本文作者:大模型善后工程师-K 叔,TRAE 核心用户
前言
TRAE Work 不是"输入主题就吐出完美 PPT"的魔法按钮。它真正的价值,是把散落在文章整理、页面设计、素材生成、导出验收里的繁琐工作,放进一条能持续迭代的链路里,不过前提是你先把"怎么才算做好"讲清楚。
过去我做 PPT,一直抱着一个朴素的想法:只要 AI 能把页面生成出来,后面的事就轻松了。真正多做几轮之后才发现完全不是这样。
这篇文章想聊的不是"怎么写一句万能 Prompt",而是记录一次具体经验:用 TRAE Work 做 PPT 时,我是怎么先把"怎么才算做好"定义清楚,再让工具一点点往前推进的。
全程我会穿插一个真实例子:把 OpenAI 的两篇文章整理成一次社区分享。
看完本篇文章你可以了解到:
- 为什么难的不是"生成 PPT",而是"生成之后"
- 长文如何拆成"每页一个判断"
- 我实际跑通的五步链路(可复用方法论)
- 视觉方向:先定义"不要什么"
- image-gen 只做材料,不替你写事实
- 那些肉眼一次看不出的小问题
- 预览与验收:最后一段路
- 一张可以随手复用的检查清单
一、为什么难的不是"生成 PPT"
PPT 是个特殊物种。
它不是一篇文章,也不是一张海报。文章写清楚就能读,海报好看就能发,但 PPT 往往还要能讲、能改、能导出、能被批注,打开后文字最好还能编辑。
所以很多问题不是在生成之前出现,而是在生成之后才慢慢冒出来:
-
封面第一眼不够抓人
-
页面看起来像网页截图
-
标题读起来不像正常人会说的话
-
背景纹理压住了文字
-
文字框比文字本身宽出一大块,选中后才发现对象和视觉并不一致
这些问题单独看都不大,叠在一起,就会让一份 PPT 卡在"差不多有了 "和 "可以交付 "之间。
适用边界:
这套方法更适合对外分享、需要反复修改、最后要交付 PPTX 的场景。如果只是内部讨论草稿,没必要每步跑满,可以先保留 memo 和 slide plan,等内容确实值得做成正式 PPT,再补设计、image-gen 和验收流程。
memo 指的是你在正式做 PPT 之前,先整理出来的一份"想法备忘 / 内容纲要"文档,简单可以理解为备忘录。
具体实战
我读了 OpenAI 的两篇文章,一篇讲 Harness Engineering ,一篇讲开源的 Codex 编排工具 Symphony 。单独看都是技术文章,但放在一起读,能感受到背后的递进关系:先让单个 Agent 在工程环境里跑稳,再面对多个 session 同时运行、人开始盯不过来的问题。
于是我把这份读后感整理成一套社区分享 PPT。这个例子刚好也可以说明:一份好 PPT 不是把两篇文章翻译成页面,而是先把" 我读完以后真正想讲什么 "抽出来。
二、一开始也以为,难的是生成 PPT
很多人第一次用 AI 做 PPT,大概率都从一句话开始:
帮我根据这篇文章做一份分享 PPT。这句话可以作为入口,但只给到这里,后面通常很难收。因为 PPT 不是把内容放进页面就结束,它还涉及一连串判断:
-
这套内容是给谁看的?
-
每一页到底想让观众记住什么?
-
哪些是事实,哪些只是我的理解?
-
这套视觉应该像分享材料,还是像产品后台、网页组件、信息图?
-
最终怎么判断它已经可以交付?
这些问题不先说清楚,AI 会按自己最容易理解的方式去做:例如生成一套很规整的页面,每页有卡片、标题、小点、状态条,看起来完整,但放到分享场景里就觉得不对:像网页截图,像后台页面,像设计 demo,就是不像一套能站在台上讲的 PPT。
这不是工具的问题,是我们没有先把判断标准讲出来。所以我后来会先做两件事:
先分析,不生成:用 kz-article-deep-analysis 技能分别拆两篇文章的核心议题、核心主张、论证骨架和认知增量,尤其看两篇之间有没有递进关系。
再整理 memo:基于分析结果做二次组织,得到的不是摘要拼接,而是带着判断的 memo。
这份 memo 不需要复杂,但至少要回答:
-
两篇文章各自在回应什么问题?
