一、ReFS 的诞生------为什么微软需要重新设计文件系统
1.1 从 NTFS 到 ReFS------微软文件系统设计思想的演进
自 1993 年随 Windows NT 3.1 一同发布以来,NTFS(New Technology File System)一直是 Windows 平台最核心的文件系统。三十多年来,NTFS 经历了 Windows NT、Windows 2000、Windows XP、Windows Server、Windows 10、Windows 11 等多个时代的发展,凭借日志机制(Journaling)、访问控制列表(ACL)、EFS 加密、BitLocker 集成、USN Journal 等特性,逐渐成为企业级操作系统最成熟、最稳定的文件系统之一。
然而,NTFS 的设计背景源于二十世纪九十年代。当时企业存储主要面对的是:单机服务器、几 GB 到几十 GB 的磁盘容量、少量用户共享文件以及小规模数据库应用。随着云计算、虚拟化、软件定义存储(SDS)以及 AI 工作负载的发展,Windows Server 面临的数据规模已经发生了根本变化:PB 级存储容量、百万级 VHDX 文件、超大规模 Hyper-V 集群、Azure Local 与 Storage Spaces Direct(S2D)、持续在线(Always Online)的企业业务。
这些新的应用场景使 NTFS 的部分设计逐渐暴露出局限性,因此微软决定重新设计文件系统,而不是继续在 NTFS 上进行增量扩展。ReFS(Resilient File System)的设计目标正是最大化数据可用性、提供端到端数据完整性、支持超大规模数据集,并为未来的数据中心创新奠定基础。
1.2 为什么 NTFS 不能继续升级?
第一:Metadata 结构------MFT 的单点瓶颈
NTFS 将所有文件和目录的元数据集中存储在 Master File Table(MFT)中。MFT 本质上是一个顺序表结构,虽然通过 B-Tree 索引加速了查找,但所有元数据操作最终都要经过这个唯一的中心结构。当文件数量达到百万级甚至千万级时,MFT 本身成为严重的单点瓶颈和锁竞争热点。更为关键的是,MFT 的碎片化问题随着卷的使用时间增长而不断加剧,严重影响元数据访问性能。
ReFS 彻底摒弃了 MFT 的集中式设计,转而采用基于 B+Tree 的对象化元数据架构。所有文件、目录、扩展区(Extent)都以独立的对象形式存在,通过 Object Table 统一索引,从根本上解决了元数据单点瓶颈问题。
第二:MFT------修复效率与容量限制
NTFS 的 MFT 预留区域大小固定,虽然可以动态扩展,但在超大规模卷上,MFT 自身的碎片化会导致元数据访问延迟显著增加。此外,NTFS 的文件大小上限为 256 TB,卷大小上限同样为 256 TB,这对于需要支持 PB 级数据的现代数据中心来说,成为无法逾越的硬限制。
