缓存击穿、穿透、雪崩一次讲透:附 Redis hotkey 实战
导读:写过后端的同学,多少都被这三兄弟教做人过。如果你刚接触 Redis 缓存,看完这篇你能分清缓存击穿、穿透、雪崩的本质差别,并在生产里挑出合适的治理方案;如果你已经被坑过,本文会把"为什么这个方案治这个病"讲得让你能复述给别人听。
一、先把三者放在一起:它们其实是同一件事的三种姿势
很多人背面试题时把缓存击穿、穿透、雪崩当成三个独立概念,记完就忘。我的判断是:这三个问题本质上是同一件事------缓存失效导致请求直达数据库------只是失效的"姿势"不同。把它们放在一起看,治理思路就清晰了。
缓存失效三姿势(一句话版):
- 穿透 :要的 key 在缓存和数据库里都不存在,每次都打 DB。
- 击穿 :一个热 key 在缓存里刚好过期,瞬间高并发全打 DB。
- 雪崩 :一大片 key 在同一时刻过期,或 Redis 整个挂了,请求全打 DB。
我给你一个生活化类比:缓存就是商店的"前台小抽屉",数据库是"后仓"。
- 穿透 = 客人要的东西抽屉没有、后仓也没有,但他每隔一秒就问你一遍,你被问麻了。
- 击穿 = 抽屉里那件爆款商品刚好售罄下架,瞬间几十个客人挤到后仓抢货。
- 雪崩 = 抽屉整个被人搬走了,或者一整排抽屉同时被锁了,所有客人都涌向后仓。
先看这张三大问题对比图,建立整体印象:

记住了这张图,后面每一节的方案都是在解决"如何挡住冲向数据库的那波请求"。
二、缓存穿透:数据库压根没这条数据
