我相信十个程序员里有八个会在简历上写"熟悉高并发"!!
说真的,这么多年来,我见过太多人号称自己"懂高并发"的朋友,写起代码来还是一把 Mutex 走天下(最开始的我也是这样o(╥﹏╥)o)。你说,要是并发量就那几百个,锁一下也就罢了,但在那种千万级流量、微秒级延迟要求的系统里,锁简直就是性能的"杀手",是阻塞你工资涨幅的"绊脚石"啊。
说句扎心的,没把无锁队列啃透,你对高并发底层的理解顶多算个皮毛,连门都没摸着!
一、为什么高并发开发,绕不开无锁队列?
很多刚入门的兄弟会问,有锁队列用着好好的,为啥非要费劲搞无锁?
讲真,不是我没事找事,是高并发场景下,传统锁的坑真的能把人搞疯!!
这么说吧,我刚入行那会儿~ 那时候觉得,并发问题嘛,简单,给共享资源加个锁,不管是 synchronized 还是 ReentrantLock,加上就完事了,后来业务暴涨,麻烦就来了------系统响应越来越慢,查来查去,罪魁祸首就是锁。
传统锁机制下,多个线程抢一把锁,抢不到的就只能阻塞等着。这就像一群人挤着过独木桥,前面的人慢一点,后面的全得堵着,效率低到离谱。
你看,传统锁这东西,致命的问题从来不止死锁。
高并发场景下,阻塞还会引发上下文切换。操作系统给线程做上下文切换,要保存寄存器、程序计数器、栈帧,一次切换就是几十纳秒到上百纳秒,看着不多,每秒几十万次切换下来,CPU 全耗在这上面了,根本没空处理业务。
还有大家平时忽略的缓存乒乓效应。CPU 是按缓存行来存取数据的,一般一个缓存行 64 字节。多个线程抢同一把锁,锁的状态存在同一个缓存行里,多个 CPU 核心来回抢这个缓存行的所有权,你刚改完,我又要改,缓存行不停的失效、同步,CPU 的缓存命中率直接跌到谷底,性能能好才怪。
那无锁编程,到底解决了什么问题?
别以为无锁就是完全不用锁,那是扯淡,无锁不是真的没有任何同步机制,而是用了更高效的方式------非阻塞同步,核心是原子操作。
它的核心,是把锁的粒度,从操作系统层面的线程调度,下沉到了 CPU 硬件层面的原子指令。用 CPU 支持的原子操作,来实现非阻塞的同步,哪怕多个线程同时操作共享资源,也不会有线程被阻塞挂起,自然就没了上下文切换的开销。
这里要提一句,非阻塞同步也是有进度保证的,不是瞎写。无锁的保证,是至少有一个线程能在有限步内完成操作;无等待的要求更高,所有线程都能在有限步内完成操作。我们常说的无锁队列,大多是无锁级别的实现,已经能解决 99% 的高并发场景问题了。
这就是无锁队列的价值。高并发场景下,它把等待变成了"忙等+重试",配合硬件原子操作,延迟低、吞吐高。当然,它也有边界,不是万能药,但很多时候,它就是那把能打开性能天花板的钥匙。从日志组件到消息中间件,再到高频交易系统,哪儿需要极致吞吐,哪儿就少不了它。
你现在再想想,你做的高并发系统里,是不是到处都有队列的影子?队列的性能,直接决定了整个系统的性能上限。队列的底层都没啃透,你说你懂高并发,谁信啊?
二、无锁队列的底层逻辑
写到这儿,肯定有人会说,不就是个无锁队列吗,网上抄个 CAS 实现不就完事了?
我劝你趁早打消这个念头。很多哥们,从网上抄了个无锁队列的代码,放到线上就出问题,不是内存泄漏,就是链表断了。
无锁队列的坑,全在底层的这些基础原理里,你没啃透,写出来的代码全是定时炸弹。
无锁队列的底层其实也不复杂,说白了就那几样东西。
先说最基础的,无锁队列用什么数据结构来实现?
无非两种,循环数组,和单向链表。
循环数组,最典型的就是 Disruptor 用的环形缓冲区,预分配内存,大小固定,入队出队就是移动头尾指针,没有节点的申请和释放,性能极高,缓存友好性拉满。但它的问题就是容量固定,不能动态扩容,适合能预估队列峰值的场景。
单向链表,就像 ConcurrentLinkedQueue、Boost.lockfree 用的,支持动态扩容,节点按需申请,灵活性高。但问题就是节点的申请和释放有开销,缓存友好性差,而且要处理节点回收的内存安全问题,实现复杂度比数组高了好几个量级。
选哪种,完全看你的业务场景,没有绝对的好坏。但你要知道这两种结构的优劣,不是随便选一个就用。
再深一层就是原子操作了~
别跟我说 CAS 就是原子操作,CAS 只是原子操作的一种。
原子操作的本质,是 CPU 保证这个操作要么全部完成,要么完全不执行,中间不会被任何线程打断。
这东西这么厉害,全是 CPU 给的底气。
就拿 x86 架构来说,你写的 CAS 操作,最终会被编译成带 LOCK 前缀的指令。这个 LOCK 前缀,就是给 CPU 发了个信号,要么锁住系统总线,要么锁定缓存行,保证这个指令的执行是原子性的,其他 CPU 核心没法干扰。
说到这,不得不提 MESI 缓存一致性协议了。CPU 的每个核心都有自己的 L1、L2 缓存,多个核心怎么保证缓存里的数据是一致的?全靠 MESI 协议。它把每个缓存行的状态分成了修改、独占、共享、无效四种,多个核心通过总线传递消息,来同步缓存行的状态。你写的原子操作,本质上就是利用这个协议,保证了数据修改的原子性。
你看,连原子操作的硬件本质都不懂,你怎么敢写无锁代码?
