1. 概述
StarRocks x Fluss x Paimon 湖流一体方案通过将 Apache Fluss(面向分析场景的实时流存储)与 Apache Paimon(高性能湖格式表)深度融合,以 StarRocks 作为统一查询入口,构建了一套具备秒级新鲜度、十倍成本降低、一份数据一次查询的全新实时数据引擎。本文将介绍该方案的核心架构、技术优势、查询模式以及在阿里云 EMR Serverless StarRocks 上的产品化落地。
2. 背景与挑战
2.1 Lambda 架构的痛点
在传统 Lambda 架构中,实时链路采用 Kafka + Flink,离线链路采用 Hive + Spark,两套系统各自运行。这套架构虽然已服务行业多年,但始终存在三个核心痛点:
-
存储翻倍: 同一份业务数据在 Kafka 保留 7 天,在 Hive 再存一份,存储成本成倍增长。
-
代码翻倍: 流批开发、运维两套 Pipeline,数据口径经常不一致,排查问题时大量时间消耗在核对实时与离线数据上。
-
新鲜度上不去: 离线链路通常 T+1 或小时级刷新,无法满足业务对实时性的要求。
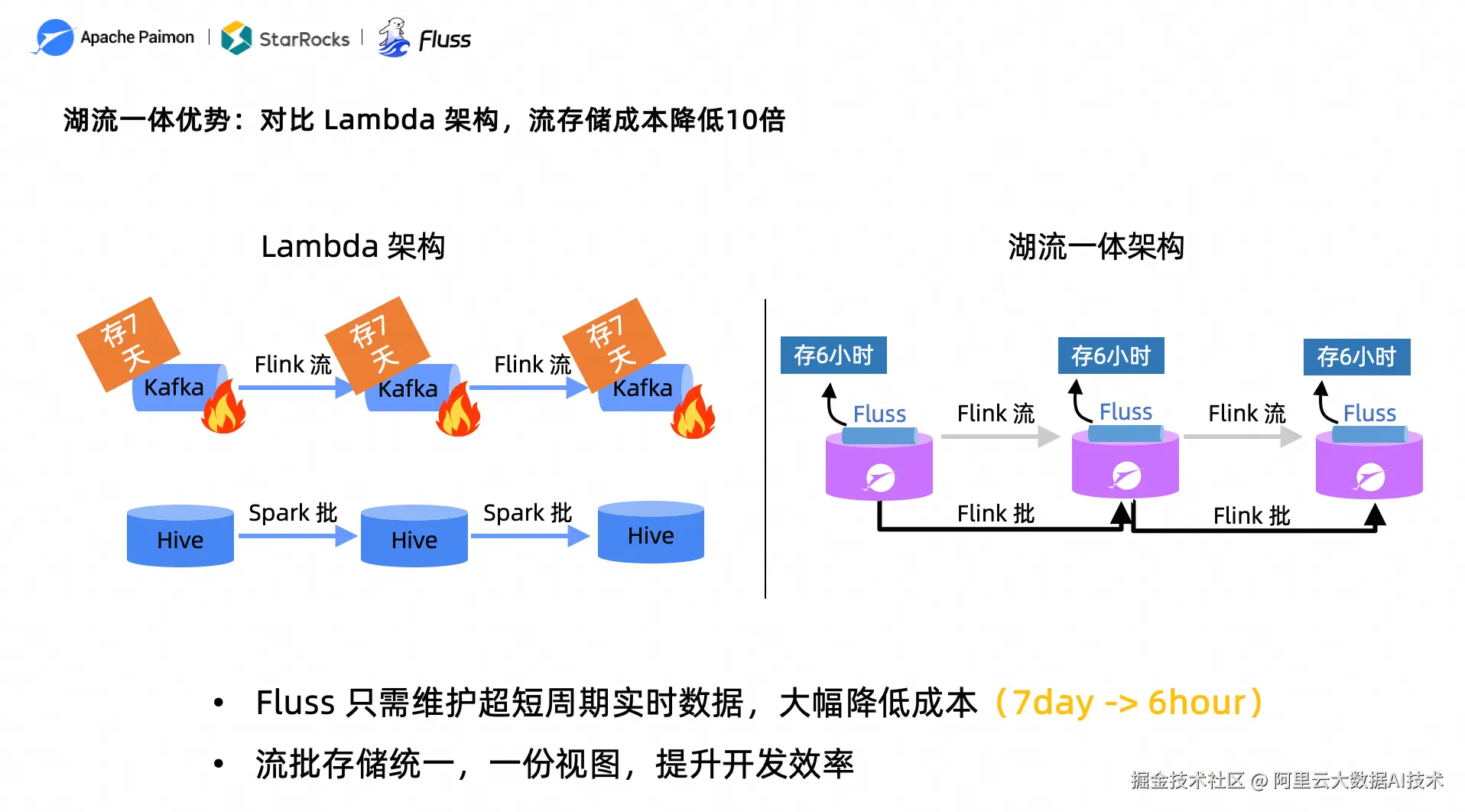
图 1:Lambda 架构与湖流一体架构对比------流存储成本降低 10 倍
2.2 纯湖仓架构的局限
湖仓架构(如 Flink + Paimon 级联加工)虽然解决了流批统一的问题,但新鲜度仍然受限。其核心原因在于 Paimon 的新鲜度绑定在 Flink Checkpoint 之上------假如 Checkpoint 设为 5 分钟,第一层湖表新鲜度为 5 分钟,第二层累加为 10 分钟,第三层达到 15 分钟。层级越多,延迟线性增长,对于需要多层加工的业务场景极不友好。
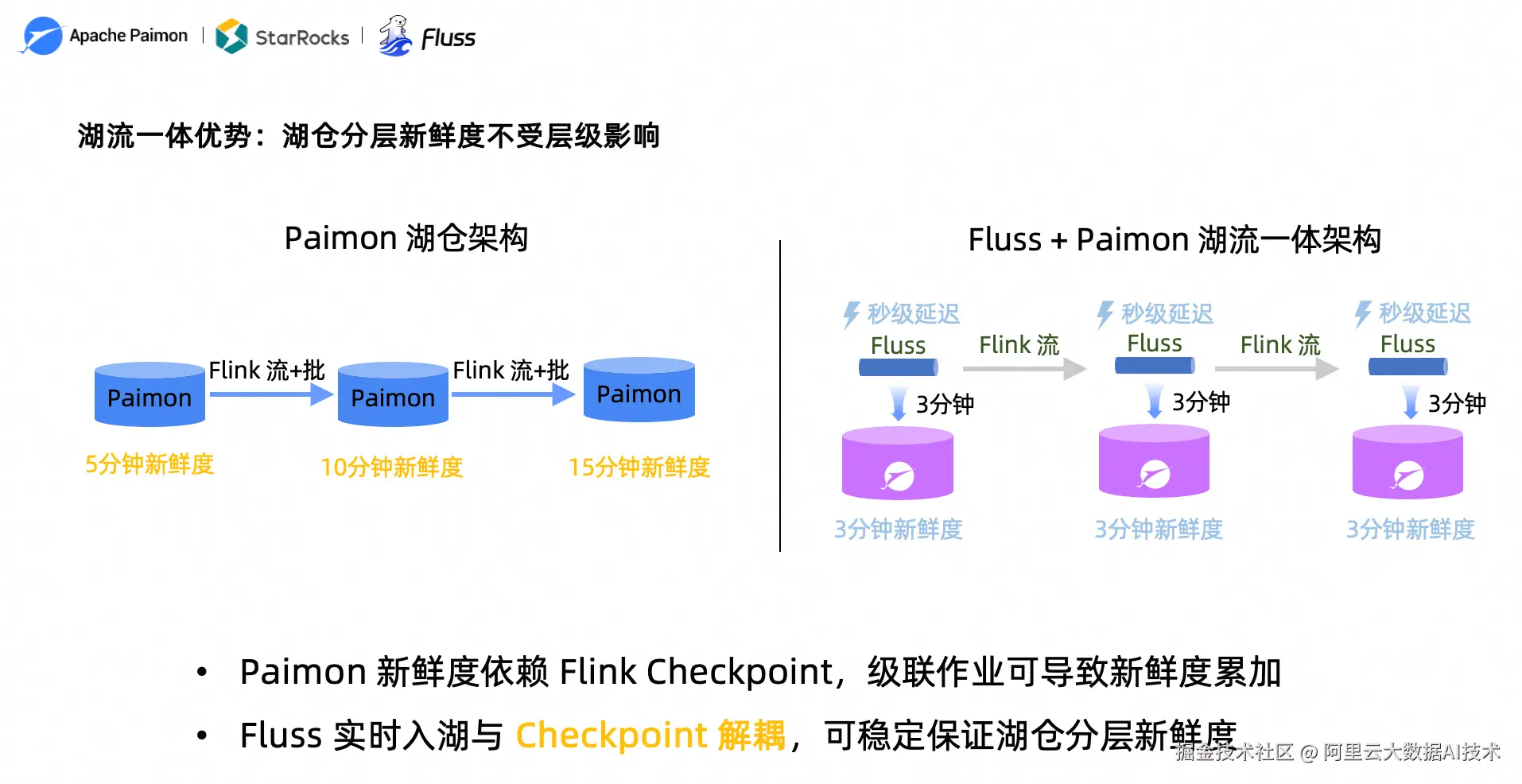
图 2:纯 Paimon 湖仓架构 vs Fluss + Paimon 湖流一体架构的新鲜度对比
3. Fluss / Paimon / Kafka 数据概念对比
下表详细对比了三者在数据模型层面的差异,这是理解 Fluss 为何比 Kafka 更适合做实时数仓的关键:
