一、前言
在 AI Coding 快速普及的这两年,越来越多的团队开始使用 Codex、Cursor、Claude Code 等工具辅助开发。围绕这些工具,也出现了大量关于 Prompt、Skills、MCP 的使用教程。但很多内容都停留在"单点提效"层面:教你怎么写 Prompt、怎么装工具、怎么调用能力,却很少回答一个更关键的问题:当 AI 进入研发流程后,我们该如何建立一套稳定、可持续、可复用的工程协作方式?
这篇文章就围绕这个问题展开。先看一下团队在使用 AI 辅助开发时最常见的几个问题:
- Prompt 过于简单,AI 获取的信息不足,会自行补全上下文,导致实现结果跑偏
- 一次性丢给 AI 的信息太多,但没有明确重点和验收标准,最终输出容易失焦
- 代码实现可能不符合团队规范,甚至无意中扩大改动范围
- 一些关键术语和业务背景只存在于当前会话,新开会话后又要重新解释
这些问题的症结,往往在于研发上下文缺乏有效组织,这是单纯优化 Prompt 难以逾越的瓶颈。因此,我们需要将重心转向工程化,搭建一套让 AI 在既定规则内稳定运行的流程。这正是今天我们要探讨的核心------SDD(Spec-Driven Development,规范驱动开发)。
二、SDD 规范驱动开发
SDD 是什么
SDD(Spec-Driven Development,规范驱动开发)并不是一个全新的概念。它在软件工程领域很早就已经出现,核心理念是:先定义规则,再进行实现。只是过去编写和维护规格文档的成本较高,所以并没有真正成为主流开发方式。
随着 2024、2025 年 AI Coding 的快速发展,AI 已经可以高效生成代码,但也暴露出需求理解不稳、改动范围失控、上下文无法持续复用等问题。在这个背景下,SDD 被重新讨论起来。比如 GitHub 的 Spec Kit 就把 AI 开发流程固化为 Specify - Plan - Tasks - Implement,让 AI 更像一个执行者,而人的重心则前移到需求定义、架构设计、约束说明和验收标准上。
SDD 与传统方案的区别
熟悉传统研发流程的人会发现,这其实就是"先写技术方案再开发"的 AI 版本,但是也和之前略有不同。
与传统方案相比,SDD 的区别大致如下:
| 维度 | 传统方案 | SDD |
|---|---|---|
| 文档读者 | 人 | AI + 人 |
| 文档颗粒度 | 可读即可 | 需要结构化,便于 AI 解析 |
| 验收标准 | 相对模糊 | 尽量可验证、可判断 |
| 文档与代码关系 | 容易逐渐脱节 | 由规格驱动实现,更容易保持一致 |
看到这里,很多人会有一个自然的疑问:
原本写方案就已经很耗时了,现在还要把文档写得更细、更结构化,成本会不会更高?
答案是:现在已经有很多成熟的工具可以辅助我们编写 Spec,整体成本其实更低
其实在生成 Spec 时,我们也会进一步加深对需求的理解,而这部分投入换来的,是后续编码阶段更低的返工率和更稳定的协作质量。
SDD 如何解决这些问题
前面提到的"AI 乱改代码",很多时候并不是单一问题,而是几个问题叠在一起:
- AI 不知道需求边界,会自行补逻辑
- AI 不知道验收标准,有可能会提前结束