相比之下,ReFS 支持最大单个文件和卷容量高达 35 PB(1 PB = 1024 TB),理论容量极限达到 1 Yottabyte(YB),彻底突破了 NTFS 的容量天花板。
第三:Journal------日志机制的局限性
NTFS 使用日志(Journaling)来保证文件系统元数据的一致性。日志机制在系统崩溃后可以回滚未完成的事务,但在面对复杂的数据损坏场景时,日志只能保证元数据一致性,无法检测或修复数据层面的静默损坏。更关键的是,NTFS 的日志文件大小固定,在高并发写入场景下,日志翻转频繁,可能影响整体性能。
ReFS 采用写时分配(Allocate-on-Write,亦称 Copy-on-Write)机制替代传统的日志更新方式。元数据的更新不再直接覆盖旧数据,而是在新位置创建完整副本后再原子化地更新指针。这种方式天然保证了元数据的一致性,无需维护复杂的日志结构,同时也从根源上消除了"撕裂写"(Torn Write)问题。
第四:CHKDSK------离线修复的业务中断
NTFS 最令 IT 管理员头疼的问题之一就是 CHKDSK。当文件系统检测到不一致或损坏时,需要将卷置于离线状态运行 CHKDSK 进行修复。对于 TB 级甚至 PB 级卷,CHKDSK 的扫描和修复时间可能长达数十小时甚至数天,对于 7×24 小时运行的企业业务来说,这意味着不可接受的停机时间。
ReFS 的核心设计理念之一就是"永不离线"(never offline)。ReFS 能够在线检测、隔离并修复大多数文件系统损坏,无需中断业务运行。微软官方明确表示,ReFS 的目标是彻底消除对离线 CHKDSK 的依赖。
第五:Storage Spaces------缺乏原生集成
NTFS 在设计时并未考虑与软件定义存储的深度集成。虽然 NTFS 可以运行在 Storage Spaces 之上,但两者之间的协作仅限于基本的 I/O 通路。当 Storage Spaces 提供的数据副本出现校验不一致时,NTFS 无法自动识别并利用冗余副本进行修复。
ReFS 从设计之初就与 Storage Spaces 深度耦合。两者被设计为完整存储系统的两个互补组件:Storage Spaces 提供数据冗余和性能优化,ReFS 提供数据完整性检测和元数据管理。当 ReFS 检测到数据损坏时,会通过 Storage Spaces 接口读取所有可用副本,基于校验和选择正确的数据,并自动修复损坏的副本。这一过程对上层应用完全透明。
二、 ReFS 总体架构设计思想
2.1 微软官方设计目标
微软为 ReFS 设定了四个核心设计目标,它们构成了 ReFS 架构设计的指导原则:
Availability(可用性)------不仅仅是"不停机",而是包括完整的在线修复能力:
- Online Repair:在线自动修复检测到的损坏,无需卷离线
- Metadata Self-Healing:元数据自愈,当校验和不匹配时自动恢复
