你的 Agent 能跑通,不代表它能承受一次真实的用户投诉。
开篇:从"跑通了"到"敢上线"
MVP 阶段的感觉,就像第一次把火箭点着火。写几个 @Tool,组一个 @AiServices,服务一启动,curl 一发,看着 JSON 数据从终端里流畅地滚出来------那一刻,你真的会觉得 Agent 开发不过如此,甚至已经开始盘算上线后的 KPI 了。
但冷静一下,咱们做个思想实验。
如果模型在这一步重复调用了「创建工单」工具两次,你的系统是会聪明地识别去重,还是闷头创建两张重复工单等着客服去哭?
如果模型在某个环节突然"走神",推理了 100 秒还没返回,前端一直转圈。用户烦躁地刷新了页面------刚才那笔半截子的操作,到底算不算数?
如果第二天客户总监拍着桌子质问:"Agent 给的诊断结论全是错的!"你面对着几万行日志,能在 5 分钟内定位出是昨天更新的 Prompt 有歧义、RAG 召回了过期的脏文档、还是那个第三方 API 偷偷改了返回字段吗?
这些问题,MVP 时期的代码一个都回答不了。
因为它能回答的只有一个问题------"能不能跑通"。而生产环境要回答的是------"能不能扛住"。
这篇文章不是代码实战,是生产级 Agent 改造前的总纲。我只讲清楚三件决定架构方向的大事:什么是真正的生产级、它必须长出哪 6 块核心肌肉、以及从 MVP 演进到生产级最稳妥的路径是什么。
所以,这个专栏开始我们不写"玩具",我们写"兵器"。 接下来的系列文章,我会带你直面那些 MVP 文档里永远不会写的坑------ 从线程池隔离、重试风暴防护,到可解释的推理追踪、模型热切换,再到灰度发布与效果评估。 我们要把那个"能跑"的 Agent,改造成"抗造、可控、可信"的生产级心脏。
如果你也曾被 Demo 骗过,觉得上线就在眼前------ 这个专栏,就是为你写的。
一、Demo vs 生产:不是量的差距,是骨架的不同
先看一张对照表,每一行都是一个「线上事发了我该怎么办」的灵魂拷问:
| 维度 | MVP(能跑通) | 生产级(敢上线) |
|---|---|---|
| 流程控制 | if-else 串逻辑,异常了就抛 | 显式状态机,每步可暂停/恢复/审计 |
| 工具调用 | LLM 说调就调,裸调 Java 方法 | 幂等防腐 + 副作用分类 + 硬预算熔断 |
| 上下文管理 | 最近 N 轮全塞进 Prompt | 四层记忆:工作区/会话/摘要/画像 |
| Prompt | 一个硬编码字符串 | 六层编译:角色→策略→工具→记忆→知识→任务 |
| RAG 检索 | 向量 Top-K,返回啥喂啥 | 混合召回 + 租户隔离 + 时效过滤 |
| 并发 | 同步等 LLM,一个请求一个线程 | 读写分离并发 + SSE 流式 + 异步 SideCar |
| 排障 | log.info 散落各处 | Trace ID 贯穿全链路 + JSON 结构化日志 |
| 合规 | 无 | 每次 LLM 调用/工具调用全程留痕,可回放 |
MVP 和生产级的差距不是「代码量多了 3 倍」,而是 骨架不同。MVP 的骨架是一根脊柱(请求进来 → LLM 推理 → 返回),生产级的骨架是一个有中枢神经系统的躯体------每一块肌肉(工具)都受中枢(Runtime 状态机)控制,每一次动作(LLM 调用、工具执行)都有感觉神经(可观测性)反馈。
二、生产级 Agent 的 6 大核心能力
能力 1:可控性 --- 状态机驱动的 Runtime
MVP 的问题不在于功能不够,而在于不可控 。Agent 在做第几步、正在等 LLM 还是等工具、能不能暂停等审批、失败了能不能从断点恢复------这些问题,一个 if-else 串起来的 chat() 方法回答不了。
生产级的解决方案是引入一个显式的状态机,把 Agent 的一次推理拆成离散的状态节点:
markdown
RECEIVED → SESSION_READY → CONTEXT_READY → MODEL_THINKING
