作者:阿里云消息团队
近日,阿里云消息队列 Kafka 版正式上线原生消息入湖能力 。通过原生集成 Apache Iceberg 与阿里云对象存储 OSS Table Bucket,用户无需部署 Spark、Flink 或 Kafka Connect 等 ETL 工具,即可将 Kafka Topic 中的实时流数据一键写入数据湖 ,实现"实时流处理 + 湖仓分析"的端到端统一。该能力于 2026 年 6 月开启公测,并计划于 9 月正式商业化。

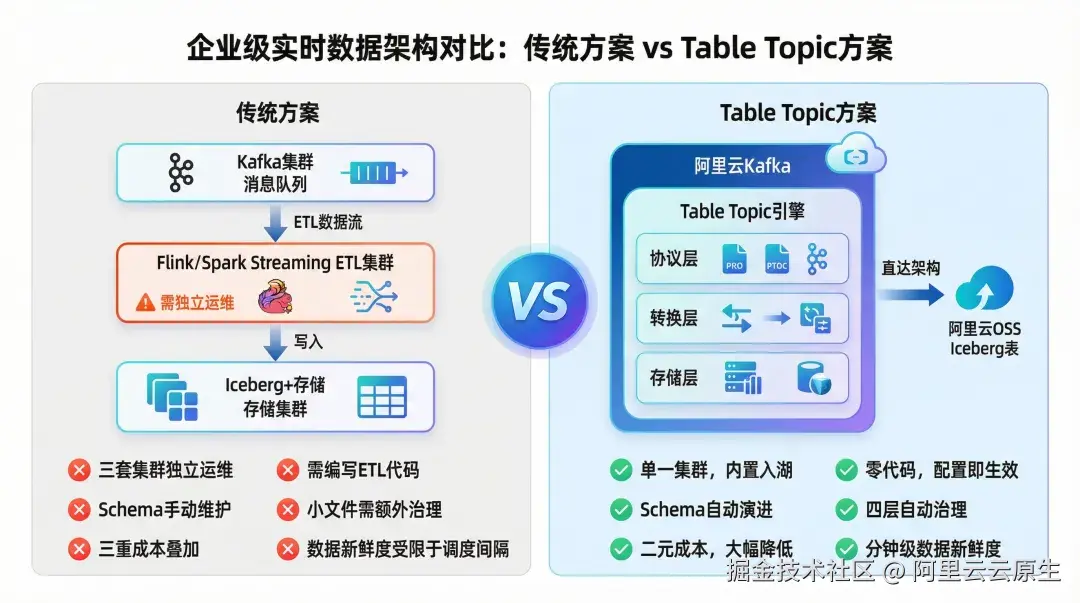
从"ETL 爆炸"到"一键入湖",重新定义 Kafka 数据流转范式
在云原生架构与 Lakehouse(湖仓一体)日益成为主流的今天,企业将 Kafka 与数据湖结合以构建实时分析能力已是大势所趋。然而,传统的 Kafka → 数据湖链路并不轻松:每个 Topic 都需要独立的 Spark 或 Flink 作业进行消费、转换和写入;Schema 变更需要手动同步至 ETL 逻辑和 Iceberg 表结构;小文件合并、过期快照清理、分区优化等"隐形运维"进一步加剧了平台的复杂度和人力成本。
阿里云消息队列 Kafka 版此次推出的原生消息入湖能力,正是为了破解上述难题。用户只需在控制台为指定 Topic 开启入湖配置,Kafka Broker 即可在后台自动完成数据格式转换、Schema 提取、分区写入与元数据提交,全程无需编写任何 ETL 代码,也无需维护额外的计算集群。
四大核心能力,打造零负担入湖体验
1. 零 ETL 架构,开箱即用
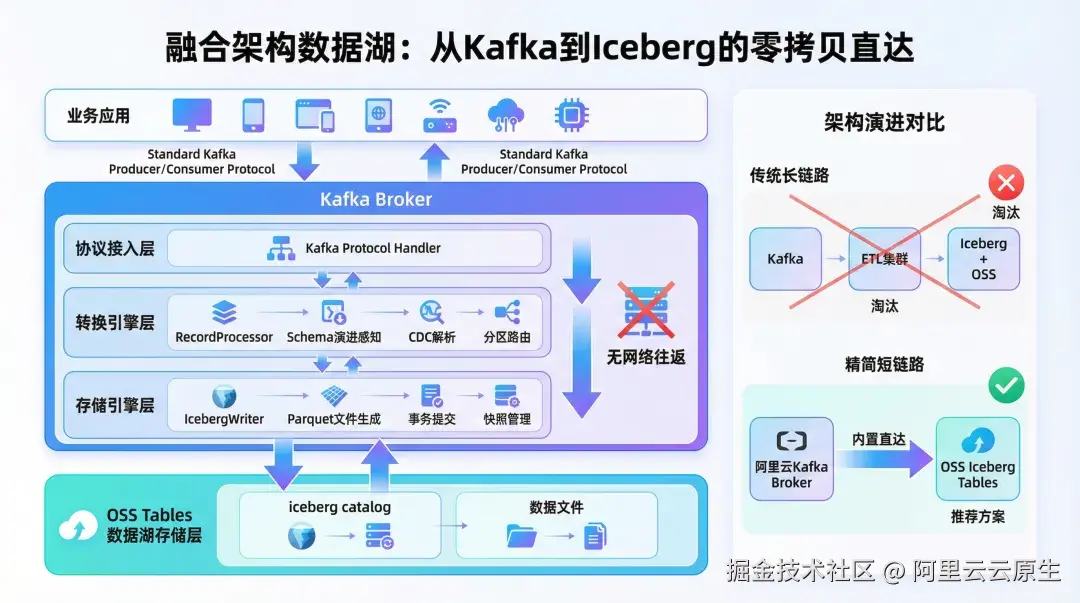
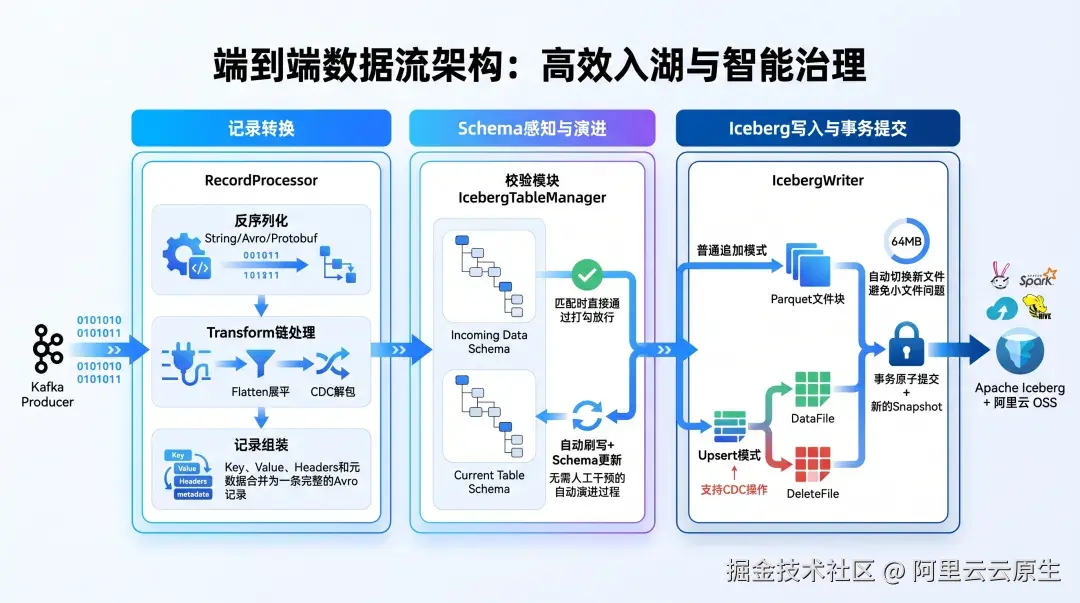
传统模式下,N 个 Topic 往往意味着 N 套 Spark/Flink 作业、N 套监控告警与 N 套资源调度策略。阿里云 Kafka 入湖能力将数据转换与写入流程内嵌至 Broker 层,通过内置的 Worker 组件将 Kafka Record 自动转换为 Parquet 格式并写入 OSS Table Bucket,用户无需部署任何外部计算任务。基于 Exactly-once 语义,确保数据在流转过程中不重复、不丢失。
