前言
最近带团队做技术复盘,有个同行问了我一道大厂面试真题:「给一个纯文本大模型加上视觉能力,它的文本推理表现为啥反而会变差?」对方当时脱口而出的答案是------「参数被占用了呗,分了一部分给视觉编码器」。听上去挺有道理,但这只答到了最表面的一层。面试官回了一句「四重打击你只答出一个」,就把人问沉默了。
很多人对「多模态诅咒」的理解都停在「参数不够分」这一层。但真正决定你能不能在这道题上拿高分、能不能在工程里把多模态模型调好的,是信息密度不对等、权重污染、注意力稀释 这些更底层的机制。给大模型装眼睛不是简单的能力叠加,它是一场要交"税"的权衡------这税率,就是文本能力的下滑幅度。
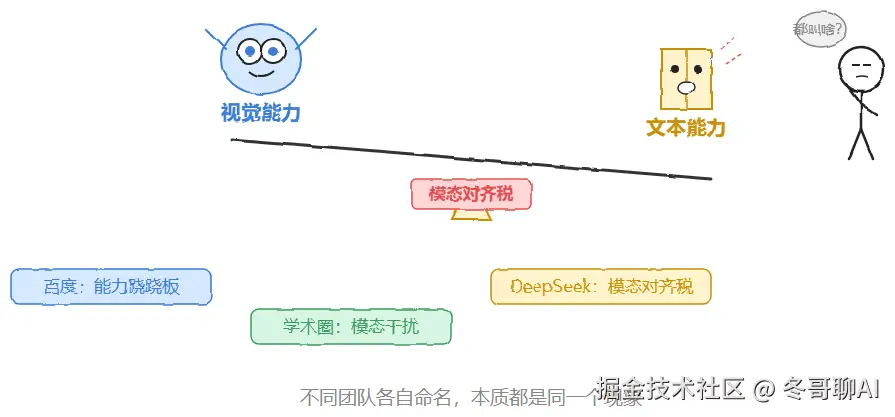
更有意思的是,这根本不是一道孤立的面试题。它背后是整个行业过去三年共同撞上的同一块石头:百度 ERNIE 叫它「能力跷跷板」,学术圈叫「模态干扰」或「模态对齐税」,CLIP 那一脉又叫「模态鸿沟」。不同实验室各自取了不同的名字------这种「撞车式共识」比任何单篇论文都更能说明问题是真实存在的。
这篇文章我想从一个研发管理者和架构师的视角,把这件事彻底讲清楚:诅咒的本质是什么、行业怎么一步步打破它、以及对资源有限的团队来说,今天该怎么针对性防御。
读完这篇文章,你能搞明白:
- 多模态诅咒到底是哪"四重打击",每一重对应什么底层机制
- 为什么「参数被占用」只是其中最浅的一层
- 行业经历的三次范式跳跃:从控损、到解耦、再到互相增强
- 推理模式怎么把「能力跷跷板」变成「能力飞轮」
- 厂商自报 benchmark 该怎么冷静地看
- 资源有限的团队微调 / 训练 VLM 时,怎么针对每一重打击做工程防御
不管你是正在准备大厂 AI 面试的求职者,还是在一线做多模态模型微调、长视频理解的工程师,这篇都能帮你把「多模态变笨」这件事从直觉拉到机制层面。开拆!
