by 雪隐_上班了 from juejin.cn/user/143341...
欢迎分享与聚合,全文转载就不必了,尊重版权,圈子就这么大,若急用可联系授权。
前言:从"手搓RAG"到"躺平式AI"
上回说到,我用 FAISS + Qwen3-Embedding 手搓了一套本地 RAG 方案,效果确实香------600 页技术书随便问,AI 对答如流,数据还不出机箱。
但问题也随之而来:每次想加点新功能,就要改代码、调参数、重启服务。 这哪是享受 AI 红利啊,这分明是给自己找了个 996 的副业。
直到我在 GitHub 上刷到一个叫 Odysseus 的项目------6 万多星,号称"私有化 AI 工作流神器",支持 Docker 一键部署,还自带 Deep Research 和 Cookbook 这种听起来就很牛的功能。
好,就它了。 今天这篇就聊聊我怎么在 5060 Ti 16G 上把 Odysseus 跑起来,以及它到底香不香。
Odysseus 是什么?一句话说清楚
Odysseus 是一个本地优先的 AI 工作空间,相当于给你的 AI 能力建了一个"指挥部":
- 数据完全本地------你的资料不用上传,隐私有保障
- 支持各种推理引擎------Ollama / vLLM / llama.cpp / LM Studio 全都能接
- 内置高级功能------Deep Research(深度研究)、Cookbook(硬件感知推荐)、Agent(自主工具调用)、Memory(持久记忆)
- Docker 一键部署------告别"我本地环境怎么又崩了"的噩梦
打个比方:云端 AI 像是去米其林餐厅吃饭,精致但你的"食材"(数据)要交给厨师;Odysseus 则是把整个厨房搬到了自己家,锅碗瓢盆全归你管,想做什么菜自己说了算。
Docker 部署:真的是一键,没骗人
前置条件(看看你达标没)