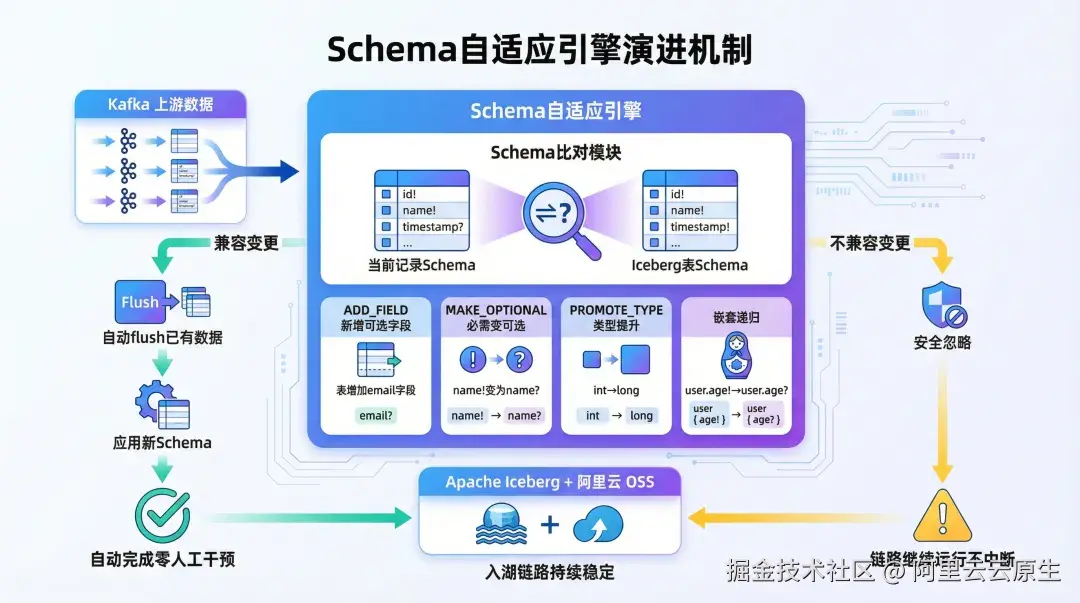
2. 自动 Schema 管理,统一"单一事实源"
数据治理的核心挑战之一,在于 Schema 的分散与不一致。阿里云 Kafka 入湖能力深度集成 Kafka Schema Registry,将原本分散在 Producer 代码、Flink 作业和 Iceberg 表中的 Schema 定义集中管理 。当 Producer 发送数据时,系统自动校验其是否符合注册 Schema;当 Schema 发生变更时,系统自动提取新版本信息并同步更新 Iceberg 表结构,实现数据持续写入不中断。这得益于 Iceberg 对 Schema 演进的天然支持,允许在不重写数据集或中断下游任务的情况下完成字段增删与类型变更。
3. 双模写入,兼顾追加与变更捕获
针对不同的业务场景,阿里云 Kafka 入湖支持两种写入模式:
- Append 模式: 适用于日志、事件流等 append-only 场景,数据以追加方式写入 Iceberg 表,支持高效批量提交。
- CDC 模式: 适用于数据库变更数据捕获场景,支持 Upsert 操作。用户可指定 Key 字段,系统基于 Iceberg 的增量文件机制高效完成数据插入、删除与修改,无需重写整张表。
此外,系统支持灵活的转换策略,包括原始归档(Raw)与结构化归档(Flatten/Debezium),满足从简单日志落盘到复杂 CDC 同步的多样化需求。
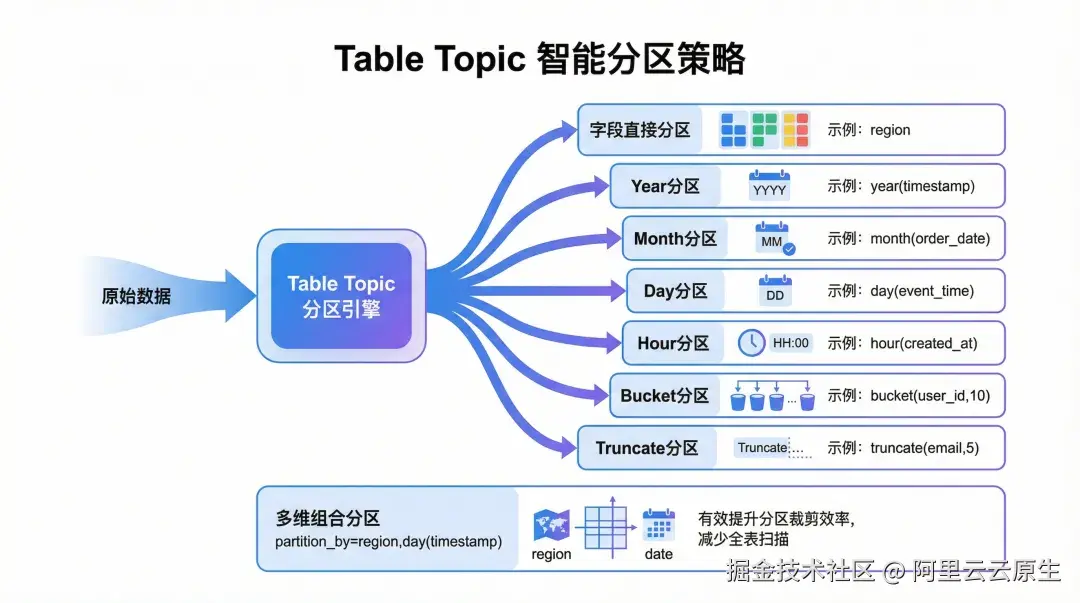
4. 智能分区与自动化运维,释放数据湖运维压力
用户可通过简单的配置为 Iceberg 表定义多列分区策略(如按日期分区),查询引擎即可根据条件裁剪分区,避免全表扫描,显著提升分析效率 。同时,数据写入 OSS Table Bucket 后,可自动获得 OSS 提供的后台运维能力 ,包括小文件合并、过期快照清理与孤儿文件移除,全部在存储层后台完成,不占用用户计算资源与业务带宽,让企业从繁琐的数据湖运维中彻底解放。
深度携手 OSS Table Bucket,实现 10 倍性能提升