接下来就是无锁编程的核心,CAS 原语,也就是比较并交换。
CAS 的逻辑很简单,它有三个参数,内存地址 V,旧的预期值 A,要修改的新值 B。只有当 V 里的值等于 A 的时候,才会把 V 里的值改成 B,返回成功;否则什么都不做,返回失败。整个操作是原子性的,不会被打断。
看着简单,坑可太多了。最经典的就是 ABA 问题,我当年就踩过这个坑,至今印象深刻。
我记得我老早前用 C 写一个链表结构的无锁队列,线上偶尔会出现链表断链的问题,数据直接丢了,复现概率极低,查了整整 3 天。最后才发现,就是 ABA 问题搞的鬼。
给你举个最简单的例子。队列里有个节点 A,next 指向 B。线程 1 要出队,拿到了头节点 A,预期 A 的 next 是 B,准备把 head 改成 B。这时候线程 1 被切走了,线程 2 进来,把 A 出队了,释放了 A 的内存,然后又入队了一个新节点,刚好内存分配器把刚释放的 A 的内存又分配给了新节点,新节点的地址还是 A,next 指向 C。这时候线程 1 切回来,一看 head 还是 A,和预期值一样,CAS 成功,把 head 改成了 B。但这时候 B 已经被释放了,链表直接就断了,内存也访问越界了。
就这么个问题,当年差点把我搞疯。后来才知道,ABA 问题的解决方案,无非就是两种,一种是给指针加版本号,每次修改都递增版本号,CAS 的时候不仅比较指针,还要比较版本号,就算地址一样,版本号不一样,CAS 也会失败;另一种就是用 Hazard Pointer、EBR、RCU 这些节点回收机制,保证节点在被引用的时候,绝对不会被释放和重用。
你看,就一个 CAS,里面的坑就这么多,你随便抄个代码就敢用?
还有一个是你绝对绕不开的------内存模型和内存屏障。
我问你,你写的代码,真的是从上到下按顺序执行的吗?
别骗自己了。编译器为了优化性能,会给你的代码做指令重排;CPU 为了提升执行效率,也会给你的指令做乱序执行。单线程场景下没问题,它能保证最终的执行结果和你代码的顺序是一致的。但到了多线程场景,指令重排会直接导致你的代码出现各种诡异的 bug,而且复现概率极低,根本没法调试。
内存屏障,就是给 CPU 和编译器立的规矩,告诉它哪些指令不能重排。我们常说的 Acquire 和 Release 语义,就是靠内存屏障实现的。Acquire 语义,保证屏障之后的读写操作,不能重排到屏障之前;Release 语义,保证屏障之前的读写操作,不能重排到屏障之后。
一定会有很多朋友,写无锁代码的时候,内存屏障用错了,该加的地方没加,不该加的地方乱加,导致代码在 x86 上跑的好好的,一放到 ARM 架构的服务器上,就各种诡异的 bug。因为 x86 是强内存模型,默认帮你做了很多顺序性保证,而 ARM 是弱内存模型,全靠内存屏障来保证顺序,你用错了,不出问题才怪。
说到底,你写的无锁代码,能不能保证在任何竞态条件下,都不会出现数据不一致,不会出现死锁、活锁,能不能满足对应的进度保证,这些都是要经过严格验证的。不是你写了个 CAS,就叫无锁编程了。
三、无锁队列的四大经典模型
聊完了底层原理,我们来聊聊实际能用的无锁队列模型。
很多人一上来就想写一个通用的多生产者多消费者无锁队列,结果写出来的代码,性能还不如加锁的队列,纯属吃力不讨好。
无锁队列的模型,一共就四种,每一种都有自己的适用场景,选对了,性能拉满,选错了,拉完了!!
