导读:让 AI 改代码不算新鲜,但有一类代码你多半不敢交给它------又长、又没测试、还在核心链路上,改错一个字段就可能是线上事故。我手上正好有一个:1021 行、零测试、被 5 处引用的 IM 消息转换文件。这次我把它整个交给 AI 重构,最后能确认改完和原来行为一致。这篇记一下过程,重点不在 AI 多会改,而在我怎么敢放手让AI改。
一、这是个什么文件
先说主角:convertNormalMsg.js,IM 消息链路上的一个转换器,干的活就是把服务端推过来的原始报文,翻成前端能直接渲染的结构。先上几个数:
| 指标 | 数值 |
|---|---|
| 文件行数 | 1021 行(团队 750 预警、1000 红线都过了) |
| 承担的消息类型 | 约 30 种(文本 / 图片 / 订单卡 / 工单卡 / 物流 / 转人工...) |
| 被引用处 | 5 处(IM 连接层、历史消息、留言...) |
| 测试覆盖 | 0 |
没测试,又被五个地方引用,改错一个字段,线上某种卡片说白屏就白屏。所以它在团队里一直是那种"能不动就别动"的存在。
这也不怪谁写砸了,多半是业务一路快迭代、几个人接力,慢慢就长成这样了------长期项目里这种文件基本都有。
这文件不是那种一眼就能看出问题的烂代码。它用了团队封装的策略表 multipleActionMap(一个 key → callback 的映射),结构挺规整,乍一看挑不出毛病。
可问题就藏在这个"看着没问题"里。打个比方你就懂了:
一家餐馆,每来一位客人,服务员先现编一份菜单------几十道菜名、价格、配料重新誊一遍,誊完才问"您点什么";客人走了把菜单撕掉,下一位进门再誊一份。
代码干的就是这事。multipleActionMap([...]) 写在函数体里,于是每转换一条消息,都要新建一个 Map、遍历 30 多项数组、当场创建 30 多个闭包。消息越密集,这套"重抄菜单"重复得越凶。
那为什么非得写在函数里?因为每个 callback 都调用了外层的局部变量(content、fromSelf、avatar...),闭包把骨架和数据焊死了,这张表压根提不出去。本质上是套了策略模式的形,却没用到它真正"装配一次、反复调用"的神。下面这张图就是重构前的真实链路:

还有一笔小账:30 多个 callback,每个都把同样的 9 个基础字段抄了一遍,哪天改一个口径,得在 30 多处一个个对齐。
其实怎么改不难。真正头疼的是:这个连人都不太敢碰的文件,我凭什么敢让 AI 上手大改?
二、先补一张测试网
说到底,不敢改不是因为不会改,是改完了你没法确认到底有没有改坏。没测试,就没有一把判断对错的尺子;没尺子,那不管谁改都是在赌。
所以第一步我没动代码,而是先把"可验证"这件事搞起来------给它补一张特征测试(Characterization Test,也叫快照测试 / golden master)。
特征测试不评判旧代码"应该"输出什么,只忠实记下它"现在"输出什么,再变成断言。比如喂它一条图片消息,旧代码吐出 { msgType: 2, picUrl: '...', isRead: 1 },我就把这条原样存成"标准答案";改完再跑一次,输出跟答案逐字段一致,就说明行为没变。它不问"对不对",只问"还是不是原来那样"------像动手术前先拍张 X 光片存档,日后哪儿变了,一比就知道。
不过真要落地,有个现实坎:这文件依赖一堆浏览器 / 原生模块(sentry、含 window / document 的 utils...),在 Node 里压根跑不起来。所以拿重构前这版代码当基准,绕过去的办法分三步。
① esbuild 打包 + 打桩
