的参数填写
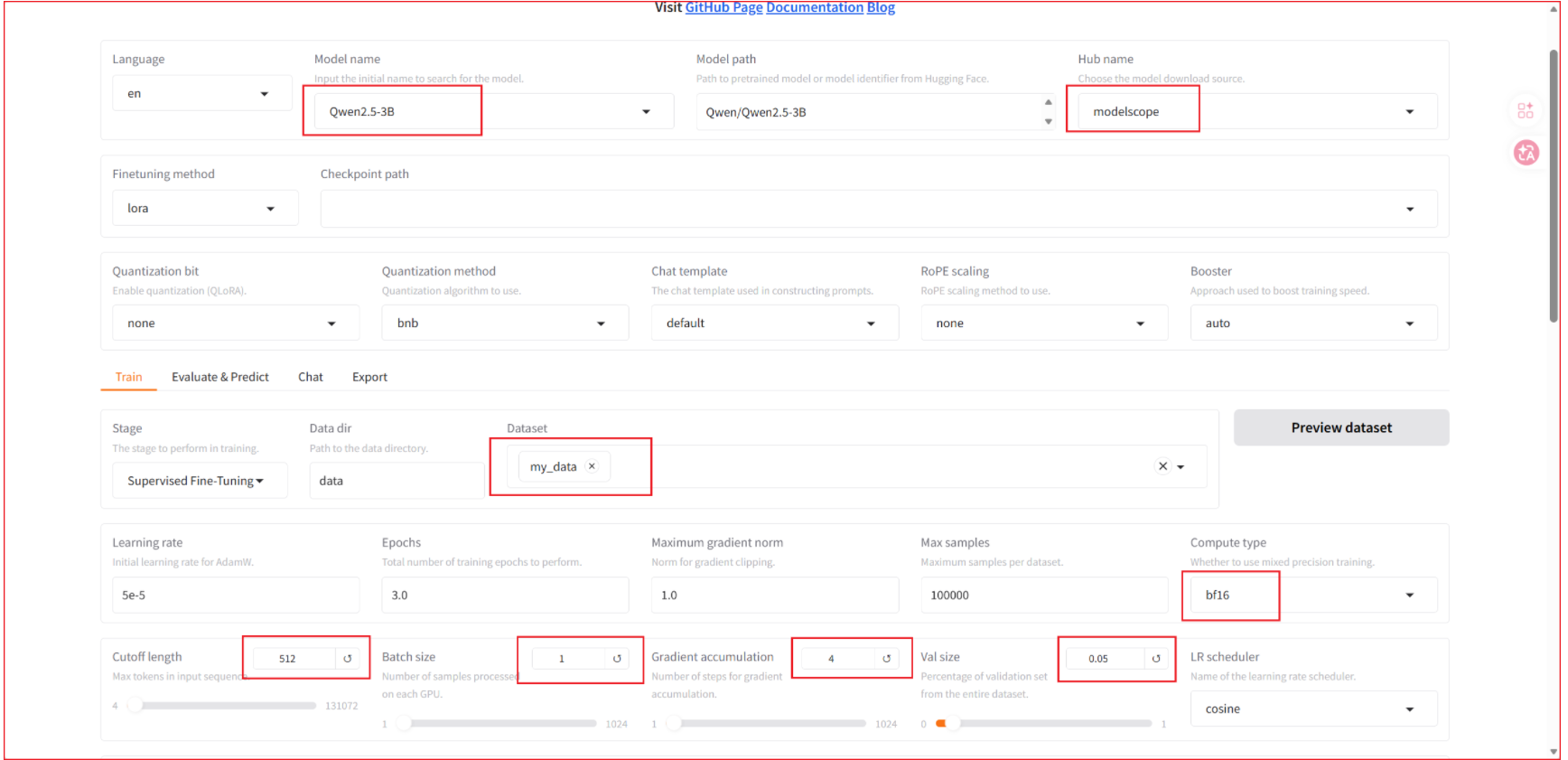
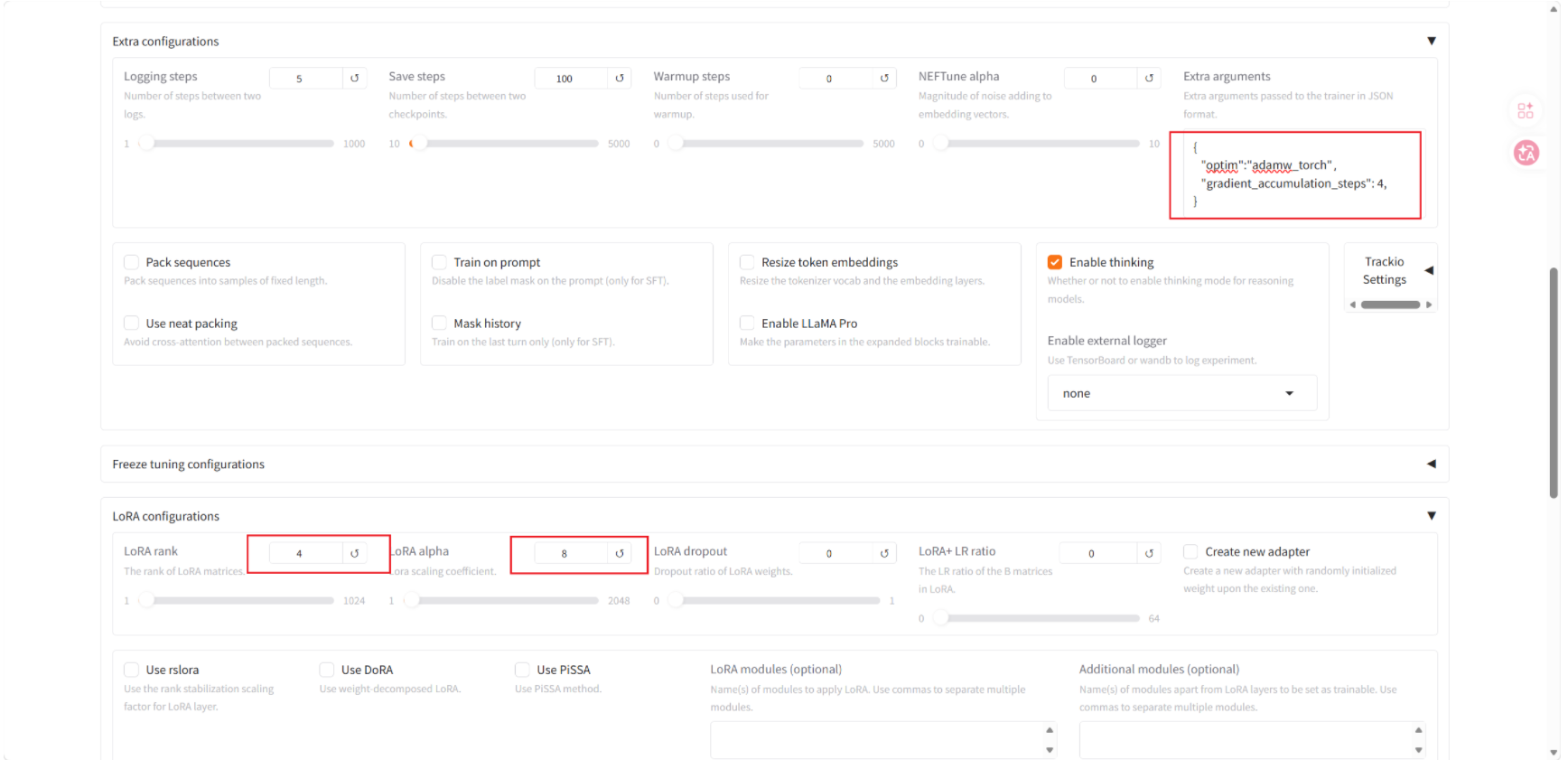
Extra arguments 中也可以换为:
json
{
"optim": "adafactor",
"preprocessing_num_workers": 4,