→ TOOL_RUNNING → (MODEL_THINKING ⇄ TOOL_RUNNING 循环)
→ POST_PROCESSING → COMPLETED/FAILED每一个状态下:
- 你知道下一步该做什么
- 你可以暂停 (等待人工审批)然后恢复(断点续传)
- 你可以观测(每个状态变更都产生事件)
- 你可以熔断(状态超时自动转入 FAILED)
这不是一个复杂的分布式状态机引擎。在单次请求的生命周期内,它是一个内存中的确定性调度器------轻量、可测试、零外部依赖。
能力 2:安全性 --- 工具调用的三层防护
这是生产事故的最高发区。LLM 不会有意作恶,但它会重复调用 (同样的 tool_call 出现在两次推理中)、过度调用 (在一个循环里不停调工具)、错误调用(把读工具当写工具用)。
三层防护:
第一层:强制幂等。 每次工具调用生成唯一的 execution_id = SHA256(session_id + tool_name + params_hash)。对于写操作(退款、发券、创建工单),在 DB 中记录该 ID 的执行状态。如果 LLM 重复调用,直接返回「已执行」的缓存结果,绝不二次操作。
第二层:副作用分类。 工具不是平等的:
READ类(查库存、查价格、查日志):可重试、可并发、不加锁WRITE类(扣库存、退款、创建工单):必须加分布式锁、必须写审计日志、必须支持 Saga 补偿(失败了能回滚)
第三层:硬预算熔断。 不给模型无限的自由度。在 RuntimeContext 中明确约束:
max_llm_calls = 5(单轮最多推理 5 次)max_read_tools = 3(读工具最多 3 次)max_write_tools = 1(写工具最多 1 次)total_latency_ms = 10000(10 秒总超时,到了就掐断)
模型是不确定的,但系统行为必须是确定的。三层防护就是把模型的不确定性关进笼子里。
能力 3:可观测 --- 全链路追踪,出问题 5 分钟定位
MVP 时代的日志长这样:
csharp
[Agent] User message: CNC-001 振动异常
[DiagnosisTool] Generating diagnosis...
[Agent] Reply: ...诊断结论较长...出了问题能知道什么?什么都不知道。你不知道 LLM 被调用了多少次、每次传了什么 Prompt、哪个工具返回了什么、是哪个环节产生了错误的上下文。
生产级在每个节点埋点,输出 JSON 结构化日志:
json
{"ts":"...","trace_id":"abc123","state":"MODEL_THINKING","event":"llm_call",
"prompt_hash":"d4e2f...","input_tokens":1234,"output_tokens":567,"latency_ms":890}
{"ts":"...","trace_id":"abc123","state":"TOOL_RUNNING","event":"tool_call",
"tool_name":"createWorkOrder","execution_id":"e7b...","params":"...","status":"ok","duration_ms":42}trace_id 贯穿网关 → Runtime → LLM → 数据库,接入 OpenTelemetry 后可以直接在 Grafana Tempo 里可视化回放整个推理链路。
「哦,是第 2 次工具调用超时了 5 秒,LLM 等不及了就自己编了数据。」------没有全链路追踪,这段推理你需要猜 2 小时。
能力 4:可演进 --- Prompt 分层编译,不发版改行为
MVP 的 System Prompt 是一个硬编码的 Java 字符串:
java
@SystemMessage("""
你是一个工业设备运维专家...可用工具...思考路径...回复规范...
