IoT 时序数据查一年直接卡死?Java + SQL 优化全过程
做光储充项目的时候遇到一个问题:查某台设备一整年的功率曲线,接口直接超时,系统卡死。
排查下来是典型的时序数据查询问题。这篇记录从问题复现到最终解决的完整过程,顺带把几千台设备同时上报这个场景也说清楚。
一、先把问题说清楚
数据规模估算
先算一下数据量,很多人在这步就没有概念:
500台设备 × 1条/分钟 × 60分钟 × 24小时 × 365天
= 2.6亿条/年这还只是功率一个指标。实际项目里一台设备上报的字段可能有十几个(电压、电流、频率、SOC......),数据量还要乘几倍。
原始表结构
最直觉的设计是这样:
sql
CREATE TABLE device_power (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
device_id VARCHAR(50) NOT NULL,
power DECIMAL(10,2) NOT NULL,
recorded_at DATETIME NOT NULL
);一条记录一行,简单直接。
问题复现
查某台设备一年的数据:
sql
SELECT device_id, power, recorded_at
FROM device_power
WHERE device_id = 'PV_001'
AND recorded_at BETWEEN '2024-01-01' AND '2024-12-31'
ORDER BY recorded_at ASC;执行计划:
sql
EXPLAIN SELECT ...
-- type: ALL ← 全表扫描
-- rows: 260000000 ← 扫了2.6亿行
-- Extra: Using filesort全表扫描 2.6 亿行,还要排序,超时是必然的。
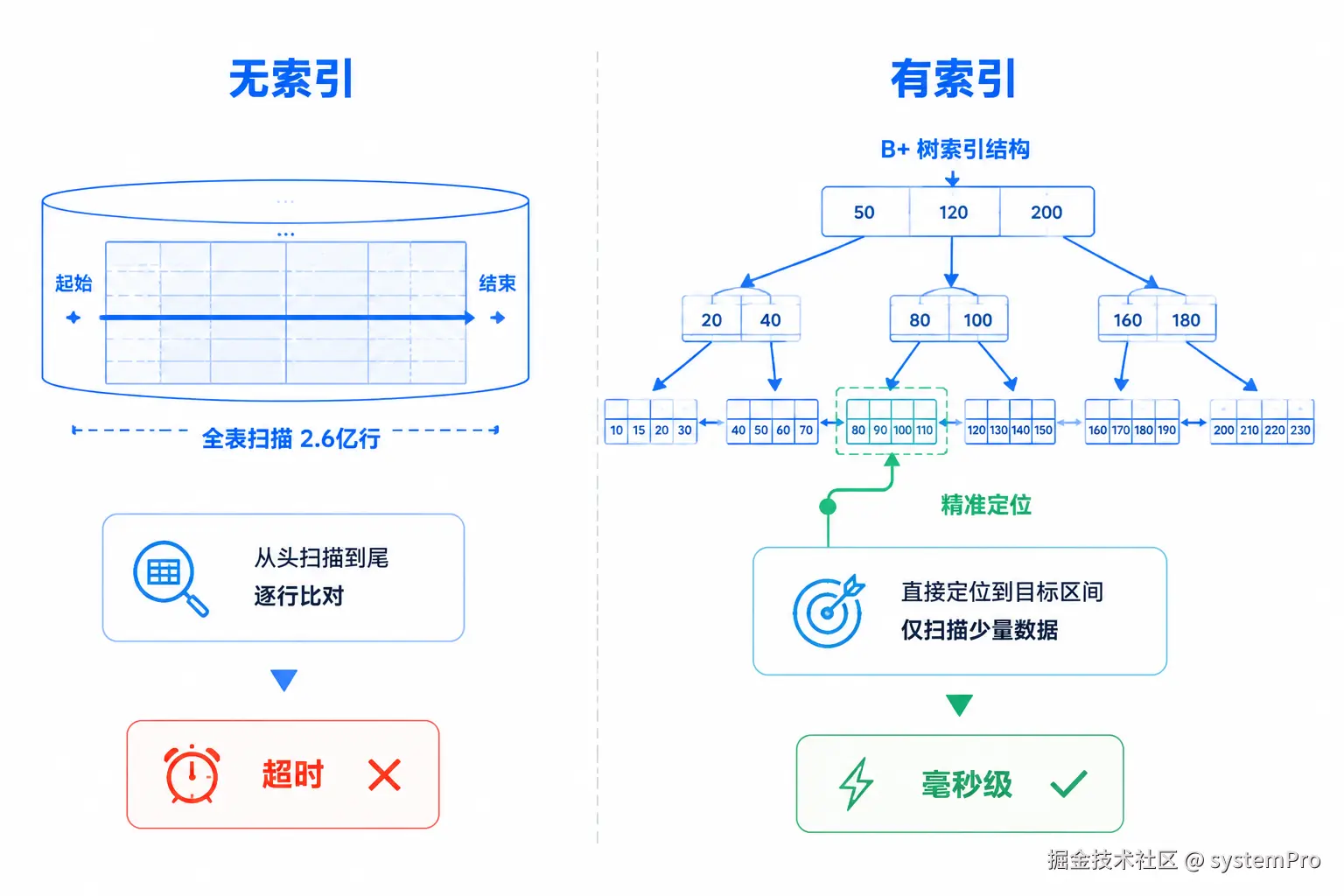
二、第一层优化:加索引
加哪个索引
先看查询条件:WHERE device_id = ? AND recorded_at BETWEEN ? AND ?
