2026年的Java后端面试,画风彻底变了。背了三个月八股,面试官一个都没问------HashMap的put流程不考了,改问"并发下HashMap有什么问题?ConcurrentHashMap怎么解决?你线上遇到过size()不准确吗?"线程池参数不背了,改问"你们系统IO密集型和CPU密集型任务,分别怎么设核心数和最大数?拒绝策略选哪个?为什么?"
先说传统考点的新考法。 JVM调优、并发编程、MySQL索引、Redis缓存这些基本功依然是地基,但问法全部场景化。面试官不再满足你背出结论,他要听你推演的过程。比如问"索引为什么用B+树",标准答案背出来没用,你得能讲出"B+树矮胖,IO次数少,叶子节点有序支持范围查询"背后的工程权衡。项目里用了Redis做限流,那Redis数据结构和限流算法你必须吃透。OOM排查的完整流程(jps定位→jstat监控GC→jmap dump堆→MAT分析)也是大厂区分度的核心考点。
再说AI方向,这是2026年拉开薪资差距的关键分水岭。 62%的企业正在用Java构建AI功能,Java+AI复合岗位增长74%,薪资高出30%-50%。面试必问Spring AI------它的核心不是大模型本身,而是统一抽象设计。你得讲清楚四大核心组件:Model接口(ChatModel/EmbeddingModel)、Prompt(SystemMessage/UserMessage)、Response、ChatClient流式API构建器。RAG检索增强生成也是高频考点,从向量数据库选型(Milvus/Redis)、文档切片策略,到检索召回和重排,整条链路要能讲透。Agent方向问得更细:MCP协议、Function Calling、工具调用链怎么设计。JDK21的虚拟线程更是加分项,能结合AI长连接响应场景讲出QPS提升数据,面试官直接眼前一亮。
项目准备上,别再写烂大街的电商/社交项目了。 面试官想看的是:你用Spring AI改造过什么现有系统?智能客服还是文档问答?RAG知识库怎么工程化落地的?-一个2000行Java从零实现的AI Agent项目,面试能讲30分钟。把"业务痛点→AI方案→成本收益→上线指标"这条线捋清楚,比背一百道题都管用。
三条转型路径最快上岸 :首选AI融合升级------用Spring AI改造现有项目加智能模块;其次是云原生AI工程化------Kubernetes+Docker+虚拟线程;第三是垂直领域深耕------金融风控、电商推荐、政企审批。
由于篇幅限制,笔记无法全部为大家展示出来,就以截图主要内容的形式让大家参考啦,需要完整版的小伙伴可以扫一扫获取

类别一:数据、接口与类型契约
1.场景:异构AI模型"工具调用"响应的统一处理
2.场景:AIAPI升级,新增可选字段的向后兼容
3.场景:复杂工作流配置的校验
4.场景:AI绘画参数的复杂校验
5.场景:长文本总结API的设计与校验
6.场景:类型安全的AI消息对象体系
7.场景:RAG答案引用片段的响应设计
8.场景:同一接口支持JSON和Protobuf响应
9.场景:复杂AI审核响应到内部模型的映射
10.场景:内部服务从V1API到V2API的无感迁移
11.场景:AI模型支持多种输出格式(SON/XML)的动态格式化
12.场景:服务端Prompt模板解析与安全变量替换
13.场景:支持多协议的ModelEndpoint配置对象
15.场景:分页查询历史对话及其最后消息摘要
16.场景:Swagger生成复杂泛型接口的准确文档
17.场景:A/B测试信息的无侵入式透传
18.场景:文件上传与附加文本指令的接口设计
19.场景:根据配置动态选择ModelService实现
20.场景:实现AI模型列表接口的条件请求(ETag)

类别二:高并发、流式响应与异步处理
1.场景:服务端SSE代理的断线重连、消息去重与网络抖动处理
2.场景:服务端的流式Markdown分片与转发
3.场景:服务端对多独立片段流式响应的Chunk合并算法
4.场景:服务端支持"优先级调度"的流式请求队列
5.场景:在SpringWebFlux中优化AI流式响应的处理与资源隔离
6.场景:服务端的流式数据缓存与断点续传支持
7.场景:利用Java并发工具并行处理多个AI流式响应
8.场景:解析AI服务端返回的流式数据中的自定义事件
9.场景:服务端实现"流式进度估算"并推送给客户端
10.场景:协调AI流式输出与语音合成(TS)的服务端同步
11.场景:从数据库分页读取海量数据,分批流式发送给AI处理
12.场景:异步处理"翻译整本电子书"的长时、可分解任务
13.场景:针对AI服务的分布式平滑限流
14.场景:在WebFlux中将流式Flux聚合为Mono<CompleteResp...
15.场景:实现用户中断AI生成请求的信号传递
16.场景:基于消息触发,并行调用多个AI服务并聚合结果
17.场景:对低优先级AI任务实现基于优先级的延迟调度
18.场景:解析AI流式响应中的自定义控制事件
19.场景:使用ProjectLoom虚拟线程重构阻塞式AI任务服务
20.场景:设计用于AI服务HTTP/2长连接的连接池

