安装
https://www.postgresql.org/download/linux/redhat/
# 1.安装PG官方yum源(修正拼写错误)
sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-9-x86_64/pgdg-redhat-repo-latest.noarch.rpm
# 2.安装PG18服务端
sudo dnf install -y postgresql18-server
# 3.初始化数据库实例
sudo /usr/pgsql-18/bin/postgresql-18-setup initdb
# 4.启动并开机自启
sudo systemctl start postgresql-18
sudo systemctl enable postgresql-18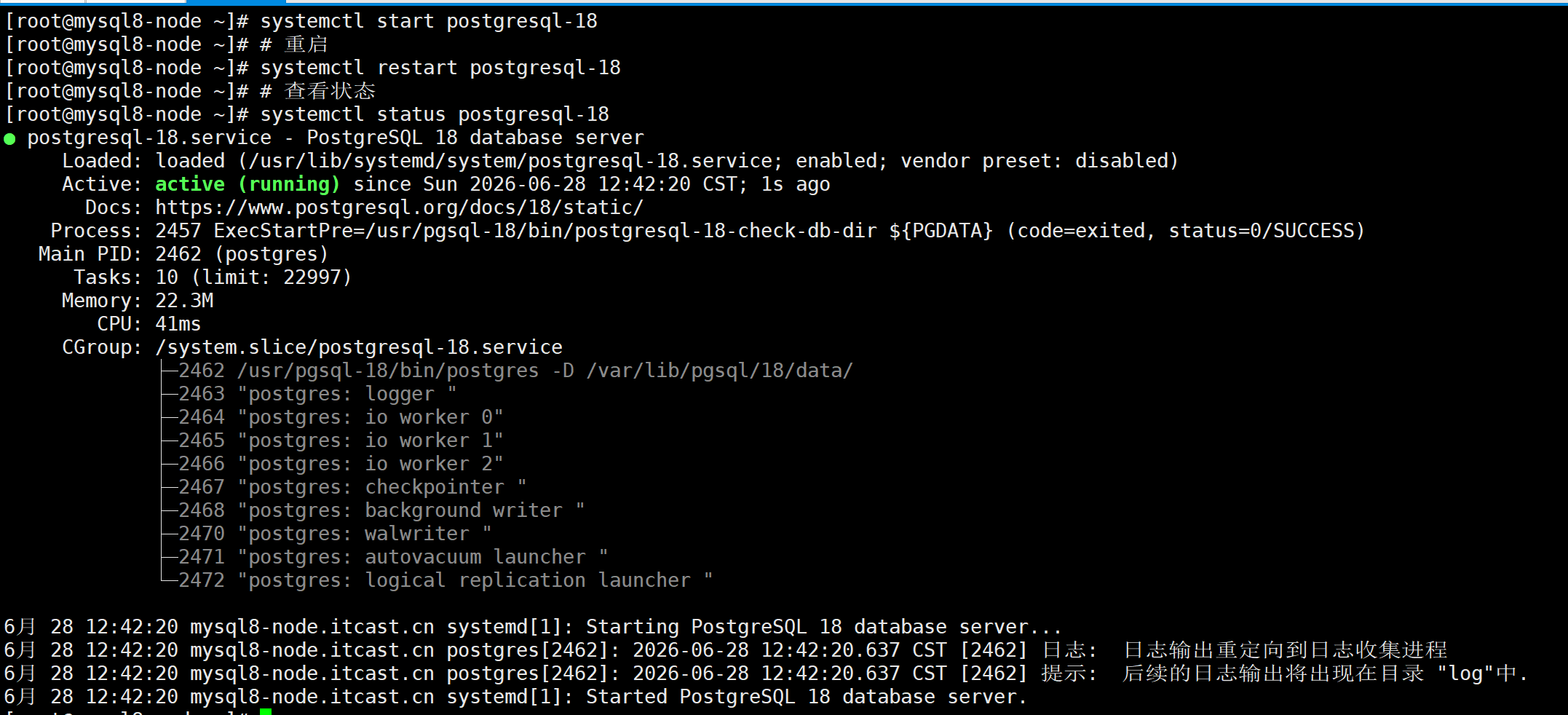
1.如果你的pgsql是通过yum安装,那么会自动帮你创建一个用户:postgres,并且当你的服务启动后,也会创建一个同名的数据库用户名
2.如果你是通过二进制方式安装的,那么需要手动创建postgres用户 sudo是暂时借用root的权限
-- 注意,这个是当你下载不成功的时候,需要换源
dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-9-x86_64/pgdg-redhat-repo-latest.noarch.rpm
# 替换为清华大学镜像源(了解)
# sed -i 's|download.postgresql.org/pub|mirrors.tuna.tsinghua.edu.cn/postgresql|g' /etc/yum.repos.d/pgdg-redhat-all.repo
# 安装
dnf install -y postgresql18-server
# 离线安装(了解)
# dnf --enablerepo=localrepo install postgresql18-server-18.1-1PGDG.rhel9.x86_64.rpm
# 初始化
/usr/pgsql-18/bin/postgresql-18-setup initdb
# 启动
systemctl start postgresql-18
systemctl status postgresql-18
systemctl enable postgresql-18
# 配置 PATH 环境变量
echo 'export PATH=/usr/pgsql-18/bin:$PATH' >> /etc/profile
source /etc/profile一键脚本
!/bin/bash
# 添加官方 postgresql 源
dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-9-x86_64/pgdg-redhat-repo-latest.noarch.rpm
# 替换为清华大学镜像源
sed -i 's|download.postgresql.org/pub|mirrors.tuna.tsinghua.edu.cn/postgresql|g' /etc/yum.repos.d/pgdg-redhat-all.repo
dnf install -y postgresql18-server
sed -i 's|Environment=PGDATA=.*|Environment=PGDATA=/opt/pgsql/data/|g' /usr/lib/systemd/system/postgresql-18.service
/usr/pgsql-18/bin/postgresql-18-setup initdb
systemctl enable postgresql-18
systemctl start postgresql-18
export PATH=/usr/pgsql-18/bin:$PATH使用与运维
进程状态管理
# 启动
systemctl start postgresql-18
# 重启
systemctl restart postgresql-18
# 查看状态
systemctl status postgresql-18
# 停止
systemctl stop postgresql-18
# 重载配置文件 ------ 并不是所有的配置文件都重载生效
systemctl reload postgresql-18
su - postgres
pg_ctl reload
ps aux|grep postgres
kill -1 进程号
psql -c 'SELECT pg_reload_conf()'
-c:可以不进入到客户端里面,就能执行pgsql语句查看日志
/var/lib/pgsql/18/data/log
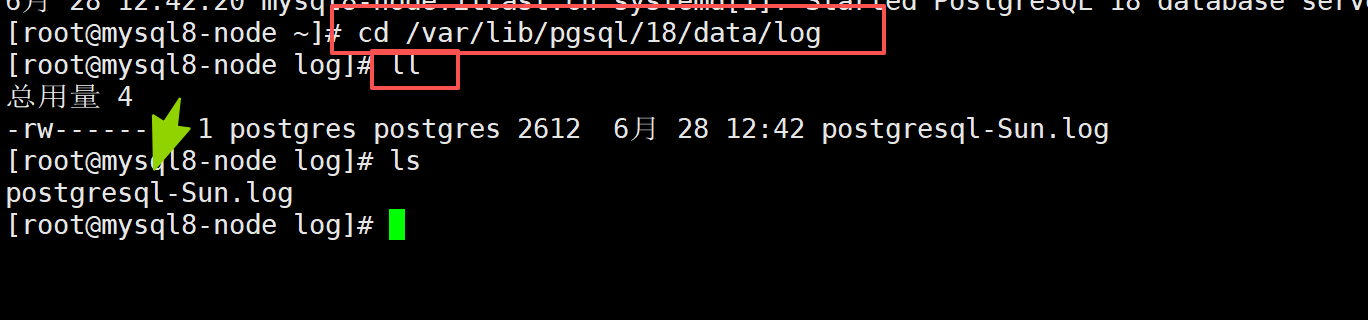
cat postgresql*.log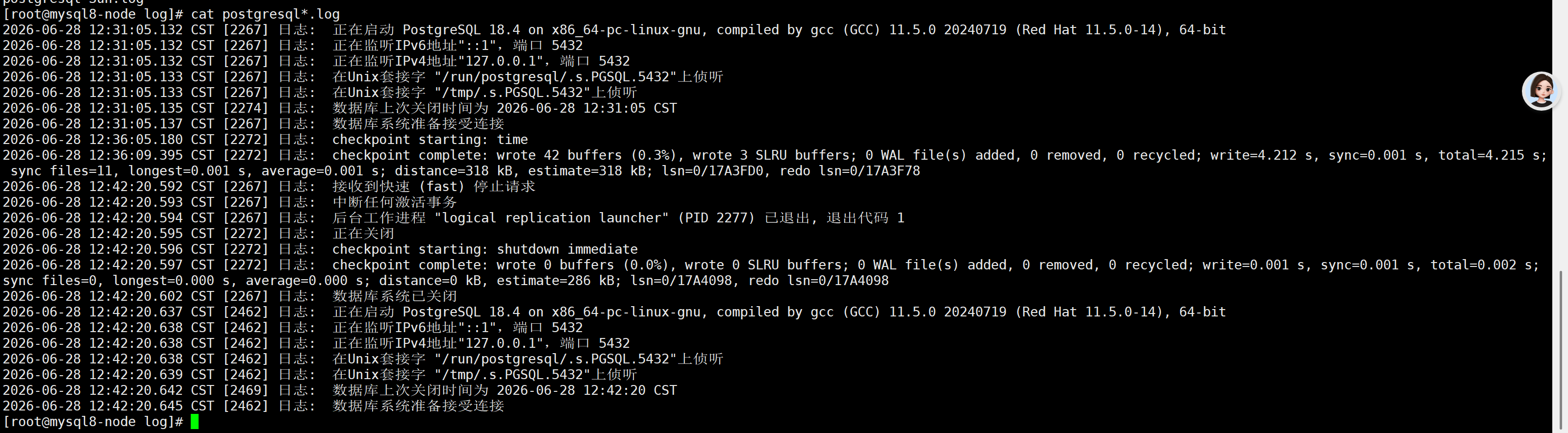
修改配置
vim /var/lib/pgsql/18/data/postgresql.conf
1,修改监听地址,接受外部链接,60行
listen_addresses = '*'2,自定义端口,5433
3,最大连接数改成1000
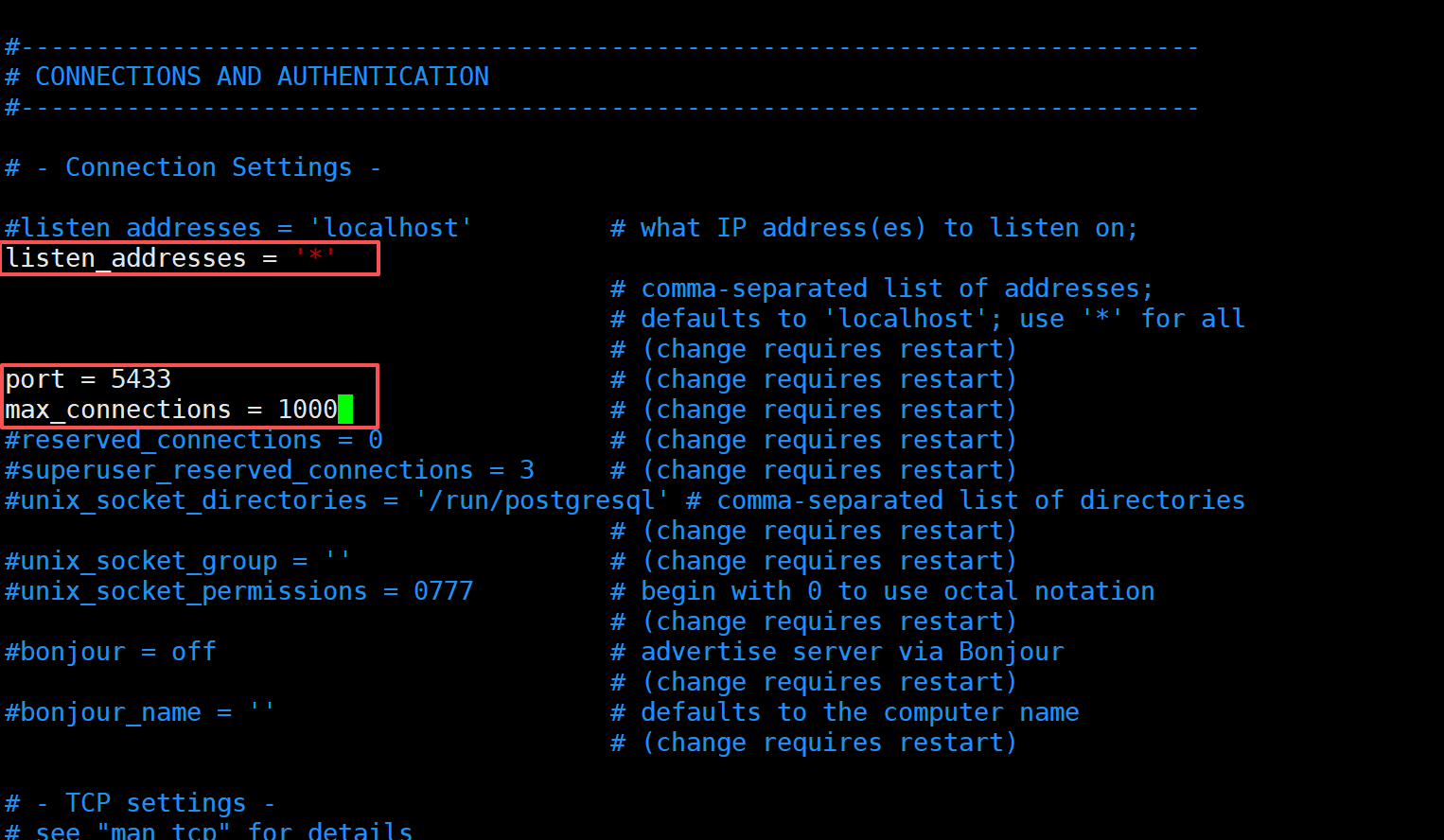
4,在504行,注释掉原来的,新加一行,修改日志文件名
log_filename = 'postgresql.log'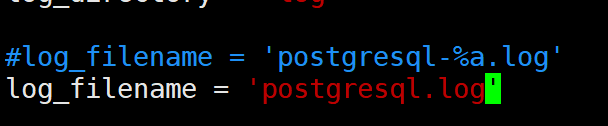
hba 权限
hba 即 host-based authentication------基于host的授权
pg_hba.conf(访问白名单,防火墙级权限)
文件作用:控制谁能连接数据库、用什么方式验证密码。
| 关键字 | 连接类型 | 使用场景 |
|---|---|---|
| local | Unix 本地套接字(无网络 TCP) | 本机在服务器内部登录,不需要 IP,比如 su - postgres; psql,不走网卡 |
| host | 普通 TCP 网络连接 | 两台虚拟机互相远程连接、本机用 127.0.0.1 连接,全部走 TCP 网络 |
| hostssl | 只允许带 SSL 加密的 TCP 连接 | 必须开启 SSL 加密,明文连接直接拒绝,生产外网安全用 |
| hostnossl | 只允许不加密的明文 TCP 连接 | 拒绝所有 SSL 加密连接,内网测试偶尔用 |
| hostgssenc | 只允许 GSSAPI 加密连接 | Kerberos 域认证专用,普通学习环境基本用不到 |
| hostnogssenc | 只允许不带 GSS 加密的连接 | 同上,企业域环境才会配置 |
格式统一:类型 数据库 用户名 地址/网段 认证方式
database指定可以访问哪一个数据库
all= 所有库- 写库名 = 仅允许这一个库
user指定哪个数据库账号可以登录
all= 所有账号- 写用户名 = 只放行该用户address(IP 网段) 只针对
host/hostssl
这类网络连接两种写法:
简写网段:
192.168.88.0/24IP + 子网掩码分开写:
192.168.88.0 255.255.255.0
- auth-method(认证方式)
scram-sha-256:PG10 + 新版默认,高强度密码加密(你现在用的)md5:旧版本加密trust:无条件免密登录(危险,仅本地测试用)ident:操作系统账号自动映射登录
实操
给 PostgreSQL 加上内网 IP 白名单,允许另一台虚拟机(192.168.88 网段)远程连接数据库。
# 切换到 root 用户
su - root
# 编辑文件
vim /var/lib/pgsql/18/data/pg_hba.conf
host all all 192.168.88.0/24 scram-sha-256host:TCP 网络远程连接- 第一个
all:允许访问所有数据库 - 第二个
all:允许所有数据库账号 192.168.88.0/24:只放行你两台主从虚拟机所在的内网网段scram-sha-256:使用密码加密校验
方法2
#追加配置
echo 'host all all 192.168.88.0/24 scram-sha-256' >> /var/lib/pgsql/18/data/pg_hba.conf修改数据目录
/var 属于系统分区。一旦业务数据暴涨,会把系统磁盘占满,直接导致服务器死机、SSH 连不上、系统崩溃。
解决办法:
把数据库数据迁移到独立的数据盘 /opt/pgsql/data。
-
系统盘只放操作系统、程序文件
-
数据盘单独存放所有库文件系统和数据库磁盘相互隔离,互不影响。
不操作 你的数据目录 还是在 /var/lib/pgsql/18/data
# 切换到 root 用户
su - root
# 创建目标路径
mkdir /opt/pgsql
# 通过 service 文件环境变量修改
vim /usr/lib/systemd/system/postgresql-18.service
Environment=PGDATA=/opt/pgsql/data/
# 或者
sed -i 's|Environment=PGDATA=.*|Environment=PGDATA=/opt/pgsql/data/|g' /usr/lib/systemd/system/postgresql-18.service
# 不使用环境变量的情况需要在配置文件修改
echo "data_directory = '/opt/pgsql/data'" >> /var/lib/pgsql/18/data/postgresql.conf
# 空目录需要重新初始化数据目录
chown -Rf postgres:postgres /opt/pgsql
su - postgres
initdb -D /opt/pgsql/data
# 或把原先的目录复制到新路径
su - root
systemctl stop postgresql-18
cp -r /var/lib/pgsql/18/data /opt/pgsql
chown -Rf postgres:postgres /opt/pgsql
# 重启
su - root
systemctl daemon-reload
systemctl restart postgresql-18
systemctl status postgresql-18
# 注意 尽量查看一下之前的5432端口是否还启动了,如果启动了,需要先kill掉,然后再重启 5433的客户端连接
本地连接cli
切换登录到 PostgreSQL 内置的系统用户 postgres,并且完整加载这个用户的环境变量。
su - postgrespsql 是 PostgreSQL 自带的客户端命令行工具,用来登录、操作数据库
psql- 在 root 用户直接敲
psql会报错。因为 root 不是 PG 内置账号,没有免密权限。必须切到postgres用户再执行。 - 只改了 pg_hba.conf,没改
listen_addresses='*',远程 psql 连接会拒绝。
psql= PG 的黑窗口客户端;先su - postgres,再敲psql,是本地登录 PG 的标准操作。
help
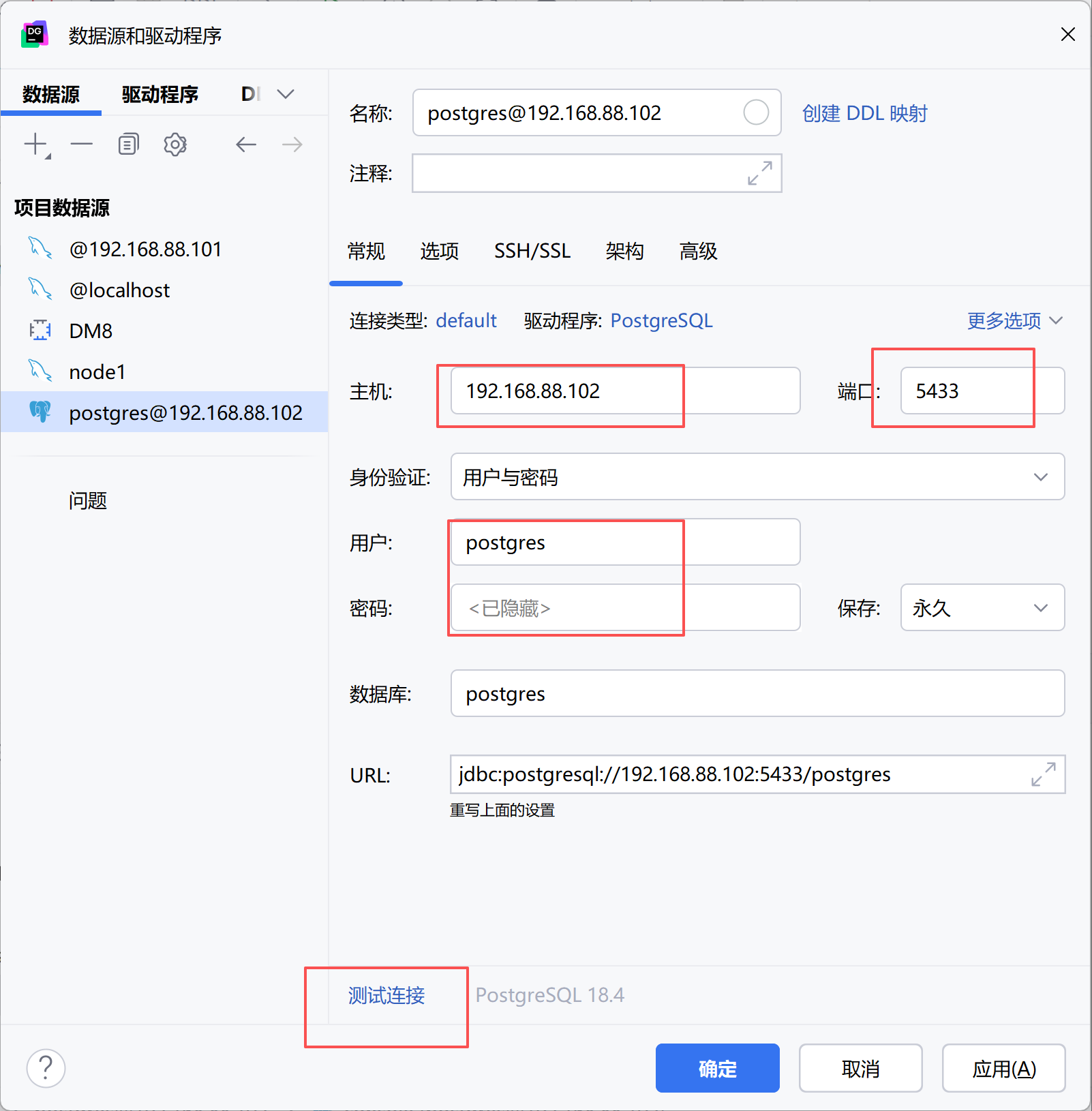
异地连接datagrip
添加远程权限
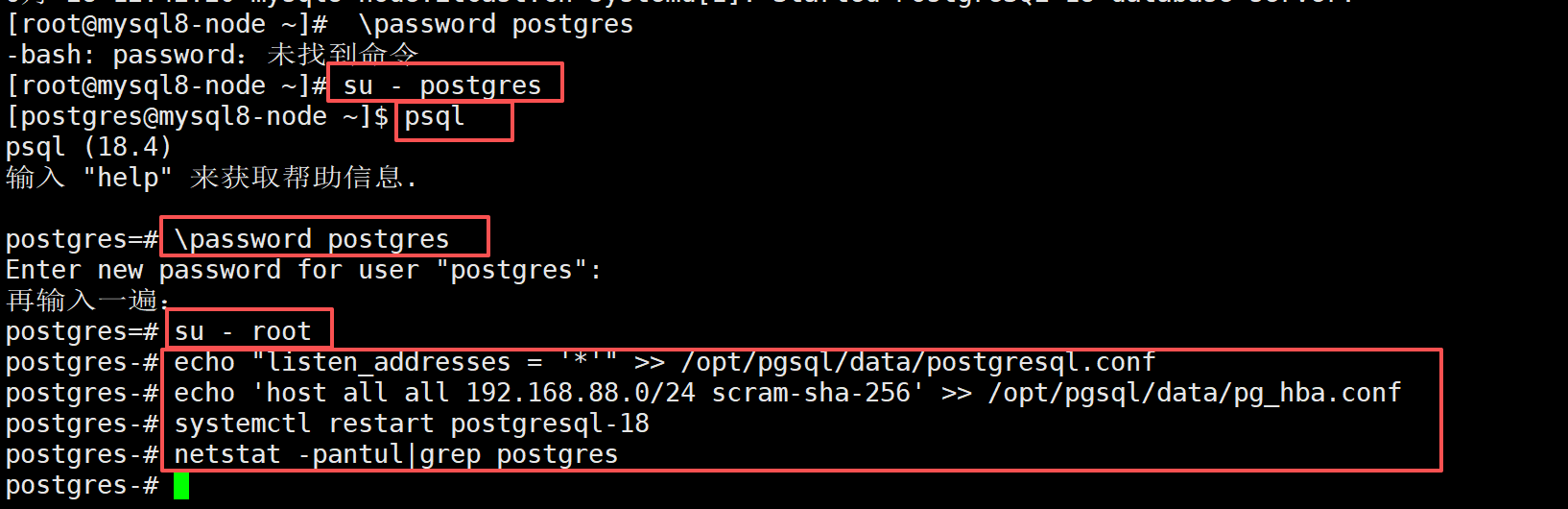
# 修改密码,输入两遍 PostgreSQL 作为密码
postgres=# \password postgres
exit
exit
#修改监听地址
echo "listen_addresses = '*'" >> /opt/pgsql/data/postgresql.conf
# 添加 hba 授权,Host-Based Authentication
echo 'host all all 192.168.88.0/24 scram-sha-256' >> /opt/pgsql/data/pg_hba.conf
# 重启数据库生效
systemctl restart postgresql-18
# 查看 pg 运行端口
netstat -pantul|grep postgres第一层 exit:退出 psql 控制台,回到 postgres 系统用户
第二层 exit:从 postgres 用户退回到 root 用户
https://jdbc.postgresql.org/download/ 手动下载驱动,可以直接下载 42.7.x
-- 等价于 psql 里的 \dt,列出所有用户表
SELECT
schemaname AS schema,
tablename AS name,
tableowner AS owner
FROM pg_tables
WHERE schemaname NOT IN ('pg_catalog', 'information_schema') -- 排除系统表
ORDER BY schemaname, tablename;
-- 1. 创建测试数据库(如果已存在则跳过)
CREATE DATABASE test_db;
-- 2. 连接到测试数据库(psql 中用 \c test_db,DataGrip 直接选中执行下方命令即可)
\c test_db; -- psql 专用,DataGrip 可忽略,直接切换左侧数据库上下文
-- 3. 创建简单测试表(仅含3个基础字段,方便查询)
CREATE TABLE test_table (
id SERIAL PRIMARY KEY, -- 自增主键
name VARCHAR(50), -- 字符串字段
age INT -- 数字字段
);
-- 4. 插入5条测试数据(少量数据,方便直观查询)
INSERT INTO test_table (name, age) VALUES
('张三', 25),
('李四', 30),
('王五', 28),
('赵六', 35),
('钱七', 22);
-- 5. 简单查询测试(核心验证步骤)
-- 5.1 查询表中所有数据
SELECT * FROM test_table;
-- 5.2 按条件查询(比如年龄大于25的记录)
SELECT name, age FROM test_table WHERE age > 25;
-- 5.3 统计总行数
SELECT COUNT(*) AS total_rows FROM test_table;
-- 5.4 按年龄排序查询
SELECT * FROM test_table ORDER BY age DESC;独立盘
-
没有迁移数据目录(现在实验环境默认)
-
数据目录:
/var/lib/pgsql/18/data/配置文件路径:/var/lib/pgsql/18/data/postgresql.conf
/var/lib/pgsql/18/data/pg_hba.conf -
已经迁移到独立盘(命令里的环境)
-
数据目录:
/opt/pgsql/data/配置文件路径:/opt/pgsql/data/postgresql.conf
/opt/pgsql/data/pg_hba.conf
1. 什么叫独立盘
一台服务器会挂两块硬盘:
- 磁盘 A:装 CentOS 系统(系统盘,对应目录
/、/var) - 磁盘 B:专门只放数据库文件(数据盘,挂载到
/opt)
把 PG 数据放在第二块独立磁盘上,就叫 "独立盘存放数据"。
2. 为什么生产要这么干?
PG 默认数据目录:/var/lib/pgsql/18/data这个文件夹在系统盘里。如果业务数据越来越大,把系统磁盘占满,整台 Linux 系统直接卡死、SSH 都连不上。
解决方案:把数据库整体搬家到另一块单独的数据盘 /opt/pgsql/data。系统盘只跑系统,数据盘只存库文件,互不挤占空间。
命令与SQL
su - postgres
psql列出和 MySQL 的对应关系,方便记忆理解。
| PostgreSQL | MySQL | |
