Agent 快做完了,我却开始怀疑自己
最近在开发一个 Agent,设计阶段就考虑过语音能力:用户说话 → 识别成文字 → 丢给大模型 → 再把模型的文字回复读出来。
做技术选型的时候,基于我已知的前端语音实现技术,当时的判断很干脆:Web 端语音轮转太折腾,直接用 APP 原生,省事。 因为第一代 Flash 插件早成历史,后来 getUserMedia 要拼讯飞 WebSocket,太费劲了。
桌面端采音、调 API 都顺手,功能做到差不多,马上要收尾了,突然就愣了一下:
难道以后但凡涉及语音采集播报,都得用 APP?那也太局限了吧。
用户打开个网页就想用语音助手,难道非得先下载安装包?
带着这个疑问,我又去搜了一圈 ,看看有没有我漏掉的、新的东西?
还真有。2025 年 8 月 Chrome 139 为 Web Speech API 引入了 On-device Speech Recognition 能力------processLocally、SpeechRecognition.available()、install(),浏览器终于能在设备本地完成语音转文字(STT),可离线、音频不出设备。也许我的 Agent 也不必绑死在 APP 原生 上。
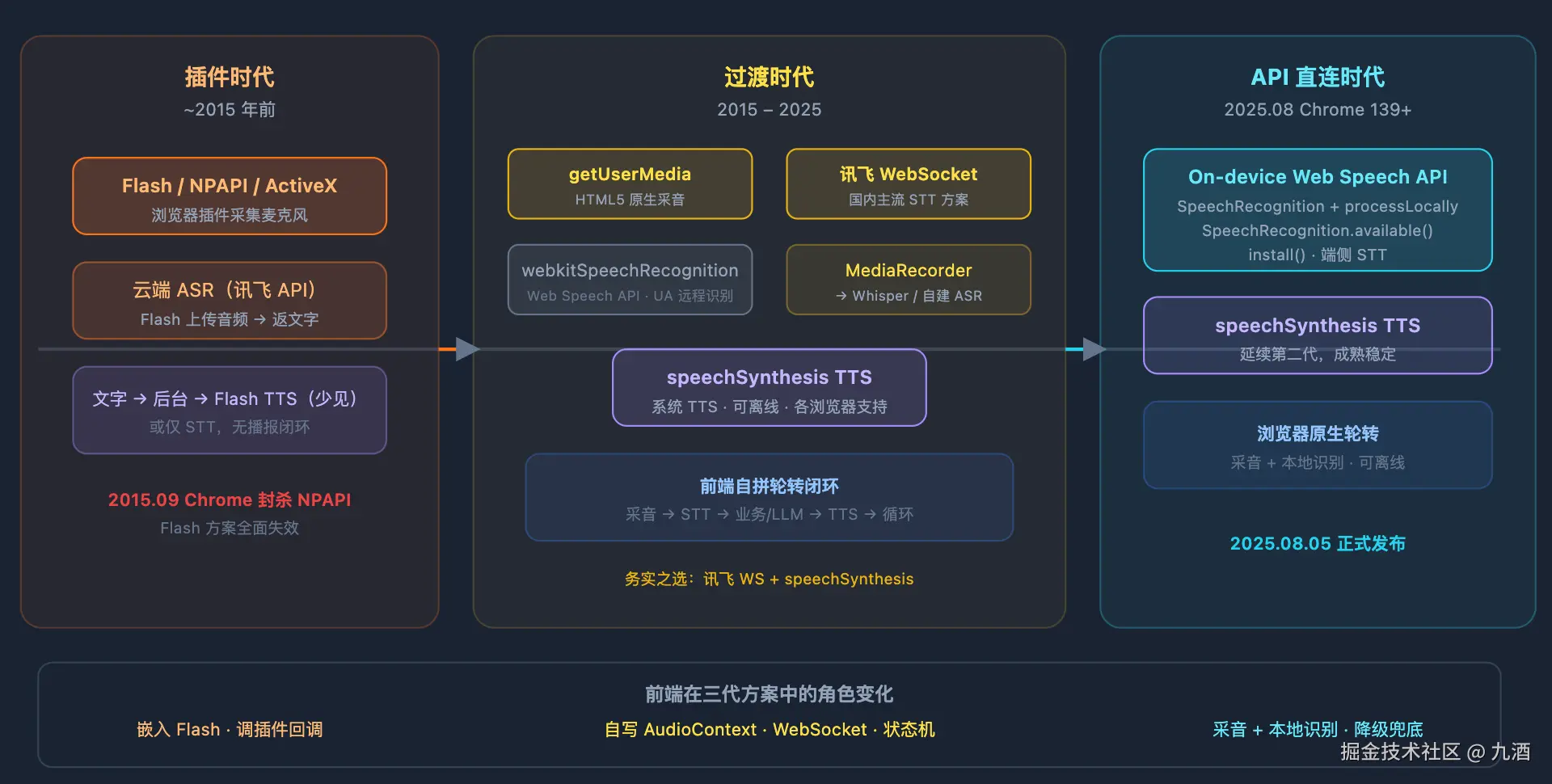
一、方案总览
| 阶段 | 年代 | 前端怎么采音 | 怎么识别 | 怎么播报 | 痛点 |
|---|---|---|---|---|---|
| 插件时代 | ~2015 前 | Flash / NPAPI / ActiveX | 云端 API(讯飞等) | Flash 或暂无 | 装插件、安全性差、IE 兼容地狱 |
| 过渡时代 | 2015--2025 | getUserMedia / WebSocket |
云端 ASR SDK / webkitSpeechRecognition |
speechSynthesis |
国内云端受限、方案碎片化 |
| API 时代 | 2025.08+ | 浏览器原生采音(同过渡时代) | 端侧识别 processLocally |
speechSynthesis |
需 Chrome 139+、语言包 |
浏览器语音其实是两条线在走------采音能力 (Flash →
getUserMedia→MediaRecorder)和识别能力 (无 →webkitSpeechRecognition→SpeechRecognition→ On-device Speech Recognition)。
二、插件时代------Flash 扛下了所有
2015 年之前,浏览器原生根本不给麦克风权限。前端要实现"说话变文字",标准答案是:塞一个 Flash。
当年很火的 voicewo jQuery 插件,架构一目了然:
Flash 采集麦克风 → 上传云端(讯飞 API)→ JS 拿到文字 → 填入表单
html
<!-- 2012 年典型写法:页面上嵌一个 .swf -->
<div id="voicewo-container">
<object type="application/x-shockwave-flash" data="voicewo.swf" width="120" height="40">
