一、单核时代,计算机是怎么继续变快的?
先思考一个问题,在进入 多核 时代之前,在 单核 时代,是怎么让计算机越来越快的?
首先我们要知道
执行时间 ≈ 指令数 /(IPC(每周期指令) × 时钟频率(GHz))
那么提高效率的方式就有两种
- 提高时钟频率
- 提高IPC,同一时钟周期内并行处理更多指令
但是,问题出现了,单核提高效率到后面,有三堵墙出现了
二、单核继续提速,为什么后来越来越难?
第一堵墙:功耗墙(Power Wall 频率越高,功耗和发热压力越大)
CPU的动态功耗与频率的关系,常被近似写成: P = α · C · V² · f
- α:活动因子
- C:等效开关电容
- V:电压
- f:频率
所以主频继续往上堆,功耗和发热也会一起往上走,散热压力会越来越大
第二堵墙:频率墙(Frequency Wall 信号传播的物理极限)
时钟频率越高,意味着信号传递时间越短,一旦时钟周期短到信号来不及在芯片各部分之间同步,则整个系统都会出错
第三堵墙:存储墙(Memory Wall)
CPU的速度是非常快了,但内存(RAM)跟不上啊
- CPU 速度:1纳秒
- 从L1缓存读数据: 4个时钟周期
- 从L2缓存读数据: 12个时钟周期
- 从内存读数据: 数百个时钟周期
这导致大部分时间,CPU都在等待数据
这三堵墙,让人意识到,继续堆频率,死路一条,我们需要换个思路,与其让单核频率越来越快,不如再加几核,让他们一起工作
这就是多核的核心逻辑
三、多核带来了新问题
但这会有个问题,如果 线程A 和 线程B 同时处理同一份共享数据,会出现什么问题?
举个例子:
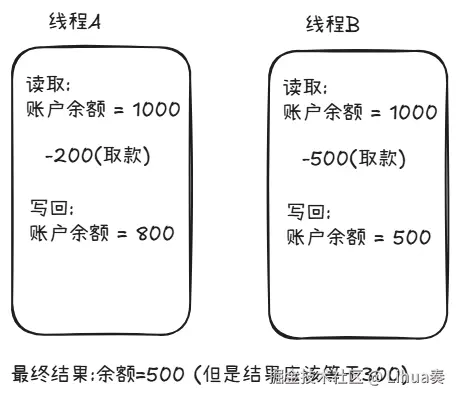
这种现象还有个名字,叫做: 竞争条件
两个线程同时读取了同一份数据,各自修改,各自写回,那么后写的会覆盖掉前一个结果,数据就被破坏了,并且没有任何的报错
还有个更隐蔽的问题:缓存不一致
每个核心都有自己的缓存,他们把内存里的数据复制一份放在自己的缓存中,这样就不用每次都访问内存去数据了,但问题就出现在这
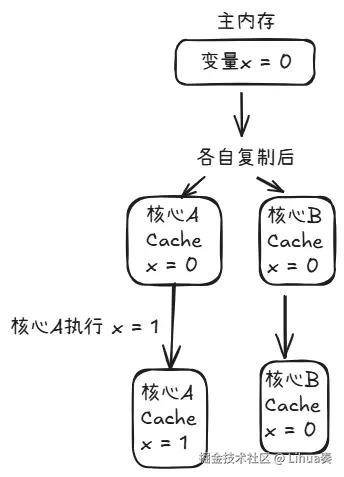
核心B缓存中是过期的数据,并且他不知道,以为是最新的,这就是缓存一致性的问题(Cache Coherence)
那么如何解决这两个问题?
竞争条件: 互斥锁(Mutex),核心概念:让同一时间只有一个线程进去改

代价也是等待,锁越多,核心越多时间在等待而非工作
缓存一致性: MESI协议,核心概念:各核心之间能互相通知
- M - Modified (我改过了,主内存还没更新,其他人别用)
- E - Exclusive (只有我有这份数据,是最新的)
- S - Shared (大家都有,但都没改,是一致的)
- I - Invalid (我这份已经过期了,不能用)
比如: 当核心A修改了数据X,它会通过一致性机制通知别的核心:"这份数据已经不是旧版本了"。核心B的缓存收到消息后,会把自己那份X标记为 Invalid,下次再用时必须重新取。
对比两种核心数量的问题

所以,多核的代价是什么?
- 协调成本增高
- 等待时间过长
- 沟通成本增高
这也是为什么多核不是免费的午餐,你加4个核心,程序并不会自动快4倍(除非程序被设计成能并行运行),这个规律也有个名字: 阿姆达尔定律
四、为什么多核不会让程序自动快好几倍?
来看一下为什么,不会自动快几倍
对于强依赖的任务来说:单核执行
rust
A -> B -> C -> D ->完成
时间:10秒多核执行
rust
核心A: A -> 等待B -> C
核心B: B -> 等待C -> D ->完成
时间:几乎也是十秒,因为依赖问题但是如果没有依赖问题,它是一个完全可并行的任务的话
makefile
核心A:A ->完成
核心B:B ->完成
核心C:C ->完成
核心D:D ->完成
时间:理论上接近2.5秒,也就是接近4倍多核的性能增益就在这,完全取决于任务是否可以并行
阿姆达尔定律:多核的真实上限