- Docker + Docker Compose(这俩得有,没有先去装)
- NVIDIA 显卡 + CUDA 支持(5060 Ti 16G 完全 OK)
- 建议 16GB+ 内存(16G 刚好,32G 更宽裕)
开整
bash
# 克隆项目
git clone https://github.com/pewdiepie-archdaemon/odysseus.git
cd odysseus
cp .env.example .env
# 一键启动
docker compose up -d --build
# 看一眼状态,确保都在 running
docker compose ps启动后浏览器访问 **http://localhost:7000**,就能看到登录页面了。
账号密码注意 :默认用户名是 admin,密码藏在 Docker 日志里。怎么找?
bash
docker compose logs | grep -i password如果懒得敲命令,还有个骚操作------用 Claude Code + 本地 AI(Gemma-4-26B-A4B-QAT),直接把日志扔给它,让它帮你把密码扒出来。AI 时代嘛,能用工具解决的绝不自己动手。
登录后第一件事:改密码。别嫌麻烦,这玩意儿暴露在局域网里,不改密码等于家门没锁。
接入模型:LM Studio 走起
我本地已经有 LM Studio 跑着 Qwen3-Embedding 和 Gemma 模型了,地址是 http://localhost:1234,直接在 Odysseus 里填上就行:
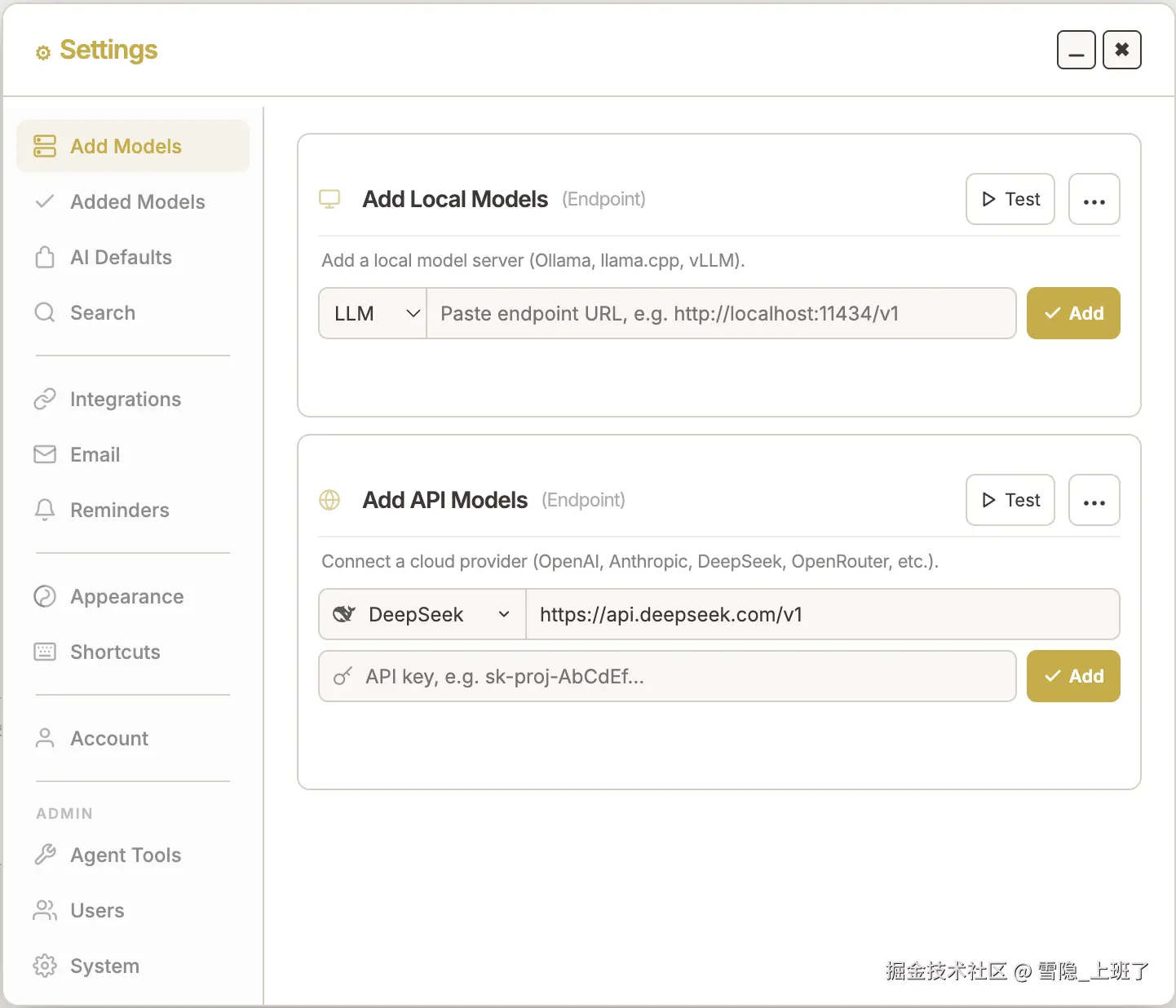
有云 API Key 的也可以加 DeepSeek 之类的模型,但我全部本地,零费用,纯离线。
Cookbook:再也不用纠结"我该用哪个模型"
这是 Odysseus 最让我惊喜的功能,没有之一。
它到底干了啥?