- Automatic Recovery:即使遇到不可纠正的损坏,ReFS 也能通过"数据打捞"(Salvaging)将损坏数据从命名空间中移除,同时保持卷的在线状态
- Integrity Scanner(Scrubber):后台定期扫描整个卷,主动检测和修复潜在的静默损坏
Integrity(完整性)------从底层保障数据一致性:
- 所有元数据强制使用 64 位校验和
- 可选的文件数据校验和(Integrity Streams)
- 写时分配确保原子性更新
- 与 Storage Spaces 协作实现端到端数据完整性
Scalability(可扩展性)------支持超大规模数据集:
- 最大卷/文件容量:35 PB
- 通过 B+Tree 结构的原生支持,高效管理百万级目录和千万级文件
- 存储池和虚拟化使得文件系统可建立并易于管理
Performance(性能)------针对现代硬件和工作负载优化:
- 块克隆(Block Cloning)加速 VHDX 等大文件复制
- 稀疏 VDL 加速虚拟磁盘创建
- 镜像加速奇偶校验(Mirror-Accelerated Parity)平衡性能与容量效率
- 针对 NVMe 和 SSD 的 I/O 路径优化
2.2 ReFS 总体架构图
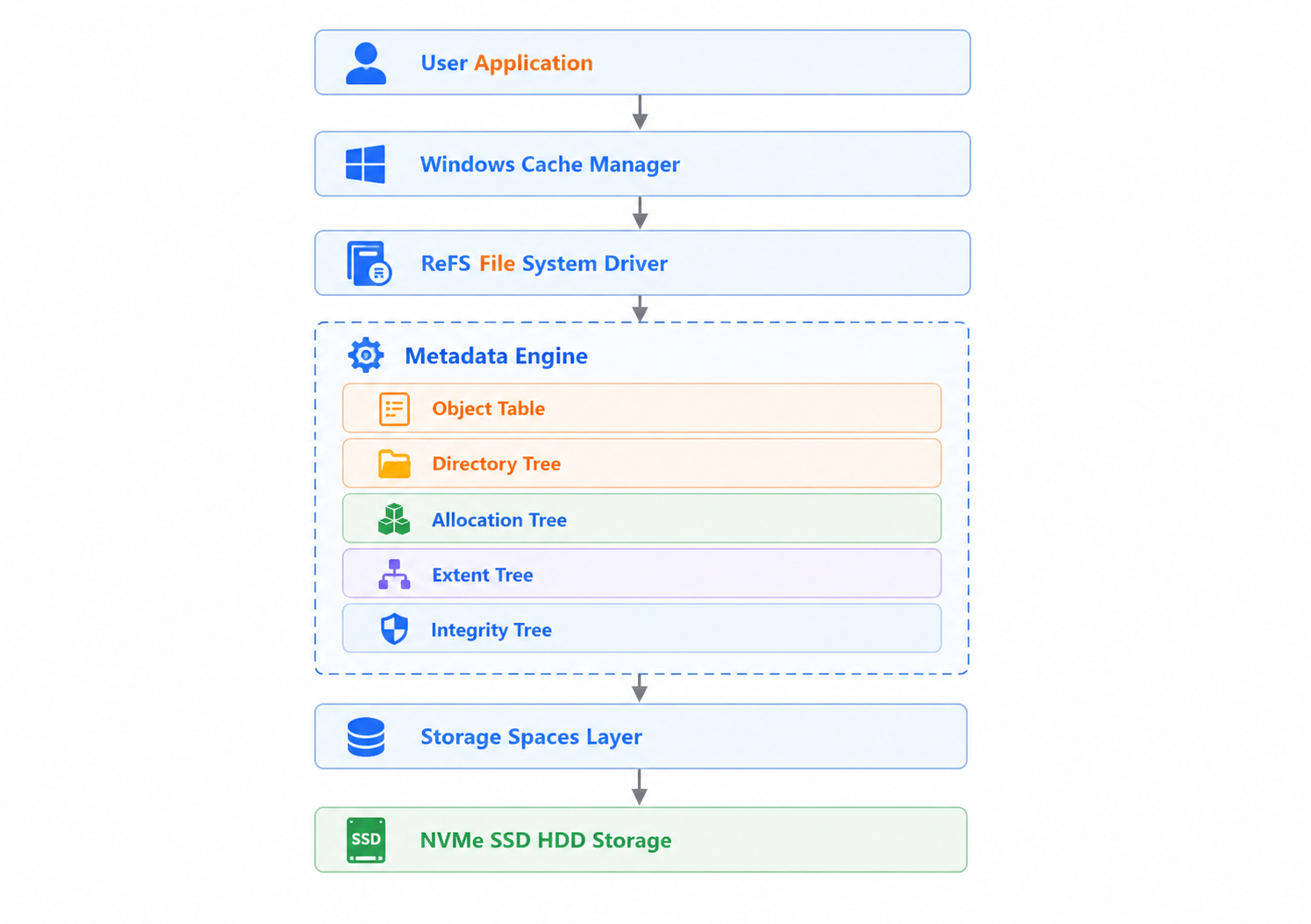
这张图是理解 ReFS 架构的核心。与传统文件系统不同,ReFS 将元数据管理抽象为一个独立的 Metadata Engine,所有文件系统结构(对象、目录、分配信息、扩展区、完整性信息)都以 B+Tree 形式组织在这个引擎中。这种分层设计使得 ReFS 能够灵活地扩展功能,同时保持底层存储的抽象一致性。
三、 ReFS 元数据架构
3.1 从 MFT 到 Object Table------元数据管理的范式转变
NTFS 使用 MFT 集中管理所有文件和目录的元数据。每条 MFT 记录(Record)对应一个文件或目录,包含文件属性、时间戳、数据位置等信息。MFT 本质上是一个扁平的顺序表,虽然通过 B-Tree 索引加速查找,但所有元数据操作最终都要经过这个中心表,成为单点瓶颈。
ReFS 彻底告别了 MFT 的设计,引入对象化元数据管理 。在 ReFS 中,所有文件系统元素------包括文件、目录、扩展区、元数据属性------都被抽象为独立的对象,每个对象具有唯一的 Object ID 。这些对象通过 Object Table 统一索引和管理。
Object Table 本身也是一个 B+Tree 结构,以 Object ID 为键进行索引。这种设计的优势在于:
- 无单点瓶颈:任何对象的访问都通过 B+Tree 的路径查找完成,不存在类似 MFT 的中心热点
- 自然支持超大规模:B+Tree 的平衡多叉树结构使得即使存在数十亿对象,查找路径的深度也仅需几个层级
- 对象化隔离:每个对象的损坏不会影响其他对象,实现了细粒度的故障隔离
3.2 为什么全部采用 B+Tree?