3.1 SPSC:极致的简单
最简单,也是性能最强的 SPSC 模型,单生产者单消费者。
这个模型,只有一个线程往队列里写,只有一个线程从队列里读,没有多线程之间的写竞争,连 CAS 都用不上几次,只需要靠内存屏障保证顺序性就行,性能直接拉到天花板。
我做过压测,SPSC 无锁队列的吞吐量,能达到每秒几千万次操作,延迟只有几纳秒,比其他所有模型都快一个数量级。比如你写的日志异步落盘,单线程写日志,单线程刷盘;比如你做的网络数据处理,单线程收包,单线程解析,这种场景,用 SPSC 模型,绝对是最优解。
很多人总觉得,模型越复杂越牛逼,明明是 SPSC 的场景,非要用 MPMC,结果性能没上去,复杂度还翻了倍,真的没必要。
c
// 原子操作库,用于实现线程安全的无锁编程
#include <atomic>
// 固定宽度整数类型(如uint64_t),保证跨平台类型一致性
#include <cstdint>
// 智能指针库,用于管理环形缓冲区内存
#include <memory>
// 异常处理库(本代码未直接使用,属于模板类通用依赖)
#include <stdexcept>
/**
* @brief 单生产者单消费者(SPSC)无锁环形队列
* @tparam T 队列存储的元素类型
* @tparam Capacity 队列的最大容量
* 特点:无锁设计,仅支持一个生产者线程、一个消费者线程,高并发低延迟
*/
template <typename T, size_t Capacity>
class SPSCLockFreeQueue {
private:
// 环形缓冲区,使用智能指针自动管理内存,避免内存泄漏
std::unique_ptr<T[]> buffer_;
// 读指针(消费者专用):指向当前可读取的元素位置,原子类型保证线程安全访问
std::atomic<uint64_t> head_{0};
// 写指针(生产者专用):指向当前可写入的元素位置,原子类型保证线程安全访问
std::atomic<uint64_t> tail_{0};
/**
* @brief 环形缓冲区实际容量
* 环形队列设计:必须预留一个空位,用于区分【队列空】和【队列满】
* 空:head == tail
* 满:(tail + 1) % kCapacity == head
*/
static constexpr size_t kCapacity = Capacity + 1;
public:
// 构造函数:初始化指定大小的环形缓冲区
SPSCLockFreeQueue() : buffer_(std::make_unique<T[]>(kCapacity)) {}
// 析构函数:使用默认实现,智能指针会自动释放缓冲区内存
~SPSCLockFreeQueue() = default;
/**
* @brief 元素入队(生产者线程调用)
* @param value 要入队的元素
* @return 入队成功返回true,队列满返回false
*/
bool enqueue(const T& value) {
// 加载当前写指针,使用memory_order_relaxed:无同步需求,仅读取原子值
uint64_t current_tail = tail_.load(std::memory_order_relaxed);
// 计算下一个可写入的位置(环形队列取模实现回绕)
uint64_t next_tail = (current_tail + 1) % kCapacity;
// 判满:下一个写指针 == 读指针,说明队列已满
// memory_order_acquire:保证读取到最新的head_值,避免数据竞争
if (next_tail == head_.load(std::memory_order_acquire)) {
return false;
}
// 将元素写入当前写指针位置
buffer_[current_tail] = value;
// 更新写指针,memory_order_release:保证写入操作对消费者线程可见
tail_.store(next_tail, std::memory_order_release);
return true;
}
/**
* @brief 元素出队(消费者线程调用)
* @param value 出队元素的接收变量
* @return 出队成功返回true,队列空返回false
*/
bool dequeue(T& value) {
// 加载当前读指针,使用memory_order_relaxed:无同步需求,仅读取原子值
uint64_t current_head = head_.load(std::memory_order_relaxed);
// 判空:读指针 == 写指针,说明队列无元素可读取
// memory_order_acquire:保证读取到最新的tail_值,避免数据竞争
if (current_head == tail_.load(std::memory_order_acquire)) {
return false;
}
// 从当前读指针位置取出元素
value = buffer_[current_head];
// 计算下一个可读取的位置(环形队列取模实现回绕)
uint64_t next_head = (current_head + 1) % kCapacity;