|---|---|---|
| 用户 | role | user |
| 模式 | schema | 没有 |
常用命令
-- 选项,每个命令后边都可以加
S = 显示系统对象
x = 展开模式 -- 相当于 MySQL \G
+ = 额外细节
\dS:列出所有用户表 + 系统表(即包含 pg_catalog 和 information_schema 中的对象)
\dS+:额外显示更多细节(如表大小、描述等),相当于组合了 S 和 + 选项
\dx:展开模式显示扩展信息(但注意 \dx 本身是列出已安装扩展的命令,不要混淆)
\dSx:以展开模式列出所有系统对象(每行一个字段)
-- 列出对象:表、视图、序列
postgres=# \d
Did not find any relations. -- 表、视图、序列 统称为 relation
postgres=# \d
List of relations
Schema | Name | Type | Owner
--------+-------------------+----------+----------
public | test_table | table | postgres
public | test_table_id_seq | sequence | postgres
(2 rows)
postgres=#
-- 列出数据库
postgres=# \l
List of databases
Name | Owner | Encoding | Locale Provider | Collate | Ctype | Locale | ICU Rules | Access privileges
-----------+----------+----------+-----------------+-------------+-------------+--------+-----------+-----------------------
postgres | postgres | UTF8 | libc | en_US.UTF-8 | en_US.UTF-8 | | |
template0 | postgres | UTF8 | libc | en_US.UTF-8 | en_US.UTF-8 | | | =c/postgres +
| | | | | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | libc | en_US.UTF-8 | en_US.UTF-8 | | | =c/postgres +
| | | | | | | | postgres=CTc/postgres
(3 rows)
postgres=# \l
List of databases
Name | Owner | Encoding | Locale Provider | Collate | Ctype | Locale
| ICU Rules | Access privileges
-----------+----------+----------+-----------------+-------------+-------------+--------
+-----------+-----------------------
postgres | postgres | UTF8 | libc | en_US.UTF-8 | en_US.UTF-8 |
| |
template0 | postgres | UTF8 | libc | en_US.UTF-8 | en_US.UTF-8 |
| | =c/postgres +
| | | | | |
| | postgres=CTc/postgres
template1 | postgres | UTF8 | libc | en_US.UTF-8 | en_US.UTF-8 |
| | =c/postgres +
| | | | | |
| | postgres=CTc/postgres
test_db | postgres | UTF8 | libc | en_US.UTF-8 | en_US.UTF-8 |
| |
(4 rows)
postgres=#
-- 列出模式
postgres=# \dn
List of schemas
Name | Owner
--------+-------------------
public | pg_database_owner
(1 row)
-- 列出表
postgres=# \dt
Did not find any tables.
-- 列出函数
postgres=# \df
List of functions
Schema | Name | Result data type | Argument data types | Type
--------+------+------------------+---------------------+------
(0 rows)
-- 列出视图
postgres=# \dv
Did not find any views.
-- 查看函数定义
\sf[+] FUNCNAME
-- 查看视图定义
\sv[+] VIEWNAME
-- 列出表空间
postgres=# \db
List of tablespaces
Name | Owner | Location
------------+----------+----------
pg_default | postgres |
pg_global | postgres |
(2 rows)
-- 列出角色
test_db=# \dg
List of roles
Role name | Attributes
-----------+------------------------------------------------------------
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS
postgres=# \du
List of roles
Role name | Attributes
-----------+------------------------------------------------------------
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS
-- 查看默认配置
postgres=# \dconfig
List of non-default configuration parameters
Parameter | Value
----------------------------+---------------------------------
application_name | psql
client_encoding | UTF8
config_file | /opt/pgsql/data/postgresql.conf
data_directory | /opt/pgsql/data
default_text_search_config | pg_catalog.english
hba_file | /opt/pgsql/data/pg_hba.conf
ident_file | /opt/pgsql/data/pg_ident.conf
lc_messages | en_US.UTF-8
lc_monetary | en_US.UTF-8
lc_numeric | en_US.UTF-8
lc_time | en_US.UTF-8
listen_addresses | *
log_filename | postgresql-%a.log
logging_collector | on
log_rotation_size | 0
log_timezone | Asia/Shanghai
log_truncate_on_rotation | on
TimeZone | Asia/Shanghai
(18 rows)
-- 断开退出
\q -- 或 Ctrl+D
-- 创建数据库
[postgres@pg ~]$ psql
psql (18.3)
Type "help" for help.
postgres=# CREATE DATABASE itheima;
-- 切换数据库
postgres=# \c itheima
You are now connected to database "itheima" as user "postgres".
-- 查看连接信息,相当于 MySQL 的 \s
postgres=# \conninfo
Connection Information
Parameter | Value
----------------------+-----------------
Database | postgres
Client User | postgres
Socket Directory | /run/postgresql
Server Port | 5432
Options |
Protocol Version | 3.0
Password Used | false
GSSAPI Authenticated | false
Backend PID | 8206
SSL Connection | false
Superuser | on
Hot Standby | off
(12 rows)
-- 查看连接编码
postgres=# \encoding
UTF8
-- 设置连接编码
postgres=# \encoding GBK -- 中文编码
-- 支持的编码 https://www.postgresql.org/docs/current/multibyte.html#MULTIBYTE-CHARSET-SUPPORTED
-- 修改密码
postgres=# \password postgres -- 不带角色名默认修改当前角色
Enter new password for user "postgres":
Enter it again:DCL角色管理
-- 创建角色
postgres=# CREATE ROLE itheima;
CREATE ROLE
-- 查看角色
postgres=# \du
-- 删除角色
postgres=# DROP ROLE itheima;
DROP ROLE
--在itheima用户:展示该用户的权限、成员关系,不存在该用户:无输出,不会报错
psql -U postgres -c "\du itheima"
-- 查看角色,相当于 MySQL 的 select user from mysql.user;
SELECT rolname FROM pg_roles;
-- 查看拥有某权限的角色
SELECT rolname FROM pg_roles WHERE rolcanlogin;创建授权语句
GRANT island TO joe WITH INHERIT TRUE, SET FALSE;- INHERIT
INHERIT TRUE:子角色自动拥有父角色的权限,不用手动切换;INHERIT FALSE:必须手动执行SET ROLE才能拿到父角色权限,不会自动继承。
- SET
SET TRUE:允许执行SET ROLE xxx切换到此角色;SET FALSE:只允许自动继承权限,禁止手动切换身份。
角色组
在PostgreSQL中,角色(ROLE)和角色组(GROUP ROLE)本质上是同一个概念:
都是使用 CREATE ROLE 命令创建的数据库对象。一个角色可以被授予其他角色,从而成为一个"组角色",而被授予的角色则成为该组的成员。这种设计非常灵活,但也容易让人混淆,尤其是当我们需要在逻辑上区分"用户角色"和"组角色"时。
-- 创建角色组
CREATE ROLE 角色组名;
-- 赋予角色组权限到角色,也相当于往角色组添加角色
GRANT 角色组名 TO 角色1, ... ;
REVOKE 角色组名 FROM 角色2, ... ;
-- 实操
postgres=# CREATE ROLE itheima;
CREATE ROLE
-- 创建角色 devops
postgres=# create role devops;
CREATE ROLE
-- 将角色赋值给itheima用户
postgres=# grant devops to itheima;
GRANT ROLE
-- 将角色从itheima用户移除
postgres=# revoke devops from itheima;
REVOKE ROLE
-- 删除角色组
postgres=# drop role devops;
DROP ROLE-- owner 转移
-- 1. 创建接收角色
CREATE ROLE new_owner;
-- 2. 处理itheima库
\c itheima
REASSIGN OWNED BY itheima TO new_owner;
DROP OWNED BY itheima;
# 切换到 itheima 数据库,将 该数据库中 属于 itheima 的所有对象(表、序列、函数等)的所有权转给 new_owner,然后删除 itheima 在该数据库中拥有的剩余对象(通常此时已无对象,主要用于清理权限)。
-- 3. 处理test_db库
\c test_db
REASSIGN OWNED BY itheima TO new_owner;
DROP OWNED BY itheima;
-- 4. 处理postgres库
\c postgres
REASSIGN OWNED BY itheima TO new_owner;
DROP OWNED BY itheima;
-- 5. (可选)转移itheima库所有权
ALTER DATABASE itheima OWNER TO new_owner;
-- 6. 删除角色
DROP ROLE itheima;
-- 7. 查看所有者
SELECT datname AS "数据库名", pg_get_userbyid(datdba) AS "当前所有者"FROM pg_database WHERE datname IN ('itheima', 'test_db', 'postgres');角色组实操
-- ==============================================
-- 前置说明:
-- 1. 需以 postgres 超级用户先执行(创建角色)
-- 2. 核心验证 PG 角色继承/切换/权限限制规则
-- 3. 关键规则:INHERIT 控制自动权限,SET 控制角色切换,成员关系决定能否切换
-- ==============================================
-- 1. 清理残留角色(避免权限干扰)
DROP ROLE IF EXISTS joe, admin, wheel, island;
-- 2. 重建角色(明确权限属性,避免默认值歧义)
CREATE ROLE joe LOGIN; -- 仅可登录,无超级权限(核心测试角色)
CREATE ROLE admin NOLOGIN; -- 不可登录,普通角色
CREATE ROLE wheel NOLOGIN; -- 不可登录,普通角色
CREATE ROLE island NOLOGIN; -- 不可登录,普通角色
-- 3. 精准授权(标注每个参数的作用)
GRANT admin TO joe WITH INHERIT TRUE; -- joe 自动继承 admin 权限(无需SET ROLE)
GRANT wheel TO admin WITH INHERIT FALSE; -- admin 需手动SET ROLE才拥有wheel权限(仅成员关系)
GRANT island TO joe WITH INHERIT TRUE, SET FALSE; -- joe 自动继承island权限,但禁止切换到island
-- 4. 切换到 joe 登录(模拟真实登录场景,psql专用)
\c - joe
-- 提示:You are now connected to database "postgres" as user "joe".