比如: 程序有 90% 可并行

小总结:
多核不是频率的替代品,而是一种吞吐量的补充。它牺牲了单任务的执行速度提升,换来了同时处理多个任务的能力。对于可并行的工作,增益显著;对于串行任务,增益有限且有理论上限
多核芯片带来的好处,首先受益的是操作系统和多任务场景
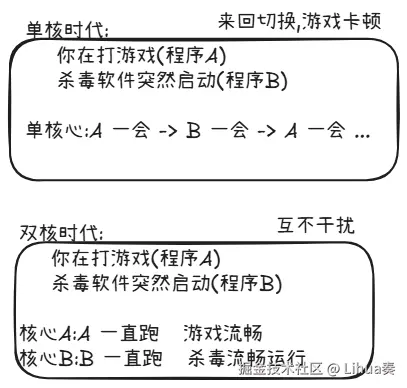
但是,要让一个程序真正利用多核,程序员必须主动把任务拆分成可以同时运行的 线程(Thread) 或并行任务,这意味着整个软件行业的编程思维必须升级
五、为什么后来会有越来越多核心?
摩尔定律
它的诞生:来自一个工程师 戈登.摩尔 的观察
他发现了:每隔约两年,晶体管数量翻一倍,他把这个观察写了下来,预测这个趋势会持续下去,这就是 摩尔定律
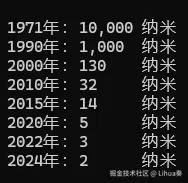
从1971年到 2023年,这52年,晶体管的数量从 2300 到 134,000,000,000
为什么摩尔定律能够传下来?
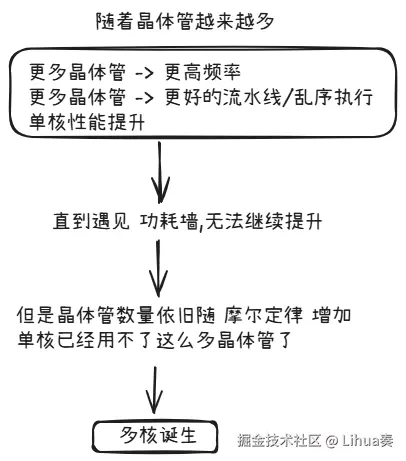
所以说,多核并不是凭空出现的新思想,而是晶体管越来越多之后,工程上开始寻找更划算的新出路
现在,又有了新的问题,随着晶体管数量增多,继续缩小和继续堆下去也越来越难了
看数据:
对应的解决方法有三种:
- 3D堆叠(向上堆,相当于加一个z轴)
- 专用芯片(AI芯片、GPU 为特定任务优化)
- 新材料(碳纳米管、量子计算等,探索其他的可能)
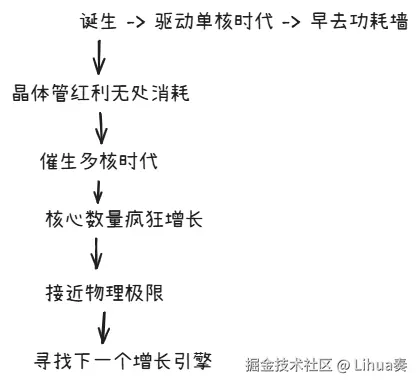
摩尔定律的一生:
六、为什么现在又出现了大小核?
现在我们的核心数量已经很多了,我自己的电脑CPU就有二十个核心,但你仔细看会发现,有些核心速度快,有些核心速度慢,为什么要这样设计?
核心动机:功耗墙
有些程序它的性能需求并不高,比如 时钟 或后台同步,如果你用大核去跑,不亚于你开车去50米处一小卖部买冰棍,虽说也能买到吧,但是真的很浪费,走路过去就好了啊

以手机息屏举例:
makefile
纯大核:更耗电,续航更短
大小核:小核接管息屏状态,更省电,续航更长核心概念:最有效率的使用每一瓦电能
总结
如果只用一句话去理解这篇,那就是: 单核继续提频越来越难,所以计算机开始把更多晶体管用在"并行干活"上,这才有了多核、大小核以及后面一整套新的设计思路。
多核确实能带来更强的吞吐能力,但它不是免费的午餐。核心一多,同步、等待、缓存一致性、任务拆分这些问题也都会跟着出来。所以从单核到多核,本质上不是"变简单了",而是从拼单核速度,变成了拼整体协作效率。