<param name="movie" value="voicewo.swf" />
<param name="allowscriptaccess" value="always" />
</object>
</div>
<script>
// Flash 通过 ExternalInterface 回调 JS
function onVoiceResult(text) {
document.getElementById('comment').value = text;
}
</script>那时候做语音轮转,链路大概是:
css
用户点 Flash 按钮 → Flash 录音 → 讯飞云端 STT → 文字进 input
→ AJAX 问后台 → 后台返文字 → 再调 Flash/第三方文字播报(TTS)(如果有的话)前端的真实体验:
- 要用户装 Flash,还要在控制面板里授权麦克风
- IE 走 ActiveX,Chrome/Firefox 走 NPAPI,一套代码三套兼容
- Flash 编译
.swf、绑域名防盗用appid,调试成本极高 - 但没办法------这是当时唯一能在网页里采到音的方案
三、Chrome 封杀插件,前端被迫重构
2013 年 Google 宣布逐步废弃 NPAPI;2015 年 9 月 Chrome 45 彻底移除 NPAPI 支持。Firefox、Opera 跟进。Adobe Flash 也在 2020 年寿终正寝。
对前端来说,这意味着:
所有基于 Flash/NPAPI 的语音方案,一夜之间全废。
当时业内几种典型应对:
策略 A:老系统不改造,继续押 IE 生态
当时在「请使用 IE 浏览器访问本系统」的提示在企业内网上非常普遍(银行、政务、老 OA......),往往整站绑 ActiveX、UKey、Flash 控件,语音只是其中一个模块。插件时代语音若嵌在 Flash 里,Chrome 封杀 NPAPI 之后,这类系统常见的应对不是单独重写 STT,而是整站继续跑 IE 11。
策略 B:getUserMedia + WebSocket 流式 ASR
插件死了,HTML5 的 navigator.mediaDevices.getUserMedia 终于能稳定采音了。前端自己录,自己通过 WebSocket 推给云端识别------讯飞、阿里云、Azure 都提供了这类 SDK。
javascript
// 2016 年前后主流过渡方案
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
const audioContext = new AudioContext();
const source = audioContext.createMediaStreamSource(stream);
const processor = audioContext.createScriptProcessor(4096, 1, 1);
processor.onaudioprocess = (e) => {
const pcm = e.inputBuffer.getChannelData(0);
