一、前置基础:工具调用的诞生背景与核心定位
在讲解具体技术前,先明确两个底层认知,理解工具调用能力的核心价值:
- 大语言模型的原生能力边界纯文本大模型本质是「基于训练知识的推理生成器」,存在三类天然局限:
- 知识边界:训练数据有截止时间,无法获取实时信息(如实时天气、最新股价)
- 交互边界:无法直接操作外部系统,如查询数据库、调用 API、执行代码
- 精度边界:复杂计算、结构化数据处理的准确率低于专用工具,容易出现幻觉工具调用能力正是为了突破这些边界而生。
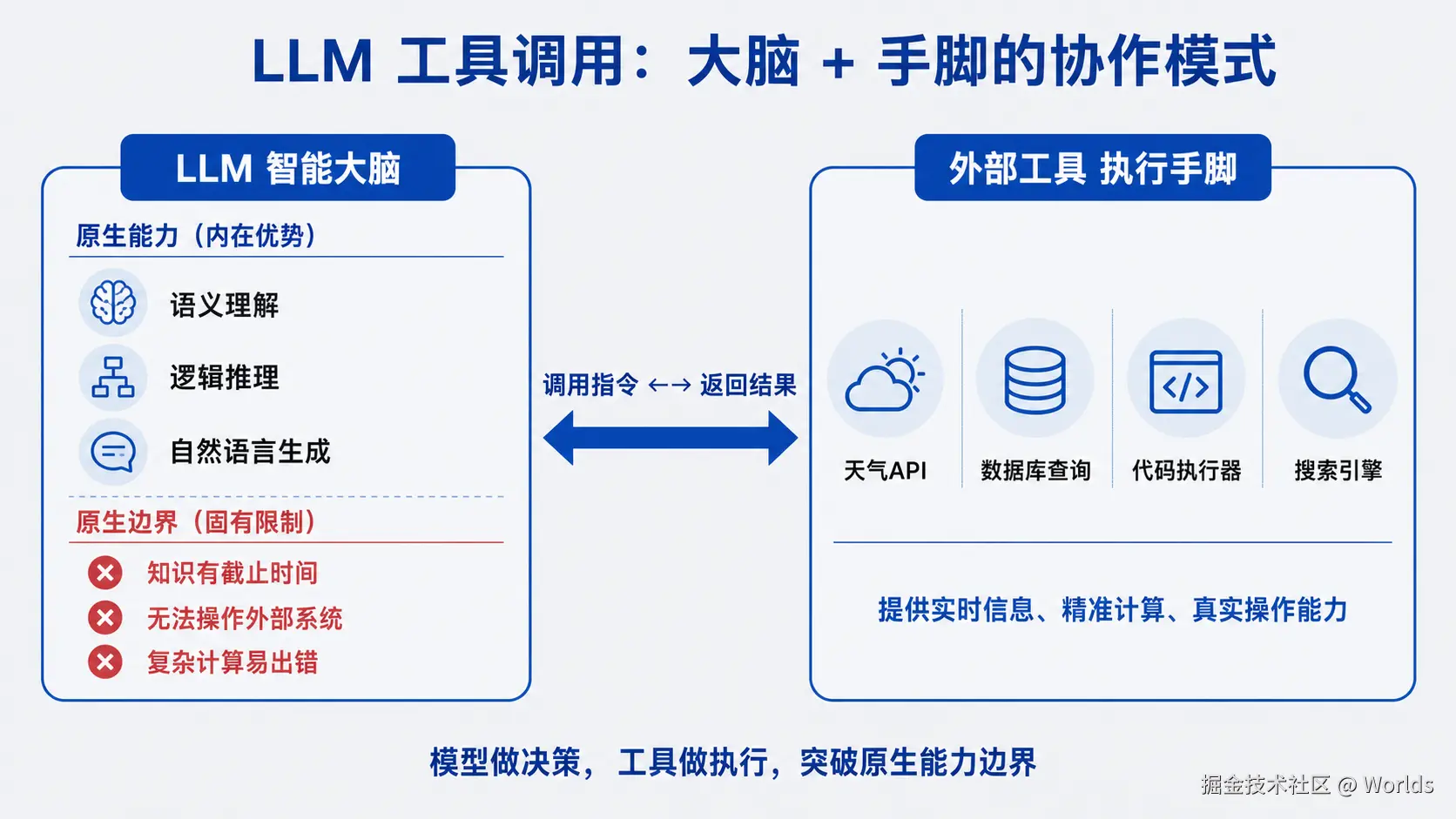
- 工具调用的核心分工逻辑Function Calling(工具使用)的核心是「大脑 + 手脚」的协作模式:
- LLM 承担「大脑」角色:负责理解用户需求、判断是否需要工具、选择对应工具、生成调用参数
- 外部工具承担「手脚」角色:负责执行具体操作、返回真实结果模型本身不会真正执行函数,所有实际操作都由外部宿主程序完成,这是理解整个机制的核心前提。
二、核心概念定义
2.1 什么是 Function Calling / Tool Use
Function Calling(常称函数调用,又称 Tool Use 工具使用)是现代大语言模型的关键能力,指模型能够识别用户需求中需要外部能力的场景,按照指定格式输出结构化的工具调用请求,由外部程序执行后,再基于返回结果生成最终回答。
它是大模型从「纯文本生成器」向「可与现实世界交互的智能体(Agent)」演进的核心基础机制。
2.2 核心组成要素
一次完整的工具调用包含三个基础要素:
- 工具定义(Schema) :工具的名称、功能描述、参数规则,相当于工具的使用说明书
- 调用请求:模型输出的结构化内容,包含要调用的工具名和对应参数
- 执行回传:宿主程序(调用大模型的业务代码 / 框架)执行工具后,将结果回填到对话上下文,供模型继续推理
三、底层工作原理
3.1 核心本质
工具调用的底层并不神秘,本质是「结构化生成能力 + 外部流程协同」的组合,由三个核心环节构成:
- 工具定义注入:将所有可用工具的描述、参数规则(Schema)通过系统提示或 API 参数注入对话上下文,让模型知道有哪些工具可用、分别怎么用