- AI 不理解项目约束,容易改出不符合团队习惯的代码
- AI 缺少长期上下文,新会话里又会重复犯同样的问题
SDD 要解决的,就是把这些原本藏在需求评审、技术方案、开发经验里的信息,提前整理成 AI 可以持续读取复用的规格文档。比如:
Spec 解决"要做什么、不能做什么"的问题。它会写清楚用户场景、功能边界、异常情况和验收标准。这样 AI 在实现时就不需要自己猜需求,也不容易把无关逻辑一起改掉。
Design 解决"应该怎么做"的问题。这里会说明我们的技术方案、模块影响范围、数据流、接口依赖和兼容性要求等。
Tasks 解决"先做哪一块、做到什么程度"的问题。它会把需求拆成可执行、可验证的小任务。AI 每次只处理一个明确范围,改动就更容易收敛,更方便人做 review 和回滚。
这样一来,AI 从分析、计划到编码,都能围绕同一组规格文档展开。人负责定义规则和判断结果,AI 负责在规则内完成实现。随着这些 Spec 文档在项目里持续沉淀,它们还会逐渐形成项目级知识库。后续再开启新会话时,AI 不需要从零理解业务,也不需要反复解释同一批规则,协作稳定性会明显提升。
三、工具选型
OpenSpec
目前 SDD 已经出现了很多优秀的工具帮辅助我们提效,比较常见的方案包括 OpenSpec、Spec Kit、superpowers 等。
如果团队希望轻量接入、尽快落地,我会更倾向于选择 OpenSpec。它不一定适合所有场景,但对现有团队流程的侵入更小,落地门槛也更低。
初始化方式比较直接:安装 OpenSpec 后,在项目中执行 openspec init,再选择对应的 AI Coding 工具即可生成如下目录结构:
plain
openspec/
├── specs/ # Source of truth (your system's behavior)
│ └── <domain>/
│ └── spec.md
├── changes/ # Proposed updates (one folder per change)
│ └── <change-name>/
│ ├── proposal.md
│ ├── design.md
│ ├── tasks.md
│ └── specs/ # Delta specs (what's changing)
│ └── <domain>/
│ └── spec.md
└── config.yaml # Project configuration (optional)我们重点关注如下几个核心文件:
| 文件 | 作用 |
|---|---|
spec.md |
定义需求、边界、行为、约束、验收标准,作为 AI 的长期上下文 |
design.md |
记录具体的技术方案与实现设计 |
proposal.md |
描述背景、目标、影响面与推进理由 |
tasks.md |
任务拆解与执行进度参考 |
以 Codex 为例,如果已经接入了对应能力,可以通过 /opsx 的快捷指令快速进入这套流程。
更多能力可以参考 OpenSpec GitHub。
工作流程
OpenSpec 只是这套工作流的一种承载方式,核心不是某个具体工具,而是"先定义规格,再约束执行,再持续沉淀"的协作方式。在理想状态下,我们不直接从代码开始,而是先定义和持续修正 Spec 文档,再让 AI 围绕这些文档进行 Coding。