iatWebSocket.send(JSON.stringify({ audio: toBase64(pcm) }));
};
iatWebSocket.onmessage = (msg) => {
const { text, isFinal } = JSON.parse(msg.data);
if (isFinal) handleUserText(text); // 拿到文字,进入业务逻辑
};轮转链路:
sql
getUserMedia 采音 → WebSocket 推流 → 讯飞 STT 返文字
→ fetch 调后台/大模型 → speechSynthesis 播报优点:国内可用、识别率可控、不依赖 Google。
缺点:前端代码量大,要处理音频编码、断线重连、鉴权签名,本质上是在浏览器里重写半个 Native SDK。
虽然当时有了实验性的 Web Speech API:webkitSpeechRecognition ,但除了STT需要依赖 chrome 云端(国内不可用)之外,由于是实验性的 api,兼容性也堪忧,各大厂商实现也没有统一的标准。
虽然 STT 还是很复杂,但 TTS 却是先稳了。speechSynthesis 不依赖插件,2014 年起 Firefox、Safari 陆续支持,调用系统 TTS 引擎,也可以离线:
javascript
function speak(text) {
const u = new SpeechSynthesisUtterance(text);
u.lang = 'zh-CN';
speechSynthesis.speak(u);
}于是过渡时代的语音轮转,常见组合是:
| 组合 | STT | TTS | 国内可用性 |
|---|---|---|---|
| 偷懒型 | webkitSpeechRecognition | speechSynthesis | 国内网络环境下通常难以作为正式生产方案 |
| 务实型 | 讯飞 WebSocket | speechSynthesis | ✅ 主流 |
| 极客型 | MediaRecorder → 自建 Whisper | speechSynthesis | ✅ 成本高 |
四、过渡时代的轮转状态机(前端必备)
不管 STT 怎么采的,业务层的状态机长这样
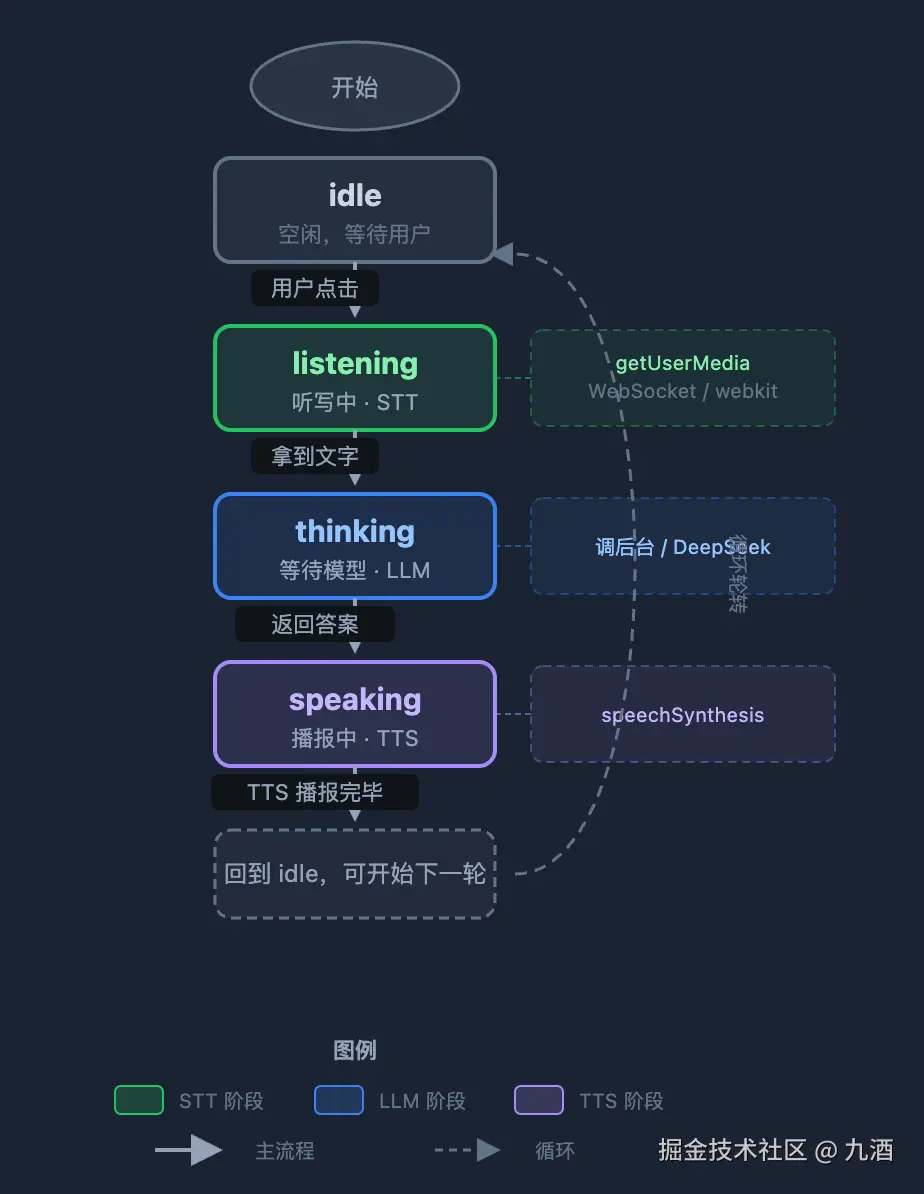
三个前端血泪细节:
- TTS 播报时不要开麦------回声录入,识别出自己的播报声
speechSynthesis.cancel()切轮次前必调 ------不然上一条没播完就叠音- WebSocket STT 要处理
onaudioprocess和页面切后台------visibilitychange时暂停推流,不然白烧钱
javascript
// 过渡时代封装示例(讯飞 STT + 原生 TTS)
class VoiceRotator {
constructor({ onText, onSpeakEnd }) {
this.onText = onText;
this.onSpeakEnd = onSpeakEnd;
this.status = 'idle';