类别三:状态管理、业务流程与架构
1.场景:请为"AI智能客服工单处理"设计一个状态机。状态包括待分配、AI处理中、等待人工、已解决
等。触发事件包括用户回复、AI推荐方案、人工接管。请画出状态转移图,并用Java枚举和状态模式实现
核心逻辑。
2.场景:在分布式部署中,如何实现一个分布式的、可重入的锁,来保证"为同一用户生成月度报告"的定时任务
在同一时刻只有一个实例执行?请对比基于Redis和基于ZooKeeper的实现方案。
3.场景:用户与AI的对话会话(ChatSession)需要支持分布式集群中的任意节点访问。你会如何设计这个会
话对象的存储、检索和过期策略?请比较将会话状态存储在Redis与存储在数据库中的利弊。
4.场景:当AI调用外部工具(如查询库存、创建日历事件)失败时,系统应进入"等待修复"状态,并通知人工。
请用状态模式或SpringStateMachine实现此流程,并考虑失败重试和超时机制。
5.场景:请用DDD(领域驱动设计)的思想,对"AI绘画订单"进行领域建模。识别核心聚合根(Order)、实体(ImageTask)、值对象(PaintingStyle)和领域事件(OrderCreated,ImageGenerated)。
6,场景:用户编辑了已提交给AI处理的Prompt,需要取消l日任务并启动新任务。请设计一个TaskManager服务,管理任务的生命周期,并确保状态变更的原子性(如从PROCESSING到CANCELLED)。
7.场景:在事件驱动架构下,UserMessageReceivedEvent事件会触发AI处理。但同一用户可能在极短时间内发送多条消息。如何确保对于同一会话,AI处理是串行的,避免回答错乱?请基于消息队列(如Kafka分区键)设计解决方案。
8,场景:请设计一个"工作流引擎"的数据模型,用于支持用户拖拽配置包含AI节点、判断节点、人工审核节点的流程。如何持久化这个流程图,并在运行时解释执行?
9.场景:AI生成的代码需要经过"自动化测试"和"安全扫描"两个后续步骤。请用SpringEvents或消息队列设计一个流程,在AI生成完成后自动发布事件,触发后续的监听器执行,并最终汇总结果通知用户。
10.场景:在CQRS架构下,用户的"发送消息"命令(Command)会触发AI处理并更新ChatSession聚合。如何设计"查询端"(QuerySide)的投影(Projection),来高效支持"按关键词搜索历史对话"这个查询需求?
11,场景:我们需要为每个AI对话会话维护一个"上下文令牌窗口"。当新消息加入时,如果超出窗口大小,需要按特定策略(如FIFO、或基于重要性的裁剪)移除I日消息。请设计一个线程安全的TokenWindow类来实现此逻辑。
12.场景:在Saga分布式事务模式中,"创建订单并调用AI生成内容"作为一个业务事务。如果AI服务调用成功但扣款失败,需要触发补偿操作(撤销AI生成的内容)。请设计Saga的协调流程和补偿逻辑。
13,场景:多租户SaaS平台中,每个租户有独立的AIAPI密钥、模型权限和费率限制。如何在运行时根据当前租户上下文,动态选择正确的配置和客户端实例?请给出基于ThreadLocal或SpringScope的实现思路。
14.场景:请设计一个RateLimit值对象,包含capacity、refillRate、tokens等属性,并实现一个
tryAcquire方法。然后,将其应用于"按租户维度限制AI调用频率"的业务规则中。
15,场景:用户的操作(如"点赞AI回答"、"提交反馈")需要异步更新AI模型的微调数据源。如何设计一个最终一致性的方案,确保用户反馈能被可靠地收集和处理,即使反馈服务暂时不可用?
16,场景:在"AI辅助编程"场景,需要维护文件的编辑历史(类似迷你Git)。请设计一个版本管理的数据结构,支持提交更改、查看差异、以及回滚到某个AI建议之前的版本。
17.场景:当AI服务大规模故障时,我们需要将系统整体降级,将用户请求导向一个静态的提示页面。请设计一个基于配置中心(如Apollo,Nacos)的全局降级开关,并描述其在集群中生效的机制。
18,场景:在微服务架构下,"用户服务"发生"用户注销"事件。"AI对话服务"需要监听此事件,并清理该用户的所有会话缓存和临时文件。请描述如何通过消息总线可靠地实现这一跨服务数据同步。
19,场景:请为"AI模型训I练任务"设计一个状态模型,包含QUEUED,DATA_PREPROCESSING,TRAINING,EVALUATING,DEPLOYING,COMPLETED,FAILED等状态。并考虑如何在任务失败时,根据失败原因(如数据错误、资源不足)提供重试建议。
20,场景:在订单履行流程中,AI用于生成产品描述。但描述生成后需要人工审核。请设计一个"审批工作流",支持多级审批、驳回修改、以及审批通过后自动上架。如何用状态机和任务队列实现?

类别四:性能、安全、成本与数据持久化
1.场景:AI模型列表和配置信息变化不频繁但读取极其频繁。请设计一个多级缓存方案,使用Caffeine作为本地缓存,Redis作为分布式缓存,并解决缓存穿透、雪崩和一致性问题。
2,场景:用户与AI的对话历史可能非常长(上万条)。请设计数据库表结构来存储这些历史,并支持高效地:1)按会话分页查询;2)模糊搜索对话内容;3)归档日对话。你会使用什么类型的数据库和索引策略?
3.场景:在RAG系统中,需要将知识库文档切片并向量化后存入向量数据库(如Milvus,Pinecone)。请描述Java后端如何与向量数据库交互,实现"给定问题,检索最相关的N个文本片段"的流程。
4,场景:为了防止API密钥被盗用,我们不应在前端硬编码,而应由后端代理。请设计一个安全的密钥管理方案:如何存储、轮换密钥,并在代理请求时将其安全地添加到请求头中?如何为不同内部服务分配不同权限的密钥?
5,场景:用户上传的文档可能包含公司机密。在发送给第三方AI服务前,必须进行脱敏。请设计一个可扩展的脱敏框架,支持通过正则、关键词列表和机器学习模型识别敏感信息(如身份证号、手机号),并将其替换为占位符。
6,场景:我们需要按部门统计AI的Token消耗成本。请设计数据埋点、收集和聚合方案。是每次调用后实时更新统计表,还是发送消息异步处理?如何保证统计数据的准实时性和准确性?
7,场景:某些恶意用户可能通过脚本高频调用"代码生成"接口,消耗大量资源。请实现一个基于滑动时间窗口的分布式限流(使用Redis),针对用户ID和接口两个维度进行限制。
8,场景:AI生成的内容(如营销文案)需要入库前审核。请设计一个异步审核流水线:内容先入待审表,由审核服务(人或AI)处理,审核结果通过消息队列回写。如何保证内容状态同步的最终一致性?
9,场景:用户对话中包含了大量图片的Base64编码,导致单条记录巨大。请设计存储策略:是将图片单独存到对象存储(如S3),数据库中只存URL,还是使用数据库的LOB字段?各自的考量是什么?
10.场景:我们的服务调用多个AI供应商,其中一家供应商的失败率突然飙升。请基于Resilience4j实现一个熔断器,当失败率达到阀值时自动熔断,并在一段时间后进入半开状态试探恢复。
11.场景:为降低Token成本,我们希望对用户输入的冗长Prompt进行智能摘要后再发送。请设计一个服务,它能判断输入长度,当超过阀值时,调用一个更便宜的模型(如GPT-3.5)进行摘要,再用摘要调用主力模型(如GPT-4) 。
12,场景:在AI绘画场景,生成的高清图片很耗存储。请设计一个生命周期管理策略:热门图片缓存,7天前的图片移入低频存储,30天前的图片自动删除。如何用Spring的@Scheduled和对象存储的生命周期规则协同实现?
13.场景:数据库中的conversations表随着时间推移变得非常庞大,影响查询性能。请设计一个历史数据归档方案,将6个月前的对话迁移到归档表(或数据仓库),并提供统一的查询接口。
14,场景:用户敏感操作(如删除对话、清空历史)需要记录详细的操作日志(谁、何时、操作什么、IP地址)。请设计一个基于AOP的审计日志切面,并确保日志记录不影响主业务流程的性能。
15,场景:为了防止爬虫批量抓取我们公开的AI生成内容,请设计一套后端防护策略,包括请求频率限制、User-Agent校验、以及针对可疑IP的行为分析(如短时间内访问大量无关联的页面)。
16,场景:我们需要在Java应用中本地运行一个轻量级句子嵌入模型(如all-MiniLM-L6-v2),为文本生成向量。如何集成ONNXRuntime或DJIL库?需要注意哪些内存管理和性能优化问题?
17.场景:AI服务返回的响应可能包含不实信息(幻觉)。请设计一个"事后验证"流程,对关键事实(如日期、数据)通过调用内部知识库或搜索引擎进行交叉验证,并将验证结果标记在响应中。
18,场景:在微服务架构下,如何集中化管理所有服务的AI调用配置(如端点、超时、重试策略)?使用配置中心(如Nacos)时,如何实现配置的热更新,并确保各个服务实例能动态生效?
19,场景:设计一个"资源包"模型,用户购买一定额度的Token包。每次AI调用后,实时扣除相应Token。请设计数据库表结构和扣减逻辑,确保在高并发下不会超卖,并能给出精确的余额提示。
20,场景:AI生成的内容可能需要符合不同地区的法律法规(如GDPR的"被遗忘权")。请设计一个功能,允许用户导出其所有数据,并永久删除。这涉及到哪些服务的数据清理?如何保证删除的彻底性?