"gradient_checkpointing": true
}2、 配置完之后到页面最下方点击 Start 训练完图会显示,大概长这样:
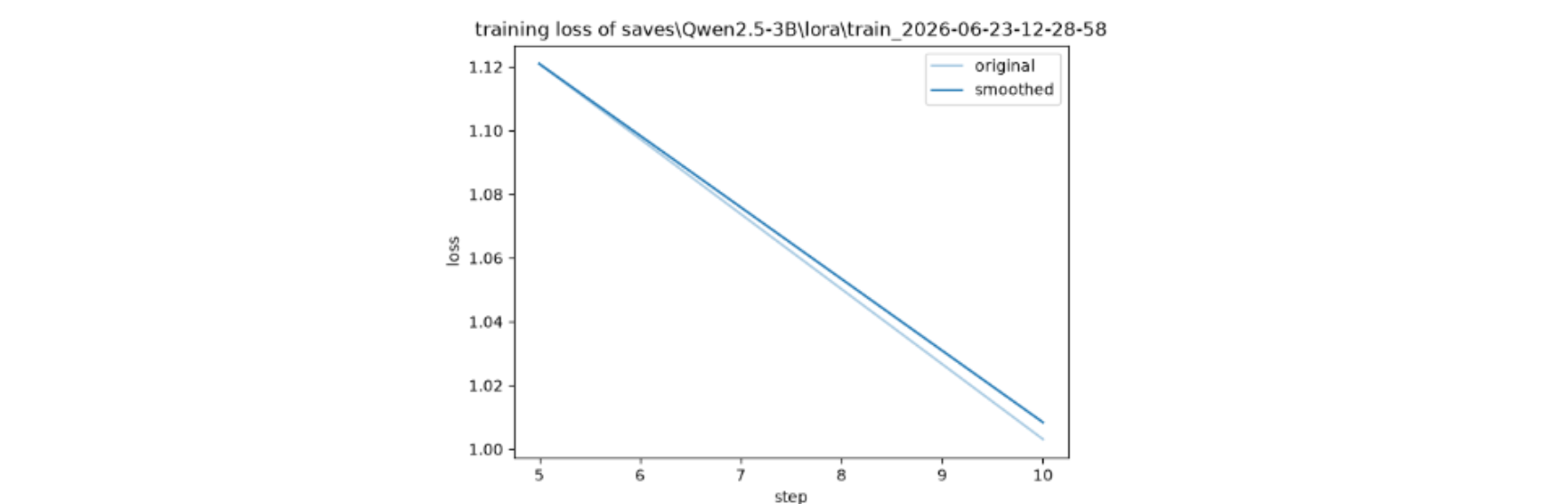
这个里面是微调时的日志,失败可以在这里找原因。