// 更新读指针,memory_order_release:保证读取操作对生产者线程可见
head_.store(next_head, std::memory_order_release);
return true;
}
/**
* @brief 判断队列是否为空
* @return 空返回true,非空返回false
*/
bool empty() const {
// 内存序acquire:保证读取到最新的头尾指针
return head_.load(std::memory_order_acquire) == tail_.load(std::memory_order_acquire);
}
/**
* @brief 获取队列中当前的元素个数
* @return 元素数量
*/
size_t size() const {
uint64_t head = head_.load(std::memory_order_acquire);
uint64_t tail = tail_.load(std::memory_order_acquire);
// 分两种情况计算元素数量:
// 1. 写指针未回绕:直接相减
if (tail >= head) {
return tail - head;
}
// 2. 写指针已回绕:tail + 总容量 - head
else {
return tail + kCapacity - head;
}
}
};3.2 SPMC:单生产者多消费者
就是一个线程往队列里写,多个线程从队列里读。这种场景其实不多见,最典型的就是配置更新,单线程定时拉取最新的配置,放到队列里,多个工作线程从队列里拿配置更新。还有就是任务分发,单线程生成任务,多个线程消费任务。
这个模型的核心,是要处理多个消费者之间的读竞争,保证同一个元素不会被多个消费者重复消费。实现起来比 SPSC 复杂一点,但比多生产者的模型简单很多。
3.3 MPSC:多生产者单消费者
接下来就是整个行业里用得最多的,MPSC 模型,框架的最爱。
我敢说,你平时接触到的大部分业务场景,都是 MPSC 的场景。比如业务线程池,多个业务线程往任务队列里提交任务,单个核心线程消费任务;比如 Netty 的 IO 线程模型,多个业务线程往 Channel 的任务队列里写任务,单个 IO 线程消费执行;比如日志收集,多个业务线程写日志,单个落盘线程消费。
这种场景,多线程写,单线程读,写有竞争,读没有竞争,刚好契合 MPSC 模型的特性。MPSC 的实现复杂度,比 MPMC 低很多,但是性能却非常能打,所以几乎所有的主流框架,都用了 MPSC 模型的无锁队列。
我见过太多人,明明是 MPSC 的场景,非要用 MPMC 的队列,结果不仅性能没提升,还引入了很多不必要的复杂度,真的是画蛇添足。
3.4 MPMC:多生产者多消费者
全场景通吃但更复杂的 MPMC 模型,多个线程写,多个线程读,既要处理生产者之间的写竞争,也要处理消费者之间的读竞争,还要保证生产者和消费者之间的同步,实现复杂度是四个模型里最高的,坑也是最多的。
当然它的通用性也是最强的,不管什么场景都能用。比如 Kafka 的生产消费,多个业务线程生产消息,多个消费线程消费;比如高频交易系统的订单撮合,多个线程提交订单,多个线程撮合交易;比如 DPDK 的网络数据包处理,多个收包线程写队列,多个处理线程读队列,这些场景,都需要用到 MPMC 模型。
但你要记住,MPMC 的性能上限,是比 SPSC、MPSC 低的,因为它要处理更多的竞争,引入更多的 CAS 操作和内存屏障。所以能用更简单的模型解决的问题,绝对不要用 MPMC。
那,这四个模型到底怎么选?我给大家整理了一个对比表,你对着自己的业务场景选。
| 并发模型 | 性能上限 | 实现复杂度 | 核心适配场景 |
|---|---|---|---|
| SPSC 单生单消 | 最高 | 极低 | 日志异步落盘、单线程数据转发、双线程数据传递 |
| SPMC 单生多消 | 高 | 中等 | 配置更新、单线程任务分发、广播类数据同步 |
| MPSC 多生单消 | 中高 | 中等 | 业务线程池、Netty 任务队列、IO 事件处理、日志收集 |
| MPMC 多生多消 | 中等 | 极高 | 消息中间件生产消费、高频交易撮合、多核数据包并行处理 |
👉 【就业避坑】C++ 就业前景全解析:为什么劝退声不断,大厂核心岗仍刚需 C++?
👉 【大厂标准】Linux C/C++ 后端开发系统学习路线
👉 【音视频】音视频流媒体高级开发核心学习路径
👉 【Qt进阶】C++ Qt 桌面 & 嵌入式开发一条龙学习攻略
👉 【内核底层】Linux 内核硬核修炼指南
👉 【面试冲刺】C/C++ 高频八股面试题 1000 题(三)
👉 【项目实战】手撕线程池:C++ 程序员的能力试金石
四、工业级的无锁队列实现
聊完了模型,我们来实战,工业级的无锁队列实现
无锁队列不管什么模型,入队和出队的本质,都是对队列头尾指针的操作。入队,就是把新元素放到尾指针的位置,然后移动尾指针;出队,就是把头指针位置的元素取出来,然后移动头指针。无锁队列的所有复杂度,都来自于并发场景下,怎么保证头尾指针移动的原子性,不会出现竞态问题。
来看一个极简的 SPSC 无锁队列实现,用 C++ 写的,代码不多,但求把核心逻辑给大家讲清楚。
arduino
template<typename T>