类别五:工程化、运维与可观测性
1.场景:我们需要在Kubernetes中部署AI代理服务,该服务需要访问多个外部AIAPI。请设计ConfigMap和Secret来管理不同环境的配置(如API端点、密钥),并描述如何通过环境变量或Volume挂载到Pod中。
2.场景:请设计一个完整的Java应用监控指标方案,使用Micrometer暴露给Prometheus。需要包含哪些关键指标?(如:各AI接口的QPS、P99延迟、Token消耗速率、不同状态码的计数、JVM内存和线程池状态)。
3.场景:当AI服务调用发生大量超时或4xx/5xx错误时,需要触发告警。请描述如何在Prometheus中配置相关的告警规则(AlertingRule),并通过Alertmanager将通知发送到钉钉/企业微信。
4.场景:请为AI网关服务设计结构化日志。日志中应包含哪些关键字段(如traceId,userId,model,promptLength,responseLength,'latency,costTokens,statusCode)?如何与ELK(Elasticsearch,Logstash,Kibana)栈集成进行日志分析?
5.场景:你需要实现一个"动态功能开关",在不重启服务的情况下,控制某些AI功能(如"启用DeepSeek模型"、"使用新的Prompt模板")的开启或关闭。请基于配置中心或数据库实现此开关,并保证在集群中快速生效。
6,场景:我们的AI应用依赖一个内部的"敏感词过滤"服务。请设计一个健康检查接口(/actuator/health的扩展),能检测该依赖服务的状态,并在其不可用时将应用整体健康状态标记为DOWN或OUT_OF_SERVICE。
7.场景:请设计CI/CD流水线(如GitLabCI),实现:代码提交时触发代码规范检查、单元测试、集成测试(使用Testcontainers模拟Redis等)、构建Docker镜像、安全扫描,并自动部署到测试环境。
8,场景:AI服务的API密钥需要定期轮换以提高安全性。请设计一个自动化的轮换方案:如何生成新密钥、更新到配置中心、并让所有服务实例无感知地、平滑地切换到新密钥(避免在轮换期间出现请求失败)?
9.场景:在微服务调用链中,如何集成OpenTelemetry来实现分布式追踪?请描述从网关接收请求,到调用业务服务,再到调用AI服务,这个过程中Trace和Span是如何传递和记录的。
10.场景:我们的SpringBoot应用引入了多个AISDK,导致JAR包体积巨大。请给出优化方案:如何通过依赖分析、排除未使用的传递依赖、以及使用spring-boot-thin-launcher来减小镜像大小?
11.场景:请设计一个金丝雀发布(CanaryRelease)方案:新版本AI服务先部署1个实例,将10%的流量导入这个新实例,监控其错误率和延迟。若无异常,再逐步增加流量比例。如何实现流量切分(如通过网关的权重路由)?
12.场景:AI模型文件(如.onnx,bin)很大,不适合打包进Docker镜像。在K8s部署时,如何通过InitContainer或持久化卷(PersistentVolume)在Pod启动时下载模型文件到本地?
13,场景:你需要编写一个集成测试,验证"从用户提问到收到AI回复"的完整流程。请描述如何用@SpringBootTest和Mock Server(如MockWebServer)来模拟外部AI服务的响应。
14,场景:请设计一个优雅关机的处理逻辑。在收到SIGTERM信号时,应用应:1)停止接收新请求;2)等待正在处理的AI流式请求完成或超时;3)关闭连接池;4)然后退出。如何在SpringBoot中实现?
15,场景:如何监控AI调用成本?请设计一个指标,实时计算每分钟的Token消耗费用(假设不同模型单价不同),并通过Grafana面板展示费用趋势和模型用量排行。
16,场景:在A/B测试新老Prompt模板的效果时,你需要收集两组在响应质量、用户满意度等指标上的差异。如何在代码中埋点,并将实验分组信息(如group=A)关联到具体的请求日志和业务指标中?
17,场景:当线上出现"AI返回内容格式错误导致解析失败"的问题时,如何快速定位?请描述你会在异常捕获和日志中记录哪些上下文信息,以及如何通过TraceId快速找到相关的用户请求和AI原始响应。
18,场景:为方便问题排查,我们需要在界面上能"重放"任意一次用户与AI的历史对话。请描述后端如何存储足够的信息(包括原始请求、响应、中间结果)来支持对话的精确重放。
19,场景:请设计一个简单的容量规划模型。假设单个AI请求平均耗时2秒,消耗0.1核心CPU,你的Pod配置为2核心。你想要维持P95延迟在5秒以内,预估需要支持100QPS。你需要部署多少个Pod实例?请给出估算思路。
20,场景:在K8s中,如何为AI服务配置水平Pod自动伸缩(HPA)?基于什么指标(如CPU使用率、内存使用率、还是自定义的QPS指标)?如何设置合理的目标值和边界?