缓存穿透的核心特征是"查的东西压根不存在",所以缓存永远不会生效 。攻击者最喜欢这种姿势------用 user:-1、user:99999999 这种永远查不到的 key 把数据库拖垮。
可能有人会问:缓存里查不到,那就去数据库查一次呗,反正就一次?
不行。穿透的危险就在于"永远查不到",所以同一个非法 key 每次都会打到数据库。如果有人用脚本刷你,QPS 一高数据库就挂。判断句:穿透不是性能问题,是安全问题。
先看请求是怎么一路打到数据库的:
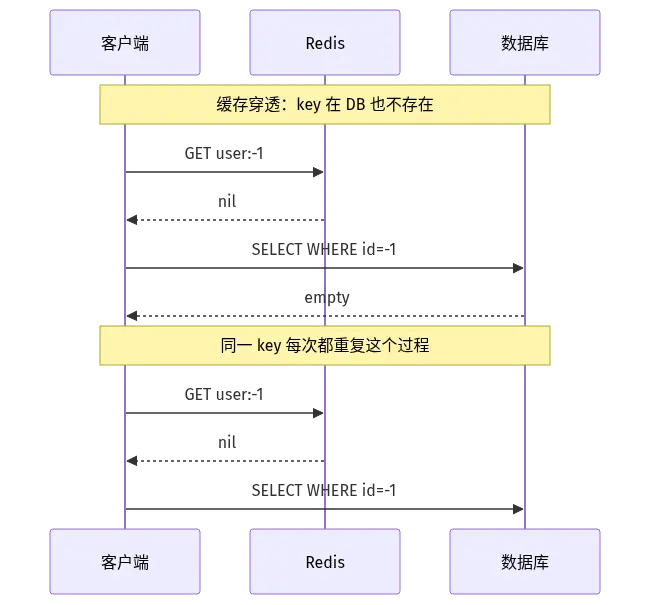
治理穿透有三条路,按落地难易度递增:
1)参数校验 + 黑名单 :在网关或 Service 入口对参数做格式校验,把 id <= 0、负数、明显非法的 key 直接挡掉。这是最便宜的一道闸。
2)缓存空值(Cache Null) :数据库查不到时,往 Redis 写一个 nil 占位值,TTL 设短一点(比如 60 秒)。下次同样的 key 来了,缓存命中空值直接返回,不再打 DB。代价是占用一点内存,且短期内"数据库新增了这条数据但缓存还是空值"造成短暂不一致。
3)布隆过滤器(Bloom Filter):在缓存之前再加一层"存在性判断",把数据库里真实存在的 key 预先放进布隆过滤器。请求来了先过布隆过滤器,说"不存在"就直接拒绝,说"可能存在"再去查 Redis/DB。
布隆过滤器(Bloom Filter):一种空间效率极高的概率型数据结构,用位数组 + 多个哈希函数判断"某元素是否在集合中"。你可以理解为"一个会撒谎说'可能在'、但绝不说谎说'不在'的安检门"。
布隆过滤器的原理看图最直观:
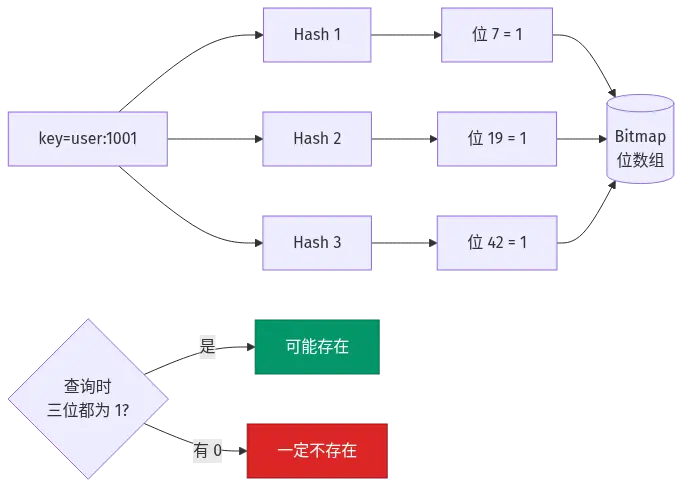
布隆过滤器有两个绕不开的缺点:有误判 (说"可能在"时其实可能不在,叫假阳性),不支持删除 (数据库删了一条记录,布隆过滤器没法同步删位)。如果你需要删除,得用 Bloom Filter 的变体------布谷鸟过滤器(Cuckoo Filter),Redis 的 RedisBloom 模块里都有。
我的建议是:参数校验必做,缓存空值做兜底;只有当非法 key 的种类多到缓存空值都浪费内存时,才上布隆过滤器。
三、缓存击穿:一个热 key 突然没了
缓存击穿的关键词是"热 key "和"刚好过期"。一个被高并发访问的 key(比如爆款商品详情),在 TTL 到期的瞬间,几千个线程同时发现缓存 miss,全部冲向数据库。
缓存击穿(Hot Key Problem):某个被高并发访问、缓存重建成本较高的 key 在 TTL 到期瞬间失效,瞬间把请求压力转嫁给数据库。和穿透的最大差别:穿透是"压根不存在",击穿是"存在但缓存没了"。
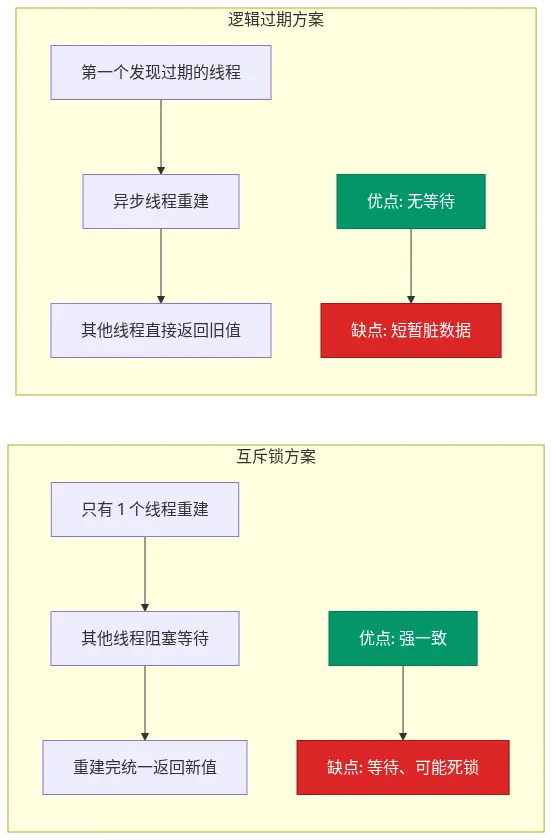
治理击穿的主流方案就两个:互斥锁 和逻辑过期。我用我踩过的坑给你对比讲。
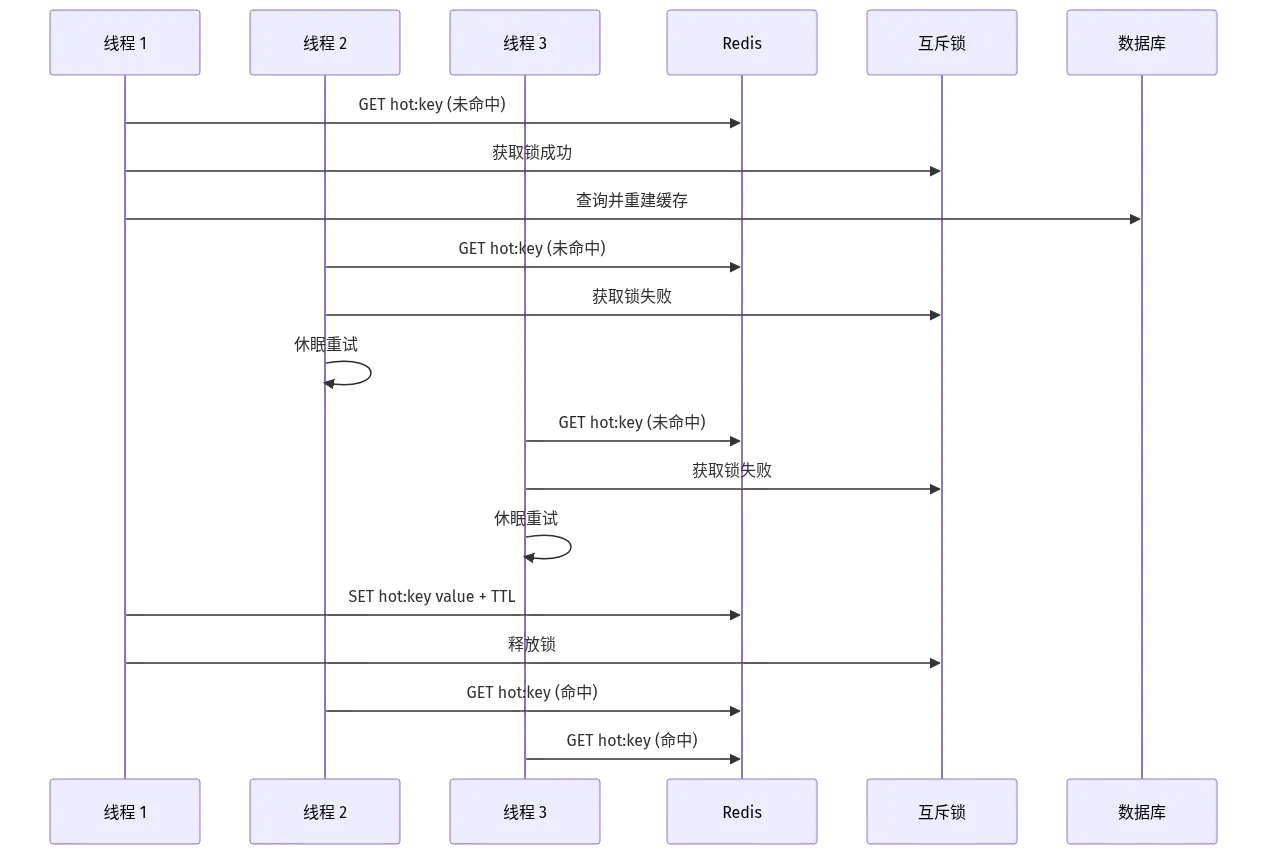
1)互斥锁:只让一个线程去重建
第一个线程发现 miss 后,先抢一把分布式锁(Redis 的 SET NX PX 即可),抢到的去查 DB 重建缓存;抢不到的就休眠重试,等缓存填好后直接读。注意要做双重检查:拿到锁后再查一次缓存,避免重复重建。