3、 接下来可以与微调过的模型进行对话,看是否达到预期:
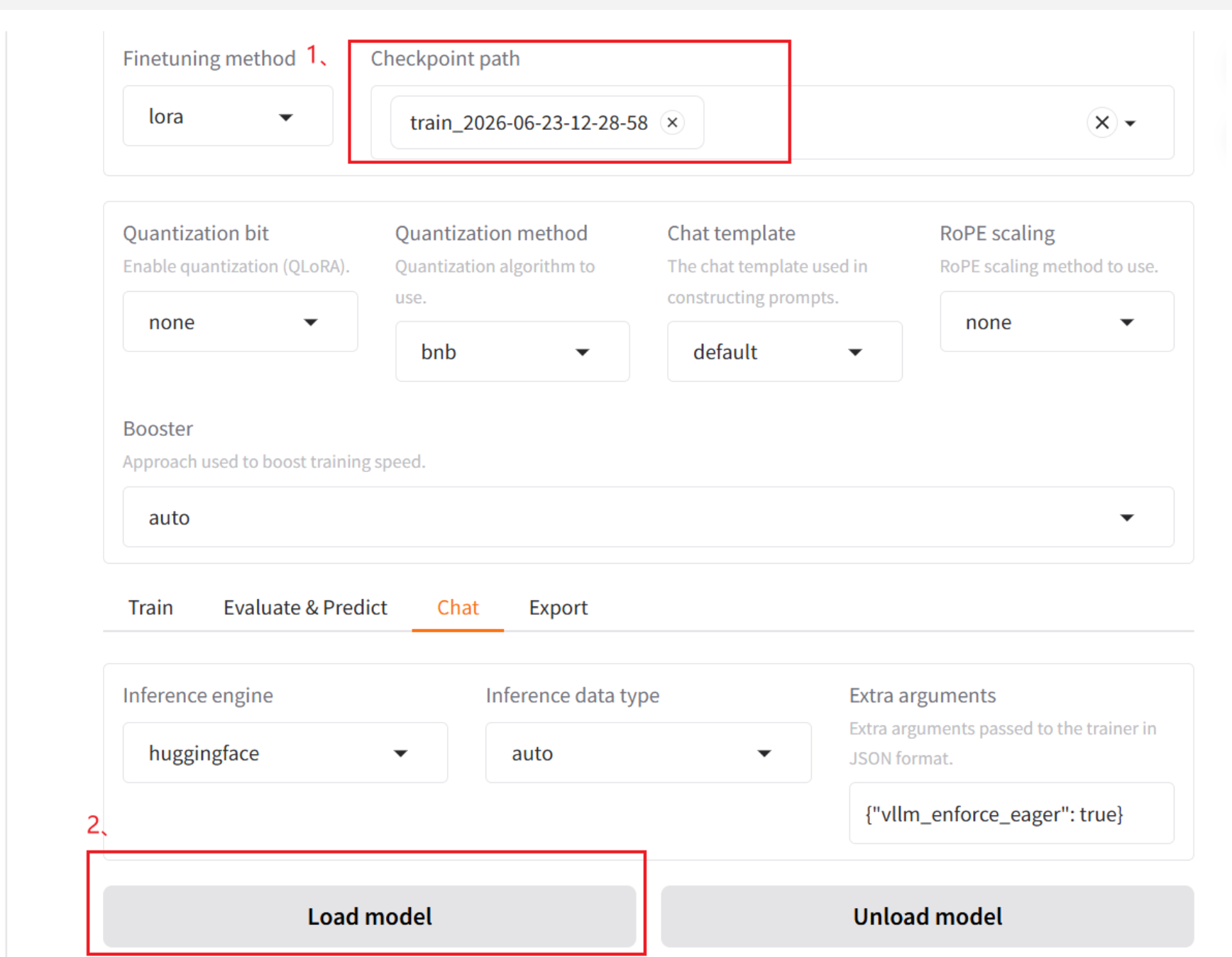
完成之后可以在页面下方直接进行对话了,此处不在给出示例页面
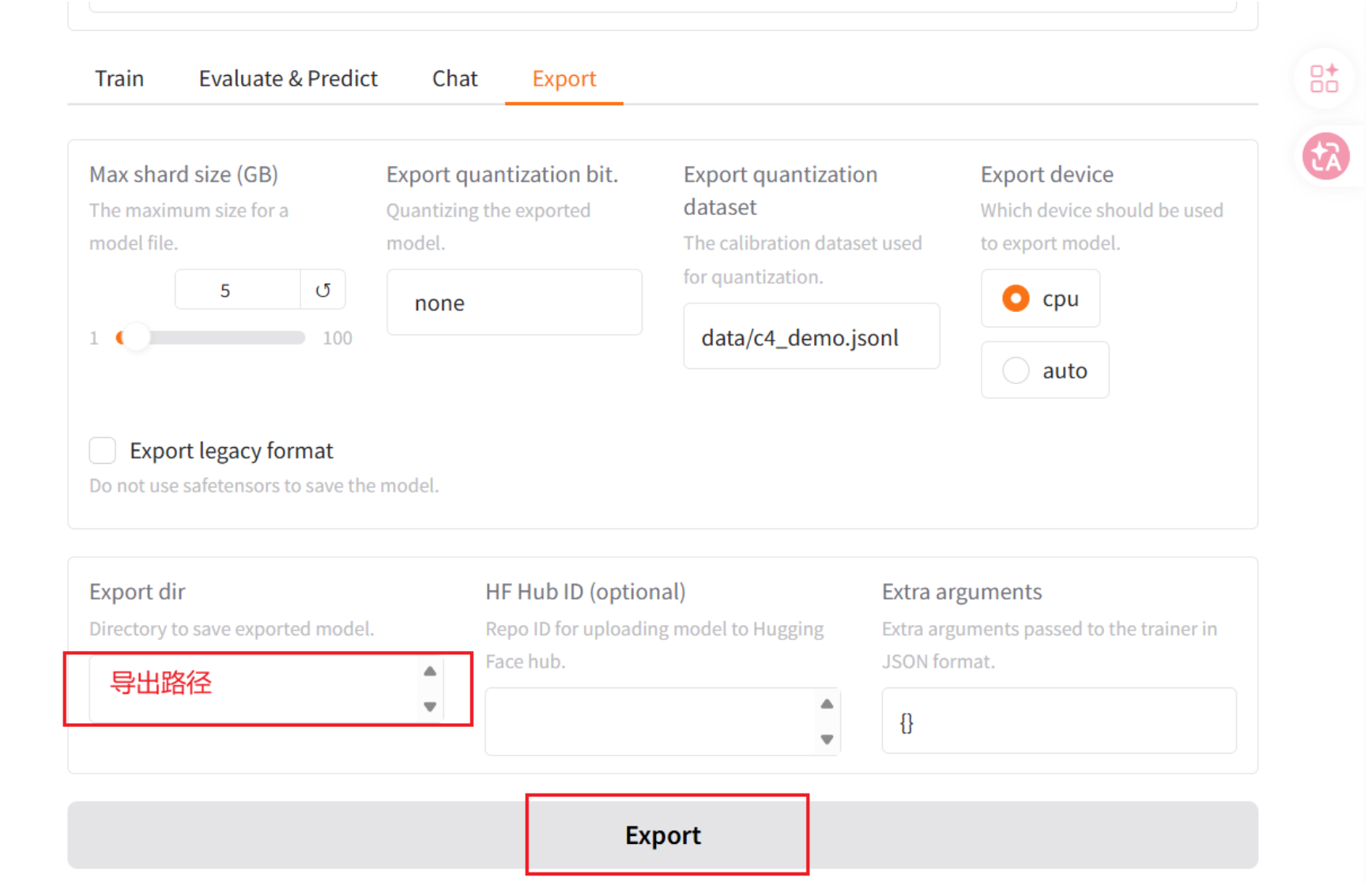
4、 导出模型
导出之后文件如下:
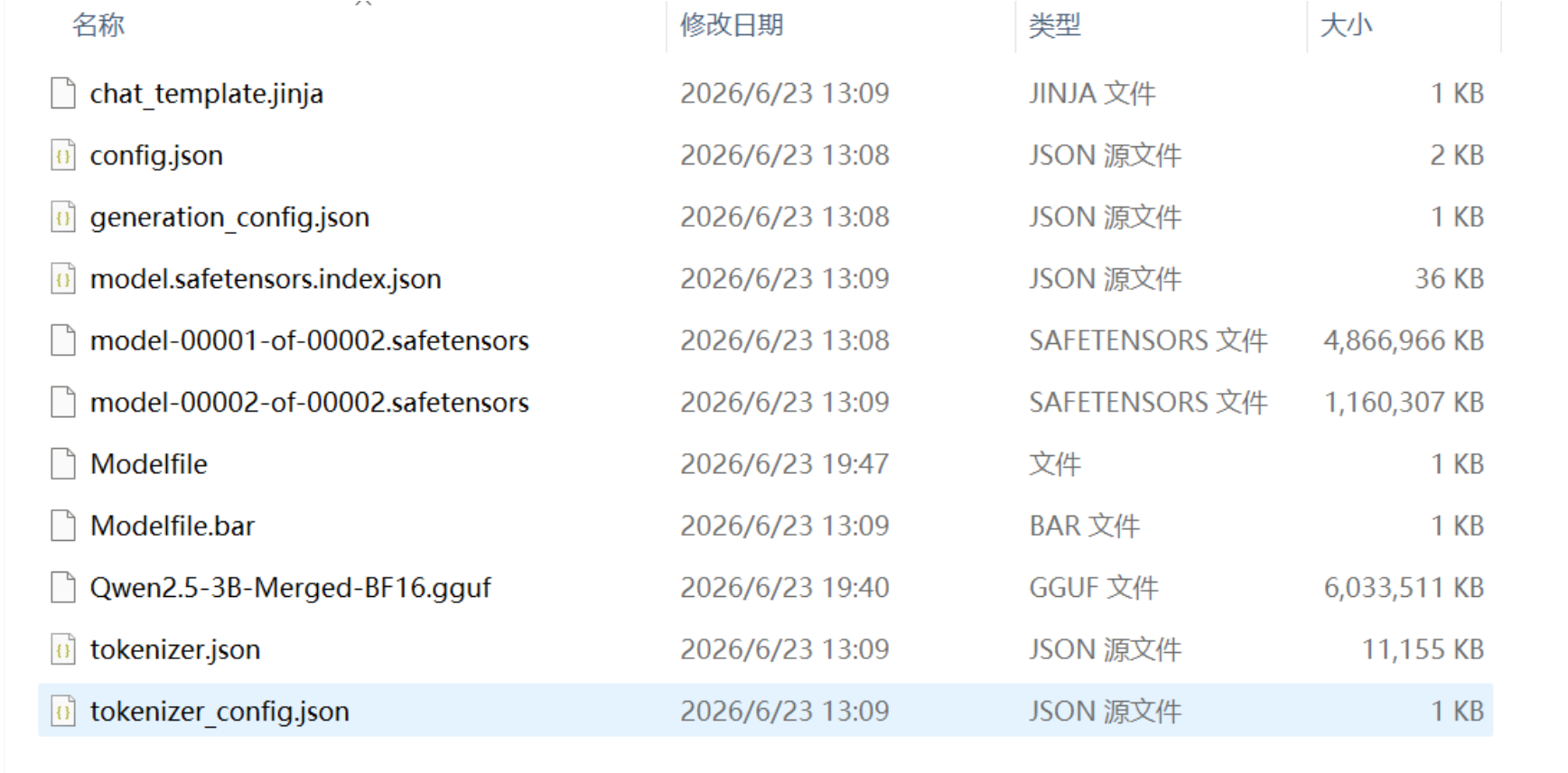
但是这种 safetensors Ollama 无法识别,需要转为 gguf 格式
Ollama部署
上面说了要先转格式,需要用到 llama.cpp ,那么提前需要安装 Cmake
1、安装 Cmake