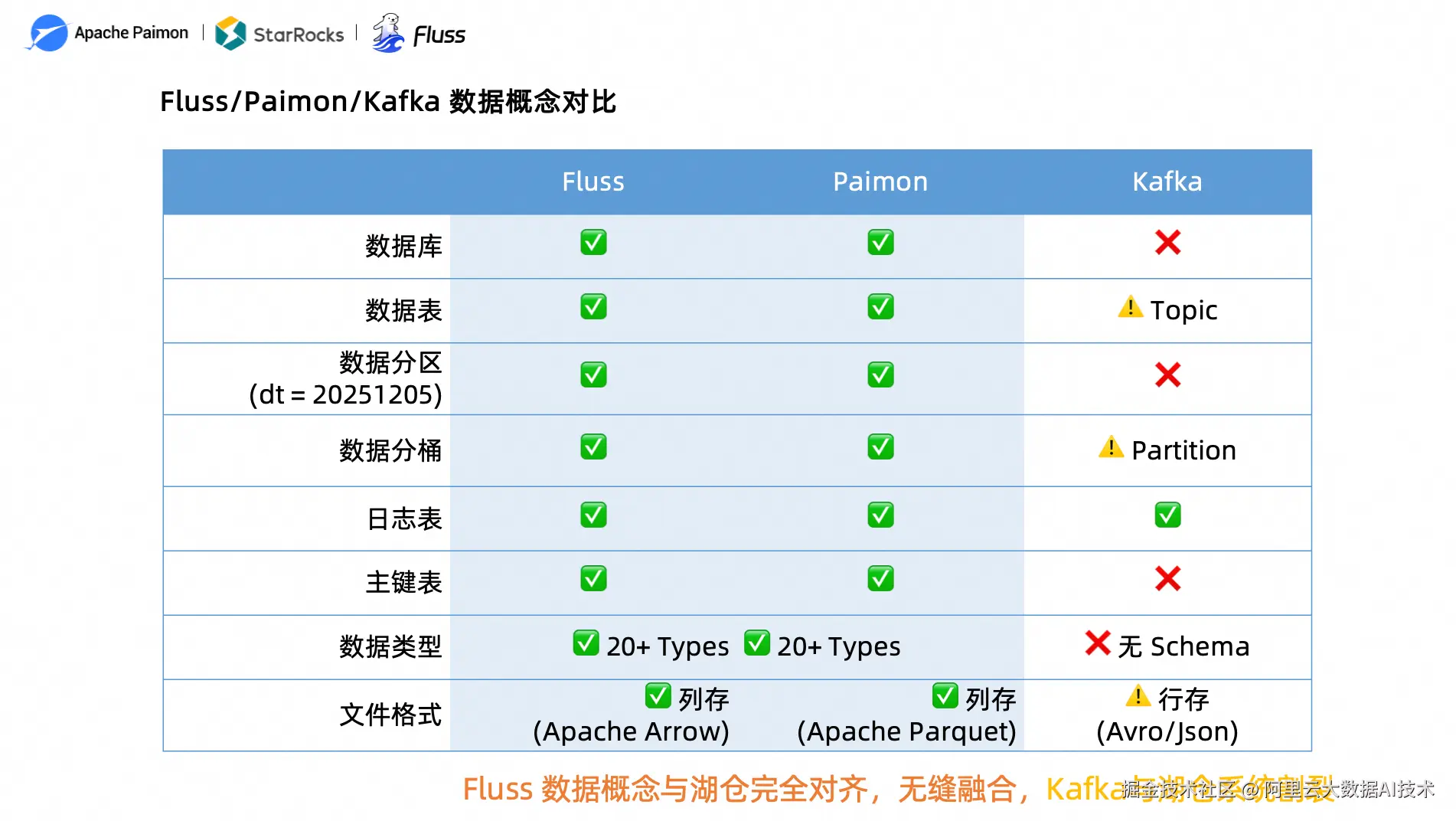 图 3: Fluss/Paimon/Kafka 数据概念对比
图 3: Fluss/Paimon/Kafka 数据概念对比
Fluss 的数据概念与湖仓完全对齐,可无缝融合;而 Kafka 与湖仓系统存在本质性割裂------无 Schema、行存、无库表分区概念,这正是实时数仓场景中 Kafka 的核心短板。
4. 湖流一体方案核心优势
4.1 流存储成本降低 10 倍
在 Lambda 架构中,Kafka 通常需要保留 7 天数据以保证回溯能力,存储成本居高不下。而在湖流一体架构中,Fluss 只需保留超短周期的实时数据(如 6 小时),超过 TTL 的数据由 Tiering Service 自动沉淀到 Paimon 湖表中。流存储从 7 天缩减到 6 小时,成本直接降低一个数量级。同时流批存储统一为一份视图,不再维护两套独立的数据链路。
4.2 湖仓分层新鲜度不受层级影响
在 Fluss + Paimon 湖流一体架构中,Flink 流式作业直接读写 Fluss,实时数据流始终保持秒级延迟。长周期数据入湖过程与 Checkpoint 解耦,每层湖表新鲜度稳定在约 3 分钟,无论分层多少层都不累加。简而言之:实时段秒级、湖仓段约 3 分钟,且新鲜度稳定不随层级增加而累加。
4.3 批查秒级新鲜度(Union Read)
Union Read 是湖流一体架构的核心查询能力。当用户发起查询时,StarRocks 同时拉取 Paimon 上的历史数据(Snapshot)和 Fluss 上的实时增量数据(从 Snapshot 对应的 log_offset 开始),在内部执行 Sort Merge 操作,合并为一份完整的结果集。这意味着一次普通的 SELECT 查询就能获得秒级新鲜度的全量数据视图,且语义为 Exactly-Once------不重不漏。
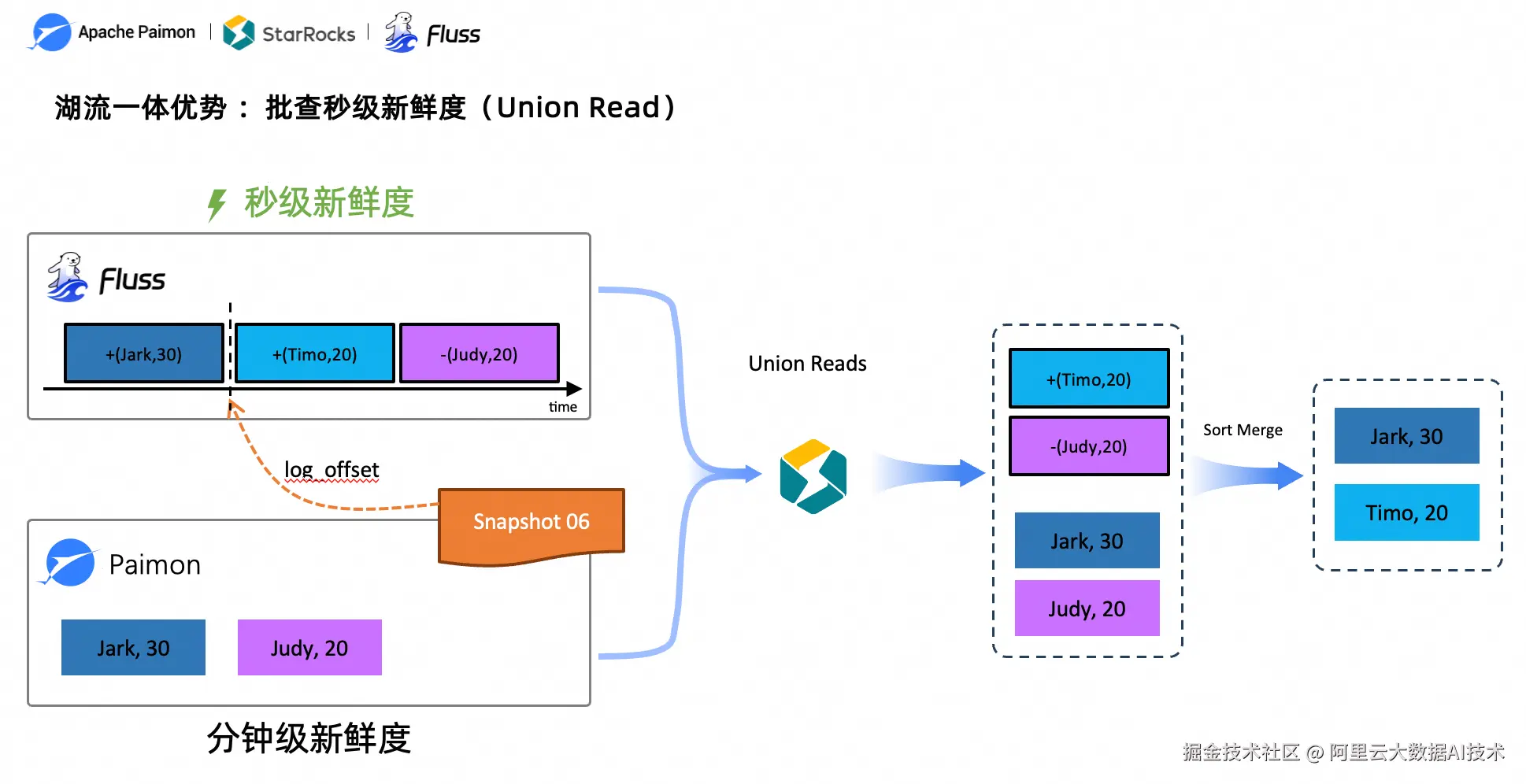
图4:Union Read 工作原理------实时数据与历史数据一次查询合并
5. 湖流一体架构总览
湖流一体架构的核心设计理念是"三个同一份":
-
