一、引言
在人工智能技术快速演进的今天,扩散模型(Diffusion Models)已成为生成式AI领域最具革命性的技术之一。从DALL-E 2、Midjourney到Stable Diffusion,这些令人惊艳的图像生成系统背后都基于扩散模型的核心原理。与传统的生成对抗网络(GAN)和变分自编码器(VAE)相比,扩散模型不仅生成质量更高,训练过程也更加稳定。本文将从资深AI科学家的视角,深入剖析扩散模型的数学原理、技术演进路径、工程实现细节以及最新研究进展,帮助读者构建对这一前沿技术的系统性认知。
扩散模型的核心思想源于非平衡热力学中的扩散过程,通过学习数据从噪声到真实样本的逆向去噪过程,实现高质量样本的生成。这一看似简单的思想,经过DDPM(Denoising Diffusion Probabilistic Models)Ho et al., 2020、Score-based Models Song et al., 2020等一系列理论创新,已经发展成为当今最强大的生成模型范式之一。
二、核心原理
2.1 前向扩散过程与马尔可夫链
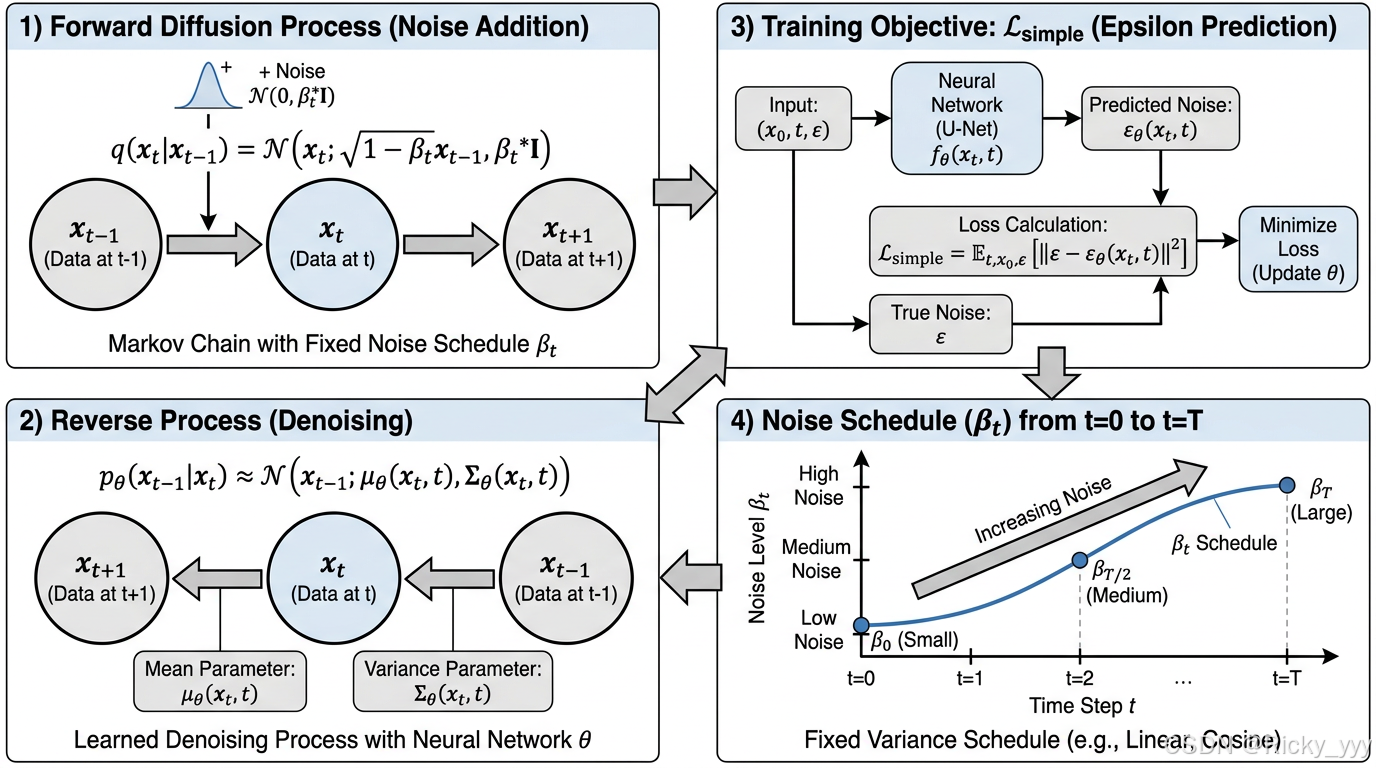
扩散模型的数学基础建立在马尔可夫链(Markov Chain)之上。前向扩散过程定义为从真实数据分布 q ( x 0 ) q(x_0) q(x0) 逐步添加高斯噪声,直到数据完全变为各向同性的高斯噪声。这个过程可以表示为:
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{1-\beta_t}x_{t-1}, \beta_t I) q(xt∣xt−1)=N(xt;1−βt xt−1,βtI)
其中 β t ∈ ( 0 , 1 ) \beta_t \in (0,1) βt∈(0,1) 是时间步 t t t 的噪声调度参数(noise schedule),控制每一步添加噪声的强度。通过重参数化技巧(reparameterization trick),我们可以直接从 x 0 x_0 x0 采样任意时间步 t t t 的噪声数据:
x t = α ˉ t x 0 + 1 − α ˉ t ϵ , ϵ ∼ N ( 0 , I ) x_t = \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1-\bar{\alpha}_t}\epsilon, \quad \epsilon \sim \mathcal{N}(0,I) xt=αˉt x0+1−αˉt ϵ,ϵ∼N(0,I)
其中 α t = 1 − β t \alpha_t = 1-\beta_t αt=1−βt, α ˉ t = ∏ i = 1 t α i \bar{\alpha}t = \prod{i=1}^t \alpha_i αˉt=∏i=1tαi。这一公式的优雅之处在于,它将 T T T 步的马尔可夫链压缩为一步采样,极大提升了训练效率。
