一、引言
Flink SQL 内置了丰富的函数库(字符串处理、数学运算、时间操作、条件判断等),但在实际生产环境中,以下场景内置函数无法覆盖:
| 场景类别 | 典型需求 | 内置函数局限 |
|---|---|---|
| 业务规则封装 | 风控规则评分、用户画像标签计算 | 逻辑过于定制化 |
| 外部数据关联 | 调用外部 API、查询 Redis/HBase | 无内置 I/O 函数 |
| 复杂数据解析 | 自定义协议解析、嵌套 JSON 展开 | 内置解析能力有限 |
| 领域算法集成 | NLP 分词、地理围栏判断、加解密 | 不具备算法库集成能力 |
| 复杂聚合逻辑 | TopN 聚合、精确去重位图、分位数计算 | 内置聚合函数有限 |
自定义函数(User-Defined Functions)作为 Flink SQL 的核心扩展机制,允许开发者以 Java/Scala/Python 编写自定义计算逻辑并无缝嵌入 SQL 查询,本文将介绍 Flink SQL 自定义函数的内部机制原理与使用建议。
二、UDF核心机制
Flink SQL 自定义函数分为四种类型,对应不同的输入/输出映射关系:

1.函数注册与解析机制
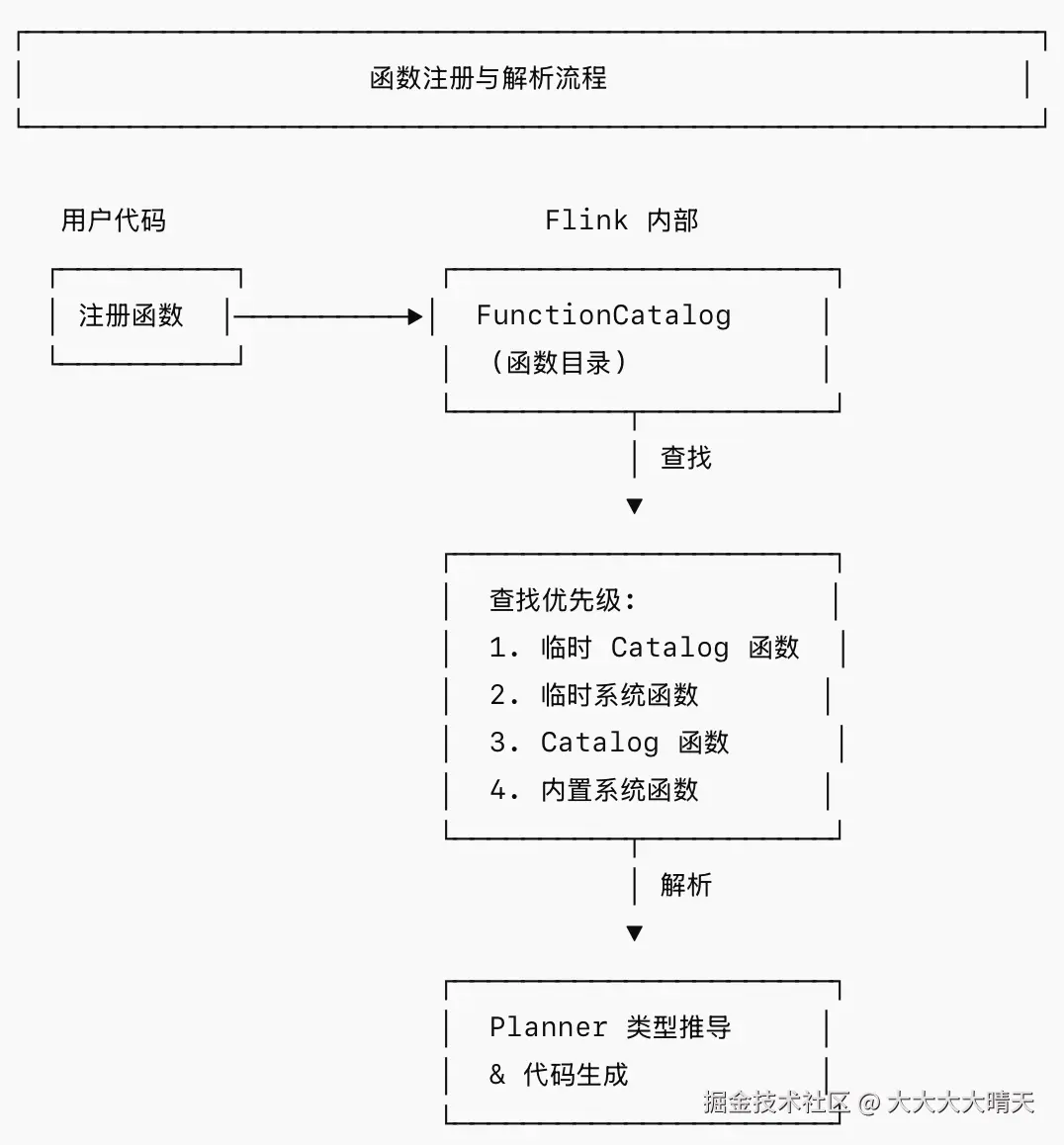
三种注册方式对比:
| 注册方式 | API | 生命周期 | 可见性 |
|---|---|---|---|
| 临时 Catalog 函数 | createTemporaryFunction | Session 级别 | 当前 Catalog/Database |
| 临时系统函数 | createTemporarySystemFunction | Session 级别 | 全局可见 |
| Catalog 持久化函数 | createFunction | 持久化 | 取决于 Catalog 实现 |
2.类型推导机制
Flink 需要在编译期确定函数输入/输出的数据类型,以完成查询计划的优化和代码生成。类型推导有三种方式:
方式一:基于反射的自动推导(默认)
Flink 通过反射分析 eval 方法的签名,自动映射 Java 类型到 Flink 内部逻辑类型。
方式二:注解显式声明(推荐)
less
// 方法级别注解
@DataTypeHint("DECIMAL(12, 3)")
public BigDecimal eval(@DataTypeHint("STRING") String input) { ... }
// 类级别注解(适用于多个 eval 重载)
@FunctionHint(
input = @DataTypeHint("STRING"),
output = @DataTypeHint("ROW<word STRING, length INT>")
)
public class MySplitFunction extends TableFunction<Row> { ... }方式三:重写getTypeInference方法(完全自定义)
less
@Override
public TypeInference getTypeInference(DataTypeFactory typeFactory) {
return TypeInference.newBuilder()
.inputTypeStrategy(InputTypeStrategies.explicitSequence(
DataTypes.STRING()))
.outputTypeStrategy(TypeStrategies.explicit(
DataTypes.ROW(
DataTypes.FIELD("word", DataTypes.STRING()),
DataTypes.FIELD("length", DataTypes.INT())
)))
.build();
}3.运行时生命周期
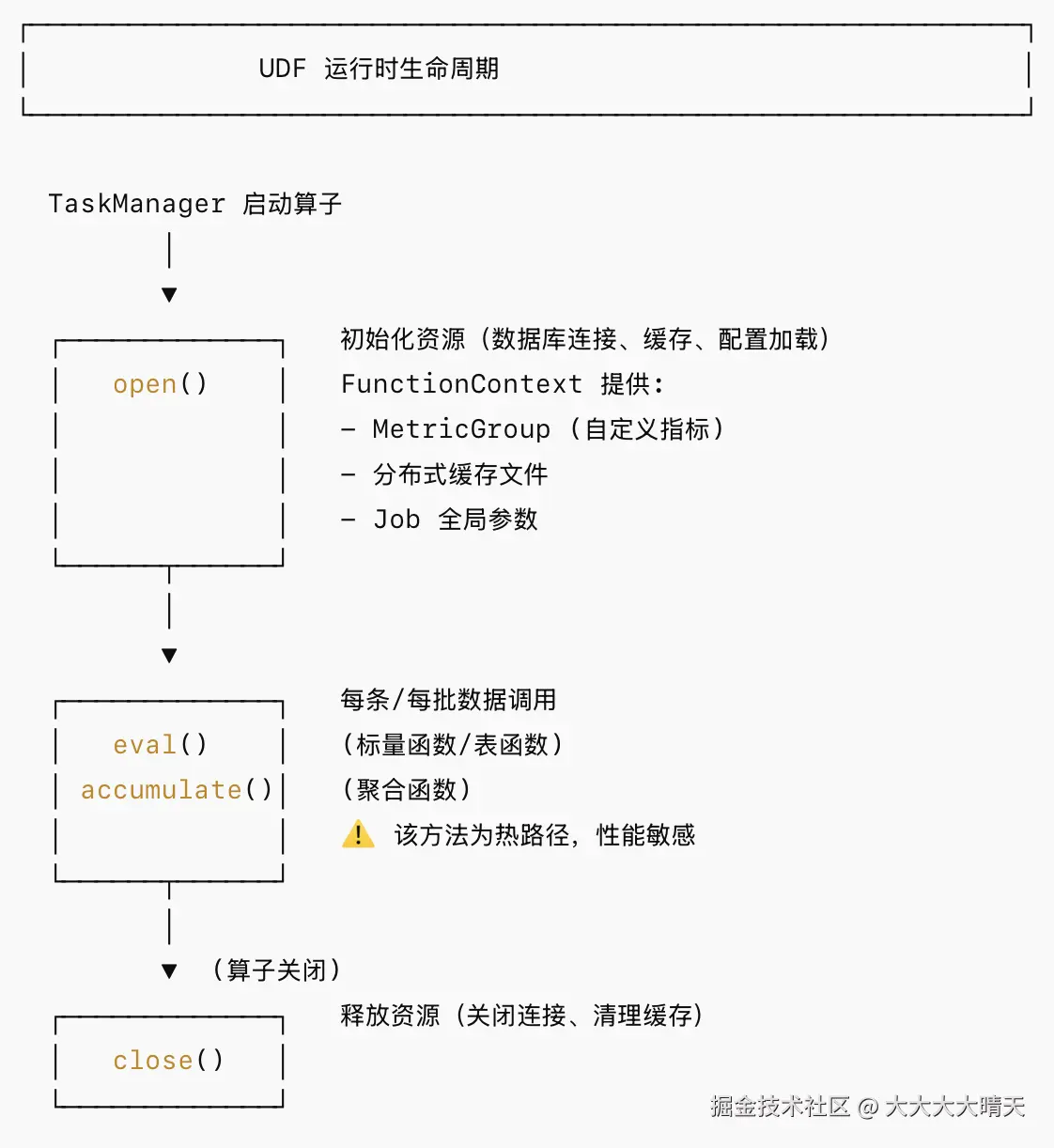
4.代码生成机制
Flink SQL 的 Planner 在优化阶段会将 UDF 调用内联到生成的 Java 代码中:
- SQL 解析 → 生成逻辑执行计划(含 UDF 调用节点)
- 逻辑优化 → 常量折叠、谓词下推等(UDF 若标记为
isDeterministic=true可参与常量折叠) - 物理优化 → 生成物理执行计划
- 代码生成 → 将 UDF 调用编译为高效的 Java 字节码
三、四种函数类型详解与示例
1.Scalar Function(标量函数)
语义:一行输入,一个标量值输出。
typescript
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.InputGroup;
import org.apache.flink.table.functions.ScalarFunction;
public class HashFunction extends ScalarFunction {
// 支持多种重载
public int eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object o) {
return o.hashCode();
}
public int eval(String s) {
return s != null ? s.hashCode() : 0;
}
// 声明为确定性函数(相同输入必然产生相同输出)
@Override
public boolean isDeterministic() {
return true;
}
}SQL使用:
vbnet
CREATE TEMPORARY FUNCTION hash_code AS 'com.example.HashFunction';
SELECT hash_code(user_name) AS name_hash FROM user_events;2.Table Function(表函数)
语义:一行输入,零到多行输出,通常配合LATERAL TABLE使用。
scala
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
@FunctionHint(output = @DataTypeHint("ROW<word STRING, length INT>"))
public class SplitFunction extends TableFunction<Row> {
public void eval(String str) {
if (str == null) return;
for (String s : str.split(",")) {
// 使用 collect 输出每一行
collect(Row.of(s.trim(), s.trim().length()));
}
}
}SQL使用:
sql
CREATE TEMPORARY FUNCTION split_func AS 'com.example.SplitFunction';
-- LATERAL TABLE + JOIN
SELECT o.order_id, t.word, t.length
FROM orders AS o,
LATERAL TABLE(split_func(o.tags)) AS t(word, length);
-- LEFT JOIN LATERAL(保留无匹配的行)
SELECT o.order_id, t.word, t.length
FROM orders AS o
LEFT JOIN LATERAL TABLE(split_func(o.tags)) AS t(word, length) ON TRUE;3.Aggregate Function(聚合函数)
语义:多行输入,一个聚合值输出,需维护中间累加器状态。
typescript
import org.apache.flink.table.functions.AggregateFunction;
// 累加器定义
public class WeightedAvgAccumulator {
public long weightedSum = 0;
public int weightCount = 0;
}
// 聚合函数:加权平均
public class WeightedAvgFunction
extends AggregateFunction<Long, WeightedAvgAccumulator> {
@Override
public WeightedAvgAccumulator createAccumulator() {
return new WeightedAvgAccumulator();
}
// 累加逻辑(必须实现,方法名固定为 accumulate)
public void accumulate(WeightedAvgAccumulator acc, Long value, Integer weight) {
acc.weightedSum += value * weight;
acc.weightCount += weight;
}
// 获取最终结果
@Override
public Long getValue(WeightedAvgAccumulator acc) {
return acc.weightCount == 0 ? null : acc.weightedSum / acc.weightCount;
}
// 用于 Session Window 等场景的合并(可选)
public void merge(WeightedAvgAccumulator acc, Iterable<WeightedAvgAccumulator> others) {
for (WeightedAvgAccumulator other : others) {
acc.weightedSum += other.weightedSum;
acc.weightCount += other.weightCount;
}
}
// 用于 OVER 窗口的撤回(可选)
public void retract(WeightedAvgAccumulator acc, Long value, Integer weight) {
acc.weightedSum -= value * weight;
acc.weightCount -= weight;
}
}SQL使用:
vbnet
CREATE TEMPORARY FUNCTION weighted_avg AS 'com.example.WeightedAvgFunction';
SELECT
product_id,
weighted_avg(score, weight) AS avg_score
FROM reviews
GROUP BY product_id;4.Table Aggregate Function(表聚合函数)
语义:多行输入,多行输出。目前仅支持 Table API。
java
import org.apache.flink.table.functions.TableAggregateFunction;
import org.apache.flink.util.Collector;
// Top2 累加器
public class Top2Accumulator {
public Integer first = Integer.MIN_VALUE;
public Integer second = Integer.MIN_VALUE;
}
public class Top2Function
extends TableAggregateFunction<Row, Top2Accumulator> {
@Override
public Top2Accumulator createAccumulator() {
return new Top2Accumulator();
}
public void accumulate(Top2Accumulator acc, Integer value) {
if (value > acc.first) {
acc.second = acc.first;
acc.first = value;
} else if (value > acc.second) {
acc.second = value;
}
}
// 输出多行结果
public void emitValue(Top2Accumulator acc, Collector<Row> out) {
if (acc.first != Integer.MIN_VALUE) {
out.collect(Row.of(acc.first, 1));
}
if (acc.second != Integer.MIN_VALUE) {
out.collect(Row.of(acc.second, 2));
}
}
}四、开发流程与使用建议
开发流程:
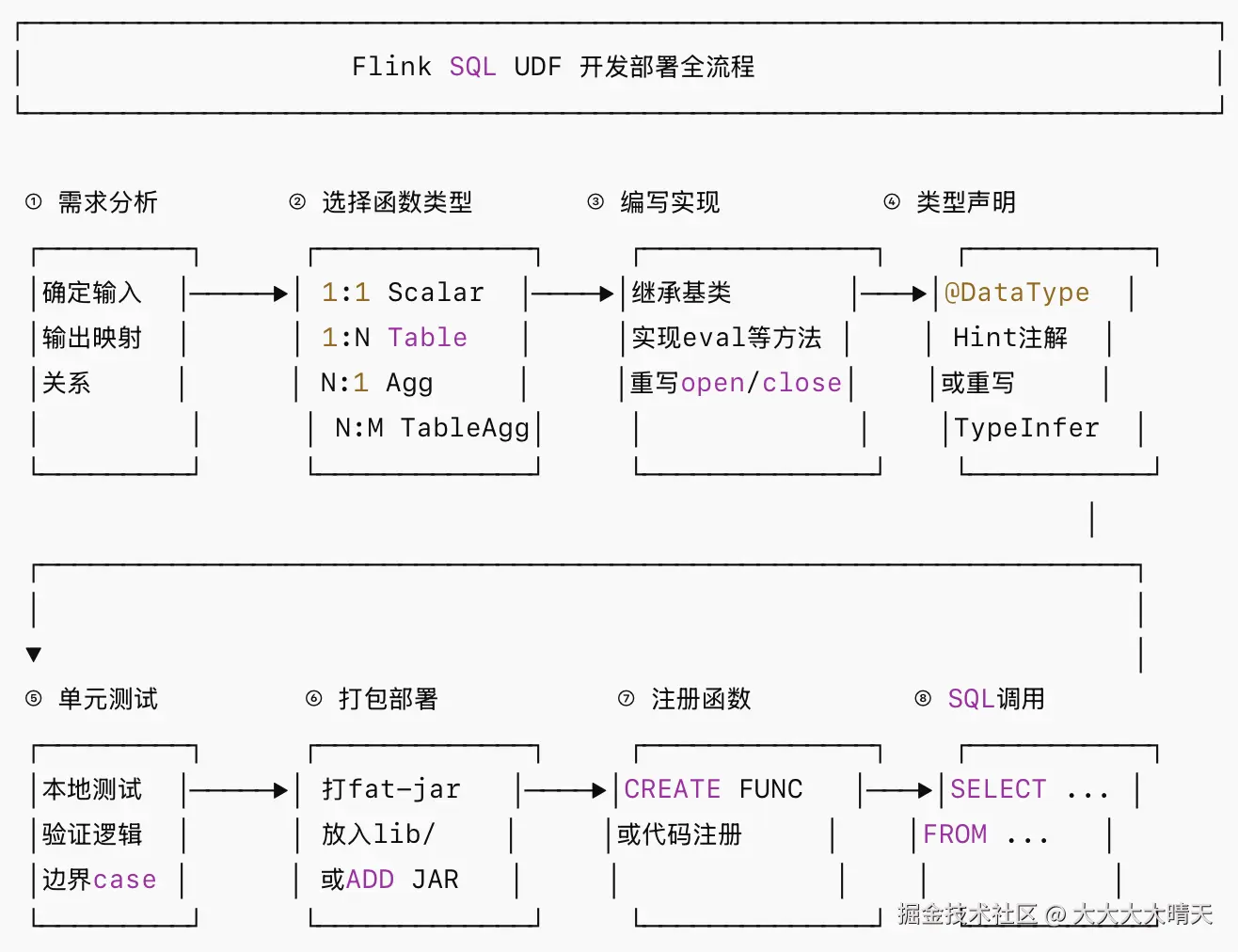
选型建议:
sql
┌─────────────────────┬──────────────────┬───────────────────────────┐
│ 场景 │ 推荐函数类型 │ 典型示例 │
├─────────────────────┼──────────────────┼───────────────────────────┤
│ 数据清洗/格式转换 │ Scalar Function │ 手机号脱敏、JSON字段提取 │
│ 自定义加解密 │ Scalar Function │ AES/SM4 加解密 │
│ 一行展多行 │ Table Function │ 数组/Map展开、正则多匹配 │
│ 自定义聚合指标 │ Aggregate Func │ 精确UV(BitMap)、百分位数 │
│ 维度数据关联 │ Scalar Function │ 查询Redis/HBase维表 │
│ 规则引擎集成 │ Scalar Function │ Drools/Aviator规则求值 │
│ NLP/AI推理 │ Scalar/Table │ 分词、情感分析、模型推理 │
│ TopN/排序聚合 │ Table Agg Func │ Top3商品、最活跃用户 │
└─────────────────────┴──────────────────┴───────────────────────────┘