-
这次分享的主线是什么?
-
读者/听众是谁?
-
文章里哪些判断必须保留?
-
哪些说法有事实边界?
-
这套 PPT 最后要输出什么文件和预览?
拿这次 Codex Symphony 的分享来说,前面先确认了一条主线:不是把 Harness、Symphony、Loop Engineering 并排解释一遍,而是讲一个递进过程。
先有 Harness,让单个 Agent 在项目里跑稳。等 session 多起来,人开始盯不过来,于是才自然出现 Symphony 这种调度实践。
主线一旦确认,后面的页面就不再是随便摆内容:封面为什么讲"人站的位置变了"、第 9 页为什么不能写成"官方定义"、每页标题为什么要短一点,这些判断都有了来源。
这也是 "读后感做 PPT" 和 "文章摘要做 PPT"的差别。
摘要会拆成"第一篇讲什么、第二篇讲什么、最后总结一下",能做但很平,真正适合分享的,是把读完后形成的判断讲出来。
这次的判断就是:
AI 编程的新词不是凭空冒出来的。
先有 Harness 解决"Agent 怎么跑稳"。
再有 Symphony 回应"Agent 多起来以后,人怎么盯得住"。
真正变化的,不只是工具,而是人站的位置。所以我现在更习惯把第一步写成:
bash
请先不要生成 PPT。
先使用 $kz-article-deep-analysis 分别分析这两篇文章。($kz-article-deep-analysis这个是我自己的skill)
每篇都提取核心议题、核心主张、论证骨架、认知增量和边界条件。
然后基于两份分析结果,整理一份 memo、主线和每页要表达的核心判断。
输出后停住,等我确认。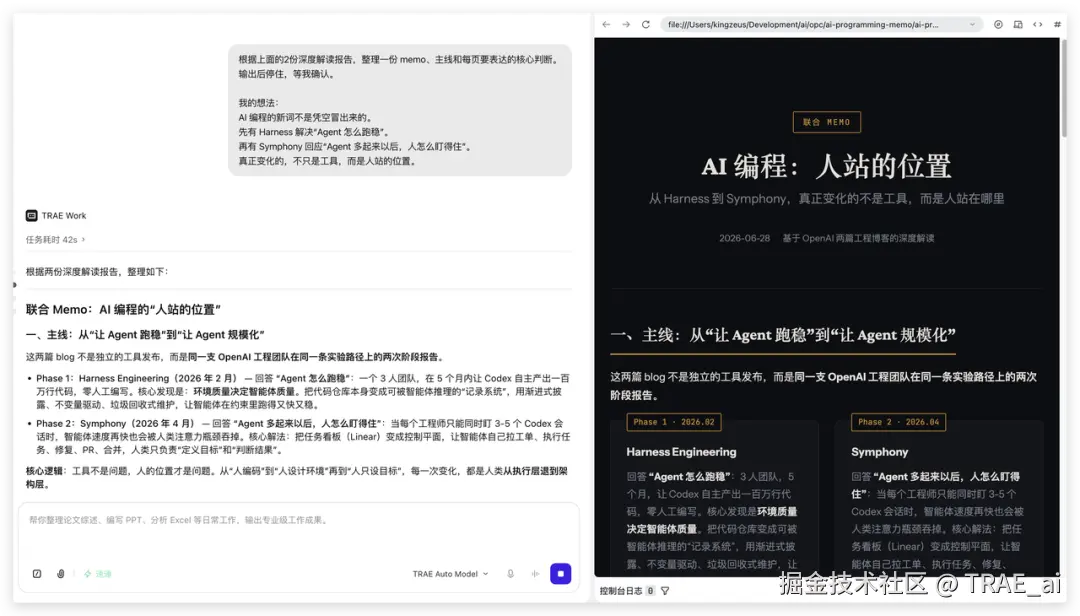
这个"停顿"很重要。它让人先把方向看一遍,也让后面的修改不至于变成无休止的"再高级一点"、"再好看一点"。
这里还有一个小技巧:让 AI 把 memo 保存成文档,而不是在对话里临时说一版。
文档化以后,你和 AI 的沟通就有了固定锚点,可以直接围绕 memo.md 来改:这句是不是主线、哪页多讲了一个观点、某个判断有没有越过事实边界。
这比生成一整套 PPT 后再回头改要轻很多。
PPT 一旦生成,问题会混在一起:可能主线不对、标题不自然、视觉不舒服、文本框太宽。
你说"整体调一下",AI 很难判断该改内容、改设计还是改文件。
但停在 memo 阶段,修改成本就低得多。

三、长文要先变成"每页一个判断"
文章和 PPT 最大的区别不是字数,而是观看方式。文章可以慢慢铺垫,分享型 PPT 不行,观众每页停留时间很短,一页塞三个观点,讲的人累,听的人散。
所以我会先做 slide plan,不追求漂亮,先把每页功能说清楚:
rust
Slide 03
Claim: AI 编程的痛点在往后移。
Proof object: Harness -> sessions -> supervision overload -> Symphony。
Layout: process sequence。这里最有用的是 Claim。它不是标题,也不是文案,而是这一页必须讲清楚的那句话。先有这句话,标题和设计才有依附的东西。
这次 PPT 改过很多标题。早期偏概念:例如"认知递进""模式变化""官方边界",在文章里能解释,放到标题上就太重。后来改成更像现场会说的话:
偏概念的旧标题
-
认知递进
-
模式变化
-
官方边界
像人话的新标题
-
AI 新词不是凭空冒出来的
-
痛点在往后移
-
session 多了,人盯不过来
-
关系可以这样讲
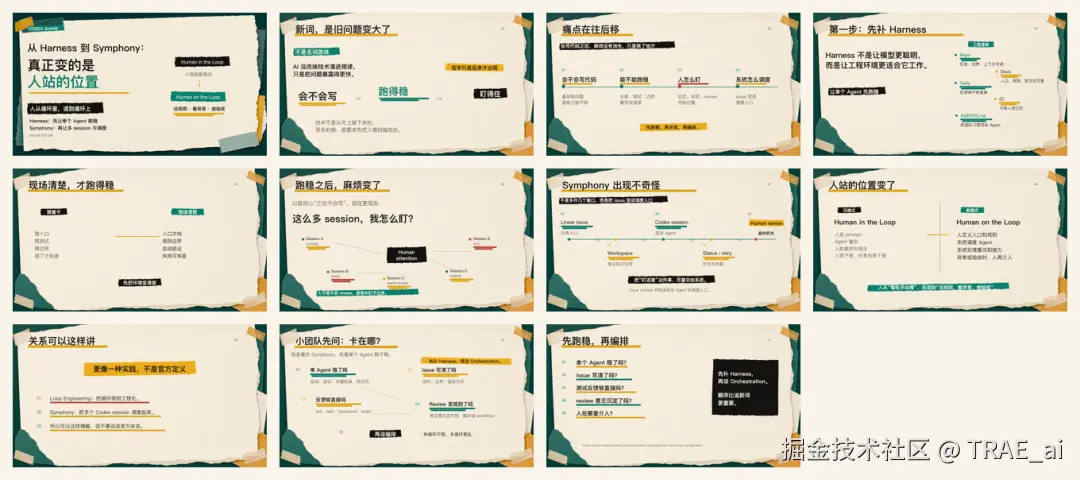
这套读后感 PPT 最后拆成了 11 页 ,是按读后的认知顺序来拆,而不是按两篇文章的目录:
vbnet
01 封面:从 Harness 到 Symphony,真正变的是人站的位置
02 Hook:AI 没改掉技术演进规律,只是把问题暴露得更快
03 递进:AI 编程的痛点在往后移
04 Harness:第一阶段不是调度,而是先让 Agent 跑稳
05 现场:项目现场越清楚,单个 Agent 越容易跑稳
06 新瓶颈:Agent 跑稳后,瓶颈从写代码转向盯 session
07 Symphony:session 多起来之后,调度实践就变得自然
08 模式变化:真正变的是人站的位置
09 边界:可以用 Loop Engineering 理解,但不能说成官方定义
10 给小团队:别急着抄 Symphony,先看自己卡在哪一层
11 收束:先补 Harness,再谈 Orchestration判断标题好坏有个简单办法: 把标题单独读一遍。 如果这句话我不会在现场说出来,那它大概率就不该放在页面最上面。再短一点,再直一点,少一点概念包装。
四、实际跑通的五步链路
与其复述每一条 prompt,我更想留下几个关键节点:下次再做类似 PPT,至少要守住这些地方。
第一步:深度解读 + memo
先把两篇文章各自的核心议题、核心主张和边界拆出来,再合并成 memo.md。要反复和 AI 对齐,直到"这套分享到底讲什么"能一句话说清。
第二步:memo 拆成 slide plan
每页只保留一个 claim,写清对应的 proof object。先不追求文案漂亮,重点确认每页有没有存在的必要,以及要让观众记住什么。
第三步:写 design brief