2.2 逆向去噪过程与条件概率
生成过程的本质是学习前向过程的逆过程,即从纯噪声 x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0,I) xT∼N(0,I) 逐步去噪恢复到真实数据 x 0 x_0 x0。逆向过程同样是马尔可夫链:
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_\theta(x_{t-1}|x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t)) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
其中 μ θ \mu_\theta μθ 和 Σ θ \Sigma_\theta Σθ 是由神经网络参数化的均值和方差。DDPM的关键贡献是证明了当前向过程的噪声足够小时,逆向过程的条件分布也近似为高斯分布,且方差可以固定为 σ t 2 I \sigma_t^2 I σt2I,只需学习均值函数。
2.3 训练目标与变分下界
扩散模型的训练目标是最大化数据的对数似然 log p θ ( x 0 ) \log p_\theta(x_0) logpθ(x0)。通过变分推断,可以推导出证据下界(ELBO):
L = E q − log p θ ( x 0 ∣ x 1 ) + ∑ t = 2 T D K L ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) \mathcal{L} = \mathbb{E}_q\left-\\log p_\\theta(x_0\|x_1) + \\sum_{t=2}\^T D_{KL}(q(x_{t-1}\|x_t,x_0) \\\| p_\\theta(x_{t-1}\|x_t))\\right L=Eq−logpθ(x0∣x1)+t=2∑TDKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))
实践中,DDPM简化为预测每一步添加的噪声 ϵ \epsilon ϵ,训练目标变为均方误差损失:
L s i m p l e = E t , x 0 , ϵ ∥ ϵ − ϵ θ ( x t , t ) ∥ 2 \mathcal{L}{simple} = \mathbb{E}{t,x_0,\epsilon}\left\\\|\\epsilon - \\epsilon_\\theta(x_t, t)\\\|\^2\\right Lsimple=Et,x0,ϵ∥ϵ−ϵθ(xt,t)∥2
这一简化不仅降低了实现复杂度,还意外地提升了生成质量,成为后续研究的标准范式。
2.4 评分函数与Langevin动力学