互斥锁的时序长这样:
Java 伪代码(用 Redisson 最省心):
java
// 示例:互斥锁重建缓存
String value = redis.get(key);
if (value == null) {
RLock lock = redisson.getLock("lock:" + key);
if (lock.tryLock(3, 10, TimeUnit.SECONDS)) {
try {
value = redis.get(key); // 双重检查
if (value == null) {
value = db.query(key);
redis.set(key, value, 30, TimeUnit.MINUTES);
}
} finally { lock.unlock(); }
} else {
Thread.sleep(50); return get(key); // 重试
}
}互斥锁的代价是线程阻塞等待 ,高并发下吞吐会被拖一点;好处是强一致,所有人拿到的都是新值。
2)逻辑过期:不设 TTL,自己埋过期时间
热 key 永不设 Redis TTL,把"过期时间"作为一个字段写进 value 里。请求来了先取 value,看逻辑过期时间是否到期------没过期直接返回;过期了,第一个发现过期的线程抢一把锁,异步 起一个新线程去查 DB 重建缓存,自己和其他线程直接返回旧数据。
逻辑过期的时序:
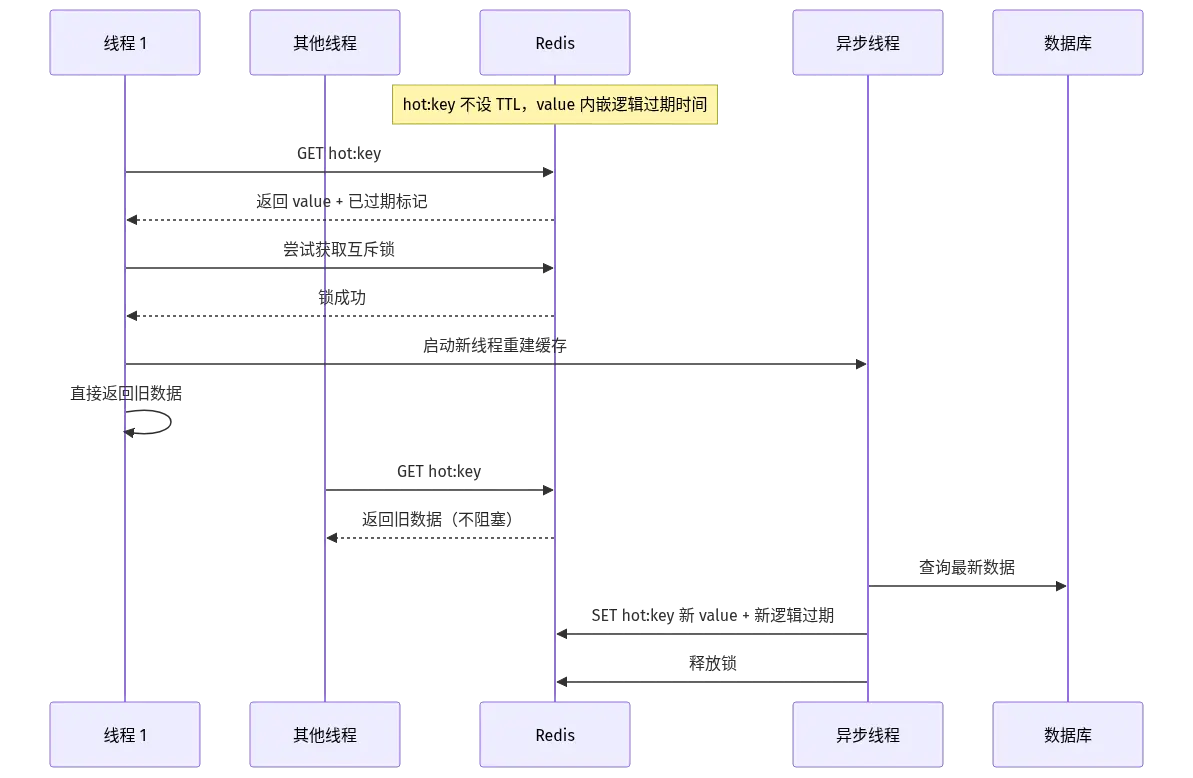
可能有人会问:返回旧数据不会出事吗?