一次 OpenSpec 的生命周期大致如下:
B
rust
B --> C
C --> D
D --"否"--> B
D --"是"--> E
E --> G
G --"是 (退回重做)"--> B
G --"否 (结案)"--> F -->
整体架构
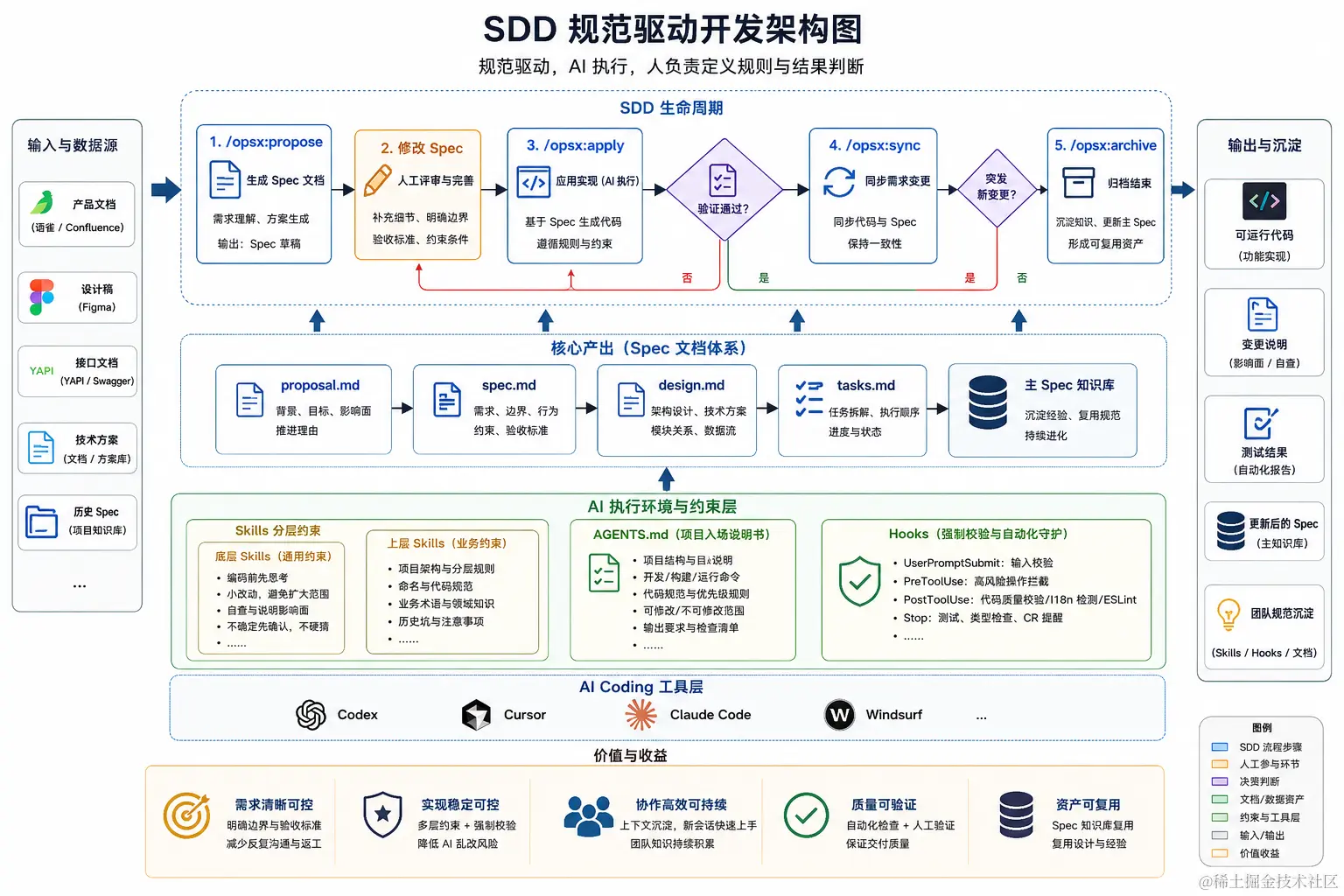
OpenSpec 解决了"按规格推进开发"的主流程,但要让 AI 输出更稳定,还需要把上下文获取、项目规则和自动化校验一起补齐。整体上,可以把这套协作方式理解为下面这张图:
四、实际落地
只看流程图和整体的架构图很多没实践过的人还是会觉得抽象,可能并不清楚 MCP、Skills 等约束在里面扮演的角色, 不清楚在什么阶段应该使用哪个指令,下面我们沿着一次常见的 AI Coding 协作流程,看看 OpenSpec 的一套流程在实际研发中是怎么落地。
生成 Spec
一次复杂需求开始时,我们可以先使用 /opsx:propose + 需求内容、技术方案等 生成一版 Spec 文档。但实操下来会发现,如果完全依赖复制粘贴把信息塞进对话框,不仅效率低,也容易遗漏关键信息,最终影响 Spec 的完整性。
MCP:获取更全的上下文
因此,我们需要借助 MCP 的能力,让 AI 能够直接获取散落在 Figma、语雀、Yapi 等工具里的上下文。把研发流程中常用的数据源统一封装到 MCP Server 中,一方面可以减少手动复制带来的信息损耗,另一方面也能让 Spec 的生成更贴近真实业务上下文。
有了这个能力之后我们再进行 Spec 编写就可以:
shell
/opsx:propose
产品文档: 链接1
技术方案: 链接2
...AI 输出完成之后,仍然需要我们介入检查。因为当前项目可能还没有足够多的历史 Spec,AI 对业务知识的理解并不完整,生成内容里可能会出现错误的业务词汇、不合理的架构设计等问题。这时直接修改生成的 Spec 文档即可。随着 Spec 持续丰富,后续生成时这类问题也会越来越少。
文档修改完成之后,就可以进行最为关键的下一步:生成代码
生成代码
这一步我们只需 /opsx:apply 即可让 AI 根据 Spec 文档快速生成代码,但是实操下来会发现使用 /opsx:apply 之后它虽然理解了业务名词和逻辑,但仍然会扩大改动范围,或者产出一些不符合团队规范的命名和实现。这一步我们就需要借助一些额外的手段来约束这些不规范行为:
1. Skills:把软约束变成可复用的规则层
每个团队都有自己的开发规范,如果每次把这些团队通用规则都通过 Prompt 和 Spec 的方式告诉AI会造成很大的资源浪费,在这里我们可以把这些软约束变成可复用的规则层。
在我的工作流中 Skills 分为两层 底层 Skill(约束模型) + 上层 Skill(指导模型理解业务)
底层 Skill
你可以把这个 Skill 理解成"给模型的长期工作习惯",放一些编码通用规则,比如:
- 编码前先思考
- 优先做小改动,不随意扩大范围
- 修改后要自查并说明影响面
- 遇到不确定的地方先确认,不要硬猜
- ...