数据同一份: 不是双写,而是通过 Tiering Service 自动将 Fluss 中超过 TTL 的数据沉淀到 Paimon,一份数据自动流转。
-
元数据同一份: 使用 DLF Omni Catalog 统一管理 Fluss 和 Paimon 的元数据,一套 Catalog 管理全部数据资产。
-
查询入口同一份: 全部使用 StarRocks 作为统一查询引擎,一条 SQL 即可获取实时+历史全量数据。
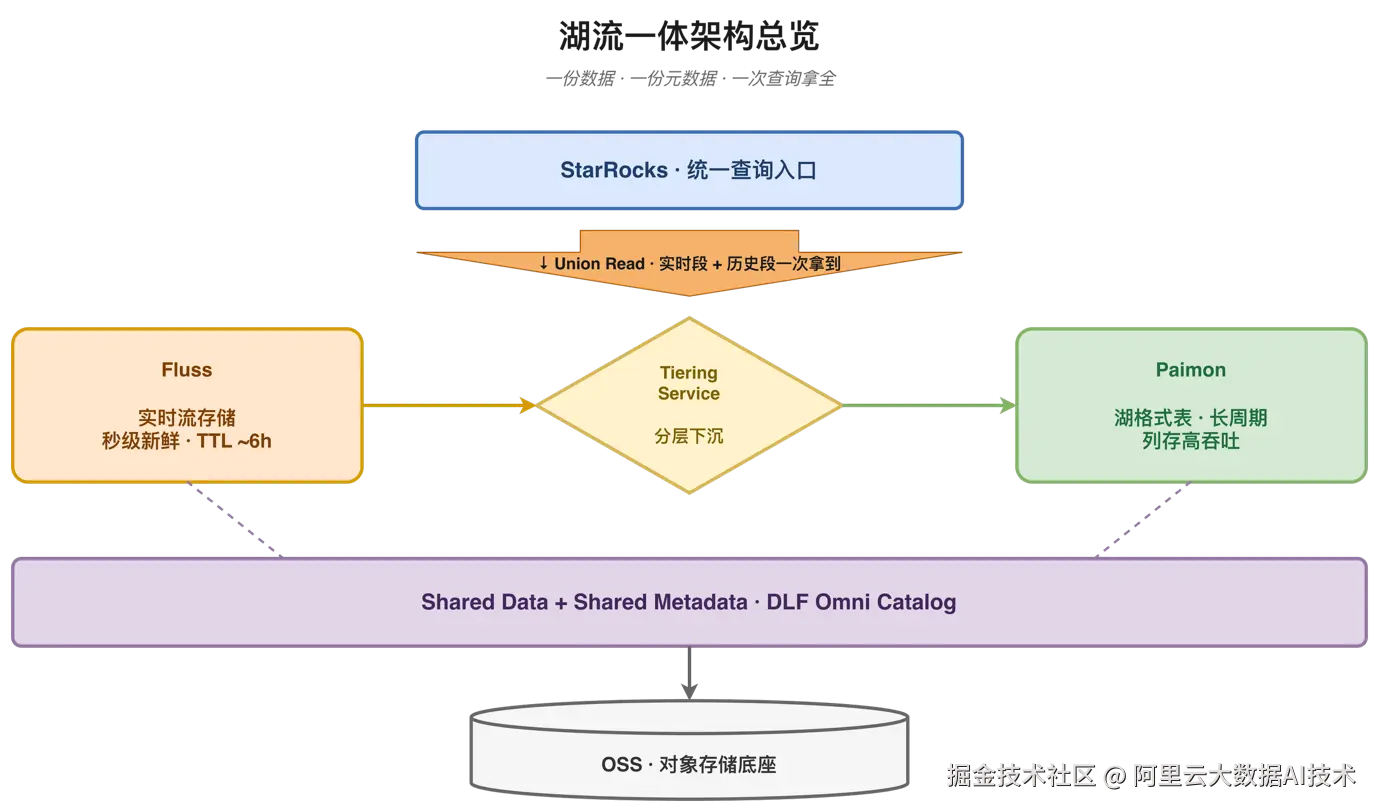
图5:湖流一体架构总览------一份数据、一份元数据、一次查询拿全
Tiering Service ------ 数据自动分层下沉: 在上述架构中,Tiering Service 是实现"数据同一份"的关键枢纽。Tiering Service 是湖流一体架构中的关键组件,本质上是一个常驻的 Flink 作业。它自动将 Fluss 中超过 TTL(如 6 小时)的数据导入 Paimon 湖表,并删除过期数据。用户无需编写 ETL 作业,只需开启配置开关即可。Fluss + Paimon 共同组成完整的数据视图:Fluss 持有秒级新鲜的实时数据,Paimon 持有长周期历史数据。
6. StarRocks 统一查询入口
StarRocks 作为湖流一体架构的统一查询入口,通过一个 Fluss Catalog 即可接入全部数据,提供三种查询姿势满足不同场景需求。
6.1 接入方式
只需一行 SQL 即可将 Fluss 接入 StarRocks:
sql
CREATE EXTERNAL CATALOG `fluss_catalog`
PROPERTIES ("type" = "fluss",
"fluss.option.client.security.sasl.mechanism" = "PLAIN",
"bootstrap.servers" = "fluss-cn-2rn4ffq4o01:9123",
"fluss.option.client.security.sasl.password" = "xxx",
"fluss.option.client.security.protocol" = "SASL",
"fluss.option.client.security.sasl.username" = "xxx"
