面试高频题:RAG 检索优化策略有哪些?索引层、查询层、召回层、重排序层分别解决什么问题?
在实际项目中,很多人认为 RAG 的核心是:
text
Embedding → 向量数据库 → LLM但真正上线后会发现:
- 为什么知识库明明有内容,却搜不到?
- 为什么召回到了文档,却回答错误?
- 为什么相同问题有时候回答正确,有时候回答不正确?
实际上,企业级 RAG 的优化已经形成了一套完整体系:
text
文档层
↓
索引层
↓
查询层
↓
召回层
↓
重排序层
↓
生成层每一层都有自己要解决的问题。
RAG 优化体系
text
用户问题
↓
Query Rewrite
(查询层)
↓
Hybrid Search
(召回层)
↓
Vector Recall
(召回层)
↓
Rerank
(重排序层)
↓
Prompt构建
↓
LLM生成简单理解:
| 层级 | 目标 |
|---|---|
| 索引层 | 建好知识库 |
| 查询层 | 理解用户问题 |
| 召回层 | 找到相关内容 |
| 重排序层 | 挑出最相关内容 |
| 生成层 | 输出最终答案 |
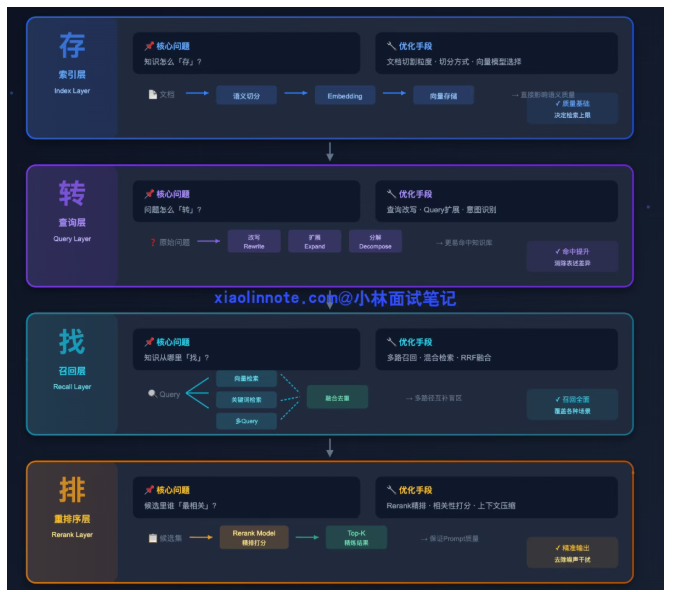
一、索引层优化(Index Layer)
解决什么问题?
核心目标:
text
知识有没有被正确存进去?如果索引阶段做不好,后续检索能力再强也没有意义。
常见问题
1. Chunk 切分不合理
原始文档:
text
报销制度:
住宿标准300元
交通补贴100元错误切分:
text
Chunk1:
报销制度
Chunk2:
住宿标准300元
Chunk3:
交通补贴100元导致语义被割裂。
2. Chunk 太大
text
5000 Token 一个 Chunk问题:
- 召回精度下降
- 噪音增加
- 相关性变弱
3. Chunk 太小
text
50 Token 一个 Chunk问题:
- 上下文缺失
- 信息不完整
- 回答容易断章取义
优化方案
- Parent-Child Chunking 是最直接的方案。把文档切成两个版本:一份是细粒度的子 chunk(比如 150 token 一个),一份是粗粒度的父 chunk(比如 500 token 一个),每个子 chunk 通过 parent_id 关联到对应的父 chunk。入库时只给子 chunk 建向量索引;检索时用子 chunk 的向量来匹配,精度高;命中之后,根据 parent_id 取出对应的父 chunk,把父 chunk 塞给 LLM 阅读,上下文完整。这样就做到了「检索用小的,阅读用大的」,两全其美。
- 摘要索引(Summary Index)的思路稍有不同,它不是切割文档,而是让 LLM 为每一段内容生成一段摘要,用摘要来建向量索引。为什么这样做?因为文档原文有时候表述很散,而摘要是对核心意思的提炼,语义更聚焦,在向量空间里和用户的问题会更接近,命中率更高。检索时用摘要的向量匹配,命中后把原始段落塞给 LLM 阅读。
- 多粒度分层索引则更激进,同时建章节级、段落级、句子级三层索引。不同类型的问题适合不同粒度:「什么是 RAG」这种宽泛的概念性问题,用章节级就够了;「退款申请需要几个工作日」这种细节性问题,用句子级更精准。系统根据问题类型自动选择合适的粒度去检索,能覆盖更多类型的用户需求。
索引层解决的问题
text
召回不到
召回不全
上下文断裂
知识质量差二、查询层优化(Query Layer)
解决什么问题?