- 结构化输出:模型经过专项训练后,能够在需要工具时输出符合规范的结构化数据(通常为 JSON 格式),而非直接用自然语言回答
- 后处理拦截:宿主程序拦截识别模型的结构化输出,执行真实的函数 / API 调用,再把执行结果注入上下文,让模型基于结果生成回答
3.2 完整数据流
一次标准的工具调用交互,完整流程分为 6 步:
- 用户输入自然语言问题
- 大模型接收上下文与工具定义,自主判断是否需要调用工具
- 若需要工具,模型输出结构化的工具调用指令,不直接回答问题
- 宿主程序解析指令,执行真实的函数 / API / 数据库操作,获取执行结果
- 将执行结果以指定角色加入对话上下文,再次调用大模型
- 大模型基于工具返回的真实结果,整理生成自然语言的最终回答

3.3 模型层面的四种实现方式
不同模型实现工具调用能力的技术路径不同,主流分为四类:
| 实现方式 | 通俗说明 | 代表产品 / 方案 |
|---|---|---|
| 指令微调(IFT) | 在训练数据中加入大量工具调用样本,让模型学会识别调用时机、输出指定格式 | GPT-4、Claude 系列 |
| 原生架构支持 | 在模型结构与训练阶段就深度适配工具调用,识别准确率与格式稳定性更高 | 当代主流商用模型 |
| Prompt 工程模拟 | 纯靠提示词引导模型输出结构化调用,无需对模型做训练 | 早期开源模型、小众模型 |
| 约束解码(Constrained Decoding) | 在生成阶段强制约束输出的语法规则,保证输出一定符合 JSON Schema,不会出现格式错误 | Outlines、Guidance 等开源工具 |
四、主流实现模式详解

4.1 原生支持模式(Native / First-Class)
定义
模型服务商在 API 层面原生封装了工具调用能力,开发者只需通过标准参数传入工具定义,由平台侧完成格式校验、调用识别等处理,是当前生产环境的主流方案。
底层原理
服务商在模型训练与 API 层面对工具调用做了深度优化,开发者无需手动设计提示词、解析输出,API 会直接返回结构化的工具调用结果,大幅降低开发成本。