);6.2 三种查询姿势
姿势一:默认 Union Read
直接查询表名,StarRocks 自动合并 Fluss 实时数据与 Paimon 历史数据,适用于实时大盘、实时报表等场景。
sql
SELECT user_id, COUNT(*) FROM ods.ordersWHERE dt = '20260528' GROUP BY user_id;姿势二:$lake 后缀(仅读历史数据)
在表名后加 $lake 后缀,只查询 Paimon 湖上历史数据,跳过实时段。适用于 T+1 报表、跨天回算,性能最优。
姿势三:$rt 后缀(仅读实时数据)
在表名后加 $rt 后缀,只读取 Fluss Server 端的实时数据。适用于线上排查、数据回追、实时监控场景。
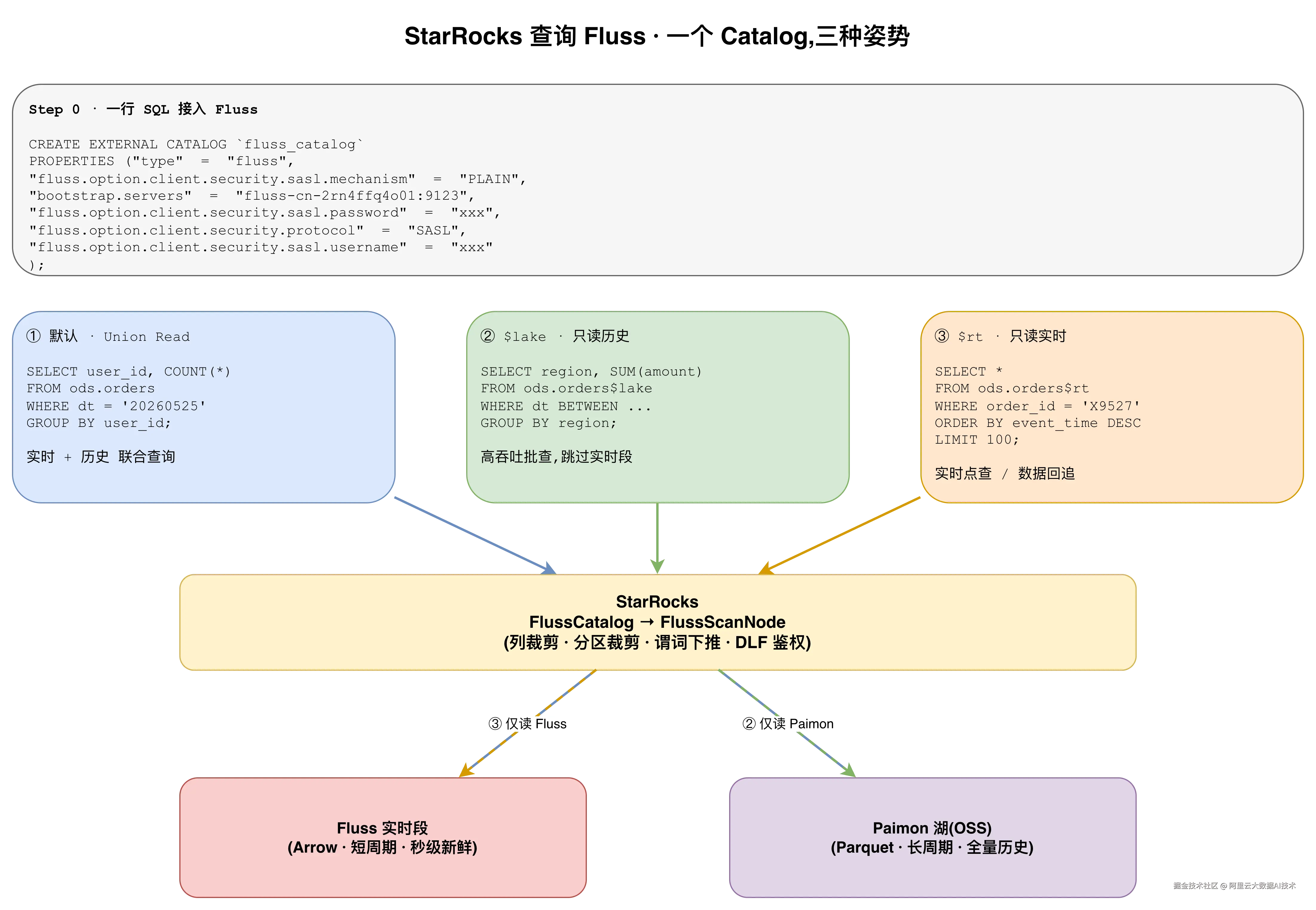
图6:StarRocks 查询 Fluss------一个 Catalog,三种查询姿势
7. 技术架构详解
StarRocks 读取 Fluss 数据时,根据表名后缀自动路由到不同的 Scan 通道:
7.1 Paimon Scan(历史段)
历史数据查询走 Native C++ 直读链路,零 JVM 开销,支持列存高吞吐、向量化执行,并可利用 DataCache 加速。数据直接从 OSS 上的 Paimon 文件读取,充分发挥 StarRocks 在湖查询上的性能优势。
7.2 Fluss Scan(实时段)
实时数据查询通过 JNI Bridge 调用 Fluss Java Client,复用官方 Fluss 协议,通过 Arrow 格式跨边界传递数据。虽然当前仍有 JVM 开销,但 Arrow 列式传输已显著减少行列转换损耗。
7.3 Union Read Merge
当用户执行默认查询时,StarRocks 同时读取 Paimon Snapshot N 和 Fluss 中 offset > N.commit 的增量数据,按主键合并,保证 Exactly-Once 语义。这套机制实现了真正的"一次查询,实时+历史全拿到"。
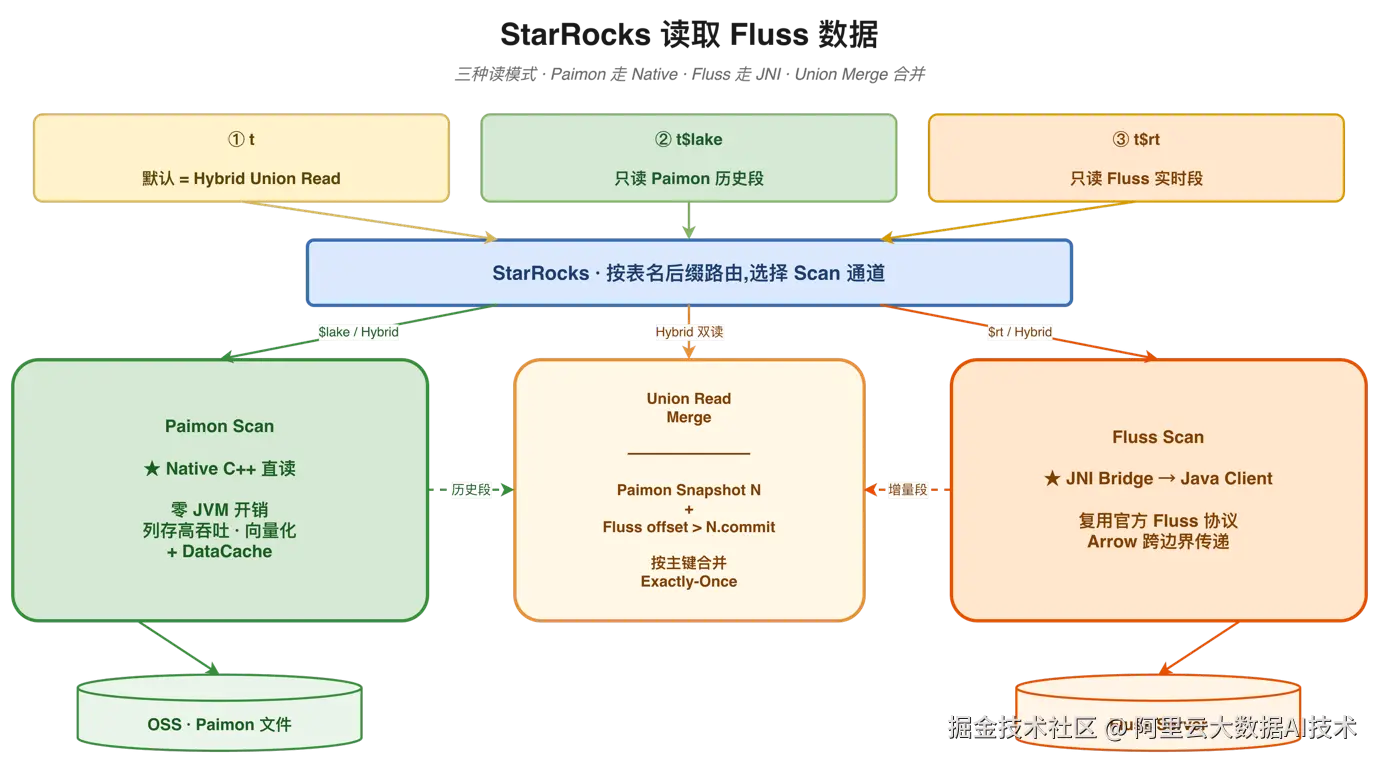