class SpscArrayQueue {
alignas(64) T* buffer;
const size_t mask;
alignas(64) std::atomic<size_t> producerTail{0};
alignas(64) std::atomic<size_t> consumerHead{0};
public:
explicit SpscArrayQueue(size_t capacity) {
// 容量必须是2的幂,方便位运算取模
size_t realCapacity = 1;
while (realCapacity < capacity) realCapacity <<= 1;
buffer = new T[realCapacity]();
mask = realCapacity - 1;
}
~SpscArrayQueue() {
delete[] buffer;
}
// 禁止拷贝
SpscArrayQueue(const SpscArrayQueue&) = delete;
SpscArrayQueue& operator=(const SpscArrayQueue&) = delete;
// 入队,仅生产者线程调用
bool offer(const T& e) {
size_t pTail = producerTail.load(std::memory_order_relaxed);
size_t index = pTail & mask;
// 队列满校验:尾指针 - 头指针 == 数组容量
if (pTail - consumerHead.load(std::memory_order_acquire) == mask + 1) {
return false;
}
buffer[index] = e;
// Release语义更新尾指针,保证元素写入对消费者可见
producerTail.store(pTail + 1, std::memory_order_release);
return true;
}
// 出队,仅消费者线程调用
bool poll(T& out) {
size_t cHead = consumerHead.load(std::memory_order_relaxed);
// 队列空校验:头指针 == 尾指针
if (cHead == producerTail.load(std::memory_order_acquire)) {
return false;
}
size_t index = cHead & mask;
out = buffer[index];
buffer[index] = T{}; // 帮助析构/重置
// 更新头指针
consumerHead.store(cHead + 1, std::memory_order_release);
return true;
}
};你看,这个 SPSC 队列,连 CAS 都没用到,因为生产者只修改自己的尾指针,消费者只修改自己的头指针,没有多线程的写竞争,只需要靠 std::atomic 保证内存可见性和顺序性就行。日常的单生单消场景,这个实现完全够用,性能拉满。
接下来我们拆解工业级的 MPSC 无锁队列,就像 Netty 里用的 MpscQueue,这个在 C++ 世界里也有很多类似实现,比如 Folly 中的 MPMCQueue 也提供了相应模式。下面用 C++ 原子操作来体现其核心逻辑。
MPSC 无锁队列,底层基于循环数组实现,核心设计有几个很牛批的点:
第一个是缓存行填充,彻底解决伪共享问题。它把生产者指针、消费者指针都用缓存行填充隔离开,保证每个被多线程访问的变量都独占一个缓存行,完全避免了缓存乒乓效应。
第二个是多生产者入队的竞态处理。多个线程同时入队时,会通过 CAS 循环竞争更新生产者尾指针,谁 CAS 成功,谁就拿到了对应的数组槽位,写入元素后再发布。完美保证了多生产者同时入队,不会出现元素覆盖的问题。
第三个是消费者的无锁设计。因为只有一个消费者线程,消费者指针的修改完全不需要 CAS,只需要保证可见性就行,把读性能做到了极致。
下面是一段 MPSC 无锁队列的核心入队逻辑,用 C++ 原子操作展示它的设计:
arduino
template<typename T>
class MpscArrayQueue {
// 缓存行对齐的生产者索引
alignas(64) std::atomic<size_t> producerIndex{0};
// 缓存行对齐的消费者索引
alignas(64) std::atomic<size_t> consumerIndex{0};
const size_t mask;
T* const buffer;
public:
// ... 构造函数等
bool offer(const T& e) {
const size_t mask = this->mask;
size_t pIndex;
do {
pIndex = producerIndex.load(std::memory_order_relaxed);
size_t offset = pIndex & mask;
// 队列满校验:检查对应槽位是否已被消费(即不为空)
if (buffer[offset] != T{}) {
return false;
}
// CAS更新尾指针,拿到当前槽位的独占权