先写清楚"不要像什么",再写希望接近什么效果。比如:不要网页截图感、不要 dashboard、不要把事实文字拷进图片里。
brief 写清楚,后面生成页面才不容易跑偏。
第四步:用 kz-design 生成 PPTX 和预览
这个 kz-design 是我自己设计的 PPT skill
这一步输入的不再是"帮我做个 PPT",而是已确认的 memo.md、slide plan 和 design brief。
$kz-design 负责把内容翻译成 deck:固定 16:9 画布、可编辑 PPTX、页面节奏、字体层级、图形关系、无文字背景资产、逐页预览和 contact sheet。
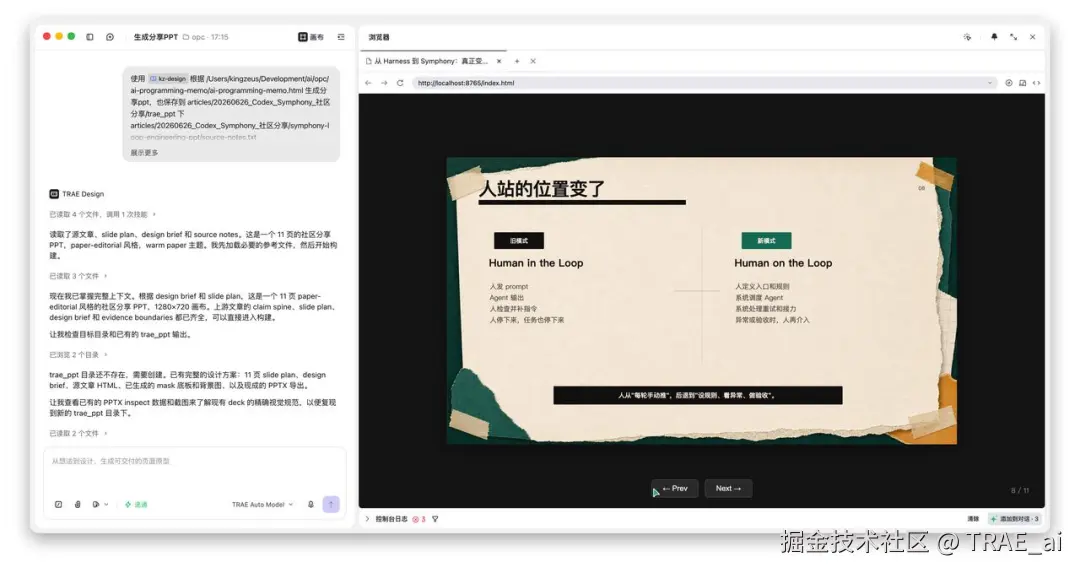
它不应该重新猜文章逻辑,也不应该把个人理解改成官方定义。
PPTX 只是交付文件,逐页截图和 contact sheet 才是验收工具,每次大改后都要重新看整套节奏,而不是只盯刚改的那一页。
第五步:根据批注逐项修 + 清理文件
反馈要拆成可执行的小问题:标题是否像人话、文字框是不是太宽、mask 有没有跟着文字重算、背景安全区有没有被占用、旧文案有没有残留。
不要只说"帮我整体优化一下"。
最后做一次文件清理:多轮 image-gen、导出、预览后目录里容易留下中间文件,明确最终保留哪些 PPTX、预览图和可复用资产,否则下次回头很容易分不清哪个才是最终版。
五、视觉目标 ≠ "高级点"
做 PPT 时最容易给 AI 的视觉要求是:
做得高级一点,有科技感,适合社区分享。这句话听起来没问题,但很难执行。
因为"高级 "有太多种理解,AI 很可能走向一套常见科技风:蓝紫渐变、玻璃卡片、等距组件、状态点、仪表盘布局,这些不一定难看,但会把页面带向网页、产品 UI、后台截图。
这次最有帮助的反馈,反而是一个反向判断:"整体风格太像网页截图了,不像 PPT",一句话就把问题说清了。
后面我不再只写"请帮我优化的更好看",而是把 design brief 写得更具体:
-
不要等距卡片
-
不要按钮感很强的标签
-
不要 dashboard 式页面
-
不要把每页都做成产品 UI
-
希望更像社区分享里的纸张笔记、批注、撕边标签和现场讲解
设计往往不是先定义"我要什么",而是先定义"我不要什么"。反例越清楚,AI 越容易避开默认模板。
放到这套读后感 PPT 里:它不是 OpenAI 官方发布会,也不是产品 UI 演示,所以不需要假装有一堆系统截图、状态点和控制台组件。
更合适的方向,是做成一份社区分享里的纸面笔记:暖色纸张、黑色文字、撕边标签、少量批注,用流程图和对比页把递进关系讲清楚。
⚠️注意 :不使用 OpenAI logo,不伪造产品截图。因为这套 PPT 讲的是我的读后理解,不是官方物料。视觉可以有质感,但事实层要干净。