图7:StarRocks 读取 Fluss 数据技术架构------Paimon 走 Native,Fluss 走 JNI,Union Merge 合并
8. 未来规划
StarRocks x Fluss 的未来演进方向围绕"读得最快、读得最稳"两个目标展开:
8.1 Union Read 2.0:跳过 Sort Merge
当前 Union Read 在处理主键大表时需要 Sort Merge 合并,未来计划支持 Fluss 的 Delete Vector,通过 Bitmap 标记删除行并跳过,避免 Sort Merge 过程,显著提升端到端性能。
8.2 优化器看懂 Fluss
接入行数、NDV、Min/Max 等统计信息,支持元数据短路优化 COUNT 查询、Limit 下推、Time Travel 等能力,让优化器精准选择最优执行策略。
8.3 Native 全链路
将实时段也优化为 C++ 直读,通过 Fluss Arrow 做零拷贝传输,并接入 DataCache、谓词下推到 Fluss Server 等能力。最终实现 Snapshot 和 Log Split 统一一个 Native Scanner,消除 JVM 占用。

图8:StarRocks x Fluss 未来规划------Union Read 2.0、优化器增强、Native 全链路
9. 阿里云 EMR Serverless StarRocks 对 Fluss 的适配与增强
阿里云 EMR Serverless StarRocks 对 Fluss 进行了全面的原生适配,提供了从 Catalog 注册、数据读取、分区裁剪到 Union Read 的完整能力支持,并在每个环节叠加商业版独有的性能增强。下表列出了商业版在湖流一体查询场景下的关键能力与增强点:
| 能力 | 说明 | 商业版增强 |
|---|---|---|
| Fluss Catalog | 通过 CREATE EXTERNAL CATALOG 注册 Fluss 数据源,SQL 直查 |
预置 Catalog 模板,一键配置 |
| Native 读取 Paimon 数据 | 对 Fluss 湖侧(Paimon 格式)数据实现原生 C++ 读取,绕过 JNI 开销 | Stella 自研算子,性能领先开源 |