索引顺序是 (device_id, recorded_at),不能反过来:
sql
CREATE INDEX idx_device_time
ON device_power (device_id, recorded_at);为什么 device_id 在前?
因为 device_id 是等值查询,recorded_at 是范围查询。索引的最左前缀原则要求等值条件放前面,范围条件放后面,才能让两个条件都走索引。
如果反过来写 (recorded_at, device_id),范围查询之后索引就失效了,device_id 这个条件就没法用上。
sql
-- 加完索引再看执行计划
EXPLAIN SELECT ...
-- type: range ← 范围扫描,不再全表
-- rows: 525600 ← 只扫这台设备一年的数据量
-- Extra: Using index condition查询时间从超时降到了几秒。但几秒对一个接口来说还是太慢,继续优化。
三、第二层优化:分区表
为什么要分区
索引解决了扫描效率,但 2.6 亿行的表本身就是个问题------索引文件很大,维护成本高,写入也会变慢。
分区表把一张大表物理上拆成多个小文件,查询时只扫描相关分区,效果类似于"自动分表"但不需要改应用代码。
按月分区
sql
CREATE TABLE device_power (
id BIGINT NOT NULL AUTO_INCREMENT,
device_id VARCHAR(50) NOT NULL,
power DECIMAL(10,2) NOT NULL,
recorded_at DATETIME NOT NULL,
PRIMARY KEY (id, recorded_at) -- 分区键必须包含在主键里
)
PARTITION BY RANGE (MONTH(recorded_at)) (
PARTITION p01 VALUES LESS THAN (2),
PARTITION p02 VALUES LESS THAN (3),
PARTITION p03 VALUES LESS THAN (4),
PARTITION p04 VALUES LESS THAN (5),
PARTITION p05 VALUES LESS THAN (6),
PARTITION p06 VALUES LESS THAN (7),