安装完成之后,在系统变量 Path 中新建,填入 /bin 目录,例如:D:\CMake\bin

win+R
bash
cmake --version检查是否 🆗
此外,还需要安装 MinGW/Visual Studio
安装 MinGW: 参考教程
省事点就安装 Visual Studio,勾选C++编译环境
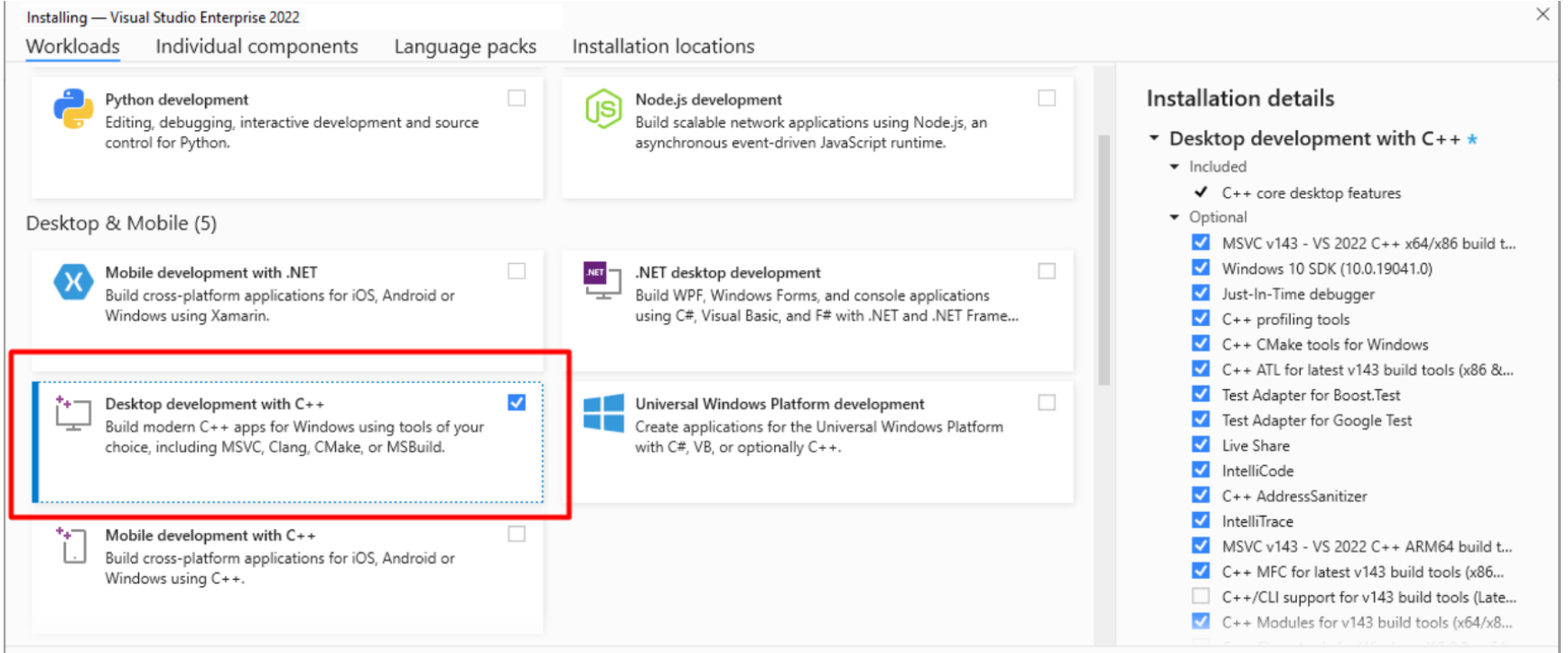
2、安装 llama.cpp
bash
git clone https://github.com/ggerganov/llama.cpp.gitcmd 进入 **llama.cpp **目录然后执行命令编译
bash
mkdir build
cd build
cmake ..