一、多模态诅咒:一场行业级的"撞车式共识"
先抛个反直觉的结论:给一个纯文本大模型装上「眼睛」,它大概率不会变得更聪明,反而会在数学推理、代码生成、逻辑推理这些纯文本任务上掉分。
这听起来很违反常识。多一个理解世界的维度------能读图、能看视频------怎么算都该是好事才对。但行业过去三年交出的答卷,恰恰是反过来的。
从 2023 年开始,几乎所有从纯文本 LLM 升级到多模态 VLM 的模型,在上面那几类纯文本任务上,都画出了同一条下滑曲线。这不是某一家的个案,而是整个行业不约而同踩进的同一个坑。
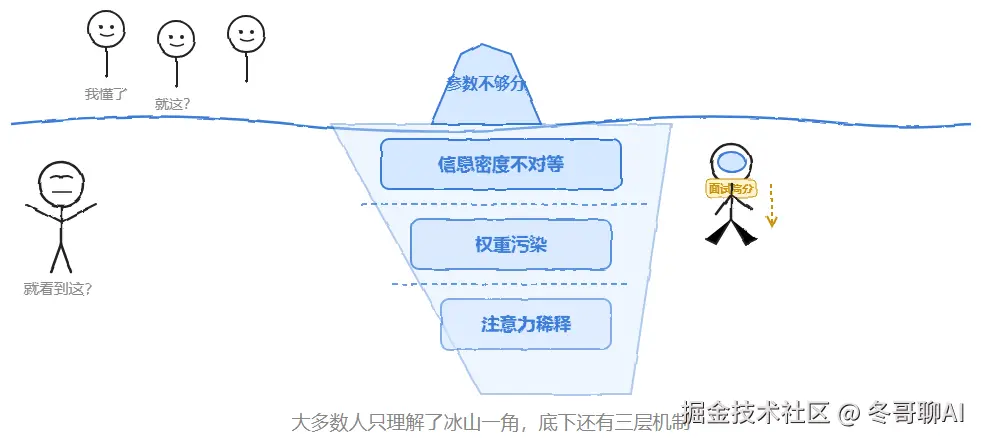
不同团队给它起了不同的名字。百度 ERNIE 管它叫「能力跷跷板」,InternVL 和 DeepSeek VL 的技术报告里各自讨论过;学术圈说得更直白,叫「模态干扰」或者「模态对齐税」------意思是你想加视觉这项能力,得先交税,税率就是文本能力的下滑幅度。
命名越混乱,反而越能侧面证明这件事的真实性。不同实验室、不同团队,彼此独立地观察到同一个现象,又各自取了不同的名字。这种「撞车式共识」在 AI 研究里,比任何单篇论文的结论都更有分量。
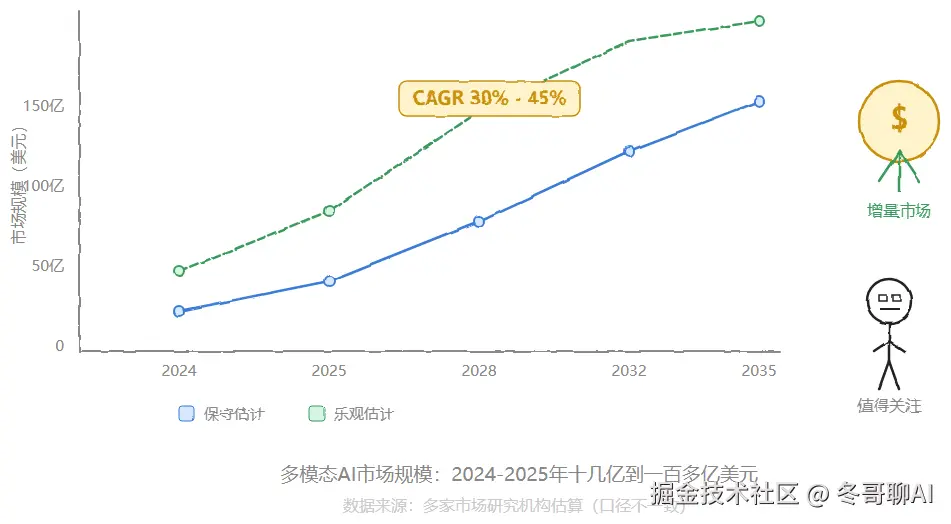
从市场角度也能看出这个问题的体量。多家研究机构对全球多模态 AI 市场的估算口径不一,但大致都认同 2024 到 2025 这个市场规模在十几亿到一百多亿美元之间,未来十年复合增长率普遍预测在 30% 到 45% 区间。换句话说,多模态正在变成大模型产品的标配项------谁先解决「加了视觉就变笨」,谁就先吃到这块增量。
好消息是,2025 年之后风向变了,这个诅咒正在被打破。千问 3 Omni 的技术报告给出了一个相当强的表述:在文本、图像、音频、视频四个模态上,相对于同规模的单模态模型,第一次实现了没有可测量的性能退化。
那既然诅咒都快被解开了,现在回头讲它还有什么意义?我的看法有两条。第一,理解诅咒为什么存在,你才能理解今天的解法为什么真的有效------否则你只是背了个结论,换个场景就用不上。第二,对资源有限的团队、中小规模模型、微调场景来说,这个问题到今天依然存在------不是每个团队都有预算从零训一个万亿参数的原生多模态模型。
所以接下来的逻辑是:先把四重打击的本质讲透,再讲行业怎么一步步打破它,最后落到「这对你意味着什么」。
那个同行在面试里只答出了「参数被占用」,对应的是四重打击里的第二重。但在它前面,还有一层更根本的东西。我们从第一重开始拆。
二、第一重打击:信息密度不对等
第一重打击,也是最根本的矛盾:信息密度不对等。
文本是人类经过几千年压缩出来的高密度符号系统,一句话里能塞下时间、人物、因果关系。而一张图有几百万个像素,其中绝大多数像素描述的,都是对逻辑推理毫无用处的低级物理特征------头发丝、纹理、光线、衣服褶皱这些东西。
拿具体数字说话。一张 224×224 的图像,按 ViT-L/14 的切片方式,会被切成几百个 Patch token。这堆 token 里能扛起「高阶语义」那部分的占比极低,跟等长的一段文字比起来差出几个量级。把这些贫信息的特征投影进文本空间后,模型接收到的基本是一片噪声。