| 分区裁剪 | 按分区条件过滤 Fluss 表,避免全表扫描 | 与内表一致的裁剪优化 |
| Union Read | 一条 SQL 自动合并 Fluss 实时数据 + Paimon 历史数据 | 全托管,无需运维 Tiering Service |
| Native SDK 接入 | StarRocks 通过 Fluss Native SDK 直连,替代 JNI 调用链路 | 进一步降低读取开销,提升吞吐 |
| 读取性能持续优化 | 缩小与内表查询性能差距,目标 1.5x 以内 | 湖流一体场景下查询性能对标内表 |
典型使用方式
sql
-- 1. 创建 Fluss Catalog
CREATE EXTERNAL CATALOG fluss_catalog
PROPERTIES (
"type" = "fluss",
"fluss.bootstrap.servers" = "<fluss-bootstrap-servers>"
);
-- 2. 直接查询:Union Read 自动合并实时 + 历史数据
SELECT region, COUNT(*) as event_count, AVG(speed) as avg_speed
FROM fluss_catalog.fluss_db.enriched_vehicle_events
WHERE event_time >= NOW() - INTERVAL 1 HOUR
GROUP BY region;无需 Flink/Spark ETL 作业,无需手动 UNION 两张表,一条 SQL 即可查到秒级新鲜度的完整数据。
9.1 Stella 引擎独有优化
EMR Serverless StarRocks 使用自研 Stella 引擎,在 Fluss 湖流一体查询场景下有多项开源不具备的优化:
-
Native Reader 性能优化: 对 Fluss Lake Split 实现原生 C++ 读取,绕过 JNI 调用开销;向量化批处理 + 列式裁剪,大幅减少反序列化开销;相比开源 JNI 方式,查询性能提升显著。
-
