AI 这股浪潮还在往前涌,作为一个研发,日常里用得最多的,就是用 Ai 辅助写代码,把业务需求赶紧落地上线。用了挺长时间,来回对比过几个工具,慢慢有个感觉:Claude Code 生成的代码质量,确实要比其他竞品高一些。这就让人忍不住想,它到底强在哪?
带着疑问下探求索,这里面可能有方方面面的原因,但是无意间发现 Claude Code 对生码底层有一个质量门禁,底层使用 @meeseeks-sdk/core 这个包来控制代码高质量输出
@meeseeks-sdk/core 是怎么控制质量的呢?官方是这么说的:
An LLM quality gate that learns. Executes AI-generated code in a sandbox, scores it 0--10, retries until the threshold is met --- and remembers what worked.
翻译过来就是:它在一个沙盒环境中执行AI生成代码,然后对代码进行验收,通过一定的标准和机制,对生成的代码打分,分值合格验收通过,分值不合格->重试->直到达到阈值才算合格,最终将合格代码,输出给用户。
这里我们观察到,他有个验收机制来保证代码质量,那么我们接着思考,我们是不是可以借鉴这个思路,通过某种方法方式来提高我们平时的spec coding产生的代码质量呢?
琢磨了一下,有两个方向:
1、一个是直接上 Harness 那种企业级的门禁方案。但翻了翻文档,发现 Harness 的门禁大多是跟 CI/CD 流水线绑死的,策略得用 Rego 语言写,学习成本不低,而且想在 Skill 这个层面去落地,感觉不太顺畅,整体偏重,不太像本地开发该有的样子。
2、另一个方向是,我们日常用的 spec coding 本身就是三段式,在 Skill 这个维度上跑的。那有没有可能,在 Skill 这个层级上,自己做一套轻量的验收机制?这样本地开发完,顺手就能触发验收,跟三段式流程串起来,一整套下来很顺,不用切到别的地方。
基于上面的思路和目的,我们进一步探索实现方案,但是这里有个前置需要注意的点:我们的验收机制,是得同时覆盖 代码层 和 业务层的,实现代码和业务上双层验收
Spec Coding 质保本地轻量级方案
项目定位 :为前端/Node.js 团队设计的、基于 Spec Coding 三段式工作流的代码质量保障本地轻量级方案。核心输出物为 "技术门禁 Skill + 业务审查 Skill"双轨方案,强调"人机协作,人最终拍板"的工程方式。
一、背景与问题域
1.1 我们面对的核心矛盾
随着 Spec Coding 的普及,团队正面临三个递进式挑战:
| 阶段 | 问题 | 典型表现 |
|---|---|---|
| 生成阶段 | AI 生成代码质量不稳定 | 风格不一致、缺少错误处理、硬编码敏感信息 |
| 验证阶段 | 缺乏系统化的质量检查 | 依赖人工 Review,效率低、标准不统一 |
| 业务对齐 | 代码"写对了"但"做错了" | 实现了功能但不符合 AC(验收标准),需求理解偏差 |
| 门禁执行 | 质量要求停留在"建议"层面 | 违反规则依然可以提交/合并,规范形同虚设 |
1.2 核心命题
如何在"不引入复杂工具链、不增加团队学习成本"的前提下,为 Spec Coding 建立一套"可落地、可维护、可演进"的质量保障体系?