具象示例
以 OpenAI 风格 API 为例,调用方式如下:
python
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "北京今天天气怎么样?"}],
# 传入工具定义
tools=[{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的实时天气",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市名称"},
"date": {"type": "string", "description": "查询日期"}
},
"required": ["city"]
}
}
}],
tool_choice="auto" # auto=模型自主判断,required=强制调用工具,none=不调用
)API 返回结果中会包含 tool_calls 字段,开发者直接解析执行即可。
适用场景
企业级生产应用、对稳定性和准确率要求高的场景,是绝大多数业务场景的首选方案。
4.2 ReAct 模式(Reasoning + Acting)
定义
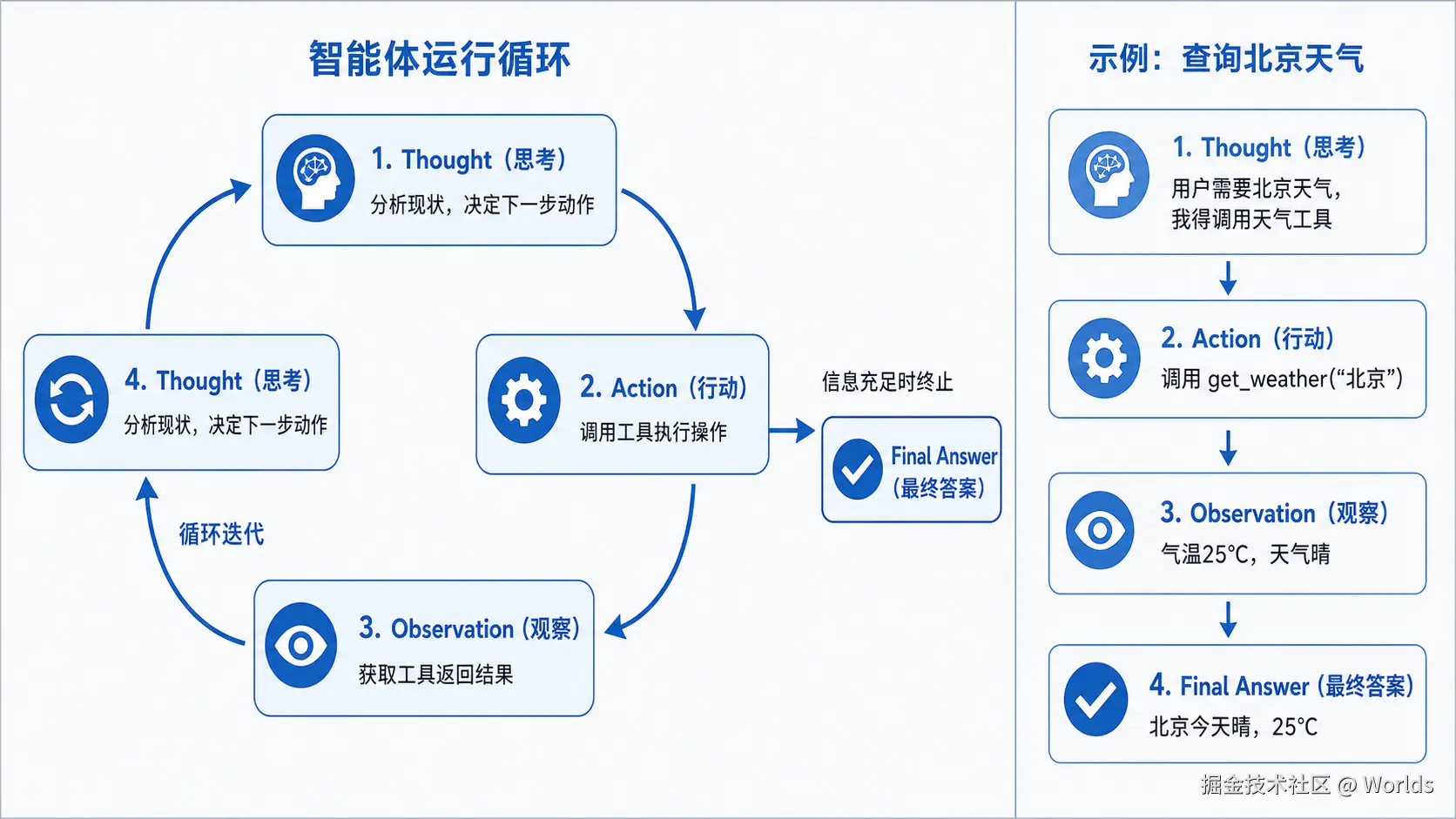
ReAct 是「推理 - 行动」循环模式,模型在调用工具前会显式输出思考过程,按照「思考→行动→观察」的步骤迭代推进,是构建复杂智能体的经典范式。
底层原理
将思维链(CoT)与工具调用结合,每一步先让模型输出当前的思考逻辑(Thought),再决定执行什么动作(Action),拿到结果(Observation)后再进入下一轮思考,全程推理过程透明可追溯。
具象示例
以天气查询为例,标准输出格式如下:
plaintext
Thought: 用户想知道北京今天的天气,我需要调用天气查询工具获取实时数据。
Action: get_weather
Action Input: {"city": "北京", "date": "今天"}
Observation: {"temperature": "25℃", "condition": "晴", "humidity": "45%"}