换信息论的语言讲:一个在文本上训练出来的解码器,只会沿着文本对齐的方向去抽取信息。视觉信号里大量不在这个方向上的东西,对它而言全是干扰项。
这个矛盾还有一个更学术的佐证。在 CLIP 训练出的视觉-语言联合空间里,它有个名字叫「模态鸿沟」(modality gap)。即便经过对比学习对齐,图像和文本的 embedding 在向量空间里也常常各自聚成两团,而不是完全重合。这从几何结构上印证了:信息密度不对等不只是个比喻,而是真实存在、有结构支撑的现象。
一句话概括第一重打击:你喂给模型的视觉信号,绝大部分对推理无用,却又全部挤进了它的输入------这本身就是在往一锅清汤里掺沙子。
三、第二重打击:参数容量的零和博弈
第二重打击,就是那个同行在面试里答出来的那层:参数容量的零和博弈。
一个 7B 的纯文本模型,理论上 100% 的参数都能拿去理解语言和逻辑。一旦加了视觉,它就必须分出一部分参数去理解空间、纹理、色彩、物体边界。总量没变,分蛋糕的人却多了。

拿早期的 Qwen-VL 系列做参照:它的视觉编码器本身就有数亿参数的规模,这部分容量是独立于语言主干之外另配的。看着像「免费午餐」------语言模型那块我一动不动,旁边单独挂一个视觉模块就完事。可代价是整个模型训练和推理的开销都被抬高了。一旦不肯多掏预算,语言主干的参数空间照样会被悄悄蚕食,这事儿在 7B 以下的小模型上尤其要命------蛋糕本来就小,再切一刀给视觉,语言这块自然瘦得明显。
一句话概括第二重打击:参数是有限的预算,视觉和语言在抢同一笔钱。模型越小,这场零和博弈越惨烈。
四、第三重打击:跨模态对齐的权重污染
第三重打击是跨模态对齐过程中的权重污染。
早期的主流做法是:把一个预训练好的 ViT,通过一个投影层接到预训练好的 LLM 上,然后整体做微调。问题在于,视觉的 Embedding 空间和文本的 Token 空间本质上是异构的,为了把两边对齐,微调过程难免会去改动 LLM 原本的权重。

学术界一系列关于「持续视觉指令微调」的研究反复验证了这个代价。不少论文发现,用 LoRA 做视觉-语言对齐微调时,模型会出现一种「双重灾难性遗忘」------不光是原本学到的视觉理解能力会被新任务冲掉,连指令遵循能力也会随着任务数量增多而逐渐衰退。
说得直白点:你原来精心训好的那套文本权重,会在对齐视觉的过程中被悄悄扭曲。这跟第二重的「参数被分走」不是一回事------第二重是「容量被占」,第三重是「已有的能力被改坏」。前者是预算问题,后者是质量问题。
一句话概括第三重打击:为了让模型看懂图,你不得不动它原本写好的「语言脑回路」,结果手术做完,视力是有了,但说话的逻辑也跟着乱了。
五、第四重打击:视觉 Token 对注意力的稀释
第四重打击是视觉 Token 对注意力的稀释。
一张图切成 Patch 之后,会变成几百甚至上千个 Token。而自注意力机制要计算所有 Token 两两之间的相关性。当大量冗余的视觉 Token 涌进上下文窗口,模型分给关键文本提示词的那点注意力,就被摊薄了。
