前端转agent-【python】-15 Agent 评估与观测:像监控前端应用一样监控 AI
前端上线后你会接 Sentry、埋点、看性能面板。Agent 也一样------调用链有没有报错?Token 烧了多少?回答质量如何?
今天用 LangFuse(开源可观测平台)给 Ollama + LangChain 的 Agent 装上"黑匣子",再用 LLM 当裁判自动评估回答质量。
为什么需要评估与观测?
| 观测维度 | 解决什么问题 | 前端类比 |
|---|---|---|
| 链路追踪 (Tracing) | 一次问答经历了哪些步骤?哪步慢了? | Sentry Performance 的 Span 瀑布图 |
| 指标 (Metrics) | Token 消耗、成功率、平均延迟 | Google Analytics / 自定义埋点 |
| 日志 (Logging) | 提示词原文、LLM 返回的原始 JSON | 浏览器 Console 或 ELK 日志 |
| 质量评估 (Eval) | 回答是否正确?有没有幻觉? | 自动化 E2E 测试,断言 UI 状态 |
LangFuse 相当于 AI 版的 Sentry + PostHog,而且对个人开发者完全免费(可自部署)。
环境准备
bash
pip install langfuse langchain langchain-ollama注册 LangFuse Cloud(免费额度足够学习):cloud.langfuse.com
获取 Public Key 和 Secret Key,设为环境变量:
bash
export LANGFUSE_PUBLIC_KEY="pk-..."
export LANGFUSE_SECRET_KEY="sk-..."
export LANGFUSE_HOST="https://cloud.langfuse.com" # 如果用 cloud 版也可以把这段代码放到同级目录下.env文件里,我此处采用的就是这个方式。
模型:
bash
ollama pull qwen3:4b第一步:自动追踪 LLM 调用
LangFuse 有 LangChain 的 callback 集成,只需传入 LangfuseCallbackHandler,所有 LLM 调用、链执行都会被自动记录。
python
# trace_demo.py
import os
from dotenv import load_dotenv
load_dotenv() # 加载 .env 环境变量
from langchain_ollama import ChatOllama
from langfuse.langchain import CallbackHandler
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 初始化 LangFuse callback(自动读取环境变量)
# v4 版本通过 trace_context 传递 trace 级别的信息
langfuse_handler = CallbackHandler(
trace_context={
"session_id": "user-123", # 类似前端埋点里的 session
"user_id": "learner", # 用户标识
"tags": ["demo", "ollama"] # 自定义标签,方便过滤
}
)
llm = ChatOllama(model="qwen3:4b", temperature=0)
prompt = ChatPromptTemplate.from_template("用一句话回答:{question}")
chain = prompt | llm | StrOutputParser()
# 调用时传入 config,callback 会自动记录
result = chain.invoke(
{"question": "什么是向量数据库?"},
config={"callbacks": [langfuse_handler]}
)
print(result)发生了什么?
- 每一次
chain.invoke都生成一个 Trace,包含 Span(LLM 调用细节)。 - 自动捕获提示词、模型名称、输出、耗时、token 使用量(若 Ollama 返回)。
- 前端类比:就像 Sentry 的
Sentry.captureException自动捕获错误上下文。
Langfuse上的截图
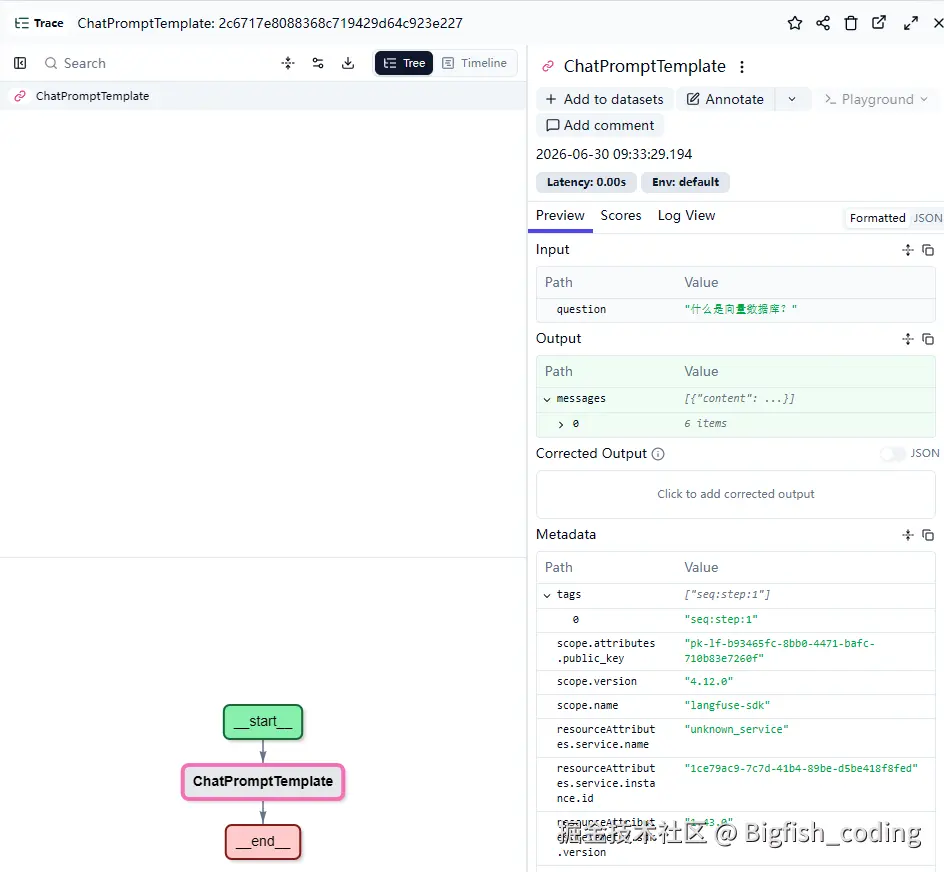
第二步:手动添加自定义事件
有时你想记录非 LLM 的操作,比如检索耗时、工具调用结果。LangFuse 支持手动创建 Span。
python
# custom_span.py
import os
import time
from dotenv import load_dotenv
load_dotenv() # 加载 .env 环境变量
from langfuse import Langfuse
langfuse = Langfuse()
# Langfuse v4 使用 start_as_current_observation 创建 trace
with langfuse.start_as_current_observation(
name="rag-query",
input={"query": "退货政策"},
metadata={"session_id": "user-123"}
) as trace:
# 在关键步骤埋点
with langfuse.start_as_current_observation(
name="vector-search",
input={"query": "退货政策"},
metadata={"index": "products"}
) as retrieval_span:
# 模拟检索
time.sleep(0.5)
retrieval_span.update(
output={"documents": ["7天无理由退货"]},
metadata={"latency_ms": 500}
)
# LLM 调用
with langfuse.start_as_current_observation(name="llm-generation") as gen_span:
# ... 调用 LLM ...
gen_span.update(output="您可以7天内无理由退货。")
trace.update(output="您可以7天内无理由退货。")
langfuse.flush()
print("✅ Trace 已发送到 Langfuse")
前端类比 :手动打点就像 console.time('search') + console.timeEnd('search'),但数据会持久化并聚合。
第三步:质量评估 ------ LLM 当裁判
评估回答质量,可以用规则(关键词匹配)或更高级的 LLM-as-judge(用另一个 LLM 打分)。
python
# evaluate.py
import os
from dotenv import load_dotenv
load_dotenv() # 加载 .env 环境变量
from langchain_ollama import ChatOllama
from langchain_core.prompts import ChatPromptTemplate
from langfuse import Langfuse
eval_llm = ChatOllama(model="qwen3:4b", temperature=0)
langfuse = Langfuse()
def evaluate_answer(question: str, answer: str, ground_truth: str = None) -> dict:
"""用 LLM 给回答打分,返回评分和理由"""
prompt = ChatPromptTemplate.from_template("""
你是一个评估专家。根据以下标准给回答打分(1-5分):
- 准确性:是否回答正确
- 完整性:是否覆盖了关键信息
- 简洁性:是否简明扼要
参考标准答案:{ground_truth}
用户问题:{question}
回答:{answer}
请输出JSON格式:{{"score": 数字, "reason": "评分理由"}}
""")
chain = prompt | eval_llm
result = chain.invoke({
"question": question,
"answer": answer,
"ground_truth": ground_truth or "无标准答案"
})
# 尝试解析 JSON(实际应用需加异常处理)
import json
try:
return json.loads(result.content)
except:
return {"score": 0, "reason": "解析失败"}
# 示例:评估一个回答
score_data = evaluate_answer(
question="退货政策是什么?",
answer="7天内无理由退货。",
ground_truth="7天内无理由退货,30天内质量问题换货。"
)
print(f"评分: {score_data['score']}, 理由: {score_data['reason']}")
# 可将评估结果回传到 LangFuse 的 trace 中
with langfuse.start_as_current_observation(name="eval-example") as trace:
trace.score(
name="accuracy",
value=score_data["score"],
comment=score_data["reason"]
)
langfuse.flush()
# 结果:评分: 2, 理由: 回答部分正确(7天内无理由退货是退货政策的正确组成部分),但缺少关键信息'30天内质量问题换货',导致完整性严重不足;简洁性良好(表述简明扼要),但整体上未覆盖参考标准答案的全部关键内容,故综合评分为2分。这样,每次回答都会被自动打分,你可以在 LangFuse Dashboard 查看评分分布,发现质量下滑时及时调整提示词。
Vue 3 横向对比
| LangFuse 功能 | Vue 3 对应实践 |
|---|---|
| Trace / Span 自动记录 | 用 vue-router 的 beforeEach 埋点页面访问 |
session_id / user_id |
GA 的 gtag('set', { user_id }) 或 Sentry 的 setUser |
| 手动 span 打点 | 在组件生命周期中用 performance.mark 测量 |
| LLM-as-judge 评估 | E2E 测试中的断言,如 expect(page).toContainText('7天') |
| Dashboard 聚合分析 | 前端性能监控的 Lighthouse / Sentry 面板 |
本质都是 记录 → 聚合 → 发现异常 → 优化,只是 Agent 观测还多了个"质量评估"。
总结
- LangFuse 让 AI Agent 有了可观测性,每一轮对话都变成可回放、可分析的 Trace。
- 自动追踪 LLM 调用(零侵入),手动打点能覆盖检索、工具等环节。
- 用 LLM-as-judge 做自动化质量评估,替代人工检查,形成反馈闭环。
- 对前端开发者来说,这就是 Agent 版的 Sentry,学会就多了一项"AI 工程质量保障"的技能。
你的 Agent 不再是个黑盒子,快去注册 LangFuse,给 Ollama 装上行车记录仪吧 🚗📊。
bash
python trace_demo.py
# 然后打开 https://cloud.langfuse.com 查看追踪记录