一、引言
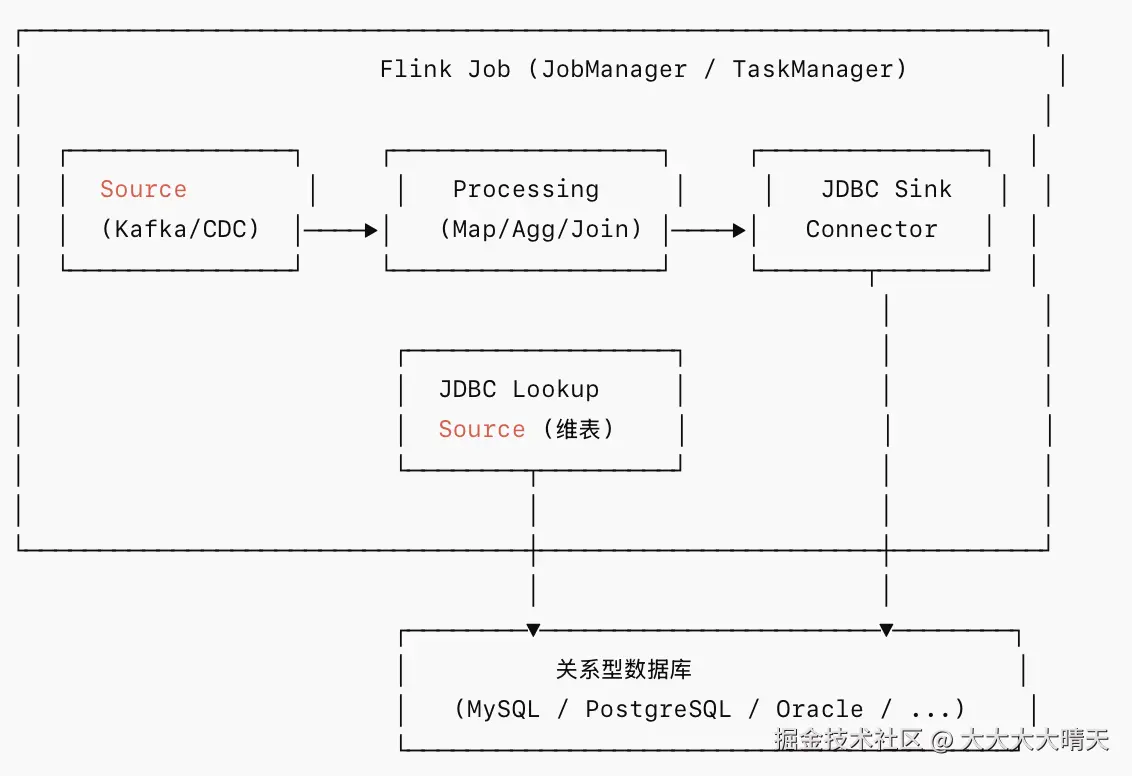
在实时计算架构中,Flink 作为流处理引擎负责数据的实时加工,在很多场景下最终结果往往需要写入关系型数据库供业务系统查询,或者需要从数据库中读取维度数据进行关联,Flink 的 JDBC Connector 正是连接流处理引擎与关系型数据库的核心桥梁,本文将深入剖析 JDBC Connector 的内部机制与数据流转原理、详解关键配置参数的含义与调优策略。
二、架构与机制原理
1.JDBC Sink 写入机制
JDBC Sink 的核心写入流程如下:
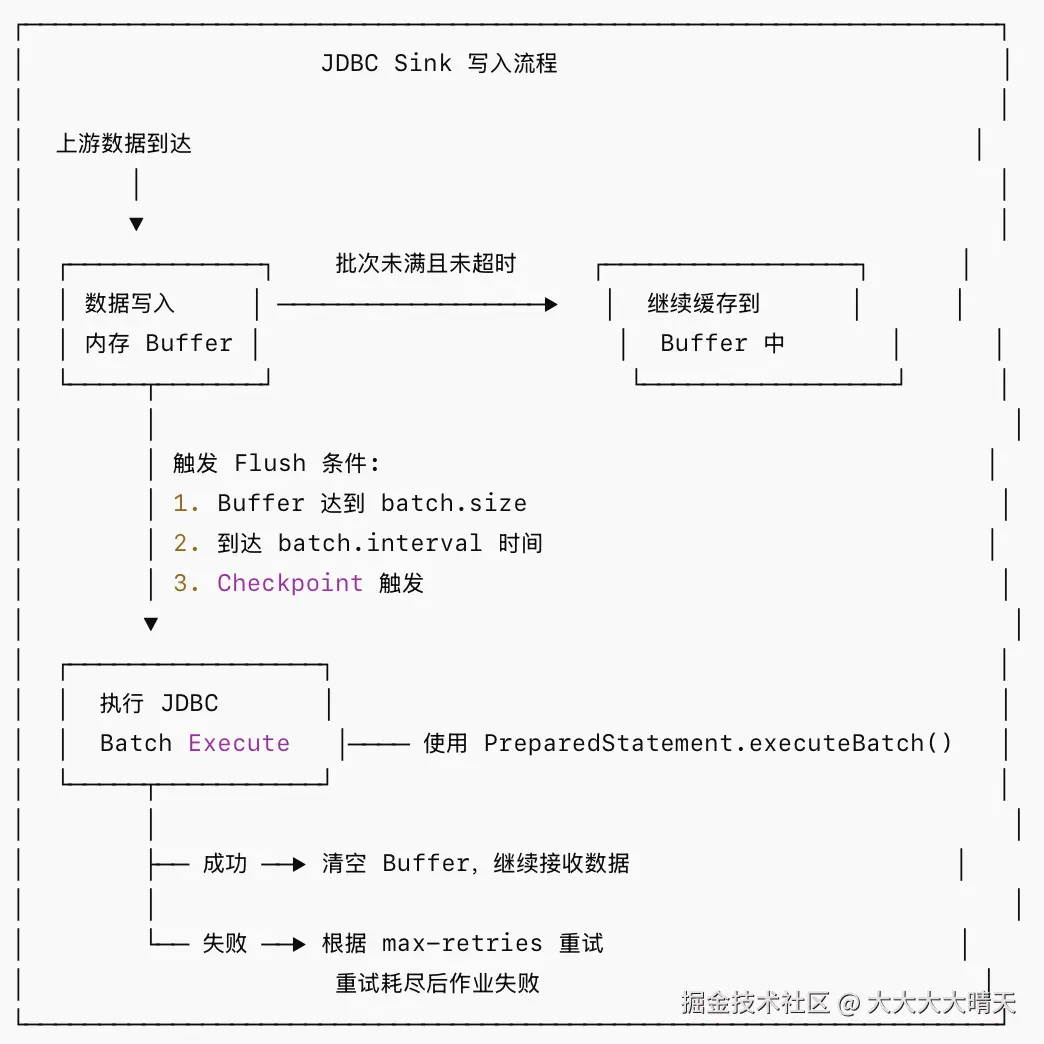
关键机制说明:
- 批量写入(Batching):数据先缓存在内存中,达到阈值后批量通过
executeBatch()写入数据库,减少网络往返和数据库压力。 - Upsert 语义:当定义了主键时,Connector 自动生成方言相关的 UPSERT 语句(如 MySQL 的
INSERT ... ON DUPLICATE KEY UPDATE,PostgreSQL 的INSERT ... ON CONFLICT ... DO UPDATE)。 - Exactly-Once 与 Checkpoint 联动:Flush 操作在 Checkpoint 时被强制触发,配合 Flink 的 Checkpoint 机制保证至少 At-Least-Once 语义。严格的 Exactly-Once 需要搭配数据库侧的幂等写入(UPSERT)或 XA 事务(Flink 1.13+ 支持
JdbcExactlyOnceOptions)。
2.Lookup Join 机制(维表关联)
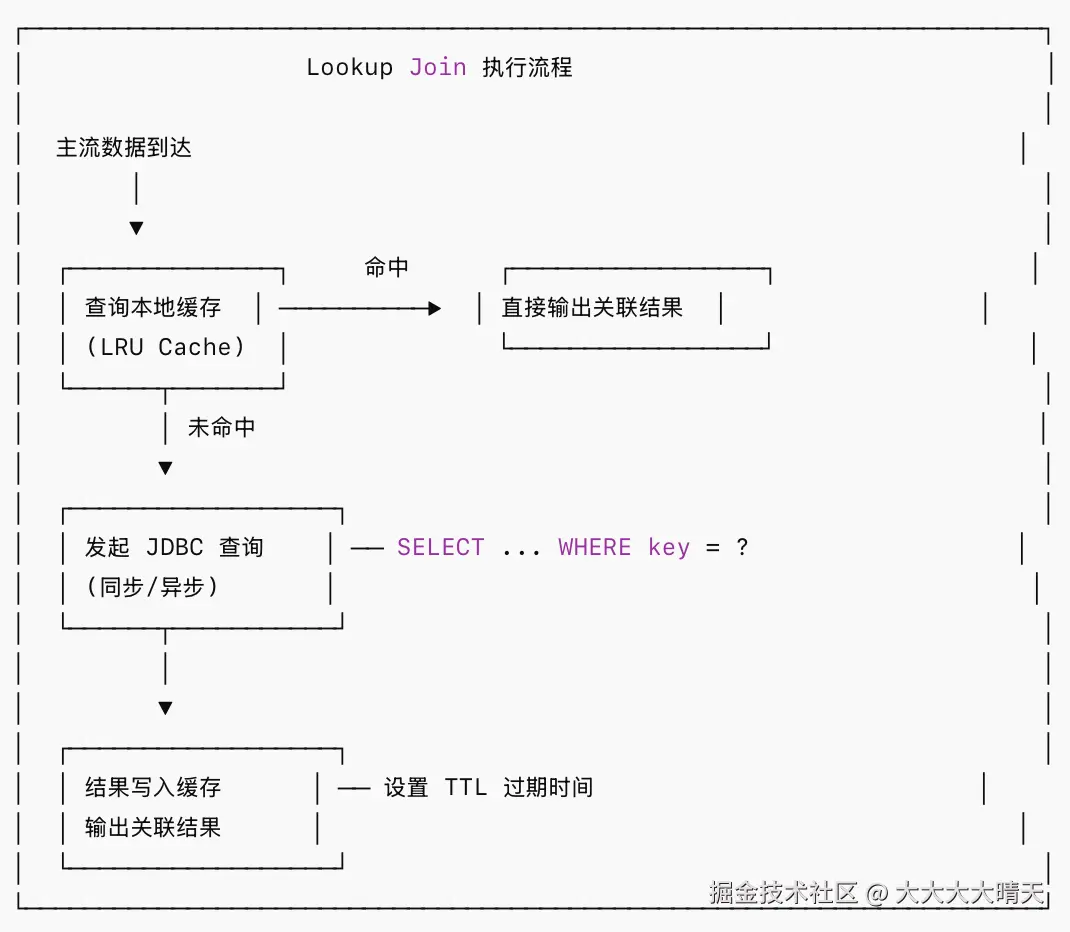
关键特性:
- 支持本地 LRU 缓存,减少数据库查询压力
- 缓存有 TTL 控制,平衡数据新鲜度与性能
- 支持同步查询模式