类别六:核心AI特性与集成
1.场景:当AI模型返回一个FunctionCall(例如{"name":"get_weather","arguments":{"city":"Beijing"}})时,请设计后端的工作流程:如何安全地解析、路由到对应的工具实现、执行(可能调用外部API)、并将结果格式化后返回给AI模型?
2.场景:在RAG系统中,用户提问"公司最新的年假政策是什么?"。请描述后端完整的处理链条:从接收问题,到将其向量化,在向量数据库中检索相关片段,再到组装包含上下文的Prompt发送给AI,最后返回答案。
3.场景:请用代码草图展示,如何利用Spring的@EventListener或消息队列,实现一个简单的工作流:用户提问->触发意图识别AI->根据意图(如"翻译"或"总结")路由到不同处理AI>聚合结果。
4,场景:你需要设计一个"模型路由"服务。根据请求的属性(如语言是中文还是英文、需求是创意写作还是逻辑推理、预算高低),动态选择最合适的AI模型(如GPT-4,Claude-3,国产大模型)进行调用。请设计路由规则的数据结构和匹配逻辑。
5.场景:在"AI辅助编程"场景,用户选择一段代码并请求"解释"。后端需要将代码和指令发送给AI。请设计一个Prompt模板系统,允许管理员根据不同编程语言(ava,Python,JavaScript)动态配置和优化对应的解释性Prompt。
6,场景:如何实现一个简单的"模型熔断与降级"策略?当首选模型(如GPT-4)连续失败或超时时,自动将流量切换到备选模型(如GPT-3.5),并在首选模型恢复后逐步切回。
7,场景:对于"生成周报"这种长文本任务,AI的上下文窗口可能不够。请设计一个"分而治之"的算法:将任务拆分成多个子问题(如按项目拆分),分别调用AI,最后将结果合并。需要注意哪些问题(如子任务间的连贯性)?
8.场景:在多轮对话中,如何管理不断增长的上下文?请实现一个"智能摘要"策略:当对话轮数或Token数超过阀值时,自动调用AI对早期对话进行摘要,并用摘要替换掉原始冗长的历史,以节省Token并保持核心信息。
9,场景:请设计一个"多模型投票"机制。将同一个问题发送给三个不同的AI模型,收集它们的回答,然后通过一个"裁判"模型或基于规则的方法(如选择最简洁、最符合格式要求的)选出最终答案。如何实现并行调用和结果聚合?
10.场景:你需要集成一个本地的开源大模型(如通过Ollama部署的Llama3)。请描述Java后端如何通过HTTP或gRPC与这个本地模型服务交互,并处理与商用API在响应格式上的差异。
11、场景:在AI绘画中,用户可能会多次调整参数(如"更明亮一些"、"增加一个小孩")进行迭代。请设计一个会话机制,能够基于上一张图片的生成参数和种子(seed)进行微调,而不是完全重新生成。
12,场景:如何实现一个"函数注册表",允许系统在运行时动态注册新的工具函数(如search_web,
query_database)及其JSON Schema,供AI模型在Function Calling时使用?
13.场景:设计一个"思维链(Chain-of-Thought)"的调用模式。首先让AI输出其推理过程,然后根据内部规则对推理过程进行校验或提取关键步骤,最后再输出最终答案。如何在服务端协调这个多步过程?
14,场景:在知识库问答中,如何实现"引|用溯源"?即,在返回答案的同时,高亮显示答案来源于知识库中的哪几个原文片段。请设计返回的数据结构以及前端交互所需的标注信息。
15.场景:用户要求"用莎士比亚的风格写一首关于春天的诗"。请设计一个两阶段Prompt:第一阶段让AI分析"莎士比亚风格"的特点;第二阶段基于分析结果进行创作。如何在服务端串联这两个AI调用?
16,场景:当AI在处理用户请求时,可能需要询问用户以澄清模糊意图(如"您指的是北京还是南京?")。请设计一个中断-恢复机制:暂停当前AI处理流程,将问题返回给用户,并在收到用户回复后,从暂停点继续执行。
17,场景:如何对AI生成的代码进行"后处理"?例如,自动调用代码格式化工具(如Prettier)、进行基础的静态检查、或者插入相关的import语句。请设计一个可插拔的后处理器管道。
18,场景:在"AI法律顾问"场景,生成的法律文本需要插入准确的条款引|用(如"根据《XX法》第N条")。请设计一个RAG流程,从法律条文数据库中检索相关条款,并将其作为上下文提供给AI模型。
19,场景:请设计一个批处理接口,接收一个文件(如包含100个商品描述的CSV),调用AI批量生成对应的营销文案。需要考虑API的速率限制、处理进度反馈、以及部分失败时的处理(是全部失败还是继续剩余任务)。
20,场景:如何实现"AI结果缓存"?对于相同或高度相似的用户问题,直接返回缓存的结果,避免重复调用AI产生成本和延迟。请设计缓存键的生成逻辑(如对Prompt进行标准化和哈希),以及缓存的过期策略。