PARTITION p07 VALUES LESS THAN (8),
PARTITION p08 VALUES LESS THAN (9),
PARTITION p09 VALUES LESS THAN (10),
PARTITION p10 VALUES LESS THAN (11),
PARTITION p11 VALUES LESS THAN (12),
PARTITION p12 VALUES LESS THAN MAXVALUE
);查询时 MySQL 自动做分区裁剪,只读对应月份的文件:
sql
-- 查3月数据,只扫 p03 分区
EXPLAIN SELECT ... WHERE recorded_at BETWEEN '2024-03-01' AND '2024-03-31'
-- partitions: p03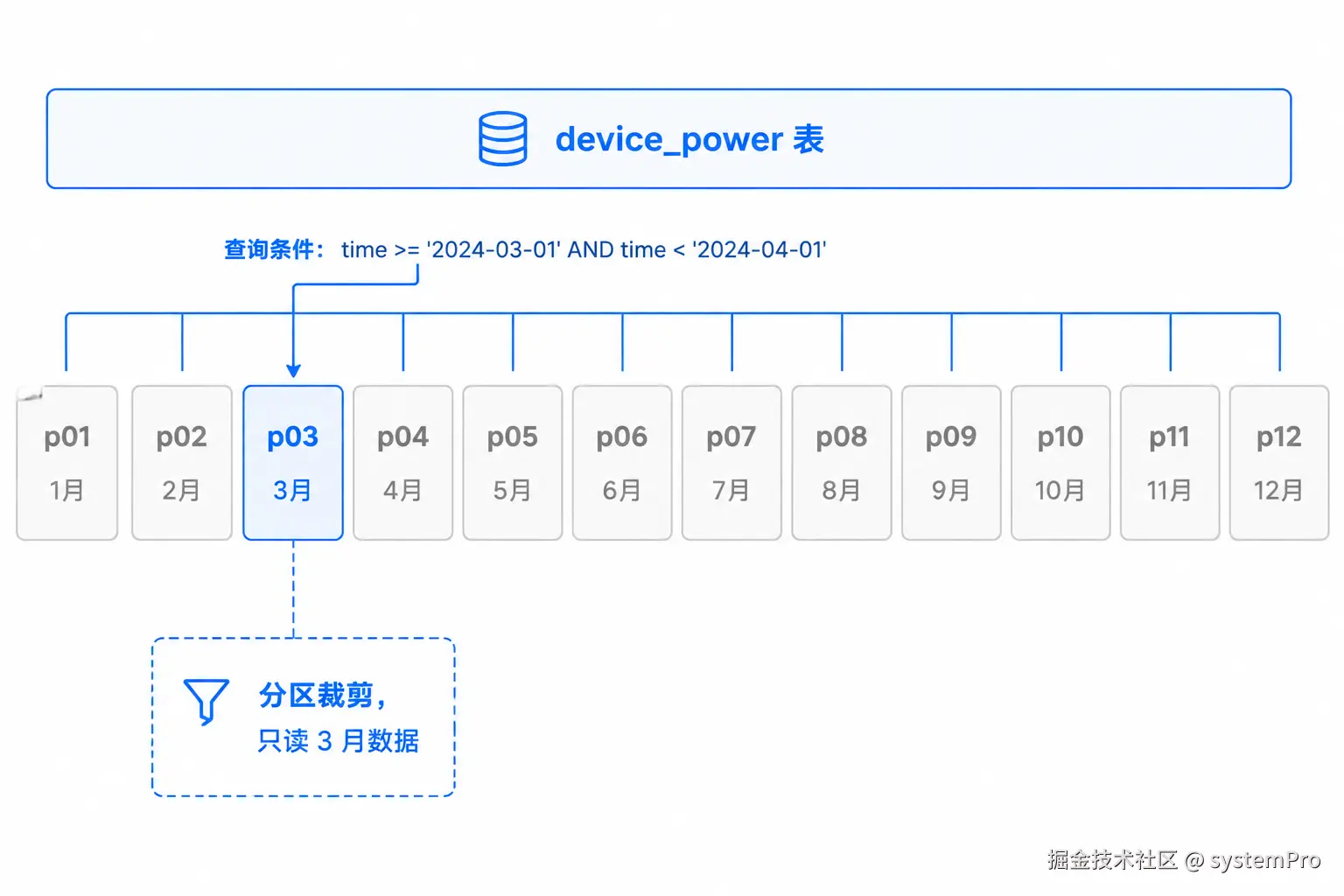
四、第三层优化:降采样
问题所在
查一年的功率曲线,每分钟一个点,一年有 525600 个点。
前端 ECharts 折线图能展示的点也就几百个,把 52 万个点全返回给前端:
- 网络传输慢
- 前端渲染卡
- 用户根本看不出区别
按时间粒度聚合
根据查询时间范围动态选择聚合粒度:
java
public String getAggregateInterval(LocalDateTime start, LocalDateTime end) {
long days = ChronoUnit.DAYS.between(start, end);
if (days <= 1) return "minute"; // 查1天,按分钟
if (days <= 7) return "hour"; // 查1周,按小时
if (days <= 90) return "day"; // 查3个月,按天
return "month"; // 查更长,按月
}对应的 SQL:
sql
-- 按小时聚合(查1周时使用)
SELECT
device_id,
DATE_FORMAT(recorded_at, '%Y-%m-%d %H:00:00') AS time_bucket,
AVG(power) AS avg_power,
MAX(power) AS max_power,