更麻烦的是,高分辨率和动态分辨率技术让单张图能产生的 Token 数量越来越大。像千问系列的动态分辨率方案,一张高清图切出上千个视觉 Token 并不罕见。这个问题在长视频场景里被进一步放大------视频本质上就是连续多帧图像的堆叠,Token 数量是成倍累积的。你输入一段几分钟的视频,光视觉 Token 就能把上下文窗口撑爆,留给文本指令的注意力所剩无几。
一句话概括第四重打击:注意力是一种稀缺资源,视觉 Token 一多,就把它稀释了------模型不是不想专心听你的指令,是它的「注意力预算」被一屏幕像素瓜分掉了。
把这四重摞在一起,就是多模态诅咒的完整机制:
- 信息密度不对等 → 带来噪声
- 参数容量零和博弈 → 分蛋糕的人变多
- 跨模态对齐权重污染 → 扭曲已练好的文本能力
- 视觉 Token 稀释注意力 → 摊薄关键信息
也正因为它是四重叠加、而非单一原因,后面你会看到,行业的解法注定不是单点突破,而是分层递进、一层一层往下啃的。
六、三次范式跳跃:行业怎么一步步把诅咒拆掉
理解了四重打击,就能看懂行业这三年的解法为什么是这么演进的。三次范式跳跃,每一次都比上一次往下啃得更深一层。
1. 第一次跳跃(2023-2024):承认诅咒,用工程手段控损
这一阶段的两个核心策略,都是在不挑战根本矛盾的前提下做减法。
策略一:数据配比。 多模态训练阶段刻意保持 70% 以上的纯文本数据,图文数据只作为增量加进去,持续用文本、代码、数学题把模型的文本基本盘拽住。DeepSeek VL 的报告里明确写过这个比例。思路很朴素------既然加图会掉文本分,那我就让文本数据占大头,别让图把模型带跑偏。
策略二:冻结策略。 LLaVA 系列是这条路线最典型的代表,训练分两段走。第一阶段,用大约 55.8 万对图文数据做特征对齐,这时候视觉编码器和语言模型的参数全冻住,只训中间那个投影层;到第二阶段才把语言模型解冻,用约 66.5 万条指令数据端到端微调,视觉编码器则继续锁着不动。这套「先对齐参数、再逐步解冻」的两步走思路,随后被 InstructBLIP、MiniGPT-4 等同期项目不同程度地搬了过去------说明它不是 LLaVA 一家的孤立选择,而是当时整个开源社区面对诅咒时的共同妥协。
代价也很清楚:视觉编码器全程冻结,意味着它没法跟着下游任务深度学习,多模态融合的深度被锁死在投影层这薄薄一层上,这就是这条路线的天花板。
这一阶段的本质是「认清问题、尽量缓解」。 解法有效,但有上限------它没解决信息密度不对等和参数零和博弈的根本矛盾,只是把伤害控制在了可接受范围。
2. 第二次跳跃(2024-2025):不再外挂,从头设计原生多模态架构
代表是 GPT-4o、Gemini 系列、ERNIE 5.0、DeepSeek VL2,它们做了两件事。
第一件:联合预训练。 从第一天起就让文本和视觉在同一个模型里一起训,而不是先训好一个再嫁接另一个。公开资料最齐全的案例要数百度 ERNIE 5.0------这是个 2.4 万亿参数体量的统一多模态模型,各路模态打一开始就被拉到一起从头训练。官方报告里明确写道,这套做法缓解了后融合方法里观察到的「能力跷跷板」。为什么有效?因为在参数空间还没被文本占满的时候就让视觉进来,模型会自然学会怎么分配空间,不必把一种模态的参数强行改造去适配另一种。这是直接针对第三重「权重污染」的解法------你压根就不存在「先练好文本再去改」这一步,自然也就没有改坏一说。
