先说 NLP 技术演进的四个阶段
- 规则系统阶段(1950s - 1980s):手写一切的"语言学家时代"
- 统计方法阶段(1980s - 1990s):概率教会机器"语感"
- 机器学习阶段(2000s - 2010s初):特征工程的"手艺活"
- 深度学习阶段(2010s中期至今):端到端与认知涌现
前三个阶段,咱先不讲,直接说深度学习阶段。
深度学习彻底颠覆了前三个阶段的范式,核心理念是:用深度神经网络,直接从原始文本中端到端地学习一切,从词法、句法到语义、知识。
-
词向量时代(2013,Word2Vec、GloVe): 首次让"词"有了真正的几何空间。语义关系变成了向量运算:国王 - 男人 + 女人 ≈ 女王。这为神经网络输入铺平了道路。
-
序列建模王朝(2014-2017,RNN/LSTM/GRU): 循环神经网络及其门控变体,解决了变长序列的建模问题,能处理长距离依赖。Seq2Seq+Attention(2014) 架构成为机器翻译、对话生成的标配,注意力机制让模型动态聚焦重点,意义非凡。
-
Transformer革命(2017,"Attention Is All You Need"): 抛弃了循环和卷积,完全基于自注意力机制,实现了并行计算和超长距离建模。它彻底统一了NLP的模型架构。
-
预训练大语言模型时代(2018至今): 这是一场真正的范式统一。
BERT(2018): 开启"预训练+微调"范式,通过掩码语言模型等任务,在海量无标注文本上学习通用语言知识,在11项NLP任务上刷新记录。
GPT系列: 从GPT-1到GPT-4,证明了通过"语言模型即一切任务"的自回归生成范式,当模型规模和数据量跨越阈值后,会涌现出上下文学习、思维链推理等惊人的复杂能力。
1. 循环神经网络 RNN(Recurrent Neural Network)
RNN(循环神经网络)的核心结构是一个具有循环连接的隐藏层,它以时间步(time step)为单位,依次处理输入序列中的每个 token。
在每个时间步,RNN 接收当前 token 的向量和上一个时间步的隐藏状态(即隐藏层的输出),计算并生成新的隐藏状态,并将其传递到下一时间步。
RNN 结构图
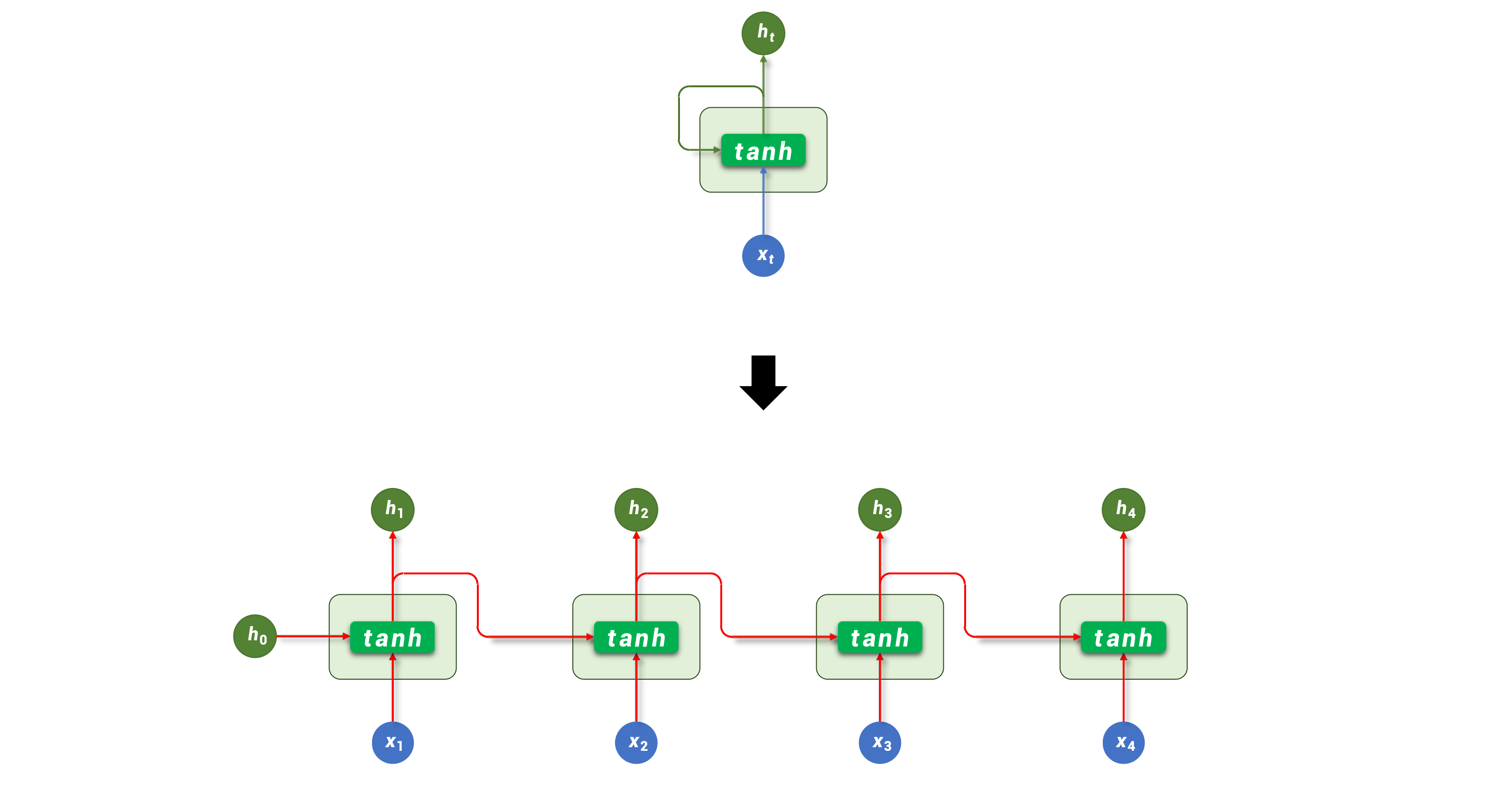
ht=tanh(xtWx+ht−1Wh+b) h_t = \tanh(x_t W_x + h_{t-1} W_h + b) ht=tanh(xtWx+ht−1Wh+b)
优势:
缺点:
1. 长期依赖建模困难(梯度消失导致早期输入对应的参数无法更新,进而让模型无法学到早期特征
)
这种时序依赖在反向传播(BPTT)时暴露了致命的数学缺陷。当序列极长时,早期路径的梯度展开会产生多次 tanh′(ut)⋅Wh\tanh'(u_t) \cdot W_htanh′(ut)⋅Wh 的连乘 。因为 tanh′\tanh'tanh′ 的值在 (0, 1] 之间,若参数 WhW_hWh 也小于 1,经过多次连乘后梯度会呈指数级衰减,引发"梯度消失",导致早期输入的权重无法得到有效更新 。反之若连乘结果大于 1,则会产生"梯度爆炸",令参数更新极不稳定 。
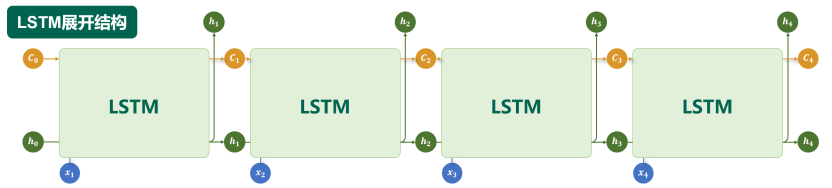