""")问题:想改一条规则(比如「写工具最多调 1 次」),你得改代码、走 CI、重新部署。而且这条规则被埋在几百字的 Prompt 里,LLM 可能根本没注意到。
生产级把 Prompt 拆成 6 层,每一层独立管理:
| 层级 | 内容 | 管理方式 |
|---|---|---|
| L1 Role | 角色定义 | 配置文件 |
| L2 Policy | 安全红线、预算约束 | 动态加载,热更新 |
| L3 Tool Contract | 可用工具列表 + JSON Schema | 从 ToolRegistry 自动生成 |
| L4 Memory | 用户画像、会话摘要 | 从 MemoryManager 拉取 |
| L5 Knowledge | RAG 检索结果 | 检索后动态注入 |
| L6 Task | 当前用户问题 + 输出格式 | 本次请求传入 |
关键思路:把约束写在 Policy 层而不是让 LLM 自己猜。「禁止同一写工具调用超过 1 次」不是一句 Prompt 建议,而是编译后的硬约束文本,LLM 在推理前就看到了明确的边界。
能力 5:高性能 --- 读写分离并发 + 异步剥离
MVP 的瓶颈在「等」------等 LLM 返回、等工具返回、等日志写入、等摘要生成。所有事情都在主线程排队。
生产级做三件事:
读写分离并发。 当 Agent 需要查 3 个读工具(库存、价格、物流),3 个调用并行发出(CompletableFuture.allOf);当涉及写工具(扣库存 + 创建订单),强制串行且加事务------因为后者的执行顺序就是业务语义。
SSE 早返回。 流式输出不是「等 LLM 生成完再一起发给前端」,而是 LLM 吐出第一个 Token 就立即通过 SSE 推送。用户的「首字延迟」从 3 秒降到 300ms,体验差距巨大。
异步 SideCar。 主链路只做「LLM 推理 + 工具关键执行」。日志落库、审计归档、记忆摘要生成、用户画像更新------全部扔进异步消息队列,绝不让用户等待这些事情。
能力 6:可审计 --- 全程留痕,可回放
金融、医疗、工业控制领域对 Agent 的基本要求是:任何一个决策,必须能追溯到完整的推理链条。
这意味着:
- 每次 LLM 调用记录:Prompt 原文(hash 索引)、返回结果、token 消耗
- 每次工具调用记录:入参、返回值(摘要)、耗时、状态
- 状态机每一次变迁记录:时间戳、触发事件、上下文快照
配合全链路 Trace ID,任何一个用户投诉都可以按时间线回放整个推理过程------这不仅是排障工具,也是合规审计的基础。
三、生产级 Agent 的五层架构
把这 6 个能力落实到代码,形成五层架构:
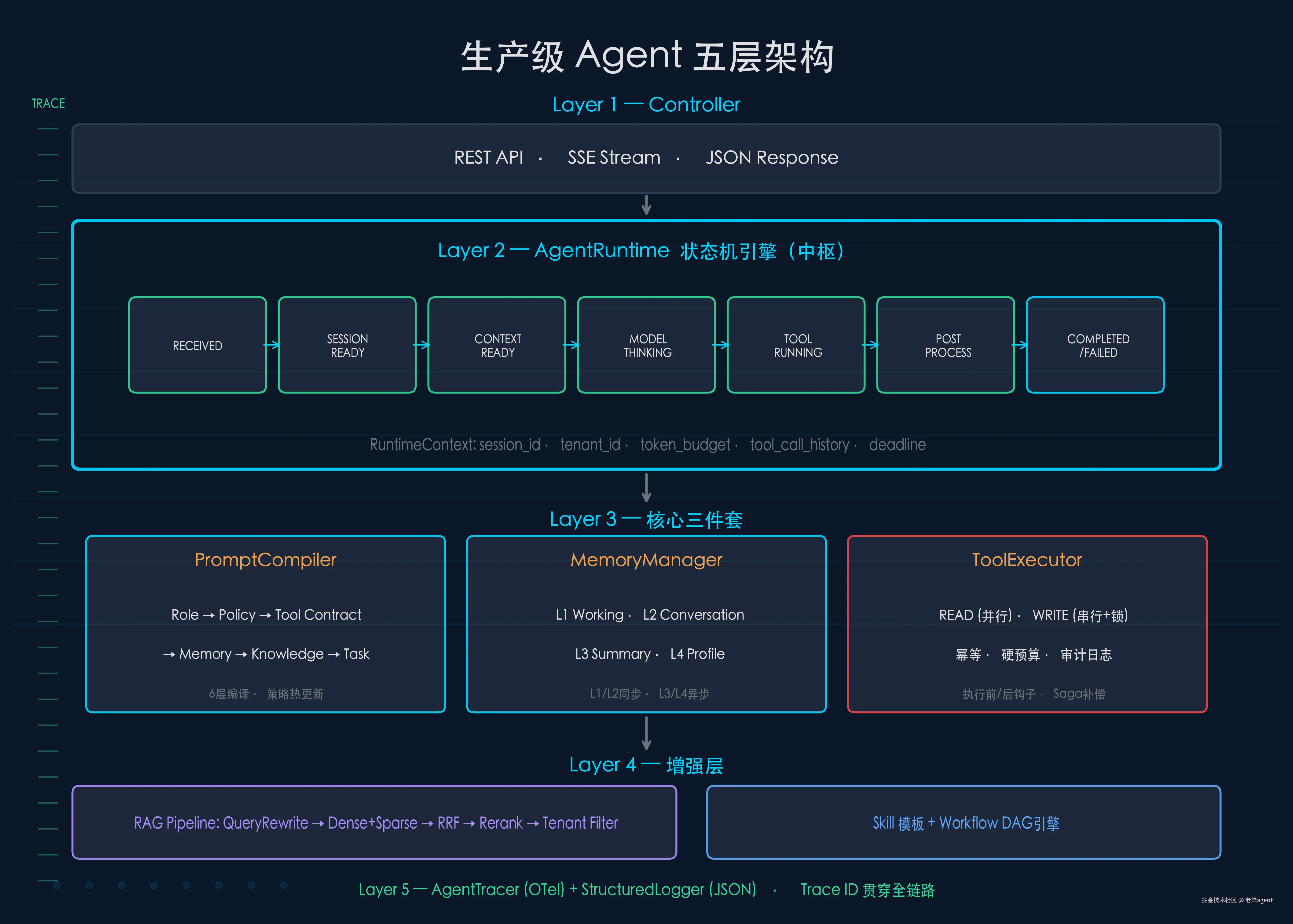
每一层的职责边界清晰:
- Runtime 是大脑中枢,驱动状态流转
- Prompt Compiler 负责「告诉模型什么」,Policy 动态注入