第二件:MoE 解耦。 借混合专家架构给不同模态铺设各自的计算通道------遇到视觉 Token 就唤起视觉专家,遇到文本 Token 就唤起文本专家,在路由那一层就把两者岔开。这样参数容量上的零和博弈也就化解了,毕竟各模态调用的根本是互不重叠的专家子集。这直接回应了第二重打击。DeepSeek VL2 正是沿用了 DeepSeekMoE 的稀疏专家设计来实现这一点。
这一阶段大幅缓解了诅咒,但在极致的数学推理和代码生成上,跟同规模纯文本模型相比依然有微小差距。因为前两重打击虽然被缓解,第三、第四重------权重污染的残留和视觉 Token 对注意力的稀释------还在。说到底,信息密度那个最根上的矛盾,无论联合预训练还是 MoE 路由都没真正啃下来,不过是把它摊派给了各个专家分别消化罢了。
七、从跷跷板到飞轮:推理模式带来的质变
1. 第三次跳跃(2025-2026):引入推理模式
这一代做对了一件之前没人正面解决的事:让模型在多模态输入上投入更多计算量去深度理解,而不是直接输出。
关键洞察在于------视觉信息密度低,不等于视觉信息没价值,问题在于模型花了多少计算量去提取其中的高阶语义。之前的模型看到一张图,编码成几百个 Token 就直接扔进后续生成,视觉 Token 里大量低级特征就这么裹挟着涌进了推理过程。
推理型多模态模型的做法不一样:正式输出之前,先进入一个思考阶段,用大量隐式推理步骤去消化视觉输入,把里面的结构化高阶语义提炼出来,再基于精炼后的信息做逻辑推理。
千问 3 Omni 用的是 Thinker-Talker 架构。Thinker 负责接收所有模态输入并做深度推理,它那套内部推理流程,干的活儿其实就是把稀薄的视觉信息浓缩成致密的逻辑表征。这一步浓缩烧掉了额外算力,换回来的是在推理环节把信息密度拉齐------这恰恰是第一重打击的根,绕了一大圈,终于有人正面去碰它了。
2. 推到 Agent 层面:从读图到操作环境
千问 3.7 Plus 进一步把这条路线推到了 Agent 层面。它被官方定义为「多模态交互混合智能体」,能在同一个上下文窗口里同时操作 GUI 和 CLI:从读懂一张界面截图,到写代码复现这个界面,再到跑测试验证结果,整条链路不需要切换模型或管道。
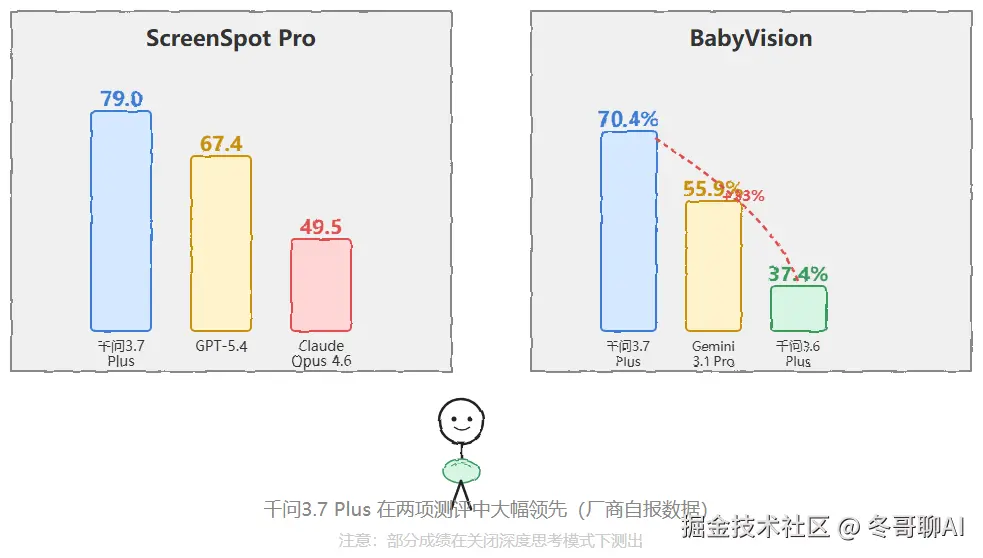
这里有一组对比数据值得拿出来看:
| 测评 | 千问 3.7 Plus | 对照组 |
|---|---|---|
| ScreenSpot Pro(GUI 视觉定位) | 79.0 | GPT-5.4:67.4 / Claude Opus 4.6:49.5 |
| BabyVision(视觉认知与空间推理) | 70.4%(上代 3.6 Plus 仅 37.4%) | Gemini 3.1 Pro:55.9% |
数字确实亮眼。但站在一个要为采购和选型负责的人的角度,我得补一句更冷静的话:这些全是厂商自报的测评成绩,而且部分是在关闭深度思考模式下测出来的,更适合当作一个待验证的假设,而不是可以直接拍板的采购依据。 真实业务里的分布外样本,往往比测评集更不讲道理。Benchmark 看趋势可以,当结论慎重。