2. 长短期记忆网络 LSTM(Long Short-Term Memory)
LSTM 通过引入特殊的记忆单元(Memory Cell,图中的 CtC_tCt),有效提升了模型对长序列依赖关系的建模能力。
LSTM 架构图
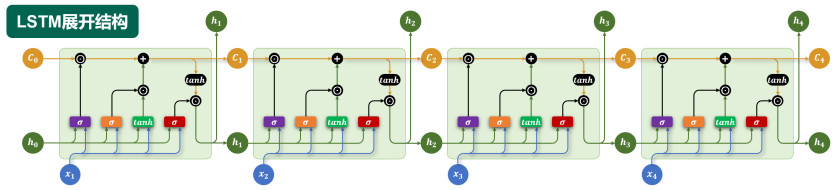
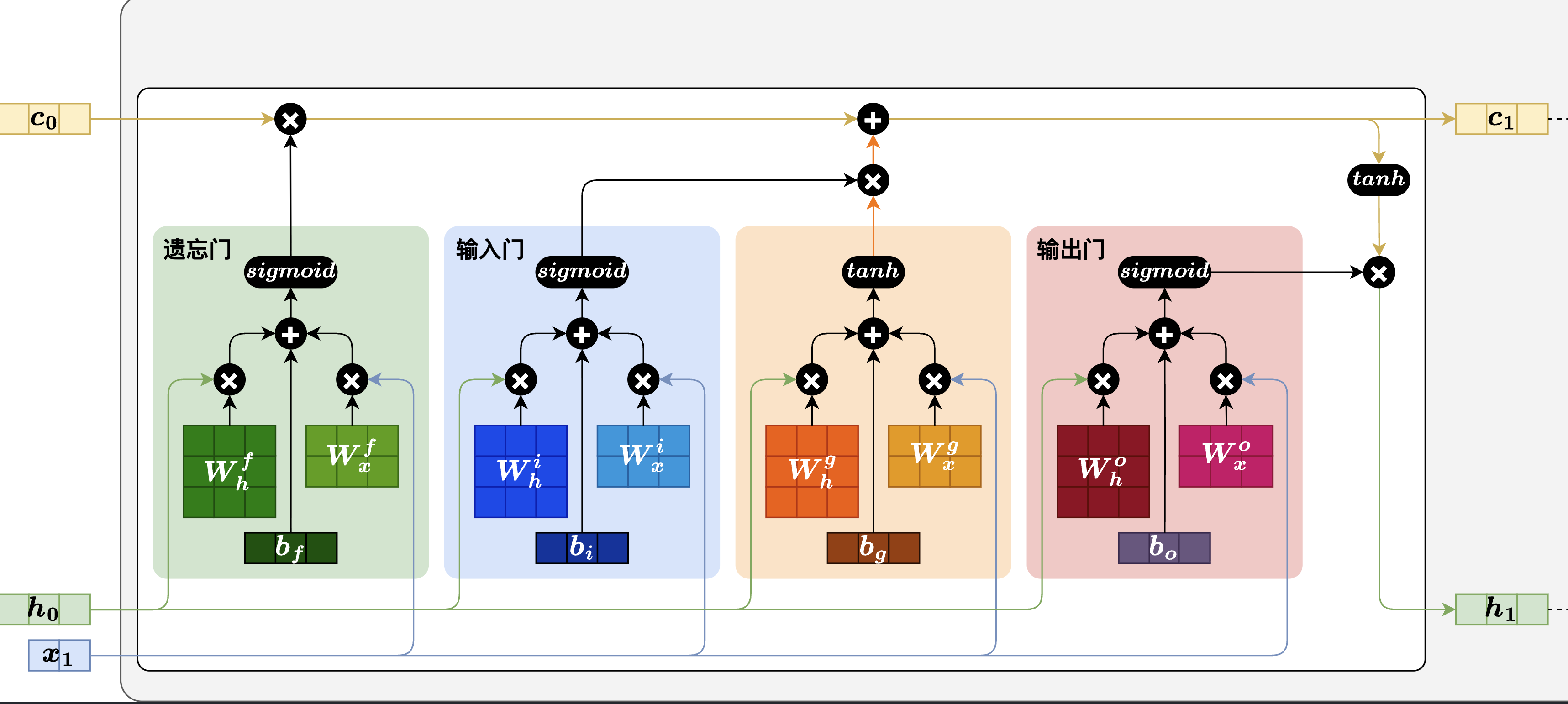
引入了门控机制
- 遗忘门
- 输入门
- 输出门
拆解 LSTM 的数学公式
LSTM 的核心是那条贯穿全局的"记忆单元(Memory Cell)"状态 CtC_tCt。为了保护这条主干道,它设计了三个用 Sigmoid 函数(σ\sigmaσ) 控制的门。σ\sigmaσ 函数的值域在 (0, 1) 之间,天然适合用来做"开关"或"比例尺"。
1. 遗忘门(Forget Gate):决定"丢弃"多少旧记忆
ft=σ(Wf⋅ht−1,xt+bf)f_t = \sigma(W_f \cdot h_{t-1}, x_t + b_f)ft=σ(Wf⋅ht−1,xt+bf)
- 物理意义 :它综合了上一时刻的隐藏状态 ht−1h_{t-1}ht−1 和当前的输入 xtx_txt,算出一个 0 到 1 之间的数值 ftf_tft。
- 你的洞察 :正如你所说,在训练良好的模型中,如果遇到长依赖,ftf_tft 的值会被学得非常接近 1(比如 0.99)。这意味着"旧记忆几乎原封不动地保留"。
2. 输入门(Input Gate):决定"写入"多少新记忆
这里分两步:
- 先用 tanh\tanhtanh 算出一个"候选的新记忆":C~t=tanh(Wc⋅ht−1,xt+bc)\tilde{C}_t = \tanh(W_c \cdot h_{t-1}, x_t + b_c)C~t=tanh(Wc⋅ht−1,xt+bc)
- 再用输入门算出一个 0 到 1 的比例:it=σ(Wi⋅ht−1,xt+bi)i_t = \sigma(W_i \cdot h_{t-1}, x_t + b_i)it=σ(Wi⋅ht−1,xt+bi)
- 物理意义 :两者相乘(it∗C~ti_t * \tilde{C}_tit∗C~t),就是当前这个词最终决定要往主干道上写入的新信息。
3. 核心更新(记忆单元的进化):加法代替了单纯的乘法
这是 LSTM 能救命的最关键公式:
Ct=ft∗Ct−1+it∗C~tC_t = f_t * C_{t-1} + i_t * \tilde{C}_tCt=ft∗Ct−1+it∗C~t
- 为什么梯度消失被缓解了? 在传统 RNN 中,状态传导全是 tanh\tanhtanh 嵌套的乘法 。但在 LSTM 的这条主干道上,CtC_tCt 是通过加法 (+++)和 ftf_tft 的乘法传导的。如果 ft≈1f_t \approx 1ft≈1,在反向传播求导时,∂Ct∂Ct−1\frac{\partial C_t}{\partial C_{t-1}}∂Ct−1∂Ct 的值就约等于 1。梯度可以沿着加法路径无损地"流"回去!
4. 输出门(Output Gate):决定向外"展示"什么
ot=σ(Wo⋅ht−1,xt+bo)o_t = \sigma(W_o \cdot h_{t-1}, x_t + b_o)ot=σ(Wo⋅ht−1,xt+bo)