从另一个视角,扩散模型等价于学习数据分布的评分函数(score function) ∇ x t log q ( x t ) \nabla_{x_t}\log q(x_t) ∇xtlogq(xt)。基于评分的生成模型(Score-based Generative Models)Song et al., 2020通过以下随机微分方程(SDE)描述扩散过程:
d x = f ( x , t ) d t + g ( t ) d w dx = f(x,t)dt + g(t)dw dx=f(x,t)dt+g(t)dw
其中 f ( ⋅ , t ) f(\cdot,t) f(⋅,t) 是漂移系数, g ( t ) g(t) g(t) 是扩散系数, w w w 是维纳过程。逆向SDE为:
d x = f ( x , t ) − g ( t ) 2 ∇ x log p t ( x ) d t + g ( t ) d w ˉ dx = \leftf(x,t) - g(t)\^2\\nabla_x\\log p_t(x)\\rightdt + g(t)d\bar{w} dx=f(x,t)−g(t)2∇xlogpt(x)dt+g(t)dwˉ
通过训练神经网络拟合评分函数 s θ ( x , t ) ≈ ∇ x log p t ( x ) s_\theta(x,t) \approx \nabla_x\log p_t(x) sθ(x,t)≈∇xlogpt(x),可以使用常微分方程(ODE)求解器或Langevin动力学进行采样。这一统一框架连接了离散时间的DDPM和连续时间的SDE,为后续的加速采样算法奠定了理论基础。
三、技术演进
3.1 从深度生成模型到扩散模型
生成模型的发展经历了多个阶段。早期的变分自编码器(VAE)Kingma et al., 2013通过潜在空间建模实现了数据生成,但生成样本往往模糊不清。生成对抗网络(GAN)Goodfellow et al., 2014通过对抗训练大幅提升了生成质量,但训练不稳定和模式崩塌(mode collapse)问题始终困扰着研究者。
扩散模型的早期探索可以追溯到Sohl-Dickstein等人2015年的开创性工作,但直到2020年Ho等人提出DDPM,扩散模型才真正走向成熟。DDPM通过简化的训练目标和精心设计的噪声调度,首次在图像生成任务上超越了GAN,且训练过程稳定可靠。
3.2 加速采样:从DDPM到DDIM
DDPM的一个主要缺陷是采样速度慢,通常需要1000步迭代才能生成高质量样本。Song等人2021年提出的DDIM(Denoising Diffusion Implicit Models)Song et al., 2021通过将生成过程重新表述为确定性的常微分方程(ODE),实现了加速采样。DDIM的关键创新在于引入了非马尔可夫前向过程,使得可以跳步采样,将生成步数从1000降低到50甚至10步,而生成质量几乎不损失。