阿里云 Kafka 入湖能力的底层存储依托阿里云对象存储 OSS 推出的 Table Bucket 服务。OSS Table Bucket 在 OSS 海量、安全、低成本的存储底座之上原生实现 Apache Iceberg 表语义,全面兼容 Iceberg REST API 与 S3 Table API。
基于 OSS 底层技术架构的端到端深度优化,Table Bucket 在大规模数据读写场景下的 TPS 可达到通用 Bucket 上自建 Iceberg 方案的 10 倍以上。同时,Table Bucket 可无缝接入 OSS 加速器,按需扩展吞吐带宽,轻松应对大模型训练、实时分析等高并发读取峰值。同一份表数据可被 Spark、Flink、Trino、StarRocks 等主流查询引擎直接读写,告别"ETL 复制 + 多副本"的烟囱式架构。
五大典型场景,让数据价值即刻释放
🛒 场景一:电商大促实时经营分析
电商大促期间,每秒产生数十万条订单、支付与物流事件。平台需要维护大量 Flink 作业,将不同业务线的 Kafka Topic 消费后写入 Iceberg 表,作业调度、资源抢占和故障恢复消耗了数据团队大量的精力。Schema 变更(如大促期间临时新增补贴字段)更是需要协调多个团队同步修改 ETL 逻辑,稍有不慎便导致数据中断。
采用阿里云 Kafka 入湖能力,各业务 Topic 一键开启入湖,Broker 自动完成数据转换与写入,Flink 作业数量归零 。经营看板从"小时级刷新"跃升至"分钟级刷新",运营团队可实时追踪 GMV、转化率和库存水位,数据团队则得以将精力投入到指标建模与策略优化中。配合 OSS Table Bucket 的自动小文件合并与分区裁剪,即席查询性能较自建方案提升 10 倍以上。
🏦 场景二:金融核心系统 CDC 实时同步
交易系统的 MySQL 数据实时同步至数据湖,供风控模型与监管报送使用。传统方案下,Debezium 捕获的变更事件需经过"Kafka → Flink → Iceberg"三道关卡,Upsert 逻辑需要在 Flink 作业中手动实现,任何一处故障都可能导致数据不一致,修复窗口长达数小时。