取决于业务。商品详情、热门帖子这类能容忍短暂脏数据 的场景非常适合;金融账户、库存这类强一致场景千万别用。我的判断是:逻辑过期是给"展示型热 key"准备的,不是给"交易型热 key"准备的。
3)互斥锁 vs 逻辑过期:一张对比图说清
两套方案的本质差别是"要不要让线程等":
| 维度 | 互斥锁 | 逻辑过期 |
|---|---|---|
| 一致性 | 强一致 | 短暂脏数据 |
| 性能 | 线程阻塞,吞吐略降 | 无等待,吞吐高 |
| 实现复杂度 | 中(要处理死锁、重试) | 高(要异步线程、value 嵌字段) |
| 适用场景 | 交易、账户、库存 | 商品详情、热帖、首页推荐 |
四、缓存雪崩:一大片 key 一起没了
雪崩的特征是"批量失效 "或"Redis 整体不可用"。最经典的诱因是:批量预热的 key 用了同一个 TTL,时间一到集体过期;或者 Redis 主节点宕机、哨兵还没切完。
缓存雪崩(Cache Avalanche):同一时刻大量 key 同时失效或 Redis 服务整体宕机,导致海量请求同时打到数据库,造成数据库压力骤增甚至宕机。和击穿的区别:击穿是"一个热 key",雪崩是"一大批 key"。
雪崩的治理思路要分两种诱因看:
诱因一:大量 key 同时过期。 给 TTL 加随机偏移是最便宜的招:TTL = base + random(0, 300s),让过期时间分散开。对热点 key 做缓存预热 ,业务高峰前手动续命。对不常变的数据,干脆不设 TTL,靠异步任务去更新或淘汰。
诱因二:Redis 整体宕机。 这不是 TTL 能解决的事,要靠高可用 + 兜底:Redis 集群(Cluster)或哨兵(Sentinel)保证可用性;服务端用 Hystrix/Sentinel 做限流、熔断、降级;多级缓存(本地 Caffeine + Redis + DB)做兜底。
整张图看清雪崩的防护面:
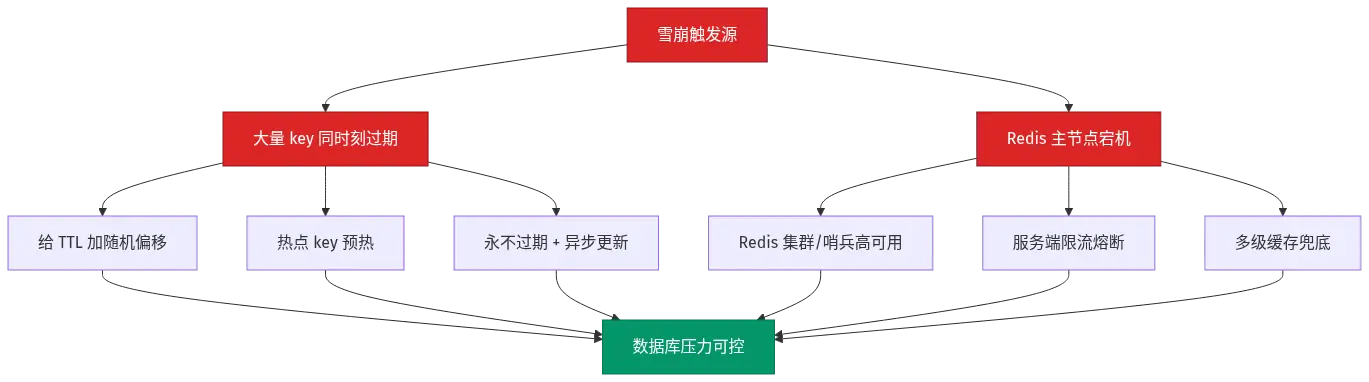
我的实践经验是:TTL 随机化是雪崩治理的底线,没做的项目今天就该补上;Redis 集群是中大型项目的标配;限流熔断是最后一道闸,决定了数据库会不会真被打挂。
五、延伸:hotkey 探测------治本而不是治标
讲到击穿和雪崩,你会发现"热 key"是反复出现的角色。前面互斥锁、逻辑过期都是在"热 key 已经失效"之后的兜底,那有没有办法在热 key 失效之前就把它识别出来,提前缓存到本地内存?有,这就是 hotkey 探测中间件干的事。