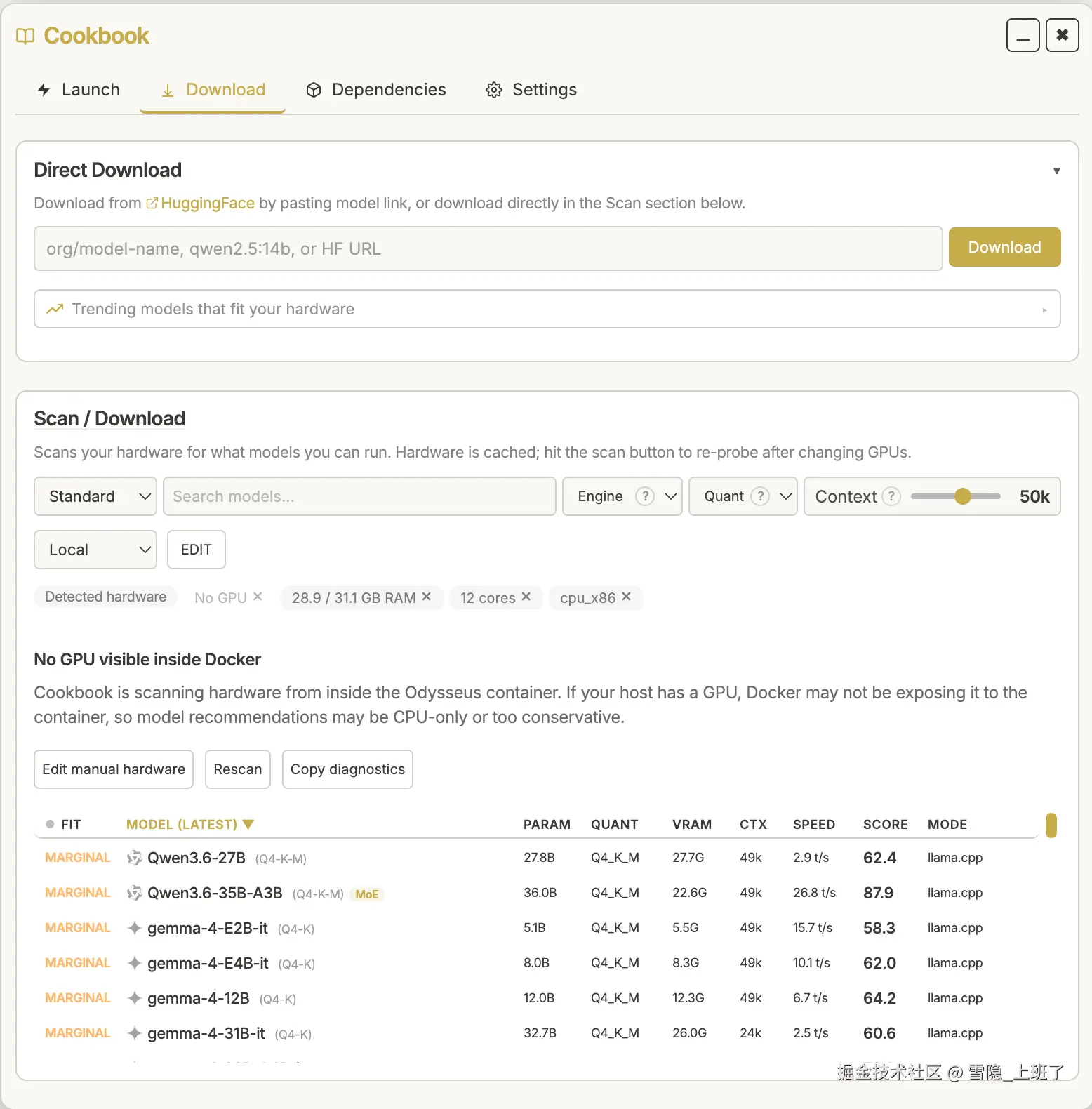
以前你决定用哪个模型,得去查各种评测、看参数、估显存,最后还得亲自试------试错了就 OOM,OOM 了就重启。Cookbook 把这个流程自动化了:
- 自动扫描硬件:CPU、内存、GPU、显存,全部摸清楚
- 智能计算内存需求:参数量 × 量化位宽 + KV 缓存 + 系统开销
- 分级推荐:Q8_0 → Q6_K → Q5_K_M → Q4_K_M → Q3_K_M → Q2_K,按你能跑的级别推荐
5060 Ti 16G 能跑啥?Cookbook 告诉你
显存需求 ≈ 参数量 × 量化位宽 + KV缓存 + 系统开销Cookbook 帮我算好了:
| 模型 | 量化 | 显存占用 | 跑不跑得动 |
|---|---|---|---|
| Qwen2.5-7B | Q4_K_M | ~6GB | ✅ 流畅 |
| Qwen2.5-14B | Q4_K_M | ~11GB | ✅ 能跑 |
| Gemma-4-26B | Q4_K_M | ~16GB | ✅ 刚好卡线 |
| Gemma-4-26B | Q6_K | ~20GB | ❌ 别想了 |
Qwen-27B 确实强,但 16G 显存跑起来会怀疑人生------慢到你以为程序卡死了。至少 24G 显存才能舒服地跑 27B,而且最好用 vnfp4 格式。Cookbook 也不会推荐你跑不动的模型,省得你白折腾。
实操:三步搞定
- 打开 Cookbook 界面
- 选场景(聊天 / 代码 / 研究)
- 点下载 + 启动