用 esbuild 把旧代码打成一个能在 Node 里独立运行的产物。打包时,esbuild 每遇到一条 import,都会通过 onResolve 钩子询问"这个路径该解析到哪个文件",我们写一个插件接管这一步,按依赖对输出的影响分三类处理:
- 在 Node 环境下无法加载的模块 ------比如依赖
window/document的 utils、只负责错误上报的 sentry------替换成行为等价的桩。sentry 不影响转换结果,直接换成空实现(no-op);utils 只保留真正被用到的几个纯函数,其余含浏览器 API 的部分一概剔除。 - 会影响转换结果的依赖 ------比如
./constants里的msgType取值------不拦截,交给 esbuild 正常解析,用真实值,保证产物算出来的字段是真的。 - 桩文件只补齐被引用到的导出,不还原整个模块。
一句话:把加载不起来的依赖换成等价替身,把影响输出的依赖留作真身。
js
const stub = {
setup(build) {
// sentry 只是上报副作用 → 换成 no-op
build.onResolve({ filter: /sentry-capture$/ }, () => ({ path: STUB_SENTRY }))
// 整份 utils 含浏览器 API → 只留真正用到的 4 个纯函数
build.onResolve({ filter: /libs\/utils$/ }, () => ({ path: STUB_UTILS }))
build.onResolve({ filter: /libs\/common$/ }, () => ({ path: STUB_COMMON }))
// ./constants 是纯文件,不拦截 → 用真值,保证 msgType 取值是真的
}
}② 造样本
样本得把代码里走得到的分支尽量铺满------没覆盖到的分支,哪天改坏了网照样是绿的,等于白织。这里按三个维度组合:
- 消息类型:30 种 msgType(文本、图片、订单卡、工单卡、物流、转人工...),分支最多的一维,每种都得有;
- 收发双方:同一种消息,自己发的(用户侧)和对方发的(客服侧)走的字段不一样,所以每种类型都跑用户、客服两侧;
- 是否实时消息 :
isOnMsg取true/false,实时推送和历史消息的处理略有差别。
三维全排列,再把最容易出岔子的边界(chxMsgType 子类型、缺 richText / otherInfo、空 data、未知 msgType 兜底...)补上,合起来 130 个输入。
③ 跑旧版,录基线
让打好桩的旧版挨个吃这 130 个样本,每条输出按用例名存进一个大对象,最后整体写进 golden.json------这份就是后面对拍用的"底片"。这里有两个容易漏掉的细节。
一是抛错也照样录。每次调用都包在 try / catch 里:正常就记返回值,抛异常就记下报错信息。因为"这条输入会让旧代码抛错"本身也是它当前行为的一部分,得一起锁住,不能当它不存在。
二是存之前先把 key 递归排序 。直接 JSON.stringify 比对有个坑------它对字段顺序敏感,{a,b} 和 {b,a} 序列化出来是两个字符串。可重构后字段的书写顺序很容易变(比如改走 baseMsg 拼装),语义其实没动,这种不该被判成"行为变了"。所以存档前先用一个 canon 把每层对象的 key 递归排好序(数组顺序保留不动),再序列化,把"字段顺序"这个噪音彻底抹掉:
js
const canon = (v) => Array.isArray(v) ? v.map(canon)
: (v && typeof v === 'object')
? Object.fromEntries(Object.keys(v).sort().map(k => [k, canon(v[k])]))