Java面试八股
JavaOOP面试题
1、什么是B/S架构?什么是C/S架构
2、Java都有那些开发平台?
3、什么是JDK?什么是JRE?
4、Java语言有哪些特点
5、面向对象和面向过程的区别
6、什么是数据结构?
7、Java的数据结构有那些?
8、什么是OOP?
9、类与对象的关系?
10、Java中有几种数据类型
11、标识符的命名规则。
12、instanceof关键字的作用
13、什么是隐式转换,什么是显式转换
14、Char类型能不能转成int类型?能不能转化成string类型,能不能转成double类型
15、什么是拆装箱?
16、Java中的包装类都是那些?
17、一个java类中包含那些内容?
18、那针对浮点型数据运算出现的误差的问题,你怎么解决?
19、面向对象的特征有哪些方面?
20、访问修饰符public,private,protected,以及不写(默认)时的区别?
21、String是最基本的数据类型吗?
22、floatf=3.4;是否正确?
23、short s1=1;s1=s1+1;有错吗?short s1=1;s1 +=1;有错吗?
24、重载和重写的区别
25、equals与=---的区别
36、++与i++的区别
37、程序的结构有那些?
38、数组实例化有几种方式?
39、Java中各种数据默认值
40、Java常用包有那些?

Java集合/泛型面试题
1、ArrayList和linkedList的区别
2、HashMap和HashTable的区别
3、Collection包结构,与Collections的区别
4、泛型常用特点(待补充)
5、说说List,Set,Map三者的区别
6、Array与ArrayList有什么不一样?
7、Map有什么特点
8、集合类存放于Java.util包中,主要有几种接口
9、什么是list接口
10、说说ArrayLlist(数组)
11、Vector(数组实现、线程同步)
12、说说LinkList(链表)
13、什么Set集合
14、HashSet(Hash表)
15、什么是TreeSet(二叉树)
16、说说LinkHashSet (HashSet+LinkedHashMap)
17、HashMap(数组+链表+红黑树)
18、说说ConcurrentHashMap
19、HashTable(线程安全)
20、TreeMap (可排序)
21、LinkHashMap(记录插入顺序)
22、泛型类
23、类型通配符?
24、类型擦除

多线程&并发面试题
1、Java中实现多线程有几种方法
2、继承 Thread类
3、实现Runnable接口。
4、ExecutorService、Callable、Future有返回值线程
5、基于线程池的方式
6、4种线程池
7、如何停止---个正在运行的线程
8、notifyO和notifyAll0有什么区别?
9、sleep0和wait0 有什么区别?
10、volatile是什么?可以保证有序性吗?
11、Thread类中的start0和run0方法有什么区别?
12、为什么wait,notify和notifyAl这些方法不在thread类里面?
13、为什么wait和notify方法要在同步块中调用?
14、Java中interrupted 和isInterruptedd方法的区别?
15、Javar中synchronized 和 ReentrantLock有什么不同?
16、有三个线程T1,T2,T3,如何保证顺序执行?
17、SynchronizedMap和ConcurrentHashMap有什么区别?
18、什么是线程安全
19、Thread类中的yield方法有什么作用?
20、Java线程池中submit0和execute0方法有什么区别?
21、说一说自己对于synchronized关键字的了解
22、说说自己是怎么使用synchronized关键字,在项目中用到了吗synchronized关键字最主要的三种使用方式
23、什么是线程安全?Vector是一个线程安全类吗?
24、volatile关键字的作用?
25、简述一下你对线程池的理解
26、线程生命周期(状态)
27、新建状态(NEW)
28、就绪状态(RUNNABLE)
29、运行状态(RUNNING)
30、阻塞状态(BLOCKED)
31、线程死亡(DEAD)
32、终止线程4种方式
33、start与run区别
34、JAVA 后台线程
35、什么是乐观锁
36、什么是悲观锁
37、什么是自旋锁
38、Synchronized 同步锁
39、ReentrantLock
40、Condition类和Object类锁方法区别区别