别忘了"背景安全区"
用 image-gen 做背景时很容易被质感吸引:纸张、胶带、撕边、色块都好看。
但真正放文字时才发现:好看的背景不等于可用的背景。
右上角有胶带、底部有撕纸边、左下角有大色块,这些地方就不能随便放正文。
所以我会让 design brief 明确写 safe area,哪怕不精确也要先说清楚:
常规内容尽量放在中间纸面区域。
底部不要贴得太低。
左下角有装饰色块时,正文尽量避开。
页码和来源信息不要压到纹理边缘。六、image-gen 适合做材料,不适合替你写事实
这次我对 image-gen(AI 图片生成) 的看法也变了:它很适合帮 PPT 增加质感,但不适合直接承担所有内容。
分工原则:图片负责气质,文字负责事实。
凡是有事实、有标题、有术语、有中文说明的地方,都尽量让文字留在 PPT 的可编辑文本层里。
image-gen 适合做
-
无文字纸张背景
-
低对比工作流纹理
-
撕边标签
-
胶带、纸条、印刷颗粒等材料
不让它直接画进去
-
标题
-
页码
-
引用来源
-
关键术语
原因很现实:中文可能生成错、文案后面大概率会改、别人打开还要挪位置。事实文字一旦拷进图片,检查和修改都会变麻烦。
这次比较有收获的一步,是把一张撕边标签处理成白色 alpha mask。有了这个 mask,后面需要黑色、绿色、黄色标签时,就不用每次重新生成图片,用代码着色,再按文字长度做九宫格缩放,就能在不同页面复用。

这一步生成的不是最终页面,而是一批无文字底板素材:纹理、标签、badge、面板和高亮条。后面按颜色和尺寸复用,文字仍留在 PPT 文本层。
这个细节看起来工程化,但对 PPT 很有用:一套 PPT 里很多视觉元素不止出现一次,标签、底板、提示条、强调块如果每页手工调,后面会越来越乱。
把它做成可复用资产,风格更稳定,修改也更轻松。
这也是 TRAE Work 适合接住的一段工作,它不只帮你"想一个设计",还能把设计里可重复的部分变成一套能继续用的资产。
七、有些小问题,肉眼一次看不出来
这次有个很小但典型的问题:有些文字标签看起来上下边距不舒服 。第一眼以为是背景图或底图没做好,后来发现真正影响视觉的是文字框本身:文字框比实际文字宽很多,右边就显得空,宽度估算太紧,到了 PowerPoint 里又可能意外换行。
这种问题很微妙:单看导出图片只觉得"哪里怪怪的",一旦选中对象,才能看到文本框和视觉对象并不匹配。
所以我后来会把文字框也纳入检查:
-
单行文字有没有意外换行
-
短文字的文本框有没有过宽
-
背景底纹有没有跟着文字框重新计算
-
上下左右留白是不是大致均衡
-
文字是不是仍然可以编辑