-- ========== 场景1:joe 刚登录(未切换角色) ==========
-- 查看当前会话/有效角色
SELECT session_user AS "登录角色", current_user AS "当前角色", current_role AS "有效角色";
-- 输出:登录角色=joe,当前角色=joe,有效角色=joe
-- 验证继承的权限(admin/island有权限,wheel无)
SELECT
pg_has_role('admin', 'USAGE')::text AS "拥有admin权限",
pg_has_role('island', 'USAGE')::text AS "拥有island权限",
pg_has_role('wheel', 'USAGE')::text AS "拥有wheel权限";
-- 预期结果:true, true, false
-- 结论:joe 自动继承 admin/island 权限,无 wheel 权限(admin未自动继承wheel)
-- ========== 场景2:joe 切换到 admin 角色 ==========
SET ROLE admin;
SELECT current_role AS "有效角色"; -- 输出:admin
-- 验证切换后权限(仅保留admin自身权限)
SELECT
pg_has_role('joe', 'USAGE')::text AS "拥有joe权限",
pg_has_role('island', 'USAGE')::text AS "拥有island权限",
pg_has_role('wheel', 'USAGE')::text AS "拥有wheel权限";
-- 预期结果:false, false, false
-- 结论:SET ROLE后仅保留目标角色权限,原继承权限暂时失效
-- ========== 场景3:admin 切换到 wheel 角色(关键修正) ==========
SET ROLE wheel;
-- 执行结果:成功(因admin是wheel成员,INHERIT FALSE仅控制自动权限,不限制切换)
SELECT current_role AS "有效角色"; -- 输出:wheel
-- 补充:若需让此步骤报错,需执行 REVOKE wheel FROM admin; 切断成员关系
-- ========== 场景4:切回 joe 原始角色(三种等价方式) ==========
-- 方式1:直接指定角色(推荐)
SET ROLE joe;
-- 方式2:重置为登录角色(等价)
-- SET ROLE NONE;
-- 方式3:RESET命令(等价)
-- RESET ROLE;
SELECT current_role AS "有效角色"; -- 输出:joe
-- 验证权限恢复
SELECT
pg_has_role('admin', 'USAGE')::text AS "拥有admin权限",
pg_has_role('island', 'USAGE')::text AS "拥有island权限";
-- 预期结果:true, true(恢复继承权限)
-- ========== 场景5:尝试切换到 island 角色(验证 SET FALSE) ==========
SET ROLE island;
-- 执行结果:报错 ERROR: permission denied to set role "island"
-- 原因:GRANT时指定 SET FALSE,禁止joe切换到island角色(即使继承权限)
-- ========== 可选:让场景3切换wheel报错的配置(按需执行) ==========
-- \c - postgres -- 切回超级用户
-- REVOKE wheel FROM admin; -- 切断admin与wheel的成员关系
-- \c - joe
-- SET ROLE admin;
-- SET ROLE wheel; -- 此时会报错:permission denied to set role "wheel"
su - postgres
psql
DROP ROLE IF EXISTS joe, admin, wheel, island;DDL
#查询所有数据库
SELECT datname FROM pg_database;
#创建基础数据库
CREATE DATABASE itheima;
#删除数据库(注意:删除前确保数据库无连接)
DROP DATABASE IF EXISTS itheima;
#创建数据库并指定所有者(需先确保用户 itheima 存在,不存在则先创建:CREATE ROLE itheima LOGIN;)
CREATE DATABASE itheima OWNER itheima;
#基于模板创建数据库(template0 是干净的模板,避免继承原模板的多余配置)
CREATE DATABASE itheima0 TEMPLATE template0;
-- 6. 修改数据库配置(例如禁用 GEQO 优化器)
-- geqo 是 Genetic Query Optimizer(遗传查询优化器)的缩写,是 PostgreSQL 中专门用于优化 复杂多表连接 查询的模块。
ALTER DATABASE itheima SET geqo TO off;
-- 查询itheima数据库的geqo配置
SELECT
datname AS 数据库名,
unnest(setconfig) AS 配置项 -- 展开配置数组
FROM pg_db_role_setting
JOIN pg_database ON pg_db_role_setting.setdatabase = pg_database.oid
WHERE datname = 'itheima';
-- 重置数据库配置
ALTER DATABASE itheima RESET geqo;
-- === 表空间(Tablespace) 操作 ===
-- 1. 创建表空间(注意:/opt/pgsql/data1 目录需存在且PostgreSQL用户postgres有读写权限)
CREATE TABLESPACE space1 LOCATION '/opt/pgsql/data1';
-- 查看表空间 \db 或者 \db+ space1;
-- 删除表空间 drop TABLESPACE space1;
-- 2. 在指定表空间创建表
CREATE TABLE foo(i int) TABLESPACE space1;
-- 3. 查询 space1 表空间的基本信息
SELECT
spcname AS 表空间名,
pg_tablespace_location(oid) AS 存储路径,
spcowner::regrole AS 所有者
FROM pg_tablespace
WHERE spcname = 'space1';
-- 4. 查询所有表空间(包含名称、所有者、存储路径)
SELECT spcname, spcowner::regrole, pg_tablespace_location(oid) FROM pg_tablespace;
SELECT table_name
FROM information_schema.tables
WHERE table_schema = 'pg_catalog'
AND table_name = 'pg_tablespace';
\d pg_tablespace;
-- === 表(Table) 基础操作 ===
-- 1. 创建基础表
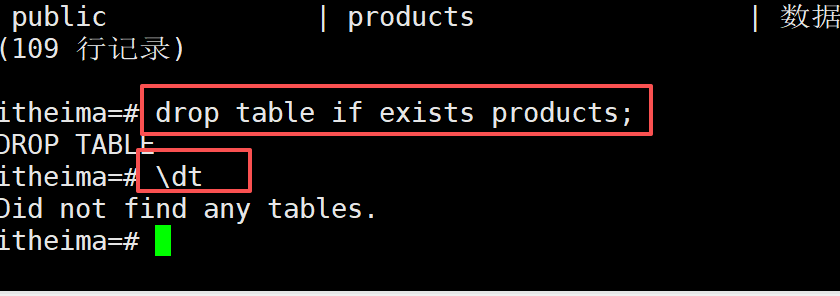