}
async listen() {
if (this.status === 'speaking') return; // 播报中禁止采音
this.status = 'listening';
await this.iat.start(); // 讯飞 WebSocket 实例
}
async speak(text) {
this.status = 'speaking';
this.iat.stop();
return new Promise(resolve => {
const u = new SpeechSynthesisUtterance(text);
u.onend = () => { this.status = 'idle'; this.onSpeakEnd?.(); resolve(); };
speechSynthesis.speak(u);
});
}
onIatResult(text, isFinal) {
if (isFinal && this.status === 'listening') {
this.status = 'thinking';
this.onText(text);
}
}
}五、2025 年 8 月,浏览器开始支持本地语音识别
过渡时代折腾了快十年,在浏览器上,可靠的 STT 依旧需要接云 ASR。
25年8月 新增的不是 SpeechRecognition 这个 API,而是为 Web Speech API 引入了 On-device Web Speech API 能力,统一了规范。规范里的 SpeechRecognition 早就存在;Chromium 以前通过 webkitSpeechRecognition 暴露,默认走Chrome云端识别;139 之后,同一套接口可以使用 processLocally = true,在设备本地完成STT。
javascript
// 1. 查语言包
const status = await SpeechRecognition.available({
langs: ['zh-CN'],
processLocally: true
});
// 2. 没装就装
if (status === 'downloadable') {
await SpeechRecognition.install({ langs: ['zh-CN'], processLocally: true });
}
// 3. 端侧识别------音频不出设备(SR 兼容 webkit 前缀)
const SR = window.SpeechRecognition || window.webkitSpeechRecognition;
const recognition = new SR();
recognition.lang = 'zh-CN';
recognition.processLocally = true;
recognition.onresult = (e) => {
const text = e.results[0][0].transcript;
handleRotating(text);
};
recognition.start();对前端意味着什么?