1.3 约束条件
- 前端/Node.js 技术栈,团队全员熟悉 JavaScript/TypeScript
- 不引入新语言(如 Rego)、不引入新平台(如 OPA 服务)
- 与 Spec Coding 三段式(需求→设计→编码)自然集成
- 验证时机:代码生成后立即执行,不依赖 CI/CD
- 门禁须具备"硬性阻断能力",但最终决策权保留在开发者手中
二、核心理念
2.1 设计出发点
"让机器干机器擅长的事,让人干人擅长的事。"
| 角色 | 负责事务 |
|---|---|
| 机器(AI + 脚本) | 确定性检查、可自动修复的问题、生成建议补丁 |
| 人(开发者) | 架构判断、业务决策、主观质量评价、最终签字权 |
2.2 核心方法论
采用 "技术门禁 + 业务审查"双轨并行 的验证范式:
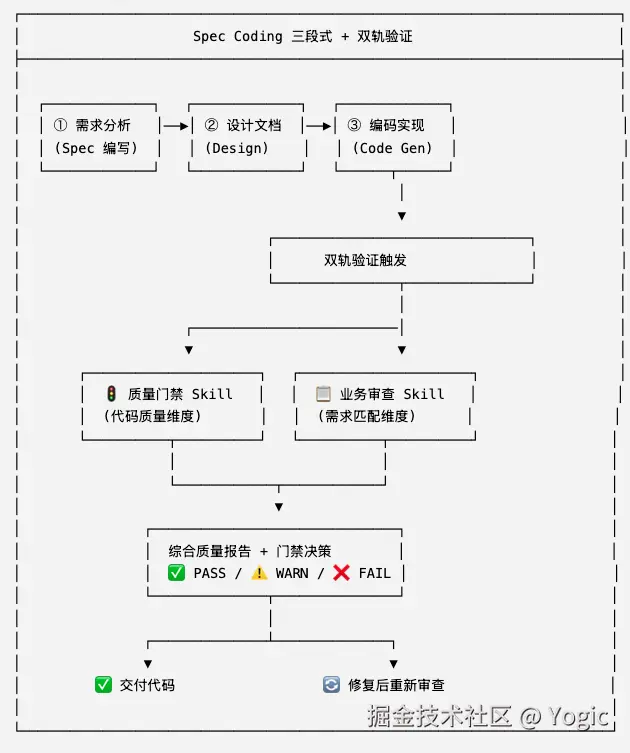
2.3 方案定位:一次性门禁 vs 自动迭代
经过与 Meeseeks SDK 等外部方案的交叉对比,明确本方案的定位是 "一次性门禁 + 建议补丁" ,而非 "全自动迭代"。
| 特性 | 本方案 | Meeseeks SDK |
|---|---|---|
| 验证次数 | 一次(或有限次) | 直到通过为止(∞) |
| 失败处理 | 出报告,等人修复 | AI 自动重写重试 |
| 决策者 | 人 | 机器 |
| 适用场景 | 前端业务代码 | 确定性算法题 |
| 风险控制 | ✅ 人把关 | ⚠️ 可能越改越偏 |
2.4 为什么不在 CI/CD 上做?
本方案定位为 "开发时质量门禁"(Shift-Left),而非"提交合入代码时检查":
| 维度 | 本地时机(本方案) | CI/CD 时机 |
|---|---|---|
| 反馈速度 | 即时 | 分钟级延迟 |
| 迭代成本 | 低(改完立刻再跑) | 高(需 commit + push) |
| 心智模型 | 边写边验 | 写完了再验 |
| 集成复杂度 | 低(仅依赖 Node.js) | 高(需配置流水线) |
2.5 为什么不用 Rego/OPA?
经过深度交叉验证,确认本场景下不使用 Rego/OPA 是正确决策:
| 评估维度 | Rego/OPA 方案 | JS Skill 方案(本方案) |
|---|---|---|
| 学习成本 | 需学习新语言 | 团队已掌握 JS |
| 环境依赖 | OPA CLI/WASM | 仅 Node.js |
| 维护归属 | 需专人/平台团队 | 前端团队自主 |
| 扩展成本 | 跨项目统一管理(平台级) | 项目级自包含 |
| 适用规模 | 多团队/多语言/企业级 | 1-N 个前端项目 |
结论 :Rego/OPA 的价值在于 "公司级策略统一管控" ,对于前端项目本地开发时有点过重。本方案的 JS Skill 路线是 "比较合适的本地轻量化的技术选型"。
三、双轨方案详解
3.1 质量门禁 Skill(代码质量维度)
定位:检查"代码写得对不对",关注代码本身的质量。
执行方式:Skill(Markdown 提示词)编排 Node.js 脚本执行。
架构 : 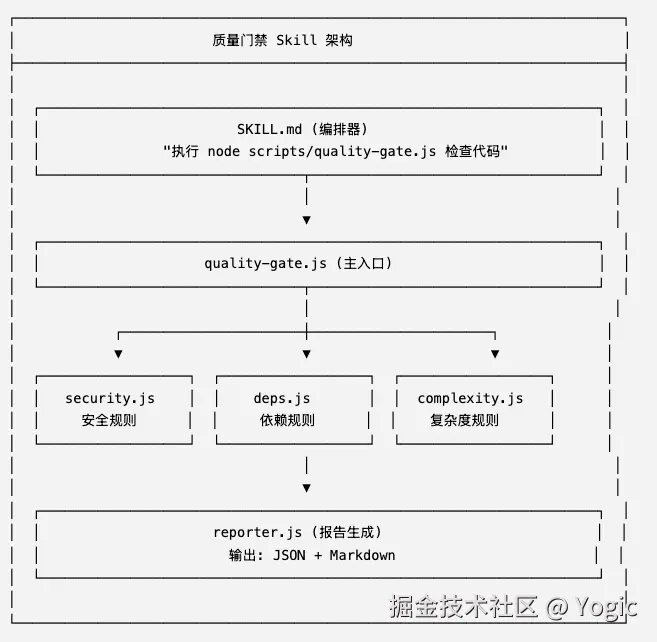
规则分类与处理方式:
| 分类 | 规则示例 | 处理方式 |
|---|---|---|
| 🔴 阻断规则 | 硬编码密钥、高危依赖漏洞、逻辑错误 | 只报告,不出补丁,必须人工修复 |
| 🟡 可修复规则 | 未使用 import、缺 try-catch、命名规范 | 生成 diff 补丁,人工确认后应用 |
| 🔵 优化规则 | 组件过大、性能优化点、代码重复 | 生成建议文档,开发者参考 |
3.2 业务审查 Skill(需求匹配维度)
定位:检查"需求做对了没",关注代码与 Spec 的匹配度。
核心能力:
| 检查项 | 说明 |
|---|---|