JVM面试题
1、java中会存在内存泄漏吗,请简单描述。
2、64 位JVM中,int 的长度是多数?
3、Serial与Parallel GC之间的不同之处?
4、32位和64位的JVM,int类型变量的长度是多数?
5、Java 中 WeakReference与SoftReference 的区别?
6、JVM选项-XXx+UseCompressedOops有什么作用?为什么要使用
7、怎样通过Java程序来判断JVM是32位还是64位?
8、32位JVM和64位JVM的最大堆内存分别是多数?
9、JRE、JDK、JVM及JIT之间有什么不同?
10、解释Java堆空间及GC?
11、JVM 内存区域
12、程序计数器(线程私有)
13、虎拟机栈(线程私有)
14、本地方法区(线程私有)
15、你能保证GC执行吗?
16、怎么获取Java程序使用的内存?堆使用的百分比?
17、Java中堆和栈有什么区别?
18、描述一下JVM加载class文件的原理机制
19、GC是什么?为什么要有GC?
20、堆(Heap-线程共享)-运行时数据区
21、方法区/永久代(线程共享)
22、JVM运行时内存
23、新生代
24、老年代
25、永久代
26、JAVA8 与元数据
27、引用计数法
28、可达性分析
29、标记清除算法(Mark-Sweep)
30、复制算法(copying)
31、标记整理算法(Mark-Compact)
32、分代收集算法
33、新生代与复制算法
34、老年代与标记复制算法
35、 JAVA强引用
36、JAVA软引用
37、JAVA弱引用
38、JAVA虚引用
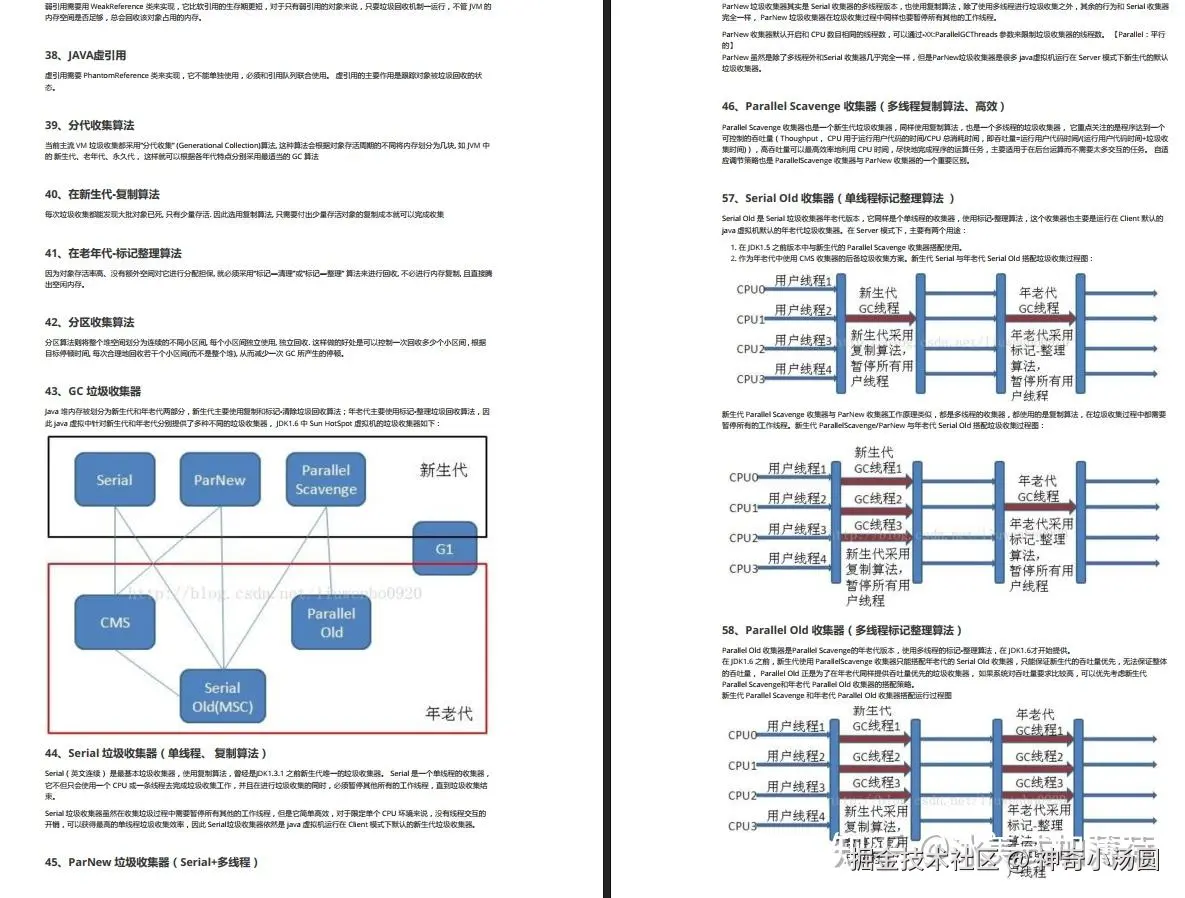
39、分代收集算法
40、在新生代-复制算法
Mysql面试题
1、数据库存储引攣
2、InnoDB (B+树)
2、TokuDB(Fractal Tree-节点带数据)
3、MylASM
4、 Memory
5、数据库引掌有哪些
6、InnoDB与MyISAM的区别
7、索引
8、常见索引原则有
9、数据库的三范式是什么
10、第一范式(1st NF-列都是不可再分)
11、第二范式(2ndNF-每个表只描述一件事情)
12、第三范式(3rdNF-不存在对非主键列的传递依赖)
13、数据库是事务
14、SQL优化
15、简单说一说drop、delete与truncate的区别
16、什么是视图
17、什么是内联接、左外联接、右外联接?
18、并发事务带来哪些问题?
19、事务隔离级别有哪些?MySQL的默认隔离级别是?
20、大表如何优化?
21、水平分区
22、分库分表之后,id主键如何处理
23、存储过程(特定功能的SQL语句集)
24、存储过程优化思路
25、触发器(一段能自动执行的程序)
26、数据库并发策略
27、MySQL中有哪几种锁?
28、MySQL 中有哪些不同的表格?
29、简述在MySQL数据库中MyISAM和InnoDB的区别
30、MySQL中InnoDB支持的四种事务隔离级别名称,以及逐级之间的区别?
31、CHAR和 VARCHAR 的区别?
32、主键和候选键有什么区别?
33、myisamchk是用来做什么的?
34、MylSAM Static和MyISAM Dynamic 有什么区别?
35、如果一个表有一列定义为TIMESTAMP,将发生什么?
36、你怎么看到为表格定义的所有索引?
37、LIKE声明中的%和是什么意思?
38、列对比运算符是什么?
39、BLOB和TEXT有什么区别?
40、MySQLfetch_array和MySQLfetch_object 的区别是什么?

Redis面试题
1、什么是Redis?
2、Redis与其他 key-value 存储有什么不同?
3、Redis 的数据类型?
4、使用Redis 有哪些好处?
5、Redis 相比 Memcached 有哪些优势?
6、Memcache与Redis 的区别都有哪些?
7、Redis是单进程单线程的?
8、一个字符串类型的值能存储最大容量是多少?
9、Redis持久化机制
10、缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存降级等问题
11、热点数据和冷数据是什么
12、单线程的redis为什么这么快
13、redis的数据类型,以及每种数据类型的使用场景
14、redis的过期策略以及内存淘汰机制
15、Redis常见性能问题和解决方案?
16、为什么Redis的操作是原子性的,怎么保证原子性的?
17、Redis事务
18、Redis的持久化机制是什么?各自的优缺点?
19、Redis常见性能问题和解决方案:
20、redis过期键的删除策略?
21、Redis 的回收策略(淘汰策略)?
22、为什么edis需要把所有数据放到内存中?
23、Redis 的同步机制了解么?
24、Pipeline有什么好处,为什么要用 pipeline?
25、是否使用过Redis集群,集群的原理是什么?
26、Redis集群方案什么情况下会导致整个集群不可用?
27、Redis支持的Java客户端都有哪些?官方推荐用哪个?
28、Jedis与Redisson对比有什么优缺点?
29、Redis如何设置密码及验证密码?
30、说说Redis 哈希槽的概念?
31、Redis集群的主从复制模型是怎样的?
32、Redis集群会有写操作丢失吗?为什么?
33、Redis集群之间是如何复制的?
34、Redis集群最大节点个数是多少?
35、Redis集群如何选择数据库?
36、怎么测试 Redis 的连通性?
37、怎么理解Redis事务?
38、Redis事务相关的命令有哪几个?
39、Redis key的过期时间和永久有效分别怎么设置?
40、Redis如何做内存优化?