MIN(power) AS min_power
FROM device_power
WHERE device_id = 'PV_001'
AND recorded_at BETWEEN '2024-03-01' AND '2024-03-07'
GROUP BY device_id, time_bucket
ORDER BY time_bucket ASC;
sql
-- 按天聚合(查3个月时使用)
SELECT
device_id,
DATE(recorded_at) AS time_bucket,
AVG(power) AS avg_power,
MAX(power) AS max_power,
MIN(power) AS min_power
FROM device_power
WHERE device_id = 'PV_001'
AND recorded_at BETWEEN '2024-01-01' AND '2024-03-31'
GROUP BY device_id, time_bucket
ORDER BY time_bucket ASC;返回的数据点从 52 万降到几百,接口响应时间降到毫秒级。
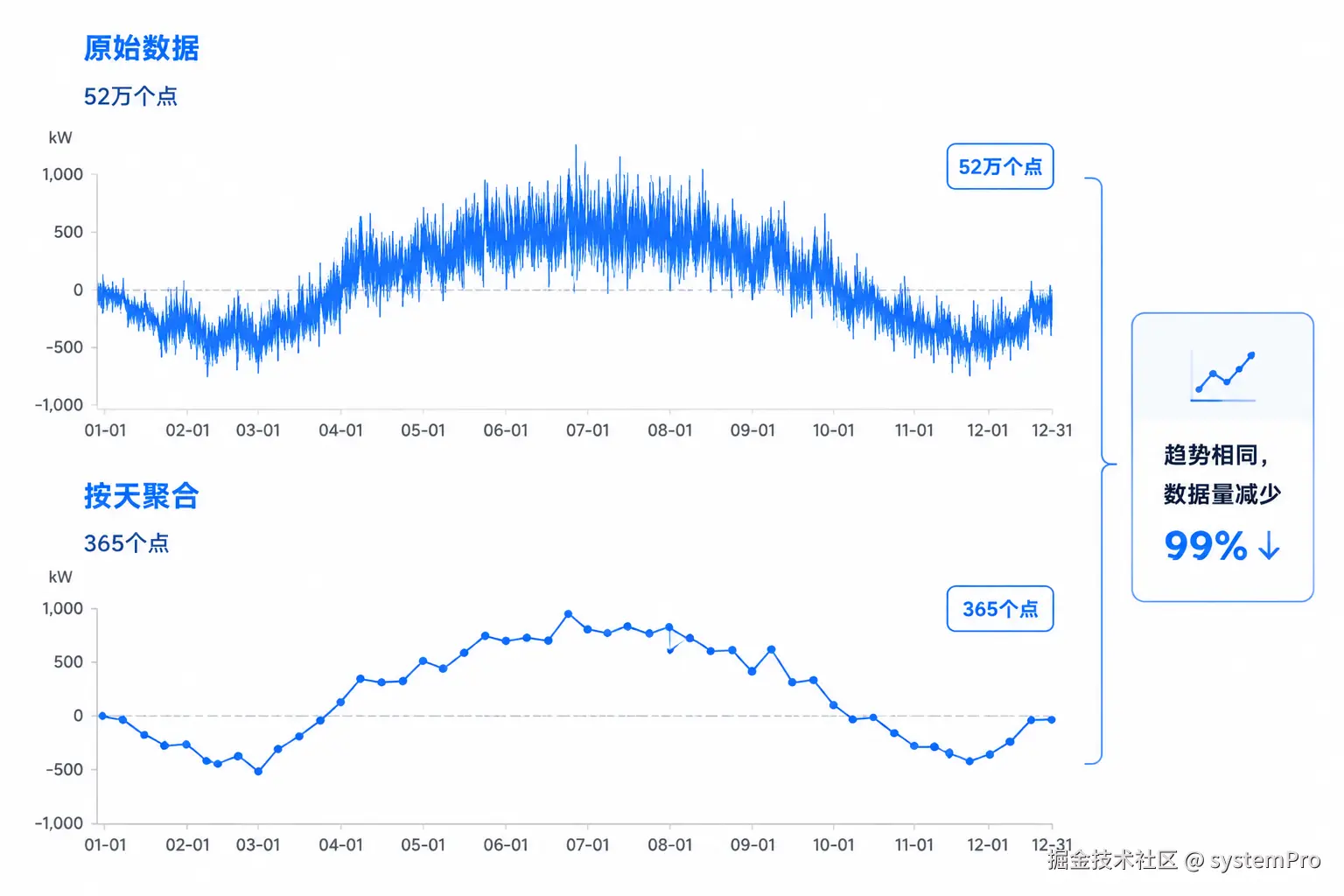
Java 层封装
java
@Service
public class PowerQueryService {
public List<PowerAggDTO> queryPowerCurve(
String deviceId,
LocalDateTime start,
LocalDateTime end) {
String interval = getAggregateInterval(start, end);
return switch (interval) {
case "minute" -> powerMapper.queryByMinute(deviceId, start, end);
case "hour" -> powerMapper.queryByHour(deviceId, start, end);
case "day" -> powerMapper.queryByDay(deviceId, start, end);