ht=ot∗tanh(Ct)h_t = o_t * \tanh(C_t)ht=ot∗tanh(Ct)
- 物理意义 :主干道 CtC_tCt 里的秘密太多了,当前时刻对外输出(比如用来预测下一个词)时,只需要根据当前语境提取一部分。输出门 oto_tot 就起到了这个过滤作用。
回到你的灵魂拷问:为什么连乘依然是个问题?
你的判断完全正确。虽然 ftf_tft 接近 1 加上加法路径,让 LSTM 撑过了几十上百个词的长度,但它依然没有脱离时序结构。
- 无限长的梦魇 :哪怕 ft=0.99f_t = 0.99ft=0.99,当句子长度达到 1000 个词时,0.9910000.99^{1000}0.991000 依然会趋近于 0。
- 容量瓶颈 :随着序列越来越长,你要把前面所有的信息都塞进一个固定维度的向量 CtC_tCt 里。这就好比一个容量只有 100MB 的 U 盘,你非要往里面塞 10GB 的文件,早期的文件必然会被后来的文件覆盖掉。
我们来纠正一个极其容易踩坑的直觉误区:CtC_tCt 并不是一个会随着词数增加而变长的"列表",它是一个"维度永远固定"的向量(一维数组)。
为什么 CtC_tCt 不能变大?
当我们搭建一个 LSTM 或 RNN 模型时,在写代码的第一步,就必须先设定一个超参数(Hyperparameter),叫做 隐藏层维度(Hidden Size) 。假设我们设定 hidden_size = 512。
这意味着:
- 模型里所有的权重矩阵(Wf,Wi,WcW_f, W_i, W_cWf,Wi,Wc 等)的形状在初始化那一刻就被彻底"锁死"了。
- 因为权重矩阵的形状是固定的,那么经过矩阵乘法算出来的 CtC_tCt 和 hth_tht,其大小也永远被锁死在了 512 个浮点数。
我们再来看那条加法公式:
Ct=ft∗Ct−1+it∗C~tC_t = f_t * C_{t-1} + i_t * \tilde{C}_tCt=ft∗Ct−1+it∗C~t
在数学上,两个向量能够相加,前提是它们的维度必须完全一样 。
无论走到第 1 个词,还是第 1000 个词,Ct−1C_{t-1}Ct−1 是 512 维,新提取的信息 C~t\tilde{C}_tC~t 也是 512 维,加起来之后得到的新 CtC_tCt 依然只有 512 维。它绝对不可能膨胀变成 1024 维或者更大,否则下一步的矩阵乘法直接就会报错崩溃(维度不匹配)。
你的理解非常精准!尤其是对第二个问题的三种假设,直接触及了神经网络特征表示的最核心本质。
1. 关于梯度消失:是的,完全正确。
LSTM 只是"延缓"了梯度消失,而不是从根本上"消灭"了它。
打个比方,RNN 的梯度"保质期"可能只有 20 个词,过了 20 个词梯度就归零了;LSTM 靠着那条加法"高速公路",把保质期延长到了 100 甚至 200 个词。但是,如果面对一篇 1000 个词的超长文本,反向传播经过 1000 次的微小折损,传到第 1 个词的梯度依然会衰减到接近于零。所以,在超长上下文中,早期词的特征依然无法被有效提取。
2. 关于固定维度的容量瓶颈:你的"第三种猜测"是绝对的真理。
"后面的一直可以往里塞,只是说把前面的都改掉了,导致前面的一些向量维度的数据丢失。" ------ 完全正确!