} while (!producerIndex.compare_exchange_weak(pIndex, pIndex + 1,
std::memory_order_acq_rel, std::memory_order_relaxed));
// 写入元素,Release 语义保证元素写入后队列指针更新对其他线程可见
buffer[pIndex & mask] = e;
return true;
}
// 单消费者出队略...
};你看,核心就是用 CAS 循环竞争生产者尾指针,谁 CAS 成功,谁就拿到了对应的数组位置。这里的满队列检查检查的是槽位是否还有未取走的元素;元素写入采用了 Release 语义,保证写入完成之后,消费者才能看到新的尾指针,不会出现读到空元素的问题。
这个队列,在多生产者单消费者的场景下,性能比加锁的队列高出数倍,所以在 Netty、Dubbo 等框架的核心链路里大量使用,C++ 中类似的实现也是高性能网络库的标配。
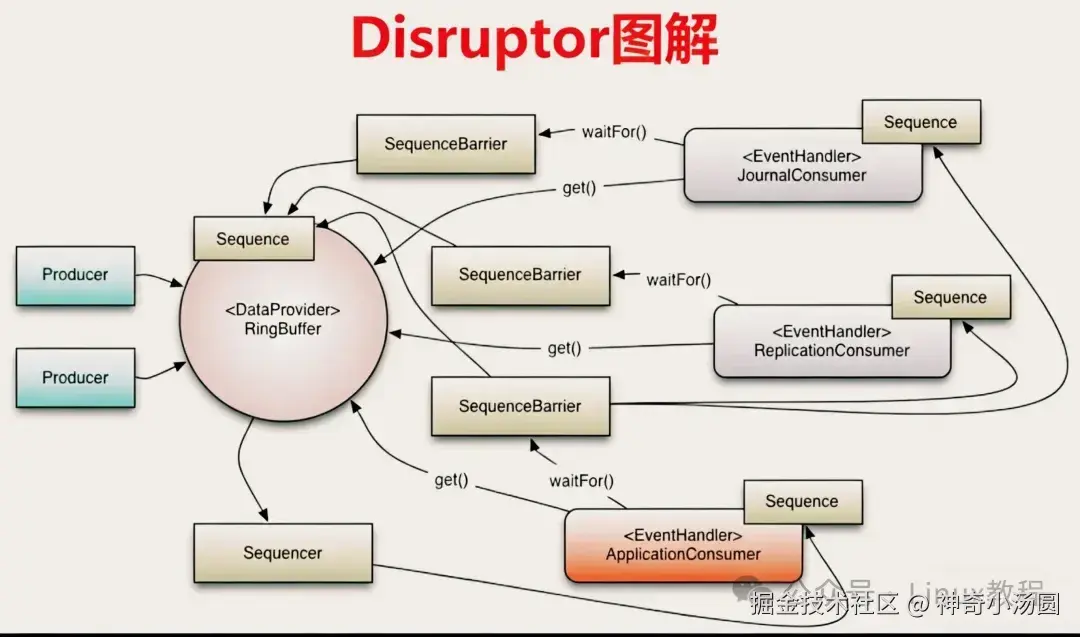
然后就是工业级的 MPMC 无锁队列,最经典的就是 Disruptor 的环形队列。Disruptor 是 LMAX 交易所开源的,当年号称单线程能做到每秒 600 万订单的处理,核心就是靠这个极致优化的 MPMC 无锁队列。
Disruptor 的设计和传统队列完全不一样,它没有头尾指针,而是用了序列号机制。每个生产者和消费者,都有自己独立的序列号,生产者要写入元素,先 CAS 申请对应的序列号,拿到之后写入元素,再发布序列号;消费者要读取元素,先检查自己要读的序列号有没有被发布,确认发布后再读取,读完更新自己的序列号。
它的核心优势,除了无锁设计,还有极致的缓存优化。每个序列号都做了缓存行填充,完全解决伪共享问题;环形数组预分配内存,所有元素提前初始化,没有节点的申请和释放,缓存友好性拉满;同时支持批量入队出队,大大降低了 CAS 的均摊开销。
聊到这里,必须提一下无锁队列里最头疼的问题:内存安全和节点回收。
尤其是链表结构的无锁队列,你出队的节点,什么时候能释放?如果节点被释放了,还有线程在引用它,就会出现内存访问越界,直接崩溃;如果一直不释放,就会内存泄漏。
这个问题,业界有三个成熟的解决方案:
第一个是 Hazard Pointer,也就是 hazard 指针。每个线程都维护自己的 hazard 指针,把当前正在引用的节点地址放到 hazard 指针里。要释放节点的时候,先检查所有线程的 hazard 指针,确认没有线程引用这个节点,才能释放。这个方案实现简单,适合线程数不多的场景。
第二个是 EBR,基于纪元的回收机制。它把时间分成一个个纪元,每个线程操作的时候,都标记自己当前所在的纪元。要释放的节点,先放到待释放列表里,等过了几个纪元之后,确定没有线程在引用这些节点了,再统一释放。性能比 Hazard Pointer 好很多,很多工业级实现都在用。
第三个是 RCU,读拷贝更新。这个是 Linux 内核里用得最多的机制,读操作完全无锁,写操作的时候,先拷贝一份数据,修改拷贝之后,再把原数据的指针指向新的拷贝,等所有正在引用原数据的线程都退出临界区之后,再释放原数据。读操作性能极致,适合读多写少的场景。
这些回收机制,是链表结构无锁队列的核心,你要是没搞懂,写出来的代码,不是内存泄漏,就是崩溃。
五、性能优化
很多人问我,为什么我抄了个大牛的无锁队列代码,性能还是上不去?
很简单,你只抄了核心逻辑,没做优化。无锁队列的性能,80% 都来自于细节优化,这些优化点,网上的教程很少会讲给你听。
无锁队列的核心性能瓶颈,说白了,就两个:一个是 CPU 缓存的利用率,也就是缓存命中率;另一个就是原子操作的开销,也就是 CAS 操作的次数。所有的优化,都是围绕这两个点来的。
头号优化手段,就是缓存行填充,彻底解决伪共享问题。
这个我前面提了好几次,因为它太重要了。我见过太多人写的无锁队列,性能上不去,全是因为伪共享。
再给你讲一遍,CPU 存取数据,是按缓存行来的,一般一个缓存行 64 字节。如果两个会被不同线程同时修改的变量,放在了同一个缓存行里,就会出现缓存乒乓效应。多个 CPU 核心来回抢这个缓存行的所有权,缓存行不停的失效、同步,CPU 的缓存命中率直接跌到谷底,性能直接腰斩。
怎么解决?很简单,缓存行填充。给每个会被多线程修改的变量,前后都填充一些无用的变量,让这个变量独占一个缓存行。比如 Java 里的 long 类型是 8 字节,一个缓存行 64 字节,那你就在变量前后各加 7 个 long 类型的变量,刚好填满一个缓存行。
Disruptor 就是这么做的,它的序列号类,前后各加了 7 个 long 类型的填充,保证每个序列号都独占一个缓存行,完全解决了伪共享问题。
我做过测试,同样的无锁队列,加了缓存行填充之后,吞吐量能提升 2-3 倍,延迟能降低一半以上。这个优化,是你必须要做的。
第二个核心优化,就是批量入队和出队操作。
CAS 操作是有开销的,哪怕它是硬件级的原子操作,每次 CAS 也要消耗几十纳秒。如果你每次入队出队都要做一次 CAS,那开销就很大。但如果你一次批量操作多个元素,只做一次 CAS,那就能把 CAS 的开销摊薄,吞吐量直接上去。
比如 Disruptor,就支持批量申请序列号,一次申请 100 个元素的序列号,只做一次 CAS,然后批量写入 100 个元素,再批量发布。这样一来,每个元素的 CAS 开销,就变成了原来的 1%,性能能不高吗?