: v
// 把旧版 130 条输出归一后写进基线 golden.json三步串起来,整条"织网"流水线是这样:
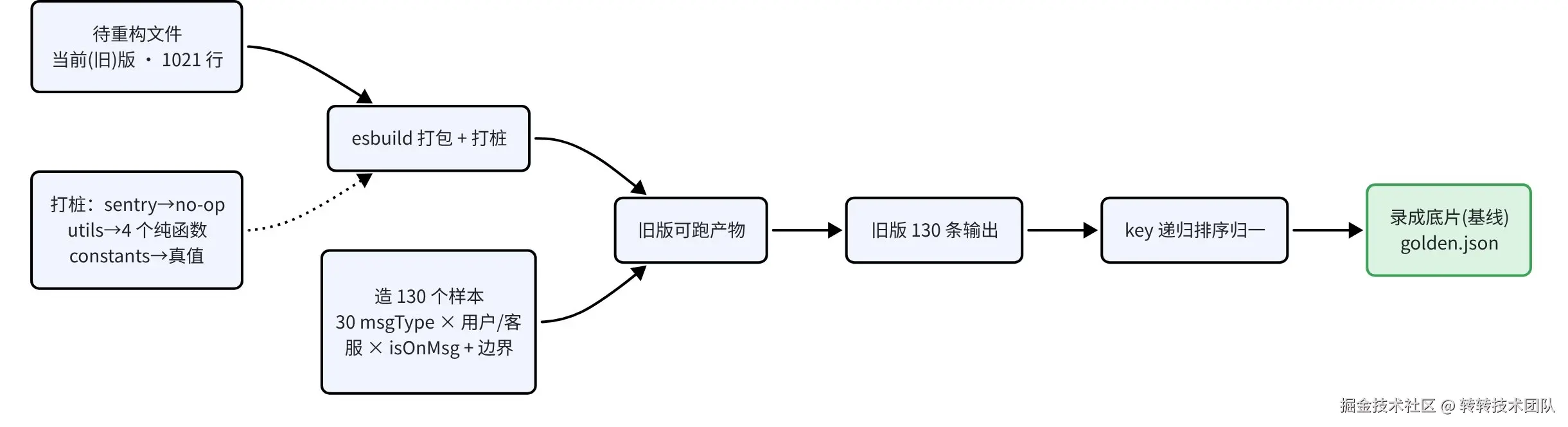
到这儿网就织好了:130 条旧版当前行为,全进了档。这套东西后来干脆作为回归测试留在了仓库里(src/dal/__characterization__/),以后谁动这个文件,跑一下就知道有没有动坏。我还故意往里塞了个多余字段试它,结果立马红了一大片------确认它是真兜得住的。
注意,整个过程一行业务逻辑都没碰,只是把这文件此刻的行为,从"凭感觉"变成了一套能逐字段对比的底片。等真改完,拿新输出跟它对一遍就行(见第四节)。
三、动手:三步改造
网是绿的,心里才有底,才敢往下动。整个改造分三步,每改完一步就重跑一遍网。
第 1 步:上下文注入
先把散在函数体里、被各个 callback "借用"的局部变量,显式打包成一个 ctx 对象,由 buildContext(msgObj, isOnMsg) 统一产出。每个 handler 从闭包 () => {} 变成纯函数 (ctx) => {},不再依赖任何外部局部变量。
handler 不"纯",就甭想搬出函数,所以这步是后面所有动作的前提。
第 2 步:把策略表提到模块作用域
handler 干净了,就能把整张表搬到模块顶层,文件加载时只构建一次:
js
// 关键:这一行只在模块加载时执行一次
const HANDLER_MAP = multipleActionMap(MSG_HANDLERS)
export default function convertNormalMsg(msgObj, isOnMsg = false) {
const ctx = buildContext(msgObj, isOnMsg)
const handler = HANDLER_MAP.get(ctx.msgType) || HANDLER_MAP.get('default')
return handler(ctx)
}这样餐馆就不用每来一个客人重抄一遍菜单了------开店印好一份,之后每位客人都是"看菜单 → 点单 → 上菜",一次 O(1) 查表。
第 3 步:抽 baseMsg,以及网兜不住的地方
把抄了 30 多遍的 9 个基础字段提成 baseMsg(ctx, extra),extra 放各类型的差异。一个图片消息 handler 从十几行字段堆叠缩成一句话。
但就在这儿,碰到了网兜不住的地方。AI 有点"强迫症",想统一到最整齐,差点把所有 handler 都套上 baseMsg------可历史上偏偏有两类消息(优惠券、保卖卡片)就是不带 isRead 字段的。
要真这么套,网立马就红:输出凭空多了个字段,跟底片对不上。可网也就只能告诉你"行为变了",至于这变化到底是对是错,它判不了------这个 isRead 缺失,说不定是早年留下的,也说不定下游就指着它不存在。
这种事网管不了,只能人来拍板:宁可保留原样,加一行注释写清楚为啥。网负责测出哪儿不一样,人负责定这不一样该不该,各管各的。
四、验收
最开始织的那张网,到这儿第二次派上用场------出具"没改坏"的凭据。三步改完,让新版吃同一批 130 个样本,输出归一后跟底片逐字段对一遍:
diff
=== characterization: 130 pass / 0 fail (of 130) ===
ALL OUTPUTS IDENTICAL ✅130 个用例,新版和重构前逐字段完全一样。各维度对比:
| 维度 | 重构前 | 重构后 | 变化 |
|---|---|---|---|
| 行为一致性 | --- | 特征测试 130 / 130 全过 | 逐字段一致 ✅ |