在数学公式 Ct=ft∗Ct−1+it∗C~tC_t = f_t * C_{t-1} + i_t * \tilde{C}_tCt=ft∗Ct−1+it∗C~t 中,因为向量只有固定的 512 维,它处理新信息的方式是数值累加与混合。
- 不是"塞不进去":因为是加法运算,不管来多少个词的向量,都可以和原来的向量相加。
- 不是"直接覆盖":它不是像电脑硬盘那样把旧文件删掉存新文件。
- 真相是"无限稀释与混淆" :就像在一个固定大小的水杯里滴墨水。第 1 滴红墨水(第一个词)进去时,特征很清晰;接着滴入黄的、蓝的、绿的......当滴入第 500 滴不同颜色的墨水时,第 500 滴确实加进去了,但整杯水已经变成了浑浊的黑色。最早那滴红墨水的特征,在经历了 500 次的数值相加和混合后,已经在数学层面被彻底"破坏"和"稀释"了。 这在深度学习中被称为信息过载(Information Overload)导致的分辨率下降。
存在问题
尽管 LSTM 相较传统 RNN 解决了长期依赖问题,性能大幅提升,但在实际应用中,仍存在一些明显的局限性和问题,主要包括:
-
难以并行计算
LSTM 的时间步之间具有强依赖性(后一个时间步的输入依赖前一个时间步的输出),导致无法进行大规模并行加速,训练和推理速度受限。
-
参数量大,计算开销高
每个 LSTM 单元内部包含多个门控机制(输入门、遗忘门、输出门),每个门都需要独立计算,导致参数数量和计算量远大于普通 RNN。
在资源受限的场景下(如移动端、嵌入式设备),部署 LSTM 会面临挑战。
-
长期依赖建模仍然有限
虽然 LSTM 延缓了梯度消失问题,但并不能完全消除。当序列极长时,模型依然难以有效捕捉非常远距离的依赖关系。
3. 门控循环单元 Gated Recurrent Unit(GRU)
Gated Recurrent Unit(GRU)是为了进一步简化 LSTM 结构、降低计算成本而提出的一种变体。GRU 保留了门控机制的核心思想,但相比 LSTM,结构更为简洁,参数更少,训练效率更高。
在许多实际任务中,GRU 能在保持类似性能的同时,显著减少训练时间。
与LSTM相比,GRU做出了以下改进:
- 取消了LSTM中独立的记忆单元,只保留隐藏状态。
- 通过两个门控结构控制信息流动:更新门(Update Gate)和 重置门(Reset Gate)。
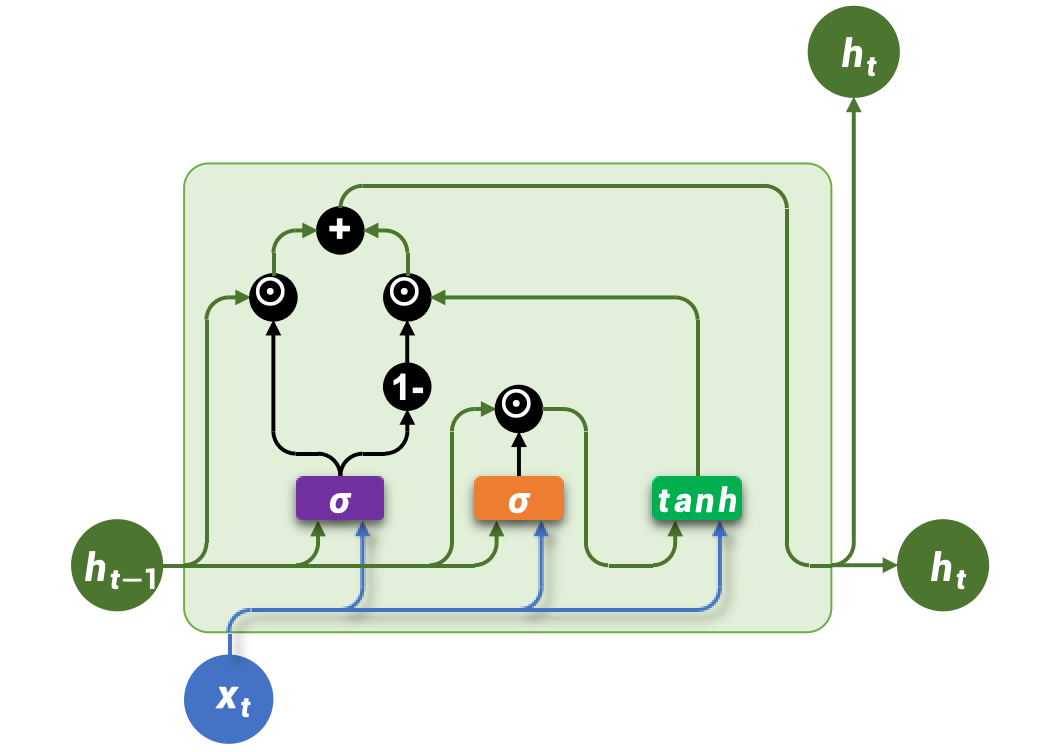
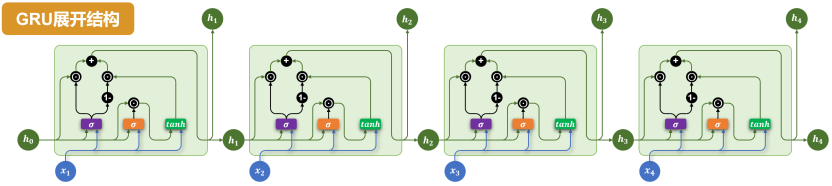
GRU 只有两个门,参数量比 LSTM 足足少了约三分之一!这意味着它训练得更快,占用的显存更少。
- GRU 的更新门 (ztz_tzt) ,相当于 LSTM 的遗忘门 (ftf_tft) 和输入门 (iti_tit) 的合体,负责控制长期记忆的保留与更新。
- GRU 的重置门 (rtr_trt) ,负责短期记忆的筛选,它没有直接对应的 LSTM 门,但功能上可类比为一种 "短期遗忘机制"。
- LSTM 的输出门 (oto_tot) 在 GRU 中没有对应,因为 GRU 直接暴露整个隐藏状态,不再单独控制输出。
存在问题
GRU 在简化结构、提高训练效率方面表现优秀,但在超长依赖建模、灵活性和并行计算方面仍存在天然限制。
4. 序列到序列 Sequence to sequence(Seq2Seq)
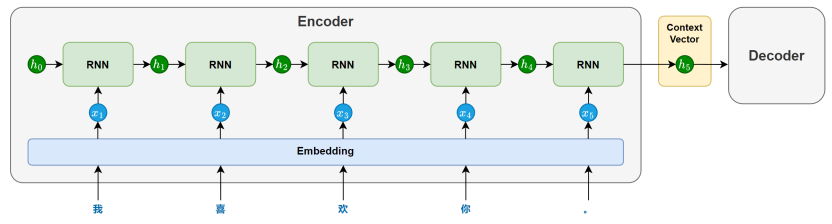
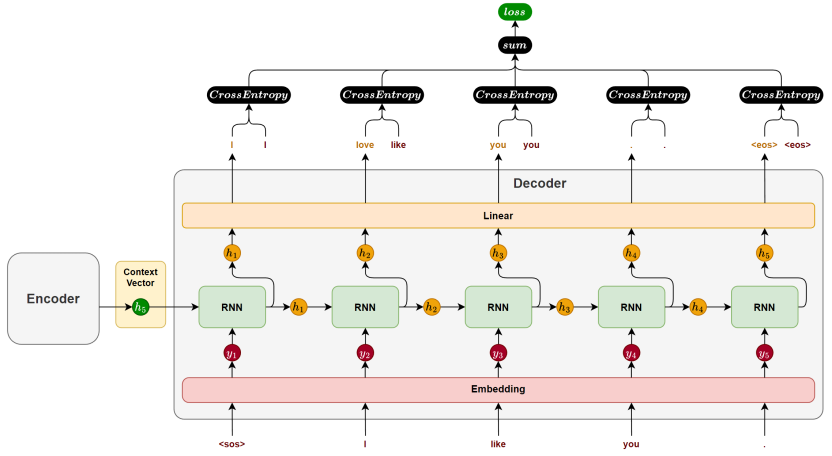