- Memory Manager 负责「记住什么」,四层分级存储
- Tool Executor 负责「安全执行什么」,幂等 + 预算 + 审计
- RAG + Workflow 是增强层,混合检索 + 确定性流程
- AgentTracer 是神经系统,贯穿所有层次
四、从 MVP 到生产级的演进路径
有了能力定义和架构蓝图,就可以拆成具体的改造任务。按风险等级分三期,每次改造可独立验证、独立合入:
P0(致命,必须第一批改)
| 改造项 | 为什么致命 |
|---|---|
| Tool 层:幂等 + 副作用分类 + 硬预算 | 工具裸调,模型重复调用直接造成数据事故 |
| Runtime 层:状态机 + 统一上下文 | 没有骨架,其他改造无处挂载 |
| 可观测性:OTel 全链路追踪 | 没有这个,P0 改造上线后出问题只能靠猜 |
P1(核心质量,第二批改)
| 改造项 | 为什么重要 |
|---|---|
| Memory 层:四层存储模型 | 告别无限滑窗,支持长期记忆 |
| Prompt 层:六层编译引擎 | 策略热更新,不发版改行为 |
| 调度并发:读写分离 + 异步 SideCar | 解决单点阻塞,提升并发吞吐 |
P2(增强完善,第三批改)
| 改造项 | 为什么排最后 |
|---|---|
| RAG:混合检索 + 租户隔离 + 时效过滤 | 已有独立组件,主要是整合 |
| Skill/Workflow:划清自由与约束 | 在已有 Runtime 基础上做高层抽象 |
五、一个真实的例子:同样一句话,MVP vs 生产级
假设用户说:「CNC-001 刚报了振动异常告警,帮我诊断一下,如果需要维修就创建工单。」
MVP 的执行路径:
scss
Controller.chat() → DeviceAgent.chat() → LLM 推理 → 调用 alarms + data + diagnosis
→ LLM 决定 createWorkOrder → WorkOrderTool 直接 INSERT → 返回- 如果 LLM 在这轮推理中调用了两次
createWorkOrder(ReAct 循环中重复决策),你会得到两张重复工单 - 如果第 3 次 LLM 推理超时了,用户看到的是一个 500 错误,但工单已经悄悄创建了(没有回滚)
- 如果第二天用户投诉「为什么给我创建了两张工单」,你查不到是哪次推理创建的
生产级的执行路径:
ini
Controller → AgentRuntime.execute()
│
├─ [RECEIVED] 生成 trace_id, 初始化 RuntimeContext
├─ [SESSION_READY] MemoryManager 加载 L1-L4
├─ [CONTEXT_READY] PromptCompiler 编译 6 层 Prompt(Policy: "写工具最多1次")
├─ [MODEL_THINKING] LLM 推理 → 返回 tool_calls: [alarms, data, diagnosis]