DataCache 统一管理: Fluss 外表查询与 StarRocks 内表共享统一 DataCache 层;热数据自动缓存到本地 SSD,重复查询直接命中缓存;避免了内表与外表缓存空间冲突的问题(开源版需手动配置)。
-
查询优化器增强: Fluss 表与 StarRocks 内表 Join 时,自动选择最优 Join 策略;支持跨 Catalog 的全局查询优化(Fluss + Paimon + "内表"混合查询)。
9.2 场景示例:车联网实时安全大屏
以车联网实时安全大屏场景为例,Fluss + 阿里云 EMR Serverless StarRocks 在端到端实时分析中的落地能力。
业务需求:
-
车辆实时事件数据(GPS、速度、报警)需秒级入湖
-
实时大屏展示车队安全态势(超速告警、区域分布、趋势变化)
-
历史数据支持回溯分析(过去 7 天/30 天趋势对比)
架构方案:
-
Flink 实时消费车辆事件流 → 关联车辆档案维表 → 写入 Fluss 宽表
-
Fluss 配置
table.datalake.freshness = 1min,自动 Tiering 到 Paimon -
StarRocks 通过 Fluss Catalog 的 Union Read,一条 SQL 查全量数据
-
QuickBI 连接 StarRocks,秒级刷新实时大屏
商业版优势体现:
-
Flink / Fluss / StarRocks 全链路 Serverless,无需管理任何基础设施
-
DataCache 加速高频查询,大屏刷新延迟 < 1s
-
RAM 统一权限管理,数据安全合规
9.3 与传统实时数仓方案对比
对于正在选型实时数仓方案(Kafka + Flink ETL + "数据湖" + StarRocks)的用户,以下从架构复杂度、数据存储、ETL 链路、查询实时性、数据一致性、运维成本、存储成本七个维度进行对比:
| 维度 | Kafka + Flink ETL + 数据湖 + StarRocks | Fluss + EMR Serverless StarRocks |
|---|---|---|
| 架构复杂度 | 4 套系统,各自运维 | 2 套系统(Fluss + StarRocks),全托管 |
| 数据存储 | Kafka 一份 + 数据湖一份,双写 | Fluss 一份数据,流和湖是两种视图 |