为了把 Seq2Seq 的内部逻辑彻底变成"白盒",我们可以把它想象成一个由两个独立车间组成的"流水线工厂"。
传统的 Seq2Seq 架构由三个核心部件构成:编码器(Encoder) 、上下文向量(Context Vector) 、和解码器(Decoder)。它们底层的零件,正是我们刚刚讲过的 RNN、LSTM 或 GRU。
第一步:Encoder(编码器)------ 负责"读"和"压缩"
假设我们要把中文"我爱你"翻译成英文"I love you"。
Encoder 车间的任务是:逐个读取源语言的词,并把它理解成数学特征。
- 第 1 步:读取"我",更新一次隐藏状态 h1h_1h1。
- 第 2 步:读取"爱",结合 h1h_1h1,更新状态为 h2h_2h2。
- 第 3 步:读取"你",结合 h2h_2h2,更新出最终的状态 h3h_3h3。
关键点来了: 当读完最后一个字时,Encoder 会把整个句子的所有信息,全部浓缩进这最后一步的隐藏状态 h3h_3h3 中。我们给这个 h3h_3h3 起了个专有名词,叫做 上下文向量(Context Vector,通常用 CCC 表示)。
第二步:Context Vector(上下文向量)------ 唯一的"交接棒"
这个向量 CCC 就是连接两个车间的唯一桥梁。
你可以把它想象成一个"高度浓缩的密码箱"。Encoder 把读到的所有中文含义打包塞进这个箱子里,然后把它"扔"给下一个车间。至此,Encoder 的工作彻底结束。
第三步:Decoder(解码器)------ 负责"解压"和"生成"
Decoder 是另一个 RNN/LSTM。它的任务是拿着这个"密码箱 CCC",把里面的内容翻译成英文,而且是逐字生成(自回归计算):
- Decoder 的初始大脑状态,就是那个密码箱 CCC。它根据 CCC 里的信息,预测出第一个词:"I"。
- 接着,它把刚刚生成的"I"作为下一步的输入,结合自己的状态,预测出下一个词:"love"。
- 依此类推,直到它预测出一个特殊的结束符号
<EOS>(End of Sentence),整个生成过程才算完毕。
白盒理解:为什么要搞这么复杂?
你可能会问,为什么不直接让一个网络一边读一边写?
因为自然语言中,输入输出的长度往往是不一样的,语序也是乱的。
比如中文说"我/最近/在/学/大模型"(7个字),英文可能翻译成 "I/am/learning/LLMs/recently"(5个单词)。而且"最近"在中文里放前面,在英文里 "recently" 放句末。
Seq2Seq 完美解决了这个问题:Encoder 只管读,不管写;Decoder 只管写,不管读。 它们通过中间那个密码箱 CCC 来传递信息,从而打破了输入和输出必须长度一致、一一对应的限制。
重新回到刚才的"致命瓶颈"
现在,你已经完全掌握了 Seq2Seq 的整个工作流(Encoder -> 浓缩成 CCC -> Decoder)。
让我们重新代入刚才那个"翻译 500 字长文"的场景:
Encoder 辛辛苦苦读完了 500 个中文词,把这 500 个词的所有细节(主谓宾、语气、情感、逻辑),全部强行塞进了唯一的一个 、且维度固定 (比如只有 512 维)的密码箱 CCC 里。
然后,Decoder 拿着这个极其拥挤、特征被无限混合稀释的密码箱 CCC,准备开始翻译第一个英文字母。
结合 Seq2Seq 的这个架构原理,你现在能感受到,Decoder 此时面临的最大的灾难是什么了吗?