3. 从「能力跷跷板」到「能力飞轮」
抛开具体数字不谈,这一跳的质变意义是清晰的:多模态不再是拖累了。
当模型学会用足够多的计算量去深度消化视觉信息,而不是浅层编码直接扔进推理,视觉输入反而变成了推理能力的增量来源。因为图表、架构图、UI 截图这些东西,本身就包含丰富的结构化逻辑------而这些逻辑信息,是纯文本语料里根本没有的。
从「能力跷跷板」到「能力飞轮」,这是一次质的跳跃。跷跷板是此消彼长,飞轮是互相驱动。把这三次跳跃串起来看,会发现一条很清楚的主线:
- 第一次解决的是怎么少受伤(数据配比 + 冻结策略)
- 第二次解决的是怎么不互相伤害(原生联合预训练 + MoE 解耦)
- 第三次解决的是怎么互相增强(推理模式)
一次比一次往根上走。
八、从架构师视角看多模态融合的几个工程取舍
前面讲的是机制和演进,都偏「认知」。但作为一个带团队做工程落地的人,我更关心的是:知道了这四重打击和三次跳跃,在真实项目里到底该怎么用?下面这几条,是我认为最容易被忽略、却最影响结果的工程取舍。
1. 别迷信「原生多模态」,先看清自己在哪个段位。
很多团队一听「原生联合预训练 + MoE 解耦」就想照搬,但这套打法的前提是万亿参数级别的算力预算和数据规模。绝大多数团队真正在用的,是 7B 到 70B 区间的开源权重模型(Qwen、Llama、InternVL 这类)。在这个段位,第一次跳跃的「数据配比 + 冻结策略」依然是你的主力武器,不是过时的东西。别拿头部实验室的解法,去套自己手里的小模型。
2. 数据配比是微调阶段的第一道防线,也是最容易翻车的地方。
如果你在微调一个开源 VLM,图文数据占比过高,文本能力必然下降------这几乎是铁律。很多团队第一次做多模态微调,兴冲冲灌了一大堆图文对,结果发现模型连原来好好的指令都不听了,回头一查就是文本数据被稀释得太狠。把纯文本、代码、数学题的占比拉到 70% 以上当兜底,是花小钱省大坑的事。
3. 中小模型上,MoE 解耦不是「可选项」而是「必选项」。
第二重打击在小模型上格外严重------参数本来就少,视觉和语言抢得更凶。如果你在训练一个中小规模的多模态模型,与其纠结怎么把视觉硬塞进稠密模型,不如一开始就考虑稀疏专家路由,从架构层面把模态竞争分开。这笔架构债,越往后欠越难还。
4. 长视频 / 多图场景,视觉 Token 压缩策略决定你的上限。
第四重打击在长视频里被成倍放大。动态分辨率、关键帧采样、语义级 Token 压缩------这些不是锦上添花的优化,而是决定你能不能把场景跑起来的生死线。做长视频理解,第一天就要把 Token 预算当成一等公民来设计,而不是等 OOM 了再回头补。
5. Benchmark 看趋势,POC 看自己的数据。
厂商自报的跑分能帮你筛掉明显不行的候选,但绝不能拿来直接拍采购板。任何一个号称「零退化」的模型,进你的业务之前,都得用你自己的分布外样本跑一轮 POC。别人的 benchmark 是别人的题库,你的业务才是你的考卷。
6. 「四重打击」是个好用的诊断框架,但别把它当永恒真理。
它今天是诊断工具,但随着治理成本下沉,未来它可能更多是用来「解释历史」而不是「指导当下」。用它来定位问题出在哪一层很好用------掉分了,先问是噪声(第一重)、是容量(第二重)、是污染(第三重)、还是稀释(第四重)。但别拿一个框架去框死所有未来的解法。