| AC 覆盖度 | 逐条比对验收标准(AC),标记已实现/未实现/部分实现 |
| 业务规则验证 | 边界场景、权限控制、状态流转是否正确 |
| 数据完整性 | 必填字段校验、数据格式、唯一性约束 |
| 用户体验一致性 | 反馈提示、加载状态、跳转逻辑 |
输出示例:
| AC 编号 | 描述 | 状态 | 证据 |
|---|---|---|---|
| AC-001 | 登录成功跳转首页 | ✅ | login.ts L45 |
| AC-002 | 登录失败有错误提示 | ⚠️ | 有提示但未区分错误类型 |
| AC-003 | 记住密码功能 | ❌ | 代码中无相关实现 |
业务审查 SKILL.md 中定义业务审查逻辑 示例:
markdown
---
name: business-reviewer
description: 业务需求审查 Skill
---
# 角色
你是业务验收专家,负责验证代码是否完整、准确地实现了 Spec 中定义的业务需求。
# 执行步骤
## 第一步:读取 Spec
从 `spec.md` 中提取所有验收标准(AC),识别 AC 编号和描述。
## 第二步:分析代码
审查生成的代码文件,理解每个函数/组件/API 的实际行为。
## 第三步:逐条比对
对每条 AC:
| AC 编号 | 描述 | 实现状态 | 证据/代码行 |
|---------|------|----------|-------------|
| AC-001 | 登录成功跳转首页 | ✅ | `login.ts` L45 |
| AC-002 | 错误密码提示 | ⚠️ | 有提示但未区分账号/密码错误 |
| AC-003 | 不存在的账号提示 | ❌ | 未实现 |
| AC-004 | 3次失败锁定 | ❌ | 未实现 |
| AC-005 | 控制台打印日志 | ✅ | `login.ts` L48 |
## 第四步:业务规则深度检查
- 边界场景:空数据、极端值、并发操作
- 权限控制:无权限用户的体验
- 状态流转:订单/审批/流程状态是否正确迁移
- 数据完整性:必填字段校验、唯一性约束
## 第五步:输出报告
输出 AC 覆盖矩阵 + 缺失功能清单 + 修复指引四、技术落地路径
4.1 文件结构
bash
项目根目录/
├── .codebuddy/
│ └── skills/
│ ├── quality-gate/
│ │ └── SKILL.md # 质量门禁 Skill
│ └── business-reviewer/
│ └── SKILL.md # 业务审查 Skill
│
├── scripts/
│ ├── quality-gate.js # 主入口
│ ├── rules/
│ │ ├── security.js # 安全规则
│ │ ├── dependencies.js # 依赖规则
│ │ ├── error-handling.js # 错误处理规则
│ │ ├── conventions.js # 代码规范规则
│ │ └── complexity.js # 复杂度规则
│ └── config/
│ └── thresholds.json # 门禁阈值配置
│
└── package.json # 依赖管理4.2 脚本执行机制
- 质量门禁
javascript
quality-gate Skill 触发 → child_process.spawn('node', ['scripts/quality-gate.js']) → 脚本执行 → JSON 输出 → Skill 解析 → Markdown 报告- 业务审查
javascript
business-reviewer Skill 触发 → AC 规则审查 → JSON 输出 → Skill 解析 → Markdown 报告4.3 门禁阈值配置示例
json
{
"thresholds": {
"max_file_lines": 300,
"max_function_lines": 50,