我做过压测,同样的 MPMC 队列,批量操作的吞吐量,比单元素操作高 5-10 倍。尤其是在高并发场景下,批量操作的优势非常明显。
还有一些进阶的优化技巧,也能给你带来不小的性能提升。
第一个就是内存布局对齐。比如数组的起始地址,要对齐到缓存行的边界,保证数组里的元素,不会跨缓存行存储。不然你访问一个元素,要读两个缓存行,性能自然就差了。
第二个就是 NUMA 架构适配。现在的服务器,大多是 NUMA 架构,每个 CPU 插槽都有自己的本地内存,访问本地内存的速度,比访问远程内存快很多。所以你要保证,操作队列的线程,和队列的内存,在同一个 NUMA 节点上,不然延迟会翻好几倍。
第三个就是指令预取。CPU 支持指令预取,你可以在操作元素之前,提前把元素的内存预取到 CPU 缓存里,这样等你真正操作的时候,直接从缓存里拿,速度快很多。
当然,这些优化都是锦上添花,最核心的还是缓存行填充和批量操作,把这两个做好了,你的无锁队列性能,就超过了 90% 的实现。
我在 32 核的 x86 服务器上做过压测,队列容量 1024,每个线程操作 1000 万次,测试结果如下:
| 队列实现 | 并发模型 | 吞吐量(ops / 秒) | 平均延迟(ns) |
|---|---|---|---|
| ArrayBlockingQueue | MPMC | 120 万 | 830 |
| ConcurrentLinkedQueue | MPMC | 380 万 | 260 |
| 自研 SPSC 无锁队列 | SPSC | 8600 万 | 11 |
| Netty MpscQueue | MPSC | 2100 万 | 47 |
| Disruptor RingBuffer | MPMC | 1500 万 | 66 |
你看,SPSC 无锁队列的吞吐量,是 ArrayBlockingQueue 的 70 多倍,延迟只有它的 1/75。哪怕是最复杂的 MPMC 模型,Disruptor 的吞吐量,也是 ArrayBlockingQueue 的 12 倍多。
这就是无锁队列的威力。
六、无锁队列落地避坑
我写了这么多年无锁代码,踩过的坑能绕服务器机房一圈。将几个最容易踩的坑,以及对应的解决方案,帮大家少走点弯路。
第一个坑,也是最常见的,内存屏障误用导致的顺序性 bug。
很多人写无锁代码,只知道用 CAS,不知道内存屏障的重要性。该加内存屏障的地方没加,导致指令重排,代码出现各种诡异的 bug。最典型的,就是入队的时候,先更新了尾指针,再写入元素,导致消费者线程看到尾指针更新了,去读元素,结果元素还是空的,直接空指针。
这种 bug,最坑的地方就是复现概率极低。x86 是强内存模型,默认帮你保证了很多顺序性,你在 x86 上跑的好好的,一放到 ARM 架构的服务器上,就各种崩溃,根本没法调试。
怎么避免?很简单,严格遵守 Acquire 和 Release 语义。入队的时候,先写入元素,再用 Release 语义更新尾指针,保证元素写入完成之后,尾指针的更新才能被其他线程看到;出队的时候,先用 Acquire 语义读头指针,再读取元素,保证头指针读取之后,才能读取对应的元素。
还有,不要随便优化掉内存屏障,哪怕它在 x86 上是空操作,到了弱内存模型的架构上,它就是救命的。
第二个坑,伪共享问题的隐蔽场景。
很多人以为,给变量加了缓存行填充,就解决了伪共享问题,其实不然,伪共享的坑,比你想象的多得多。
比如,你写了一个父类,里面有个 volatile 变量,子类继承了父类,给子类的变量加了缓存行填充,结果父类的变量和子类的变量,还是在同一个缓存行里,伪共享还是存在。
再比如,数组里的相邻元素,被不同的线程修改。比如你搞了一个数组,每个线程对应数组里的一个元素,每个线程只修改自己对应的元素,结果这些元素在同一个缓存行里,还是会出现伪共享。
还有,JDK 的 GC 会做对象重排列,你加的填充变量,可能被 GC 重排之后,和其他变量放到了同一个缓存行里,白加了。
怎么定位?用 perf 工具,看 cache-misses 指标,如果你的队列运行的时候,cache-misses 非常高,那大概率就是伪共享导致的。怎么解决?除了缓存行填充,还可以用 Java 里的 @Contended 注解,JVM 会自动帮你处理缓存行填充,避免 GC 重排的问题。
第三个坑,无锁编程的常见陷阱,活锁和饥饿问题。
很多人以为,无锁就不会有锁的问题了,其实不然,无锁代码会出现活锁。什么是活锁?多个线程同时 CAS,都失败了,然后不停的重试,CPU 跑满了,但是啥活也没干,线程一直处于 "活" 的状态,但是一直没法完成操作。