├─ [TOOL_RUNNING] ToolExecutor 并行执行 3 个 READ 工具(各生成 execution_id)
├─ [MODEL_THINKING] LLM 收到结果 → 确认是硬件故障 → tool_call: createWorkOrder
├─ [TOOL_RUNNING] ToolExecutor 执行 WRITE 工具
│ ├─ 检查预算(write_calls: 1/1,OK)
│ ├─ 生成 execution_id
│ ├─ 获取分布式锁
│ ├─ 幂等检查(该 execution_id 未执行过)
│ ├─ 执行 createWorkOrder + 写审计日志
│ └─ 释放锁
├─ [MODEL_THINKING] LLM 生成最终诊断报告
├─ [POST_PROCESSING] 触发 AsyncSideCar(摘要生成 + 画像更新 + 日志归档)
└─ [COMPLETED] 返回结果 + SSE 推送如果 LLM 在下一轮又发起了一次 createWorkOrder(相同参数),ToolExecutor 发现 execution_id 已存在 → 直接返回「已执行」结果,绝不开第二次 INSERT。
如果诊断过程中 total_latency_ms 超时,RuntimeContext 超时检测触发 → 状态转入 FAILED → 已执行的写操作进入 Saga 补偿(将工单标记为 ABORTED 而非留在 PENDING)。
如果用户投诉,你通过 trace_id 在 Grafana 里回放:6 次状态变迁、4 次 LLM 调用(各含 prompt_hash)、4 次工具调用(各含入参/出参/耗时)。
六、核心理念:在模型不确定性下构建确定性工程
这句话是我整个改造计划的核心思想:
不要追求「模型一次性把所有事做对」,而要通过「Runtime 状态机 + 预算管控 + 幂等防腐」来兜底。
模型会产生幻觉,会超时,会重复调用工具,会在开放上下文中偏离指令------这些都是 LLM 的本性,你无法消除它们。
但你可以构建一个 确定性的工程框架,把这些不确定性关在笼子里:
- 模型超时了?BudgetManager 掐断它。
- 模型重复调工具了?execution_id 防重。
- 模型编造数据了?OutputGuard 拦截 + 审计日志回溯。
- 模型推理出错了?你可以回放整条链路找到污染源。
这就是从一个 Demo 到一个敢上线的系统之间的距离。
下一步
这篇文章定义了「生产级 Agent 长什么样」。下一篇文章我会拿这个标准去体检 industrial-agent-long 的当前代码------对照 5 个病灶逐一举证,然后给出完整的三期改造路线图。
项目地址:github.com/LaoLiang-ag...
下一篇预告:「industrial-agent-long 生产级体检报告:MVP 的 5 个致命伤与改造路线图」
本文由 LaoLiang 原创,首发于掘金/知乎/微信公众号。转载请联系作者。