很多 PPT 看起来不够精致,不一定是设计方向错了,而是这些小关系没有对齐。
比如封面右侧的 Human on the Loop 标签,一开始背景宽度偏大、整个标签显得松;解决办法不是简单缩图,而是重新计算文字框宽度,再按文字框和留白重新生成 mask。
如果只让 AI"再美化一下",它不一定知道你在说什么。把问题拆成"文字框宽度 "、"mask 尺寸 "、"padding 是否均衡",反而更容易改到位。
八、最后一段路,靠预览和验收
PPT 做完后,我现在不敢只打开第一页看一眼就说完成。
因为改 PPT 有个常见问题:你盯着刚改的那一页,就很容易忘掉整套节奏。
封面好看了,中间某页突然变挤;第 9 页文案改顺了,旧文案还残留在隐藏对象里;某个标签宽度调好了,又导致另一页换行。
所以我会让工具做四类检查:
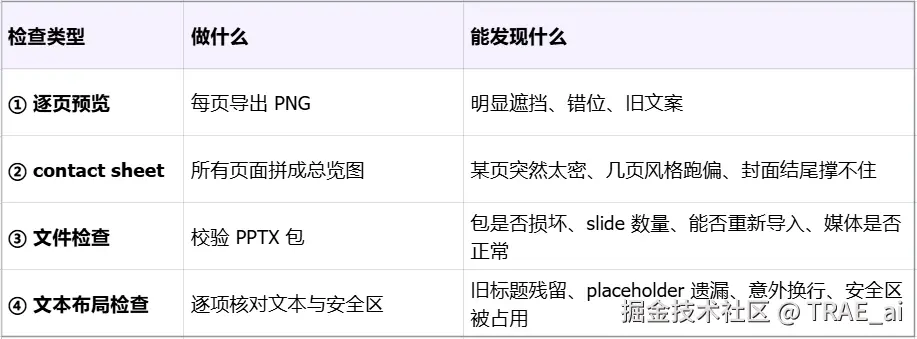
这些检查并不复杂,却很容易被忽略。如果目标是交付一个文件而不是看一张截图,这些检查就很值得: 它们能把"凭感觉还行"的地方,变成可以复核的结果。
那套读后感 PPT 也是这样收尾的:每次大改后重新导出 PPTX,渲染成 11 张预览拼成 contact sheet,一眼就能看出封面撑不撑得住、第 9 页边界说明是不是太硬、后面 checklist 页是不是突然像表格。
尤其是第 9 页,最初标题是"别说成官方定义",意思没错但读起来生硬。后来改成"关系可以这样讲",下面补一句"更像一种实践,不是官方定义"。
这是 PPT 里很常见的平衡:标题要像人话,但边界不能丢。
九、我现在会怎么给 TRAE Work 派任务
如果现在重新做一套 PPT,我不会把任务写成一句完整的大 Prompt,而是拆成几轮,每轮只解决一类问题。
第一轮 · 先分析、再整理,不生成 PPT
css
请先不要生成 PPT。
先使用 $kz-article-deep-analysis 分别分析这两篇文章。
每篇都提取核心议题、核心主张、论证骨架、认知增量和边界条件。
再基于两份分析结果整理一份读后感 memo。
不要逐段摘要,重点提取它们之间的递进关系。
再整理 claim spine 和 10 页左右的 slide plan。
每页只保留一个 claim,并写出 proof object。
输出后停住,等我确认。第二轮 · 写设计 brief
diff
基于已确认的 slide plan,写 design brief。
重点写清楚:
- 这套 PPT 不要像什么
- 视觉方向和参考对象
- 背景安全区
- 哪些文字必须可编辑
- 哪些元素可以用 image-gen 生成