九、给一线技术人的几条落地建议
机制和取舍都讲完了,最后给几条可以马上动手的。按时间梯度排,从这周能干的,到需要长期建设的。
1. 这周可以做的:把「四重打击」当成你的排错清单
下次你的多模态模型在某个纯文本任务上掉分,别再笼统地说「多模态变笨了」。拿这四重去逐个排查:是输入噪声太多(第一重)、是模型太小容量不够(第二重)、是微调把文本权重改坏了(第三重)、还是视觉 Token 把注意力稀释了(第四重)?定位到具体哪一层,解法自然就清楚了。
2. 这个月可以做的:给你的微调流程加一道「文本基本盘」回归测试
在图文微调的 pipeline 里,固定挂一组纯文本的数学、代码、逻辑推理测试集,每轮微调后都跑一遍。一旦文本分数开始往下掉,立刻回头查数据配比。别等模型上线后用户投诉「以前会的现在不会了」,才发现文本能力被悄悄掏空了。
3. 这个季度可以做的:建立团队级的多模态数据配比规范
把「纯文本占比不低于 70%」「图文数据按场景分层」这类经验,沉淀成团队的训练规范,而不是每个工程师凭手感调。多模态微调最贵的不是算力,是反复试错踩同一个坑的时间。一份规范能让新人少走半年弯路。
4. 长期需要建立的:从「调模型」转向「设计模态融合策略」的能力
随着治理成本下沉,未来的竞争力不在于你会不会调一个 VLM,而在于你能不能根据业务场景,设计出合适的模态融合策略------什么场景该用原生多模态、什么场景外挂视觉编码器就够、什么场景必须上推理模式。工具会越来越平民化,但「在哪一层做取舍」的判断力,才是长期值钱的东西。
总结
把全文收一下,核心就这么几条:
-
多模态诅咒的本质是四重打击叠加:信息密度不对等带来噪声、参数容量零和博弈让分蛋糕的人变多、跨模态对齐污染扭曲了原本练好的文本能力、视觉 Token 稀释摊薄了关键信息。「参数被占用」只是其中最浅的第二重。
-
行业用三次范式跳跃来打破它:从数据配比 + 冻结策略的「少受伤」,到原生联合预训练 + MoE 解耦的「不互相伤害」,再到推理型多模态的「互相增强」。每一次都比上一次往根上走一层。
-
推理模式是从「跷跷板」到「飞轮」的关键:当模型肯花计算量去深度消化视觉信息,图表、架构图、UI 截图里那些纯文本没有的结构化逻辑,反而成了推理能力的增量来源。
-
厂商自报的「零退化」要冷静看:这些成绩大多还停留在 benchmark 阶段,距离独立第三方和真实业务的充分验证还有一段路。Benchmark 看趋势,选型看自己的 POC。
-
对中小模型和微调场景,诅咒到今天依然存在:万亿参数的原生多模态是头部实验室的专利,大多数团队还在 7B-70B 区间做微调------理解每一层机制、针对性做工程防御,仍是绕不开的必修课。
最后说一句我自己的判断:多模态诅咒大概率不会被某一次架构创新彻底「治愈」,更可能的走向是治理成本不断下沉。 今天只有万亿参数模型才能做到的「零退化」,未来两三年里,会随着 MoE 路由和推理范式的工程化,逐步下沉到百亿甚至十亿参数级别。到那时候,「四重打击」这个分析框架本身,可能就从诊断工具,变成了历史课本里的一段注脚。
技术的进步往往就是这样------今天的天花板,是明天的地板。