ReFS 使用 B+Tree 作为唯一的磁盘上结构来表示所有元数据信息。这不是巧合,而是深思熟虑的设计决策:
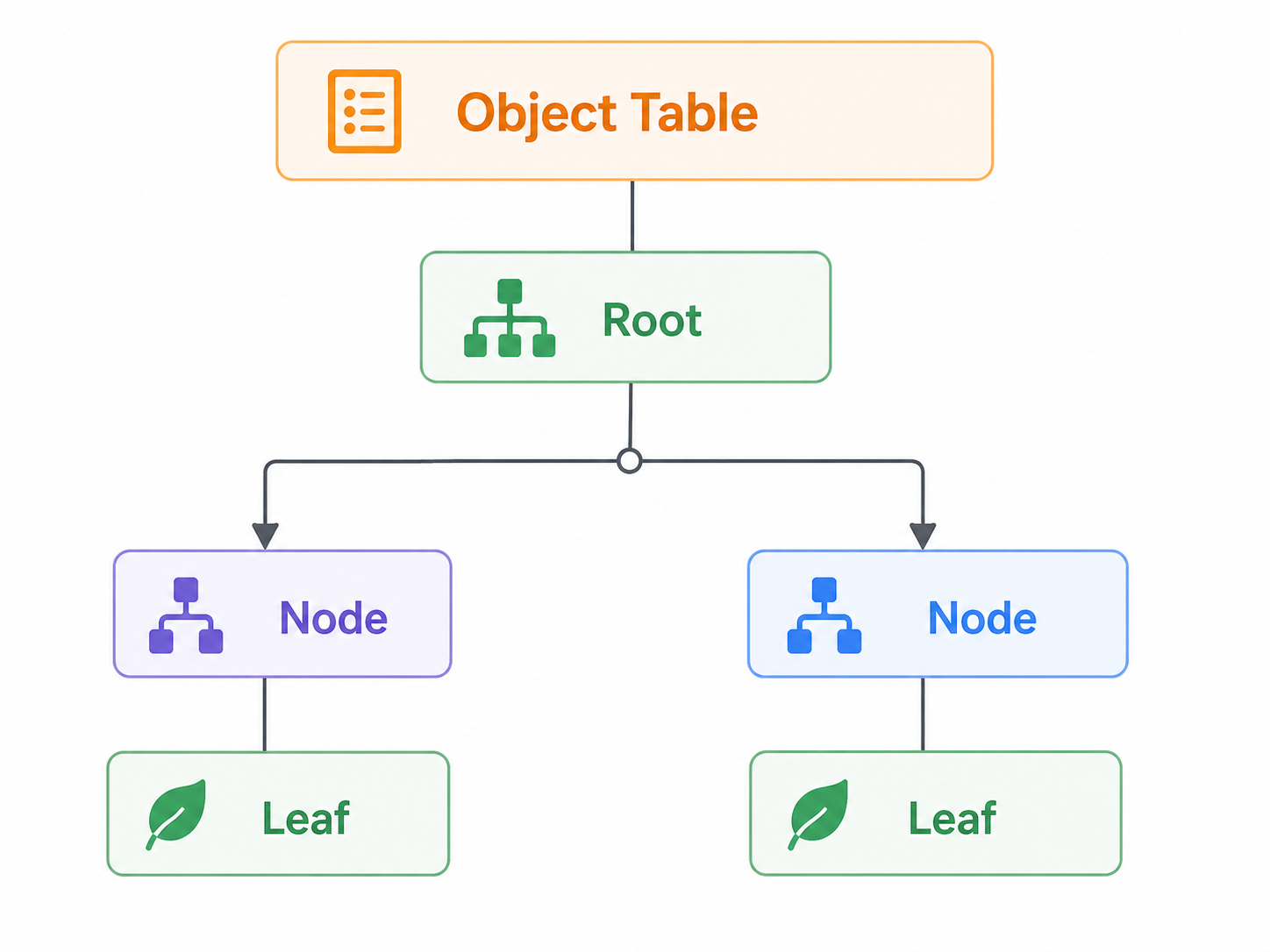
在 ReFS 中,以下所有结构都通过 B+Tree 实现:
- Object Table:全局对象索引,以 Object ID 为键
- Directory Tree:目录项以 Table 表示,每个目录对应一个 B+Tree
- File Metadata:文件属性存储在父目录的行中
- Extent Tree:文件数据的物理位置映射,包含偏移与校验和信息
- Allocation Tree:空闲空间管理,以范围范围(Extent Range)表表示
- Integrity Tree:校验和信息的存储结构
B+Tree 天然适合超大规模场景的原因:
- 对数级查找复杂度:即使卷中有数百万个目录和数千万个文件,查找任意对象的路径深度也仅需 4-5 次 I/O
- 范围查询高效:B+Tree 的叶子节点使用链表连接,支持高效的范围扫描(如枚举目录内容)
- 写优化:B+Tree 的节点分裂和合并机制与写时分配完美配合