CREATE TABLE IF NOT EXISTS products (
product_no integer,
name text,
price numeric
);
-- 查看表结构
\d products;
-- 2. 删除表(IF EXISTS 避免表不存在时报错)
DROP TABLE IF EXISTS products;
-- 3. 创建带默认值的表
CREATE TABLE IF NOT EXISTS products (
product_no integer,
name text,
price numeric DEFAULT 1999.00 -- 价格默认值 1999.00
);
-- 批量插入3条混合数据
INSERT INTO products (product_no, name, price)
VALUES
(1, 'OPPO Find X8', DEFAULT), -- 显式使用默认值 1999.00
(2, '荣耀Magic 7', 3999.00),
(3, '一加14', 2999.99);
-- 查询插入结果
SELECT * FROM products;
-- 4. 创建带自增字段的表(推荐使用 GENERATED ALWAYS AS IDENTITY,比 SERIAL 更规范)
CREATE TABLE IF NOT EXISTS people (
id bigint GENERATED ALWAYS AS IDENTITY, -- 强制自增,无法手动赋值
-- id bigint GENERATED BY DEFAULT AS IDENTITY, -- 可手动赋值,无赋值时自增
name varchar(32),
address varchar(255)
);
-- 测试自增字段插入数据
INSERT INTO people (name, address) VALUES ('A', 'foo');
INSERT INTO people (name, address) VALUES ('B', 'bar');
INSERT INTO people (id, name, address) VALUES (DEFAULT, 'C', 'baz');
-- 查询插入结果
SELECT * FROM people;
-- 5. 创建带生成列的表(生成列由其他字段计算得出,不可手动修改)
CREATE TABLE IF NOT EXISTS people_ext (
id bigint GENERATED ALWAYS AS IDENTITY,
name varchar(32),
height_cm numeric, -- 身高(厘米)
height_in numeric GENERATED ALWAYS AS (height_cm / 2.54) STORED -- 身高(英寸),STORED 表示存储在磁盘
);
-- 插入测试数据
INSERT INTO people_ext (name, height_cm) VALUES
('Alice', 170), -- 身高 170 cm → 约 66.93 in
('Bob', 180), -- 180 cm → 约 70.87 in
('Charlie', 165.5), -- 165.5 cm → 约 65.16 in
('Diana', 175), -- 175 cm → 约 68.90 in
('Eve', NULL), -- 身高未知,height_in 也为 NULL
('Frank', 190), -- 190 cm → 约 74.80 in
('Grace', 155), -- 155 cm → 约 61.02 in
('Henry', 200.3), -- 200.3 cm → 约 78.86 in
('Ivy', 160), -- 160 cm → 约 62.99 in
('Jack', 150); -- 150 cm → 约 59.06 in
-- 查看测试数据
select * from people_ext;
-- === 表结构修改(ALTER TABLE) ===
-- 1. 给表添加字段
ALTER TABLE products ADD COLUMN IF NOT EXISTS description text;
-- 2. 删除表字段
ALTER TABLE products DROP COLUMN IF EXISTS description;
-- 3. 修改字段默认值
ALTER TABLE products ALTER COLUMN price SET DEFAULT 777.00;
-- 4. 删除字段默认值
ALTER TABLE products ALTER COLUMN price DROP DEFAULT;
-- 5. 修改字段数据类型
ALTER TABLE products ALTER COLUMN price TYPE numeric(10,2);
-- 6. 重命名字段
ALTER TABLE products RENAME COLUMN product_no TO product_number;
-- 7. 重命名表
ALTER TABLE products RENAME TO items;
-- === 模式(Schema) 操作(重点优化) ===
-- 说明:Schema 是数据库内的逻辑分组,可理解为"文件夹",用于隔离不同业务的表,默认所有表都在 public schema 下
-- 1. 创建模式(IF NOT EXISTS 避免重复创建报错)
CREATE SCHEMA IF NOT EXISTS myschema;
-- 2. 在指定模式下创建表(格式:schema名.表名)
CREATE TABLE IF NOT EXISTS myschema.mytable (
id int PRIMARY KEY
);
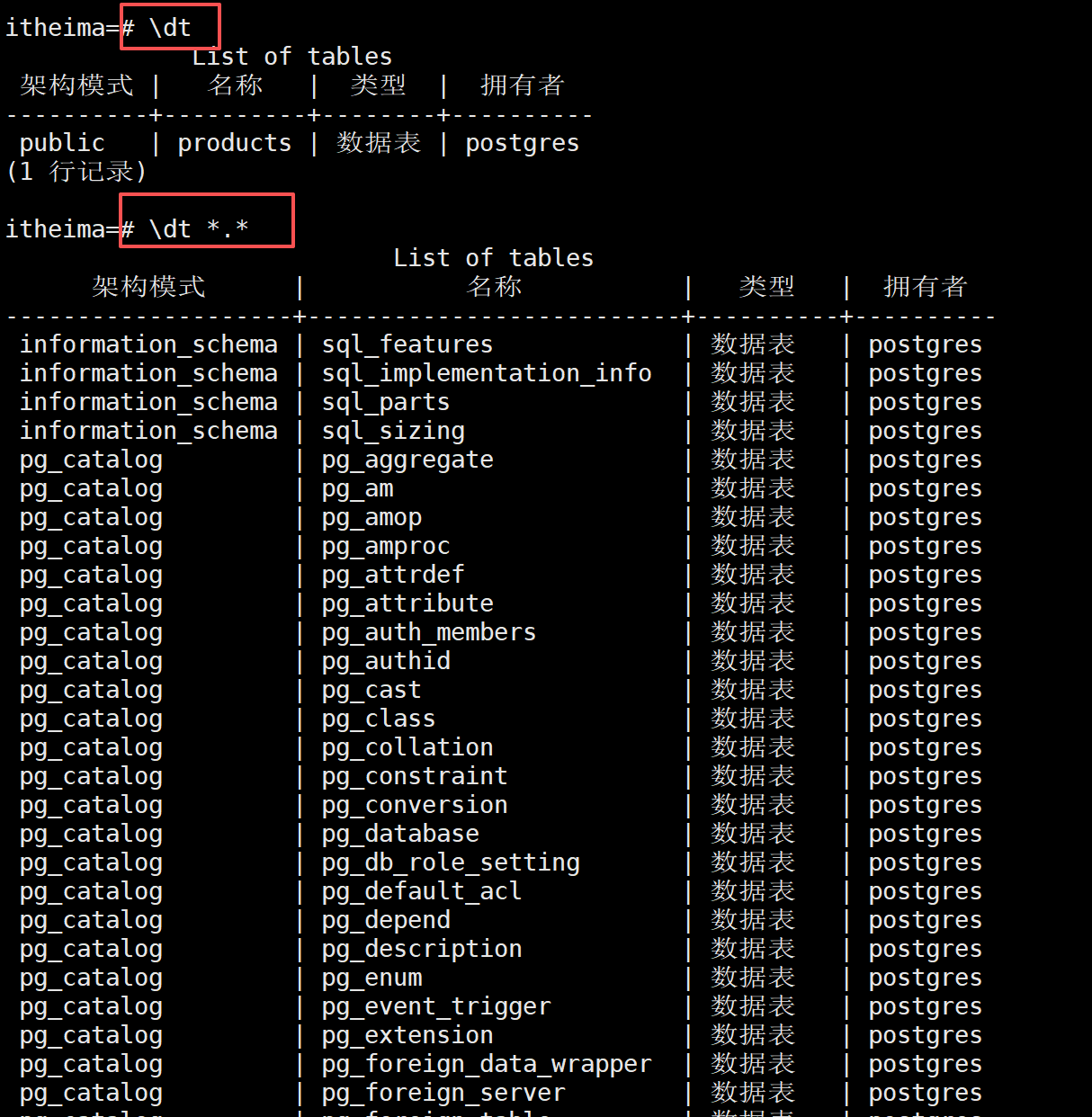
\dn -- 列出所有模式
\dt *.* -- 列出所有模式中的所有表
\dt myschema.* -- 列出指定模式中的所有表
-- 3. 向模式内的表插入数据
INSERT INTO myschema.mytable (id) VALUES (1), (2), (3);
-- 4. 查询模式内的表数据(两种方式)
-- 方式1:直接指定 schema.表名(推荐)
SELECT * FROM myschema.mytable;
-- 方式2:先切换默认 schema,再查询(临时生效)
SET search_path TO myschema;
SELECT * FROM mytable; -- 此时无需加 schema 前缀
-- 恢复默认 search_path(回到 public schema)
SET search_path TO public;
-- 5. 删除模式
-- 方式1:仅删除空模式(模式内无表时可用)
DROP SCHEMA IF EXISTS myschema;
-- 方式2:级联删除(删除模式及其中所有表、函数等,谨慎使用)
DROP SCHEMA IF EXISTS myschema CASCADE;
-- 6. 查看当前数据库所有 schema
SELECT nspname FROM pg_namespace WHERE nspname NOT LIKE 'pg_%' AND nspname != 'information_schema';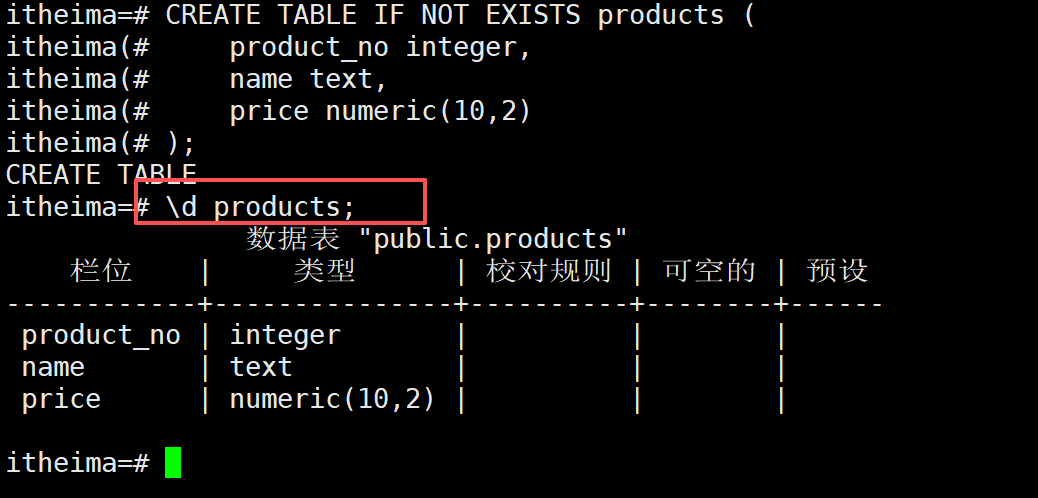
DML
增删改
CREATE TABLE products (
product_no integer,
name text,
price numeric