Thought: 我已经获取到完整的天气信息,可以整理成自然语言回答用户了。
Final Answer: 北京今天天气晴朗,气温25℃,空气湿度45%,整体体感舒适。适用场景
复杂多步骤任务、需要可解释性的场景,如调研分析、故障排查、多工具协同的智能体。
4.3 Prompt 模拟模式
定义
对于不支持原生工具调用的模型,通过在提示词中手动写入工具定义、输出格式要求,引导模型模拟输出结构化的工具调用,是兼容性最强的轻量化方案。
底层原理
完全利用大模型的上下文学习能力,通过提示词明确规则、给出示例,让模型模仿输出符合要求的格式,无需依赖模型的专项训练。
具象示例
典型的提示词结构如下:
plaintext
你是一个智能助手,可以使用以下工具完成任务:
## 工具1:get_weather
- 参数:city(字符串,必填,城市名称)、date(字符串,可选,日期)
- 功能:获取指定城市的天气信息
## 输出规则
- 如果需要调用工具,请严格输出JSON格式,不要添加任何额外内容,格式如下:
{"tool": "get_weather", "arguments": {"city": "城市名"}}
- 如果不需要工具,直接用自然语言回答用户。
用户问题:北京今天天气怎么样?适用场景
开源模型适配、小众模型、无法使用原生 API 的场景,或快速验证原型的阶段。
4.4 并行与多轮链式调用模式
定义
支持在一次请求中同时调用多个独立工具(并行调用),也支持在一轮对话中连续多轮调用工具(链式调用),用于处理复杂的多工具协同任务。
底层原理
- 并行调用:模型一次输出多个工具调用指令,宿主程序同时执行,全部完成后统一返回结果,减少总延迟
- 链式调用:上一个工具的输出结果,作为下一个工具调用的输入依据,模型根据中间结果动态决定下一步动作
具象示例
并行调用示例:同时查询北京和上海的天气
python
response = client.chat.completions.create(
model="gpt-4",
messages=messages,
tools=[weather_tool],
