SQL Server 在企业生产环境里通常运行时间长,且承载着大量核心业务系统。对这类数据库做实时同步时,用户最关心问题是:数据同步会不会增加主库压力、账号权限能不能最小化、已有 Always On 高可用架构能不能复用。
SQL Server CDC 的增量数据由 SQL Server 事务日志进入捕获流程,再写入 CDC 变更表。同步任务在增量阶段读取 CDC 变更表和相关元数据。
对已经部署 Always On 的环境,可以将这部分操作放到可读副本,让主库继续专注业务写入和 CDC 捕获;同步账号只需要读取角色,从而降低对核心库的权限和性能影响。
SQL Server CDC 增量读取原理
SQL Server CDC 的增量读取入口不是业务表本身,而是启用 CDC 后生成的 capture instance 和对应的 CDC 变更表。
每个启用 CDC 的业务表,都会对应一张 CDC 变更表,命名通常为 cdc.<capture_instance>_CT。业务表发生 INSERT、UPDATE、DELETE 后,变更会先写入 SQL Server 事务日志,再由 SQL Server Agent 的 CDC capture job 捕获,并写入对应的 CDC 变更表。

同步任务消费增量数据时,主要读取 cdc schema 下的几类对象:cdc.<capture_instance>_CT 存放业务表的 DML 变更,是最核心的数据来源;cdc.change_tables 记录 capture instance、源表、起始 LSN 等信息,用于识别 CDC 表和可读范围;cdc.captured_columns、cdc.index_columns、cdc.ddl_history 等元数据,则用于识别捕获列、索引列和 DDL 历史。
其中,_CT 表中的每条记录除了业务字段外,还包含几类关键 CDC 字段:
__$start_lsn:变更所属事务的提交 LSN,是增量推进的主要位置。__$seqval:同一 LSN 下的操作序列,用于区分多条变更的先后顺序。__$operation:操作类型,1 表示删除,2 表示插入,3 表示更新前镜像,4 表示更新后镜像。__$update_mask:标识 UPDATE 涉及的列。
因此,SQL Server CDC 增量读取的核心,是按照 __$start_lsn、__$seqval、__$operation 等字段顺序消费 _CT 表中的变更记录,并将 INSERT、DELETE、UPDATE 前后镜像转换为下游可以处理的变更事件。
Always On 备库 CDC 原理
在 Always On 场景下,SQL Server CDC 的捕获仍由主副本完成。业务 DML 写入事务日志后,SQL Server Agent 的 capture job 从日志中捕获变更,并写入主副本上的 CDC 变更表;cleanup job 按配置的保留时间清理历史变更。
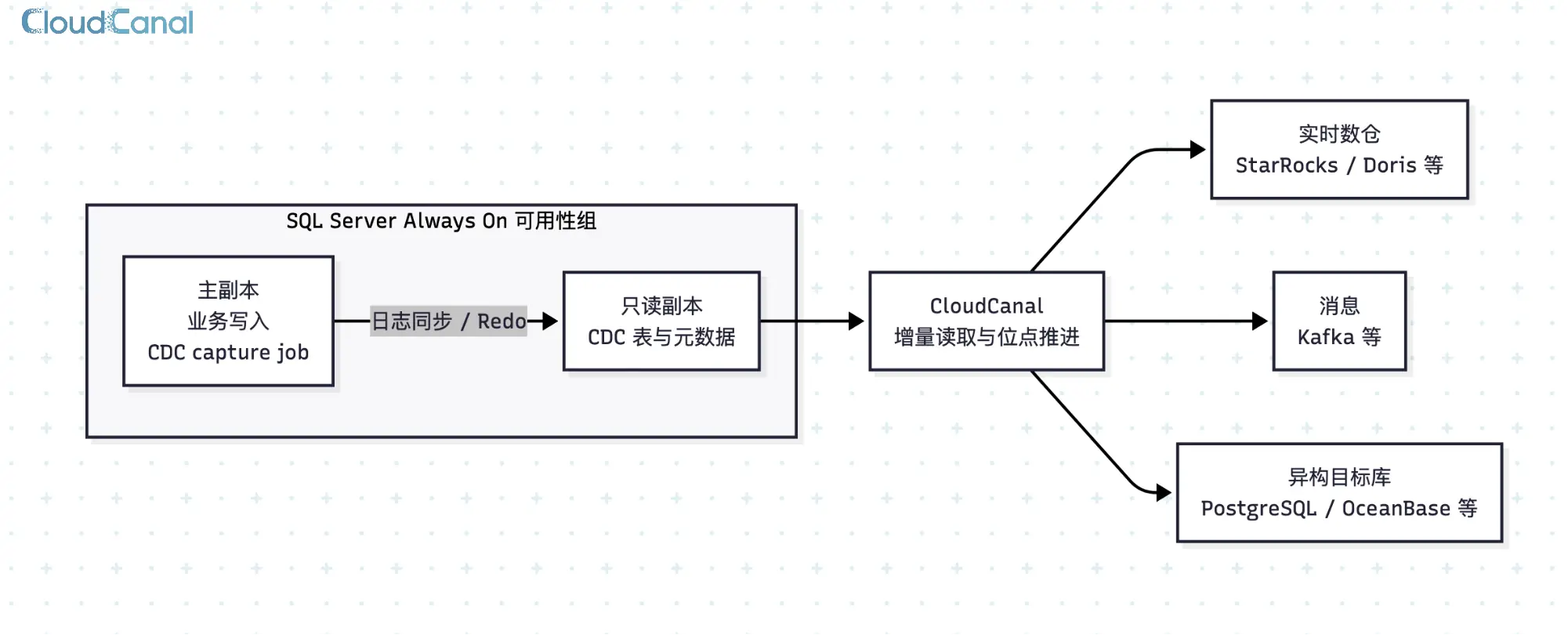
这些 CDC 变更表和相关元数据会随 Always On 日志同步和 Redo 在可读副本上可见。CloudCanal 连接可读副本后,读取已经同步过来的 cdc.<capture_instance>_CT、cdc.change_tables 等对象完成增量消费。
因此,Always On 场景下的优化点不是改变 SQL Server CDC 的捕获方式,而是把同步任务对 CDC 表的持续查询从主副本转到可读副本。主副本继续处理业务写入和 CDC 捕获,可读副本提供同步链路所需的 CDC 读取。
静态 CDC 与最小权限运行
SQL Server CDC 初始化需要较高权限。数据库级 CDC 需要 sysadmin 服务器角色,表级 CDC 和 capture instance 创建则需要 db_owner 角色。这些操作通常由 DBA 在主库侧一次性完成。