| ETL 链路 | 需要 Flink 作业将 Kafka 数据导入数据湖 | Fluss 内置 Tiering Service,自动同步 |
| 查询实时性 | 分钟级(取决于 ETL 批次间隔) | 秒级(Union Read 直查 Fluss 实时层) |
| 数据一致性 | 需对齐 Kafka 与数据湖的数据口径 | 原生一致,同一份数据 |
| 运维成本 | 高(多系统协调、故障定位困难) | 低(全托管 + AI Agent 智能运维) |
| 存储成本 | 高(数据双写) | 低(数据单写,Tiering 文件级转换) |
9.4 商业版核心价值总结
EMR Serverless StarRocks 商业版在 Fluss 湖流一体场景下的核心差异化价值:
-
全托管免运维: Fluss + StarRocks 全链路 Serverless,一键开通即用。
-
Stella 引擎独有优化: Native Reader + DataCache "统一管理" + "跨 Catalog 查询优化",湖流一体查询性能对标内表。
-
端到端一站式方案: 从数据接入到可视化(Flink → Fluss → Paimon → StarRocks → BI),全链路阿里云一站式交付,RAM 统一权限满足企业合规要求。
-
TCO "总拥有成本"更优: 数据单写 + Serverless 弹性(按需付费,空闲零成本) + DataCache "缓存加速",TCO 显著低于 Kafka + Flink ETL + "数据湖" + StarRocks 自建方案。
对于正在评估实时数仓建设方案、寻找 Kafka 替代方案(Kafka Alternative)、或希望将传统 Lambda 架构迁移到湖流一体 Lakehouse 架构的企业用户,阿里云 EMR Serverless StarRocks + Fluss + Paimon 湖流一体方案提供了一条开箱即用、成本可控、性能领先的落地路径。全链路 Serverless 免运维、Stella 引擎性能加持、以及 Fluss 原生流湖融合能力,使其成为替代传统 Kafka + Flink + "数据湖"系统的最优解之一。