再也不用纠结"我这个配置能跑哪个模型"了,Cookbook 就是你的AI 私人导购,还不用看它脸色。
Deep Research:给 AI 装了个"研究助理"
这是 Odysseus 的另一个王炸功能,源自通义千问的 DeepResearch------如果你之前用 RAG 只是让 AI"翻书",那 Deep Research 就是让 AI"做研究"。
传统搜索 vs Deep Research
| 传统搜索 | Deep Research | |
|---|---|---|
| 深度 | 问一句答一句 | 拆解成子问题逐个攻克 |
| 过程 | 单次检索 | 多轮检索 + 分析 + 整合 |
| 输出 | 一段文字 | 结构化报告 + 图表 |
| 思考 | 没有 | 有,且很明显 |
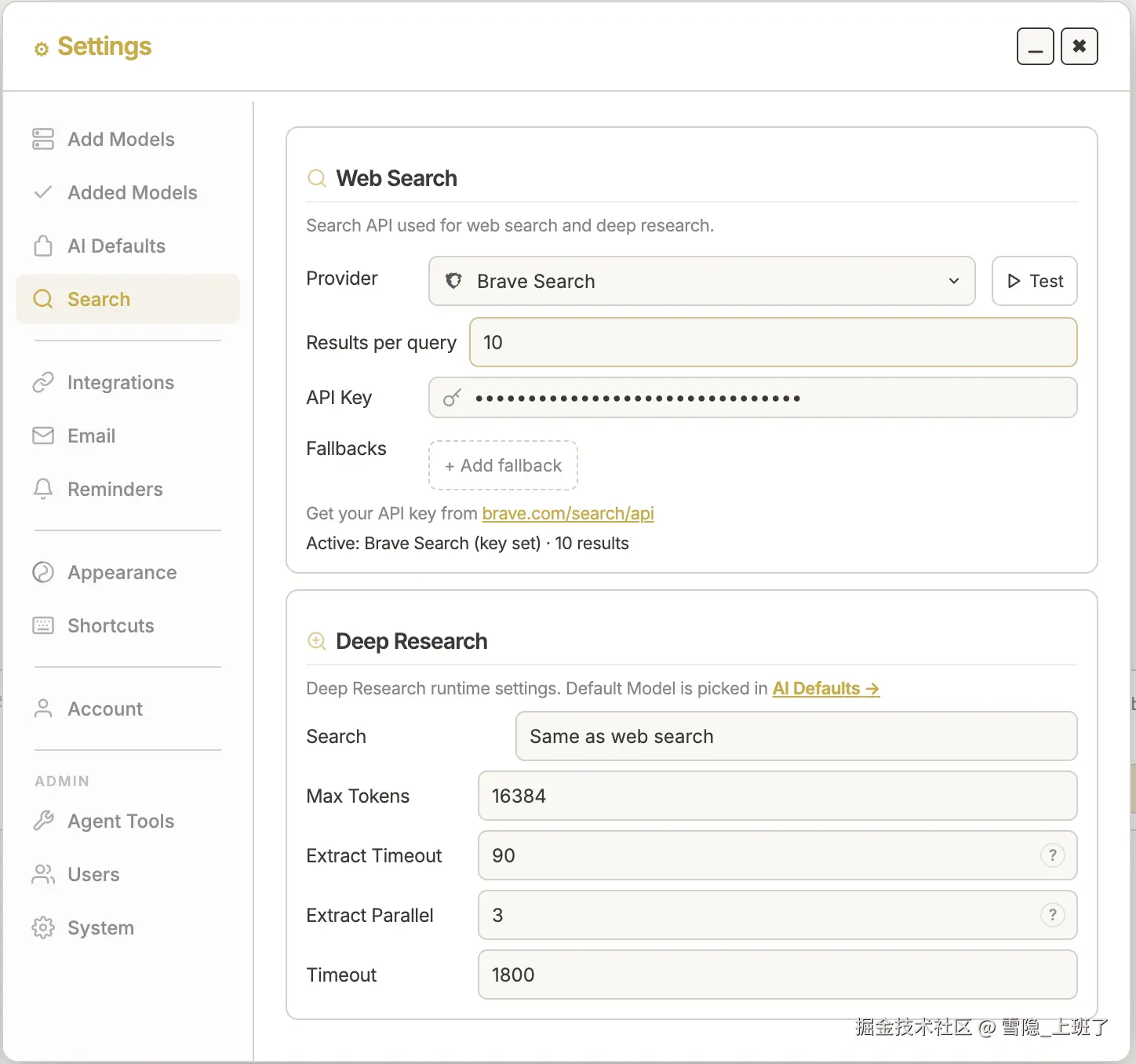
先配置搜索引擎
我用的 Brave Search,个人免费版一天 2000 次请求,够用了。DeepSeek 那类自带搜索的模型也可以,但我更喜欢独立配置的灵活性。
实战:让它写份分析研报
我扔了一个专业需求进去:
"按照国泰君安五步法(信息差→逻辑差→预期差→催化剂→结论+风险闭环)撰写深度分析研报,分析新东山精密,报告请务必使用中文"
注意:一定要加"使用中文",不然它可能给你整出一篇英文报告来------不是看不懂,是看着别扭。
Deep Research 收到任务后的工作流:
- 先搜索东山精密的基本信息、行业地位
- 再检索竞争对手的财务数据
- 对比市场预期和实际业绩
- 整合成结构化报告
- 生成图表