);
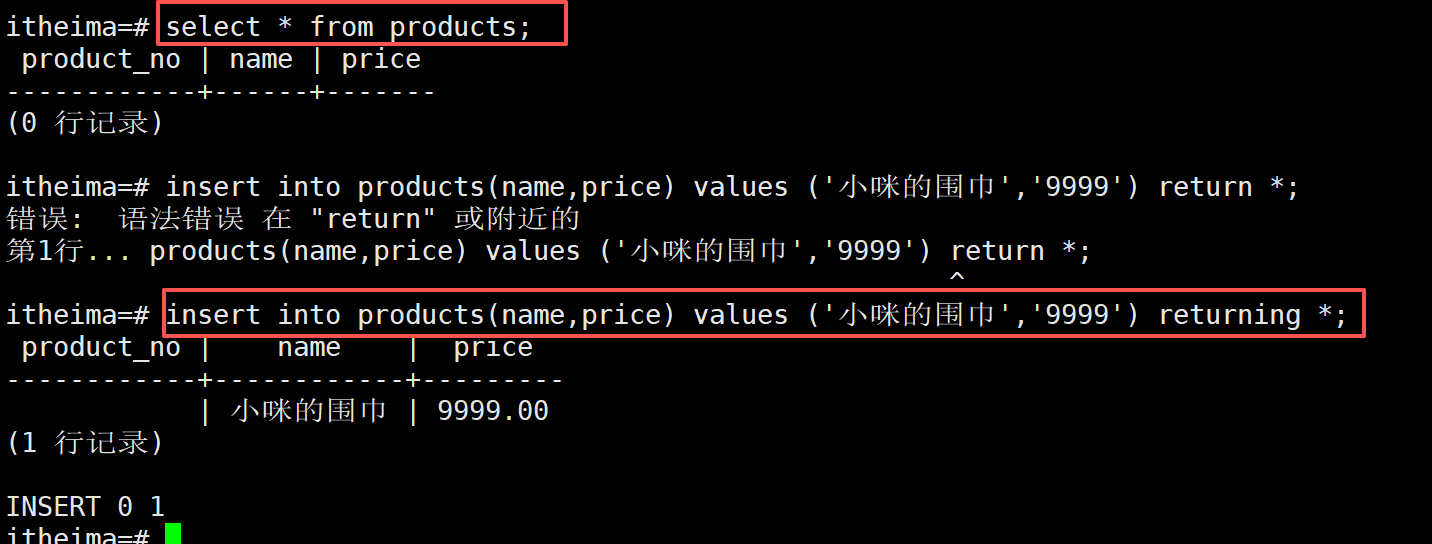
-- insert
INSERT INTO products VALUES (1, 'Cheese', 9.99) [returning 字段名];
-- insert 多行
INSERT INTO products (product_no, name, price) VALUES
(1, 'Cheese', 9.99),
(2, 'Bread', 1.99),
(3, 'Milk', 2.99);
-- update
UPDATE products SET price = 10 WHERE price = 1.99 [returning 字段名];
-- 统一涨价
UPDATE products SET price = price * 1.10;
-- delete
DELETE FROM products WHERE price = 10 [returning 字段名];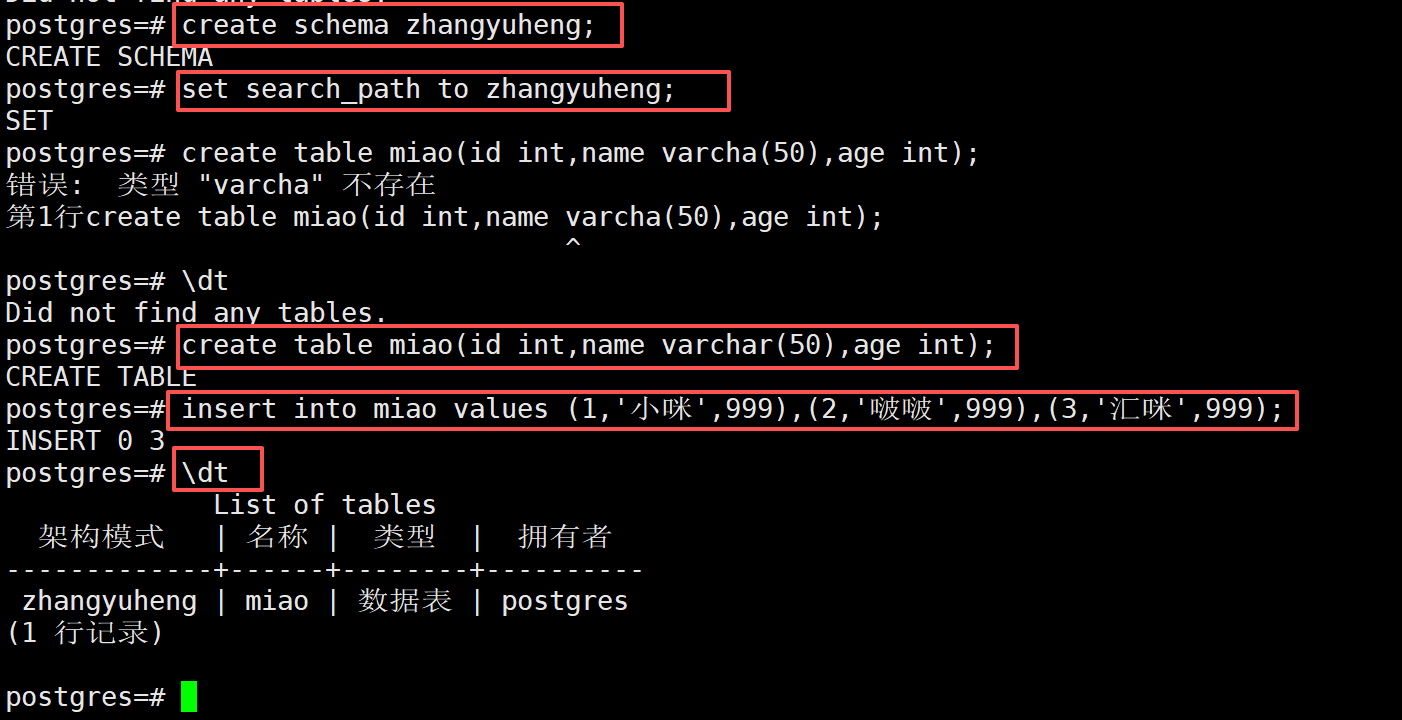
DQL
基本和MySQL一样
postgres=# CREATE TABLE products (
product_no integer,
name text,
price numeric
);
CREATE TABLE
postgres=# \d
List of relations
Schema | Name | Type | Owner
--------+-------------------+----------+----------
public | foo | table | postgres
public | items | table | postgres
public | people | table | postgres
public | people_ext | table | postgres
public | people_ext_id_seq | sequence | postgres
public | people_id_seq | sequence | postgres
public | products | table | postgres
public | test_table | table | postgres
public | test_table_id_seq | sequence | postgres
(9 rows)
postgres=# INSERT INTO products VALUES (1, 'Cheese', 9.99);
INSERT 0 1
postgres=# select * from products;
product_no | name | price
------------+--------+-------
1 | Cheese | 9.99
(1 row)
postgres=# INSERT INTO products (product_no, name, price) VALUES
(1, 'Cheese', 9.99),
(2, 'Bread', 1.99),
(3, 'Milk', 2.99);
INSERT 0 3
postgres=# select * from products;
product_no | name | price
------------+--------+-------
1 | Cheese | 9.99
1 | Cheese | 9.99
2 | Bread | 1.99
3 | Milk | 2.99
(4 rows)
postgres=# UPDATE products SET price = 10 WHERE price = 5;
UPDATE 0
postgres=# select * from products;
product_no | name | price
------------+--------+-------
1 | Cheese | 9.99
1 | Cheese | 9.99
2 | Bread | 1.99
3 | Milk | 2.99
(4 rows)
postgres=# UPDATE products SET price = 10 WHERE price = 9.99;
UPDATE 2
postgres=# select * from products;
product_no | name | price
------------+--------+-------
2 | Bread | 1.99
3 | Milk | 2.99
1 | Cheese | 10
1 | Cheese | 10
(4 rows)
postgres=# UPDATE products SET price = 10 WHERE price = 1.99;
UPDATE 1
postgres=# select * from products;
product_no | name | price
------------+--------+-------
3 | Milk | 2.99
1 | Cheese | 10
1 | Cheese | 10
2 | Bread | 10
(4 rows)
postgres=# UPDATE products SET price = price * 1.10;
UPDATE 4
postgres=# select * from products;
product_no | name | price
------------+--------+--------
3 | Milk | 3.2890
1 | Cheese | 11.00
1 | Cheese | 11.00
2 | Bread | 11.00
(4 rows)
postgres=# DELETE FROM products WHERE price = 10;
DELETE 0
postgres=# select * from products;
product_no | name | price
------------+--------+--------
3 | Milk | 3.2890
1 | Cheese | 11.00
1 | Cheese | 11.00
2 | Bread | 11.00
(4 rows)
postgres=# DELETE FROM products WHERE price = 11;
DELETE 3
postgres=# select * from products;
product_no | name | price
------------+------+--------
3 | Milk | 3.2890
(1 row)
postgres=#备份与恢复
逻辑备份与恢复
逻辑备份工具
-
pg_dump
-
pg_dumpall 实例级备份