三、配置参数详解
1.通用连接参数
| 参数 | 必填 | 默认值 | 说明 |
|---|---|---|---|
| connector | 是 | - | 固定为 'jdbc' |
| url | 是 | - | JDBC 连接 URL |
| table-name | 是 | - | 数据库表名 |
| driver | 否 | 自动推断 | JDBC 驱动类名,通常可从 URL 自动推断 |
| username | 否 | - | 数据库用户名 |
| password | 否 | - | 数据库密码 |
2.Sink 写入参数
| 参数 | 默认值 | 说明 |
|---|---|---|
| sink.buffer-flush.max-rows | 100 | Buffer 最大行数,达到此值触发 Flush |
| sink.buffer-flush.interval | 1s | 定时 Flush 间隔,'0' 表示禁用定时 Flush |
| sink.max-retries | 3 | 写入失败最大重试次数 |
| sink.parallelism | 否 | Sink 并行度,未设置时继承上游 |
3.Lookup 维表参数
| 参数 | 默认值 | 说明 |
|---|---|---|
| lookup.cache | NONE | 缓存策略:NONE、PARTIAL、FULL(1.16+) |
| lookup.cache.max-rows | - | PARTIAL 模式下缓存最大行数 |
| lookup.cache.ttl | - | 缓存条目存活时间 |
| lookup.max-retries | 3 | 查询失败最大重试次数 |
| lookup.partial-cache.expire-after-write | - | 写入后过期时间(1.16+) |
| lookup.partial-cache.expire-after-access | - | 访问后过期时间(1.16+) |