随后,一系列采样加速方法相继提出,包括基于变分推断的Analytic-DPM Bao et al., 2022、基于知识蒸馏的Progressive Distillation Salimans et al., 2022,以及最新的Consistency Models Song et al., 2023,将单步生成变为可能。
3.3 条件生成与引导机制
为了实现可控生成,研究者们提出了多种条件扩散模型。Classifier Guidance Dhariwal et al., 2021通过在采样过程中引入预训练分类器的梯度,实现了类别条件生成,但需要额外训练分类器。Classifier-Free Guidance Ho et al., 2022则通过在训练时随机丢弃条件信息,使得模型同时学习条件和无条件分布,采样时通过插值实现引导,成为当前主流方案。
文本到图像生成的突破来自于将大规模语言模型(如CLIP)与扩散模型结合。DALL-E 2 Ramesh et al., 2022使用CLIP编码文本,通过先验模型(prior)将文本嵌入映射到图像空间,再用扩散模型解码生成图像。Stable Diffusion Rombach et al., 2022则在VAE的潜在空间中进行扩散,大幅降低了计算成本,使得高分辨率生成成为可能。
四、实现细节
4.1 网络架构:U-Net与Transformer
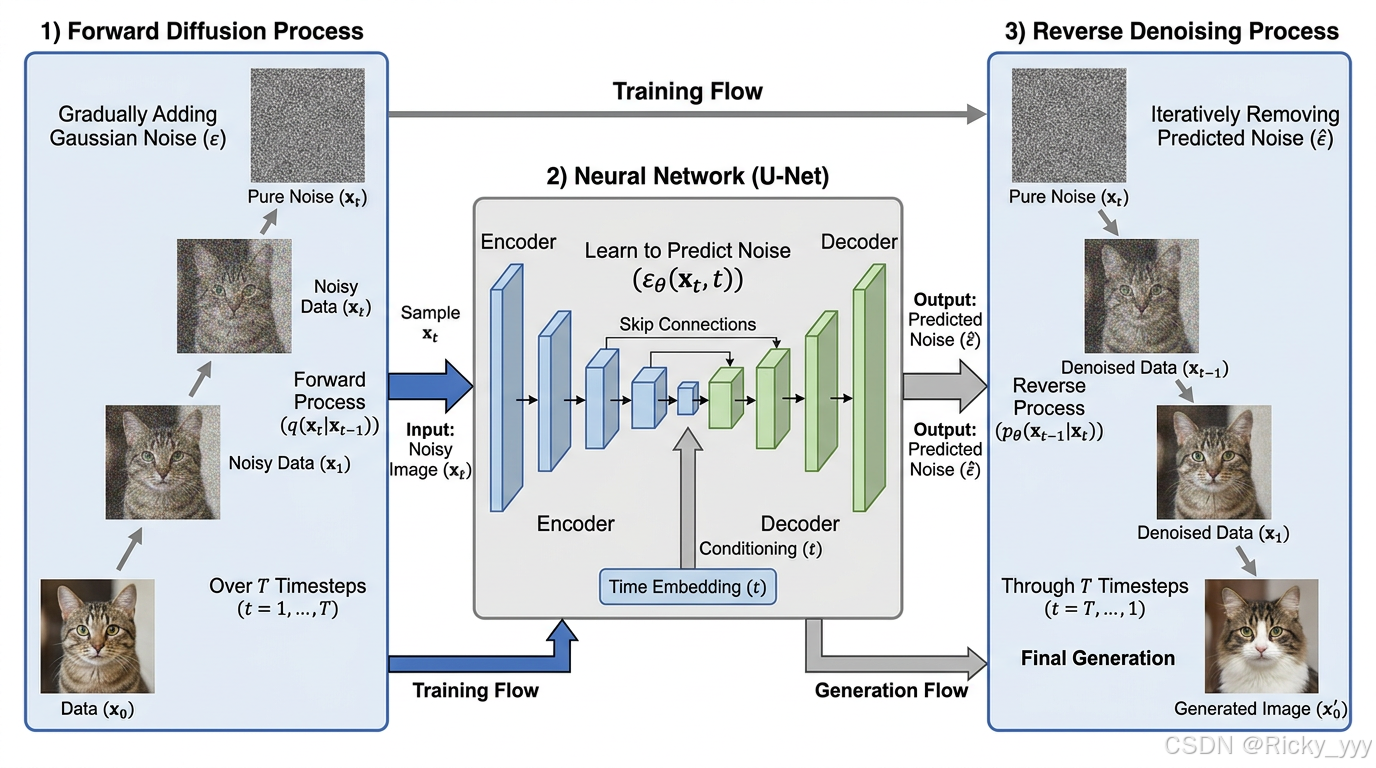
扩散模型的去噪网络通常采用U-Net架构,这一设计源于图像分割任务。U-Net通过编码器-解码器结构和跳跃连接(skip connections),有效地传递多尺度特征,非常适合图像去噪任务。
现代扩散模型的U-Net通常包含以下关键组件:
-
时间步嵌入(Time Embedding) :将时间步 t t t 通过正弦位置编码转换为高维向量,注入到每个残差块中,使网络感知当前的噪声水平。
-
残差块(Residual Blocks):包含GroupNorm、SiLU激活函数和卷积层,增强网络的表达能力。
-
注意力机制(Attention Layers):在低分辨率特征图上插入自注意力层,捕获全局依赖关系。
-
交叉注意力(Cross-Attention):用于条件生成,将文本嵌入与图像特征融合。
以下是一个简化的DDPM训练代码示例(PyTorch实现):
python
import torch
import torch.nn as nn
class DiffusionModel(nn.Module):
def __init__(self, unet, timesteps=1000):
super().__init__()
self.unet = unet
self.timesteps = timesteps
# 定义噪声调度(线性调度)
self.betas = torch.linspace(1e-4, 0.02, timesteps)