| 对比项 | 过渡时代(讯飞 WebSocket) | API 时代(Chrome 139 On-device) |
|---|---|---|
| 采音 + 识别 | 自己写 AudioContext + WS | 浏览器 start(),采音+本地识别一体 |
| 离线 | 不行 | 可以 |
| 国内可用 | 要申请 appId、签名校验 | 端侧识别,音频不出设备 |
| 代码量 | 200+ 行打底 | 几十行 |
| 兼容性 | 自己控 | 目前主要 Chrome 139+(端侧 STT) |
这一次变动的重点不是将实验性API变成了通用规范,而是浏览器开始支持本地STT能力。以前的路径是:
浏览器采音 → 推云端 ASR → 返文字现在多了一条:
浏览器采音 → 本地识别 → 返文字对 Agent 这类场景,这意味着更低延迟、更好隐私、支持离线------轮转闭环可以在纯 Web 里跑起来,不必为了 STT 专门套 APP。
但是:它不会替代企业级云 ASR。 需要行业模型、说话人分离、私有部署、关键词检测的生产场景,讯飞/Azure WebSocket 仍是更可控的选择。
新的轮转链路:
用户说话 → processLocally STT → DeepSeek API → speechSynthesis TTS → 循环
javascript
// 2025 年版 VoiceRotator
async function createModernRotator() {
const SR = window.SpeechRecognition || window.webkitSpeechRecognition;
const opts = { langs: ['zh-CN'], processLocally: true };
if (SR?.available) {
const s = await SR.available(opts);
if (s === 'downloadable') await SR.install(opts);
}
const recognition = new SR();
recognition.processLocally = true;
recognition.lang = 'zh-CN';
return {
async listen() {
if (speechSynthesis.speaking) return;
recognition.start();
},
async speak(text) {
recognition.stop();
speechSynthesis.cancel();
await new Promise(r => {
const u = new SpeechSynthesisUtterance(text);
u.onend = r;
speechSynthesis.speak(u);
});
},
onResult: null,
init() {
recognition.onresult = (e) => {
this.onResult?.(e.results[0][0].transcript);
};
}
};
}八、最后
语音轮转要分两块看:
STT(听写)
- 端侧
SpeechRecognition的processLocally本地识别功能目前主要是 Chrome 139+ ;Safari、Firefox 等仍要远程连接,必要时降级到讯飞/Azure 等云 ASR WebSocket。(同一接口不设processLocally时,Chromium 默认仍是远程识别。)
TTS(播报)
speechSynthesis各主流浏览器支持都不错,Demo、内网工具、对音色要求不高的 Agent 往往够用,但由于系统默认音色太过僵硬,若对音色有一定需求,则可以考虑下述方法:- 系统语音包 :在 Windows / macOS 系统配置中安装更好的中文语音,前端用
getVoices()选localService: true的条目(网页里无法 install,可自行安装); - 神经网络 TTS :接 Azure、阿里云、MiniMax、CosyVoice 等 API,要情绪、多角色、品牌声线都行------口播类 AI 产品里最常见,返回音频用
Audio播放即可。
- 系统语音包 :在 Windows / macOS 系统配置中安装更好的中文语音,前端用
最后,AI Agent 不必为了语音专门上终端,可根据 STT、TTS 各自的需求再进行选择。
参考资料: