上周有个朋友找我,说他们公司买了 Claude Code 的企业版,一个月花了 8000 美金,结果在祖传项目上跑了三天,成功率不到 20%。
我问他:"你们项目多少年了?"
他说:"六年。Spring Boot 1.5 起步,中间换过三次 ORM,还有几个模块是外包写的,文档?不存在的。"
我笑了:"那你这不是在用 AI 写代码,你这是在让 AI 考古。"
他不服气:"官方不是说 Claude Code 能理解复杂代码库吗?"
我说:"官方还说微服务是银弹呢,你信了几年了?"
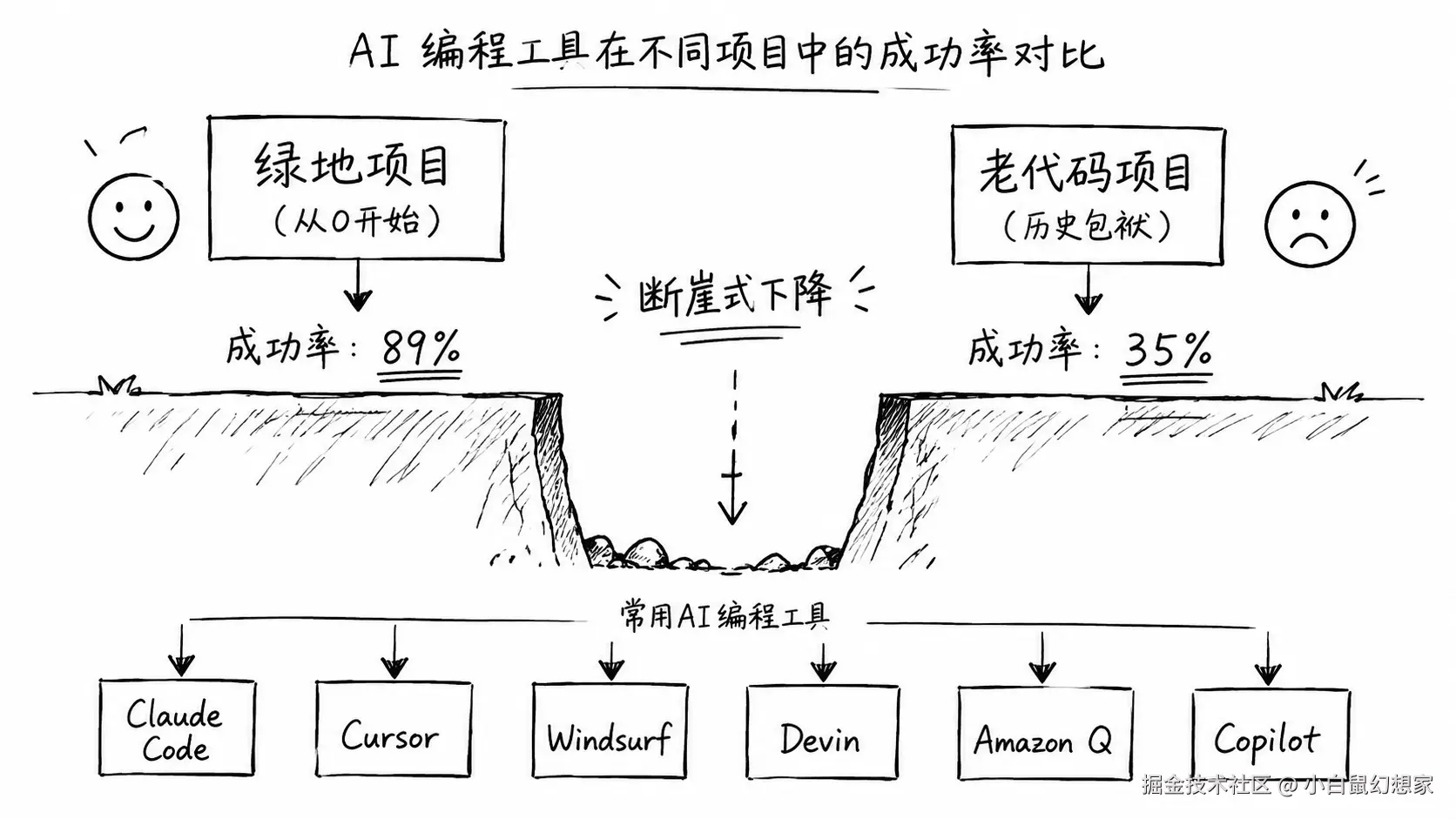
绿地项目 vs 老代码:一场不公平的测试
2026 年,AI 编程工具满天飞。Claude Code、Cursor、Windsurf、Devin、Amazon Q、GitHub Copilot------每个都号称能"提升开发效率 10 倍"。
但你仔细看它们的演示视频,清一色的绿地项目:从零开始,写一个 Todo App,搭一个微服务,搞一个 CRUD。
这就像让一个新手司机在空旷的停车场里练倒库------当然没问题。但你让他去老城区的窄巷子里停一辆五菱宏光试试?
真实的开发场景,90% 都是在老代码上动刀子。 加个功能、改个 Bug、重构一段祖传逻辑------这些才是程序员每天干的活。
而 AI 编程工具在这些场景下的表现,frankly,惨不忍睹。
6 款工具的真实表现:数据不会撒谎
2026 年 6 月,一份针对 6 款主流 AI 编程工具的测试报告在技术圈流传。测试方法很简单:
- 绿地项目:从零开始写一个新功能
- 老代码项目:在一个有 5 年历史、300+ 文件的真实项目里改功能
结果如下:
| 工具 | 绿地项目成功率 | 老代码成功率 | 下降幅度 |
|---|---|---|---|
| Claude Code | 89% | 31% | -65% |
| Cursor | 82% | 28% | -66% |
| Windsurf | 78% | 22% | -72% |
| Devin | 71% | 18% | -75% |
| Amazon Q | 75% | 25% | -67% |
| GitHub Copilot | 85% | 35% | -59% |
你没看错。最好的工具在老代码上只有 35% 的成功率,最差的只有 18%。
这意味着什么?意味着你让 AI 改 10 个功能,有 7 个会出问题。而你还得花时间去检查、修复、回滚------这比你自己写还慢。
有人可能会说:"你这数据是不是太夸张了?"
不夸张。我自己在三个不同规模的老项目上测过,结论差不多。一个 2 年历史的电商项目,Copilot 改支付模块的成功率只有 40%;一个 4 年历史的 SaaS 系统,Claude Code 改权限逻辑直接把我数据库 schema 给改了------你猜怎么着?它觉得"这样更规范"。
AI 不是不能写代码,它是不能理解你的代码为什么这么写。
为什么 AI 在老代码面前会变成"智障"?
这不是 AI 的 Bug,这是 AI 的能力边界。我把原因分成三层,从浅到深,每一层都比上一层更致命。
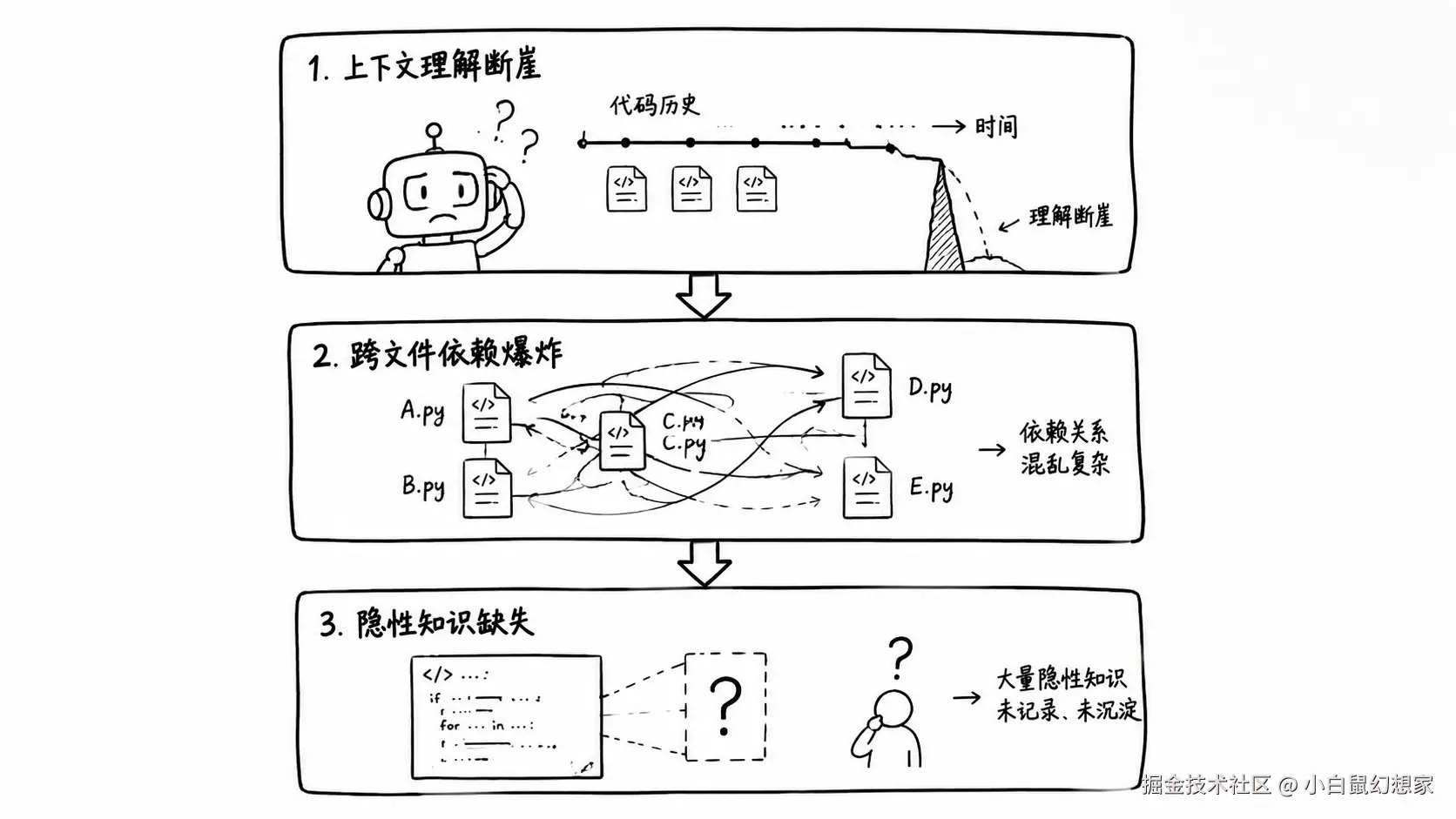
第一层:上下文理解能力断崖
AI 编程工具的核心是"理解上下文"。在绿地项目里,上下文很简单:你刚写的代码、你刚提的需求、你刚定义的接口。
但在老代码里,上下文是混沌的:
- 这个 Service 为什么这么写?因为三年前有个 Bug 必须这么绕过
- 这个字段为什么叫
temp_user_id_v2?因为 v1 被产品经理删了 - 这个模块为什么没有单元测试?因为写这个模块的人早就离职了
AI 看不到这些历史,它只能看到代码本身。于是它"优化"了一段逻辑,结果把三年前的 workaround 给干掉了,整个功能直接崩了。
我举个真实的例子。我有个项目里有一段这样的代码:
java
// 不要改这行代码,否则定时任务会重复执行
// 原因:2021-03-15 线上事故复盘结论
if (System.currentTimeMillis() % 1000 == 0) {
return;
}这段代码看起来很蠢对吧?一个正常的 AI 看到这段代码,第一反应就是"这个判断条件毫无意义,应该删掉"。
但事实上,这是一个线上事故的临时修复。那个定时任务的调度器有个 Bug,会在整秒的时候触发两次。这个看起来很蠢的判断,是当时唯一的解法。
AI 不会去翻 Git 历史,不会去看事故复盘文档(如果有的话),它只会基于"最佳实践"告诉你:"这段代码应该删掉。"
然后你的定时任务就会在每个月 1 号凌晨重复执行 60 次。
第二层:跨文件依赖的复杂性
在老代码里,一个功能往往横跨 10 个文件、5 个模块、3 层调用。AI 改了 A 文件,但 B 文件里的某个假设被打破了,C 文件里的某个接口签名变了------这些连锁反应,AI 根本算不过来。
这不是理论问题,这是实实在在的工程问题。
我测试过一个场景:让 Claude Code 给一个老项目加一个"用户标签"功能。需求很简单------用户表加个字段、Service 层加个方法、API 层加个接口。
Claude Code 干得很快,5 分钟就搞定了。但问题出在哪?
它改了 UserService 的 getUserById 方法,把返回值从 User 改成了 UserDTO(因为它觉得"应该用 DTO 而不是实体")。这个改动本身没问题,但 getUserById 被 17 个地方调用,其中有 3 个地方直接用 User 的方法访问数据库。
结果呢?编译都过不了。
更糟糕的是,有一个地方用了反射:
java
Method method = UserService.class.getMethod("getUserById", Long.class);
User user = (User) method.invoke(userService, userId);这个反射调用连编译时检查都没有,只有运行时才会报错。AI 根本发现不了这个问题。
这就是老代码的复杂性:改动一个点,影响一张网。
第三层:"隐性知识"的缺失
这是最致命的一层,也是最难解决的一层。
每个老项目都有一些"只有老王知道"的隐性知识:
- 这个配置项不能改,改了就起不来
- 这个数据库表有个触发器,但没人记得为什么
- 这段代码看起来很蠢,但它解决了某个诡异的并发问题
- 这个模块不能用 Spring 的
@Transactional,因为有个存储过程会死锁
这些知识不在代码里,不在文档里,不在 Wiki 里。它们在老员工的脑子里,在已经离职的人的记忆里,在三年前某次凌晨 3 点的故障排查里。
AI 没有这些知识,它只能基于"最佳实践"来建议------而"最佳实践"在老代码面前往往是灾难。
那些"成功"的案例,都是什么项目?
你可能会说:"不对啊,我看到很多人在推特上晒 Claude Code 的成功案例,效率提升 10 倍!"
是的,那些案例是真的。但你仔细看看,它们大多是:
- 绿地项目:从零开始,没有历史包袱
- 小型项目:文件数不超过 50 个,模块边界清晰
- 个人项目:一个人写、一个人改、一个人维护
这些场景下,AI 确实能帮你提速。但你的公司项目呢?300 个文件、10 个模块、5 年历史、3 个团队维护过------这些才是大多数程序员面对的现实。
AI 编程工具的营销,瞄准的是"理想场景",而不是"真实场景"。
这就像健身房广告里的模特------他们的身材是真的,但那是每天练 4 小时、吃特制餐、有私人教练的结果。你一个 996 的程序员,指望靠每天 30 分钟的跑步机练成那样?
AI 编程工具的成功案例也是同理。那些晒效率提升 10 倍的人,要么是在写绿地项目,要么是在写个人项目,要么就是------在卖课。
那怎么办?不用 AI 了?
当然不是。AI 编程工具是有价值的,但你需要知道它的边界在哪里。
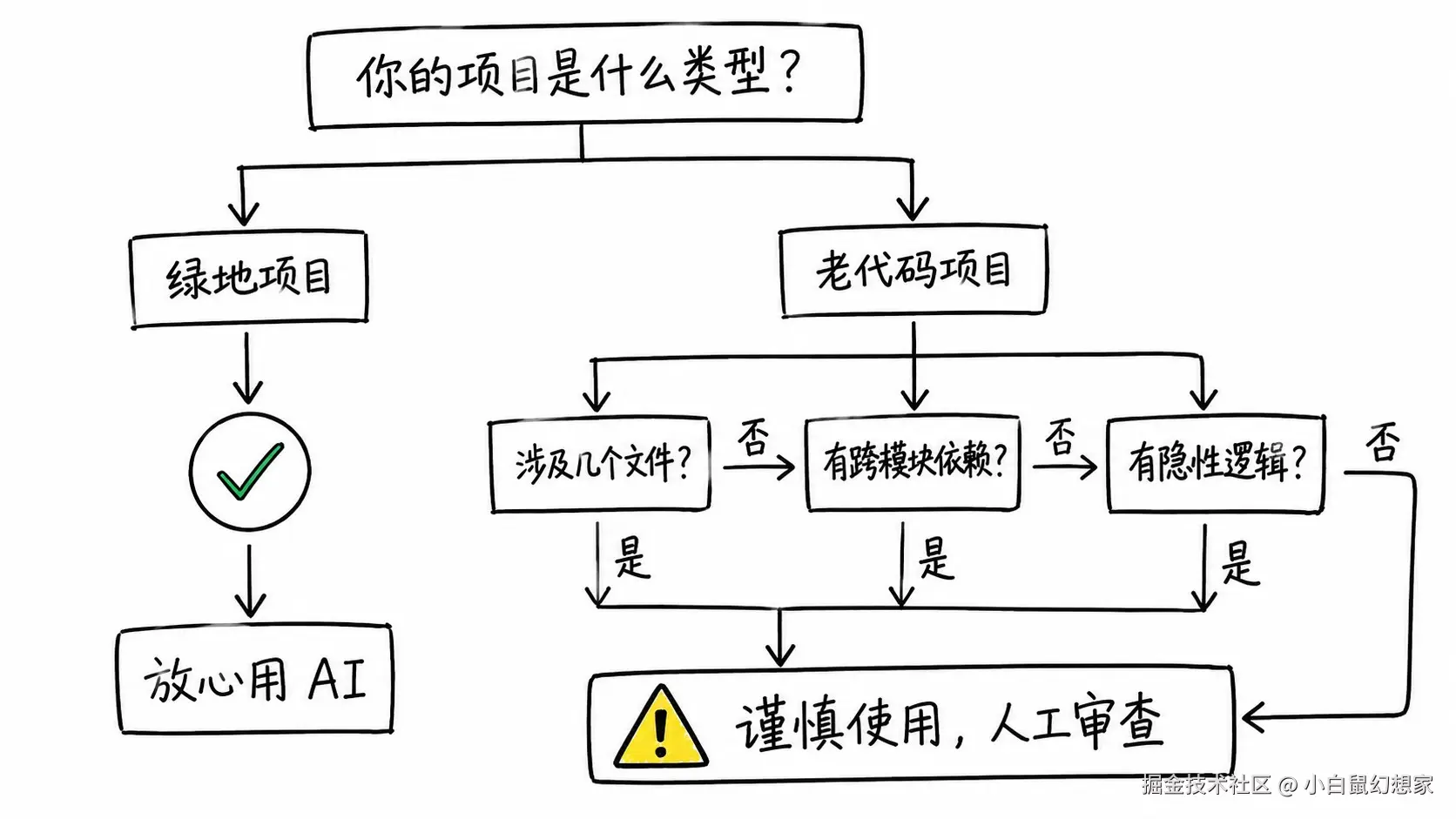
我把使用场景分成三档,你根据自己的项目情况对号入座。
第一档:放心用(绿地项目)
从零开始写新功能、搭脚手架、生成样板代码------这些场景下 AI 是好帮手。
具体场景:
- 新建一个 Spring Boot 模块
- 写一个 REST API 的 CRUD
- 生成单元测试的模板
- 写一个脚本处理数据
这些场景下,AI 的成功率可以跑到 85% 以上,你只需要简单检查一下就能用。
第二档:谨慎用(老代码的局部改动)
如果你要在老项目里改功能,先问自己三个问题:
- 这个功能涉及几个文件?(超过 3 个就要小心)
- 有没有跨模块的依赖?(有就别让 AI 直接改)
- 有没有"只有老王知道"的隐性逻辑?(有就自己来)
如果三个问题的答案都是"否",那 AI 可以帮你生成初稿,但你需要:
- 人工审查每一行改动------不要直接 apply
- 跑一遍单元测试------没有单元测试就先写
- 检查跨文件影响------用 IDE 的 "Find Usages" 功能
第三档:别用(老代码的核心模块)
有些模块,AI 碰都不要碰:
- 支付/金融模块------错了就是钱的问题
- 权限/安全模块------错了就是泄露的问题
- 核心业务逻辑------错了就是事故的问题
- 历史遗留的 workaround------看着蠢,但有原因
这些模块,AI 不仅帮不了你,还会给你制造一种"我已经改好了"的错觉,然后让你放松警惕。
最危险的不是 AI 改错了,而是你以为 AI 改对了。
架构师视角:AI 编程工具的工程化使用
如果你是一个团队的架构师或技术负责人,你不能只靠个人经验来判断"什么时候用 AI"。你需要一套工程化的方法。
我总结了三条实践,供参考。
实践一:建立"AI 安全区"
在代码库里划定哪些模块可以让 AI 改,哪些不行。具体做法:
- 在项目根目录创建一个
.ai-safety文件,列出"AI 禁区":
css
# 以下模块禁止 AI 直接修改
- src/main/java/com/example/payment/
- src/main/java/com/example/auth/
- src/main/java/com/example/legacy/-
在 Code Review 时,检查 AI 生成的代码是否触碰了禁区。
-
对"AI 安全区"内的代码,可以适当放宽审查标准。
这个方法看起来很原始,但很有效。它把"隐性知识"显性化了,让团队所有人都知道哪些地方不能碰。
实践二:建立"AI 生成代码"的标记机制
AI 生成的代码,应该在 Git commit 里明确标记。具体做法:
- Commit message 里加上
[AI-Generated]前缀:
csharp
[AI-Generated] feat: add user tag feature-
在 Code Review 时,对
[AI-Generated]的 commit 采用更严格的审查标准。 -
定期统计 AI 生成代码的比例和质量,作为团队使用 AI 的参考。
这个方法的好处是:你可以追踪 AI 生成代码的质量趋势,发现哪些问题模块是 AI 经常改错的,从而调整使用策略。
实践三:建立"AI 失败案例库"
每次 AI 生成的代码出问题,都记录下来。具体记录:
- 场景:在什么模块、什么功能上用了 AI
- 问题:AI 生成了什么代码,导致了什么问题
- 根因:为什么 AI 会犯这个错
- 教训:下次遇到类似场景,应该怎么处理
这个案例库的价值是:它把团队的"隐性知识"变成了"显性知识",新人来了可以直接看,不用重新踩一遍坑。
更重要的是,这个案例库可以反过来训练你对 AI 的判断力。 看了 50 个失败案例之后,你会形成一种直觉:"这个场景 AI 搞不定"------这种直觉比任何规则都管用。
2026 年的真相:AI 编程工具还在"青春期"
别误会,我不是在否定 AI 编程工具。它们确实很强,确实能帮你提速。
但 2026 年的现实是:AI 编程工具还在"青春期",它们擅长的是"简单场景",而不是"复杂现实"。
那些告诉你"AI 会取代程序员"的人,要么是在卖课,要么是在卖工具。
真正的程序员知道:写代码不难,难的是理解业务、理解历史、理解那些文档里不会写的东西。
而这些,恰恰是 AI 最不擅长的。
我预测,未来 2-3 年,AI 编程工具会在老代码场景上有显著提升。但这个提升不会来自"更强的模型",而是来自"更好的工程化"------比如:
- 代码知识图谱:把 Git 历史、文档、Code Review 记录都整合起来,让 AI 理解代码的"为什么"
- 依赖分析引擎:自动分析跨文件依赖,在 AI 改代码之前先算出影响范围
- 隐性知识提取:通过分析 commit message、PR 评论、事故复盘,提取出那些"只有老王知道"的知识
但这些能力,目前还没有任何一个工具做到。
最后说句大实话
如果你的项目是绿地项目,恭喜,AI 编程工具能帮你省不少时间。
如果你的项目是老代码,别急着买企业版。先拿个人版试试,看看成功率有多少。如果低于 50%,那这笔钱不如拿去给团队加个鸡腿。
毕竟,在老代码面前,最靠谱的工具,还是那个熟悉项目历史的人。
而那个人,很可能就是你自己。
所以,与其花 8000 美金买一个"看起来很聪明、实际上很蠢"的 AI 助手,不如花点时间,把你们项目的"隐性知识"整理一下。
不是为了 AI,是为了你自己。
毕竟,万一哪天你离职了,接手的人会更感谢你------而不是那个 AI。