parallel_tool_calls=True # 开启并行调用
)
# 返回结果中包含2组独立的tool_calls,可同时执行适用场景
多信息聚合类任务、有依赖关系的复杂工作流、多工具协同的智能体。
4.5 MCP 标准化协议模式
定义
MCP(Model Context Protocol,模型上下文协议)是 Anthropic 提出的开放标准,用于统一大模型与工具、数据源之间的连接方式,实现工具的「即插即用」。
底层原理
将工具的实现封装为标准的 MCP 服务,大模型客户端通过统一协议与服务通信,无需为每个工具单独做适配开发,实现工具生态的标准化、可复用。
核心架构
plaintext
┌─────────────┐ MCP 协议 ┌──────────────┐
│ LLM 客户端 │ ◄───────────────► │ MCP 服务端 │
│ (调用方) │ (stdio/sse) │ (工具提供方) │
└─────────────┘ └──────────────┘适用场景
大型工具生态建设、多模型多工具统一管理、企业级智能体平台,是未来工具生态的主流发展方向。
五、核心设计考量
在落地工具调用能力时,需要重点关注五个维度的设计:
| 设计维度 | 核心说明 |
|---|---|
| Schema 设计 | 工具名称、参数命名要具备语义,功能描述要清晰准确,这直接决定模型调用的准确率;参数粒度要适中,避免过于笼统或过于细碎 |
| 错误处理 | 需要设计工具执行失败后的重试策略,同时要把错误信息清晰反馈给模型,让模型能够自主调整参数或更换方案 |
| 安全性 | 必须做参数校验、权限控制,防止提示词注入导致工具被滥用;高危操作需要增加人工确认环节 |
| 成本控制 | 每轮工具调用都会消耗 Token,多轮迭代成本会快速累积;需要设置最大调用次数限制,避免无限循环 |
| 延迟优化 | 优先使用并行调用减少总耗时,常用工具可做结果缓存,简单场景尽量减少调用轮次 |
六、常见认知误区
- 误区一:大模型会自己执行函数 / 工具纠正:模型本身只输出结构化的调用指令,所有实际操作都由外部宿主程序执行。模型没有执行代码、调用 API 的能力,只是负责「决策什么时候调用、怎么调用」。