cmake --build . --config Release -j 8下载依赖
bash
pip install -r requirements.txt转换格式
bash
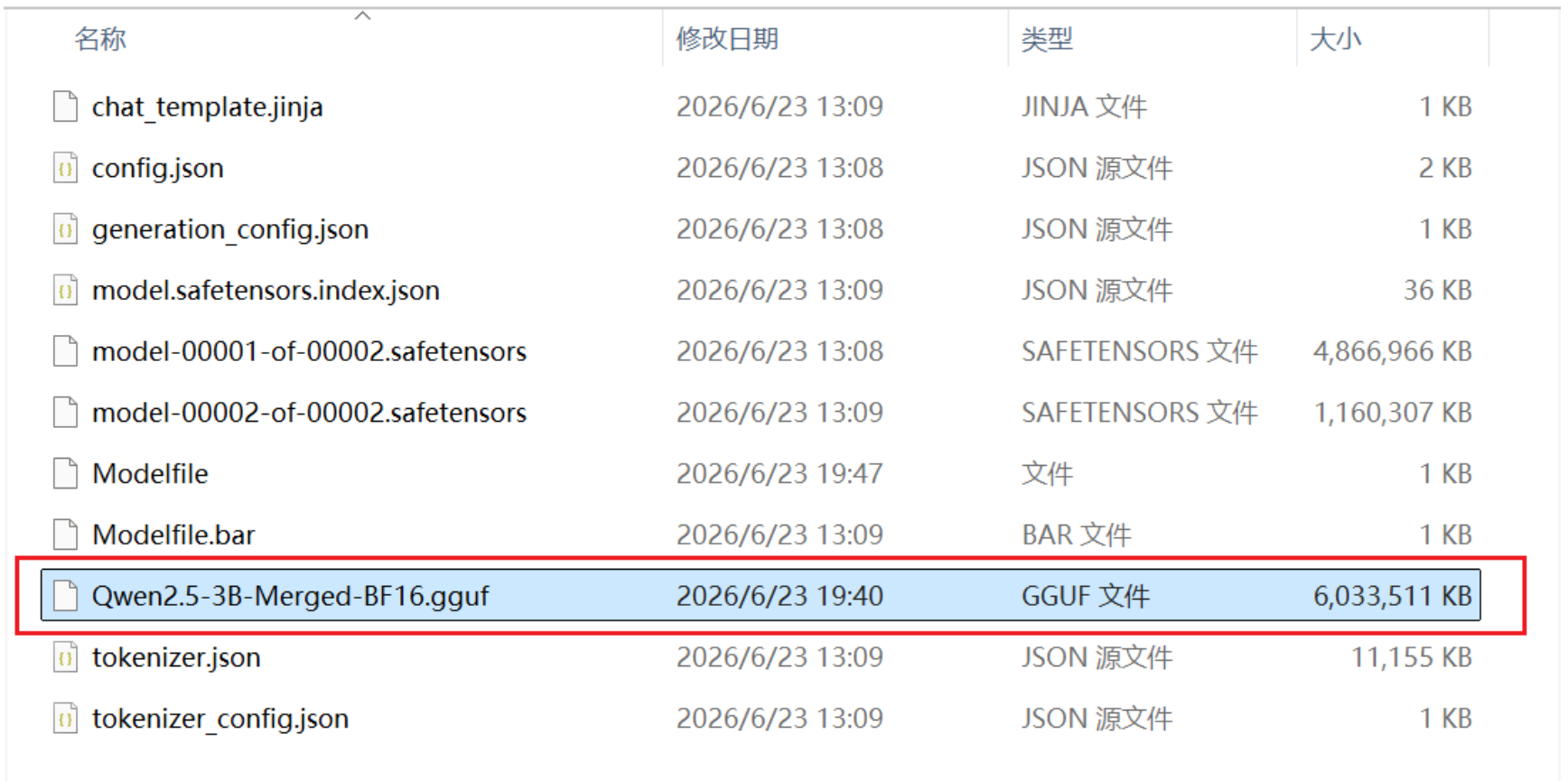
python convert_hf_to_gguf.py D:\Anconda\Model\Qwen2.5-3B-Merged(换成你的位置)
此时模型文件夹D:\Anconda\Model\Qwen2.5-3B-Merged下会生成一个Qwen2.5-3B-Merged-BF16.gguf文件
3、安装 Ollama
访问网址下载 :Download Ollama on Windows
准备 Modelfile 一般都是有的(没有自己创),将内容换为下面这段(第一行名字记得改):