整个过程可能需要 6-12 分钟 (取决于模型速度),但它在"思考",不是简单地从某个网页摘一段话。最终报告的质量------你会惊讶于这是一台 5060 Ti 家用电脑跑出来的东西。

Deep Research 适合谁?
- 行业分析报告------让 AI 当研究员,你当审核员
- 技术调研------比如"对比目前开源 RAG 方案的优劣势"
- 市场研究------竞品动态、趋势分析
- 投资分析------就像上面那个例子
一句话:你负责提问题,AI 负责查资料、做分析、写报告。
其他功能:一个能打的都没有?不,个个都能打
| 功能 | 干啥的 | 我的评价 |
|---|---|---|
| Chat | 对话界面,支持各种推理引擎 | 基础功能,该有的都有 |
| Agent | AI 自主调用工具(搜索、代码、文件) | 让它自己干活,你在旁边监工 |
| Compare | 盲测对比多个模型效果 | 想换模型时用的,谁好谁差一目了然 |
| Documents | Markdown 编辑器,AI 辅助写作 | 比 Notion 轻量,比记事本聪明 |
| Memory | 持久化记忆,ChromaDB 存向量 | 相当于 Odysseus 自带的 RAG |
| 邮件自动处理 | 还没深度用过,看着挺强 | |
| Calendar | 本地日历,CalDAV 同步 | 适合把 AI 当秘书用的场景 |
Odysseus 不是"一个聊天工具",而是一套 AI 办公套件 ------ChatGPT 能干的事它能干,Notion AI 能干的事它也能干,而且全在本地。