备份 pg_dump 数据库名 > 指定备份文件名路径 pg_dump -d数据名 -f /指定备份文件名路径 -F p 还原 psql -d数据库名 -f指定备份文件名路径 -F p psql 数据库名 < /指定备份文件名路径 pg_restore -d 数据库名 /指定备份文件名路径 -F c 单库备份 数据库: pg_dump -U postgres -p 5432 -d postgres -f /opt/pgsql/backup/pg_dump_postgres.sql -F p 备份指定数据库的表: pg_dump -p 5432 -d postgres -t orders -f /opt/pgsql/backup/pg_dump_orders.dmp -F c -F c:custom 自定义二进制(生产首选,支持选择性恢复、压缩) -F p:plain 普通 SQL 文本格式,就是.sql文件,可直接打开执行,只能全量恢复 -F d:directory 目录格式,生成多个备份文件存到文件夹,支持并行备份恢复 还原: 1.还原数据库:psql -p 5432 -f /opt/pgsql/backup/pg_dump_postgres.sql -d postgres 2.还原数据表:pg_restore -p 5432 /opt/pgsql/backup/pg_dump_orders.dmp -d postgres -F c 注意:可以省略-U -p 但是:如果省略了-U -p那么代表使用的是默认的 -U postgres -p 5432,如果你的用户名和端口号和默认的不一样,需要添加
实操--备份
我现在要备份postgres库下的zhangyuheng模式下的内容
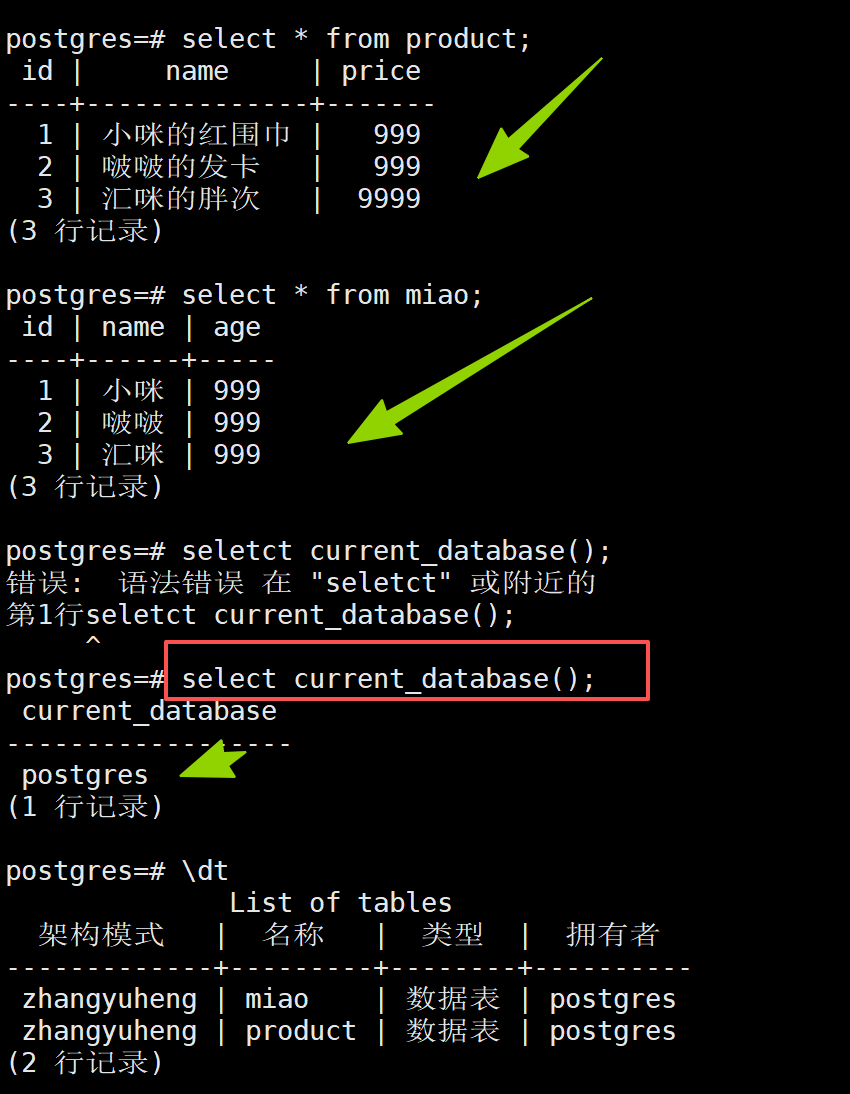
如果要全部用户,全部库全部模式全部表备份,恢复的话,psql -f all.sql
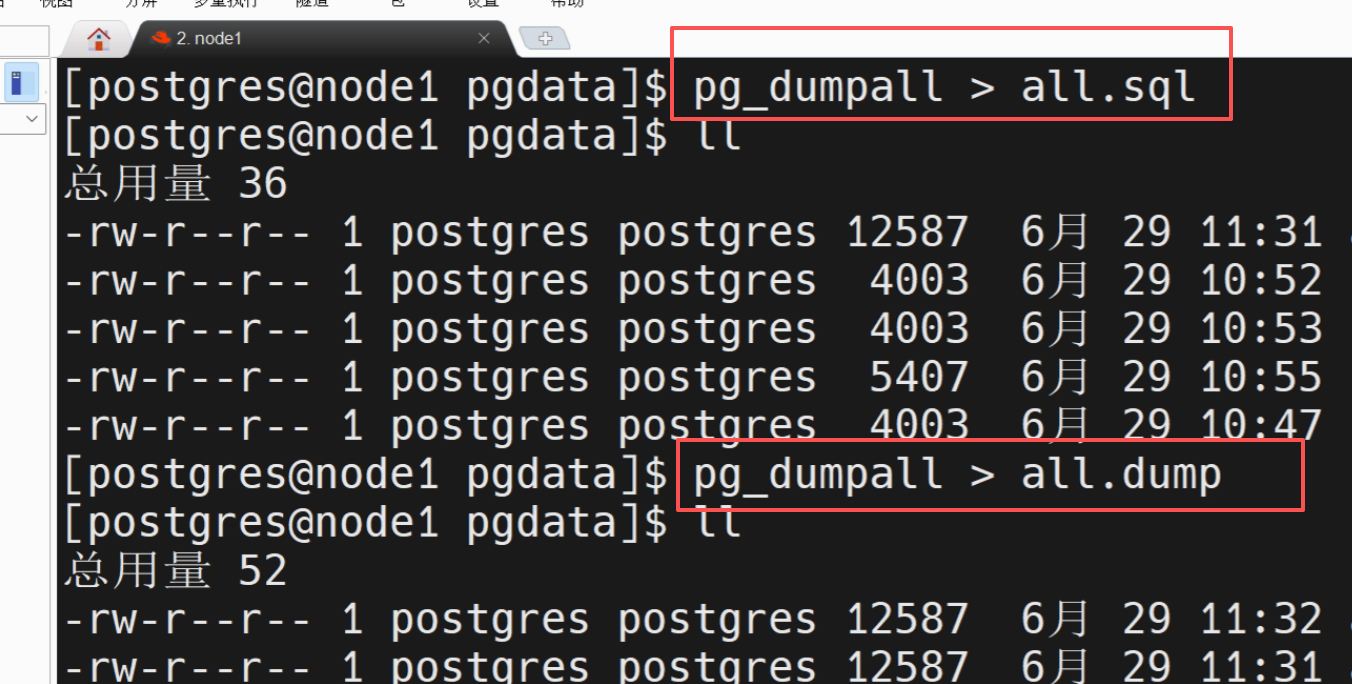
备份.dmp
连接 5433 端口,只备份 postgres 库下 zhangyuheng 模式,保存为二进制自定义备份文件
#创建目录来存放备份,给权限(root执行)
mkdir -p /opt/pgsql/schema_bak
chown -R postgres:postgres /opt/pgsql
chmod 700 /opt/pgsql/schema_bak
#生产2进制备份(progres执行)
pg_dump -U postgres -p 5433 -d postgres -n zhangyuheng -F c -f /opt/pgsql/schema_bak/zhangyuheng.dmp
#或者用sql文件形式的备份
pg_dump -d postgres -n zhangyuheng -p 5433 -f /opt/pgsql/schema_bak/zhangyuheng_schema.sql
恢复
pg_restore -p 5433 -d postgres -n zhangyuheng /opt/pgsql/schema_bak/zhangyuheng.dmp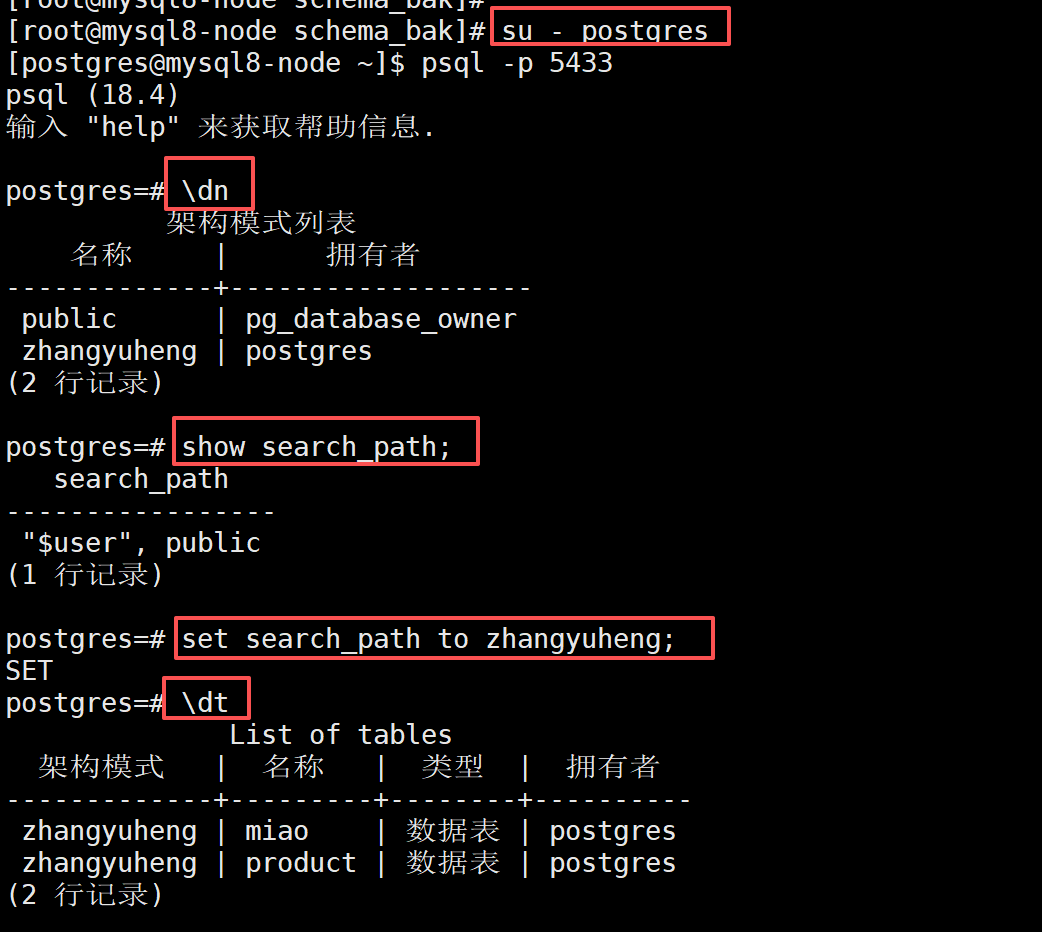
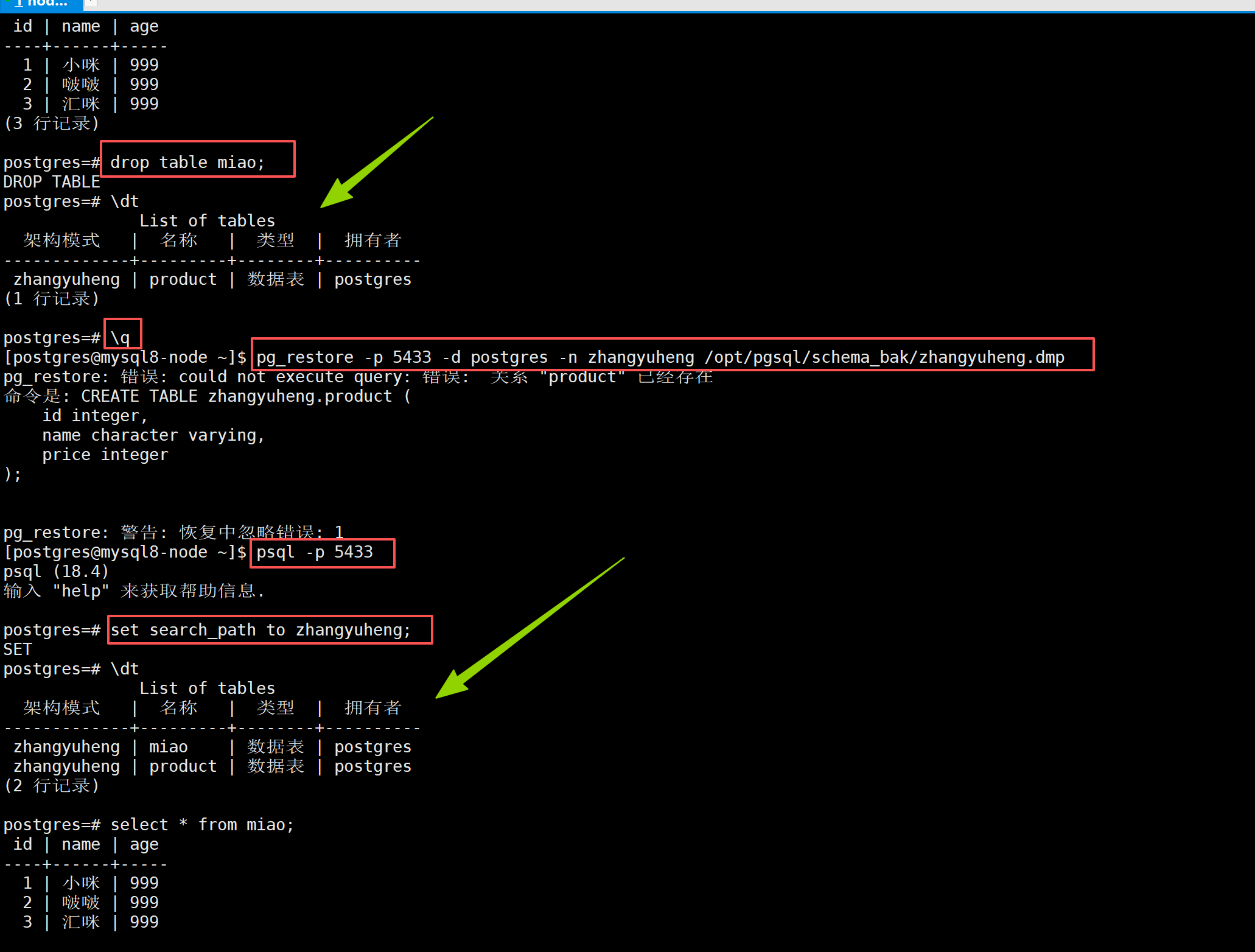
以下为自行练习数据
--实操数据
-- 创建数据库
create database itheima;
\c itheima;
-- 创建表并插入测试数据
CREATE TABLE departments (
dept_id SERIAL PRIMARY KEY,
dept_name VARCHAR(100) NOT NULL
);
CREATE TABLE employees (
emp_id SERIAL PRIMARY KEY,
emp_name VARCHAR(100) NOT NULL,
dept_id INTEGER REFERENCES departments(dept_id),
salary NUMERIC(10,2)
);
INSERT INTO departments (dept_name) VALUES
('研发部'), ('市场部'), ('人事部');
INSERT INTO employees (emp_name, dept_id, salary) VALUES
('张三', 1, 15000),
('李四', 1, 16000),
('王五', 2, 12000),
('赵六', 3, 9000),
('孙七', 2, 13000);
-- 查看表和测试数据
\dt;
select * from departments;
select * from employees;
-- 备份单库
pg_dump itheima > itheima.sql
-- 备份全部库、模式、表空间等
pg_dumpall > data.sql
-- 备份时压缩,适合大文件
pg_dump itheima | gzip > itheima.sql.gz
-- 并行备份(目录格式)
pg_dump -j num -F d -f /路径地址 dbname
-- 实操
pg_dump -j 2 -Fd -f out itheima
-j 2表示同时启动 2 个并行的进程/线程 来执行备份(或恢复),可以加快大型数据库的处理速度。
-Fd:指定备份格式为目录格式(directory format)。备份输出到一个目录中,每个表和数据段会存储为单独的文件,支持并行操作和灵活恢复。
-f:指定输出目标。与目录格式搭配时,-f 后面跟的是输出目录的名称(如 -f out 表示备份到 out/ 目录)。物理备份与恢复
只能复制整个 data 目录,不能筛选模式
全量备份与恢复
切换回 root 用户,向 pg_hba.conf 追加一条复制权限规则
su - root
echo 'host replication postgres 192.168.88.0/24 scram-sha-256' >> /var/lib/pgsql/18/data/pg_hba.conf
tail -1 /var/lib/pgsql/18/data/pg_hba.conf切回 postgres 普通用户执行重载配置
su - postgres
pg_ctl reload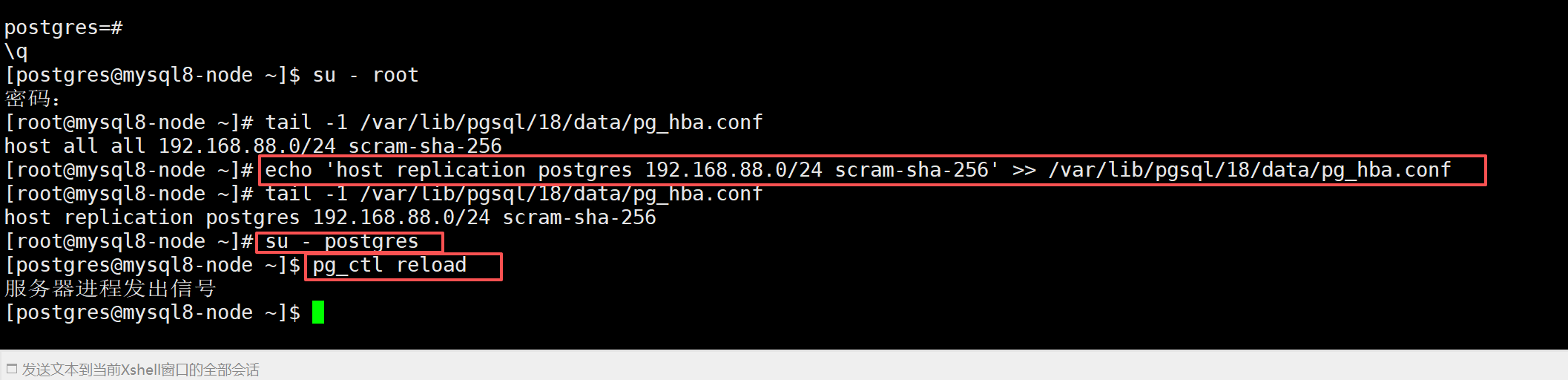
然后的备份流程是
# 1.切换root
exit
# 2.创建目录放备份文件
mkdir -p /opt/pgsql/data_new
# 3.修改目录归属为postgres用户组,否则备份会权限报错
chown -R postgres:postgres /opt/pgsql
# 4.切换postgres普通用户
su - postgres
# 5.(实例级别)全量备份
pg_basebackup -h 192.168.88.101 -D /opt/pgsql/data_new -U postgres -W -v -P -Xs
# 执行后输入postgres数据库用户密码-
-h 192.168.88.101目标主库 IP,从库去连接主库拉取数据。 -
-D /opt/pgsql/data_new本地新数据目录,目录必须为空,不能是已有 PG 数据目录。 -
-U postgres具备 replication 复制权限的超级用户。 -
-W强制弹出密码输入框。 -
-vverbose 详细日志。 -
-P实时打印备份进度百分比。 -
-Xs(简写-X stream)流式同步 WAL 日志。备份期间主库持续产生新事务,只拷贝数据文件会产生断点;流式实时同步备份过程中产生的 WAL,保证整套备份是事务一致的,恢复后数据库可以正常启动。
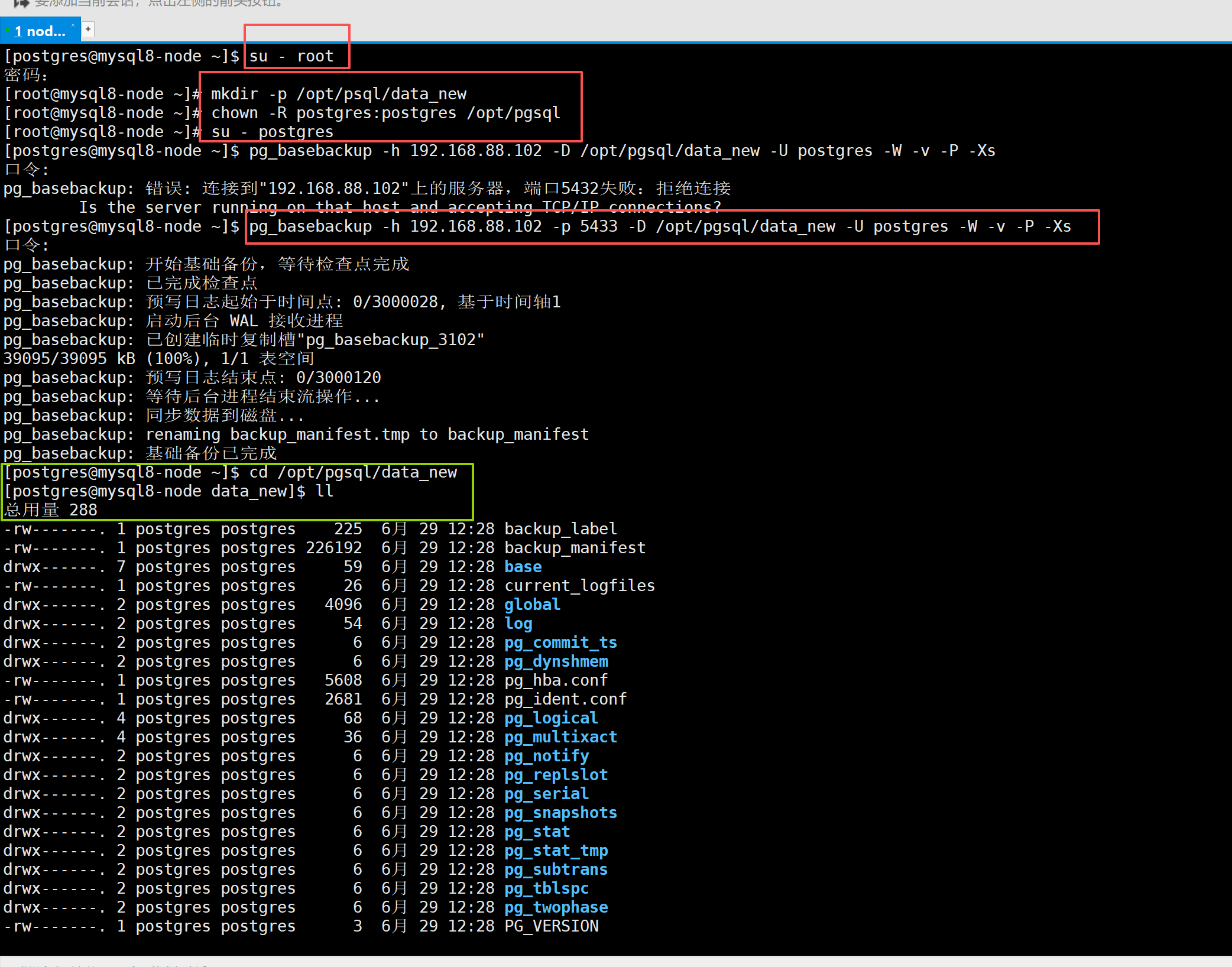
现在就全部备份为data_new了 我们来看一下这个data_new能不能用
先把服务停了,给原来的data改名为data01模拟data的损坏丢失,再起服务会发现起不来了
# root执行
systemctl stop postgresql-18
#模拟data损坏
mv /var/lib/pgsql/18/data /var/lib/pgsql/18/data01
systemctl start postgresql-18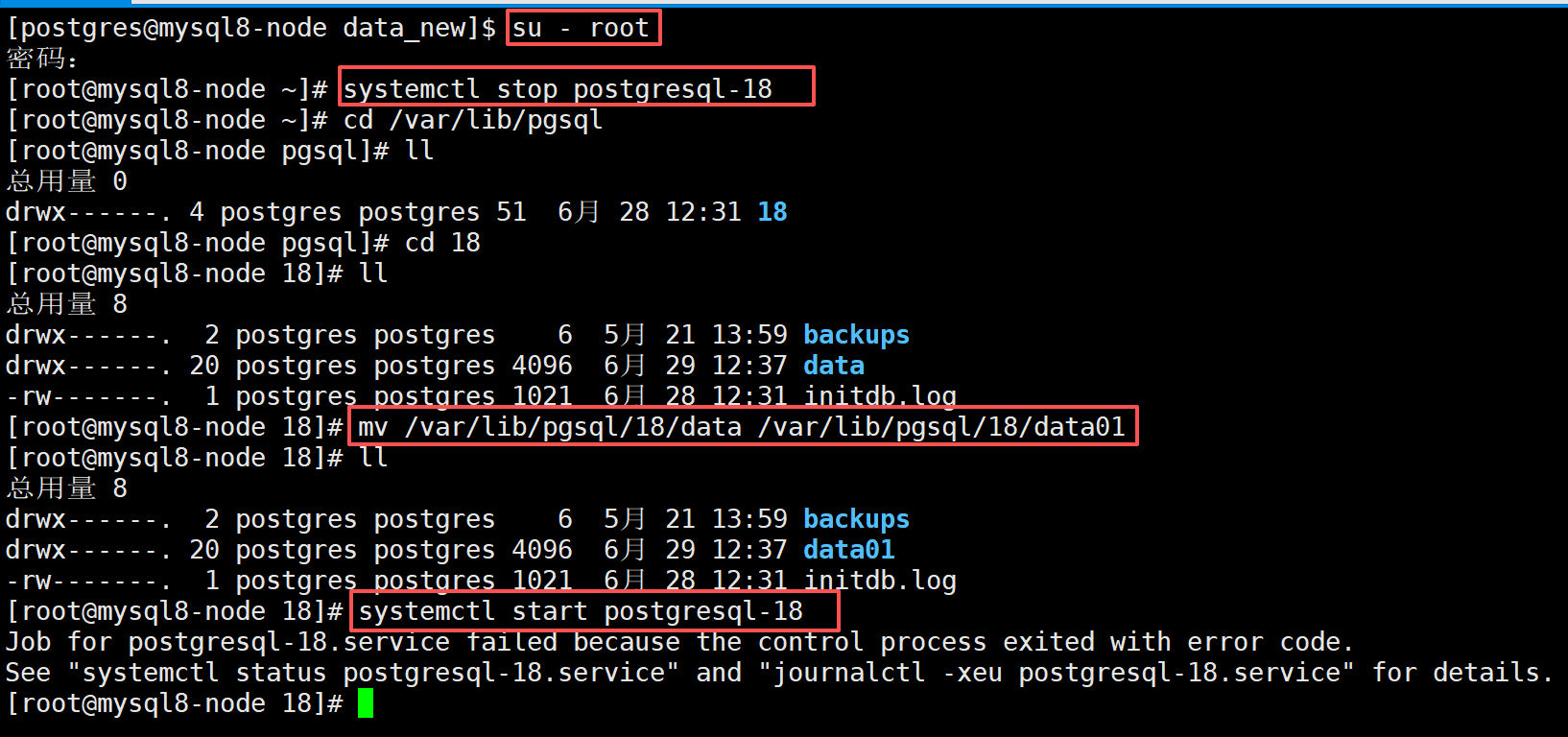