| lookup.partial-cache.cache-missing-key | true | 是否缓存查询为空的 Key(1.16+) |
四、最佳实践
1.Sink 写入调优
| 实践项 | 建议 |
|---|---|
| 批次大小 | 根据目标库 TPS 承受能力设置,推荐 200 ~ 2000 |
| Flush 间隔 | 对延迟不敏感的场景可设为 5 ~ 10s,减少小批量写入 |
| 主键与 Upsert | 有更新场景务必定义 PRIMARY KEY,避免数据重复 |
| 连接池 | JDBC Connector 内部每个并行度维护一个连接,注意数据库最大连接数限制:总连接数 = sink.parallelism × TaskManager 数 |
| 重试策略 | sink.max-retries 建议设为 3 ~ 5,配合数据库超时参数 |
2.Lookup Join 优化
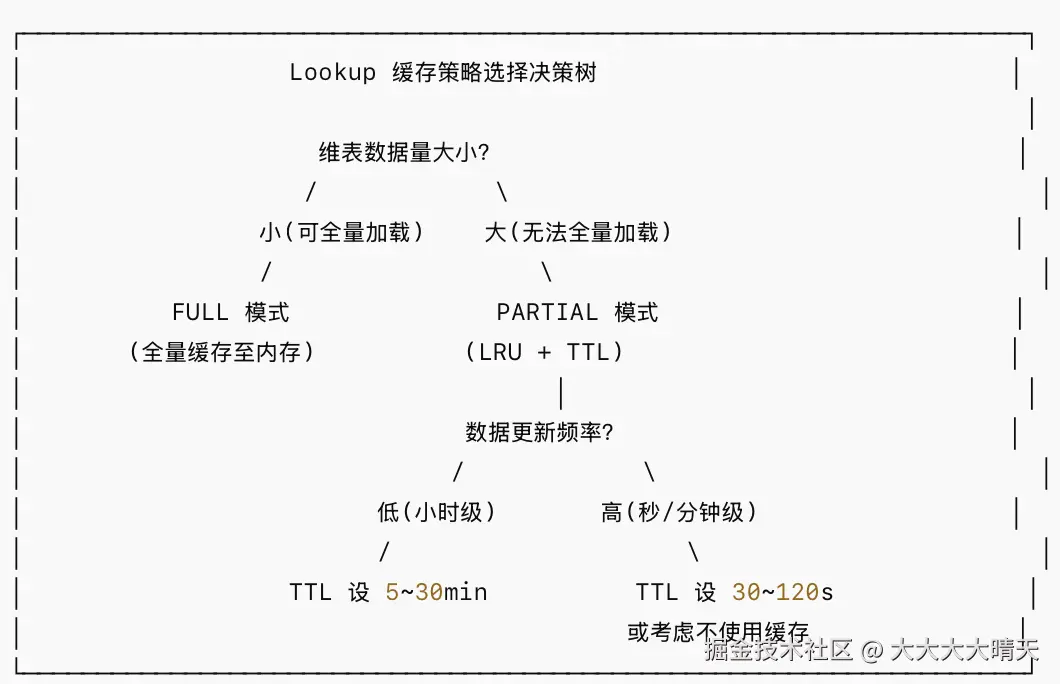
建议:
FULL模式会在 TaskManager 启动时全量加载维表,适用于数据量小(万级以内)且变更频率低的场景- 高 QPS 场景必须开启
PARTIAL缓存,避免对数据库形成查询风暴 cache-missing-key = true可以防止缓存穿透,对不存在的 Key 也缓存空结果- 注意缓存大小与 TaskManager 内存的关系,避免 OOM
3.常见问题与解决方案
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 写入延迟高 | batch.size 过大或数据库慢查询 | 降低 batch.size,优化目标表索引 |
| 数据库连接耗尽 | 并行度过高 | 降低 sink 并行度,增大数据库连接池 |
| 数据重复 | 未定义主键,使用 Append 模式 | 定义 PRIMARY KEY 启用 Upsert |
