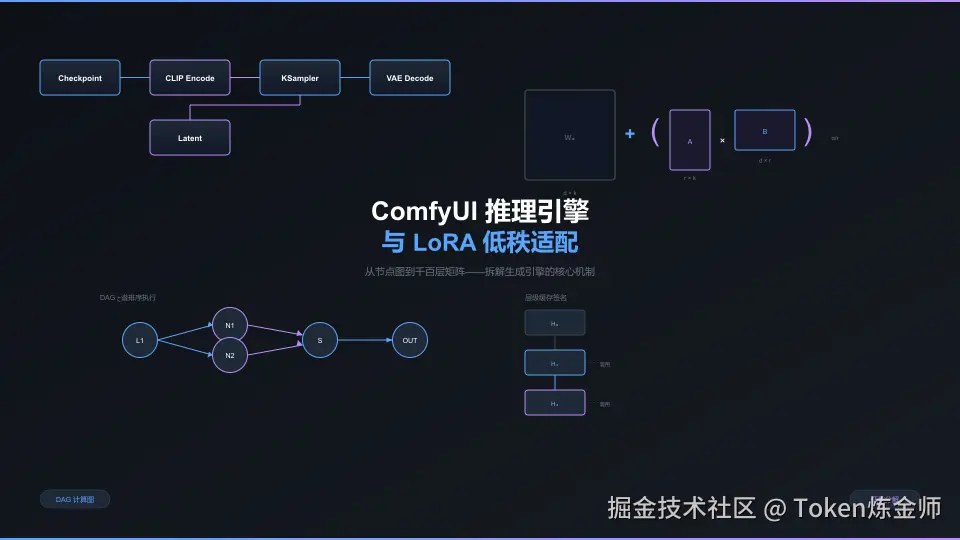
ComfyUI 将扩散模型的推理流程建模为 DAG 计算图,通过拓扑排序调度节点执行,并借助层级缓存减少重复计算;LoRA 则通过低秩矩阵分解对冻结权重进行旁路微调。本文从源码层面拆解两者的核心机制,揭示节点式工作流如何承载低秩适配的数学原理。
1. 节点系统:原子化计算单元
ComfyUI 的节点本质上是一个 Python 类,通过 INPUT_TYPES 和 RETURN_TYPES 声明输入输出契约。每个节点实现 FUNCTION 方法,接收输入张量并返回输出。
python
# 来源:ComfyUI / comfy/nodes.py
class CLIPTextEncode(ComfyNodeABC):
@classmethod
def INPUT_TYPES(s) -> InputTypeDict:
return {
"required": {
"text": (IO.STRING, {"multiline": True, "dynamicPrompts": True}),
"clip": (IO.CLIP, {"tooltip": "The CLIP model used for encoding the text."})
}
}
RETURN_TYPES = (IO.CONDITIONING,)
FUNCTION = "encode"
def encode(self, clip, text):
tokens = clip.tokenize(text)
return (clip.encode_from_tokens_scheduled(tokens),)节点间的连线定义了数据流方向,形成有向无环图。类型系统严格校验连接合法性------将 CLIP 模型连接到图像输入端口会立即报错,避免运行时类型不匹配。
2. 执行引擎:拓扑排序与异步调度
执行引擎在 comfy_execution/graph.py 中实现,核心类 ExecutionList 继承 TopologicalSort,使用 Kahn 算法变体进行调度。时间复杂度 O(V+E),可实时处理数千节点的工作流。
python
# 来源:ComfyUI / comfy_execution/graph.py
class ExecutionList(TopologicalSort):
"""执行列表实现图的拓扑溶解。节点被调度执行后,仍可在添加新依赖后返回图中。"""
async def stage_node_execution(self):
assert self.staged_node_id is None
if self.is_empty():
return None, None, None
available = self.get_ready_nodes()
while len(available) == 0 and self.externalBlocks > 0:
await self.unblockedEvent.wait()
available = self.get_ready_nodes()
# 取出队首节点执行,完成后通知下游减少入度关键优化在于增量重算 :每个节点可定义 IS_CHANGED 方法,IsChangedCache 在求值前检查输入签名,未变化则直接返回缓存输出。对于只改了提示词的工作流,可跳过整个采样链路,执行时间减少 80% 以上。
3. 缓存系统:层级签名与智能失效
缓存层在 comfy_execution/caching.py 中实现四种模式:
- Classic:立即持久化输出
- LRU:基于访问时间的淘汰策略
- RAM 压力感知:根据系统内存动态调整
- Null:禁用缓存(调试用)
默认的 HierarchicalCache 使用 CacheKeySetInputSignature------对节点输入的完整祖先链进行哈希,而非仅哈希当前节点。这意味着只要上游任意输入变化,下游缓存自动失效。
python
# 来源:ComfyUI / comfy_execution/caching.py
async def get_node_signature(self, dynprompt, node_id):
signature = []
# 获取节点的有序祖先链
ancestors, order_mapping = self.get_ordered_ancestry(dynprompt, node_id)
signature.append(await self.get_immediate_node_signature(dynprompt, node_id, order_mapping))
for ancestor_id in ancestors:
signature.append(await self.get_immediate_node_signature(dynprompt, ancestor_id, order_mapping))
return to_hashable(signature)4. LoRA 核心数学:低秩分解与缩放机制
LoRA 的核心假设:模型权重更新 ΔW 具有低内在秩,可用两个小矩阵的乘积近似。对于 d×k 的权重矩阵 W₀(如 4096×4096 = 16M 参数),使用秩 r=8 的 LoRA 仅需 2×4096×8 = 65K 参数,压缩比 99.8%。
前向传播公式:
h = W₀x + (α/r) · B(Ax)
其中 α/r 为缩放因子,确保不同秩下的更新幅度一致。典型配置 α=r,缩放因子为 1。
python
# 来源:LoRA 论文 Hu et al. 2021, arXiv:2106.09685
class LoRALayer(nn.Module):