1)为什么需要 hotkey 探测
hotkey(热点 key):在一段时间内被高频访问的 Redis key。它的危害不只是缓存失效时的击穿,还包括:单分片 Redis 的 CPU/网卡打满、集群场景下流量倾斜、跨节点请求放大。
判断句:当你能在日志里看到某个 key 的 QPS 异常高时,往往已经晚了。手动埋点统计费时费力,且无法在大促前夜临阵换枪。京东开源的 hotkey 框架就是为了解决这个问题------它在 618、双 11 大促里每天探测数十亿个 key,worker 集群秒级吞吐量达到 1500 万级,是真正经历过实战的方案。
2)hotkey 整体架构
hotkey 由四个核心组件构成,看架构图最清楚:
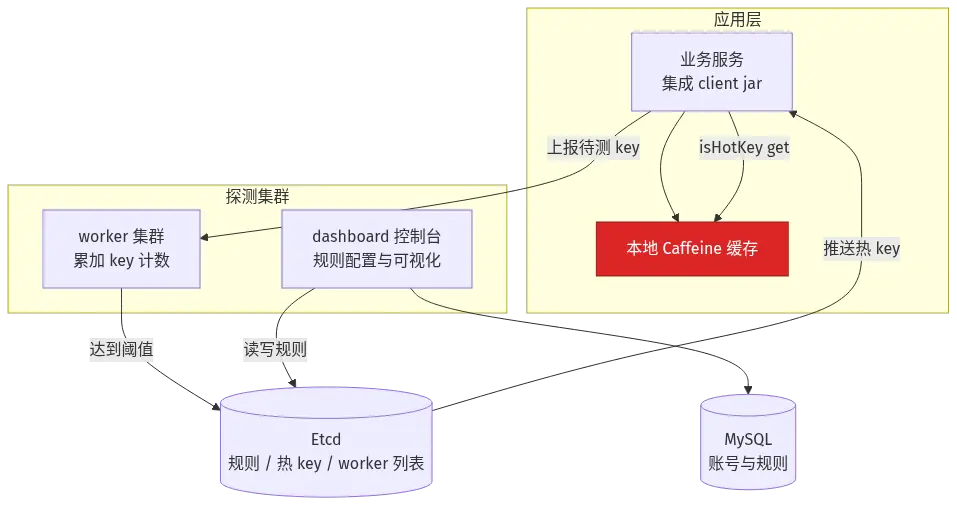
Etcd:高性能分布式键值存储,常用于配置中心和注册中心。在 hotkey 里负责存规则配置、worker 地址、探测出的热 key 列表。
Caffeine:Java 生态里最常用的本地高性能缓存库,相当于"应用进程内的迷你 Redis"。hotkey 把探测到的热 key 缓存到 Caffeine 里,让后续请求直接走进程内存。
四个组件的分工一句话总结:client 上报、worker 累加、etcd 推送、dashboard 配置。
工作时序看这张图:
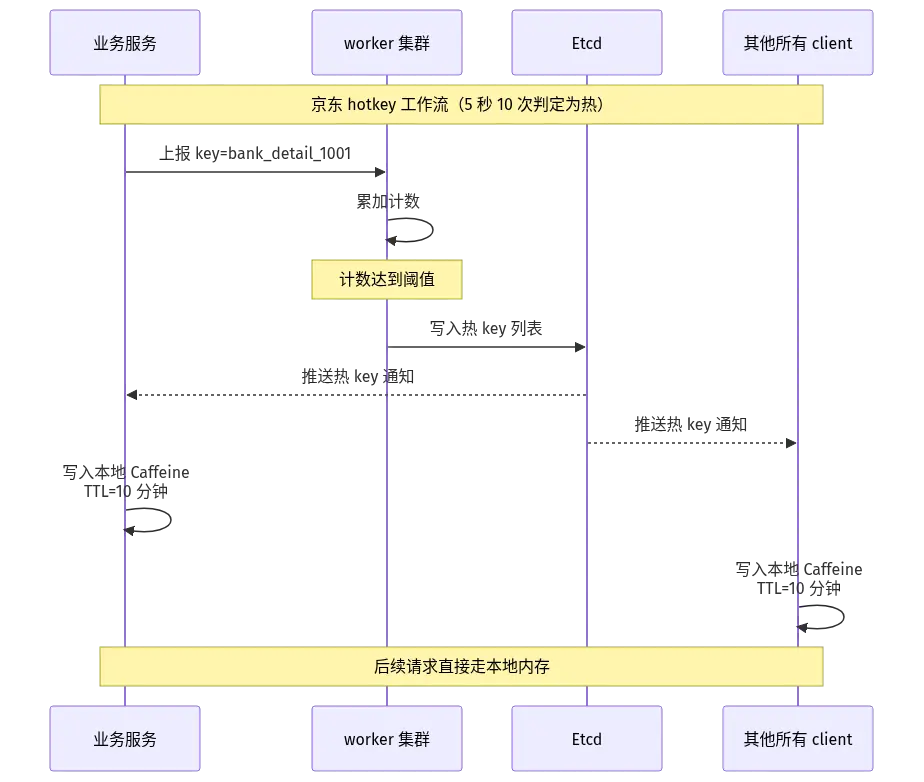
整个链路是毫秒级的------从 worker 探测到达标、写入 etcd、到所有 client 收到推送并写入本地 Caffeine,几乎是大促期间"实时"完成。
3)实战落地:从安装到代码
部署 hotkey 不复杂,但有几个坑我替你踩过了:
- Etcd :从 GitHub releases 下载对应平台版本,解压后跑
etcd脚本,默认占用 2379(HTTP API)和 2380(节点通讯)两个端口。 - Worker :官方 v0.0.4 版本要求 JDK < 17 ,否则会报"找不到类"的诡异错误。修改
application.yml端口后直接启动WorkerApplication。打包用mvn package拿到 jar,部署命令带上参数:java -jar worker-0.0.4-SNAPSHOT.jar --etcd.server=127.0.0.1:2379。 - Dashboard :先在 MySQL 里建库