case "month" -> powerMapper.queryByMonth(deviceId, start, end);
default -> powerMapper.queryByDay(deviceId, start, end);
};
}
}五、第四层优化:冷热分离
为什么要冷热分离
经过前三层优化,查询性能已经够用了。但随着时间推移,数据会一直增长,表会越来越大。
实际业务里,用户 90% 的查询都是查近 30 天的数据,历史数据很少被查。把冷热数据混在一起是浪费:
- 热数据表小,读写都快
- 冷数据归档压缩,节省存储
表设计
sql
-- 热数据表:只存最近30天
CREATE TABLE device_power_hot (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
device_id VARCHAR(50) NOT NULL,
power DECIMAL(10,2) NOT NULL,
recorded_at DATETIME NOT NULL,
INDEX idx_device_time (device_id, recorded_at)
);
-- 冷数据表:历史归档
CREATE TABLE device_power_cold (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
device_id VARCHAR(50) NOT NULL,
power DECIMAL(10,2) NOT NULL,
recorded_at DATETIME NOT NULL,
INDEX idx_device_time (device_id, recorded_at)
) ROW_FORMAT=COMPRESSED; -- 压缩存储,节省空间Java 定时归档任务
java
@Component
public class DataArchiveJob {
// 每天凌晨2点执行
@Scheduled(cron = "0 0 2 * * ?")
public void archiveOldData() {
LocalDateTime cutoff = LocalDateTime.now().minusDays(30);
// 1. 把30天前的数据写入冷表
int archived = powerMapper.insertColdFromHot(cutoff);