def __init__(self, original_layer, rank, alpha):
# 冻结原始权重
self.original_layer = original_layer
self.original_layer.weight.requires_grad = False
# 低秩矩阵:A 用 Kaiming 初始化,B 初始化为零
self.lora_A = nn.Parameter(torch.zeros(rank, self.in_features))
self.lora_B = nn.Parameter(torch.zeros(self.out_features, rank))
self.scaling = alpha / rank
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def forward(self, x):
# 原始输出 + LoRA 增量
return self.original_layer(x) + self.scaling * self.lora_B @ self.lora_A @ xB 初始化为零确保训练开始时 ΔW=0,模型行为与预训练一致。A 的 Kaiming 初始化保证梯度在反向传播初期有效流动。
5. 权重合并:零推理开销
推理时可将 LoRA 增量合并进原始权重,得到等效的单矩阵乘法,推理延迟增加为零。这使得同一基础模型可在不同任务间快速切换------只需替换合并后的权重矩阵。
python
# 来源:LoRA 论文 Hu et al. 2021, arXiv:2106.09685
def merge_weights(self):
"""将 LoRA 增量合并到原始权重中,实现零开销推理"""
# W_new = W₀ + (α/r) · BA
self.original_layer.weight.data += (self.scaling * self.lora_B @ self.lora_A).data
self.merged = True6. ComfyUI 中的 LoRA 加载实现
ComfyUI 的 LoRA 加载涉及两层:节点层接收用户参数(强度、目标模型),模型管理层执行实际的权重 patch。加载后权重缓存在 GPU 显存中,相同 LoRA 文件不会重复加载。
python
# 来源:ComfyUI / comfy/lora.py
def load_lora_for_models(model, clip, lora, strength_model, strength_clip):
"""将 LoRA 权重应用到模型和CLIP上"""
# 遍历 LoRA 中的每个权重对
for key in lora:
# 计算缩放后的增量:(α/r) * BA
strength = strength_model
if key.startswith("lora_TE_"):
strength = strength_clip
# 将增量合并到目标模型的对应层
model.patch_model_function(key, lora[key], strength)LoRA 强度参数(strength)本质上是对 ΔW 的线性插值系数:W = W₀ + strength × ΔW。强度为 0 时等同于原始模型,强度为 1 时应用完整 LoRA,超过 1 会放大适配效果但可能引入过拟合。
7. 显存管理:按需加载与自动卸载
comfy/model_management.py 中的 VRAMState 枚举追踪六个显存等级,从 DISABLED 到 HIGH_VRAM。load_models_gpu() 函数根据可用显存动态决定模型驻留位置------低显存模式下,模型权重按前向传播需要在 GPU 和 CPU 间分页搬运,使得 4GB 显存也能运行 SDXL。
python
# 来源:ComfyUI / comfy/model_management.py
def load_models_gpu(models, memory_required=0):
"""智能加载模型到GPU,显存不足时自动offload"""
for model in models:
# 计算模型需要的显存
model_memory = model.model_size()
if current_vram + model_memory <= available_vram:
# 显存充足,直接加载
model.to(device)
current_vram += model_memory
else:
# 显存不足,使用分片加载或CPU offload
model.to("cpu")
# 低显存模式:按需分页加载权重8. 架构权衡与设计决策
节点粒度:ComfyUI 将推理流程拆为原子节点(加载、编码、采样、解码),牺牲了部分执行效率(节点间有调度开销),换来了极致的可组合性。相比之下,AUTOMATIC1113 的 WebUI 将整个推理封装为单次调用,执行更快但不可定制。
缓存粒度:基于祖先链的签名缓存比简单哈希更精确,但计算签名本身有开销。对于节点数超过 100 的复杂工作流,签名计算可能占总时间的 5%-10%。
LoRA 秩选择:r=4 在风格迁移类任务上足够,r=16 在需要捕捉细节变化的任务上表现更好,r=64 接近全量微调但失去参数效率。实际选择需要在显存预算和任务复杂度间权衡。
总结
ComfyUI 的 DAG 执行引擎与 LoRA 的低秩适配机制构成了完整的"工作流编排 + 高效微调"方案:节点图定义计算拓扑,调度器保证执行顺序,缓存系统消除冗余计算,LoRA 旁路注入任务特定知识。理解这套机制,才能在实际工作流设计中做出正确的架构取舍。