我们直接把,刚刚备份好的data_new整个文件夹移动过去,并且重命名为data
mv /opt/pgsql/data_new /var/lib/pgsql/18/data
chown -R postgres:postgres /var/lib/pgsql/18/data
chmod 700 /var/lib/pgsql/18/data
systemctl start postgresql-18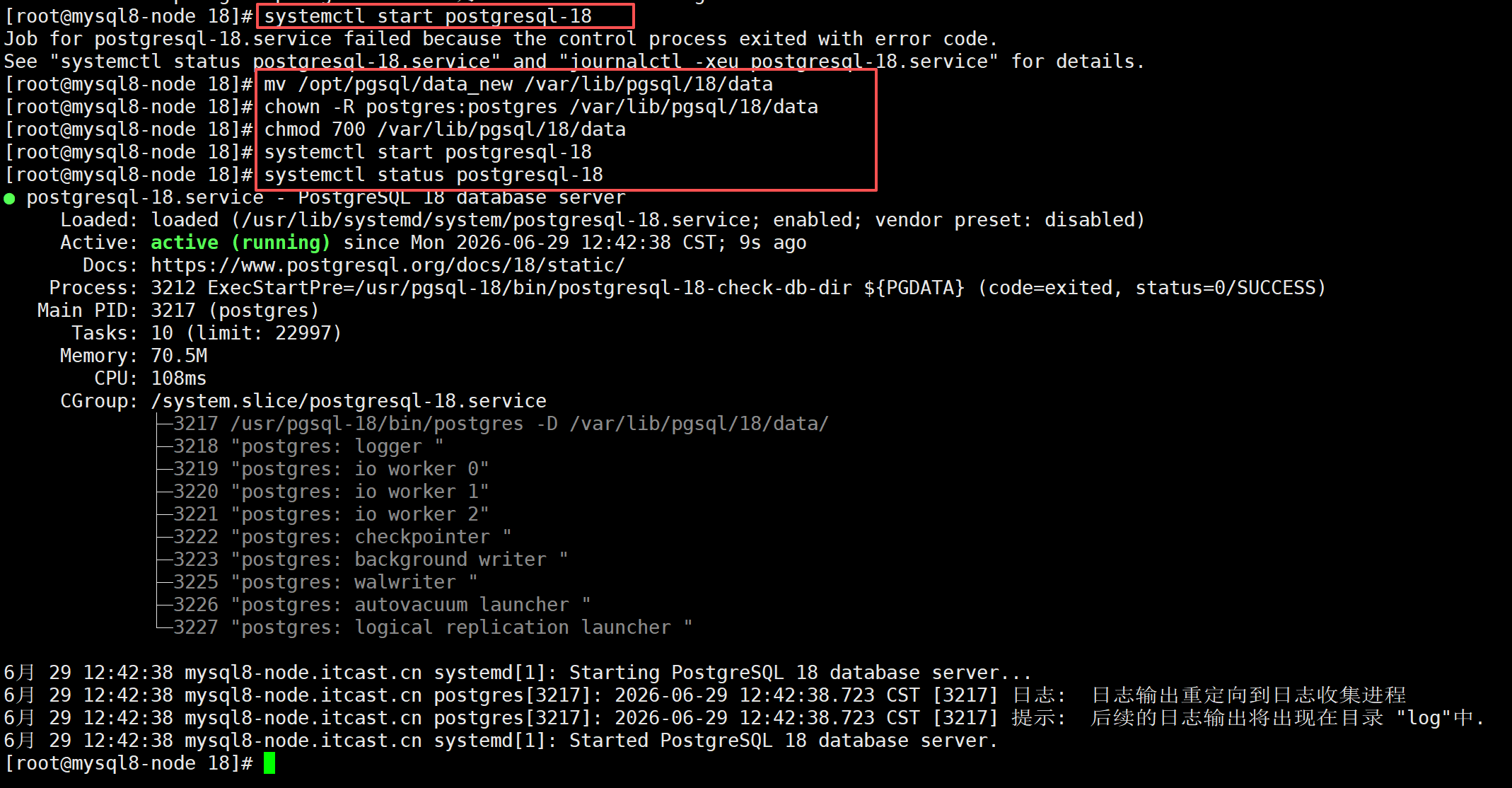
增量备份与恢复
必须开启wal_level和summarize_wal
wal_level保证日志足够详细
summarize_wal帮助快速定位变化,两者配合才能做增量备份。
summarize_wal(PG17 及以上新增参数)
开启后自动生成数据块修改摘要,工具可以快速定位变更的数据块,实现真正的块级增量备份,只备份改动过的数据,不用全量拷贝。只有 PG17 + 才需要配置这个参数做增量。
wal_level(WAL 日志级别)
minimal:日志极少,不支持归档、增量备份、主从复制,只能保证数据库正常启动。replica:默认级别,满足WAL 归档、物理增量备份、主从流复制,增量备份最低要求。logical:在 replica 基础上增加逻辑复制,用于逻辑订阅。
做增量备份 wal_level至少要是replica级别
前置准备
开启wal_level和summarize_wal,确保wal_level至少是replica级别
su - postgres
#我修改了端口号为5433,如果没动的话,直接psql上去
psql -p 5433
SHOW wal_level;
SHOW summarize_wal;
#off的话给打开
ALTER SYSTEM SET summarize_wal = on;
#重新加载 postgresql.conf、pg_hba.conf 的配置。
SELECT pg_reload_conf();
SHOW summarize_wal;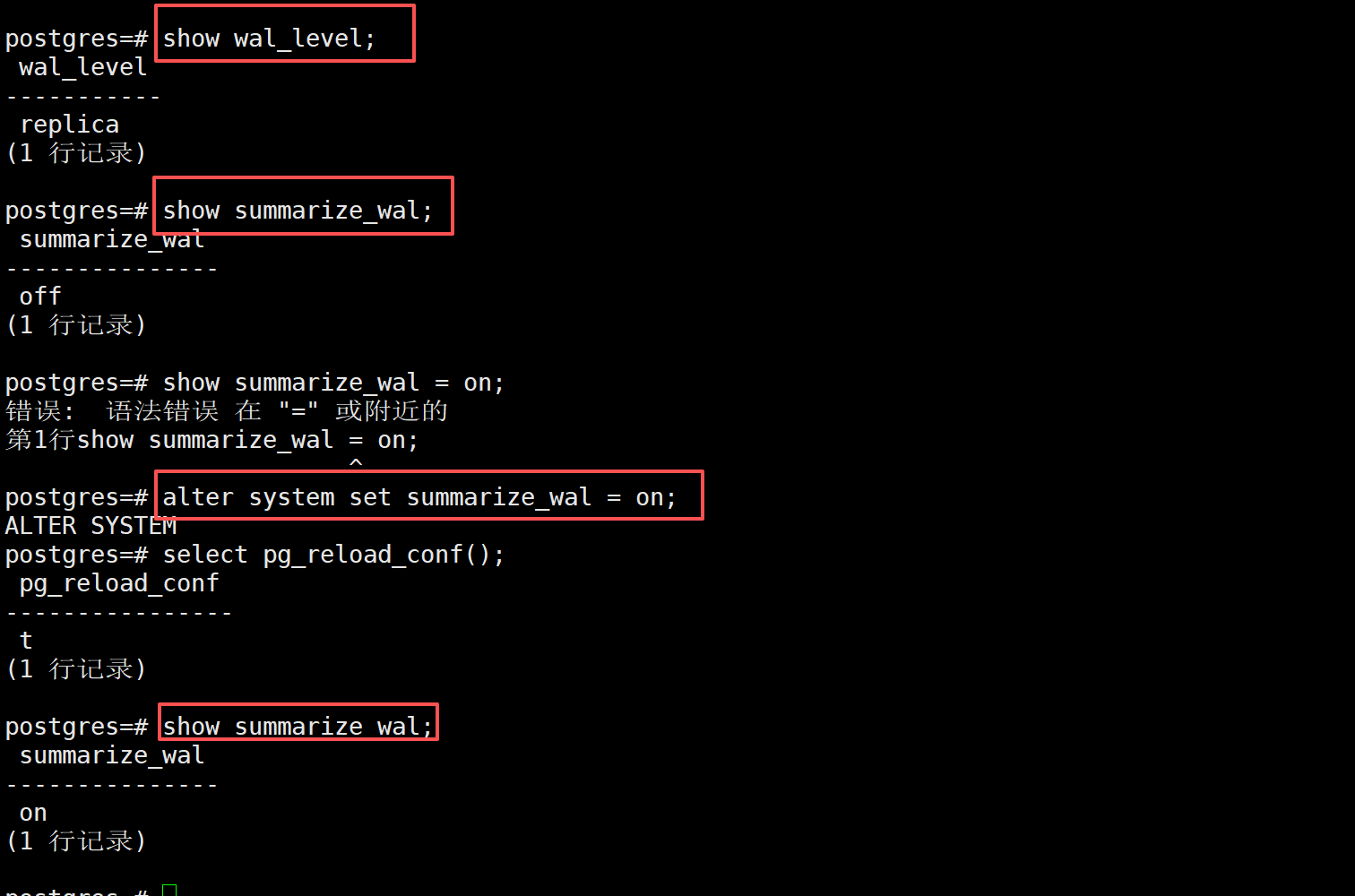
增量备份全过程
增量备份是基于全量备份的,我们先来
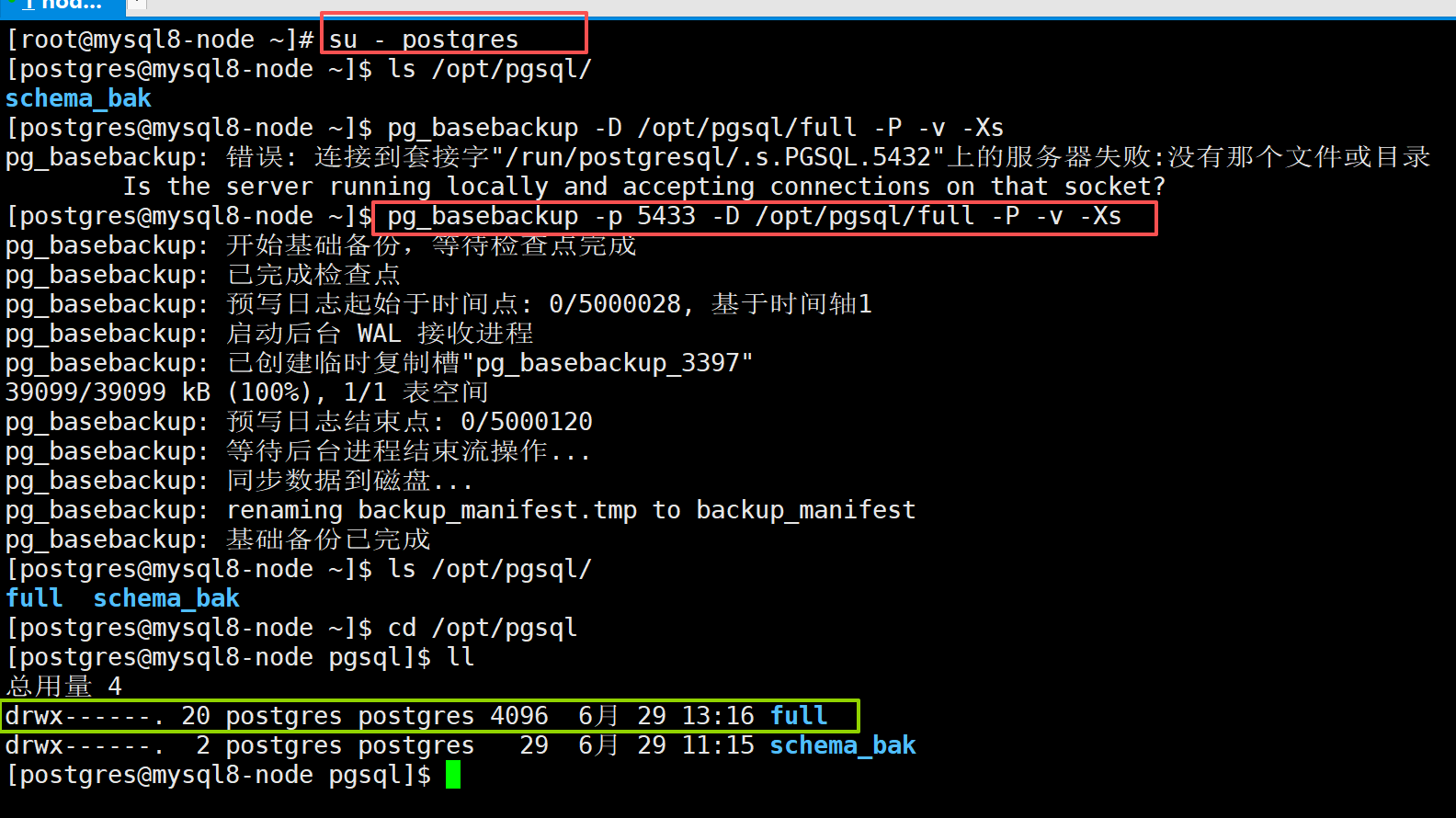
全量备份(物理备份)
su - postgres
pg_basebackup -D /opt/pgsql/full -P -v -Xs- -D /opt/pgsql/full
指定备份存放目录。目录不存在会自动创建;如果目录不为空,直接报错。备份完成后,这里就是一整套完整的 data 数据目录。
- -P(全称 --progress)
实时打印备份进度,显示文件拷贝百分比。
- -v(全称 --verbose)
输出详细日志:检查点位置、WAL 起始位置、文件复制详情。
- -Xs (-X --wal-method
s= stream,流式传输 WAL 日志)
把备份期间产生的 WAL 日志一并打包进备份目录。
新增数据
全量备份后,新增的数据,这个时候我们的备份里是没有的,如果我们过几天磁盘出问题,只做了全量备份的恢复,这一块新增的数据会丢失,所以我们需要增量备份
-- 1. 创建 itheima666 数据库
CREATE DATABASE itheima666;
-- 切换到 itheima666
\c itheima666
-- 2. 创建 departments 表
CREATE TABLE departments (
dept_id SERIAL PRIMARY KEY,
dept_name VARCHAR(100) NOT NULL
);
-- 3. 创建 employees 表
CREATE TABLE employees (
emp_id SERIAL PRIMARY KEY,
emp_name VARCHAR(100) NOT NULL,
dept_id INTEGER REFERENCES departments(dept_id),
salary NUMERIC(10,2)
);
-- 4. 插入新部门(财务部),并获取其自动生成的 dept_id
INSERT INTO departments (dept_name) VALUES ('财务部') RETURNING dept_id;
-- 5. 插入员工时,通过子查询动态获取财务部的 dept_id,避免硬编码
INSERT INTO employees (emp_name, dept_id, salary) VALUES
('周八', (SELECT dept_id FROM departments WHERE dept_name = '财务部'), 11000),
('吴九', (SELECT dept_id FROM departments WHERE dept_name = '财务部'), 10500);
-- 6. 创建 projects 表
CREATE TABLE projects (
proj_id SERIAL PRIMARY KEY,
proj_name VARCHAR(100) NOT NULL,
start_date DATE,
dept_id INTEGER REFERENCES departments(dept_id)
);
-- 7. 插入项目数据(使用子查询获取部门ID,避免硬编码)
INSERT INTO projects (proj_name, start_date, dept_id) VALUES
('研发A项目', '2026-03-01', (SELECT dept_id FROM departments WHERE dept_name = '研发部')),
('市场B项目', '2026-03-01', (SELECT dept_id FROM departments WHERE dept_name = '市场部')),
('财务系统升级', '2026-03-15', (SELECT dept_id FROM departments WHERE dept_name = '财务部'));
-- 8. 更新员工薪资(可选)
UPDATE employees SET salary = 16000 WHERE emp_name = '张三';
-- 9. 删除员工(可选)
DELETE FROM employees WHERE emp_name = '孙七';
-- 10. 验证数据
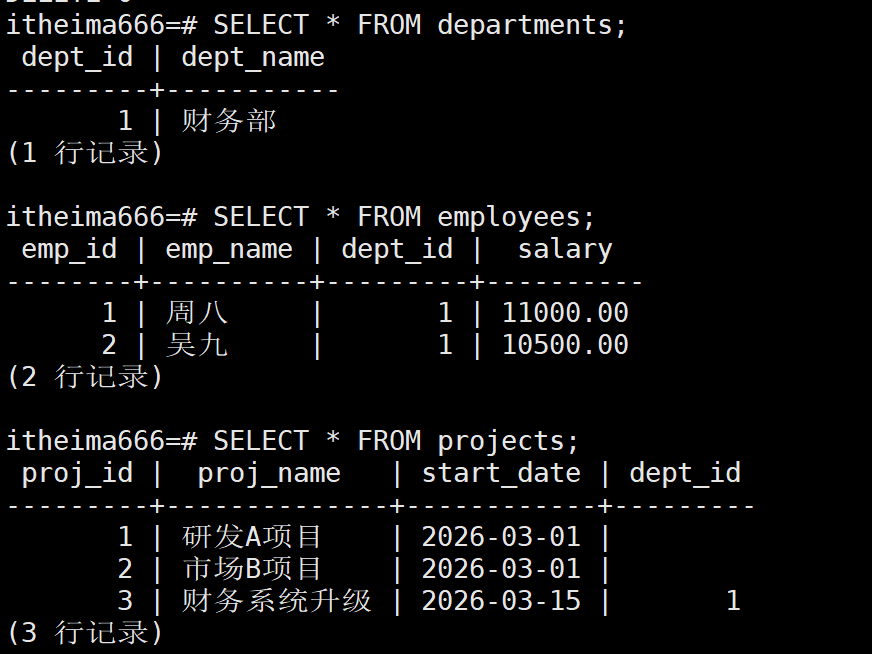
SELECT * FROM departments;
SELECT * FROM employees;
SELECT * FROM projects;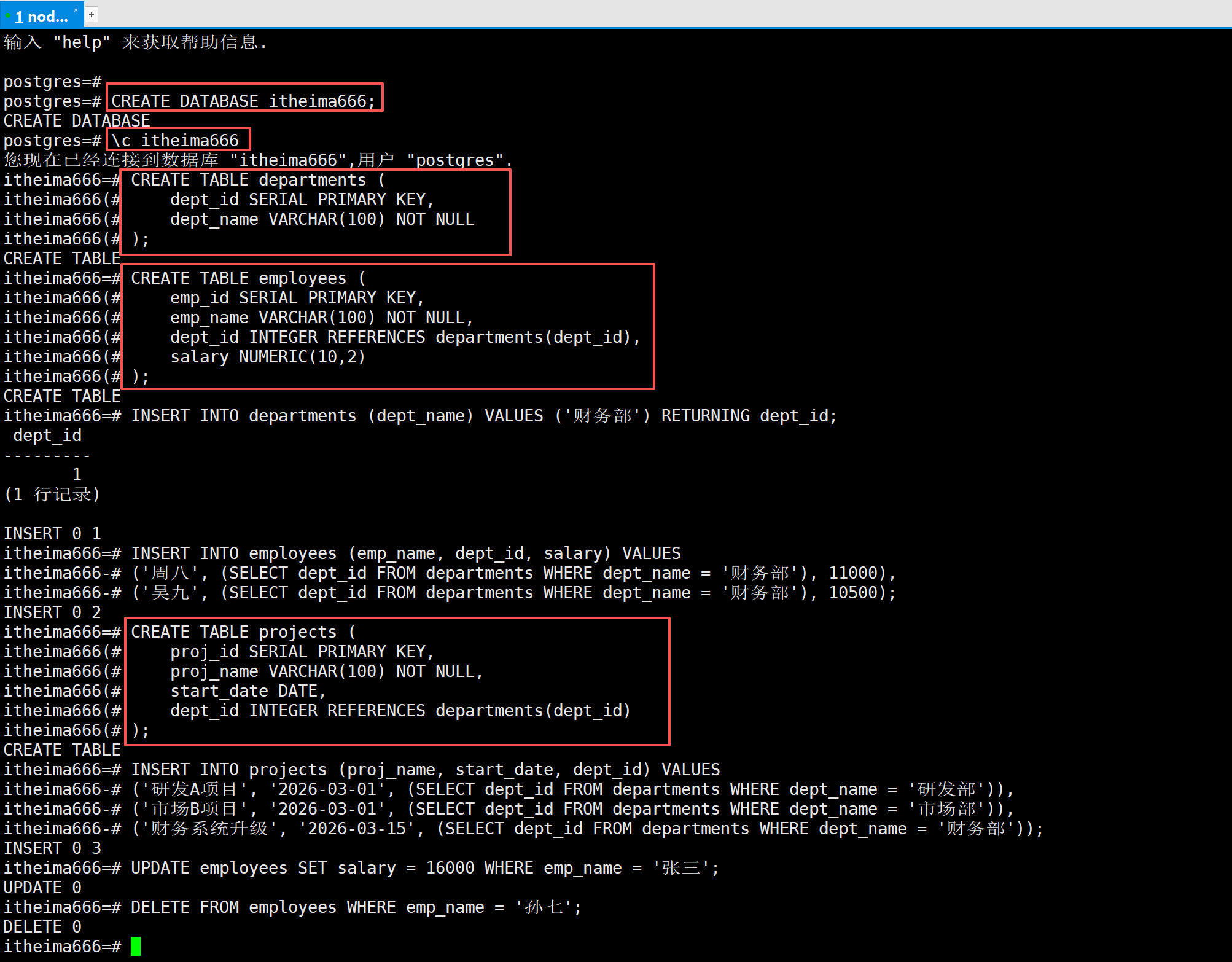
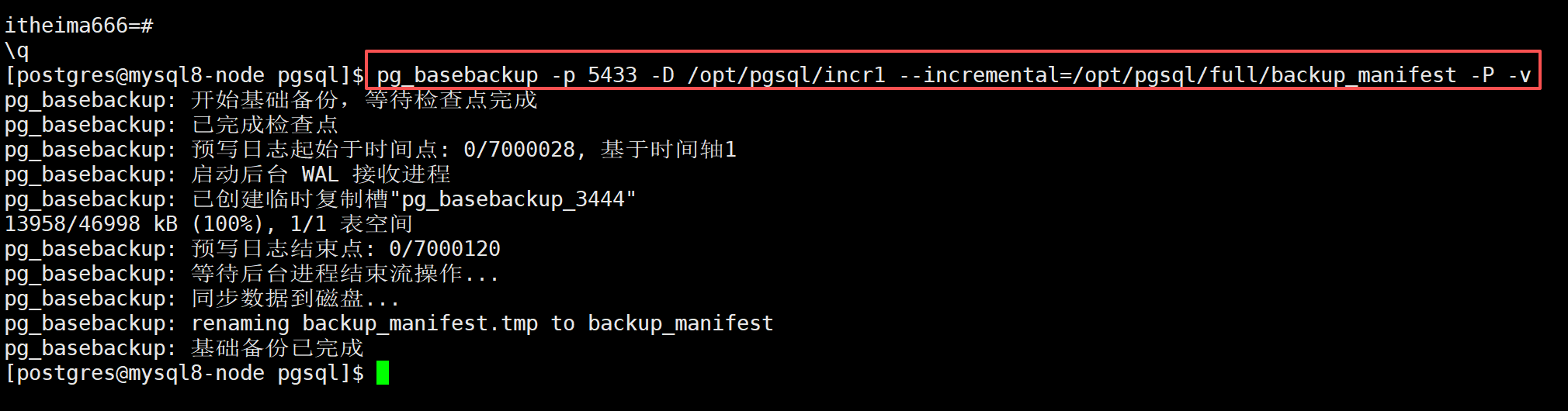
第一次增量备份(基于全量备份)
pg_basebackup -p 5433 -D /opt/pgsql/incr1 --incremental=/opt/pgsql/full/backup_manifest -P -v- 只备份自从全量备份
/opt/pgsql/full之后被修改过的数据块,不拷贝整个数据库文件。 - 备份结果存入目录:
/opt/pgsql/incr1
第二次新增数据
做完全量备份后,我们有了一些增删改操作,做了一次增量备份,储存为incr1,这时我们又有了一些增删改操作
-- 1. 创建 itheima2026 数据库
CREATE DATABASE itheima2026;
-- 切换到 itheima2026
\c itheima2026
-- 2. 创建 departments 表