// 2. 从热表删除
int deleted = powerMapper.deleteHotBefore(cutoff);
log.info("归档完成,归档{}条,删除{}条", archived, deleted);
}
}
sql
-- 归档SQL
INSERT INTO device_power_cold (device_id, power, recorded_at)
SELECT device_id, power, recorded_at
FROM device_power_hot
WHERE recorded_at < #{cutoff};
-- 删除热表旧数据
DELETE FROM device_power_hot
WHERE recorded_at < #{cutoff}
LIMIT 10000; -- 分批删,避免锁表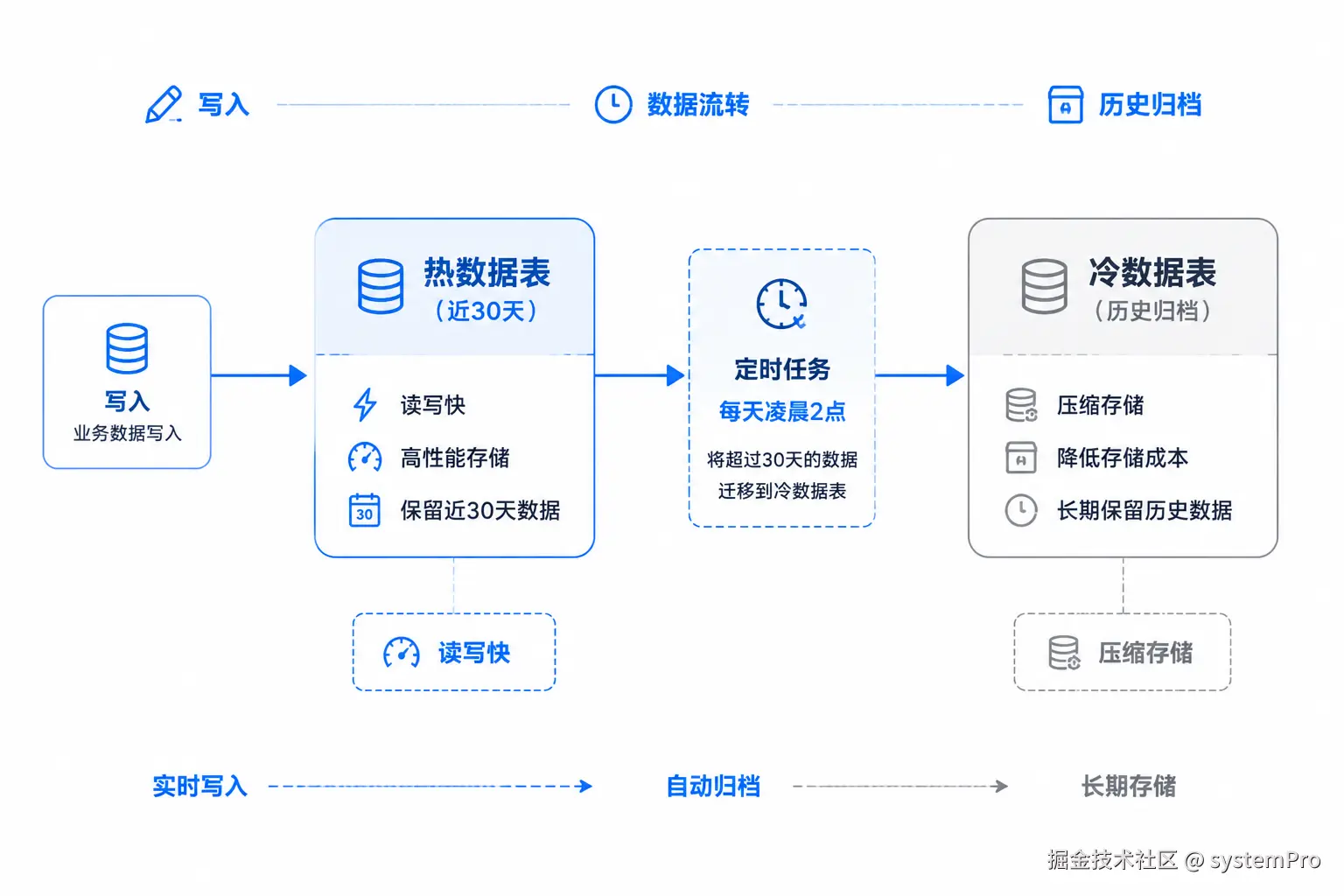
六、几千台设备同时上报怎么处理
前面说的都是查询优化,写入这块同样有坑。
问题场景
几千台设备每分钟同时上报,意味着每分钟有几千条 INSERT。高峰期会出现:
- 数据库连接池打满
- INSERT 排队等锁
- 写入延迟,数据积压
方案:MQTT + 消息队列 + 批量写入
sql
设备上报
↓ MQTT
消息队列(Kafka / RocketMQ)
↓ 消费者批量消费
批量 INSERT(每500条一批)
↓
数据库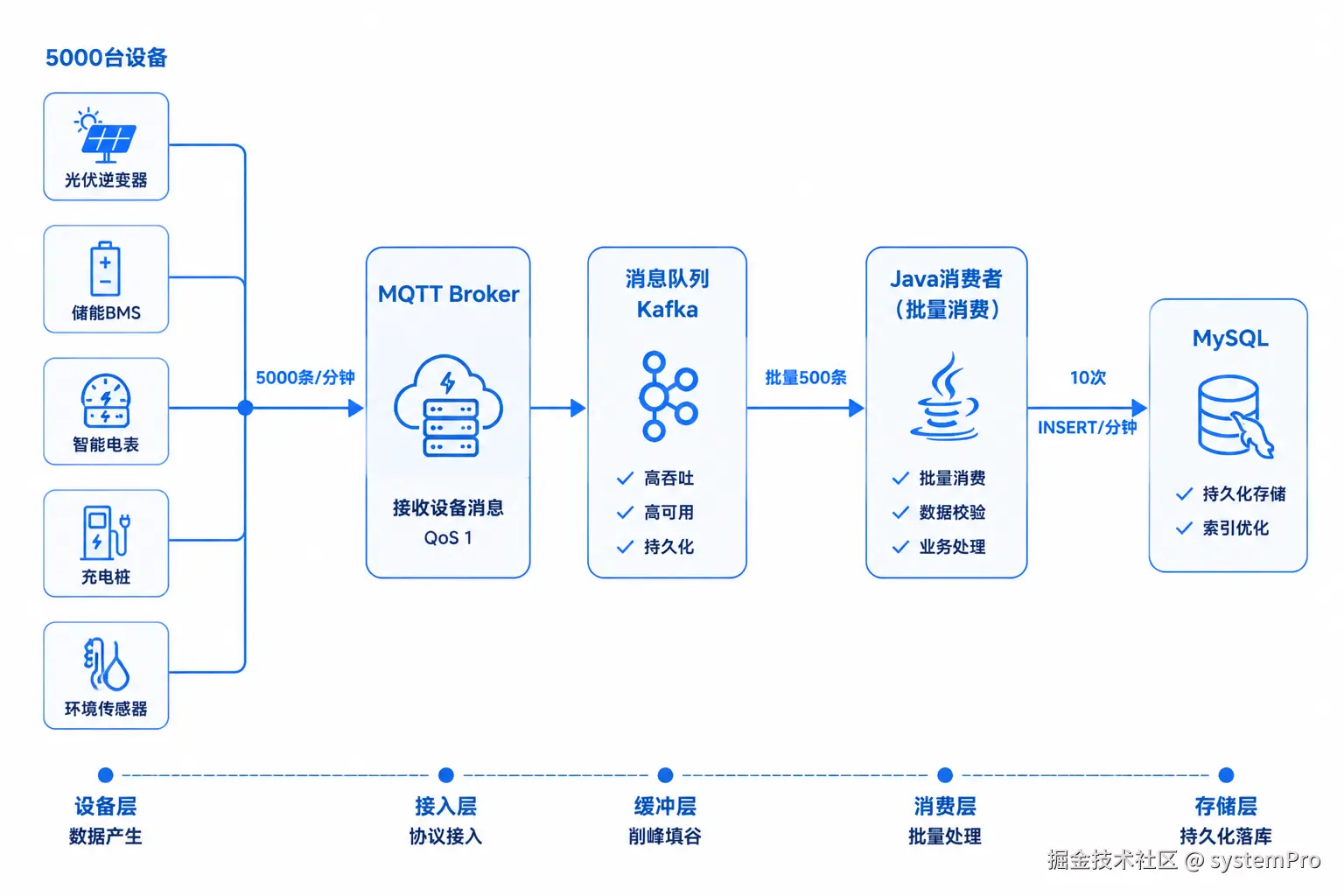
Java 批量写入实现
java
@Component
public class PowerDataConsumer {
private final List<PowerData> buffer = new CopyOnWriteArrayList<>();
// 监听 MQTT/Kafka 消息
@KafkaListener(topics = "device.power")
public void onMessage(PowerData data) {
buffer.add(data);
// 攒够500条批量写入
if (buffer.size() >= 500) {
flush();
}
}
// 兜底:每5秒强制写入一次,防止数据积压
