前言
随着AI大模型的推广,越来越多的行业和人员开始学习和使用大模型,此文将详细介绍大模型的来时路。首先先了解下什么是人工智能。
人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新技术科学。简单理解就是所有能以人类智能相似的方式做出反应的智能机器,统称为人工智能。该领域的研究包括机器人、语言识别、图像识别、自然语言处理、和专家系统等。
人工智能目前主要分为三大流派。符号主义(基于逻辑推理和符号操作)、连接主义(通过模拟人脑神经网络,将大量简单单元(神经元)的复杂连接来实现智能)、行为主义(强调"感知-行动",注重与环境的交互,不需要复杂的知识表示和推理)
今天的主角机器学习 属于连接主义的一个分支,而一切的一切还要从一个著名的思想实验说起图灵测试。
发展演进图
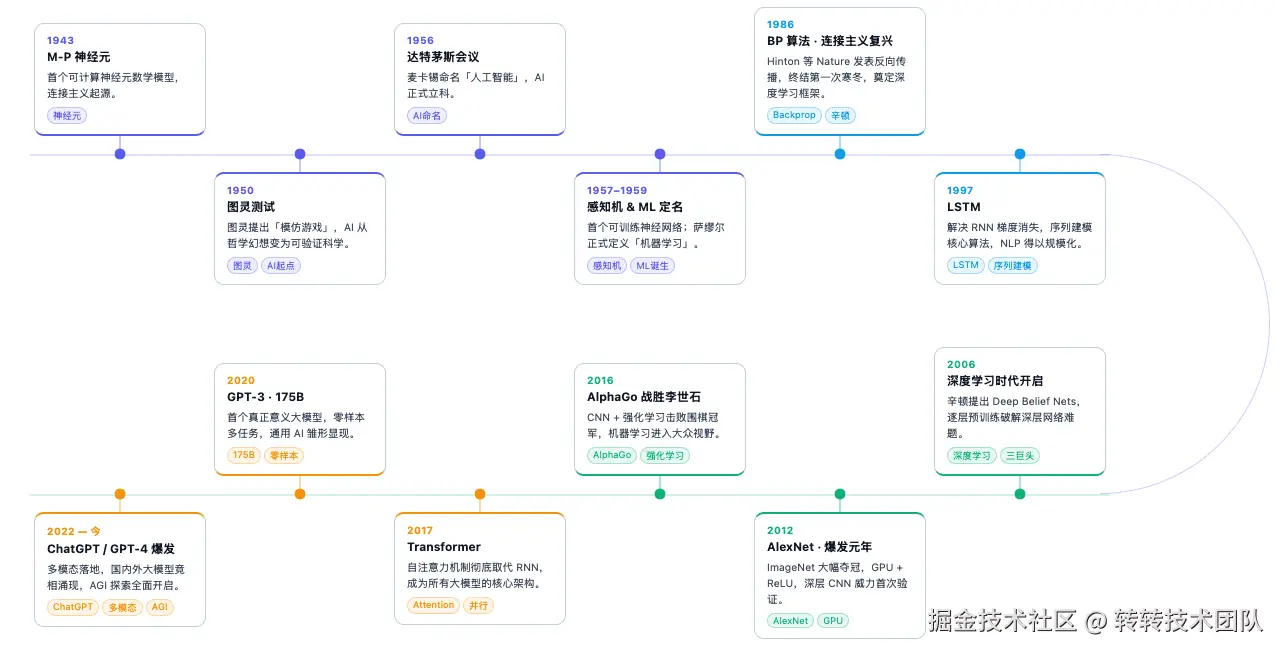
理论萌芽:让机器开口说「学」(1943---1969)
1943年 ,神经科学家沃伦·麦卡洛克(Warren McCulloch ) 和数学家 瓦尔特·皮茨(Walter Pitts )** 一起提出McCulloch-Pitts 模型 (M-P 神经元),把生物大脑里的神经元,简化成了一个可计算的逻辑单元。它接收多个输入信号(0 或 1),把它们通过设定好的权重进行计算,超过某个阈值就输出 1(兴奋),没超过就输出 0(抑制)。由于权重是设定好的,因此不能学习,只能做简单的线性分类、逻辑运算(与、或、非)。
1950年 ,计算机科学之父 艾伦・图灵 在论文**《计算机器与智能(Computing Machinery and Intelligence)》中提出一种思想实验,用于判断机器是否具备 人类级别的智能**。原文中称其为模仿游戏 (Imitation Game),后来学界为了纪念他,将这套实验方法命名为图灵测试。
图灵测试的实验过程是把一个人 和一台机器 分别关在两个房间里,只能通过文字与外部沟通。然后让一个裁判 (人)轮流跟两边对话,如果裁判分辨不出哪个是人、哪个是机器,就说明机器通过了图灵测试。这个实验的提出,标志着机器拥有智能从哲学幻想,变成了可以被科学研究和实验验证的正式课题。
1954年 ,乔治·戴沃尔提交了**《程序化物品转移 (Programmed Article Transfer)》专利(US 2,988,237)。首次提出机器可存储并执行数字指令概念。标志着第一台可编程机器人的概念诞生。1956年其与 英格伯格**(工业机器人之父)合作成立全球首家机器人公司 Unimation 。在1959年成功落地首台原型机 Unimate 001 ,并在1961年将量产型 Unimate 1900 部署至 GM(通用汽车) 工厂,成为首台进入实际生产的可编程工业机器人。
1956年 ,6月18日 - 8 月17日。约翰・麦卡锡^1、马文・明斯基2、克劳德・香农3、纳撒尼尔・罗切斯特4^等人发起了著名的达特茅斯夏季人工智能研究项目(Dartmouth Summer Research Project on Artificial Intelligence),史称达特茅斯会议。

麦卡锡在会议上首次提出并定义了人工智能 (Artificial Intelligence, AI)这一学科名称,将其从 "控制论"、"自动机理论" 等模糊概念中独立出来,确立了全新的研究领域。因此他也被公认为 "人工智能之父"。
在这个会议上,阿瑟・萨缪尔 (Arthur Samuel)也分享了西洋跳棋程序的研究思路与实验。被称为史上第一个真正实现自我学习的计算机程序。

不同于会议期间另一重要人工智能程序逻辑理论家(Logic Theorist)。西洋跳棋程序不靠穷举,用评估函数判断棋局好坏,通过自我对弈调整权重,用有限算力实现了机器从经验中学习、自主变强,正式开启了让计算机 "会学习" 的时代。为后续深蓝(Deep Blue)国际象棋、AlphaGo、AlphaZero等棋类AI奠定了夯实的基础。
1957年 ,弗兰克・罗森布拉特 (Frank Rosenblatt)提出感知机模型,是一个二分类线性判别模型。相对于M-P神经元,最大的特点在于权重不是固定的,而是通过数据自动学习。是首个可学习人工神经网络模型。
**1958年,**人类历史上第一台人工神经网络的硬件实现Mark I Perceptron在康奈尔航空实验室建造,并于1960年在实验室进行了首次公开演示。
1959年 ,阿瑟・萨缪尔 在IBM 研发期刊 (IBM Journal of Research and Development/IBM J. Res. Dev.)正式发表了名为**《利用西洋跳棋进行的机器学习若干研究(Some Studies in Machine Learning Using the Game of Checkers)》这一里程碑论文,以西洋跳棋为实验平台,证明计算机可在非显式编程下自主学习并提升性能。同文正式定义并系统论证了 "机器学习(Machine Learning )"这一概念,将机器学习定义为:"euvc"。标志机器学习正式成为独立研究领域。因此,阿瑟・萨缪尔被称为机器学习之父**。
1960年 ,马克一号(Mark I Perceptron/Alpha-Perceptron)感知机在纽约州布法罗的康奈尔航空实验室进行了首次公开演示。现场成功展示了机器通过约 50 次训练,自主学会区分几何图形与字母。是第一台能从数据中自主学习、无需预编程规则的人工智能硬件,被《纽约时报》称为"大脑的雏形"。开创了连接主义时代。

其不用显式编程,让机器从数据中自动学习规律、提升性能的本质。在后来学术界统一划分时被正式归类为机器学习。
寒冬与破冰:被质疑的十七年(1969---1986)
1969年,Minsky 和 Papert 出版《Perceptrons》一书,书中指出单层感知机的表达能力存在本质局限,无法解决非线性可分问题,最典型的就是无法学习 XOR(异或)问题。因此只能处理线性可分问题,表达能力不足。当然Minsky也承认,如果加多层神经元,理论上可以解决异或问题,但当时没有有效算法训练多层网络。所以该结论直接引发第一次神经网络寒冬,使连接主义研究停滞超过10年。
1970年 ,塞坡・林内马 (Seppo Linnainmaa)在他的硕士学位论文中,首次完整、系统地提出了自动微分的反向模式 (reverse mode of automatic differentiation)。其本质是从输出反向遍历计算图,应用链式法则,一次性算出所有参数的梯度。虽然文中并未提到反向传播 (Backpropagation)相关概念,但学界公认为其是现代反向传播算法的第一个完整、高效、可实现的版本。因此塞坡・林内马 也被称为反向传播数学之父。
1974年 ,保罗・沃博斯 (Paul Werbos)在他的博士论文中,第一次把自动微分 这套数学工具,正式用在多层神经网络的权重训练上。从理论和实验上证明"多层神经网络 + 自微分算法可以解决异或这类非线性问题"。直接回应了 Minsky 1969 年对感知机的批判,证明多层网络是可行的。但由于当时业界处于第一次神经网络寒冬,普遍不看好连接主义。而论文偏数学,没有大规模实验演示。所以影响力有限,在当时未获重视。目前业界公认为其是反向传播在神经网络应用上的真正开创者,是第一个把反向传播真正用于神经网络训练的人。
1986年 ,大卫・鲁梅尔哈特 (David Rumelhart)、杰弗里・辛顿 (Geoffrey E. Hinton)、罗纳德・J・威廉姆斯 (Ronald J. Williams)联合在Nature上发表了论文**《通过误差反向传播学习表示(Learning Representations by Back-propagating Errors)》,文中提出并正式命名了反向传播(Back-propagating/BP)算法。即基于链式法则,实现误差从输出层向输入层反向计算梯度。实现带隐藏层网络的端到端学习,成功解决异或问题。系统提出的多层神经网络训练方法,终结第一次神经网络寒冬(1969--1986)。奠定了现代深度学习的核心训练框架,连接主义由此复兴,让神经网络重回主流。其中 杰弗里・辛顿终身推广神经网络,后获称深度学习教父**。
深度化积累:算法与架构的奠基(1986---2011)
1989年 ,杨·勒丘恩(Yann LeCun)将反向传播算法应用于卷积神经网络(CNN),实现手写数字识别,构建LeNet原型,为后续计算机视觉领域的突破奠定基础;同年,克里斯托弗·沃特金斯(Christopher Watkins)提出Q学习算法,成为现代强化学习的重要基石,无需环境模型即可收敛到最优策略,开创自主学习行为的研究路径
1997年 ,辛顿 (Geoffrey Hinton)与谢鲁·奥辛德罗(Sepp Hochreiter)等人提出长短期记忆网络(LSTM),解决了传统循环神经网络(RNN)的梯度消失/爆炸问题,适用于序列数据处理,为自然语言处理、时间序列预测等场景提供核心算法支撑
2006年 ,辛顿 等人发表"Deep Belief Nets"论文,提出深度学习 (Deep Learning)概念,基于深度置信网络(DBN)提出无监督贪心逐层训练方法,解决深层网络训练难题,正式开启深度学习时代,辛顿也被称为"深度学习之父",与杨·勒丘恩、约书亚·本吉奥(Yoshua Bengio)并称为"深度学习三巨头",奠定深层模型的理论基础
2009年 ,辛顿 团队将深度置信网络(DBN)应用于手写数字识别,错误率大幅降低,验证了深度学习在图像识别领域的优势,打破了SVM等传统算法的垄断地位,进一步推动深度学习的产业化探索
深度学习爆发:算力点燃的十年(2012---2020)
2012年 ,亚历克斯·克里泽夫斯基 (Alex Krizhevsky)、伊利亚·萨茨凯弗(Ilya Sutskever)与辛顿合作,提出AlexNet模型,在ImageNet图像分类竞赛中以显著优势夺冠(错误率较传统方法降低10%以上),首次证明深层卷积神经网络在复杂图像识别中的有效性,成为深度学习爆发的标志性事件;该模型采用ReLU激活函数解决梯度消失问题,使用GPU加速训练,确立了现代CNN的基本架构,为后续计算机视觉技术的突破奠定核心基础
2013年 ,约书亚·本吉奥(Yoshua Bengio)团队提出Word2Vec模型,通过将词语映射到低维向量空间,解决了传统自然语言处理中"词袋模型"无法捕捉语义关联的难题,为自然语言处理的深度学习革命提供了核心技术支撑,广泛应用于文本分类、情感分析、机器翻译等场景
2014年 ,伊恩·古德费洛(Ian Goodfellow)等人提出生成对抗网络(GAN),通过生成器与判别器的对抗训练,实现了高质量的图像生成,开创了生成式AI的新方向,后续衍生出DCGAN、StyleGAN等多种变体,应用于图像修复、风格迁移、虚拟生成等领域;同年,残差网络(ResNet)的雏形被提出,为解决深层网络梯度消失问题提供了新思路
2015年 ,何凯明 等人提出残差网络(ResNet),通过引入残差连接(Skip Connection),成功训练出152层的深层神经网络,在ImageNet竞赛中刷新分类准确率纪录,彻底解决了深层网络训练难度大的问题,成为后续深层CNN模型的基础架构,广泛应用于计算机视觉各类任务
2016年,谷歌DeepMind团队开发的AlphaGo与世界围棋冠军李世石对弈并获胜,震惊全球;AlphaGo融合深度卷积神经网络(CNN)与强化学习(RL),实现了在复杂决策场景下的自主学习与优化,证明了深度学习与强化学习结合的巨大潜力,推动机器学习从"感知"向"决策"跨越,也让机器学习进入大众视野,引发全球范围内的技术热潮
2017年,谷歌团队提出Transformer架构,基于自注意力机制(Self-Attention),彻底改变了自然语言处理的技术路线,解决了传统RNN、LSTM处理长序列数据效率低、依赖顺序计算的局限,成为后续大语言模型(LLM)的核心架构;同年,胶囊网络(Capsule Network)被提出,试图解决CNN在姿态识别、视角变化等场景下的不足,进一步丰富深度学习模型体系
2018年 ,OpenAI推出GPT-1模型,基于Transformer架构,采用无监督预训练+有监督微调的模式,首次展现出强大的文本生成能力;同年,BERT模型(Bidirectional Encoder Representations from Transformers)问世,通过双向注意力机制,在文本理解、问答系统等任务上大幅超越传统模型,成为自然语言处理领域的基础模型,推动预训练模型(Pre-trained Model)成为行业主流
2019年,OpenAI推出GPT-2模型,参数量提升至15亿,文本生成的连贯性、逻辑性显著提升,能够生成接近人类水平的长文本,引发对生成式AI伦理与安全的讨论;同年,XLNet、RoBERTa等BERT变体模型相继推出,进一步优化预训练效果,拓展应用场景;此外,深度学习与计算机视觉深度融合,目标检测(YOLOv4、Faster R-CNN)、语义分割等技术走向成熟,广泛应用于自动驾驶、安防监控等领域
2020年,OpenAI推出GPT-3模型,参数量飙升至1750亿,成为首个真正意义上的"大模型",无需微调即可完成多种自然语言处理任务(零样本学习、少样本学习),展现出通用人工智能的雏形;同年,谷歌推出PaLM模型,参数量达5400亿,进一步推动大模型向"多模态、大参数量、高通用性"方向发展;同时,多模态模型开始兴起,能够处理图像、文本、音频等多种类型数据,打破单一模态的局限
大模型时代:从工具到伙伴(2021---今)
2021s---2020s后期,大模型进入爆发式迭代阶段,OpenAI相继推出ChatGPT、GPT-4,实现了对话交互、多模态理解与生成的重大突破,能够完成代码编写、逻辑推理、图像生成、语言翻译等复杂任务;国内企业(百度、阿里、腾讯等)也推出文心一言、通义千问等大模型,形成全球大模型竞争格局;同时,大模型的轻量化、高效化成为研究热点,边缘端大模型逐步落地,降低应用门槛
总结
机器学习的发展历程,是一部"理论突破---技术迭代---应用落地---反思优化"的循环演进史,从1940s的理论萌芽,到2020s的大模型爆发,每一次突破都离不开数据、算力、算法的协同支撑,也离不开科研工作者的持续探索。其核心价值在于,打破了"计算机只能执行显式指令"的局限,让机器具备自主学习、自主优化的能力,成为推动人工智能发展、赋能数字经济、改变人类生活的核心力量。
从发展启示来看,机器学习的进步从来不是单一技术的突破,而是理论、硬件、应用的协同发展;既要重视基础理论研究,也要关注实际应用需求,避免技术与实践脱节;同时,技术发展必须兼顾伦理与安全,实现"科技向善",让机器学习在推动社会进步的同时,规避潜在风险。
未来,随着通用人工智能的探索、技术的持续迭代与伦理监管的完善,机器学习将继续向更深层次、更广泛领域发展,成为人类社会发展的重要支撑,开启"智能时代"的全新篇章。
注释
参考文献
- 《百度百科 - 人工智能》 :baike.baidu.com/item/%E4%BA...
- 《百度百科 - 达特茅斯会议》 :baike.baidu.com/item/%E8%BE...
- 《人工智能发展简史》 :www.cac.gov.cn/2017-01/23/...
- 《机器学习编年史》 :guorn.com/forum/post/...
- 《知乎》 :zhuanlan.zhihu.com/p/29086574
- 《ChatGPT大模型》 :chatgpt.com
- 《豆包大模型》 :www.doubao.com
- 《KIMI大模型》 :www.kimi.com