传统的、没有加入 Attention 的 Seq2Seq 模型,存在以下三个最致命的硬伤:
缺点一:信息瓶颈(Information Bottleneck)------ 狭窄的独木桥
这是传统 Seq2Seq 最为人诟病的设计缺陷。
- 底层逻辑 :正如我们刚才看图所讨论的,Encoder(编码器)在处理输入序列时,每一个时间步都会产生一个隐藏状态。但是,传统 Seq2Seq 会把前面所有的中间状态全部丢弃,仅仅把最后一个时间步的隐藏状态作为上下文向量(Context Vector, CCC)传递给 Decoder。
- 带来的灾难 :这个上下文向量 CCC 的维度是固定死(比如 512 维)的。如果输入一句话只有 5 个词,这个"密码箱"空间绰绰有余;但如果输入的一句话有 80 个词,模型也必须强行把这 80 个词的所有信息、语法关系、语义细节,全部压缩进这同一个 512 维的向量里。
- 后果 :这在工程上造成了严重的信息堵塞(Bottleneck)。随着句子变长,长句子的前段、中段的细节会在压缩过程中遭受毁灭性的信息丢失。
缺点二:严重向后倾斜的"近期偏见"(Recency Bias)
虽然我们在前面说到,LSTM 和 GRU 引入了门控机制来"缓解"梯度消失,让模型能多记一些长距离的信息,但这并没有从根本上逆转 RNN 家族"喜新厌旧"的物理本能。
- 底层逻辑 :由于上下文向量 CCC 直接采用了 Encoder 的最后一个隐藏状态 hnh_nhn,在数学上,这个 hnh_nhn 受到最后输入的那几个词的影响,远远大于开头的词。
- 带来的灾难 :以翻译"我喜欢你"为例。Encoder 最后一个读入的字是"你",那么向量 CCC 里装满的几乎都是关于"你"的特征,而句首的"我"和"喜欢",由于在时序上传播得太久,其特征在传到 hnh_nhn 时已经被极大地稀释了。
- 后果 :Decoder 一拿到这个箱子,一打开发现里面全是关于句尾的记忆。这导致 Seq2Seq 模型在翻译长句子时,常常出现把句子的后半部分翻译得很对,但句子开头的词语漏翻、错翻的滑稽现象。
缺点三:静态上下文(Static Context)与无法"对齐"(Lack of Alignment)
人类在做翻译或者生成文本时,思维是动态跳跃的。
- 人类的逻辑:当你(Decoder)准备写英文单词 "I" 的时候,你的眼睛和大脑会盯着中文的"我";当你准备写 "like" 的时候,你的注意力会立刻聚焦到中文的"喜欢"。这种源语言单词和目标语言单词之间的对应关系,在 NLP 里叫做"对齐(Alignment)"。
- 传统 Seq2Seq 的灾难 :在传统架构中,Decoder 的每一个时间步(不管是第 1 步生成 "I",还是第 2 步生成 "like"),它接收到的来自 Encoder 的信息,全都是那个一模一样、静态不变的向量 CCC。