- 空间效率:树结构可以自适应地从少量键嵌入父节点,到大规模分层组织,避免 NTFS 中大目录的性能退化
这种"一切皆树"的设计使 ReFS 能够轻松应对 NTFS 无法处理的超大规模数据场景。
四、Allocate-on-Write 机制
4.1 从 Overwrite 到 Allocate-on-Write------写操作的根本性变革
NTFS 在处理元数据更新时采用**覆盖写(Overwrite)**方式:当需要更新元数据时,直接在原始位置写入新数据。这种方法虽然简单直接,但存在一个致命弱点------如果在写入过程中发生断电或系统崩溃,旧数据已被覆盖、新数据尚未写完,文件系统就会处于不一致状态。NTFS 依赖日志(Journal)来记录事务,以便在崩溃后回滚或重做,但日志机制本身也有开销和局限性。
ReFS 采用 Allocate-on-Write(写时分配,亦称 Copy-on-Write) 机制:
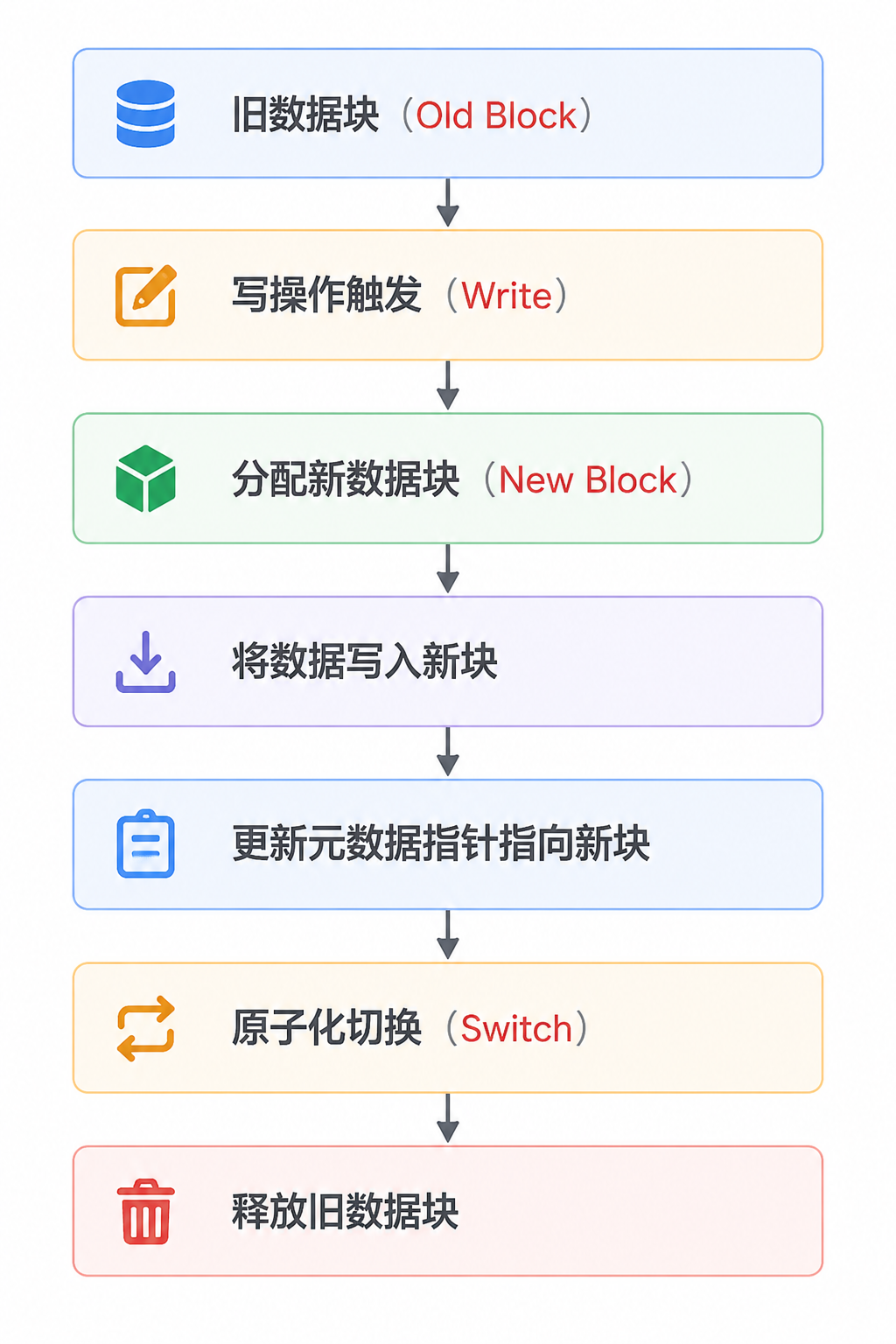
4.2 为什么 Allocate-on-Write 更可靠?