@Scheduled(fixedDelay = 5000)
public void scheduledFlush() {
if (!buffer.isEmpty()) {
flush();
}
}
private synchronized void flush() {
if (buffer.isEmpty()) return;
List<PowerData> batch = new ArrayList<>(buffer);
buffer.clear();
powerMapper.batchInsert(batch);
}
}
xml
<!-- MyBatis 批量插入 -->
<insert id="batchInsert">
INSERT INTO device_power_hot (device_id, power, recorded_at)
VALUES
<foreach collection="list" item="item" separator=",">
(#{item.deviceId}, #{item.power}, #{item.recordedAt})
</foreach>
</insert>5000 台设备每分钟上报,变成 10 次批量 INSERT,数据库压力降低 500 倍。
七、优化效果对比
| 优化手段 | 查询时间 | 说明 |
|---|---|---|
| 无优化 | 超时 | 全表扫描2.6亿行 |
| 加索引 | 3-5秒 | 范围扫描,不再全表 |
| + 分区表 | 1-2秒 | 只扫相关分区 |
| + 降采样 | 50-200ms | 数据点从52万降到几百 |
| + 冷热分离 | 10-50ms | 热表数据量小,常驻内存 |
小结
IoT 时序数据的查询优化,核心思路就四层:
- 索引:解决扫描效率,联合索引顺序很关键
- 分区:解决大表问题,查询自动裁剪分区
- 降采样:解决数据量问题,按时间粒度聚合
- 冷热分离:解决长期增长问题,热数据保持小表
写入侧用消息队列 + 批量 INSERT,解决高并发上报问题。
这套方案在几百台设备的光储充项目里验证过,查一年数据从卡死到 50ms 以内。设备量更大的场景可以考虑 TDengine、InfluxDB 这类专门的时序数据库,但 MySQL 做好优化应付几千台设备完全够用。