通过阿里云 Kafka 入湖能力的 CDC 模式,将 Debezium 采集的变更流直接接入 Kafka Topic,系统自动识别 Key 字段并以 Upsert 方式写入 Iceberg 表。Iceberg 的原子提交机制保障了 Exactly-once 语义,彻底消除了数据重复与丢失风险 。Schema 演进由系统自动处理,当业务表新增字段时,下游 Iceberg 表同步扩展,无需人工干预。这降低了整个同步链路的运维成本,且数据新鲜度从"小时级"缩短至"分钟级"。
🚗 场景三:车联网海量传感器数据入湖
百万辆联网汽车,每天产生数十亿条电池状态、驾驶行为和故障诊断数据。这些数据通过车载网关汇聚至 Kafka,需要专门的 Spark Streaming 集群进行实时清洗和落盘,存储层采用"Kafka 热数据 + HDFS 冷数据"的分层架构,跨系统数据搬运不仅延迟高,且 HDFS 的小文件问题长期困扰运维团队。
启用阿里云 Kafka 入湖能力,车载传感器数据流直接进入 OSS Table Bucket,以 Parquet 格式按"车型 + 日期"分区存储。OSS Table Bucket 的自动化运维机制在后台持续完成小文件合并与快照清理,运维团队无需再为文件治理投入人力 。同时,数据湖中的结构化数据可被 Spark MLlib 直接读取,用于电池健康度预测和故障预警模型训练,模型迭代周期从周级缩短至天级。
🤖 场景四:AI 多模态训练数据 Pipeline
在模型训练过程中,需要同时管理海量路测图片、视频片段、点云数据以及对应的标注元数据。过去,非结构化数据存放在对象存储,结构化元数据存放在数据库,向量检索依赖独立的向量数据库,三类数据分散在不同系统,数据关联和版本回溯极为困难。
依托阿里云 OSS"对象 + 向量 + 表格"的完整数据存储体系,路测原始数据写入 OSS 对象桶,Embedding 与召回索引写入 OSS 向量桶,Kafka 实时采集的车辆标注信息、传感器元数据则通过入湖能力写入 OSS Table Bucket。三桶数据共享同一套账号、权限与审计体系 ,训练样本的筛选与版本回溯可在单一平台完成,数据准备效率提升数倍,为模型快速迭代奠定了坚实基础。
🔍 场景五:日志审计与长期安全溯源