- 哪些说法只是读后理解,不能写成官方定义第三轮 · 交给 kz-design 生成和导出
bash
使用 $kz-design,基于已确认的 memo、slide plan 和 design brief 生成可编辑 PPTX。
不要重新猜文章逻辑,不要把个人理解写成官方定义。
文字保留为 PPT 文本层。
图片只做背景、材质和装饰。
每页导出 PNG 预览。
生成 contact sheet。
记录验证结果。第四轮 · 根据批注逐项改
根据我标注的问题逐项修改。
每次修改后重新导出 PPTX、预览图和 contact sheet。
检查旧文案、文字换行、安全区和 PPTX 可打开性。
尤其检查底纹和文字这类边界是否合适,不只是具体参数,更要检查视觉效果是否合适。这样拆看起来慢,实际更稳。方向错了就停在方向层改,设计不对就停在设计层改,文件有问题就回到导出验证层改。最怕的是一开始把所有事情混在一起,最后你也说不清到底是内容不对、设计不对,还是文件本身有问题。
十、一张可以随手复用的检查清单
把这次经验压成一张清单,我会保留这些问题:
- 这套 PPT 的一句话主线写清楚了吗?
- 每页是不是只讲一个判断?
- 标题是不是现场真的会说的话?
- 哪些是事实、哪些是个人理解,边界说清了吗?
- 视觉 brief 里有没有写清楚"不要像什么"?
- 背景有没有留出安全区?
- image-gen 是否只承担背景、材质和无文字资产?
- 事实文字是否保留为可编辑文本?
- 标签、底板、mask 是否能复用,而不是每页手工调?
- 有没有导出逐页预览和 contact sheet?
- 有没有检查旧文案、placeholder、意外换行和遮挡?
- PPTX 是否能正常打开或重新导入?
- 读后感做 PPT,有没有把"文章摘要"变成"你的判断"?
这张清单不一定每次都要完整跑:内部草稿可以轻一点;要交付、分享、发给别人继续改,就值得认真一点。
写在最后:人的工作没消失,只是换了位置
我现在对 TRAE Work 做 PPT 的期待,比一开始更现实了。
它不一定一次给我完美作品,也不该替我决定内容主线、事实边界和审美判断。但只要我能把这些讲清楚,它就很适合接住中间那段繁琐工作:整理结构、生成页面、调整视觉、导出预览、按反馈继续改,再把文件检查一遍。
过去做 PPT,很多时间花在反复挪文本框、换底板、看一页改一页、改完又不放心。现在这部分可以更多交给工具跑起来。
人的工作没有消失,只是换了位置。以前人站在每个细节里,一点点手工改;现在更像站在流程上面:先讲清楚要什么,再看结果哪里不对,最后判断能不能交付。
对我来说,这才是用 TRAE Work 做 PPT 最值得沉淀的地方:它不是让人少思考,而是让人把思考放在更前面,也放在更关键的位置。