"max_cyclomatic_complexity": 10,
"max_warnings": 3,
"block_rules": ["hardcoded_secret", "critical_vulnerability"],
"auto_fix_rules": ["unused_import", "missing_try_catch", "missing_typedef"]
}
}五、与外部方案的交叉对比
5.1 方案全景对比
| 方案 | 核心机制 | 验证方式 | 修复方式 | 适用场景 |
|---|---|---|---|---|
| 本方案 (Skill + Script) | Skill 编排 + Node.js 脚本 | 静态分析 + AST | 报告 + 建议补丁 | 前端业务代码 |
| Meeseeks SDK 【claude 方式】 | MCP 工具 + 沙盒执行 | 动态执行 + 评分 | AI 自动重试 | 确定性代码验证 |
| Rigour CLI | AST + LLM 交叉验证 | 静态分析 + LLM | 报告 | AI 生成代码审查 |
| Open Code Review | 静态分析 + 规则引擎 | 模式检测 | 报告 | CI/CD 门禁 |
| spec-agent | 规格层验证 | 确定性检查 | 返回错误给 AI | 规格质量合约 |
| Harness + OPA/Rego | 平台级策略引擎 | OPA 决策 | 阻断流水线 | 企业级多团队治理 |
5.2 本方案的差异化优势
| 优势 | 说明 |
|---|---|
| 零学习成本 | 团队用熟悉的 JS 维护规则,无需学新语言 |
| 零基础设施 | 仅依赖 Node.js,无需部署额外服务 |
| 即时反馈 | 在 Spec Coding 流程内触发,不依赖 CI/CD |
| 人机协作 | 机器做确定性检查,人做最终决策,风险可控 |
| 渐进演进 | 可从 5 条核心规则起步,持续扩充 |
5.3 为何不采用 Meeseeks 的"自动重试"模式?
| 评估维度 | 全自动重试(Meeseeks) | 门禁+补丁(本方案) |
|---|---|---|
| 修复 A 破坏 B 的风险 | ⚠️ 存在 | ✅ 可控(人审查) |
| 死循环/Token 浪费 | ⚠️ 可能 | ✅ 不会 |
| 适合前端 UI/业务 | ❌ 不适合 | ✅ 适合 |
| 主观质量把控(可维护性) | ❌ 无法 | ✅ 可控(人审查) |
| 业务审查把控 | ❌ 无法 | ✅ 可控(人审查) |
六、计划后续可探索的扩展能力
| 方向 | 说明 |
|---|---|
| AI 辅助生成规则 | 让 AI 根据历史 Review 记录自动建议新规则 |
| 与 Git Hook 集成 | 提交前自动触发门禁,阻断不合格提交 |
| 团队规则共享 | 建立团队级规则库,跨项目复用 |
七、结论
通过交叉思考与验证,得出以下结论:
-
方案方向正确 :"Skill + Node.js 脚本"是前端团队实施 Spec Coding 质量保障的本地轻量级的优秀技术选型。
-
验证范式清晰:"技术质量门禁 + 业务审查"双轨并行,覆盖代码质量和需求匹配两个维度。
-
与外部方案差异明确:
- vs Meeseeks:选择"一次性门禁+补丁"而非"自动重试",更适合技术和业务双场景
- vs Rego/OPA:选择"项目级 JS 规则"而非"平台级策略语言",更适合本地快速开发
-
可落地性强:无需额外基础设施,团队零学习成本,可从 5 条规则起步渐进演进。
-
具备可复制性:方法论可迁移至其他技术栈(如 Python 后端、Java 后端),具备作为独立技术项目持续发展的潜力。
核心价值主张:
让 AI 生成的代码,在交到开发者手中之前,先过一道"自动化质检关"。过关的,附上补丁和建议;不过关的,退回重写。人最终签字,但琐事不由人做。