hotkey_db并执行db.sql,改application.yml里数据库连接和 etcd 地址,启动DashboardApplication,访问 8121 端口。 - Client 引入 :Maven 远程仓库那个包引用量少、出过心跳失败,建议从源码 mvn package 自打 jar ,扔进项目
lib/目录用system作用域引入。注意 system 作用域会跳过 Maven 依赖解析,可能引发 Hutool 版本冲突,必要时把自己项目的 Hutool 降到 client 兼容版本。
应用层初始化:
java
// 示例:hotkey client 初始化
@Configuration
@ConfigurationProperties(prefix = "hotkey")
@Data
public class HotKeyConfig {
private String etcdServer = "http://127.0.0.1:2379";
private String appName = "app";
private int caffeineSize = 10000;
private long pushPeriod = 1000L;
@Bean
public void initHotkey() {
ClientStarter starter = new ClientStarter.Builder()
.setAppName(appName)
.setCaffeineSize(caffeineSize)
.setPushPeriod(pushPeriod)
.setEtcdServer(etcdServer)
.build();
starter.startPipeline();
}
}业务里只要用 JdHotKeyStore 这四个方法就够了:
java
boolean isHot = JdHotKeyStore.isHotKey(key); // 是否热 key
Object v = JdHotKeyStore.get(key); // 取本地缓存
JdHotKeyStore.smartSet(key, value); // 热时才写入本地缓存
Object v2 = JdHotKeyStore.getValue(key); // isHotKey + get 合体可能有人会问:isHotKey 都把 key 上报给 worker 了,那 getValue 不就重复上报?