self.alphas = 1 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
def forward_diffusion(self, x0, t, noise=None):
"""前向扩散过程:添加噪声"""
if noise is None:
noise = torch.randn_like(x0)
sqrt_alphas_cumprod_t = self.alphas_cumprod[t].sqrt().view(-1, 1, 1, 1)
sqrt_one_minus_alphas_cumprod_t = (1 - self.alphas_cumprod[t]).sqrt().view(-1, 1, 1, 1)
# x_t = sqrt(alpha_bar_t) * x_0 + sqrt(1-alpha_bar_t) * noise
return sqrt_alphas_cumprod_t * x0 + sqrt_one_minus_alphas_cumprod_t * noise
def training_step(self, x0):
"""训练步骤"""
batch_size = x0.shape[0]
# 随机采样时间步
t = torch.randint(0, self.timesteps, (batch_size,), device=x0.device)
# 生成噪声
noise = torch.randn_like(x0)
# 前向扩散
x_t = self.forward_diffusion(x0, t, noise)
# 预测噪声
predicted_noise = self.unet(x_t, t)
# 计算MSE损失
loss = nn.functional.mse_loss(predicted_noise, noise)
return loss
@torch.no_grad()
def sample(self, shape, device):
"""逆向采样生成新样本"""
# 从纯噪声开始
x_t = torch.randn(shape, device=device)
# 逐步去噪
for t in reversed(range(self.timesteps)):
# 预测噪声
t_batch = torch.full((shape[0],), t, device=device, dtype=torch.long)
predicted_noise = self.unet(x_t, t_batch)
# 计算去噪后的x_{t-1}
alpha_t = self.alphas[t]
alpha_bar_t = self.alphas_cumprod[t]
beta_t = self.betas[t]
# DDPM采样公式
if t > 0:
noise = torch.randn_like(x_t)