核心问题:
text
用户不会按照文档里的方式提问例如:
知识库标题:
text
员工请假制度用户提问:
text
我想休年假怎么办?语义相同。
关键词完全不同。
优化方案
Query Rewrite(问题改写)
流程:
text
用户问题
↓
Query Rewrite
↓
标准问题例如:
text
我想休年假怎么办改写为:
text
员工年假申请流程是什么?Query Expansion(查询扩展)
原问题:
text
RAG扩展为:
text
Retrieval Augmented Generation
检索增强生成
知识库问答Multi Query(多路查询)
用户问题:
text
如何报销差旅费?生成多个查询:
text
差旅报销流程
出差费用报销
财务报销制度并行检索。
查询层解决的问题
text
用户表达不规范
关键词缺失
同义词问题
专业术语差异三、召回层优化(Recall Layer)
解决什么问题?
核心目标:
text
如何找到相关内容?这是决定召回率的关键环节。
方案一:向量检索(Vector Search)
流程:
text
Question
↓
Embedding
↓
Vector Search优点:
text
理解语义例如:
text
请假
≈
休假缺点:
text
关键词容易丢失例如:
text
ErrorCode=10086
订单号=A12345向量检索效果通常较差。
方案二:BM25
传统关键词检索。
优点:
text
关键词精准匹配适用于:
text
订单号
身份证号
错误码
合同编号缺点:
text
不理解语义方案三:Hybrid Search(混合检索)
企业级主流方案。
text
BM25
+
Vector Search同时执行:
text
向量检索 Top10
+
BM25 Top10
↓
Merge
↓
Top20Hybrid Search 的优势
同时兼顾:
text
语义匹配
+
关键词匹配解决单一检索方式的缺陷。
召回层解决的问题
text
漏召回
关键词丢失
语义匹配不准确
召回率低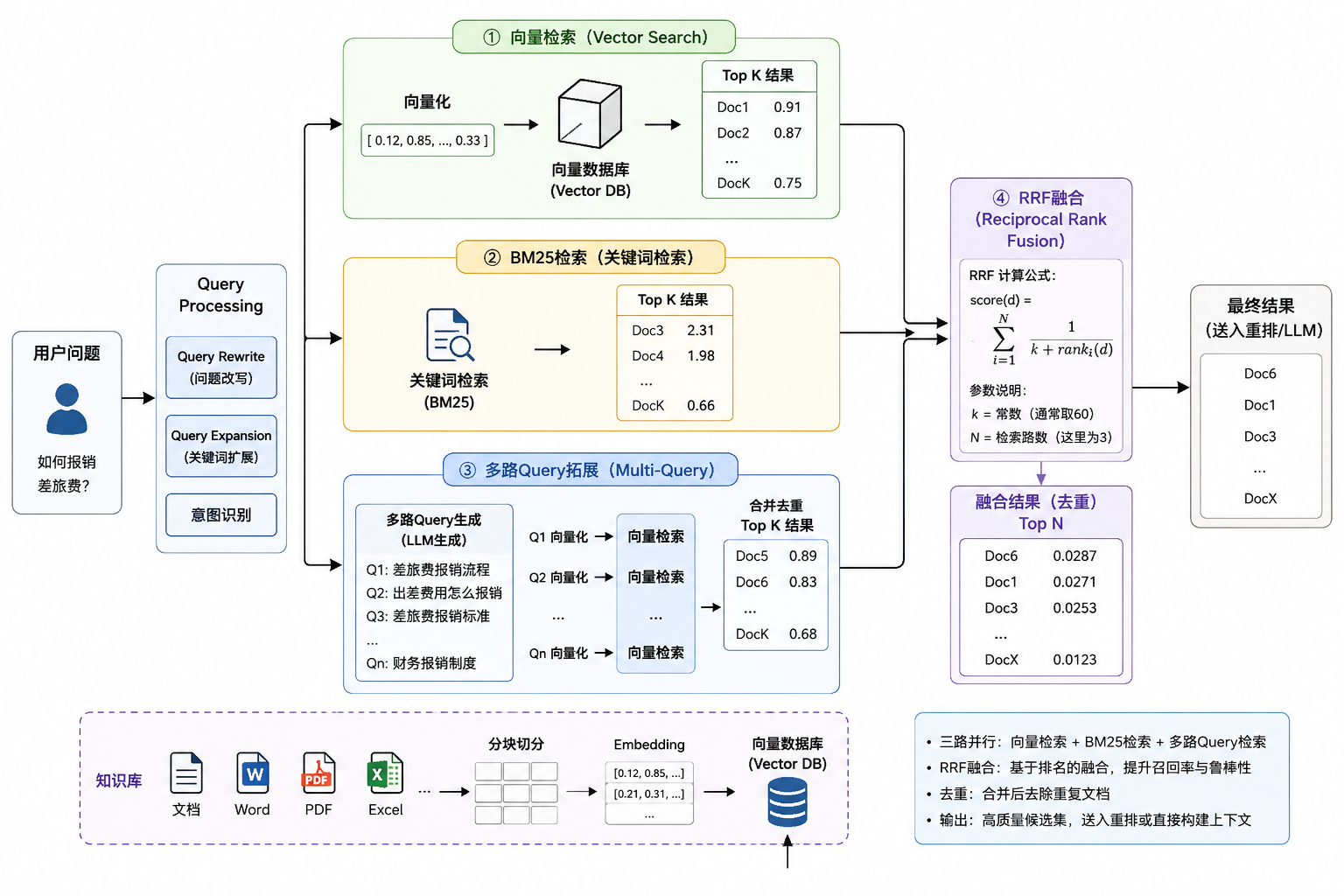
四、重排序层(Rerank Layer)
解决什么问题?
核心问题:
text
召回到了
但排序不对例如:
用户问题:
text
出差补贴标准召回结果:
text
文档A 相似度0.91
文档B 相似度0.90
文档C 相似度0.89实际上:
text
文档C才是真正答案为什么会这样?
Embedding计算的是:
text
语义相似度而不是:
text
问题相关性Rerank 工作原理
重新计算:
text
Question
+
Candidate Document之间的匹配分数。
流程:
text