Spring面试题
1、不同版本的 Spring Framework 有哪些主要功能?
2、什么是Spring Framework?
3、列举 Spring Framework 的优点。
4、Spring Framework有哪些不同的功能?
5、Spring Framework 中有多少个模块,它们分别是什么?
6、什么是Spring 配置文件?
7、Spring应用程序有哪些不同组件?
8、使用Spring 有哪些方式?
9、什么是Spring lOC 容器?
10、什么是依赖注入?
11、可以通过多少种方式完成依赖注入?
12、区分构造函数注入和setter注入
13、spring 中有多少种IOC容器?
14、区分 BeanFactory和ApplicationContext。
15、列举 loC的一些好处。
16、Spring loC 的实现机制。
17、什么是spring bean?
18、spring提供了哪些配置方式?
19、spring 支持集中 bean scope?
20、spring bean容器的生命周期是什么样的?
21、什么是spring 的内部 bean?
22、什么是spring 装配
23、自动装配有哪些方式?
24、自动装配有什么局限?
25、什么是基于注解的容器配置
26、如何在spring中启动注解装配?
27、@Component,@Controller,@Repository
28、@Required注解有什么用?
29、@Autowired 注解有什么用?
30、@Qualifier注解有什么用?
31、@RequestMapping注解有什么用?
32、spring DAO有什么用?
33、列举Spring DAO抛出的异常。
34、spring JDBC API 中存在哪些类?
35、使用Spring 访问Hibernate 的方法有哪些?
36、列举spring支持的事务管理类型
37、spring 支持哪些 ORM框架
38、什么是AOP?
39、什么是Aspect?
40、什么是切点(oinPoint)

Spring Boot面试题
1、什么是Spring Boot?
2、为什么要用SpringBoot
3、Spring Boot 有哪些优点?
4、Spring Boot的核心注解是哪个?它主要由哪几个注解组成的?
5、运行Spring Boot有哪几种方式
6、如何理解Spring Boot 中的 Starters?
7、如何在Spring Boot启动的时候运行一些特定的代码?
8、Spring Boot需要独立的容器运行吗?
9、Spring Boot中的监视器是什么?
10、如何使用Spring Boot实现异常处理?
11、你如何理解Spring Boot 中的 Starters
12、springboot常用的starter有哪些
13、SpringBoot 实现热部署有哪几种方式
14、如何理解Spring Boot 配置加载顺序
15、Spring Boot的核心配置文件有哪几个?它们的区别是什么?
16、如何集成Spring Boot 和ActiveMQ
17、什么是JavaConfig?
18、如何重新加载SpringBoot上的更改,而无需重新启动服务器?
19、Spring Boot 中的监视器是什么?
20、如何在Spring Boot 中禁用Actuator 端点安全性?
21、如何在自定义端口上运行Spring Boot 应用程序?
22、什么是YAML?
23、如何实现Spring Boot 应用程序的安全性?
24、如何集成Spring Boot和ActiveMQ?
25、如何使用Spring Boot实现分页和排序?
26、什么是Swagger??你用 Spring Boot 实现了它吗?
27、什么是Spring Profiles?
28、什么是Spring Batch?
29、什么是FreeMarker模板?
30、如何使用Spring Boot实现异常处理?
31、您使用了哪些starter maven 依赖项?
32、什么是CSRF攻击?
33、什么是WebSockets?
34、什么是AOP?
35、什么是Apache Kafka?
36、我们如何监视所有Spring Boot微服务?
37、Spring Boot 的配置文件有哪几种格式?它们有什么区别?
38、开启Spring Boot特性有哪几种方式?
39、Spring Boot 的目录结构是怎样的?
40、运行Spring Boot有哪几种方式?

MyBatis 面试题
1、什么是Mybatis?
2、Mybaits 的优点
3、MyBatis 框架的缺点
4、MyBatis框架适用场合
5、MyBatis与Hibernate 有哪些不同?
6、#[和$)的区别是什么?
7、当实体类中的属性名和表中的字段名不一样,怎么办?
8、模糊查询like语句该怎么写?
9、通常一个Xml映射文件,都会写一个Dao接口与之对应,请问,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗?
13、如何获取自动生成的(主)键值?
14、在mapper 中如何传递多个参数?
15、Mybatis动态sql有什么用?执行原理?有哪些动态sql?
16、XmI映射文件中,除了常见的selectlinserlupdaeldelete标签之外,还有哪些标签?
17、Mybatis的XmI映射文件中,不同的XmI映射文件,id是否可以重复?
18、为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?
19、一对一、一对多的关联查询?
20、MyBatis实现一对一有几种方式?具体怎么操作的?
21、MyBatis实现一对多有几种方式怎么操作的?
22、Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
23、Mybatis 的一级、二级缓存
24、什么是MyBatis的接口绑定?有哪些实现方式?
25、使用MyBatis 的mapper接口调用时有哪些要求?
26、Mapper编写有哪几种方式?
27、简述Mybatis的插件运行原理,以及如何编写一个插件。
28、MyBatis实现一对一有几种方式?具体怎么操作的?