- 后果:Decoder 根本没有办法在生成不同单词时,动态地去源句子里寻找不同的侧重点。它每走一步,面对的都是同一团高度浓缩、无法分辨局部细节的"数学迷雾"。
我们把到目前为止学到的所有缺点串联起来,你会发现这是一个死锁:
- 为了不混淆信息 ,我们不能把所有词的特征挤进一个固定维度的向量 CCC 里。
- 为了实现并行计算,我们必须打破 RNN 必须"一个词接一个词顺序传递"的串联枷锁。
科学家们看着传统 Seq2Seq 架构图,脑子里冒出了一个极其疯狂且大逆不道的想法:
"既然 Encoder 里的每一个中间时间步的隐藏状态(h1,h2,h3...h_1, h_2, h_3...h1,h2,h3...)都保留了那个时间步最纯正、没被稀释的单词特征。那我们为什么不把中间的那个'密码箱 CCC'彻底砸掉? 我们直接把 Encoder 全程产生的所有隐藏状态,变成一个'数据库',原封不动地端给 Decoder,让 Decoder 每次写词的时候,自己进数据库里去挑它想看的位置,这不就行了吗?"
这就是 Attention(注意力机制) 的诞生起源。
5. 注意力机制 Attention
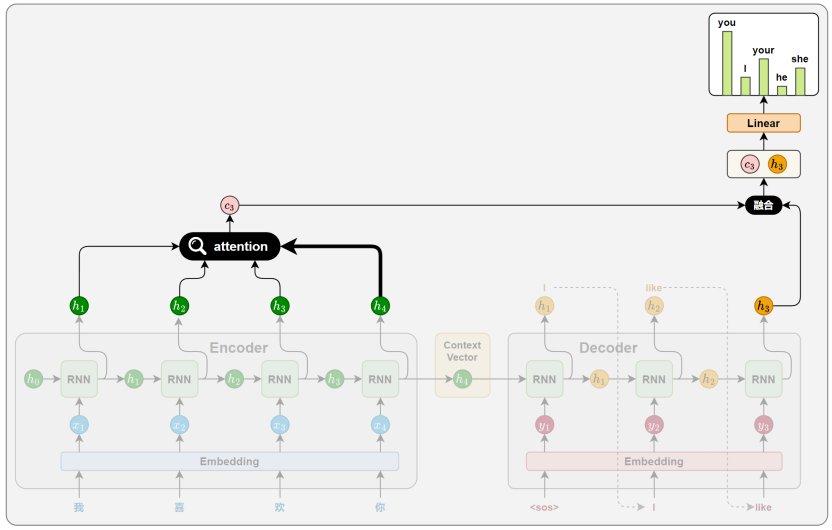
相关性计算
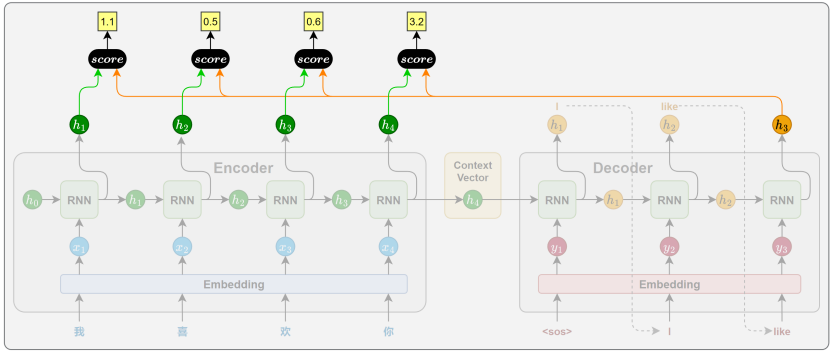
注意力权重计算
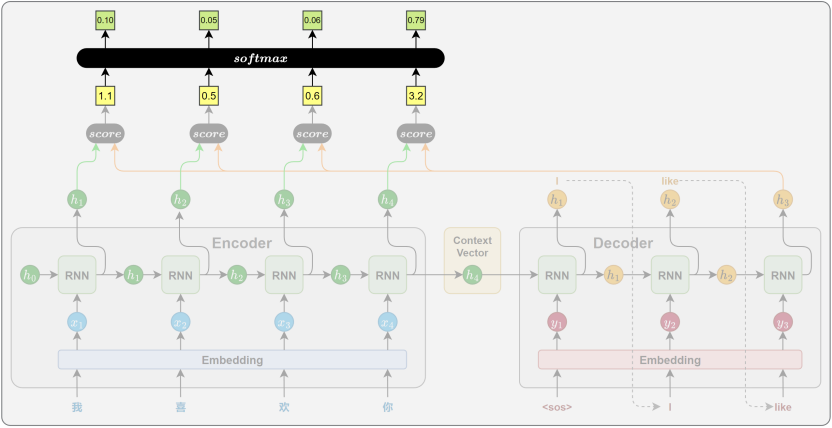
上下文向量计算
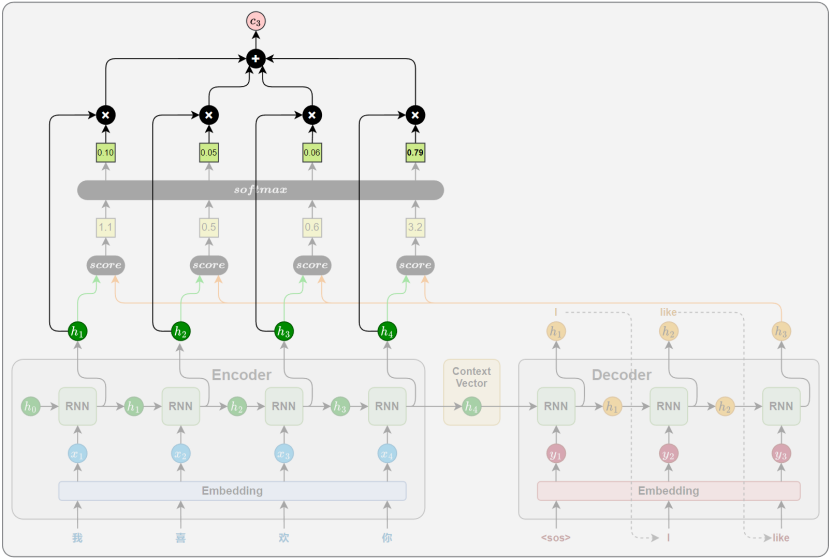
解码信息融合
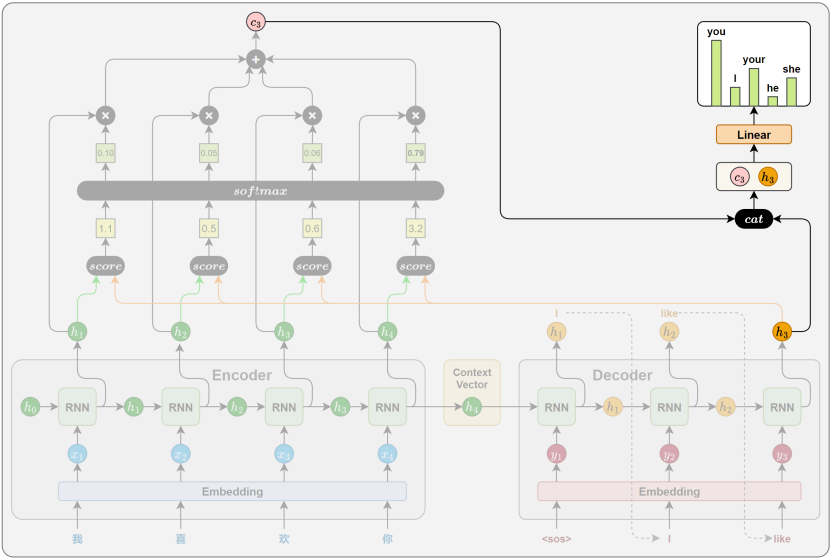
深度学习 NLP 历史上最伟大的一次革命------Attention(注意力机制)!
在 2014 年底,Bahdanau 等人发表了一篇名为《Neural Machine Translation by Jointly Learning to Align and Translate》的论文,这篇论文就像一颗核弹,彻底把传统 Seq2Seq 中间那座拥挤的"独木桥(唯一的向量 CCC)"炸得粉碎。
让我们顺着尚硅谷文档的脉络,看看 Attention 是如何用极其巧妙(甚至可以说是简单粗暴)的方式,同时解决掉"信息瓶颈"和"梯度消失"这两大死局的。
第一招:炸毁独木桥,建立"全连接广播站"
在传统的 Seq2Seq 中,Encoder 的隐藏状态 h1,h2,h3...h_1, h_2, h_3...h1,h2,h3... 算完之后,除了最后一个 hnh_nhn,前面的全被当成垃圾丢掉了。
Attention 的第一个动作是:全都要!