安全运维团队每日需处理超过百亿条系统访问日志、API 调用记录和安全审计事件。传统架构下,Kafka 中短期保留原始日志(通常 7 天),超过保留期的数据需通过定时任务迁移至低成本存储,迁移过程中的格式转换和字段映射频繁出错,导致关键安全事件无法回溯。
通过阿里云 Kafka 入湖能力,安全团队将审计日志 Topic 直接接入 OSS Table Bucket,原始日志以结构化格式长期归档,存储成本大幅降低 。Iceberg 的时间旅行能力允许安全工程师回溯任意历史时间点的数据状态,配合标准 SQL 即可在 PB 级日志中快速定位异常访问路径。即便面对突发的安全事件调查需求,也能在分钟级完成跨月度、跨年度的数据检索,真正做到"数据在手,溯源无忧"。
结语:让数据流动得更高效、更经济、更开放
Kafka 的演进史,本质上是一部数据基础设施不断解耦与开放 的历史。早期,计算与存储紧耦合在同一台物理机上,扩容意味着整机扩容;随后,冷热数据开始分层,历史数据逐步 offload 到低成本存储,但 Broker 依然是有状态的中间节点;而今天,随着对象存储成为默认的数据底座,Kafka 正从单一的消息管道进化为"既能实时消费、又能直接分析"的双模数据入口。
阿里云消息队列 Kafka 版的演进始终围绕一个核心命题:如何让数据流动得更高效、更经济、更开放 。此次推出的原生入湖能力,不仅是对这一趋势的积极响应,更是阿里云在 "流式数据入口 + 开放数据湖存储" 深度融合方面的重要布局。
未来,阿里云将持续深化 Kafka 与 OSS、流计算等数据基础设施的协同,为企业提供从数据采集、实时处理到湖仓分析的一站式数据平台,助力客户在 AI 时代释放数据的全部潜能。
限时公测,免费体验 Kafka 原生消息入湖能力
📍 产品文档:help.aliyun.com/zh/apsaramq...
📖 技术解读:AI 时代,实时入湖正在告别 ETL:从 Kafka 到 Iceberg 的架构减法
📝 如果你有日志入湖、CDC 同步、IoT 数据归档或 AI 训练数据管理等场景需求,欢迎扫码填写问卷(10 道选择题,约 3 分钟),给我们后续的产品设计与方案优化提供宝贵建议,我们也会根据你的场景安排 1v1 对接与 POC 支持:survey.aliyun.com/apps/zhilia...
👇 点击此处,在线体验 Kafka 原生消息入湖全流程。