json
FROM ./Qwen2.5-3B-Merged-BF16.gguf
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
SYSTEM """You are a helpful assistant. 你是一个乐于助人的助手。"""
PARAMETER temperature 0.2
PARAMETER num_keep 24
PARAMETER stop <|start_header_id|>
PARAMETER stop <|end_header_id|>
PARAMETER stop <|eot_id|>然后 cmd 执行下面命令:
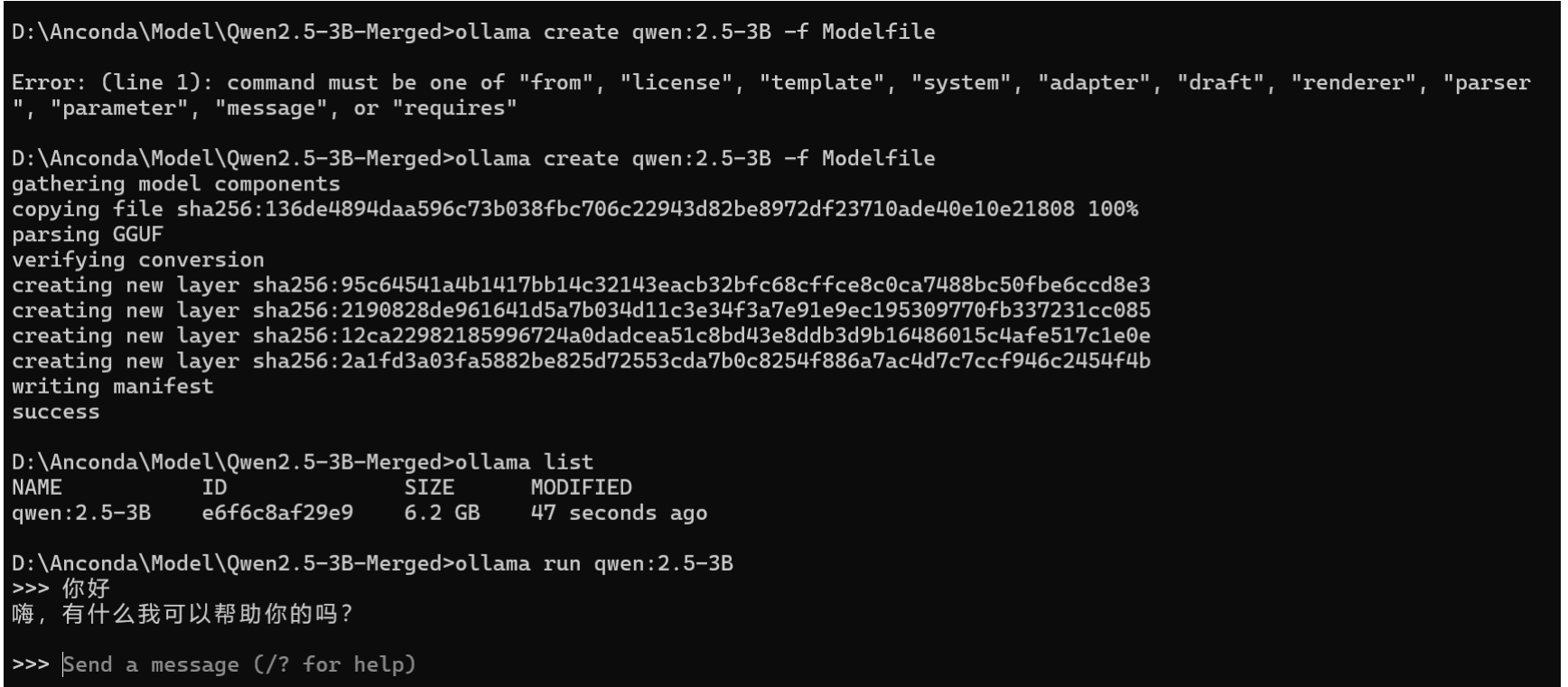
就已经部署好了你微调的模型!