else:
noise = 0
x_t = (1 / alpha_t.sqrt()) * (x_t - (beta_t / (1 - alpha_bar_t).sqrt()) * predicted_noise)
x_t = x_t + (beta_t.sqrt()) * noise
return x_t4.2 噪声调度策略
噪声调度(noise schedule)是扩散模型的关键超参数,直接影响生成质量。常见的调度策略包括:
-
线性调度(Linear Schedule) : β t \beta_t βt 在 10 − 4 , 0.02 10\^{-4}, 0.02 10−4,0.02 之间线性增长,DDPM的默认选择。
-
余弦调度(Cosine Schedule) :Nichol et al., 2021提出的改进方案, α ˉ t = cos 2 ( t / T + s 1 + s π 2 ) \bar{\alpha}_t = \cos^2(\frac{t/T + s}{1+s}\frac{\pi}{2}) αˉt=cos2(1+st/T+s2π),避免了线性调度在接近端点时的问题。
-
学习调度(Learned Schedule):将噪声调度作为可学习参数,通过端到端训练优化。
实验表明,余弦调度在大多数任务上优于线性调度,已成为当前的标准选择。
4.3 潜在扩散模型(Latent Diffusion Models)
直接在像素空间进行扩散计算成本高昂,尤其是对于高分辨率图像。Stable Diffusion采用的潜在扩散模型(LDM)Rombach et al., 2022先用VAE将图像编码到低维潜在空间,再在潜在空间进行扩散,大幅降低了计算量。
LDM的训练分为两个阶段:
-
阶段一:训练自编码器(通常是KL-VAE或VQ-VAE),学习从像素空间到潜在空间的映射。
-
阶段二:在潜在空间训练扩散模型,条件信息(如文本)通过交叉注意力注入。
这一设计使得在消费级GPU上训练和推理高分辨率扩散模型成为可能,是扩散模型走向实用化的关键技术。
五、应用场景
扩散模型已在多个领域展现出强大的应用潜力:
-
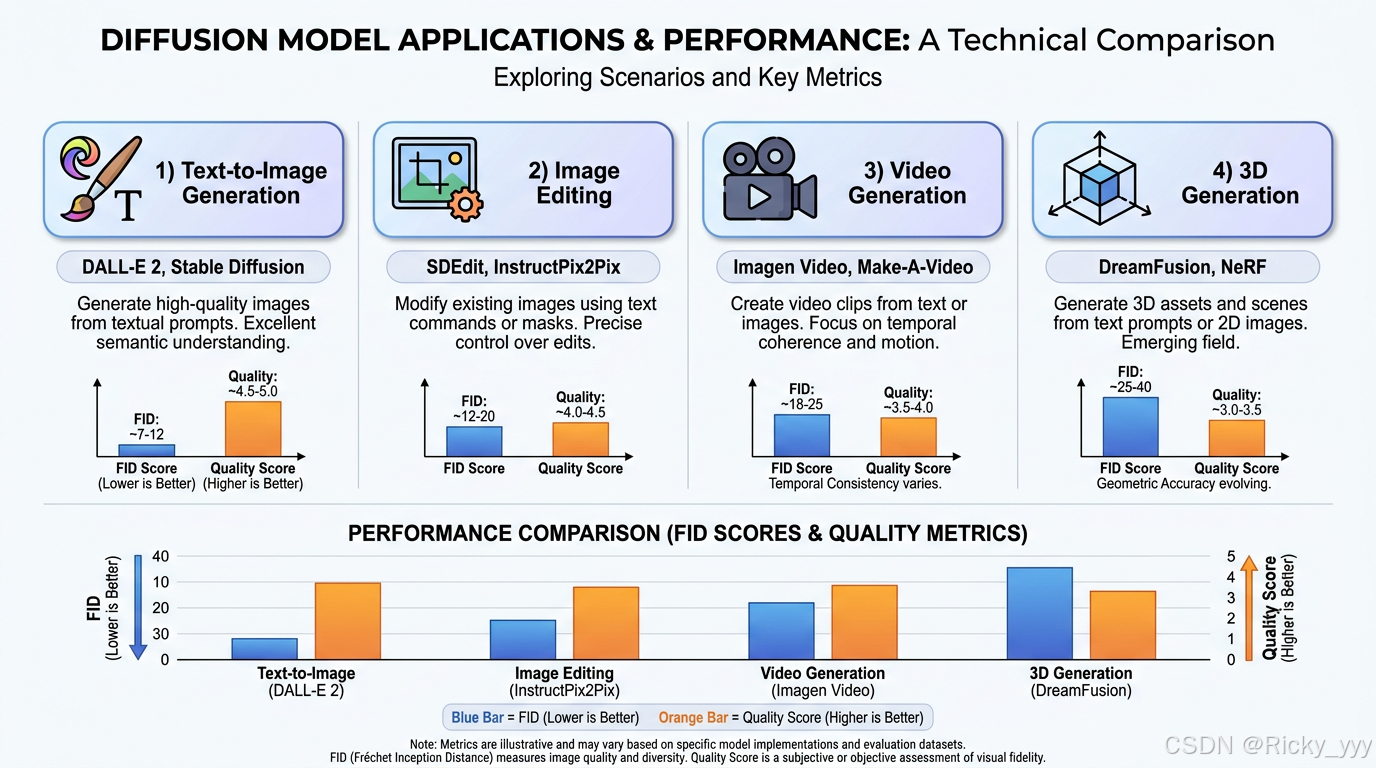
文本到图像生成(Text-to-Image):DALL-E 2、Midjourney、Stable Diffusion等工具已广泛应用于艺术创作、广告设计、游戏开发等领域,为创意工作者提供了全新的生产力工具。
-
图像编辑(Image Editing):通过反演(inversion)技术将真实图像映射到潜在空间,再结合文本引导进行局部或全局编辑,实现如风格迁移、物体替换、背景生成等功能。代表性工作包括SDEdit Meng et al., 2021、InstructPix2Pix Brooks et al., 2023等。
-