最典型的场景,就是多个线程同时入队 MPMC 队列,都在 CAS 竞争尾指针,结果每次都有其他线程 CAS 成功,自己的 CAS 一直失败,不停的重试,活锁了。
还有饥饿问题,有的线程一直 CAS 成功,有的线程一直 CAS 失败,永远没法完成操作,就像被饿死了一样。
怎么解决?最常用的就是退避策略。CAS 失败之后,不要马上重试,先等待一小段时间,或者让出 CPU,降低竞争的激烈程度,避免活锁。还有就是公平性设计,比如给每个线程分配独立的槽位,保证每个线程都有机会拿到资源,避免饥饿。
第四个坑,边界场景的处理不到位。
很多人写的无锁队列,正常入队出队没问题,一到空队列、满队列的边界场景,就出问题。比如入队的时候,队列满了,没有正确处理,导致元素覆盖;出队的时候,队列空了,没有正确处理,导致读了空元素,甚至崩溃。
还有就是优雅退出的问题。很多人写的无锁队列,程序要退出的时候,直接把线程停了,结果队列里还有没处理完的元素,直接丢了。比如日志队列,程序退出的时候,还有很多日志没写到磁盘里,直接丢了,线上排查问题的时候,连日志都找不到。
怎么解决?边界场景一定要做严格的校验,入队的时候,一定要先检查队列是否满了,再 CAS 申请位置;出队的时候,一定要先检查队列是否为空,再读取元素。优雅退出的时候,一定要给生产者发停止信号,等生产者停止之后,消费者把队列里的所有元素都处理完,再退出线程,绝对不能直接停掉。
第五个坑,无锁队列的调试和线上问题排查。
无锁代码的 bug,大多是并发竞态导致的,复现概率极低,线下根本复现不出来,只有线上高并发的时候才会出现,调试起来非常困难。
很多人一遇到无锁队列的线上问题,就想加日志,结果日志一加,问题就没了,日志一删,问题又出现了。因为加日志会加锁,会改变线程的执行时序,把竞态条件给掩盖了,也就是我们常说的 "海森堡 bug"。
给你几个实用的排查技巧:
第一,线下压测的时候,一定要用压力测试工具,把并发拉满,长时间跑,尽量复现竞态问题。比如用 JMH 做压测,连续跑几个小时,看有没有异常。
第二,用硬件性能计数器,比如 perf,看 cache-misses、上下文切换、CPU 利用率这些指标,定位性能瓶颈和问题。
第三,不要在无锁的关键路径上加日志,要加也只能加无锁的日志,比如用我们前面说的 SPSC 队列,把日志写到队列里,异步落盘,不能加带锁的日志,不然会掩盖问题。
第四,写无锁代码的时候,一定要写单元测试,尤其是竞态场景的单元测试,用多线程反复操作,验证代码的正确性。
说出来你可能不信,以上这些坑,我大部分都都踩过~o(╥﹏╥)o
七、无锁队列高频面试点
很多人找我要面试考点,说面试的时候经常被问到无锁队列,我给大家总结了一些:
- CAS 的实现原理是什么?ABA 问题怎么解决?
- 什么是伪共享?怎么解决伪共享问题?
- 内存屏障的作用是什么?Acquire 和 Release 语义分别是什么?
- SPSC、SPMC、MPSC、MPMC 四个模型的区别和适用场景是什么?
- Disruptor 的核心原理是什么?它为什么这么快?
- 无锁队列的节点回收机制有哪些?分别有什么优劣?
- 无锁编程和加锁编程的区别是什么?分别有什么优劣?
把这些问题搞懂,面试的时候,无锁队列相关的问题,你就再也不怕了。
最后,如果你想深入研究无锁编程,可以参照下面这条完整的路线,一步一步来,别跳步:
第一步,先啃透并发编程的基础,包括线程、进程、锁机制、内存模型、指令重排这些基础概念,把这些搞懂,再谈无锁编程。
第二步,深入学习原子操作的底层原理,包括 MESI 缓存一致性协议、LOCK 指令前缀、CAS 原语、内存屏障、Acquire/Release 语义,这些是无锁编程的基石,必须啃透。
第三步,自己动手写一个最简单的 SPSC 无锁队列,跑通入队出队逻辑,做压测,理解无锁队列的核心逻辑。
第四步,深入学习 MPSC 模型,看 Netty MpscQueue 的源码,自己动手写一个 MPSC 无锁队列,理解多线程竞争的处理逻辑。
第五步,深入学习 MPMC 模型,看 Disruptor 的源码,理解环形队列、序列号机制、缓存优化的核心原理。
第六步,学习无锁队列的内存安全机制,包括 Hazard Pointer、EBR、RCU,自己动手实现一个简单的 Hazard Pointer,理解节点回收的逻辑。
第七步,看更多工业级的开源实现,比如 Boost.lockfree、Folly MPMCQueue、DPDK Ring,理解不同场景下的优化技巧。
第八步,自己动手写一个完整的 MPMC 无锁队列,做压测,做优化,和开源方案对比,找差距,不断优化。
啃透底层的每一个细节,你才能真正掌握无锁编程。