- 永不覆盖原始数据:写入操作总是在新位置完成,原始数据在指针切换前保持不变
- 元数据永远一致:无论何时崩溃,文件系统都只有"旧指针→旧数据"和"新指针→新数据"两种状态,不存在中间不一致状态
- 原子性天然保证:指针更新在硬件层面可以通过原子写入实现(如 64 位指针的原子写),无需日志回滚
- 写时分配 ≠ 写时复制(CoW):严格来说,ReFS 的元数据操作采用写时分配;用户数据流的完整性流(Integrity Streams)则使用写时复制。微软文档中详细区分了这两种场景
Allocate-on-Write 与 ZFS 的 COW(Copy-on-Write)机制、Apple APFS 的写时复制、Linux Btrfs 的 COW 机制在思想上一脉相承。这些现代文件系统都放弃了传统的覆盖写+日志模式,转而采用写时分配来从根本上避免撕裂写(Torn Write)和文件系统不一致问题。
五、 Integrity Stream
5.1 元数据校验和:默认安全
ReFS 对所有元数据强制使用 64 位校验和。校验和的计算粒度在 B+Tree 页面级别,且校验和与元数据页面本身分开存储,以确保校验和的独立性。
这意味着:
- 每次读取元数据时,ReFS 都会验证校验和
- 如果校验和不匹配,ReFS 能够立即检测到损坏
- 配合 Storage Spaces 的冗余副本,可以自动进行修复
与 NTFS 的根本区别:NTFS 只在校验元数据的日志,依赖磁盘硬件的 CRC 校验。磁盘硬件只能检测介质层面的错误,无法检测由软件 bug、内存错误、固件错误等导致的数据损坏(静默损坏)。ReFS 的完整性流从文件系统层面提供了端到端的数据保护。
5.2 数据校验和:可选保护
除了元数据校验和,ReFS 还提供可选的文件数据校验和 功能,称为完整性流(Integrity Streams)。当对某个文件或卷启用完整性流时:
- 每次写入文件数据时,ReFS 会计算其校验和并存储
- 每次读取文件数据时,ReFS 会重新计算校验和并与存储值比对
- 如果校验和不匹配,检测到静默损坏
需要注意的是,完整性流仅在配合镜像或奇偶校验空间时才会默认启用。对于单个 Basic 磁盘,完整性流默认为关闭状态,因为 ReFS 在没有冗余副本的情况下无法自动修复数据损坏。
5.3 静默损坏(Silent Corruption)------传统 RAID 发现不了的危险
静默损坏是指数据在磁盘上悄无声息地发生错误,但磁盘控制器和 RAID 控制器未能检测到。常见的静默损坏场景包括:
- 谬写(Misdirected Write):数据被写入错误的位置
- 失写(Lost Write):写入操作看似成功,但数据并未实际落盘
- 位衰减(Bit Rot):存储介质随时间推移发生的微小数据退化
传统 RAID 控制器只能检测到完整的磁盘故障(全盘损坏),对于发生在正常磁盘上的静默损坏,RAID 控制器无法感知,更无法修复。RAID 5/6 中的"写入漏洞"(Write Hole)更是典型例子:在写入过程中发生断电,校验和数据不一致,但 RAID 控制器不会主动校验和修复,导致损坏的数据长期潜伏。
ReFS 的 Integrity Stream 正是针对这些问题设计的。通过元数据和数据的校验和,ReFS 能够可靠地检测各种静默损坏,并在有冗余副本时自动修复。