| Lookup 查询超时 | 维表查询无索引或网络延迟 | 加索引,开启缓存,降低 TTL |
| Checkpoint 超时 | Flush 阻塞 | 减小 batch.size,增大 Checkpoint 超时时间 |
五、SQL 完整使用示例
1.Sink 写入(Upsert 模式)
sql
-- 定义 Source(从 Kafka 读取订单数据)
CREATE TABLE kafka_orders (
order_id BIGINT,
user_id BIGINT,
amount DECIMAL(10, 2),
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'orders',
'properties.bootstrap.servers' = 'kafka:9092',
'format' = 'json',
'scan.startup.mode' = 'latest-offset'
);
-- 定义 JDBC Sink(带主键,自动使用 Upsert 语义)
CREATE TABLE mysql_user_revenue (
user_id BIGINT,
total_amount DECIMAL(12, 2),
order_count BIGINT,
last_update TIMESTAMP(3),
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysql-host:3306/analytics?useSSL=false&serverTimezone=UTC',
'table-name' = 'user_revenue',
'username' = 'flink_writer',
'password' = '${secret_value}',
'sink.buffer-flush.max-rows' = '500',
'sink.buffer-flush.interval' = '3s',
'sink.max-retries' = '5'
);
-- 实时聚合并写入
INSERT INTO mysql_user_revenue
SELECT
user_id,
SUM(amount) AS total_amount,
COUNT(*) AS order_count,
MAX(order_time) AS last_update
FROM kafka_orders
GROUP BY user_id;2.Lookup Join(维表关联)
ini
-- 定义维表
CREATE TABLE mysql_user_dim (
user_id BIGINT,
user_name STRING,
vip_level INT,
city STRING,
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysql-host:3306/dim_db',
'table-name' = 'user_info',
'username' = 'flink_reader',
'password' = '${secret_value}',
'lookup.cache' = 'PARTIAL',
'lookup.partial-cache.max-rows' = '10000',
'lookup.partial-cache.expire-after-write' = '60s',
'lookup.max-retries' = '3'
);
-- Lookup Join 关联
SELECT
o.order_id,
o.amount,
u.user_name,
u.vip_level,
u.city
FROM kafka_orders AS o
JOIN mysql_user_dim FOR SYSTEM_TIME AS OF o.proctime AS u
ON o.user_id = u.user_id;