不重复。看源码就懂:
isHotKey会调用HotKeyPusher.push上报,而get只是纯粹的本地 Caffeine 读取。官方推荐写法 是先isHotKey判断、再get取值,避免getValue的双重副作用。
业务代码长这样(取题库详情接口):
java
// 示例:业务接口接入 hotkey
@GetMapping("/get/vo")
public BaseResponse<QuestionBankVO> getVo(Long id) {
String key = "bank_detail_" + id;
if (JdHotKeyStore.isHotKey(key)) {
Object cached = JdHotKeyStore.get(key);
if (cached != null) return ResultUtils.success((QuestionBankVO) cached);
}
QuestionBankVO vo = bankService.getById(id); // 原始查库逻辑
JdHotKeyStore.smartSet(key, vo); // 热时才缓存
return ResultUtils.success(vo);
}控制台规则配置成 interval=5、threshold=10、duration=600、prefix=true,意思是"5 秒内访问 10 次的 key 推送到本地缓存 10 分钟"。
4)hotkey 与 Redis 分布式缓存的配合
hotkey 不是替代 Redis,而是给 Redis 当"挡箭牌"。两种主流配合方式:
- 方式 A(替换存储):不是热 key 就查 Redis;是热 key 时,写缓存前再判断一次,是热 key 才写 Redis。后续热 key 走 Redis。
- 方式 B(多级缓存) :原本查 DB 的逻辑改成"先查 Redis,再查 DB",hotkey 本地缓存作为最热一层挡在最前。形成 Caffeine → Redis → DB 的多级缓存。
我倾向方式 B------多级缓存是更通用的架构升级,hotkey 只负责"哪些 key 配进 Caffeine"。
5)hotkey 不会自动续期,但有"近过期续命"
有人担心热 key 缓存 10 分钟,但期间持续被访问,过期那一刻会不会击穿?看源码:isHotKey 里有个 isNearExpire 判断,离过期还有 2 秒内时会再次 push ,让这个 key 有机会被重新设为热 key。也就是说,持续被访问的热 key 几乎不会真正过期,雪崩风险被进一步降低。
java
// 示例:hotkey 源码片段(简化)
public static boolean isHotKey(String key) {
boolean isHot = isHot(key);
if (!isHot) {
HotKeyPusher.push(key, null); // 不是热 key 才上报
} else if (isNearExpire(getValueSimple(key))) {
HotKeyPusher.push(key, null); // 快过期再续一次
}
return isHot;
}六、选型建议:不是越多越好,是够用就好
讲了这么多方案,到底怎么选?我给你一张实战选型表,按业务规模递进:
| 业务规模 | 穿透 | 击穿 | 雪崩 | hotkey |
|---|---|---|---|---|
| 小型应用 | 参数校验 + 缓存空值 | 互斥锁 | TTL 随机化 | 不必上 |
| 中型应用 | + 布隆过滤器 | 互斥锁/逻辑过期按场景选 | + Redis 哨兵 + 限流 | 可选 |
| 大促型 | + 黑名单 | 互斥锁兜底 + 逻辑过期 | + 集群 + 多级缓存 | 必上 |
我的核心观点是:治理缓存三大问题不是堆方案,是按业务阶段选方案。小型应用上 hotkey 是过度设计,大促型业务不上 hotkey 是裸奔。每个方案都有它的代价(内存、复杂度、一致性损失),选型时问自己一句"这个代价我能不能接受",答案往往就出来了。
回到开篇那句话------缓存击穿、穿透、雪崩不是三个独立 bug,而是"缓存失效 → 数据库被冲垮"这一根问题的三种姿势。理解了这一层,你就不会再死记"互斥锁治击穿、布隆过滤器治穿透"这种碎片化结论,而是能在事故发生时,从"失效姿势"反推"治理方案"。