Top20 Recall
↓
Rerank
↓
Top5常见 Rerank 模型
- BGE-Reranker
- Cohere Rerank
- Qwen-Reranker
- Jina-Reranker
企业实践效果
很多项目:
text
加Rerank前:
准确率 65%
text
加Rerank后:
准确率 80%+提升非常明显。
重排序层解决的问题
text
排序错误
噪音过多
上下文不精准
相关性不足五、生成层优化(Generation Layer)
解决什么问题?
核心问题:
text
如何减少幻觉?即使召回正确:
text
正确资料
≠
正确回答Prompt 优化
推荐:
text
请严格依据提供资料回答。
如果资料中没有答案:
请直接回复:
"知识库中未找到相关内容"。引用来源
例如:
text
根据《财务报销制度V3.0》第三章规定:提升可信度。
多轮推理
复杂问题:
text
上海研发人员出差补贴标准是多少?
是否有特殊政策?可能涉及多个文档。
需要:
text
第一次检索
↓
实体抽取
↓
第二次检索
↓
综合回答即:
text
Multi-Hop RAG企业级最佳实践架构
生产环境通常采用:
text
文档处理
↓
语义Chunk
↓
Embedding
↓
向量数据库
↓
Query Rewrite
↓
Hybrid Search
↓
Top20 Recall
↓
Rerank
↓
Top5 Context
↓
Prompt Engineering
↓
LLM而不是简单的:
text
Embedding
↓
Vector Search
↓
LLM面试总结
如果面试官问:
RAG 检索优化策略有哪些?
推荐回答:
RAG 的优化主要分为四层:
- 索引层:优化 Chunk 切分、Overlap、元数据管理,提高知识存储质量;
- 查询层:通过 Query Rewrite、Query Expansion、Multi Query,提高用户问题理解能力;
- 召回层:采用 Hybrid Search(BM25 + Vector Search)提高召回率;
- 重排序层:使用 Rerank 模型提升结果排序准确率;
- 生成层:通过 Prompt Engineering、引用来源、多轮推理降低幻觉。
企业项目中收益最大的三个优化通常是:
text
语义Chunk
+
Hybrid Search
+
Rerank这三项优化往往能够解决 80% 以上的 RAG 效果问题。
一句话总结
text
索引层解决:存得好
查询层解决:问得准
召回层解决:找得到
重排序层解决:排得对
生成层解决:答得准这也是当前大厂和企业级 RAG 系统最主流的优化思路。
想要了解更多AI面试只是wx搜索:数字生命普朗克