CREATE TABLE departments (
dept_id SERIAL PRIMARY KEY,
dept_name VARCHAR(100) NOT NULL
);
-- 3. 创建 employees 表
CREATE TABLE employees (
emp_id SERIAL PRIMARY KEY,
emp_name VARCHAR(100) NOT NULL,
dept_id INTEGER REFERENCES departments(dept_id),
salary NUMERIC(10,2)
);
-- 4. 插入新部门(财务部),并获取其自动生成的 dept_id
INSERT INTO departments (dept_name) VALUES ('财务部') RETURNING dept_id;
-- 5. 插入员工时,通过子查询动态获取财务部的 dept_id,避免硬编码
INSERT INTO employees (emp_name, dept_id, salary) VALUES
('周八', (SELECT dept_id FROM departments WHERE dept_name = '财务部'), 11000),
('吴九', (SELECT dept_id FROM departments WHERE dept_name = '财务部'), 10500);
-- 6. 创建 projects 表
CREATE TABLE projects (
proj_id SERIAL PRIMARY KEY,
proj_name VARCHAR(100) NOT NULL,
start_date DATE,
dept_id INTEGER REFERENCES departments(dept_id)
);
-- 7. 插入项目数据(使用子查询获取部门ID,避免硬编码)
INSERT INTO projects (proj_name, start_date, dept_id) VALUES
('研发A项目', '2026-03-01', (SELECT dept_id FROM departments WHERE dept_name = '研发部')),
('市场B项目', '2026-03-01', (SELECT dept_id FROM departments WHERE dept_name = '市场部')),
('财务系统升级', '2026-03-15', (SELECT dept_id FROM departments WHERE dept_name = '财务部'));
-- 8. 更新员工薪资(可选)
UPDATE employees SET salary = 16000 WHERE emp_name = '张三';
-- 9. 删除员工(可选)
DELETE FROM employees WHERE emp_name = '孙七';
-- 10. 验证数据
SELECT * FROM departments;
SELECT * FROM employees;
SELECT * FROM projects;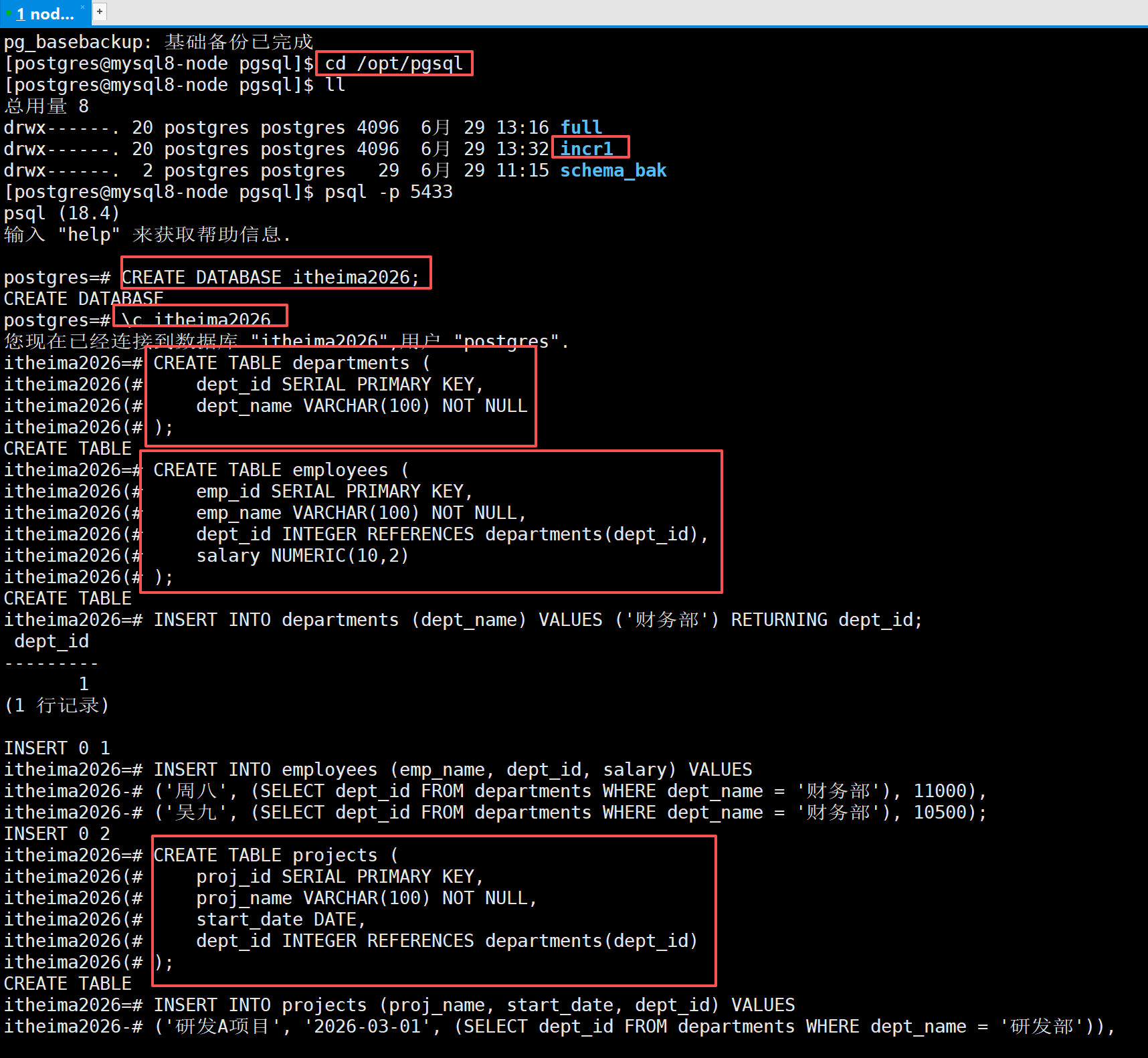
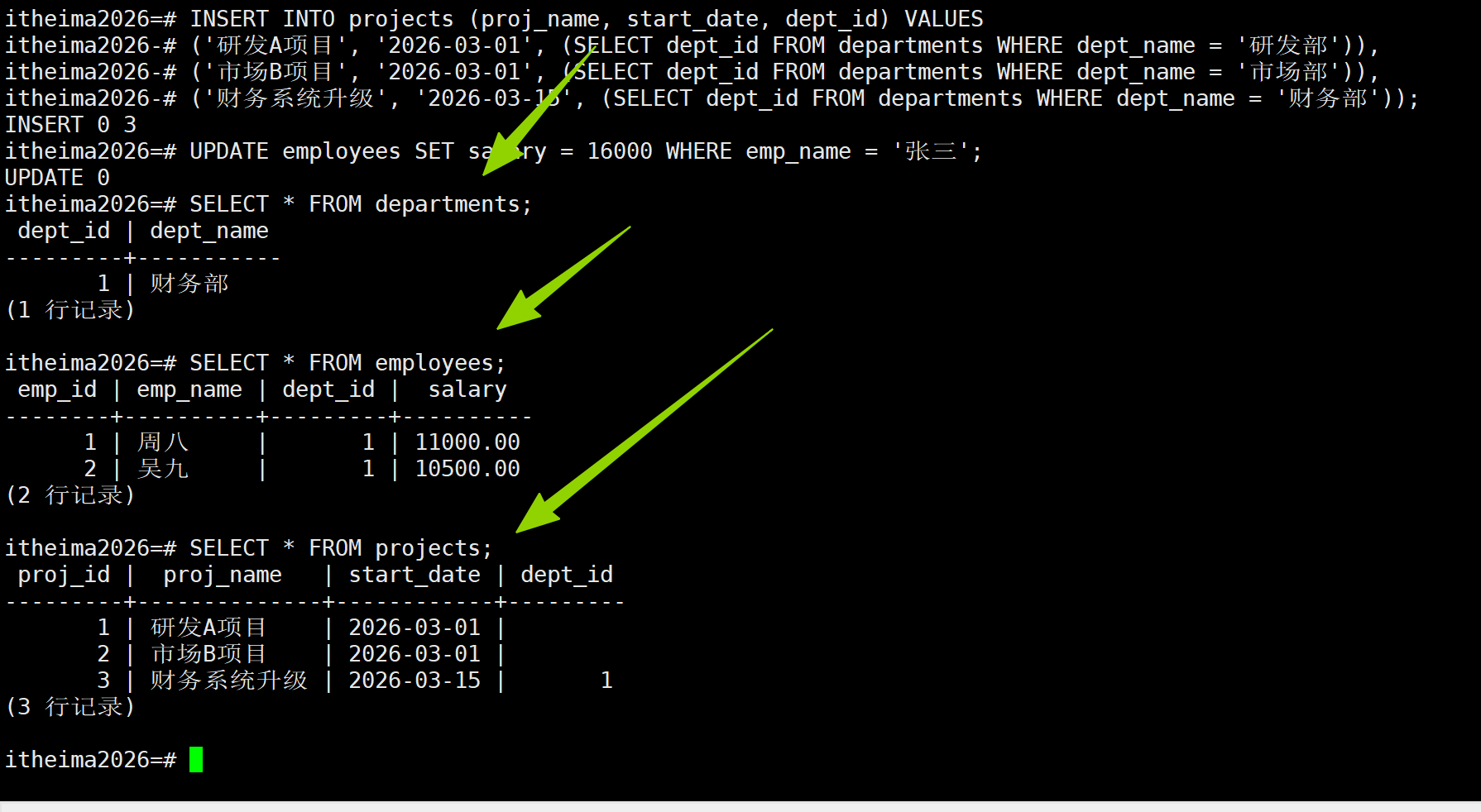
第二次增量备份
上次做完增量备份后,我们又新建了一个库,库里有三个表,以 incr1 这份增量备份作为基准,只备份后续新修改的数据块,生成新增量备份 incr2
pg_basebackup -D /opt/pgsql/incr2 --incremental=/opt/pgsql/incr1/backup_manifest -P -v-D /opt/pgsql/incr2:本次增量备份存放目录--incremental=/xxx/backup_manifest:指定上一次备份的清单文件,用来对比数据块变化-P:显示备份进度-v:输出详细日志
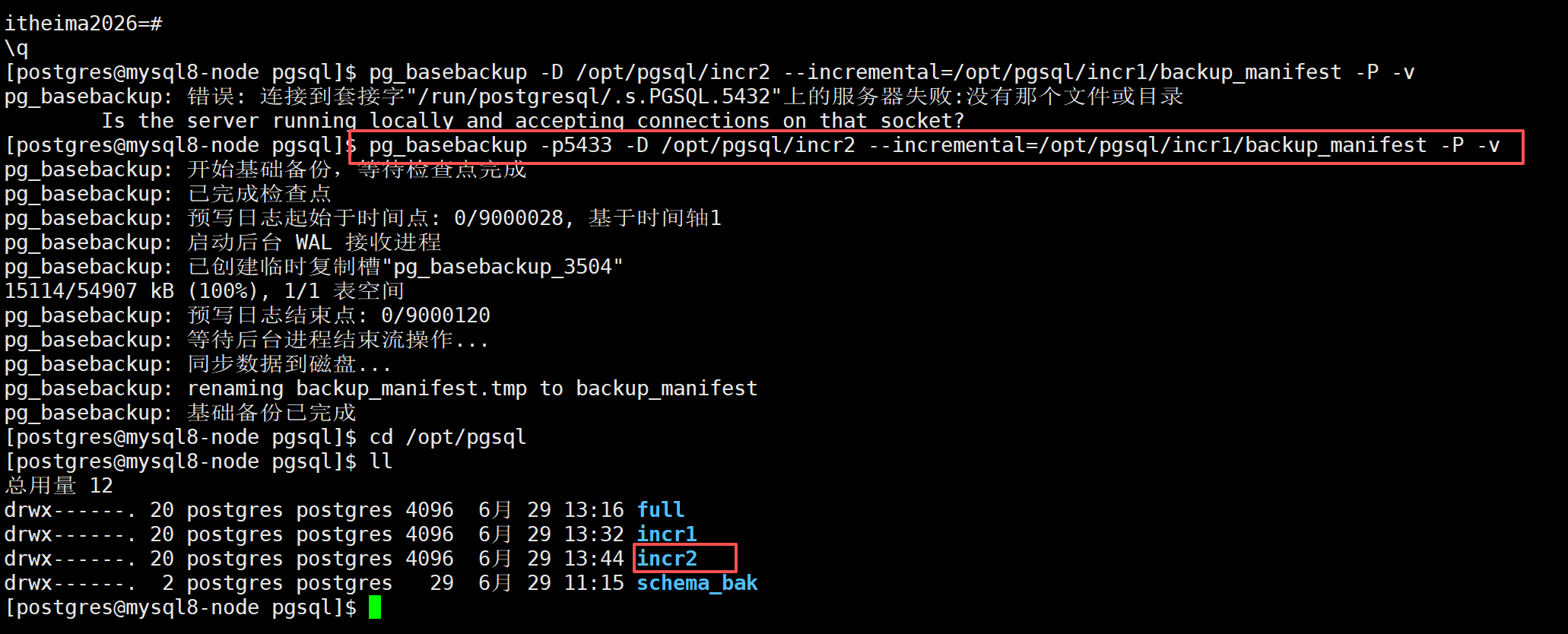
查看备份占用空间
du -sh /opt/pgsql/full /opt/pgsql/incr*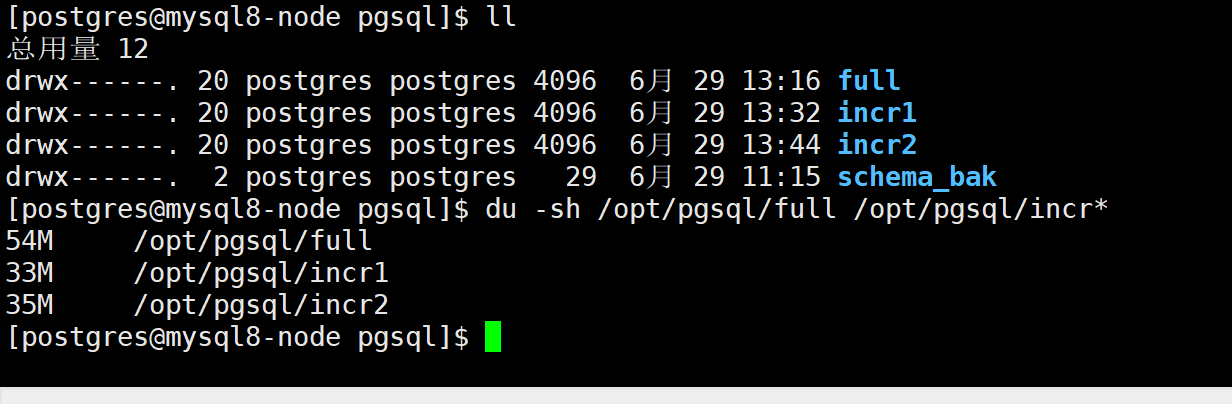
增量恢复
合并备份为完整数据目录
使用 pg_combinebackup 将全备和增量备份合并成一个可用的数据目录。
#把全量备份 full + 增量 incr1 + 增量 incr2逐层合并
#生成一套完整可直接恢复的数据目录,输出到 /opt/pgsql/ready
pg_combinebackup -o /opt/pgsql/ready \
/opt/pgsql/full \
/opt/pgsql/incr1 \
/opt/pgsql/incr2
#或者(存在外部表空间时才需要)
pg_combinebackup -o /opt/pgsql/ready \
--tablespace-mapping=/opt/pgsql/data1=/opt/pgsql/ready/data1 \
/opt/pgsql/full \
/opt/pgsql/incr1 \
/opt/pgsql/incr2
--tablespace-mapping=旧路径=新路径用来把原库的外部表空间路径,重定向到新目录。普通默认库没有自定义表空间,这条参数可以不加。
-o全称:--output- 作用:指定合并完成后数据文件的输出目录。
合并完成后检查生成的文件
ls -l /opt/pgsql/ready/
head -66 /opt/pgsql/ready/postgresql.conf
tail /opt/pgsql/ready/pg_hba.conf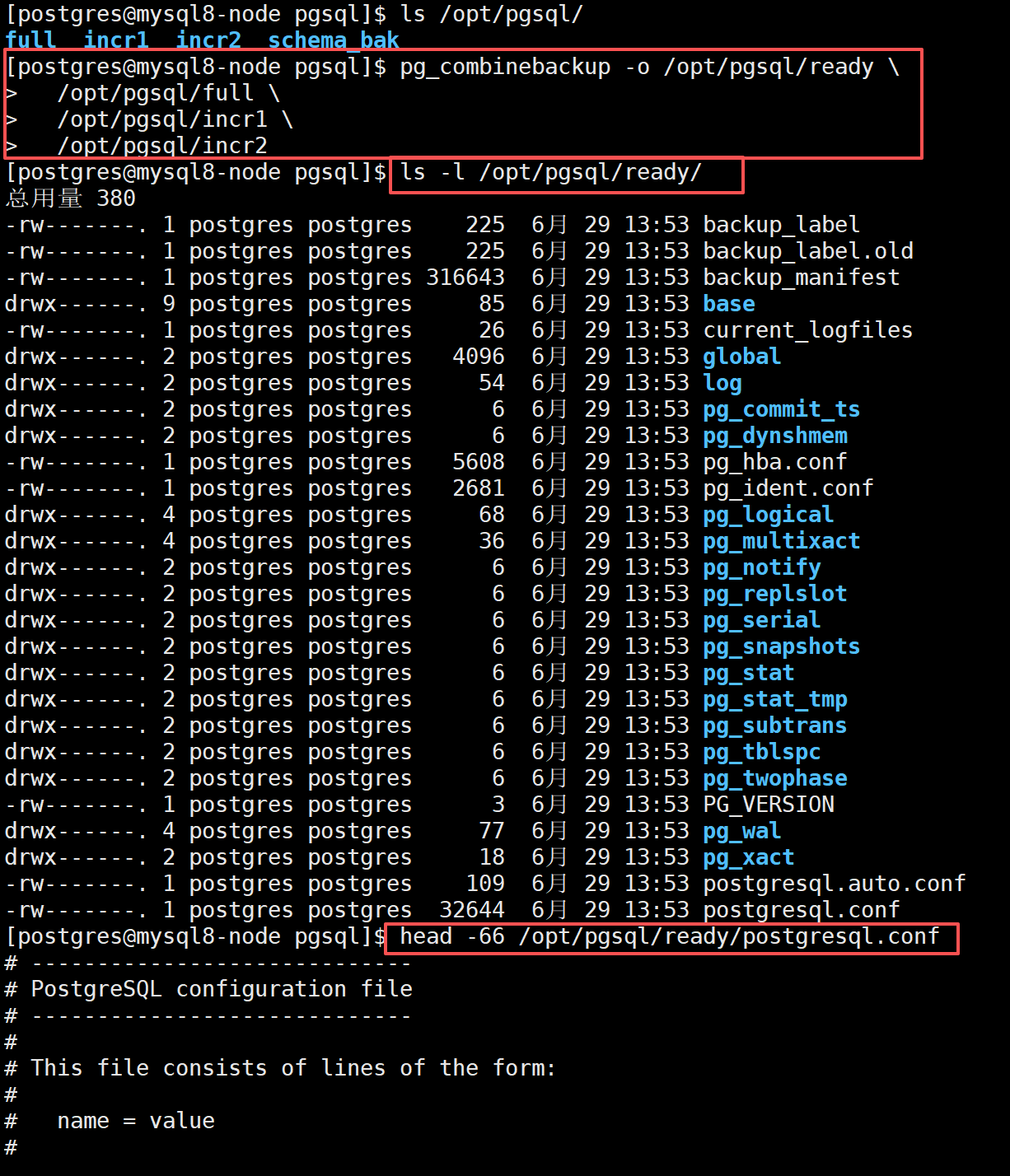
启动合并后的实例并验证数据
启动新实例(使用不同端口,避免与原有实例冲突)
su - postgres
# 递归修改所有者
chown -R postgres:postgres /opt/pgsql/ready
# 严格设置数据库目录权限(PG强制要求700)
chmod -R 700 /opt/pgsql/ready
# 手动启动数据库,指定数据目录,临时端口改为5432
pg_ctl -D /opt/pgsql/ready -o '-p 5432' start-- 如果想使用systemctl start postgresql-18启动,那么需要将ready中的数据放到 /var/lib/pgsql/18/data目录下
链接验证
psql -p5432查看连接信息:
\conninfo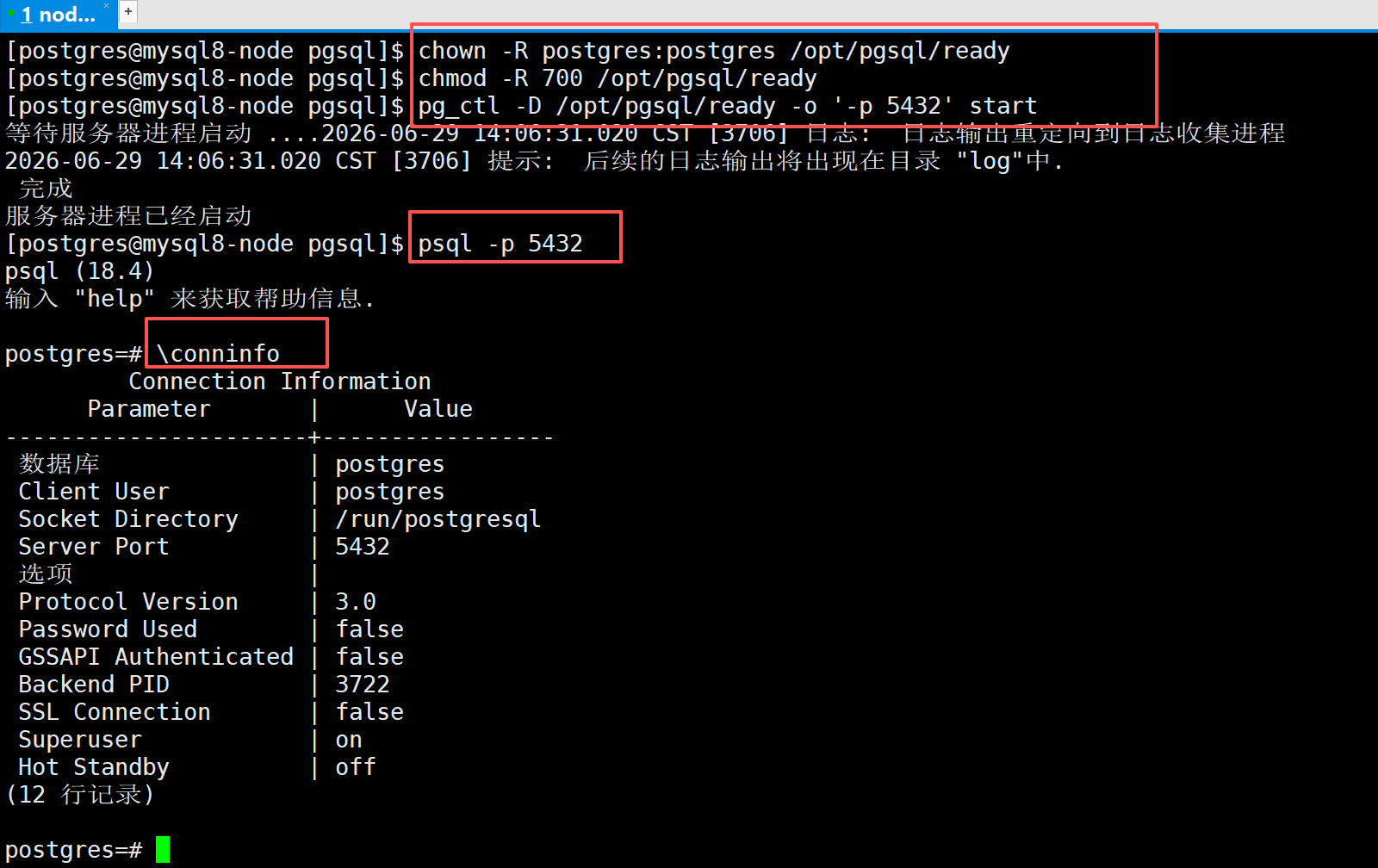
查看数据
SELECT datname FROM pg_database;
\c itheima
\dt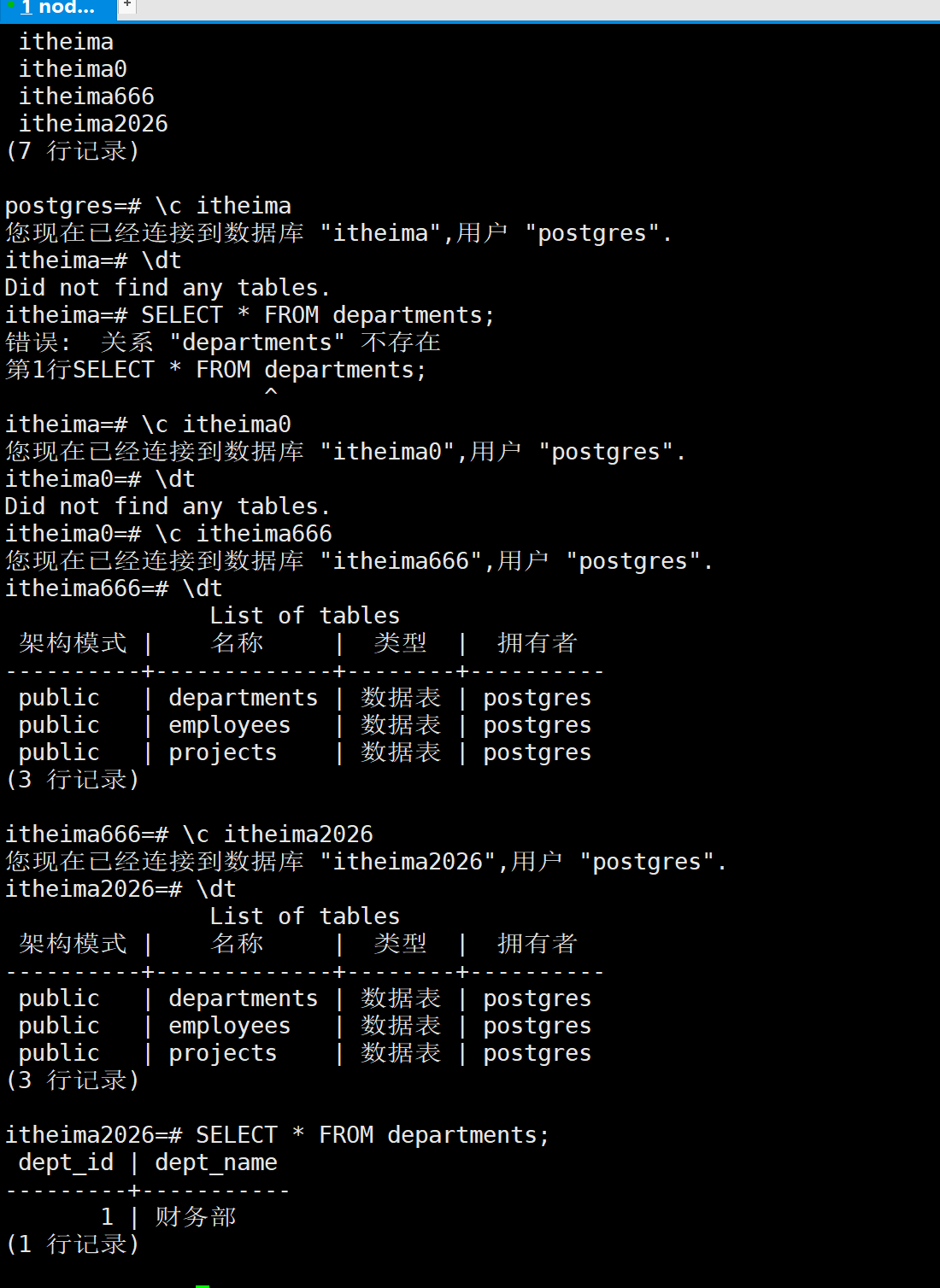
数据恢复成功,与备份时的状态一致
关键命令速查
|------|---------------------------------------------------------------------------|
| 操作 | 命令 |
| 全量备份 | pg_basebackup -D /路径/全备目录 -P -v |
| 增量备份 | pg_basebackup -D /路径/增量目录 --incremental=/路径/前一次备份/backup_manifest -P -v |
| 合并增量 | pg_combinebackup -o /输出目录 全备目录 增量1 增量2 ... |
| 启动实例 | pg_ctl -D /合并后目录 -o '-p 端口' start |