这里说的"静态 CDC",指的是 CDC 相关对象由 DBA 预先创建完成,后续同步任务在运行阶段不再动态创建 capture instance,只消费已经准备好的 CDC 表和元数据。
这种模式下,DBA 可以提前按固定格式(db_schema_table_cc_static)为订阅表创建好 CDC capture instance。后续同步账号只需对业务 schema 和 cdc schema 拥有 SELECT 权限,即可持续消费 CDC 数据,不再需要任何写入或管理类权限。
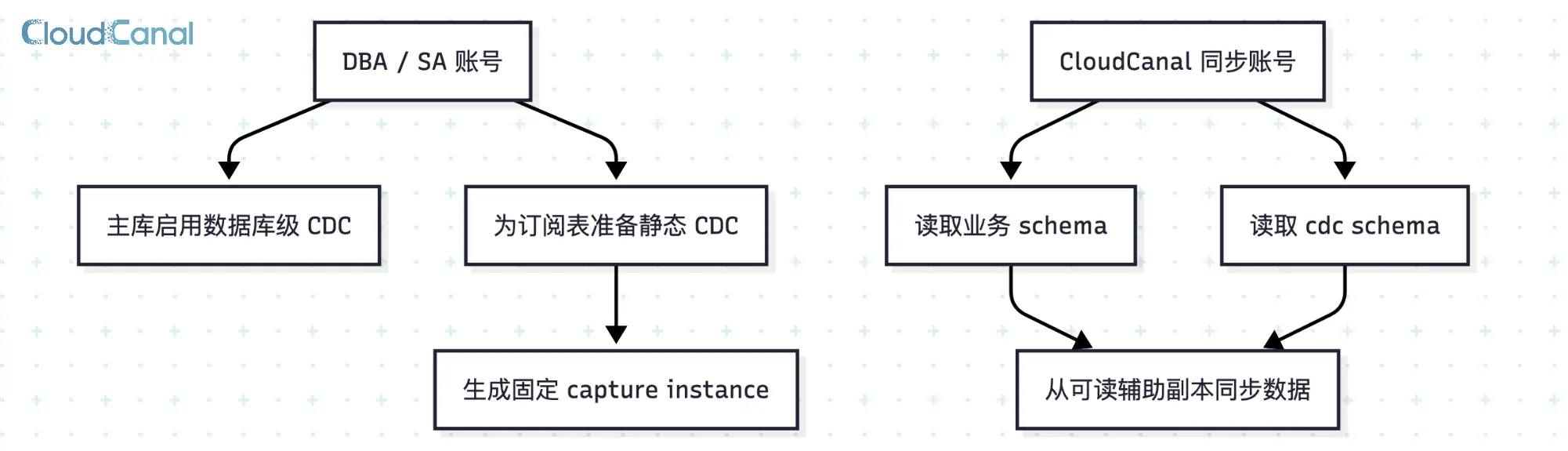
这种权限模型适合核心库。同步账号不需要长期持有 sysadmin 或 db_owner,日常运行阶段保持读权限即可。对权限审计严格的 SQL Server 生产库来说,这往往是方案能否落地的关键。
表级多位点推进
SQL Server CDC 中,每张表的 _CT 捕获表是独立的,不同表的变更进度天然不同。如果只维护一个全局 LSN,会导致同步任务重复消费数据。
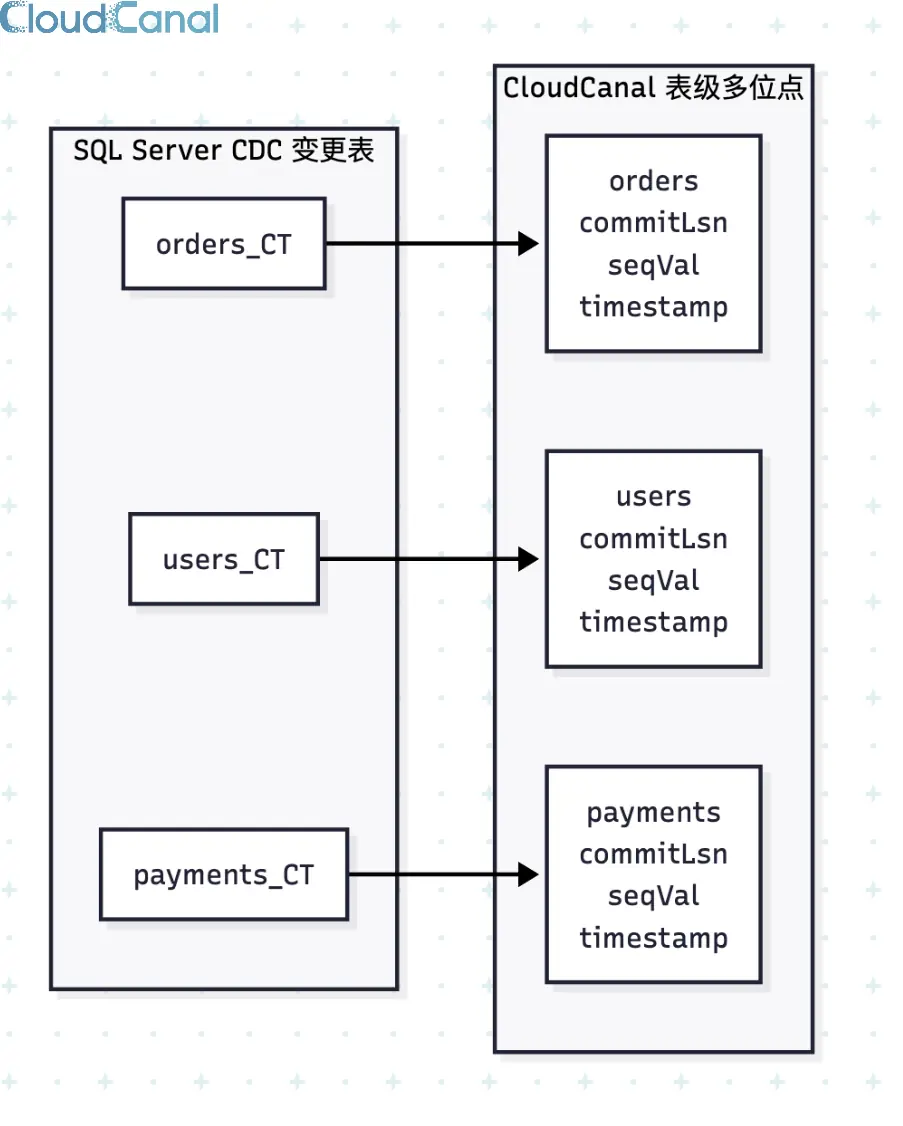
多位点机制的核心是按表独立维护进度。每张表的位点主要记录当前读取到的 LSN 和 __$seqval,读取 CDC 变更表时再结合 __$operation 识别操作类型:
- LSN:日志序列号,定位事务边界
__$seqval:同一 LSN 内多条变更的序列值,区分同一事务内的操作顺序__$operation:操作类型(1=删除, 2=插入, 3=更新前, 4=更新后)
在多表订阅、任务暂停恢复、CDC 表积压等场景下,多位点更容易定位问题:哪张表读到哪、哪张表出现延迟,一目了然。
总结
SQL Server Always On 场景下,CDC 捕获仍由主副本完成,增量数据同步连接可读副本读取 CDC 表。
这样既能复用已有高可用架构,减少同步读取对主库的影响,也能让运行账号保持最小权限。对主库负载敏感、权限要求严格的核心 SQL Server 库,这是一种更适合长期运行的 CDC 同步方式。