| 单条消息转换耗时 | 1.49 µs | 0.54 µs | 约 2.77× 提速 |
| 文件行数 | 1021 | 729 | −28.6% |
| 每条消息的对象创建 | 1 Map + 30+ 闭包 | 仅 1 个 ctx | 热路径几乎归零 |
| 对外 API | --- | 全部保留 | 零破坏 |
这张表里,真正能让我拍胸脯说"没改坏"的,其实只有第一行:130 个用例逐字段一致,就是说所有覆盖到的消息类型,新代码的输出跟旧代码一模一样。这才叫凭据,不是"我觉得没问题"。
性能纯属顺手白捡。50 万条消息的基准,旧版约 745ms,新版约 269ms:
sql
messages: 500000
OLD (rebuild table each call): 745.4 ms (1.491 µs/msg)
NEW (build table once): 269.1 ms (0.538 µs/msg)
speedup: 2.77x faster单条 0.54µs 对 1.49µs,用户其实没啥感觉,但 IM 是长时间、高频的场景,省下来的是一直在背后耗着的 GC 压力和主线程占用。不过话说回来,主次得分清:性能是白捡的,行为一致才是我敢说"没改坏"的底气。
五、把它沉淀成下次能复用的东西
"体检 → 织网 → 小步改 → 出凭据"那套流程,前面已经走了一遍,这里不再复述。真正想留下、能直接搬到下一个老文件上的,是两样具体的东西。
一个几乎不用改的脚本
那个织网脚本(esbuild 打包 + 归一 + 对拍 + 性能基准)里,真正跟业务相关的只有三处:改哪个文件、给哪些依赖打桩、按什么维度造样本。其余引擎一行不动照抄。换个老文件,把这三个问题答了,就能再织一张网。
打桩的判断也能压成一句话:每个依赖只问"它影响输出吗"------纯副作用(上报、埋点、日志)换空实现;影响输出的,留真值或只抄用到的那几个纯函数。
一条能直接粘给 AI 的指令
织网这件事与其每次现编,不如固定成一段 prompt。它跟语言、构建工具都无关,照搬即可:
markdown
我要重构 <目标:某文件 / 模块 / 函数>,但它没有测试,在测试环境里
也直接跑不起来(依赖太重 / 有环境耦合)。先别动业务逻辑,帮我建一张
特征测试网:
1. 隔离:把它从跑不起来的依赖里摘出来、能独立执行(打桩 / mock /
依赖注入,按技术栈选)。打桩原则------纯副作用(上报、日志、IO)换空实现;
影响输出的依赖保留真实现或真值,只补它真正用到的那部分。
2. 造样本:找出分支最多的那一维做主轴全排列,叠加几个次要维度,再补一批
边界(缺字段、空值、异常输入、兜底分支),覆盖所有走得到的路径。
3. 录基线:跑当前版本,把每条输出(含抛出的异常)归一化后存成基线文件。
4. 回归脚本:重跑后跟基线逐字段对拍,不一致就报出是哪几条变了。
最后自检一次:故意改动一处输出,确认网会变红------先证明它兜得住,再动手重构。第 1 步的"隔离"是整条指令里唯一跟技术栈强相关的------本文这次的 JS 实现,就是把它落成了 esbuild 打桩(前面第二节那段 onResolve 插件);换成 Java、Go、Python,把它换成对应的 mock / 依赖注入即可,其余几步原样通用。
剩下的"改造"和"验收"就简单了:让它每改一步就重跑这张网、最后贴出对拍结果,不必再展开。
六、最后
这次重构,真正关键的一步不在怎么改,而在动手之前------先给它织一张网,把"有没有改坏"从一句没底的"应该没问题",变成一条能逐字段自动判定的断言。网绿着,AI 就敢大改,我也敢收;一红,立刻知道哪儿动了。
而这套"先织网、再动手"的办法不挑语言、也不挑文件,下次再遇上又大、又没测试、又不敢碰的代码,照搬就行。所以想动那个谁都不敢碰的文件,别从改代码开始,先从织网开始。