- 误区二:提供的工具越多,模型能力越强纠正:工具数量过多会干扰模型的判断,增加选错工具、参数错误的概率。通常单次上下文内的工具数量控制在 5~10 个以内效果最佳,同类工具优先合并,按需动态加载。
- 误区三:ReAct 就是工具调用,工具调用就是 ReAct纠正:ReAct 只是工具调用的其中一种实现模式,核心特点是显式输出思考过程。原生工具调用、Prompt 模拟等模式都可以不使用 ReAct 格式。
- 误区四:原生支持一定比 Prompt 模拟效果好纠正:对于简单场景、工具数量少的情况,精心设计的 Prompt 模拟也能达到很高的准确率。原生支持的优势体现在复杂场景、多工具、稳定性上,并非所有场景都有绝对优势。
- 误区五:工具调用只适合 API 开发,日常使用用不上纠正:日常使用中,让 AI 调用搜索、计算器、代码解释器等工具,本质都是工具调用能力的应用。理解其原理能更好地判断什么时候该让 AI 查资料、什么时候该直接推理。
七、实操落地建议
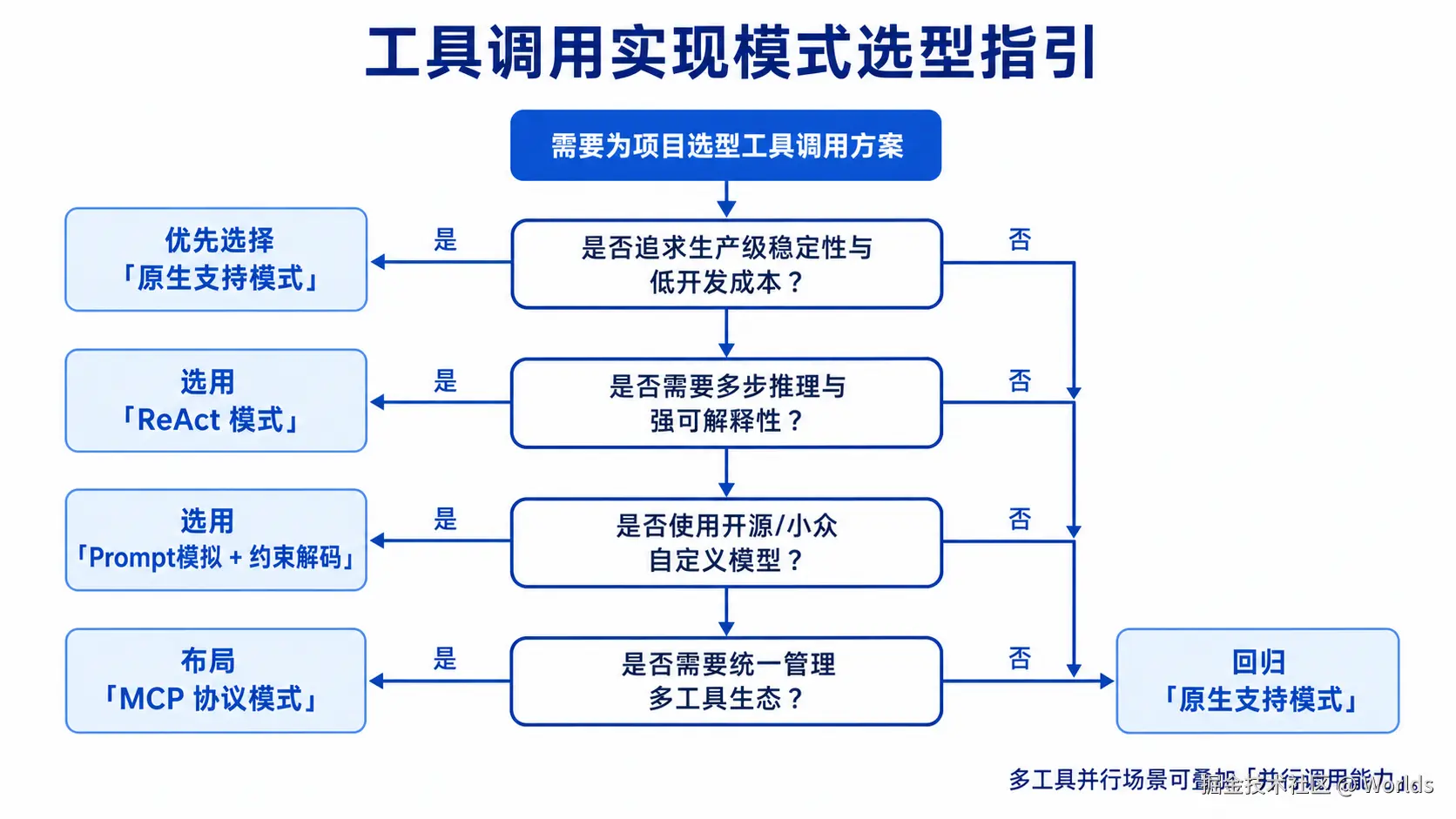
7.1 模式选型参考
- 生产级业务、追求稳定:优先选择模型原生支持的工具调用模式,开发成本低、准确率高
- 复杂多步任务、需要可解释性:选择 ReAct 模式,全程推理可追溯
- 开源模型、定制化部署:优先用 Prompt 模拟 + 约束解码,保证格式稳定性
- 企业级平台、多工具生态:提前布局 MCP 协议,降低工具适配成本
7.2 优化实操技巧
- 工具描述优化:工具功能描述要写清「能做什么、不能做什么、适合什么时候用」,参数补充清晰的取值说明,减少模型歧义
- 加入边界示例:在工具定义中补充正反例,明确什么情况该调用、什么情况不该调用,大幅降低误调用概率
- 设置调用上限:所有工具调用流程必须设置最大轮次限制,避免模型陷入无效循环,造成 Token 浪费
- 分层加载工具:根据对话场景动态加载对应工具,不要一次性塞入全部工具,提升决策准确率
- 结果精简处理:工具返回的原始结果尽量精简后再喂给模型,剔除无关信息,减少 Token 消耗同时避免干扰推理