这类的通用规则放在工具全局,所有项目共享使用。
上层 Skill
但真正和你项目业务强相关的东西,往往是另一层内容,比如:
- 我们的项目架构哪一层负责请求,哪一层负责数据处理
- 组件命名习惯
- 业务里的专有名词
- 哪些历史坑不能再踩
这部分更适合做成项目级 Skill,持续迭代,放在我们的项目中。
Skills 和 Spec 本质上都是在给 AI 提供上下文,但是放的内容 Spec 重心在做什么,而 Skills 重心在怎么做。
2. AGENTS.md:给 AI 的项目入场说明书
除了 Skills,还可以利用 AGENTS.md。很多 AI Coding 工具都会优先读取项目中的规则说明文件。它适合放那些"进入项目后默认就该知道"的内容,可以把它理解成:项目给 AI 的入场说明书。
例如,比较适合放进去的内容包括:
- 项目结构怎么读
- 哪些规范优先级最高
- 哪些目录或文件不要随便改
- ...
如果你不知道这个文件格式怎么写,这一步同样可以使用 AI 去生成,你只需要验证他生成的文档即可。
为什么这些内容不全部放进 Skills?
因为两者的触发机制和作用范围并不完全一样:
- Skills 是按需激活,更适合通用规则或者单项定制规则,像我们上面提到的通用编码规范等等。
- AGENTS.md 是进入我们项目生效,存放我们当前项目的定制规则,像我们这个特殊项目代码结构等等。
在很多工具里,AGENTS.md 的读取时机会比 Skills 更早,因此它特别适合放最底层、最稳定的项目规则。
3. Hooks:把软约束升级成硬约束
即便有了 Spec、Skills 和 AGENTS.md,AI 仍然可能在复杂任务里偶尔"抽风"。因为我们上面那些约束都是软约束,AI 可能并不会遵守这个约定,我们想要强验证和规范我们的代码,就需要使用 Hooks 能力。
很多 AI Coding 工具都提供了 Hook 能力,允许我们在特定生命周期节点执行脚本。以 Codex Hooks 为例,常见的节点包括:
UserPromptSubmit:用户提示词提交后、AI 接收前PreToolUse:调用工具前,可以拦截高风险操作PostToolUse:工具执行后、结果返回给 AI 前Stop:会话停止前,可执行检查、测试或 CR 流程
例如在实践中会发现 Codex AGENTS.md/Prompt 已经写了"前端代码不能直接写中文,要走国际化",但在长会话或复杂任务里,AI 还是偶尔会输出中文硬编码。
这时候就可以在代码修改后强制执行一个检测脚本:
bash
#!/bin/bash
FILE="$1"
# 检测中文
if grep -nE '[\u4e00-\u9fa5]' "$FILE"; then
echo ""
echo "检测到中文硬编码"
echo "请改成:"
echo "t('xxx')"
exit 2
fi
exit 0hook 示意配置如下:
json
{
"Hooks": {
"PostToolUse": [
{
"matcher": "Edit|Write",
"Hooks": [
{
"type": "command",
"command": "./scripts/check-i18n.sh $CLAUDE_FILE"
}
]
}
]
}
}在拥有了这些配置后,AI 产出的质量会有明显提升。AI Coding 完成后,我们需要继续做的工作是:
- review AI 生成的代码
- 验证界面与交互是否符合预期
- 识别这次协作中暴露出来的新问题
这些问题后续可以反过来沉淀到 Skills、AGENTS.md 和 Hooks 中,形成下一轮更稳定的协作基础。
规格同步
实际开发中,我们经常会遇到一些计划外的变化:代码写到一半,产品临时调整了交互;后端接口字段发生变化;开发过程中发现原来的技术方案走不通;或者 review 时发现某个边界场景之前没有考虑到等。