视频生成(Video Generation):将扩散模型扩展到时空域,实现连贯的视频生成。Imagen Video Ho et al., 2022、Make-A-Video Singer et al., 2022等工作已展示出令人印象深刻的视频生成能力。
-
3D生成(3D Generation):结合神经辐射场(NeRF)和扩散模型,从文本或图像生成3D模型。DreamFusion Poole et al., 2022通过Score Distillation Sampling实现了无需3D训练数据的3D生成。
-
医学图像处理:扩散模型在医学图像去噪、超分辨率、合成等任务上表现出色,已开始应用于CT、MRI等医学影像的增强和分析。
六、最新研究
扩散模型依然是AI研究的热点,近期的前沿进展包括:
-
一致性模型(Consistency Models):Song et al., 2023提出的创新框架,通过学习自一致性函数,实现了单步生成,将采样时间压缩到毫秒级,且生成质量与多步扩散模型相当。
-
离散扩散模型(Discrete Diffusion):将扩散模型扩展到离散数据,如文本和分子结构。Austin et al., 2021提出的D3PM(Discrete Denoising Diffusion Probabilistic Models)在文本生成任务上取得了与自回归模型竞争的性能。
-
扩散Transformer(DiT):Peebles et al., 2023用纯Transformer替换U-Net,结合Patch化处理,在图像生成上超越了基于U-Net的扩散模型,展示了架构创新的潜力。
-
Flow Matching:Lipman et al., 2023提出的连续归一化流(Continuous Normalizing Flows)的变体,通过直接学习最优传输路径简化训练过程,在某些任务上优于传统扩散模型。
-
可控生成与可解释性:研究者们正在探索如何增强扩散模型的可控性和可解释性,如通过语义解耦、属性编辑、因果干预等技术实现更精细的生成控制Zhang et al., 2024。
七、总结
扩散模型作为生成式AI的核心技术,已经从理论构想发展为改变行业格局的实用工具。其优雅的数学框架、稳定的训练过程和卓越的生成质量,使其在图像、视频、3D等多个领域都展现出巨大潜力。从DDPM奠定的理论基础,到DDIM、Classifier-Free Guidance等技术创新,再到Stable Diffusion等开源项目的普及,扩散模型的发展速度令人瞩目。
然而,扩散模型仍面临采样速度、计算成本、可控性等挑战。一致性模型、Flow Matching等新兴方向为解决这些问题提供了新思路。随着理论研究的深入和工程优化的持续,扩散模型必将在更多领域发挥关键作用,推动人工智能技术迈向新的高度。对于AI研究者和工程师而言,深入理解扩散模型的原理和实践,已成为把握生成式AI时代机遇的必备能力。