5060 Ti 16G 实测:到底行不行?
| 功能 | 状态 | 吐槽 |
|---|---|---|
| Docker 部署 | ✅ 正常 | 一键启动,真的没坑 |
| GPU 识别 | ✅ 正常 | nvidia-smi 能看到容器在用卡,你配置的话可以,我用的是LM studio,所以没有配置 |
| Cookbook 推荐 | ✅ 正常 | 16GB 显存识别准确,没瞎推荐 |
| Deep Research | ✅ 可用 | 速度看模型,7B 很快,26B 略慢 |
| LM Studio 模型 | ✅ 正常 | 7B 流畅,14B 能跑,26B 刚好卡线 |
Cookbook 给我推荐了 Qwen2.5-7B-Q4_K_M 和 Gemma-4-26B-Q4_K_M。实测下来:
- 7B:如丝般顺滑,响应几乎无感
- 14B:略有延迟,但完全可接受
- 26B:回答要等一会儿,但质量确实更高
5060 Ti 16G 用户:别眼馋 70B 模型,7B 和 14B 才是你的菜。 想跑 27B 以上?等换 24G 卡再说。
自建 RAG vs Odysseus:我该选哪个?
| 维度 | 自建 RAG(我上回那套) | Odysseus |
|---|---|---|
| 部署难度 | 要写代码、调参数 | Docker 一键搞定 |
| 模型管理 | 手动下载、手动配置 | Cookbook 自动推荐 + 下载 |
| Deep Research | ❌ 没有 | ✅ 强得一批 |
| 定制化 | 非常灵活 | 受限于 UI,但够用 |
| 隐私 | 同样本地 | 同样本地 |
| 学习成本 | 高(得懂技术) | 低(打开浏览器就行) |
我的建议:
- 如果你喜欢折腾、控制一切、写代码 → 自建 RAG,过程本身就是乐趣
- 如果你想要开箱即用、别让我写代码、功能要全 → Odysseus,省下的时间干点别的
我现在是两套都在用------Odysseus 当主力工作台,自建 RAG 当"实验室"搞验证。成年人不做选择,全都要。
排坑指南(都是我自己踩过的)
Q: Docker 启动后打不开 localhost:7000?
A: 看日志是永恒的解决方案:
bash
docker compose ps # 看哪些服务没起来
docker compose logs -f # 看实时日志,找 ERROR我遇到过一次端口冲突,改 .env 里的端口配置就好了。
Q: 5060 Ti 16G 到底能跑多大的模型?
A: Cookbook 会告诉你。但我的实测经验:
- 7B Q4 → 流畅(适合日常聊天)
- 14B Q4 → 能跑(适合需要深度的任务)
- 26B Q4 → 刚好卡线(Deep Research 能跑但慢)
- 26B Q6 → 别试了,会 OOM
Q: 和 LM Studio 什么关系?
A: LM Studio 是本地模型服务工具 (提供 API 接口),Odysseus 是调用这些 API 的工作台 。你可以理解成:LM Studio 是发动机,Odysseus 是整车。Cookbook 推荐模型后,用 LM Studio 下载运行,Odysseus 通过 http://localhost:1234 调用。
Q: 数据真的完全本地吗?
A: 是的。所有数据都存在 Docker 容器卷里,不走公网。LM Studio 启动的是本地服务,Odysseus 通过 localhost 调用。全程离线可用------前提是模型权重已经提前下载好了。
总结:从"手搓工具"到"搭好厨房"
回顾这条 AI 工具链的演进:
| 阶段 | 工具 | 状态 |
|---|---|---|
| 文档解析 | Unlimited-OCR(逐页循环) | 600 页书变 Markdown |
| 知识库 | FAISS + Qwen3-Embedding | 手搓 RAG,能搜能答 |
| AI 工作站 | Odysseus | 一站式搞定所有 AI 需求 |
Odysseus 解决了我三个核心痛点:
- "跑什么模型" → Cookbook 帮我算了
- "怎么做深度研究" → Deep Research 帮我做了
- "怎么管理各种 AI 功能" → 一个 Docker 全搞定
Odysseus 值得一试。尤其是你已经有一张 5060 Ti 16G 的情况下------硬件买都买了,不把软件生态跑满,对得起那张卡吗?