Kafka 面试题
1、Kafka是什么
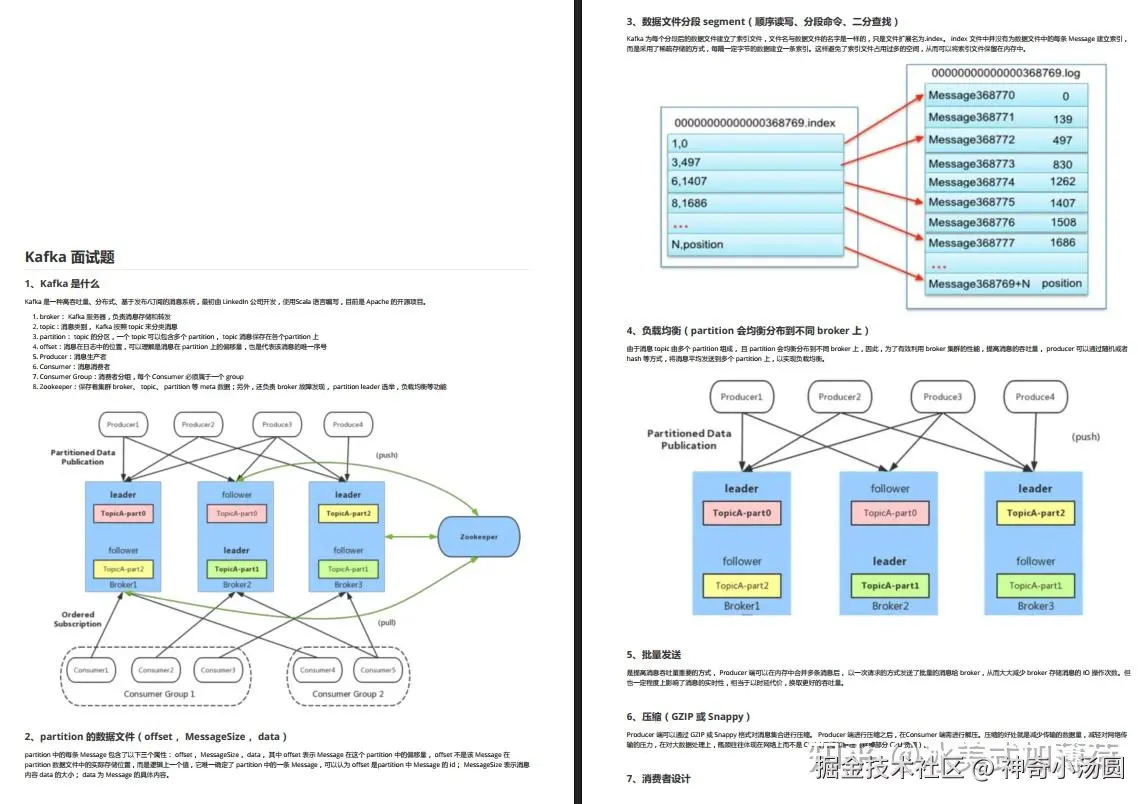
2、partition 的数据文件(offset,MessageSize,data)
3、数据文件分段segment(顺序读写、分段命令、二分查找)
4、负载均衡(partition会均衡分布到不同broker上)
5、批量发送
6、压缩(GZIP 或Snappy)
7、消费者设计
8、Consumer Group
9、如何获取topic主题的列表
10、生产者和消费者的命令行是什么?
11、consumer是推还是拉?
12、讲讲kafka维护消费状态跟踪的方法
13、讲一下主从同步
14、为什么需要消息系统,mysql不能满足需求吗?
15、Zookeeper对于Kafka 的作用是什么?
16、Kafka判断一个节点是否还活着有那两个条件?
17、Kafka与传统MQ消息系统之间有三个关键区别
18、讲一讲 kafka 的 ack 的三种机制
19、消费者如何不自动提交偏移量,由应用提交?
20、消费者故障,出现活锁问题如何解决?
21、如何控制消费的位置
22、kafka分布式(不是单机)的情况下,如何保证消息的顺序消费?
23、kafka的高可用机制是什么?
24、kafka如何减少数据丢失
25、kafka如何不消费重复数据?比如扣款,我们不能重复的扣。
Linux面试题
1、绝对路径用什么符号表示?当前目录、上层目录用什么表示?主目录用什么表示?切换目录用什么命令?
2、怎么查看当前进程?怎么执行退出?怎么查看当前路径?
3、怎么清屏?怎么退出当前命令?怎么执行睡眠?怎么查看当
4、Ls命令执行什么功能?可以带哪些参数,有什么区别?
5、查看文件有哪些命令
6、列举几个常用的Linux命令
7、你平时是怎么查看日志的?
9、目录创建用什么命令?创建文件用什么命令?复制文件用什么命令?
10、查看文件内容有哪些命令可以使用?
11、随意写文件命令?怎么向屏幕输出带空格的字符串,比如"helloworld"?
12、终端是哪个文件夹下的哪个文件?黑洞文件是哪个文件夹下的哪个命令?
13、移动文件用哪个命令?改名用哪个命令?
14、复制文件用哪个命令?如果需要连同文件夹一块复制呢?如果需要有提示功能呢?
15、删除文件用哪个命令?如果需要连目录及目录下文件一块删除呢?删除空文件夹用什么命令?
16、Linux下命令有哪几种可使用的通配符?分别代表什么含义?
17、用什么命令对一个文件的内容进行统计?(行号、单词数、字节数)
18、Grep命令有什么用?如何忽略大小写?如何查找不含该串的行?
19、Linux中进程有哪几种状态?在ps显示出来的信息中分别用什么符号表示的?
20、怎么使一个命令在后台运行?
21、利用ps怎么显示所有的进程?怎么利用ps查看指定进程的信息?
22、哪个命令专门用来查看后台任务?
23、把后台任务调到前台执行使用什么命令?把停下的后台任务在后台执行起来用什么命令?
24、终止进程用什么命令?带什么参数?
25、怎么查看系统支持的所有信号?
26、搜索文件用什么命令?格式是怎么样的?
27、查看当前谁在使用该主机用什么命令?查找自己所在的终端信息用什么命令?
28、使用什么命令查看用过的命令列表?
29、使用什么命令查看磁盘使用空间?空闲空间呢?
30、使用什么命令查看网络是否连通?
31、使用什么命令查看ip地址及接口信息?
32、查看各类环境变量用什么命令?
3、通过什么命令指定命令提示符?
34、查找命令的可执行文件是去哪查找的?怎么对其进行设置及添加?
35、通过什么命令查找执行命令?
36、怎么对命令进行取别名?
37、du和df 的定义,以及区别?
38、awk详解。
39、当你需要给命令绑定一个宏或者按键的时候,应该怎么做呢?
40、如果一个linux新手想要知道当前系统支持的所有命令的列表,他需要怎么做?
别自己先把自己劝退了。JD上写"精通Spring AI""两年AI落地经验",那是理想画像------面试官自己心里清楚,市面上没几个人能满足。面试的本质不是你"全懂",而是你"入了门、有手感、聊得出细节",那就够了。
技术可以补,经历可以攒,但敢先上车再修引擎的魄力,不是人人都有。