这是非线性优化 最经典的一条数学主线,也是 PnP、Bundle Adjustment、ICP、相机标定、SLAM 等算法的基础
三者之间的关系可以用一张图概括:
cpp
泰勒展开
│
┌────────────────┴────────────────┐
│ │
二阶泰勒 一阶泰勒
│ │
▼ ▼
牛顿法(Newton) 高斯牛顿(GN)
│ │
└──────────────┬──────────────────┘
▼
Levenberg-Marquardt(LM)它们的区别主要在于 Hessian(海森矩阵)的处理方式。
一、泰勒公式
设目标函数 f(x)
那么在x点附近展开:
一阶泰勒
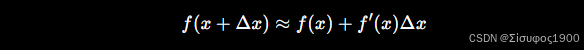
二阶泰勒
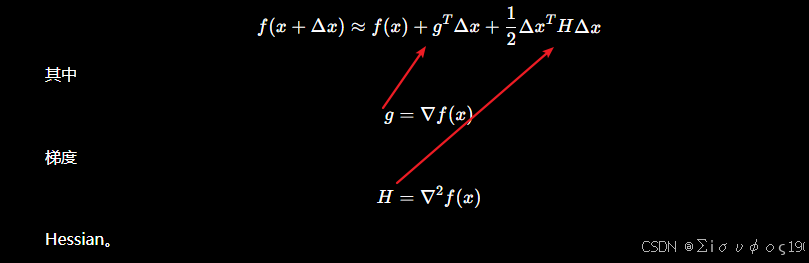
二、牛顿法(Newton)
思想
直接利用二阶泰勒寻找极小值。
目标: 
优点
- 二阶收敛(接近最优点时非常快)
- 收敛步数少
- 精度高
缺点
- Hessian难计算
- Hessian求逆开销大
- Hessian可能不可逆
- 初值不好容易发散
三、高斯牛顿法(Gauss-Newton)
适用于
最小二乘:
写成: 其中 e=e(x)
一阶泰勒
误差展开: 其中
J 就是雅克比
代入目标函数:
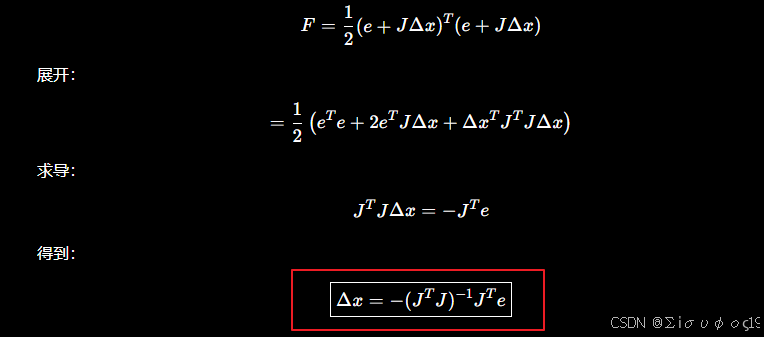
为什么不用真正 Hessian?
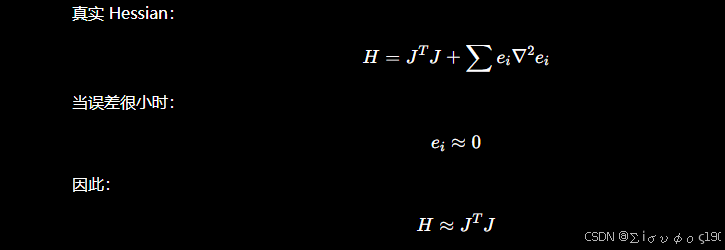
优点
- 不需要计算 Hessian
- 比牛顿法简单
- 收敛速度快
- 工程应用广泛
缺点
- 初值要求高
- 离最优解远容易发散
可能病态
四、LM算法(Levenberg--Marquardt)
LM是在高斯牛顿基础上加入阻尼。
方程:

阻尼作用
当 的时候
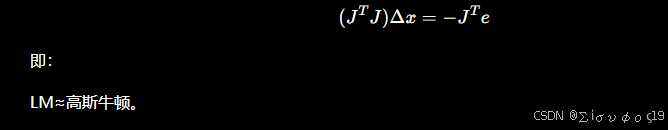
当 的时候
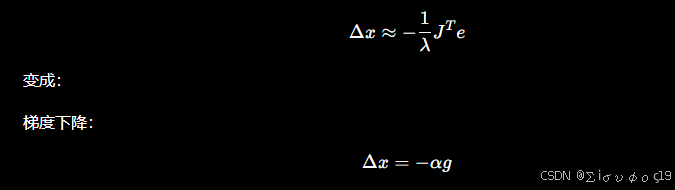
λ如何调整
如果:
误差下降
则: 减少步长
如果误差增加了:
优点
- 收敛稳定
- 不容易发散
- 对初值要求低
- 工程应用最广
缺点
- 每次需要调整阻尼
- 计算量略大于高斯牛顿
- 参数设置影响速度
五、三种算法比较
| 方法 | 泰勒展开 | Hessian | 收敛速度 | 初值要求 | 稳定性 | 计算量 |
|---|---|---|---|---|---|---|
| 牛顿法 | 二阶 | 真正Hessian | 最快 | 很高 | 差 | 最大 |
| 高斯牛顿 | 一阶(误差) | (J^TJ)近似 | 快 | 较高 | 一般 | 中等 |
| LM | 一阶(误差) | (J^TJ+\lambda I) | 快 | 较低 | 最好 | 略高 |
泰勒公式
│
▼
二阶泰勒
│
▼
牛顿法(真实 Hessian)
│
├── Hessian 难求
▼
高斯牛顿(H≈JᵀJ)
│
├── 容易发散
▼
LM(JᵀJ+λI)
│
▼
工业视觉最常用的非线性优化算法
可以把它们理解为:
- 牛顿法:理论最优,但代价最高。
- 高斯牛顿法:利用最小二乘结构,用 JTJ近似 Hessian,在效率和精度之间取得平衡。
- LM 算法:在高斯牛顿基础上加入阻尼机制,兼顾收敛速度与稳定性,因此成为现代计算机视觉和 SLAM 中的主流优化方法。