这些变化本身很正常,但在 AI Coding 流程里,如果只改代码、不更新 Spec,就会埋下一个问题:代码已经变了,但 AI 后续读取到的规则还是旧的。
短期看,这可能没什么影响,因为当前会话里大家都还记得发生了什么。但一旦换一个会话,或者过几天继续迭代,AI 仍然会按照旧 Spec 理解需求。结果就是:它可能把你刚修过的逻辑又改回去,或者在旧规则基础上继续生成代码,导致代码和规格越来越不一致。
这个时候有两种做法:
- 先通过
/opsx:sync + 变动描述,去修改 Spec 文档,然后基于最新的 Spec 文档去/opsx:apply - 特殊情况我们手动修改了代码,然后一定要使用
/opsx:sync + 描述,去更新 Spec
这样就可以保证我们的代码和 Spec 保持一致。
归档沉淀
当所有任务完成、验证通过后,最后一步就是 /opsx:archive。
很多人会把 archive 理解成"把这次任务结束掉",但在 SDD 里,它更重要的作用是:把一次临时协作中产生的有效经验,沉淀成后续可以复用的项目上下文。
一次需求做完以后,真正有价值的东西不只有代码本身,还包括:
- 这次需求最终确认下来的功能边界
- 哪些设计决策被采纳,哪些方案被放弃
- 实现过程中发现了哪些历史问题
- 哪些规则值得沉淀到主 Spec、Skills 或 AGENTS.md
- 哪些测试和验收方式可以复用到后续同类需求
如果不归档,这些信息往往只存在于当前会话、临时分支或某个人的记忆里。等下次再做类似需求时,AI 还是要重新理解一遍,团队也要重新解释一遍,很多已经踩过的坑还会再踩一次。
比如某次需求中我们发现,"后台导出类功能必须区分任务创建成功和文件生成成功"。这个规则如果只留在当前代码里,下一次 AI 做另一个导出功能时未必会知道。但如果在 archive 时把它沉淀进项目规范,后续类似需求就能直接复用这条经验。
从长期来看,archive 做得越扎实,项目里的上下文就越完整。AI 对项目的"熟悉度"不是凭空产生的,而是靠这些持续沉淀下来的规格、规则和历史决策一点点建立起来的。后续协作的边际成本,也会随着这些上下文的积累逐渐降低。
适用场景
不是所有需求都值得走完整的 SDD 流程,有些时候直接 Vibe Coding 可能效率更高
更推荐使用 SDD 的场景包括:
- 新业务模块
- 复杂功能开发
- 多人协作项目
- 长期维护项目
- 大型重构
一个很实用的经验判断是:如果一个需求预计会持续超过 2 天,通常就值得建立 Spec
因为这类需求的复杂度已经足够高,AI 很难仅靠一轮对话稳定完成;而一旦有了 Spec,后续协作成本会明显下降。
不太推荐使用 SDD 的场景包括:
- 过于简单的改动
- 纯样式调整
- 一次性方案验证
- 非持续性的临时脚本
这些场景本身信息密度不高,强行走一整套 SDD 流程,反而会拖慢效率。
实用技巧
- 刚开始生成 Spec 时,不要追求一步到位。先有一版能工作的草稿,再在验证过程中持续补齐。
- 先写清楚用户场景和目标,再讨论实现细节,不要一上来就陷入技术方案。
- 一次只推进一个最小闭环,例如"补一个页面能力"或"修一条配置链路",避免范围持续膨胀。
- 如果需求还不稳定,先把不确定项显式列出来,再开始实现,避免边做边猜。
- 任务拆分尽量按"可提交、可验证、可回退"来切,不要把多个业务点揉成一个大改动。
- 每完成一个子任务就做一次最小验证,至少确认页面渲染、请求参数和类型检查没有明显问题。
五、总结
现在模型的能力已经很强了,但它并不会自动替我们完成所有判断。真正决定产出质量的,还是取决于我们的用法,SDD 只是当下一种比较好的选择,但未来肯定远不止于此。