它把 Encoder 每一个时间步产生的隐藏状态(h1,h2,...,hnh_1, h_2, ..., h_nh1,h2,...,hn)全都保存下来,像一个完整的数据库一样,原封不动地全部端给 Decoder。
但这引发了一个新问题:如果 Encoder 读了一篇 500 字的文章,产生了 500 个向量,Decoder 每次写词的时候,难道要把这 500 个向量平均揉在一起吗?如果平均揉在一起,那不又变成一锅粥(浑浊的密码箱)了吗?
第二招:动态对齐(Alignment)------ 想要看哪里,就聚焦哪里
这就是"注意力(Attention)"这个词的灵魂所在。
人类在翻译长句时,视线是动态移动 的。Attention 机制完美地模仿了这一点,它把静态的上下文向量 CCC,变成了一个动态的、每步一换的 CtC_tCt。
我们以翻译"我喜欢你" -> "I like you"为例,看看 Decoder 现在的底层动作:
- 生成 "I" 时 :Decoder 看看自己当前的状态,再回头看看 Encoder 的数据库("我"、"喜欢"、"你"的隐藏状态)。它经过计算,决定把 90% 的注意力(权重)分给"我",5% 分给"喜欢",5% 分给"你"。然后用这个比例,把这三个向量加权求和 ,生成了当前专属的上下文向量 C1C_1C1。
- 生成 "like" 时 :Decoder 状态变了,它再次回头看数据库。这次它决定把 80% 的注意力分给"喜欢",10% 给"我",10% 给"你"。再次加权求和,生成了专属的 C2C_2C2。
完美破解信息瓶颈: Decoder 不再需要吃那口"大杂烩"了。它在生成的每一个时间步,都能根据自己当前的语境,动态地去源句子里"挑选"最相关的信息。
第三招:缩短梯度路径(O(n) 变成 O(1))
这一招是 Attention 附带的物理外挂,直接解决掉了你刚才确认的"梯度消失"问题。
在没有 Attention 时,"I" 这个词的误差想要传回给"我",必须跨越千山万水(连乘几十次)。
但在 Attention 机制下,因为 Decoder 在生成 "I" 的时候,直接拉了一根权重为 0.9 的线,连到了 Encoder 里的"我"身上!
这意味着什么?这意味着在反向传播时,误差信号(梯度)可以直接顺着这条专属的 Attention 连线,一步到位(或者说几乎没有损耗地)空降到 Encoder 的"我"这个字上! 不管序列有多长,100 个词还是 1000 个词,Decoder 和 Encoder 任意两个字之间的距离,在 Attention 连线下,全都被缩短成了"一步(O(1))"!梯度消失的魔咒,被物理层面上的直接连线彻底打破了。
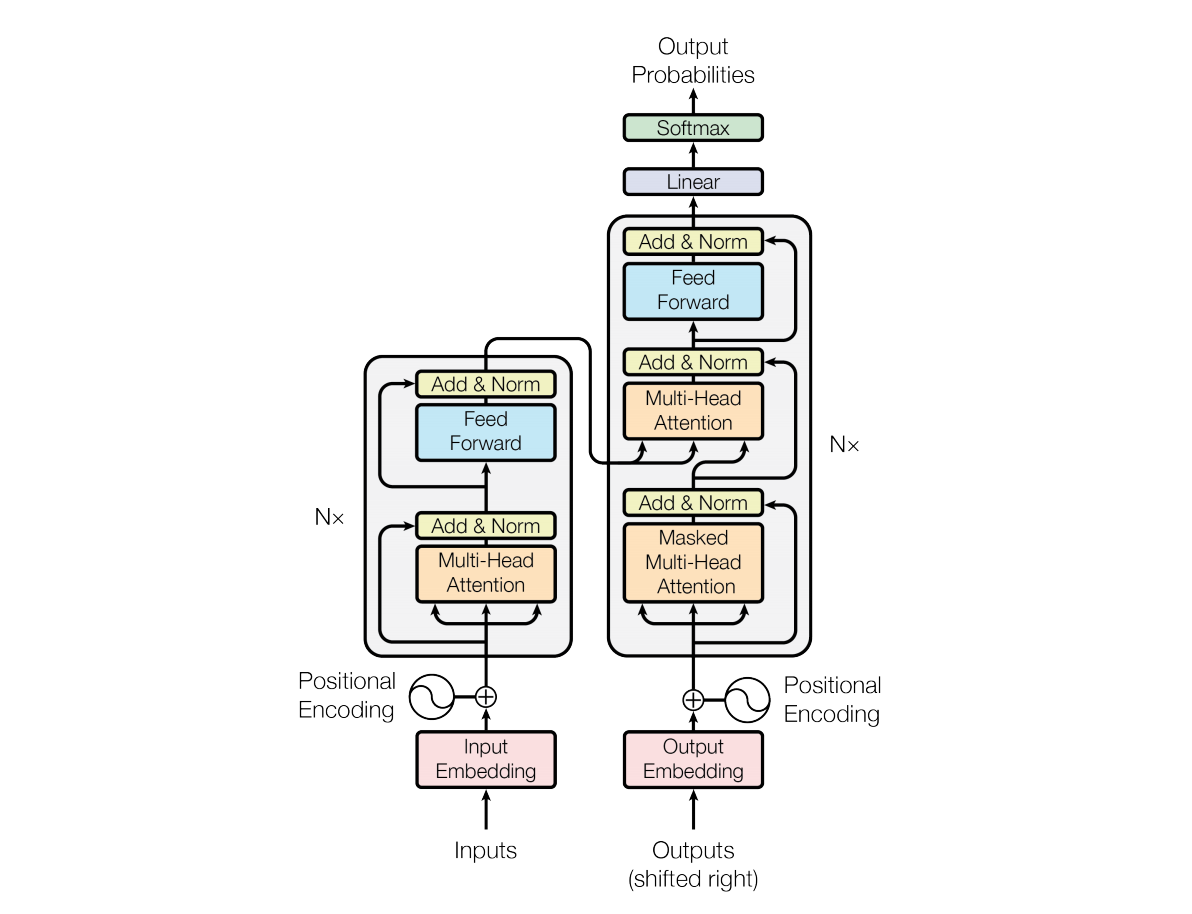
6. Transformer 模型